
a tale of 4 cpus (was: CPU running smalltalk bytecode)Jecel Assumpcao Jr jecel at merlintec.comTue Feb 12 01:34:48 UTC 2002
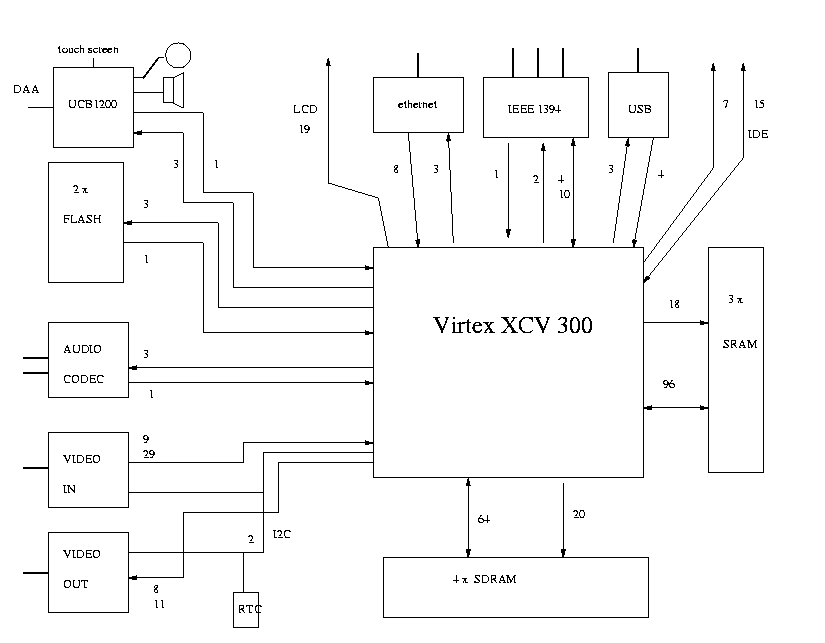
Anyone interested in hardware implementation of OO languages should read: Do object-oriented languages need special hardware support? by Urs Hölzle and David Ungar http://www.cs.ucsb.edu/labs/oocsb/papers/oo-hardware.html Here they contradict most of the results that David Ungar had obtained in SOAR (Smalltalk On A RISC). Note that I happen not to agree with their conclusions, but it is a good paper even so. On Sunday 10 February 2002 19:50, Tim Rowledge wrote: > Of course, there are still little problems like dealing with garbage > collection and primitive stuff; making a hardware interpreter does > nothing for these important areas. True, but SOAR had hardware for write barriers (gc) and tag checking (primitives). The paper I mentioned showed that these didn't help a compiled system (jitter) much, but they might have more of an impact in a simple cpu. Though this is getting very off topic, let me describe the four separate Self/Smalltalk cpu efforts I have been working on (one is currently frozen). - Oliver: a cheap embedded machine with small and narrow memories (512KB of Flash and 8MB of SDRAM, both 16 bits wide). It is actually a Forth cpu, but since this is an FPGA it will be an interesting experiment to do a Smalltalk cpu on this board. - Tachyon: a four bus MOVE processor with a fast external instruction cache (http://www.merlintec.com/merlin6/merlin6c.gif) made from 768KB of ZBT synchronous SRAM. Both the cache (96 bits) and main memory (64 bits) are as wide as possible to increase bandwidth. > My take on things is that a possible and practical change in hardware > that would benefit us (and many programs) would be an instruction > cache that was precisely controllable by the programmer. A 2-4Mb > i-cache that one could actually load the core vm into and _lock_ it > in would be nice. An improvement on that might be to go back to the > writable control store idiom, putting the vm 'above the bus'. A > controllable d-cache might be useful in letting us make sure that > recent contexts and important globals stay cached, stuff like that. That is very much what Tachyon was like. Part of the i-cache contained the VM (most of which was the bytecode->MOVE jitter) and was locked in after boot. I think this is a very good design, but have stopped working on it to do: - Plurion: a set of simple stack machines that execute bytecodes directly. I call this a "Snow White and 7 Dwarfs" architecture since one cpu is more complex than the others and can do a set of transformations on the code as it executes it (it is an interpreting jitter, if I may coin a term). I should mention that I have adopted the Self 4.1 bytecodes for my designs. These are almost exactly the same as Ian's SAM (Squeak Abstract Machine) bytecodes and are much more Smalltalk-like than the Self 4.0 bytecodes. So Squeak could run on my hardware either by making it run on top of Self (in the same way a Java ran on Self in the Jed project, not how GNU Smalltalk ran on Self: binary, not source compatibility is the goal) or by having a "half Jitter". Previously I considered handling Squeak bytecodes directly, but there is a lot of needless complexity in there and I don't have any PhD students handy. > However as I've said again and again (redundantly even), it's > bandwidth, bandwidth and bandwidth. Very true, but the only real solution is to give up the Von Neumann architecture entirely. So I am working on a fourth design which has message passing at the transistor level. Would 4.8e+16 bytes per second make you happy? This would be for a 1 million "cell" chip implemented in 0.18 micron technology. This architecture can't be implemented in FPGAs, unfortunately. I don't have a name for this one yet... -- Jecel
More information about the Squeak-dev mailing list |
{kind=link}