
Hi Eliot,
How about to nil the pc just before making the return: ``` Context >> #cannotReturn: result
self push: self pc. "backup the pc for the sake of debugging" closureOrNil ifNotNil: [^self cannotReturn: result to: self home sender; pc: nil]. Processor debugWithTitle: 'Computation has been terminated!' translated full: false ``` The nilled pc should not even potentially interfere with the #isDead now.
I hope this is at least a step in the right direction :)
However, there's still a problem when debugging the resumption of #cannotReturn because the encoders expect a reasonable index. I haven't figured out yet where to place a nil check - #step, #stepToSendOrReturn... ?
Thanks again, Jaromir
------ Original Message ------ From "Eliot Miranda" eliot.miranda@gmail.com To "Jaromir Matas" mail@jaromir.net Date 11/17/2023 8:36:50 PM Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On Nov 17, 2023, at 7:05 AM, Jaromir Matas mail@jaromir.net wrote:
Eliot, hi again,
Please disregard my previous comment about nilling the contexts that have returned. We are indeed talking about the context directly under the #cannotReturn context which is totally different from the home context in another thread that's gone.
I may still be confused but would nilling the pc of the context directly under the cannotReturn context help? Here's what I mean:
Context >> #cannotReturn: result closureOrNil ifNotNil: [^self pc: nil; cannotReturn: result to: self home sender]. Processor debugWithTitle: 'Computation has been terminated!' translated full: false.Instead of crashing the VM invokes the debugger with the 'Computation has been terminated!' message.
Does this make sense?
Nearly. But it loses the information on what the pc actually is, and that’s potentially vital information. So IMO the ox should only be nilled between the BlockCannotReturn exception being created and raised.
[But if you try this don’t be surprised if it causes a few temporary problems. It looks to me that without a little refactoring this could easily cause an infinite recursion around the sending of isDead. I’m sure you’ll be able to fix the code to work correctly]
Thanks, Jaromir
------ Original Message ------ From "Jaromir Matas" mail@jaromir.net To "Eliot Miranda" eliot.miranda@gmail.com; "The general-purpose Squeak developers list" squeak-dev@lists.squeakfoundation.org Date 11/17/2023 10:15:17 AM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Eliot,
------ Original Message ------ From "Eliot Miranda" eliot.miranda@gmail.com To "Jaromir Matas" mail@jaromir.net Cc "The general-purpose Squeak developers list" squeak-dev@lists.squeakfoundation.org Date 11/16/2023 11:52:45 PM Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas mail@jaromir.net wrote:
Hi Nicolas, Eliot,
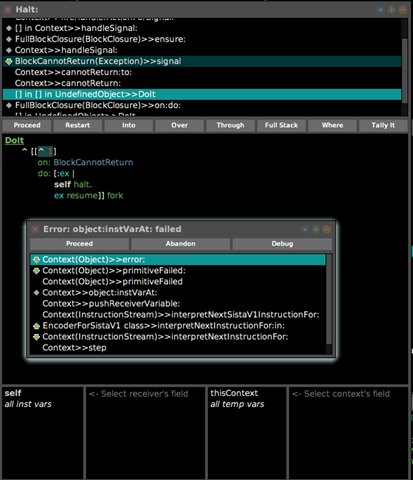
here's what I understand is happening (see the enclosed screenshot):
- we fork a new process to evaluate [^1]
- the new process evaluates [^1] which means instruction 18 is
being evaluated, hence pc points to instruction 19 now 3) however, the home context where ^1 should return to is gone by this time (the process that executed the fork has already returned
- notice the two up arrows in the debugger screenshot)
- the VM can't finish the instruction and returns control to the
image via placing the #cannotReturn: context on top of the [^1] context 5) #cannotReturn: evaluation results in signalling the BCR exception which is then handled by the #resume handler (in our debugged case the [:ex | self halt. ex resume] handler) 6) ex resume is evaluated, however, this means requesting the VM to evaluate instruction 19 of the [^1] context - which is past the last instruction of the context and the crash ensues
I wonder whether such situations could/should be prevented inside the VM or whether such an expectation is wrong for some reason.
As Nicolas says, IMO this is best done at the image level.
It could be prevented in the VM, but at great cost, and only partially. The performance issue is that the last bytecode in a method is not marked in any way, and that to determine the last bytecode the bytecodes must be symbolically evaluated from the start of the method. See implementors of endPC at the image level (which defer to the method trailer) and implementors of endPCOf: in the VMMaker code. Doing this every time execution commences is prohibitively expensive. The "only partially" issue is that following the return instruction may be other valid bytecodes, but these are not a continuation.
Consider the following code in some block: [self expression ifTrue: [^1]. ^2
The bytecodes for this are pushReceiver send #expression jumpFalse L1 push 1 methodReturnTop L1 push 2 methodReturnTop
Clearly if expression is true these should be *no* continuation in which ^2 is executed.
Well, in that case there's a bug because the computation in the following example shouldn't continue past the [^1] block but it silently does: `[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork`
The bytecodes are push true jumpFalse L1 push 1 returnTop L1 push nil blockReturn
So even if the VM did try and detect whether the return was at the last block method, it would only work for special cases.
It seems to me the issue is simply that the context that cannot be returned from should be marked as dead (see Context>>isDead) by setting its pc to nil at some point, presumably after copying the actual return pc into the BlockCannotReturn exception, to avoid ever trying to resume the context.
Does this mean, in other words, that every context that returns should nil its pc to avoid being "wrongly" reused/executed in the future, which concerns primarily those being referenced somewhere hence potentially executable in the future, is that right? Hypothetical question: would nilling the pc during returns "fix" the example? Thanks a lot for helping me understand this. Best, Jaromir
Thanks, Jaromir
<bdxuqalu.png>
------ Original Message ------ From "Eliot Miranda" eliot.miranda@gmail.com To "Jaromir Matas" mail@jaromir.net; "The general-purpose Squeak developers list" squeak-dev@lists.squeakfoundation.org Date 11/16/2023 6:48:43 PM Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
>On Nov 16, 2023, at 3:23 AM, Jaromir Matas mail@jaromir.net >wrote: > > >Hi Nicloas, >No no, I don't have any practical scenario in mind, I'm just >trying to understand why the VM is implemented like this, whether >there were a reason to leave this possibility of a crash, e.g. it >would slow down the VM to try to prevent such a dumb situation >(who would resume from BCR in his right mind? :) ) - or perhaps I >have overlooked some good reason to even keep this behavior in >the VM. That's all.
Let’s first understand what’s really happening. Presumably at tone point a context is resumed those pc is already at the block return bytecode (effectively, because it crashes in JITted code, but I bet the stack vm will crash also, but not as cleanly - it will try and execute the bytes in the encoded method trailer). So which method actually sends resume, and to what, and what state is resume’s receiver when resume is sent?
> >Thanks for your reply. >Regards, >Jaromir > > > > >------ Original Message ------ >From "Nicolas Cellier" nicolas.cellier.aka.nice@gmail.com >To "Jaromir Matas" mail@jaromir.net; "The general-purpose >Squeak developers list" squeak-dev@lists.squeakfoundation.org >Date 11/16/2023 7:20:20 AM >Subject Re: [squeak-dev] Resuming on BlockCannotReturn exception > >>Hi Jaromir, >>Is there a scenario where it would make sense to resume a >>BlockCannotReturn? >>If not, I would suggest to protect at image side and override >>#resume. >> >>Le mer. 15 nov. 2023, 23:42, Jaromir Matas mail@jaromir.net a >>écrit : >>>Hi Eliot, Christoph, All, >>> >>>It's known the following example crashes the VM. Is this an >>>intended behavior or a "tolerated bug"? >>> >>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>> >>>I understand why it crashes: the non-local return has nowhere >>>to return to and so resuming the computation leads to a crash. >>>But why not raise another BCR exception to prevent the crash? >>>Potential infinite loop? Perhaps I'm just missing the purpose >>>of this behavior... >>> >>>Thanks for an explanation. >>> >>>Best, >>>Jaromir >>> >>>-- >>> >>>Jaromir Matas >>> >>> >
-- _,,,^..^,,,_ best, Eliot
<Context-cannotReturn.st>
Hi Eliot,
------ Original Message ------ From "Jaromir Matas" mail@jaromir.net To "Eliot Miranda" eliot.miranda@gmail.com; squeak-dev@lists.squeakfoundation.org Date 11/18/2023 12:14:31 AM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Eliot,
How about to nil the pc just before making the return:
Context >> #cannotReturn: result self push: self pc. "backup the pc for the sake of debugging" closureOrNil ifNotNil: [^self cannotReturn: result to: self home sender; pc: nil]. Processor debugWithTitle: 'Computation has been terminated!' translated full: falseThe nilled pc should not even potentially interfere with the #isDead now.
I hope this is at least a step in the right direction :)
However, there's still a problem when debugging the resumption of #cannotReturn because the encoders expect a reasonable index. I haven't figured out yet where to place a nil check - #step, #stepToSendOrReturn... ?
This debugger issue has nothing to do with the proposed change... the debugging fails in the current trunk image too:
Run `[[^ 1] on: BlockCannotReturn do: [:ex | self halt. ex resume] ] fork` Click on the highlighted context Step into
So, if the suggested solution makes sense to you, it would make 'playing with fire' a bit safer :)
best, Jaromir
Thanks again, Jaromir
------ Original Message ------ From "Eliot Miranda" eliot.miranda@gmail.com To "Jaromir Matas" mail@jaromir.net Date 11/17/2023 8:36:50 PM Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On Nov 17, 2023, at 7:05 AM, Jaromir Matas mail@jaromir.net wrote:
Eliot, hi again,
Please disregard my previous comment about nilling the contexts that have returned. We are indeed talking about the context directly under the #cannotReturn context which is totally different from the home context in another thread that's gone.
I may still be confused but would nilling the pc of the context directly under the cannotReturn context help? Here's what I mean:
Context >> #cannotReturn: result closureOrNil ifNotNil: [^self pc: nil; cannotReturn: result to: self home sender]. Processor debugWithTitle: 'Computation has been terminated!' translated full: false.Instead of crashing the VM invokes the debugger with the 'Computation has been terminated!' message.
Does this make sense?
Nearly. But it loses the information on what the pc actually is, and that’s potentially vital information. So IMO the ox should only be nilled between the BlockCannotReturn exception being created and raised.
[But if you try this don’t be surprised if it causes a few temporary problems. It looks to me that without a little refactoring this could easily cause an infinite recursion around the sending of isDead. I’m sure you’ll be able to fix the code to work correctly]
Thanks, Jaromir
------ Original Message ------ From "Jaromir Matas" mail@jaromir.net To "Eliot Miranda" eliot.miranda@gmail.com; "The general-purpose Squeak developers list" squeak-dev@lists.squeakfoundation.org Date 11/17/2023 10:15:17 AM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Eliot,
------ Original Message ------ From "Eliot Miranda" eliot.miranda@gmail.com To "Jaromir Matas" mail@jaromir.net Cc "The general-purpose Squeak developers list" squeak-dev@lists.squeakfoundation.org Date 11/16/2023 11:52:45 PM Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas mail@jaromir.net wrote:
Hi Nicolas, Eliot,
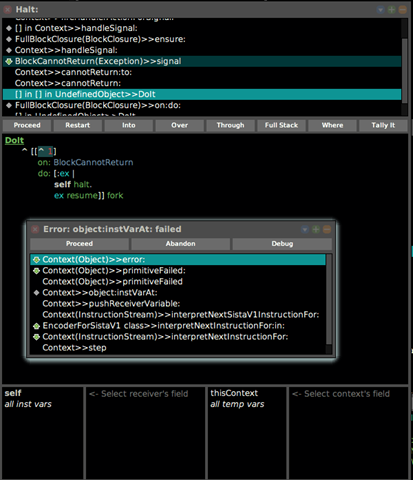
here's what I understand is happening (see the enclosed screenshot):
- we fork a new process to evaluate [^1]
- the new process evaluates [^1] which means instruction 18 is
being evaluated, hence pc points to instruction 19 now 3) however, the home context where ^1 should return to is gone by this time (the process that executed the fork has already returned
- notice the two up arrows in the debugger screenshot)
- the VM can't finish the instruction and returns control to the
image via placing the #cannotReturn: context on top of the [^1] context 5) #cannotReturn: evaluation results in signalling the BCR exception which is then handled by the #resume handler (in our debugged case the [:ex | self halt. ex resume] handler) 6) ex resume is evaluated, however, this means requesting the VM to evaluate instruction 19 of the [^1] context - which is past the last instruction of the context and the crash ensues
I wonder whether such situations could/should be prevented inside the VM or whether such an expectation is wrong for some reason.
As Nicolas says, IMO this is best done at the image level.
It could be prevented in the VM, but at great cost, and only partially. The performance issue is that the last bytecode in a method is not marked in any way, and that to determine the last bytecode the bytecodes must be symbolically evaluated from the start of the method. See implementors of endPC at the image level (which defer to the method trailer) and implementors of endPCOf: in the VMMaker code. Doing this every time execution commences is prohibitively expensive. The "only partially" issue is that following the return instruction may be other valid bytecodes, but these are not a continuation.
Consider the following code in some block: [self expression ifTrue: [^1]. ^2
The bytecodes for this are pushReceiver send #expression jumpFalse L1 push 1 methodReturnTop L1 push 2 methodReturnTop
Clearly if expression is true these should be *no* continuation in which ^2 is executed.
Well, in that case there's a bug because the computation in the following example shouldn't continue past the [^1] block but it silently does: `[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork`
The bytecodes are push true jumpFalse L1 push 1 returnTop L1 push nil blockReturn
So even if the VM did try and detect whether the return was at the last block method, it would only work for special cases.
It seems to me the issue is simply that the context that cannot be returned from should be marked as dead (see Context>>isDead) by setting its pc to nil at some point, presumably after copying the actual return pc into the BlockCannotReturn exception, to avoid ever trying to resume the context.
Does this mean, in other words, that every context that returns should nil its pc to avoid being "wrongly" reused/executed in the future, which concerns primarily those being referenced somewhere hence potentially executable in the future, is that right? Hypothetical question: would nilling the pc during returns "fix" the example? Thanks a lot for helping me understand this. Best, Jaromir
Thanks, Jaromir
<bdxuqalu.png>
------ Original Message ------ From "Eliot Miranda" eliot.miranda@gmail.com To "Jaromir Matas" mail@jaromir.net; "The general-purpose Squeak developers list" squeak-dev@lists.squeakfoundation.org Date 11/16/2023 6:48:43 PM Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception
>Hi Jaromir, > >>On Nov 16, 2023, at 3:23 AM, Jaromir Matas mail@jaromir.net >>wrote: >> >> >>Hi Nicloas, >>No no, I don't have any practical scenario in mind, I'm just >>trying to understand why the VM is implemented like this, >>whether there were a reason to leave this possibility of a >>crash, e.g. it would slow down the VM to try to prevent such a >>dumb situation (who would resume from BCR in his right mind? :) >>) - or perhaps I have overlooked some good reason to even keep >>this behavior in the VM. That's all. > >Let’s first understand what’s really happening. Presumably at >tone point a context is resumed those pc is already at the block >return bytecode (effectively, because it crashes in JITted code, >but I bet the stack vm will crash also, but not as cleanly - it >will try and execute the bytes in the encoded method trailer). So >which method actually sends resume, and to what, and what state >is resume’s receiver when resume is sent? > > >> >>Thanks for your reply. >>Regards, >>Jaromir >> >> >> >> >>------ Original Message ------ >>From "Nicolas Cellier" nicolas.cellier.aka.nice@gmail.com >>To "Jaromir Matas" mail@jaromir.net; "The general-purpose >>Squeak developers list" squeak-dev@lists.squeakfoundation.org >>Date 11/16/2023 7:20:20 AM >>Subject Re: [squeak-dev] Resuming on BlockCannotReturn exception >> >>>Hi Jaromir, >>>Is there a scenario where it would make sense to resume a >>>BlockCannotReturn? >>>If not, I would suggest to protect at image side and override >>>#resume. >>> >>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas mail@jaromir.net a >>>écrit : >>>>Hi Eliot, Christoph, All, >>>> >>>>It's known the following example crashes the VM. Is this an >>>>intended behavior or a "tolerated bug"? >>>> >>>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>> >>>>I understand why it crashes: the non-local return has nowhere >>>>to return to and so resuming the computation leads to a crash. >>>>But why not raise another BCR exception to prevent the crash? >>>>Potential infinite loop? Perhaps I'm just missing the purpose >>>>of this behavior... >>>> >>>>Thanks for an explanation. >>>> >>>>Best, >>>>Jaromir >>>> >>>>-- >>>> >>>>Jaromir Matas >>>> >>>> >>
-- _,,,^..^,,,_ best, Eliot
<Context-cannotReturn.st>
{kind=link}
Hi Eliot, all,
I've sent Kernel-jar.1535 with a suggested fix dealing with the following two examples discussed in this thread:
[[^ 1] on: BlockCannotReturn do: #resume ] fork. "VM crash"
[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork. "Illegal return from ^1"
Now both examples work correctly.
In addition, Tools-jar.1240 is an attempt to facilitate debugging the resumption from the BCR exception. Currently the debugger opens with a confusing error as a consequence of decoding an instruction with nil index. In case you have a better idea where to place the fix, please let me know.
Thanks for your help,
best, Jaromir
-- Jaromir Matas
------ Original Message ------ From "Jaromir Matas" mail@jaromir.net To "Eliot Miranda" eliot.miranda@gmail.com; squeak-dev@lists.squeakfoundation.org Date 11/18/2023 12:53:18 PM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Eliot,
------ Original Message ------ From "Jaromir Matas" mail@jaromir.net To "Eliot Miranda" eliot.miranda@gmail.com; squeak-dev@lists.squeakfoundation.org Date 11/18/2023 12:14:31 AM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Eliot,
How about to nil the pc just before making the return:
Context >> #cannotReturn: result self push: self pc. "backup the pc for the sake of debugging" closureOrNil ifNotNil: [^self cannotReturn: result to: self home sender; pc: nil]. Processor debugWithTitle: 'Computation has been terminated!' translated full: falseThe nilled pc should not even potentially interfere with the #isDead now.
I hope this is at least a step in the right direction :)
However, there's still a problem when debugging the resumption of #cannotReturn because the encoders expect a reasonable index. I haven't figured out yet where to place a nil check - #step, #stepToSendOrReturn... ?
This debugger issue has nothing to do with the proposed change... the debugging fails in the current trunk image too:
Run `[[^ 1] on: BlockCannotReturn do: [:ex | self halt. ex resume] ] fork` Click on the highlighted context Step into
So, if the suggested solution makes sense to you, it would make 'playing with fire' a bit safer :)
best, Jaromir
Thanks again, Jaromir
------ Original Message ------ From "Eliot Miranda" eliot.miranda@gmail.com To "Jaromir Matas" mail@jaromir.net Date 11/17/2023 8:36:50 PM Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On Nov 17, 2023, at 7:05 AM, Jaromir Matas mail@jaromir.net wrote:
Eliot, hi again,
Please disregard my previous comment about nilling the contexts that have returned. We are indeed talking about the context directly under the #cannotReturn context which is totally different from the home context in another thread that's gone.
I may still be confused but would nilling the pc of the context directly under the cannotReturn context help? Here's what I mean:
Context >> #cannotReturn: result closureOrNil ifNotNil: [^self pc: nil; cannotReturn: result to: self home sender]. Processor debugWithTitle: 'Computation has been terminated!' translated full: false.Instead of crashing the VM invokes the debugger with the 'Computation has been terminated!' message.
Does this make sense?
Nearly. But it loses the information on what the pc actually is, and that’s potentially vital information. So IMO the ox should only be nilled between the BlockCannotReturn exception being created and raised.
[But if you try this don’t be surprised if it causes a few temporary problems. It looks to me that without a little refactoring this could easily cause an infinite recursion around the sending of isDead. I’m sure you’ll be able to fix the code to work correctly]
Thanks, Jaromir
------ Original Message ------ From "Jaromir Matas" mail@jaromir.net To "Eliot Miranda" eliot.miranda@gmail.com; "The general-purpose Squeak developers list" squeak-dev@lists.squeakfoundation.org Date 11/17/2023 10:15:17 AM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Eliot,
------ Original Message ------ From "Eliot Miranda" eliot.miranda@gmail.com To "Jaromir Matas" mail@jaromir.net Cc "The general-purpose Squeak developers list" squeak-dev@lists.squeakfoundation.org Date 11/16/2023 11:52:45 PM Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas mail@jaromir.net wrote: >Hi Nicolas, Eliot, > >here's what I understand is happening (see the enclosed >screenshot): > >1) we fork a new process to evaluate [^1] >2) the new process evaluates [^1] which means instruction 18 is >being evaluated, hence pc points to instruction 19 now >3) however, the home context where ^1 should return to is gone by >this time (the process that executed the fork has already >returned - notice the two up arrows in the debugger screenshot) >4) the VM can't finish the instruction and returns control to the >image via placing the #cannotReturn: context on top of the [^1] >context >5) #cannotReturn: evaluation results in signalling the BCR >exception which is then handled by the #resume handler > (in our debugged case the [:ex | self halt. ex resume] >handler) >6) ex resume is evaluated, however, this means requesting the VM >to evaluate instruction 19 of the [^1] context - which is past >the last instruction of the context and the crash ensues > >I wonder whether such situations could/should be prevented inside >the VM or whether such an expectation is wrong for some reason.
As Nicolas says, IMO this is best done at the image level.
It could be prevented in the VM, but at great cost, and only partially. The performance issue is that the last bytecode in a method is not marked in any way, and that to determine the last bytecode the bytecodes must be symbolically evaluated from the start of the method. See implementors of endPC at the image level (which defer to the method trailer) and implementors of endPCOf: in the VMMaker code. Doing this every time execution commences is prohibitively expensive. The "only partially" issue is that following the return instruction may be other valid bytecodes, but these are not a continuation.
Consider the following code in some block: [self expression ifTrue: [^1]. ^2
The bytecodes for this are pushReceiver send #expression jumpFalse L1 push 1 methodReturnTop L1 push 2 methodReturnTop
Clearly if expression is true these should be *no* continuation in which ^2 is executed.
Well, in that case there's a bug because the computation in the following example shouldn't continue past the [^1] block but it silently does: `[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork`
The bytecodes are push true jumpFalse L1 push 1 returnTop L1 push nil blockReturn
So even if the VM did try and detect whether the return was at the last block method, it would only work for special cases.
It seems to me the issue is simply that the context that cannot be returned from should be marked as dead (see Context>>isDead) by setting its pc to nil at some point, presumably after copying the actual return pc into the BlockCannotReturn exception, to avoid ever trying to resume the context.
Does this mean, in other words, that every context that returns should nil its pc to avoid being "wrongly" reused/executed in the future, which concerns primarily those being referenced somewhere hence potentially executable in the future, is that right? Hypothetical question: would nilling the pc during returns "fix" the example? Thanks a lot for helping me understand this. Best, Jaromir
> >Thanks, >Jaromir > ><bdxuqalu.png> > >------ Original Message ------ >From "Eliot Miranda" eliot.miranda@gmail.com >To "Jaromir Matas" mail@jaromir.net; "The general-purpose >Squeak developers list" squeak-dev@lists.squeakfoundation.org >Date 11/16/2023 6:48:43 PM >Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn >exception > >>Hi Jaromir, >> >>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas mail@jaromir.net >>>wrote: >>> >>> >>>Hi Nicloas, >>>No no, I don't have any practical scenario in mind, I'm just >>>trying to understand why the VM is implemented like this, >>>whether there were a reason to leave this possibility of a >>>crash, e.g. it would slow down the VM to try to prevent such a >>>dumb situation (who would resume from BCR in his right mind? :) >>>) - or perhaps I have overlooked some good reason to even keep >>>this behavior in the VM. That's all. >> >>Let’s first understand what’s really happening. Presumably at >>tone point a context is resumed those pc is already at the block >>return bytecode (effectively, because it crashes in JITted code, >>but I bet the stack vm will crash also, but not as cleanly - it >>will try and execute the bytes in the encoded method trailer). >>So which method actually sends resume, and to what, and what >>state is resume’s receiver when resume is sent? >> >> >>> >>>Thanks for your reply. >>>Regards, >>>Jaromir >>> >>> >>> >>> >>>------ Original Message ------ >>>From "Nicolas Cellier" nicolas.cellier.aka.nice@gmail.com >>>To "Jaromir Matas" mail@jaromir.net; "The general-purpose >>>Squeak developers list" squeak-dev@lists.squeakfoundation.org >>>Date 11/16/2023 7:20:20 AM >>>Subject Re: [squeak-dev] Resuming on BlockCannotReturn >>>exception >>> >>>>Hi Jaromir, >>>>Is there a scenario where it would make sense to resume a >>>>BlockCannotReturn? >>>>If not, I would suggest to protect at image side and override >>>>#resume. >>>> >>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas mail@jaromir.net >>>>a écrit : >>>>>Hi Eliot, Christoph, All, >>>>> >>>>>It's known the following example crashes the VM. Is this an >>>>>intended behavior or a "tolerated bug"? >>>>> >>>>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>>> >>>>>I understand why it crashes: the non-local return has nowhere >>>>>to return to and so resuming the computation leads to a >>>>>crash. But why not raise another BCR exception to prevent the >>>>>crash? Potential infinite loop? Perhaps I'm just missing the >>>>>purpose of this behavior... >>>>> >>>>>Thanks for an explanation. >>>>> >>>>>Best, >>>>>Jaromir >>>>> >>>>>-- >>>>> >>>>>Jaromir Matas >>>>> >>>>> >>>
-- _,,,^..^,,,_ best, Eliot
<Context-cannotReturn.st>
{kind=link}

Hi Jaromir,
thanks for looking into this!
[[^ 1] on: BlockCannotReturn do: #resume ] fork. "VM crash"
Indeed, this could and should be handled more robustly in the image!
[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork. "Illegal return from ^1"
Is this really illegal? Remember that resuming an exception is generally something special, and as this exception refers to a return instruction, resuming it is something I would definitely consider metaprogramming or worse. Thinking of ^ 1 as a syntactic sugar for "thisContext home return: 1", I would actually find it plausible that resuming from the exception would skip the #return: send. However, I have not read the entire conversation, so if Eliot says something different, please ignore this objection. :-)
Kernel-jar.1535:
- closureOrNil ifNotNil: [^self cannotReturn: result to: self home sender; push: pc; pc: nil].
Do I understand correctly that the pushed pc is only visible when manually inspecting the context? This is something very unexpected to me, it just feels as if you did not find any better place to store this information. Especially if there is no ready path available to access it later. Or am I wrong? Given the expected rareness of those events and the even greater rareness of multiple non-local returns from a single block context that has survived their home context, I wonder whether this information is actually required. If yes, why don't store it in the BlockCannotReturn exception instead?
Tools-jar.1240
Can you give me an example of where this extra notification adds any value for the user? If I run any of your two examples without the change in the Debugger, I just get a Computation has been terminated error while the #cannotReturn: stack is still available, which already seems to give me all information required to identify the origin of the error, in particular due to the extensive comment in this method.
Best, Christoph
--- Sent from Squeak Inbox Talk
On 2023-11-19T17:44:24+00:00, mail@jaromir.net wrote:
Hi Eliot, all,
I've sent Kernel-jar.1535 with a suggested fix dealing with the following two examples discussed in this thread:
[[^ 1] on: BlockCannotReturn do: #resume ] fork. "VM crash"
[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork. "Illegal return from ^1"
Now both examples work correctly.
In addition, Tools-jar.1240 is an attempt to facilitate debugging the resumption from the BCR exception. Currently the debugger opens with a confusing error as a consequence of decoding an instruction with nil index. In case you have a better idea where to place the fix, please let me know.
Thanks for your help,
best, Jaromir
-- Jaromir Matas
------ Original Message ------
From "Jaromir Matas" <mail(a)jaromir.net>
To "Eliot Miranda" <eliot.miranda(a)gmail.com>; squeak-dev(a)lists.squeakfoundation.org Date 11/18/2023 12:53:18 PM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Eliot,
------ Original Message ------ From "Jaromir Matas" <mail(a)jaromir.net> To "Eliot Miranda" <eliot.miranda(a)gmail.com>; squeak-dev(a)lists.squeakfoundation.org Date 11/18/2023 12:14:31 AM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Eliot,
How about to nil the pc just before making the return:
Context >> #cannotReturn: result self push: self pc. "backup the pc for the sake of debugging" closureOrNil ifNotNil: [^self cannotReturn: result to: self home sender; pc: nil]. Processor debugWithTitle: 'Computation has been terminated!' translated full: falseThe nilled pc should not even potentially interfere with the #isDead now.
I hope this is at least a step in the right direction :)
However, there's still a problem when debugging the resumption of #cannotReturn because the encoders expect a reasonable index. I haven't figured out yet where to place a nil check - #step, #stepToSendOrReturn... ?
This debugger issue has nothing to do with the proposed change... the debugging fails in the current trunk image too:
Run `[[^ 1] on: BlockCannotReturn do: [:ex | self halt. ex resume] ] fork` Click on the highlighted context Step into
So, if the suggested solution makes sense to you, it would make 'playing with fire' a bit safer :)
best, Jaromir
Thanks again, Jaromir
------ Original Message ------ From "Eliot Miranda" <eliot.miranda(a)gmail.com> To "Jaromir Matas" <mail(a)jaromir.net> Date 11/17/2023 8:36:50 PM Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On Nov 17, 2023, at 7:05 AM, Jaromir Matas <mail(a)jaromir.net> wrote:
Eliot, hi again,
Please disregard my previous comment about nilling the contexts that have returned. We are indeed talking about the context directly under the #cannotReturn context which is totally different from the home context in another thread that's gone.
I may still be confused but would nilling the pc of the context directly under the cannotReturn context help? Here's what I mean:
Context >> #cannotReturn: result closureOrNil ifNotNil: [^self pc: nil; cannotReturn: result to: self home sender]. Processor debugWithTitle: 'Computation has been terminated!' translated full: false.Instead of crashing the VM invokes the debugger with the 'Computation has been terminated!' message.
Does this make sense?
Nearly. But it loses the information on what the pc actually is, and that’s potentially vital information. So IMO the ox should only be nilled between the BlockCannotReturn exception being created and raised.
[But if you try this don’t be surprised if it causes a few temporary problems. It looks to me that without a little refactoring this could easily cause an infinite recursion around the sending of isDead. I’m sure you’ll be able to fix the code to work correctly]
Thanks, Jaromir
------ Original Message ------ From "Jaromir Matas" <mail(a)jaromir.net> To "Eliot Miranda" <eliot.miranda(a)gmail.com>; "The general-purpose Squeak developers list" <squeak-dev(a)lists.squeakfoundation.org> Date 11/17/2023 10:15:17 AM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Eliot,
------ Original Message ------ From "Eliot Miranda" <eliot.miranda(a)gmail.com> To "Jaromir Matas" <mail(a)jaromir.net> Cc "The general-purpose Squeak developers list" <squeak-dev(a)lists.squeakfoundation.org> Date 11/16/2023 11:52:45 PM Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn exception
>Hi Jaromir, > >On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas <mail(a)jaromir.net> >wrote: >>Hi Nicolas, Eliot, >> >>here's what I understand is happening (see the enclosed >>screenshot): >> >>1) we fork a new process to evaluate [^1] >>2) the new process evaluates [^1] which means instruction 18 is >>being evaluated, hence pc points to instruction 19 now >>3) however, the home context where ^1 should return to is gone by >>this time (the process that executed the fork has already >>returned - notice the two up arrows in the debugger screenshot) >>4) the VM can't finish the instruction and returns control to the >>image via placing the #cannotReturn: context on top of the [^1] >>context >>5) #cannotReturn: evaluation results in signalling the BCR >>exception which is then handled by the #resume handler >> (in our debugged case the [:ex | self halt. ex resume] >>handler) >>6) ex resume is evaluated, however, this means requesting the VM >>to evaluate instruction 19 of the [^1] context - which is past >>the last instruction of the context and the crash ensues >> >>I wonder whether such situations could/should be prevented inside >>the VM or whether such an expectation is wrong for some reason. > >As Nicolas says, IMO this is best done at the image level. > >It could be prevented in the VM, but at great cost, and only >partially. The performance issue is that the last bytecode in a >method is not marked in any way, and that to determine the last >bytecode the bytecodes must be symbolically evaluated from the >start of the method. See implementors of endPC at the image level >(which defer to the method trailer) and implementors of endPCOf: >in the VMMaker code. Doing this every time execution commences is >prohibitively expensive. The "only partially" issue is that >following the return instruction may be other valid bytecodes, but >these are not a continuation. > > >Consider the following code in some block: > [self expression ifTrue: > [^1]. > ^2 > >The bytecodes for this are > pushReceiver > send #expression > jumpFalse L1 > push 1 > methodReturnTop >L1 > push 2 > methodReturnTop > >Clearly if expression is true these should be *no* continuation in >which ^2 is executed.
Well, in that case there's a bug because the computation in the following example shouldn't continue past the [^1] block but it silently does: `[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork`
The bytecodes are push true jumpFalse L1 push 1 returnTop L1 push nil blockReturn
> >So even if the VM did try and detect whether the return was at the >last block method, it would only work for special cases. > > >It seems to me the issue is simply that the context that cannot be >returned from should be marked as dead (see Context>>isDead) by >setting its pc to nil at some point, presumably after copying the >actual return pc into the BlockCannotReturn exception, to avoid >ever trying to resume the context.
Does this mean, in other words, that every context that returns should nil its pc to avoid being "wrongly" reused/executed in the future, which concerns primarily those being referenced somewhere hence potentially executable in the future, is that right? Hypothetical question: would nilling the pc during returns "fix" the example? Thanks a lot for helping me understand this. Best, Jaromir
> > >> >>Thanks, >>Jaromir >> >><bdxuqalu.png> >> >>------ Original Message ------ >>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>To "Jaromir Matas" <mail(a)jaromir.net>; "The general-purpose >>Squeak developers list" <squeak-dev(a)lists.squeakfoundation.org> >>Date 11/16/2023 6:48:43 PM >>Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn >>exception >> >>>Hi Jaromir, >>> >>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas <mail(a)jaromir.net> >>>>wrote: >>>> >>>> >>>>Hi Nicloas, >>>>No no, I don't have any practical scenario in mind, I'm just >>>>trying to understand why the VM is implemented like this, >>>>whether there were a reason to leave this possibility of a >>>>crash, e.g. it would slow down the VM to try to prevent such a >>>>dumb situation (who would resume from BCR in his right mind? :) >>>>) - or perhaps I have overlooked some good reason to even keep >>>>this behavior in the VM. That's all. >>> >>>Let’s first understand what’s really happening. Presumably at >>>tone point a context is resumed those pc is already at the block >>>return bytecode (effectively, because it crashes in JITted code, >>>but I bet the stack vm will crash also, but not as cleanly - it >>>will try and execute the bytes in the encoded method trailer). >>>So which method actually sends resume, and to what, and what >>>state is resume’s receiver when resume is sent? >>> >>> >>>> >>>>Thanks for your reply. >>>>Regards, >>>>Jaromir >>>> >>>> >>>> >>>> >>>>------ Original Message ------ >>>>From "Nicolas Cellier" <nicolas.cellier.aka.nice(a)gmail.com> >>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The general-purpose >>>>Squeak developers list" <squeak-dev(a)lists.squeakfoundation.org> >>>>Date 11/16/2023 7:20:20 AM >>>>Subject Re: [squeak-dev] Resuming on BlockCannotReturn >>>>exception >>>> >>>>>Hi Jaromir, >>>>>Is there a scenario where it would make sense to resume a >>>>>BlockCannotReturn? >>>>>If not, I would suggest to protect at image side and override >>>>>#resume. >>>>> >>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas <mail(a)jaromir.net> >>>>>a écrit : >>>>>>Hi Eliot, Christoph, All, >>>>>> >>>>>>It's known the following example crashes the VM. Is this an >>>>>>intended behavior or a "tolerated bug"? >>>>>> >>>>>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>>>> >>>>>>I understand why it crashes: the non-local return has nowhere >>>>>>to return to and so resuming the computation leads to a >>>>>>crash. But why not raise another BCR exception to prevent the >>>>>>crash? Potential infinite loop? Perhaps I'm just missing the >>>>>>purpose of this behavior... >>>>>> >>>>>>Thanks for an explanation. >>>>>> >>>>>>Best, >>>>>>Jaromir >>>>>> >>>>>>-- >>>>>> >>>>>>Jaromir Matas >>>>>> >>>>>> >>>> > > >-- >_,,,^..^,,,_ >best, Eliot
<Context-cannotReturn.st>
On 2023-11-19T19:04:35+01:00, christoph.thiede@student.hpi.uni-potsdam.de wrote:
Hi Jaromir,
thanks for looking into this!
[[^ 1] on: BlockCannotReturn do: #resume ] fork. "VM crash"
Indeed, this could and should be handled more robustly in the image!
[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork. "Illegal return from ^1"
Is this really illegal? Remember that resuming an exception is generally something special, and as this exception refers to a return instruction, resuming it is something I would definitely consider metaprogramming or worse. Thinking of ^ 1 as a syntactic sugar for "thisContext home return: 1", I would actually find it plausible that resuming from the exception would skip the #return: send. However, I have not read the entire conversation, so if Eliot says something different, please ignore this objection. :-)
Ah, I just found https://lists.squeakfoundation.org/archives/list/squeak-dev@lists.squeakfoun... again. Sorry for ghosting you on that conversation, I really seem to lack capacities for all these exciting discussions. :-( Seems like this question is settled then. Do we already have tests for that expectation?
Kernel-jar.1535:
- closureOrNil ifNotNil: [^self cannotReturn: result to: self home sender; push: pc; pc: nil].
Do I understand correctly that the pushed pc is only visible when manually inspecting the context? This is something very unexpected to me, it just feels as if you did not find any better place to store this information. Especially if there is no ready path available to access it later. Or am I wrong? Given the expected rareness of those events and the even greater rareness of multiple non-local returns from a single block context that has survived their home context, I wonder whether this information is actually required. If yes, why don't store it in the BlockCannotReturn exception instead?
Tools-jar.1240
Can you give me an example of where this extra notification adds any value for the user? If I run any of your two examples without the change in the Debugger, I just get a Computation has been terminated error while the #cannotReturn: stack is still available, which already seems to give me all information required to identify the origin of the error, in particular due to the extensive comment in this method.
Best, Christoph
Sent from Squeak Inbox Talk
On 2023-11-19T17:44:24+00:00, mail(a)jaromir.net wrote:
Hi Eliot, all,
I've sent Kernel-jar.1535 with a suggested fix dealing with the following two examples discussed in this thread:
[[^ 1] on: BlockCannotReturn do: #resume ] fork. "VM crash"
[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork. "Illegal return from ^1"
Now both examples work correctly.
In addition, Tools-jar.1240 is an attempt to facilitate debugging the resumption from the BCR exception. Currently the debugger opens with a confusing error as a consequence of decoding an instruction with nil index. In case you have a better idea where to place the fix, please let me know.
Thanks for your help,
best, Jaromir
-- Jaromir Matas
------ Original Message ------
From "Jaromir Matas" <mail(a)jaromir.net>
To "Eliot Miranda" <eliot.miranda(a)gmail.com>; squeak-dev(a)lists.squeakfoundation.org Date 11/18/2023 12:53:18 PM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Eliot,
------ Original Message ------ From "Jaromir Matas" <mail(a)jaromir.net> To "Eliot Miranda" <eliot.miranda(a)gmail.com>; squeak-dev(a)lists.squeakfoundation.org Date 11/18/2023 12:14:31 AM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Eliot,
How about to nil the pc just before making the return:
Context >> #cannotReturn: result self push: self pc. "backup the pc for the sake of debugging" closureOrNil ifNotNil: [^self cannotReturn: result to: self home sender; pc: nil]. Processor debugWithTitle: 'Computation has been terminated!' translated full: falseThe nilled pc should not even potentially interfere with the #isDead now.
I hope this is at least a step in the right direction :)
However, there's still a problem when debugging the resumption of #cannotReturn because the encoders expect a reasonable index. I haven't figured out yet where to place a nil check - #step, #stepToSendOrReturn... ?
This debugger issue has nothing to do with the proposed change... the debugging fails in the current trunk image too:
Run `[[^ 1] on: BlockCannotReturn do: [:ex | self halt. ex resume] ] fork` Click on the highlighted context Step into
So, if the suggested solution makes sense to you, it would make 'playing with fire' a bit safer :)
best, Jaromir
Thanks again, Jaromir
------ Original Message ------ From "Eliot Miranda" <eliot.miranda(a)gmail.com> To "Jaromir Matas" <mail(a)jaromir.net> Date 11/17/2023 8:36:50 PM Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On Nov 17, 2023, at 7:05 AM, Jaromir Matas <mail(a)jaromir.net> wrote:
Eliot, hi again,
Please disregard my previous comment about nilling the contexts that have returned. We are indeed talking about the context directly under the #cannotReturn context which is totally different from the home context in another thread that's gone.
I may still be confused but would nilling the pc of the context directly under the cannotReturn context help? Here's what I mean:
Context >> #cannotReturn: result closureOrNil ifNotNil: [^self pc: nil; cannotReturn: result to: self home sender]. Processor debugWithTitle: 'Computation has been terminated!' translated full: false.Instead of crashing the VM invokes the debugger with the 'Computation has been terminated!' message.
Does this make sense?
Nearly. But it loses the information on what the pc actually is, and that’s potentially vital information. So IMO the ox should only be nilled between the BlockCannotReturn exception being created and raised.
[But if you try this don’t be surprised if it causes a few temporary problems. It looks to me that without a little refactoring this could easily cause an infinite recursion around the sending of isDead. I’m sure you’ll be able to fix the code to work correctly]
Thanks, Jaromir
------ Original Message ------ From "Jaromir Matas" <mail(a)jaromir.net> To "Eliot Miranda" <eliot.miranda(a)gmail.com>; "The general-purpose Squeak developers list" <squeak-dev(a)lists.squeakfoundation.org> Date 11/17/2023 10:15:17 AM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
>Hi Eliot, > > > >------ Original Message ------ >From "Eliot Miranda" <eliot.miranda(a)gmail.com> >To "Jaromir Matas" <mail(a)jaromir.net> >Cc "The general-purpose Squeak developers list" ><squeak-dev(a)lists.squeakfoundation.org> >Date 11/16/2023 11:52:45 PM >Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn >exception > >>Hi Jaromir, >> >>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas <mail(a)jaromir.net> >>wrote: >>>Hi Nicolas, Eliot, >>> >>>here's what I understand is happening (see the enclosed >>>screenshot): >>> >>>1) we fork a new process to evaluate [^1] >>>2) the new process evaluates [^1] which means instruction 18 is >>>being evaluated, hence pc points to instruction 19 now >>>3) however, the home context where ^1 should return to is gone by >>>this time (the process that executed the fork has already >>>returned - notice the two up arrows in the debugger screenshot) >>>4) the VM can't finish the instruction and returns control to the >>>image via placing the #cannotReturn: context on top of the [^1] >>>context >>>5) #cannotReturn: evaluation results in signalling the BCR >>>exception which is then handled by the #resume handler >>> (in our debugged case the [:ex | self halt. ex resume] >>>handler) >>>6) ex resume is evaluated, however, this means requesting the VM >>>to evaluate instruction 19 of the [^1] context - which is past >>>the last instruction of the context and the crash ensues >>> >>>I wonder whether such situations could/should be prevented inside >>>the VM or whether such an expectation is wrong for some reason. >> >>As Nicolas says, IMO this is best done at the image level. >> >>It could be prevented in the VM, but at great cost, and only >>partially. The performance issue is that the last bytecode in a >>method is not marked in any way, and that to determine the last >>bytecode the bytecodes must be symbolically evaluated from the >>start of the method. See implementors of endPC at the image level >>(which defer to the method trailer) and implementors of endPCOf: >>in the VMMaker code. Doing this every time execution commences is >>prohibitively expensive. The "only partially" issue is that >>following the return instruction may be other valid bytecodes, but >>these are not a continuation. >> >> >>Consider the following code in some block: >> [self expression ifTrue: >> [^1]. >> ^2 >> >>The bytecodes for this are >> pushReceiver >> send #expression >> jumpFalse L1 >> push 1 >> methodReturnTop >>L1 >> push 2 >> methodReturnTop >> >>Clearly if expression is true these should be *no* continuation in >>which ^2 is executed. > >Well, in that case there's a bug because the computation in the >following example shouldn't continue past the [^1] block but it >silently does: >`[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork` > >The bytecodes are > push true > jumpFalse L1 > push 1 > returnTop >L1 > push nil > blockReturn > > > >> >>So even if the VM did try and detect whether the return was at the >>last block method, it would only work for special cases. >> >> >>It seems to me the issue is simply that the context that cannot be >>returned from should be marked as dead (see Context>>isDead) by >>setting its pc to nil at some point, presumably after copying the >>actual return pc into the BlockCannotReturn exception, to avoid >>ever trying to resume the context. > >Does this mean, in other words, that every context that returns >should nil its pc to avoid being "wrongly" reused/executed in the >future, which concerns primarily those being referenced somewhere >hence potentially executable in the future, is that right? >Hypothetical question: would nilling the pc during returns "fix" >the example? >Thanks a lot for helping me understand this. >Best, >Jaromir > > > >> >> >>> >>>Thanks, >>>Jaromir >>> >>><bdxuqalu.png> >>> >>>------ Original Message ------ >>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>To "Jaromir Matas" <mail(a)jaromir.net>; "The general-purpose >>>Squeak developers list" <squeak-dev(a)lists.squeakfoundation.org> >>>Date 11/16/2023 6:48:43 PM >>>Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn >>>exception >>> >>>>Hi Jaromir, >>>> >>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas <mail(a)jaromir.net> >>>>>wrote: >>>>> >>>>> >>>>>Hi Nicloas, >>>>>No no, I don't have any practical scenario in mind, I'm just >>>>>trying to understand why the VM is implemented like this, >>>>>whether there were a reason to leave this possibility of a >>>>>crash, e.g. it would slow down the VM to try to prevent such a >>>>>dumb situation (who would resume from BCR in his right mind? :) >>>>>) - or perhaps I have overlooked some good reason to even keep >>>>>this behavior in the VM. That's all. >>>> >>>>Let’s first understand what’s really happening. Presumably at >>>>tone point a context is resumed those pc is already at the block >>>>return bytecode (effectively, because it crashes in JITted code, >>>>but I bet the stack vm will crash also, but not as cleanly - it >>>>will try and execute the bytes in the encoded method trailer). >>>>So which method actually sends resume, and to what, and what >>>>state is resume’s receiver when resume is sent? >>>> >>>> >>>>> >>>>>Thanks for your reply. >>>>>Regards, >>>>>Jaromir >>>>> >>>>> >>>>> >>>>> >>>>>------ Original Message ------ >>>>>From "Nicolas Cellier" <nicolas.cellier.aka.nice(a)gmail.com> >>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The general-purpose >>>>>Squeak developers list" <squeak-dev(a)lists.squeakfoundation.org> >>>>>Date 11/16/2023 7:20:20 AM >>>>>Subject Re: [squeak-dev] Resuming on BlockCannotReturn >>>>>exception >>>>> >>>>>>Hi Jaromir, >>>>>>Is there a scenario where it would make sense to resume a >>>>>>BlockCannotReturn? >>>>>>If not, I would suggest to protect at image side and override >>>>>>#resume. >>>>>> >>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas <mail(a)jaromir.net> >>>>>>a écrit : >>>>>>>Hi Eliot, Christoph, All, >>>>>>> >>>>>>>It's known the following example crashes the VM. Is this an >>>>>>>intended behavior or a "tolerated bug"? >>>>>>> >>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>>>>> >>>>>>>I understand why it crashes: the non-local return has nowhere >>>>>>>to return to and so resuming the computation leads to a >>>>>>>crash. But why not raise another BCR exception to prevent the >>>>>>>crash? Potential infinite loop? Perhaps I'm just missing the >>>>>>>purpose of this behavior... >>>>>>> >>>>>>>Thanks for an explanation. >>>>>>> >>>>>>>Best, >>>>>>>Jaromir >>>>>>> >>>>>>>-- >>>>>>> >>>>>>>Jaromir Matas >>>>>>> >>>>>>> >>>>> >> >> >>-- >>_,,,^..^,,,_ >>best, Eliot <Context-cannotReturn.st>
--- Sent from Squeak Inbox Talk
Hi Christoph, all good points, thanks!
Do we already have tests for that expectation?
I haven't figured out yet how to test it :)
Do I understand correctly that the pushed pc is only visible when
manually inspecting the context? Yes
Given the expected rareness [...] I wonder whether this information is
actually required. If yes, why don't store it in the BlockCannotReturn exception instead? Definitely not required, just though it might come handy :) And precisely because of the rareness I just pushed it on the problematic context's stack in case you inspect it and wonder what the instruction where the BCR started from was. We could push more verbose info like `push: 'original pc: ', pc` or store in BCR exception but KISS :)
Can you give me an example of where this extra notification adds any
value for the user? I should have given it in the message, sorry. You can e.g. run
[[true ifTrue: [^ 1]] on: BlockCannotReturn do: [:ex | self halt. ex resume] ] fork
highlight Context>>cannotReturn: line, go three times Over and then dive in via Into, Over or Through :) You get a strange error without the fix and 'Illegal attempt...' with the fix.
I by no means understand exactly how the Debugger works so you may have a way better idea where to place a fix or maybe even fix the pc = nil debugging situation cleanly instead of my ugly patch.
Thanks for your input!
--
Jaromir Matas
------ Original Message ------ From christoph.thiede@student.hpi.uni-potsdam.de To squeak-dev@lists.squeakfoundation.org Date 11/19/2023 7:04:35 PM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
thanks for looking into this!
[[^ 1] on: BlockCannotReturn do: #resume ] fork. "VM crash"
Indeed, this could and should be handled more robustly in the image!
[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork. "Illegal return from ^1"
Is this really illegal? Remember that resuming an exception is generally something special, and as this exception refers to a return instruction, resuming it is something I would definitely consider metaprogramming or worse. Thinking of ^ 1 as a syntactic sugar for "thisContext home return: 1", I would actually find it plausible that resuming from the exception would skip the #return: send. However, I have not read the entire conversation, so if Eliot says something different, please ignore this objection. :-)
Kernel-jar.1535:
- closureOrNil ifNotNil: [^self cannotReturn: result to: self home sender; push: pc; pc: nil].
Do I understand correctly that the pushed pc is only visible when manually inspecting the context? This is something very unexpected to me, it just feels as if you did not find any better place to store this information. Especially if there is no ready path available to access it later. Or am I wrong? Given the expected rareness of those events and the even greater rareness of multiple non-local returns from a single block context that has survived their home context, I wonder whether this information is actually required. If yes, why don't store it in the BlockCannotReturn exception instead?
Tools-jar.1240
Can you give me an example of where this extra notification adds any value for the user? If I run any of your two examples without the change in the Debugger, I just get a Computation has been terminated error while the #cannotReturn: stack is still available, which already seems to give me all information required to identify the origin of the error, in particular due to the extensive comment in this method.
Best, Christoph
Sent from Squeak Inbox Talk
On 2023-11-19T17:44:24+00:00, mail@jaromir.net wrote:
Hi Eliot, all,
I've sent Kernel-jar.1535 with a suggested fix dealing with the following two examples discussed in this thread:
[[^ 1] on: BlockCannotReturn do: #resume ] fork. "VM crash"
[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork. "Illegal return from ^1"
Now both examples work correctly.
In addition, Tools-jar.1240 is an attempt to facilitate debugging the resumption from the BCR exception. Currently the debugger opens with a confusing error as a consequence of decoding an instruction with nil index. In case you have a better idea where to place the fix, please let me know.
Thanks for your help,
best, Jaromir
-- Jaromir Matas
------ Original Message ------
From "Jaromir Matas" <mail(a)jaromir.net>
To "Eliot Miranda" <eliot.miranda(a)gmail.com>; squeak-dev(a)lists.squeakfoundation.org Date 11/18/2023 12:53:18 PM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Eliot,
------ Original Message ------ From "Jaromir Matas" <mail(a)jaromir.net> To "Eliot Miranda" <eliot.miranda(a)gmail.com>; squeak-dev(a)lists.squeakfoundation.org Date 11/18/2023 12:14:31 AM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Eliot,
How about to nil the pc just before making the return:
Context >> #cannotReturn: result self push: self pc. "backup the pc for the sake of debugging" closureOrNil ifNotNil: [^self cannotReturn: result to: self home sender; pc: nil]. Processor debugWithTitle: 'Computation has been terminated!' translated full: falseThe nilled pc should not even potentially interfere with the #isDead now.
I hope this is at least a step in the right direction :)
However, there's still a problem when debugging the resumption of #cannotReturn because the encoders expect a reasonable index. I haven't figured out yet where to place a nil check - #step, #stepToSendOrReturn... ?
This debugger issue has nothing to do with the proposed change... the debugging fails in the current trunk image too:
Run `[[^ 1] on: BlockCannotReturn do: [:ex | self halt. ex resume] ] fork` Click on the highlighted context Step into
So, if the suggested solution makes sense to you, it would make 'playing with fire' a bit safer :)
best, Jaromir
Thanks again, Jaromir
------ Original Message ------ From "Eliot Miranda" <eliot.miranda(a)gmail.com> To "Jaromir Matas" <mail(a)jaromir.net> Date 11/17/2023 8:36:50 PM Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On Nov 17, 2023, at 7:05 AM, Jaromir Matas <mail(a)jaromir.net> wrote:
Eliot, hi again,
Please disregard my previous comment about nilling the contexts that have returned. We are indeed talking about the context directly under the #cannotReturn context which is totally different from the home context in another thread that's gone.
I may still be confused but would nilling the pc of the context directly under the cannotReturn context help? Here's what I mean:
Context >> #cannotReturn: result closureOrNil ifNotNil: [^self pc: nil; cannotReturn: result to: self home sender]. Processor debugWithTitle: 'Computation has been terminated!' translated full: false.Instead of crashing the VM invokes the debugger with the 'Computation has been terminated!' message.
Does this make sense?
Nearly. But it loses the information on what the pc actually is, and that’s potentially vital information. So IMO the ox should only be nilled between the BlockCannotReturn exception being created and raised.
[But if you try this don’t be surprised if it causes a few temporary problems. It looks to me that without a little refactoring this could easily cause an infinite recursion around the sending of isDead. I’m sure you’ll be able to fix the code to work correctly]
Thanks, Jaromir
------ Original Message ------ From "Jaromir Matas" <mail(a)jaromir.net> To "Eliot Miranda" <eliot.miranda(a)gmail.com>; "The general-purpose Squeak developers list" <squeak-dev(a)lists.squeakfoundation.org> Date 11/17/2023 10:15:17 AM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
>Hi Eliot, > > > >------ Original Message ------ >From "Eliot Miranda" <eliot.miranda(a)gmail.com> >To "Jaromir Matas" <mail(a)jaromir.net> >Cc "The general-purpose Squeak developers list" ><squeak-dev(a)lists.squeakfoundation.org> >Date 11/16/2023 11:52:45 PM >Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn >exception > >>Hi Jaromir, >> >>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas <mail(a)jaromir.net> >>wrote: >>>Hi Nicolas, Eliot, >>> >>>here's what I understand is happening (see the enclosed >>>screenshot): >>> >>>1) we fork a new process to evaluate [^1] >>>2) the new process evaluates [^1] which means instruction 18 is >>>being evaluated, hence pc points to instruction 19 now >>>3) however, the home context where ^1 should return to is gone by >>>this time (the process that executed the fork has already >>>returned - notice the two up arrows in the debugger screenshot) >>>4) the VM can't finish the instruction and returns control to the >>>image via placing the #cannotReturn: context on top of the [^1] >>>context >>>5) #cannotReturn: evaluation results in signalling the BCR >>>exception which is then handled by the #resume handler >>> (in our debugged case the [:ex | self halt. ex resume] >>>handler) >>>6) ex resume is evaluated, however, this means requesting the VM >>>to evaluate instruction 19 of the [^1] context - which is past >>>the last instruction of the context and the crash ensues >>> >>>I wonder whether such situations could/should be prevented inside >>>the VM or whether such an expectation is wrong for some reason. >> >>As Nicolas says, IMO this is best done at the image level. >> >>It could be prevented in the VM, but at great cost, and only >>partially. The performance issue is that the last bytecode in a >>method is not marked in any way, and that to determine the last >>bytecode the bytecodes must be symbolically evaluated from the >>start of the method. See implementors of endPC at the image level >>(which defer to the method trailer) and implementors of endPCOf: >>in the VMMaker code. Doing this every time execution commences is >>prohibitively expensive. The "only partially" issue is that >>following the return instruction may be other valid bytecodes, but >>these are not a continuation. >> >> >>Consider the following code in some block: >> [self expression ifTrue: >> [^1]. >> ^2 >> >>The bytecodes for this are >> pushReceiver >> send #expression >> jumpFalse L1 >> push 1 >> methodReturnTop >>L1 >> push 2 >> methodReturnTop >> >>Clearly if expression is true these should be *no* continuation in >>which ^2 is executed. > >Well, in that case there's a bug because the computation in the >following example shouldn't continue past the [^1] block but it >silently does: >`[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork` > >The bytecodes are > push true > jumpFalse L1 > push 1 > returnTop >L1 > push nil > blockReturn > > > >> >>So even if the VM did try and detect whether the return was at the >>last block method, it would only work for special cases. >> >> >>It seems to me the issue is simply that the context that cannot be >>returned from should be marked as dead (see Context>>isDead) by >>setting its pc to nil at some point, presumably after copying the >>actual return pc into the BlockCannotReturn exception, to avoid >>ever trying to resume the context. > >Does this mean, in other words, that every context that returns >should nil its pc to avoid being "wrongly" reused/executed in the >future, which concerns primarily those being referenced somewhere >hence potentially executable in the future, is that right? >Hypothetical question: would nilling the pc during returns "fix" >the example? >Thanks a lot for helping me understand this. >Best, >Jaromir > > > >> >> >>> >>>Thanks, >>>Jaromir >>> >>><bdxuqalu.png> >>> >>>------ Original Message ------ >>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>To "Jaromir Matas" <mail(a)jaromir.net>; "The general-purpose >>>Squeak developers list" <squeak-dev(a)lists.squeakfoundation.org> >>>Date 11/16/2023 6:48:43 PM >>>Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn >>>exception >>> >>>>Hi Jaromir, >>>> >>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas <mail(a)jaromir.net> >>>>>wrote: >>>>> >>>>> >>>>>Hi Nicloas, >>>>>No no, I don't have any practical scenario in mind, I'm just >>>>>trying to understand why the VM is implemented like this, >>>>>whether there were a reason to leave this possibility of a >>>>>crash, e.g. it would slow down the VM to try to prevent such a >>>>>dumb situation (who would resume from BCR in his right mind? :) >>>>>) - or perhaps I have overlooked some good reason to even keep >>>>>this behavior in the VM. That's all. >>>> >>>>Let’s first understand what’s really happening. Presumably at >>>>tone point a context is resumed those pc is already at the block >>>>return bytecode (effectively, because it crashes in JITted code, >>>>but I bet the stack vm will crash also, but not as cleanly - it >>>>will try and execute the bytes in the encoded method trailer). >>>>So which method actually sends resume, and to what, and what >>>>state is resume’s receiver when resume is sent? >>>> >>>> >>>>> >>>>>Thanks for your reply. >>>>>Regards, >>>>>Jaromir >>>>> >>>>> >>>>> >>>>> >>>>>------ Original Message ------ >>>>>From "Nicolas Cellier" <nicolas.cellier.aka.nice(a)gmail.com> >>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The general-purpose >>>>>Squeak developers list" <squeak-dev(a)lists.squeakfoundation.org> >>>>>Date 11/16/2023 7:20:20 AM >>>>>Subject Re: [squeak-dev] Resuming on BlockCannotReturn >>>>>exception >>>>> >>>>>>Hi Jaromir, >>>>>>Is there a scenario where it would make sense to resume a >>>>>>BlockCannotReturn? >>>>>>If not, I would suggest to protect at image side and override >>>>>>#resume. >>>>>> >>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas <mail(a)jaromir.net> >>>>>>a écrit : >>>>>>>Hi Eliot, Christoph, All, >>>>>>> >>>>>>>It's known the following example crashes the VM. Is this an >>>>>>>intended behavior or a "tolerated bug"? >>>>>>> >>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>>>>> >>>>>>>I understand why it crashes: the non-local return has nowhere >>>>>>>to return to and so resuming the computation leads to a >>>>>>>crash. But why not raise another BCR exception to prevent the >>>>>>>crash? Potential infinite loop? Perhaps I'm just missing the >>>>>>>purpose of this behavior... >>>>>>> >>>>>>>Thanks for an explanation. >>>>>>> >>>>>>>Best, >>>>>>>Jaromir >>>>>>> >>>>>>>-- >>>>>>> >>>>>>>Jaromir Matas >>>>>>> >>>>>>> >>>>> >> >> >>-- >>_,,,^..^,,,_ >>best, Eliot <Context-cannotReturn.st>
Hi Jaromir,
On 2023-11-19T18:56:54+00:00, mail@jaromir.net wrote:
Hi Christoph, all good points, thanks!
Do we already have tests for that expectation?
I haven't figured out yet how to test it :)
Hm, maybe via the DebuggerTests again? When try to resume from your second (ifTrue:) example, it should open a "cannot return" debugger. Tricky, I know. :-)
Do I understand correctly that the pushed pc is only visible when
manually inspecting the context? Yes
Given the expected rareness [...] I wonder whether this information is
actually required. If yes, why don't store it in the BlockCannotReturn exception instead? Definitely not required, just though it might come handy :) And precisely because of the rareness I just pushed it on the problematic context's stack in case you inspect it and wonder what the instruction where the BCR started from was. We could push more verbose info like `push: 'original pc: ', pc` or store in BCR exception but KISS :)
Fair ... in technical terms it is still an abuse of the stack, I think, so maybe at least add a comment to that "push: pc" to avoid confusion in the reader? Or would it be fine to just store the pc in an unused tempvar?
Can you give me an example of where this extra notification adds any
value for the user? I should have given it in the message, sorry. You can e.g. run
[[true ifTrue: [^ 1]] on: BlockCannotReturn do: [:ex | self halt. ex resume] ] fork
highlight Context>>cannotReturn: line, go three times Over and then dive in via Into, Over or Through :) You get a strange error without the fix and 'Illegal attempt...' with the fix.
I by no means understand exactly how the Debugger works so you may have a way better idea where to place a fix or maybe even fix the pc = nil debugging situation cleanly instead of my ugly patch.
Ah, I see! To me, this more looks like a bug in the simulator. The simulator should mimic the behavior of the VM, so if the VM manages to put a #cannotReturn: context on the stack, so should the simulator.
Example:
process := [(c := thisContext) pc: nil. 2+3] newProcess. process runUntil: [:ctx | ctx selector = #cannotReturn:]. self assert: process suspendedContext sender = c. self assert: process suspendedContext arguments = {c}.
... if my assumptions are correct.
I think Context>>#step and Context>>#stepToSendOrReturn should be made aware of a nil pc and push a #cannotReturn: context on the stack, like in Context>>#return:from:. Do you maybe feel like submitting an inbox version (plus ideally tests) for this? :-) If we get that to work, this should be a much cleaner solution than adding another check in the debugger to explain our own simulator issues. :-)
Thanks for your input!
--
Jaromir Matas
------ Original Message ------
From christoph.thiede(a)student.hpi.uni-potsdam.de
To squeak-dev(a)lists.squeakfoundation.org Date 11/19/2023 7:04:35 PM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
thanks for looking into this!
[[^ 1] on: BlockCannotReturn do: #resume ] fork. "VM crash"
Indeed, this could and should be handled more robustly in the image!
[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork. "Illegal return from ^1"
Is this really illegal? Remember that resuming an exception is generally something special, and as this exception refers to a return instruction, resuming it is something I would definitely consider metaprogramming or worse. Thinking of ^ 1 as a syntactic sugar for "thisContext home return: 1", I would actually find it plausible that resuming from the exception would skip the #return: send. However, I have not read the entire conversation, so if Eliot says something different, please ignore this objection. :-)
Kernel-jar.1535:
- closureOrNil ifNotNil: [^self cannotReturn: result to: self home sender; push: pc; pc: nil].
Do I understand correctly that the pushed pc is only visible when manually inspecting the context? This is something very unexpected to me, it just feels as if you did not find any better place to store this information. Especially if there is no ready path available to access it later. Or am I wrong? Given the expected rareness of those events and the even greater rareness of multiple non-local returns from a single block context that has survived their home context, I wonder whether this information is actually required. If yes, why don't store it in the BlockCannotReturn exception instead?
Tools-jar.1240
Can you give me an example of where this extra notification adds any value for the user? If I run any of your two examples without the change in the Debugger, I just get a Computation has been terminated error while the #cannotReturn: stack is still available, which already seems to give me all information required to identify the origin of the error, in particular due to the extensive comment in this method.
Best, Christoph
Sent from Squeak Inbox Talk
On 2023-11-19T17:44:24+00:00, mail(a)jaromir.net wrote:
Hi Eliot, all,
I've sent Kernel-jar.1535 with a suggested fix dealing with the following two examples discussed in this thread:
[[^ 1] on: BlockCannotReturn do: #resume ] fork. "VM crash"
[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork. "Illegal return from ^1"
Now both examples work correctly.
In addition, Tools-jar.1240 is an attempt to facilitate debugging the resumption from the BCR exception. Currently the debugger opens with a confusing error as a consequence of decoding an instruction with nil index. In case you have a better idea where to place the fix, please let me know.
Thanks for your help,
best, Jaromir
-- Jaromir Matas
------ Original Message ------
From "Jaromir Matas" <mail(a)jaromir.net>
To "Eliot Miranda" <eliot.miranda(a)gmail.com>; squeak-dev(a)lists.squeakfoundation.org Date 11/18/2023 12:53:18 PM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Eliot,
------ Original Message ------ From "Jaromir Matas" <mail(a)jaromir.net> To "Eliot Miranda" <eliot.miranda(a)gmail.com>; squeak-dev(a)lists.squeakfoundation.org Date 11/18/2023 12:14:31 AM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Eliot,
How about to nil the pc just before making the return:
Context >> #cannotReturn: result self push: self pc. "backup the pc for the sake of debugging" closureOrNil ifNotNil: [^self cannotReturn: result to: self home sender; pc: nil]. Processor debugWithTitle: 'Computation has been terminated!' translated full: falseThe nilled pc should not even potentially interfere with the #isDead now.
I hope this is at least a step in the right direction :)
However, there's still a problem when debugging the resumption of #cannotReturn because the encoders expect a reasonable index. I haven't figured out yet where to place a nil check - #step, #stepToSendOrReturn... ?
This debugger issue has nothing to do with the proposed change... the debugging fails in the current trunk image too:
Run `[[^ 1] on: BlockCannotReturn do: [:ex | self halt. ex resume] ] fork` Click on the highlighted context Step into
So, if the suggested solution makes sense to you, it would make 'playing with fire' a bit safer :)
best, Jaromir
Thanks again, Jaromir
------ Original Message ------ From "Eliot Miranda" <eliot.miranda(a)gmail.com> To "Jaromir Matas" <mail(a)jaromir.net> Date 11/17/2023 8:36:50 PM Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
>On Nov 17, 2023, at 7:05 AM, Jaromir Matas <mail(a)jaromir.net> wrote: > > >Eliot, hi again, > >Please disregard my previous comment about nilling the contexts that >have returned. We are indeed talking about the context directly >under the #cannotReturn context which is totally different from the >home context in another thread that's gone. > >I may still be confused but would nilling the pc of the context >directly under the cannotReturn context help? Here's what I mean: >``` >Context >> #cannotReturn: result > > closureOrNil ifNotNil: [^self pc: nil; cannotReturn: result to: >self home sender]. > Processor debugWithTitle: 'Computation has been terminated!' >translated full: false. >``` >Instead of crashing the VM invokes the debugger with the >'Computation has been terminated!' message. > >Does this make sense?
Nearly. But it loses the information on what the pc actually is, and that’s potentially vital information. So IMO the ox should only be nilled between the BlockCannotReturn exception being created and raised.
[But if you try this don’t be surprised if it causes a few temporary problems. It looks to me that without a little refactoring this could easily cause an infinite recursion around the sending of isDead. I’m sure you’ll be able to fix the code to work correctly]
>Thanks, >Jaromir > > >------ Original Message ------ >From "Jaromir Matas" <mail(a)jaromir.net> >To "Eliot Miranda" <eliot.miranda(a)gmail.com>; "The general-purpose >Squeak developers list" <squeak-dev(a)lists.squeakfoundation.org> >Date 11/17/2023 10:15:17 AM >Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception > >>Hi Eliot, >> >> >> >>------ Original Message ------ >>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>To "Jaromir Matas" <mail(a)jaromir.net> >>Cc "The general-purpose Squeak developers list" >><squeak-dev(a)lists.squeakfoundation.org> >>Date 11/16/2023 11:52:45 PM >>Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn >>exception >> >>>Hi Jaromir, >>> >>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas <mail(a)jaromir.net> >>>wrote: >>>>Hi Nicolas, Eliot, >>>> >>>>here's what I understand is happening (see the enclosed >>>>screenshot): >>>> >>>>1) we fork a new process to evaluate [^1] >>>>2) the new process evaluates [^1] which means instruction 18 is >>>>being evaluated, hence pc points to instruction 19 now >>>>3) however, the home context where ^1 should return to is gone by >>>>this time (the process that executed the fork has already >>>>returned - notice the two up arrows in the debugger screenshot) >>>>4) the VM can't finish the instruction and returns control to the >>>>image via placing the #cannotReturn: context on top of the [^1] >>>>context >>>>5) #cannotReturn: evaluation results in signalling the BCR >>>>exception which is then handled by the #resume handler >>>> (in our debugged case the [:ex | self halt. ex resume] >>>>handler) >>>>6) ex resume is evaluated, however, this means requesting the VM >>>>to evaluate instruction 19 of the [^1] context - which is past >>>>the last instruction of the context and the crash ensues >>>> >>>>I wonder whether such situations could/should be prevented inside >>>>the VM or whether such an expectation is wrong for some reason. >>> >>>As Nicolas says, IMO this is best done at the image level. >>> >>>It could be prevented in the VM, but at great cost, and only >>>partially. The performance issue is that the last bytecode in a >>>method is not marked in any way, and that to determine the last >>>bytecode the bytecodes must be symbolically evaluated from the >>>start of the method. See implementors of endPC at the image level >>>(which defer to the method trailer) and implementors of endPCOf: >>>in the VMMaker code. Doing this every time execution commences is >>>prohibitively expensive. The "only partially" issue is that >>>following the return instruction may be other valid bytecodes, but >>>these are not a continuation. >>> >>> >>>Consider the following code in some block: >>> [self expression ifTrue: >>> [^1]. >>> ^2 >>> >>>The bytecodes for this are >>> pushReceiver >>> send #expression >>> jumpFalse L1 >>> push 1 >>> methodReturnTop >>>L1 >>> push 2 >>> methodReturnTop >>> >>>Clearly if expression is true these should be *no* continuation in >>>which ^2 is executed. >> >>Well, in that case there's a bug because the computation in the >>following example shouldn't continue past the [^1] block but it >>silently does: >>`[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork` >> >>The bytecodes are >> push true >> jumpFalse L1 >> push 1 >> returnTop >>L1 >> push nil >> blockReturn >> >> >> >>> >>>So even if the VM did try and detect whether the return was at the >>>last block method, it would only work for special cases. >>> >>> >>>It seems to me the issue is simply that the context that cannot be >>>returned from should be marked as dead (see Context>>isDead) by >>>setting its pc to nil at some point, presumably after copying the >>>actual return pc into the BlockCannotReturn exception, to avoid >>>ever trying to resume the context. >> >>Does this mean, in other words, that every context that returns >>should nil its pc to avoid being "wrongly" reused/executed in the >>future, which concerns primarily those being referenced somewhere >>hence potentially executable in the future, is that right? >>Hypothetical question: would nilling the pc during returns "fix" >>the example? >>Thanks a lot for helping me understand this. >>Best, >>Jaromir >> >> >> >>> >>> >>>> >>>>Thanks, >>>>Jaromir >>>> >>>><bdxuqalu.png> >>>> >>>>------ Original Message ------ >>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The general-purpose >>>>Squeak developers list" <squeak-dev(a)lists.squeakfoundation.org> >>>>Date 11/16/2023 6:48:43 PM >>>>Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn >>>>exception >>>> >>>>>Hi Jaromir, >>>>> >>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas <mail(a)jaromir.net> >>>>>>wrote: >>>>>> >>>>>> >>>>>>Hi Nicloas, >>>>>>No no, I don't have any practical scenario in mind, I'm just >>>>>>trying to understand why the VM is implemented like this, >>>>>>whether there were a reason to leave this possibility of a >>>>>>crash, e.g. it would slow down the VM to try to prevent such a >>>>>>dumb situation (who would resume from BCR in his right mind? :) >>>>>>) - or perhaps I have overlooked some good reason to even keep >>>>>>this behavior in the VM. That's all. >>>>> >>>>>Let’s first understand what’s really happening. Presumably at >>>>>tone point a context is resumed those pc is already at the block >>>>>return bytecode (effectively, because it crashes in JITted code, >>>>>but I bet the stack vm will crash also, but not as cleanly - it >>>>>will try and execute the bytes in the encoded method trailer). >>>>>So which method actually sends resume, and to what, and what >>>>>state is resume’s receiver when resume is sent? >>>>> >>>>> >>>>>> >>>>>>Thanks for your reply. >>>>>>Regards, >>>>>>Jaromir >>>>>> >>>>>> >>>>>> >>>>>> >>>>>>------ Original Message ------ >>>>>>From "Nicolas Cellier" <nicolas.cellier.aka.nice(a)gmail.com> >>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The general-purpose >>>>>>Squeak developers list" <squeak-dev(a)lists.squeakfoundation.org> >>>>>>Date 11/16/2023 7:20:20 AM >>>>>>Subject Re: [squeak-dev] Resuming on BlockCannotReturn >>>>>>exception >>>>>> >>>>>>>Hi Jaromir, >>>>>>>Is there a scenario where it would make sense to resume a >>>>>>>BlockCannotReturn? >>>>>>>If not, I would suggest to protect at image side and override >>>>>>>#resume. >>>>>>> >>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas <mail(a)jaromir.net> >>>>>>>a écrit : >>>>>>>>Hi Eliot, Christoph, All, >>>>>>>> >>>>>>>>It's known the following example crashes the VM. Is this an >>>>>>>>intended behavior or a "tolerated bug"? >>>>>>>> >>>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>>>>>> >>>>>>>>I understand why it crashes: the non-local return has nowhere >>>>>>>>to return to and so resuming the computation leads to a >>>>>>>>crash. But why not raise another BCR exception to prevent the >>>>>>>>crash? Potential infinite loop? Perhaps I'm just missing the >>>>>>>>purpose of this behavior... >>>>>>>> >>>>>>>>Thanks for an explanation. >>>>>>>> >>>>>>>>Best, >>>>>>>>Jaromir >>>>>>>> >>>>>>>>-- >>>>>>>> >>>>>>>>Jaromir Matas >>>>>>>> >>>>>>>> >>>>>> >>> >>> >>>-- >>>_,,,^..^,,,_ >>>best, Eliot ><Context-cannotReturn.st>
--- Sent from Squeak Inbox Talk
Hi Christoph,
in technical terms it is still an abuse of the stack
Indeed, that's what it is :) Given the extremely short lifespan of the abused context - literally one return till VM raising an exception I thought it acceptable. There's a note "backup the pc before nilling for the sake of debugging." in the comment but maybe not clear and visible enough.
Or would it be fine to just store the pc in an unused tempvar?
I wanted to associate the information about the original pc with the problematic context but it can't be known in advance which one will be problematic (I assume you meant a tempvar in the #cannotReturn method - tried but didn't like much) hence the simple push.
To me, this more looks like a bug in the simulator. The simulator
should mimic the behavior of the VM, so if the VM manages to put a #cannotReturn: context on the stack, so should the simulator. Example [...] Even better... I suspected it may be a more general debugger issue. I was just looking for such an example - thanks!
In that case Context>>#step and #stepToSendOrReturn are hot candidates for placing the changes. What would you think, however, about this: It looks like #interpretNextInstructionFor: may be a single channel where all debugging requests must go through but I'm still just skimming the surface of the Debugger code:
``` interpretNextInstructionFor: client "Send to the argument, client, a message that specifies the type of the next instruction."
(self isContext and: [self sender notNil and: [self sender isDead]]) ifTrue: [^Processor debugWithTitle: 'Illegal return to a dead context' translated full: false]. ^self method encoderClass interpretNextInstructionFor: client in: self ```
I tried sending #cannotReturn instead of Processor debugWithTitle: but it created infinite loops.
What do you think? best, Jaromir
PS: re tests - I'll reserve some time this weekend :) --
Jaromir Matas
------ Original Message ------ From christoph.thiede@student.hpi.uni-potsdam.de To squeak-dev@lists.squeakfoundation.org Date 11/19/2023 8:57:44 PM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On 2023-11-19T18:56:54+00:00, mail@jaromir.net wrote:
Hi Christoph, all good points, thanks!
Do we already have tests for that expectation?
I haven't figured out yet how to test it :)
Hm, maybe via the DebuggerTests again? When try to resume from your second (ifTrue:) example, it should open a "cannot return" debugger. Tricky, I know. :-)
Do I understand correctly that the pushed pc is only visible when
manually inspecting the context? Yes
Given the expected rareness [...] I wonder whether this information is
actually required. If yes, why don't store it in the BlockCannotReturn exception instead? Definitely not required, just though it might come handy :) And precisely because of the rareness I just pushed it on the problematic context's stack in case you inspect it and wonder what the instruction where the BCR started from was. We could push more verbose info like `push: 'original pc: ', pc` or store in BCR exception but KISS :)
Fair ... in technical terms it is still an abuse of the stack, I think, so maybe at least add a comment to that "push: pc" to avoid confusion in the reader? Or would it be fine to just store the pc in an unused tempvar?
Can you give me an example of where this extra notification adds any
value for the user? I should have given it in the message, sorry. You can e.g. run
[[true ifTrue: [^ 1]] on: BlockCannotReturn do: [:ex | self halt. ex resume] ] fork
highlight Context>>cannotReturn: line, go three times Over and then dive in via Into, Over or Through :) You get a strange error without the fix and 'Illegal attempt...' with the fix.
I by no means understand exactly how the Debugger works so you may have a way better idea where to place a fix or maybe even fix the pc = nil debugging situation cleanly instead of my ugly patch.
Ah, I see! To me, this more looks like a bug in the simulator. The simulator should mimic the behavior of the VM, so if the VM manages to put a #cannotReturn: context on the stack, so should the simulator.
Example:
process := [(c := thisContext) pc: nil. 2+3] newProcess. process runUntil: [:ctx | ctx selector = #cannotReturn:]. self assert: process suspendedContext sender = c. self assert: process suspendedContext arguments = {c}.
... if my assumptions are correct.
I think Context>>#step and Context>>#stepToSendOrReturn should be made aware of a nil pc and push a #cannotReturn: context on the stack, like in Context>>#return:from:. Do you maybe feel like submitting an inbox version (plus ideally tests) for this? :-) If we get that to work, this should be a much cleaner solution than adding another check in the debugger to explain our own simulator issues. :-)
Thanks for your input!
--
Jaromir Matas
------ Original Message ------
From christoph.thiede(a)student.hpi.uni-potsdam.de
To squeak-dev(a)lists.squeakfoundation.org Date 11/19/2023 7:04:35 PM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
thanks for looking into this!
[[^ 1] on: BlockCannotReturn do: #resume ] fork. "VM crash"
Indeed, this could and should be handled more robustly in the image!
[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork. "Illegal return from ^1"
Is this really illegal? Remember that resuming an exception is generally something special, and as this exception refers to a return instruction, resuming it is something I would definitely consider metaprogramming or worse. Thinking of ^ 1 as a syntactic sugar for "thisContext home return: 1", I would actually find it plausible that resuming from the exception would skip the #return: send. However, I have not read the entire conversation, so if Eliot says something different, please ignore this objection. :-)
Kernel-jar.1535:
- closureOrNil ifNotNil: [^self cannotReturn: result to: self home sender; push: pc; pc: nil].
Do I understand correctly that the pushed pc is only visible when manually inspecting the context? This is something very unexpected to me, it just feels as if you did not find any better place to store this information. Especially if there is no ready path available to access it later. Or am I wrong? Given the expected rareness of those events and the even greater rareness of multiple non-local returns from a single block context that has survived their home context, I wonder whether this information is actually required. If yes, why don't store it in the BlockCannotReturn exception instead?
Tools-jar.1240
Can you give me an example of where this extra notification adds any value for the user? If I run any of your two examples without the change in the Debugger, I just get a Computation has been terminated error while the #cannotReturn: stack is still available, which already seems to give me all information required to identify the origin of the error, in particular due to the extensive comment in this method.
Best, Christoph
Sent from Squeak Inbox Talk
On 2023-11-19T17:44:24+00:00, mail(a)jaromir.net wrote:
Hi Eliot, all,
I've sent Kernel-jar.1535 with a suggested fix dealing with the following two examples discussed in this thread:
[[^ 1] on: BlockCannotReturn do: #resume ] fork. "VM crash"
[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork. "Illegal return from ^1"
Now both examples work correctly.
In addition, Tools-jar.1240 is an attempt to facilitate debugging the resumption from the BCR exception. Currently the debugger opens with a confusing error as a consequence of decoding an instruction with nil index. In case you have a better idea where to place the fix, please let me know.
Thanks for your help,
best, Jaromir
-- Jaromir Matas
------ Original Message ------
From "Jaromir Matas" <mail(a)jaromir.net>
To "Eliot Miranda" <eliot.miranda(a)gmail.com>; squeak-dev(a)lists.squeakfoundation.org Date 11/18/2023 12:53:18 PM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Eliot,
------ Original Message ------ From "Jaromir Matas" <mail(a)jaromir.net> To "Eliot Miranda" <eliot.miranda(a)gmail.com>; squeak-dev(a)lists.squeakfoundation.org Date 11/18/2023 12:14:31 AM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Eliot,
How about to nil the pc just before making the return:
Context >> #cannotReturn: result self push: self pc. "backup the pc for the sake of debugging" closureOrNil ifNotNil: [^self cannotReturn: result to: self home sender; pc: nil]. Processor debugWithTitle: 'Computation has been terminated!' translated full: falseThe nilled pc should not even potentially interfere with the #isDead now.
I hope this is at least a step in the right direction :)
However, there's still a problem when debugging the resumption of #cannotReturn because the encoders expect a reasonable index. I haven't figured out yet where to place a nil check - #step, #stepToSendOrReturn... ?
This debugger issue has nothing to do with the proposed change... the debugging fails in the current trunk image too:
Run `[[^ 1] on: BlockCannotReturn do: [:ex | self halt. ex resume] ] fork` Click on the highlighted context Step into
So, if the suggested solution makes sense to you, it would make 'playing with fire' a bit safer :)
best, Jaromir
Thanks again, Jaromir
------ Original Message ------ From "Eliot Miranda" <eliot.miranda(a)gmail.com> To "Jaromir Matas" <mail(a)jaromir.net> Date 11/17/2023 8:36:50 PM Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception
>Hi Jaromir, > >>On Nov 17, 2023, at 7:05 AM, Jaromir Matas <mail(a)jaromir.net> wrote: >> >> >>Eliot, hi again, >> >>Please disregard my previous comment about nilling the contexts that >>have returned. We are indeed talking about the context directly >>under the #cannotReturn context which is totally different from the >>home context in another thread that's gone. >> >>I may still be confused but would nilling the pc of the context >>directly under the cannotReturn context help? Here's what I mean: >>``` >>Context >> #cannotReturn: result >> >> closureOrNil ifNotNil: [^self pc: nil; cannotReturn: result to: >>self home sender]. >> Processor debugWithTitle: 'Computation has been terminated!' >>translated full: false. >>``` >>Instead of crashing the VM invokes the debugger with the >>'Computation has been terminated!' message. >> >>Does this make sense? > >Nearly. But it loses the information on what the pc actually is, and >that’s potentially vital information. So IMO the ox should only be >nilled between the BlockCannotReturn exception being created and >raised. > >[But if you try this don’t be surprised if it causes a few temporary >problems. It looks to me that without a little refactoring this >could easily cause an infinite recursion around the sending of >isDead. I’m sure you’ll be able to fix the code to work correctly] > >>Thanks, >>Jaromir >> >> >>------ Original Message ------ >>From "Jaromir Matas" <mail(a)jaromir.net> >>To "Eliot Miranda" <eliot.miranda(a)gmail.com>; "The general-purpose >>Squeak developers list" <squeak-dev(a)lists.squeakfoundation.org> >>Date 11/17/2023 10:15:17 AM >>Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception >> >>>Hi Eliot, >>> >>> >>> >>>------ Original Message ------ >>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>To "Jaromir Matas" <mail(a)jaromir.net> >>>Cc "The general-purpose Squeak developers list" >>><squeak-dev(a)lists.squeakfoundation.org> >>>Date 11/16/2023 11:52:45 PM >>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn >>>exception >>> >>>>Hi Jaromir, >>>> >>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas <mail(a)jaromir.net> >>>>wrote: >>>>>Hi Nicolas, Eliot, >>>>> >>>>>here's what I understand is happening (see the enclosed >>>>>screenshot): >>>>> >>>>>1) we fork a new process to evaluate [^1] >>>>>2) the new process evaluates [^1] which means instruction 18 is >>>>>being evaluated, hence pc points to instruction 19 now >>>>>3) however, the home context where ^1 should return to is gone by >>>>>this time (the process that executed the fork has already >>>>>returned - notice the two up arrows in the debugger screenshot) >>>>>4) the VM can't finish the instruction and returns control to the >>>>>image via placing the #cannotReturn: context on top of the [^1] >>>>>context >>>>>5) #cannotReturn: evaluation results in signalling the BCR >>>>>exception which is then handled by the #resume handler >>>>> (in our debugged case the [:ex | self halt. ex resume] >>>>>handler) >>>>>6) ex resume is evaluated, however, this means requesting the VM >>>>>to evaluate instruction 19 of the [^1] context - which is past >>>>>the last instruction of the context and the crash ensues >>>>> >>>>>I wonder whether such situations could/should be prevented inside >>>>>the VM or whether such an expectation is wrong for some reason. >>>> >>>>As Nicolas says, IMO this is best done at the image level. >>>> >>>>It could be prevented in the VM, but at great cost, and only >>>>partially. The performance issue is that the last bytecode in a >>>>method is not marked in any way, and that to determine the last >>>>bytecode the bytecodes must be symbolically evaluated from the >>>>start of the method. See implementors of endPC at the image level >>>>(which defer to the method trailer) and implementors of endPCOf: >>>>in the VMMaker code. Doing this every time execution commences is >>>>prohibitively expensive. The "only partially" issue is that >>>>following the return instruction may be other valid bytecodes, but >>>>these are not a continuation. >>>> >>>> >>>>Consider the following code in some block: >>>> [self expression ifTrue: >>>> [^1]. >>>> ^2 >>>> >>>>The bytecodes for this are >>>> pushReceiver >>>> send #expression >>>> jumpFalse L1 >>>> push 1 >>>> methodReturnTop >>>>L1 >>>> push 2 >>>> methodReturnTop >>>> >>>>Clearly if expression is true these should be *no* continuation in >>>>which ^2 is executed. >>> >>>Well, in that case there's a bug because the computation in the >>>following example shouldn't continue past the [^1] block but it >>>silently does: >>>`[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork` >>> >>>The bytecodes are >>> push true >>> jumpFalse L1 >>> push 1 >>> returnTop >>>L1 >>> push nil >>> blockReturn >>> >>> >>> >>>> >>>>So even if the VM did try and detect whether the return was at the >>>>last block method, it would only work for special cases. >>>> >>>> >>>>It seems to me the issue is simply that the context that cannot be >>>>returned from should be marked as dead (see Context>>isDead) by >>>>setting its pc to nil at some point, presumably after copying the >>>>actual return pc into the BlockCannotReturn exception, to avoid >>>>ever trying to resume the context. >>> >>>Does this mean, in other words, that every context that returns >>>should nil its pc to avoid being "wrongly" reused/executed in the >>>future, which concerns primarily those being referenced somewhere >>>hence potentially executable in the future, is that right? >>>Hypothetical question: would nilling the pc during returns "fix" >>>the example? >>>Thanks a lot for helping me understand this. >>>Best, >>>Jaromir >>> >>> >>> >>>> >>>> >>>>> >>>>>Thanks, >>>>>Jaromir >>>>> >>>>><bdxuqalu.png> >>>>> >>>>>------ Original Message ------ >>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The general-purpose >>>>>Squeak developers list" <squeak-dev(a)lists.squeakfoundation.org> >>>>>Date 11/16/2023 6:48:43 PM >>>>>Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn >>>>>exception >>>>> >>>>>>Hi Jaromir, >>>>>> >>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas <mail(a)jaromir.net> >>>>>>>wrote: >>>>>>> >>>>>>> >>>>>>>Hi Nicloas, >>>>>>>No no, I don't have any practical scenario in mind, I'm just >>>>>>>trying to understand why the VM is implemented like this, >>>>>>>whether there were a reason to leave this possibility of a >>>>>>>crash, e.g. it would slow down the VM to try to prevent such a >>>>>>>dumb situation (who would resume from BCR in his right mind? :) >>>>>>>) - or perhaps I have overlooked some good reason to even keep >>>>>>>this behavior in the VM. That's all. >>>>>> >>>>>>Let’s first understand what’s really happening. Presumably at >>>>>>tone point a context is resumed those pc is already at the block >>>>>>return bytecode (effectively, because it crashes in JITted code, >>>>>>but I bet the stack vm will crash also, but not as cleanly - it >>>>>>will try and execute the bytes in the encoded method trailer). >>>>>>So which method actually sends resume, and to what, and what >>>>>>state is resume’s receiver when resume is sent? >>>>>> >>>>>> >>>>>>> >>>>>>>Thanks for your reply. >>>>>>>Regards, >>>>>>>Jaromir >>>>>>> >>>>>>> >>>>>>> >>>>>>> >>>>>>>------ Original Message ------ >>>>>>>From "Nicolas Cellier" <nicolas.cellier.aka.nice(a)gmail.com> >>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The general-purpose >>>>>>>Squeak developers list" <squeak-dev(a)lists.squeakfoundation.org> >>>>>>>Date 11/16/2023 7:20:20 AM >>>>>>>Subject Re: [squeak-dev] Resuming on BlockCannotReturn >>>>>>>exception >>>>>>> >>>>>>>>Hi Jaromir, >>>>>>>>Is there a scenario where it would make sense to resume a >>>>>>>>BlockCannotReturn? >>>>>>>>If not, I would suggest to protect at image side and override >>>>>>>>#resume. >>>>>>>> >>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas <mail(a)jaromir.net> >>>>>>>>a écrit : >>>>>>>>>Hi Eliot, Christoph, All, >>>>>>>>> >>>>>>>>>It's known the following example crashes the VM. Is this an >>>>>>>>>intended behavior or a "tolerated bug"? >>>>>>>>> >>>>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>>>>>>> >>>>>>>>>I understand why it crashes: the non-local return has nowhere >>>>>>>>>to return to and so resuming the computation leads to a >>>>>>>>>crash. But why not raise another BCR exception to prevent the >>>>>>>>>crash? Potential infinite loop? Perhaps I'm just missing the >>>>>>>>>purpose of this behavior... >>>>>>>>> >>>>>>>>>Thanks for an explanation. >>>>>>>>> >>>>>>>>>Best, >>>>>>>>>Jaromir >>>>>>>>> >>>>>>>>>-- >>>>>>>>> >>>>>>>>>Jaromir Matas >>>>>>>>> >>>>>>>>> >>>>>>> >>>> >>>> >>>>-- >>>>_,,,^..^,,,_ >>>>best, Eliot >><Context-cannotReturn.st>
Sent from Squeak Inbox Talk
Correction: Context may be a better place for the suggested method: ``` interpretNextInstructionFor: client "Send to the argument, client, a message that specifies the type of the next instruction."
(self sender notNil and: [self sender isDead]) ifTrue: [^Processor debugWithTitle: 'Illegal return to a dead context' translated full: false]. ^super interpretNextInstructionFor: client ``` Regards, --
Jaromir Matas
------ Original Message ------ From "Jaromir Matas" mail@jaromir.net To squeak-dev@lists.squeakfoundation.org Date 11/20/2023 8:15:19 PM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Christoph,
in technical terms it is still an abuse of the stack
Indeed, that's what it is :) Given the extremely short lifespan of the abused context - literally one return till VM raising an exception I thought it acceptable. There's a note "backup the pc before nilling for the sake of debugging." in the comment but maybe not clear and visible enough.
Or would it be fine to just store the pc in an unused tempvar?
I wanted to associate the information about the original pc with the problematic context but it can't be known in advance which one will be problematic (I assume you meant a tempvar in the #cannotReturn method - tried but didn't like much) hence the simple push.
To me, this more looks like a bug in the simulator. The simulator
should mimic the behavior of the VM, so if the VM manages to put a #cannotReturn: context on the stack, so should the simulator. Example [...] Even better... I suspected it may be a more general debugger issue. I was just looking for such an example - thanks!
In that case Context>>#step and #stepToSendOrReturn are hot candidates for placing the changes. What would you think, however, about this: It looks like #interpretNextInstructionFor: may be a single channel where all debugging requests must go through but I'm still just skimming the surface of the Debugger code:
interpretNextInstructionFor: client "Send to the argument, client, a message that specifies the type of the next instruction." (self isContext and: [self sender notNil and: [self sender isDead]]) ifTrue: [^Processor debugWithTitle: 'Illegal return to a dead context' translated full: false]. ^self method encoderClass interpretNextInstructionFor: client in: selfI tried sending #cannotReturn instead of Processor debugWithTitle: but it created infinite loops.
What do you think? best, Jaromir
PS: re tests - I'll reserve some time this weekend :)
Jaromir Matas
------ Original Message ------ From christoph.thiede@student.hpi.uni-potsdam.de To squeak-dev@lists.squeakfoundation.org Date 11/19/2023 8:57:44 PM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On 2023-11-19T18:56:54+00:00, mail@jaromir.net wrote:
Hi Christoph, all good points, thanks!
Do we already have tests for that expectation?
I haven't figured out yet how to test it :)
Hm, maybe via the DebuggerTests again? When try to resume from your second (ifTrue:) example, it should open a "cannot return" debugger. Tricky, I know. :-)
Do I understand correctly that the pushed pc is only visible when
manually inspecting the context? Yes
Given the expected rareness [...] I wonder whether this information is
actually required. If yes, why don't store it in the BlockCannotReturn exception instead? Definitely not required, just though it might come handy :) And precisely because of the rareness I just pushed it on the problematic context's stack in case you inspect it and wonder what the instruction where the BCR started from was. We could push more verbose info like `push: 'original pc: ', pc` or store in BCR exception but KISS :)
Fair ... in technical terms it is still an abuse of the stack, I think, so maybe at least add a comment to that "push: pc" to avoid confusion in the reader? Or would it be fine to just store the pc in an unused tempvar?
Can you give me an example of where this extra notification adds any
value for the user? I should have given it in the message, sorry. You can e.g. run
[[true ifTrue: [^ 1]] on: BlockCannotReturn do: [:ex | self halt. ex resume] ] fork
highlight Context>>cannotReturn: line, go three times Over and then dive in via Into, Over or Through :) You get a strange error without the fix and 'Illegal attempt...' with the fix.
I by no means understand exactly how the Debugger works so you may have a way better idea where to place a fix or maybe even fix the pc = nil debugging situation cleanly instead of my ugly patch.
Ah, I see! To me, this more looks like a bug in the simulator. The simulator should mimic the behavior of the VM, so if the VM manages to put a #cannotReturn: context on the stack, so should the simulator.
Example:
process := [(c := thisContext) pc: nil. 2+3] newProcess. process runUntil: [:ctx | ctx selector = #cannotReturn:]. self assert: process suspendedContext sender = c. self assert: process suspendedContext arguments = {c}.
... if my assumptions are correct.
I think Context>>#step and Context>>#stepToSendOrReturn should be made aware of a nil pc and push a #cannotReturn: context on the stack, like in Context>>#return:from:. Do you maybe feel like submitting an inbox version (plus ideally tests) for this? :-) If we get that to work, this should be a much cleaner solution than adding another check in the debugger to explain our own simulator issues. :-)
Thanks for your input!
--
Jaromir Matas
------ Original Message ------
From christoph.thiede(a)student.hpi.uni-potsdam.de
To squeak-dev(a)lists.squeakfoundation.org Date 11/19/2023 7:04:35 PM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
thanks for looking into this!
[[^ 1] on: BlockCannotReturn do: #resume ] fork. "VM crash"
Indeed, this could and should be handled more robustly in the image!
[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork. "Illegal return from ^1"
Is this really illegal? Remember that resuming an exception is generally something special, and as this exception refers to a return instruction, resuming it is something I would definitely consider metaprogramming or worse. Thinking of ^ 1 as a syntactic sugar for "thisContext home return: 1", I would actually find it plausible that resuming from the exception would skip the #return: send. However, I have not read the entire conversation, so if Eliot says something different, please ignore this objection. :-)
Kernel-jar.1535:
- closureOrNil ifNotNil: [^self cannotReturn: result to: self home sender; push: pc; pc: nil].
Do I understand correctly that the pushed pc is only visible when manually inspecting the context? This is something very unexpected to me, it just feels as if you did not find any better place to store this information. Especially if there is no ready path available to access it later. Or am I wrong? Given the expected rareness of those events and the even greater rareness of multiple non-local returns from a single block context that has survived their home context, I wonder whether this information is actually required. If yes, why don't store it in the BlockCannotReturn exception instead?
Tools-jar.1240
Can you give me an example of where this extra notification adds any value for the user? If I run any of your two examples without the change in the Debugger, I just get a Computation has been terminated error while the #cannotReturn: stack is still available, which already seems to give me all information required to identify the origin of the error, in particular due to the extensive comment in this method.
Best, Christoph
Sent from Squeak Inbox Talk
On 2023-11-19T17:44:24+00:00, mail(a)jaromir.net wrote:
Hi Eliot, all,
I've sent Kernel-jar.1535 with a suggested fix dealing with the following two examples discussed in this thread:
[[^ 1] on: BlockCannotReturn do: #resume ] fork. "VM crash"
[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork. "Illegal return from ^1"
Now both examples work correctly.
In addition, Tools-jar.1240 is an attempt to facilitate debugging the resumption from the BCR exception. Currently the debugger opens with a confusing error as a consequence of decoding an instruction with nil index. In case you have a better idea where to place the fix, please let me know.
Thanks for your help,
best, Jaromir
-- Jaromir Matas
------ Original Message ------
From "Jaromir Matas" <mail(a)jaromir.net>
To "Eliot Miranda" <eliot.miranda(a)gmail.com>; squeak-dev(a)lists.squeakfoundation.org Date 11/18/2023 12:53:18 PM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Eliot,
------ Original Message ------ From "Jaromir Matas" <mail(a)jaromir.net> To "Eliot Miranda" <eliot.miranda(a)gmail.com>; squeak-dev(a)lists.squeakfoundation.org Date 11/18/2023 12:14:31 AM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
>Hi Eliot, > >How about to nil the pc just before making the return: >``` >Context >> #cannotReturn: result > > self push: self pc. "backup the pc for the sake of debugging" > closureOrNil ifNotNil: [^self cannotReturn: result to: self home >sender; pc: nil]. > Processor debugWithTitle: 'Computation has been terminated!' >translated full: false >``` >The nilled pc should not even potentially interfere with the #isDead >now. > >I hope this is at least a step in the right direction :) > >However, there's still a problem when debugging the resumption of >#cannotReturn because the encoders expect a reasonable index. I >haven't figured out yet where to place a nil check - #step, >#stepToSendOrReturn... ?
This debugger issue has nothing to do with the proposed change... the debugging fails in the current trunk image too:
Run `[[^ 1] on: BlockCannotReturn do: [:ex | self halt. ex resume] ] fork` Click on the highlighted context Step into
So, if the suggested solution makes sense to you, it would make 'playing with fire' a bit safer :)
best, Jaromir
> > >Thanks again, >Jaromir > > >------ Original Message ------ >From "Eliot Miranda" <eliot.miranda(a)gmail.com> >To "Jaromir Matas" <mail(a)jaromir.net> >Date 11/17/2023 8:36:50 PM >Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception > >>Hi Jaromir, >> >>>On Nov 17, 2023, at 7:05 AM, Jaromir Matas <mail(a)jaromir.net> wrote: >>> >>> >>>Eliot, hi again, >>> >>>Please disregard my previous comment about nilling the contexts that >>>have returned. We are indeed talking about the context directly >>>under the #cannotReturn context which is totally different from the >>>home context in another thread that's gone. >>> >>>I may still be confused but would nilling the pc of the context >>>directly under the cannotReturn context help? Here's what I mean: >>>``` >>>Context >> #cannotReturn: result >>> >>> closureOrNil ifNotNil: [^self pc: nil; cannotReturn: result to: >>>self home sender]. >>> Processor debugWithTitle: 'Computation has been terminated!' >>>translated full: false. >>>``` >>>Instead of crashing the VM invokes the debugger with the >>>'Computation has been terminated!' message. >>> >>>Does this make sense? >> >>Nearly. But it loses the information on what the pc actually is, and >>that’s potentially vital information. So IMO the ox should only be >>nilled between the BlockCannotReturn exception being created and >>raised. >> >>[But if you try this don’t be surprised if it causes a few temporary >>problems. It looks to me that without a little refactoring this >>could easily cause an infinite recursion around the sending of >>isDead. I’m sure you’ll be able to fix the code to work correctly] >> >>>Thanks, >>>Jaromir >>> >>> >>>------ Original Message ------ >>>From "Jaromir Matas" <mail(a)jaromir.net> >>>To "Eliot Miranda" <eliot.miranda(a)gmail.com>; "The general-purpose >>>Squeak developers list" <squeak-dev(a)lists.squeakfoundation.org> >>>Date 11/17/2023 10:15:17 AM >>>Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception >>> >>>>Hi Eliot, >>>> >>>> >>>> >>>>------ Original Message ------ >>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>Cc "The general-purpose Squeak developers list" >>>><squeak-dev(a)lists.squeakfoundation.org> >>>>Date 11/16/2023 11:52:45 PM >>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn >>>>exception >>>> >>>>>Hi Jaromir, >>>>> >>>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas <mail(a)jaromir.net> >>>>>wrote: >>>>>>Hi Nicolas, Eliot, >>>>>> >>>>>>here's what I understand is happening (see the enclosed >>>>>>screenshot): >>>>>> >>>>>>1) we fork a new process to evaluate [^1] >>>>>>2) the new process evaluates [^1] which means instruction 18 is >>>>>>being evaluated, hence pc points to instruction 19 now >>>>>>3) however, the home context where ^1 should return to is gone by >>>>>>this time (the process that executed the fork has already >>>>>>returned - notice the two up arrows in the debugger screenshot) >>>>>>4) the VM can't finish the instruction and returns control to the >>>>>>image via placing the #cannotReturn: context on top of the [^1] >>>>>>context >>>>>>5) #cannotReturn: evaluation results in signalling the BCR >>>>>>exception which is then handled by the #resume handler >>>>>> (in our debugged case the [:ex | self halt. ex resume] >>>>>>handler) >>>>>>6) ex resume is evaluated, however, this means requesting the VM >>>>>>to evaluate instruction 19 of the [^1] context - which is past >>>>>>the last instruction of the context and the crash ensues >>>>>> >>>>>>I wonder whether such situations could/should be prevented inside >>>>>>the VM or whether such an expectation is wrong for some reason. >>>>> >>>>>As Nicolas says, IMO this is best done at the image level. >>>>> >>>>>It could be prevented in the VM, but at great cost, and only >>>>>partially. The performance issue is that the last bytecode in a >>>>>method is not marked in any way, and that to determine the last >>>>>bytecode the bytecodes must be symbolically evaluated from the >>>>>start of the method. See implementors of endPC at the image level >>>>>(which defer to the method trailer) and implementors of endPCOf: >>>>>in the VMMaker code. Doing this every time execution commences is >>>>>prohibitively expensive. The "only partially" issue is that >>>>>following the return instruction may be other valid bytecodes, but >>>>>these are not a continuation. >>>>> >>>>> >>>>>Consider the following code in some block: >>>>> [self expression ifTrue: >>>>> [^1]. >>>>> ^2 >>>>> >>>>>The bytecodes for this are >>>>> pushReceiver >>>>> send #expression >>>>> jumpFalse L1 >>>>> push 1 >>>>> methodReturnTop >>>>>L1 >>>>> push 2 >>>>> methodReturnTop >>>>> >>>>>Clearly if expression is true these should be *no* continuation in >>>>>which ^2 is executed. >>>> >>>>Well, in that case there's a bug because the computation in the >>>>following example shouldn't continue past the [^1] block but it >>>>silently does: >>>>`[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork` >>>> >>>>The bytecodes are >>>> push true >>>> jumpFalse L1 >>>> push 1 >>>> returnTop >>>>L1 >>>> push nil >>>> blockReturn >>>> >>>> >>>> >>>>> >>>>>So even if the VM did try and detect whether the return was at the >>>>>last block method, it would only work for special cases. >>>>> >>>>> >>>>>It seems to me the issue is simply that the context that cannot be >>>>>returned from should be marked as dead (see Context>>isDead) by >>>>>setting its pc to nil at some point, presumably after copying the >>>>>actual return pc into the BlockCannotReturn exception, to avoid >>>>>ever trying to resume the context. >>>> >>>>Does this mean, in other words, that every context that returns >>>>should nil its pc to avoid being "wrongly" reused/executed in the >>>>future, which concerns primarily those being referenced somewhere >>>>hence potentially executable in the future, is that right? >>>>Hypothetical question: would nilling the pc during returns "fix" >>>>the example? >>>>Thanks a lot for helping me understand this. >>>>Best, >>>>Jaromir >>>> >>>> >>>> >>>>> >>>>> >>>>>> >>>>>>Thanks, >>>>>>Jaromir >>>>>> >>>>>><bdxuqalu.png> >>>>>> >>>>>>------ Original Message ------ >>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The general-purpose >>>>>>Squeak developers list" <squeak-dev(a)lists.squeakfoundation.org> >>>>>>Date 11/16/2023 6:48:43 PM >>>>>>Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn >>>>>>exception >>>>>> >>>>>>>Hi Jaromir, >>>>>>> >>>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas <mail(a)jaromir.net> >>>>>>>>wrote: >>>>>>>> >>>>>>>> >>>>>>>>Hi Nicloas, >>>>>>>>No no, I don't have any practical scenario in mind, I'm just >>>>>>>>trying to understand why the VM is implemented like this, >>>>>>>>whether there were a reason to leave this possibility of a >>>>>>>>crash, e.g. it would slow down the VM to try to prevent such a >>>>>>>>dumb situation (who would resume from BCR in his right mind? :) >>>>>>>>) - or perhaps I have overlooked some good reason to even keep >>>>>>>>this behavior in the VM. That's all. >>>>>>> >>>>>>>Let’s first understand what’s really happening. Presumably at >>>>>>>tone point a context is resumed those pc is already at the block >>>>>>>return bytecode (effectively, because it crashes in JITted code, >>>>>>>but I bet the stack vm will crash also, but not as cleanly - it >>>>>>>will try and execute the bytes in the encoded method trailer). >>>>>>>So which method actually sends resume, and to what, and what >>>>>>>state is resume’s receiver when resume is sent? >>>>>>> >>>>>>> >>>>>>>> >>>>>>>>Thanks for your reply. >>>>>>>>Regards, >>>>>>>>Jaromir >>>>>>>> >>>>>>>> >>>>>>>> >>>>>>>> >>>>>>>>------ Original Message ------ >>>>>>>>From "Nicolas Cellier" <nicolas.cellier.aka.nice(a)gmail.com> >>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The general-purpose >>>>>>>>Squeak developers list" <squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>Date 11/16/2023 7:20:20 AM >>>>>>>>Subject Re: [squeak-dev] Resuming on BlockCannotReturn >>>>>>>>exception >>>>>>>> >>>>>>>>>Hi Jaromir, >>>>>>>>>Is there a scenario where it would make sense to resume a >>>>>>>>>BlockCannotReturn? >>>>>>>>>If not, I would suggest to protect at image side and override >>>>>>>>>#resume. >>>>>>>>> >>>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas <mail(a)jaromir.net> >>>>>>>>>a écrit : >>>>>>>>>>Hi Eliot, Christoph, All, >>>>>>>>>> >>>>>>>>>>It's known the following example crashes the VM. Is this an >>>>>>>>>>intended behavior or a "tolerated bug"? >>>>>>>>>> >>>>>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>>>>>>>> >>>>>>>>>>I understand why it crashes: the non-local return has nowhere >>>>>>>>>>to return to and so resuming the computation leads to a >>>>>>>>>>crash. But why not raise another BCR exception to prevent the >>>>>>>>>>crash? Potential infinite loop? Perhaps I'm just missing the >>>>>>>>>>purpose of this behavior... >>>>>>>>>> >>>>>>>>>>Thanks for an explanation. >>>>>>>>>> >>>>>>>>>>Best, >>>>>>>>>>Jaromir >>>>>>>>>> >>>>>>>>>>-- >>>>>>>>>> >>>>>>>>>>Jaromir Matas >>>>>>>>>> >>>>>>>>>> >>>>>>>> >>>>> >>>>> >>>>>-- >>>>>_,,,^..^,,,_ >>>>>best, Eliot >>><Context-cannotReturn.st>
Sent from Squeak Inbox Talk
Hi Eliot,
------ Original Message ------ From "Eliot Miranda" eliot.miranda@gmail.com To "The general-purpose Squeak developers list" squeak-dev@lists.squeakfoundation.org Date 11/20/2023 11:02:11 PM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On Nov 19, 2023, at 10:57 AM, Jaromir Matas mail@jaromir.net wrote:
Hi Christoph,
Can you give me an example of where this extra notification adds any
value for the user? I should have given it in the message, sorry. You can e.g. run
[[true ifTrue: [^ 1]] on: BlockCannotReturn do: [:ex | self halt. ex resume] ] fork
IMO a better example is | expr | expr := true. [[expr ifTrue: [^ 1]. ^2] on: BlockCannotReturn do: [:ex | self halt. ex resume] ] fork
Here IMO we want a) the resume attempt to cause another BlockCannotReturn and/or terminate the computation opening a debugger which highlights ^1 b) we never want to execute ^2
This is more or less what's happening with the fix. However, I guess the resume attempt should cause an error different from the BCR otherwise we'll get an infinite loop, at least I did in my experiments. I thought that was the reason why the closureOrNil ifNil branch in #cannotReturn doesn't raise a BCR but just opens a Debugger instead.
So if we were writing a test we could do something like
| expr executedReturnTwo sync | expr := true. executedReturnTwo := false. sync := Semaphore new. self should: [[sync signal. [expr ifTrue: [^ 1]. ^2] on: BlockCannotReturn do: [:ex | self halt. ex resume] ] fork. sync wait] raise: Error. self deny: executedReturnTwo
Here's a working version of the test; a few notes though: 1. self should:raise: won't work across two processes so I catch the error with an `error` variable and pass it. 2. in order for this to work the #cannotReturn should raise an error (different from BCR) rather than just open a debugger; perhaps something like this: ``` cannotReturn: result closureOrNil ifNotNil: [^self cannotReturn: result to: self home sender; push: pc; pc: nil]. self error: 'Computation has been terminated!' ``` 3. such test would crash the VM when run without the fix - is it acceptable? ``` testResumeAfterBCR | expr executedReturnTwo error sync | expr := true. executedReturnTwo := false. error := false. sync := Semaphore new. [[sync signal. [expr ifTrue: [^1]. ^2] on: BlockCannotReturn do: #resume] on: Error do: [error := true]] fork. sync wait. self assert: error. self deny: executedReturnTwo ``` Regarding my attempt to fix the Debugger bit:
It must be possible to handle the issue local to the non-local return
processing. Think like an implement or and find something more elegant. I really appreciate your honest feedback. I didn't like my "solution" and I'm more than happy to throw it away now :) Thanks, Jaromir
Context>>cannotReturn: line, go three times Over and then dive in via Into, Over or Through :) You get a strange error without the fix and 'Illegal attempt...' with the fix.
I by no means understand exactly how the Debugger works so you may have a way better idea where to place a fix or maybe even fix the pc = nil debugging situation cleanly instead of my ugly patch.
Thanks for your input!
--
Jaromir Matas
Eliot _,,,^..^,,,_ (phone)
------ Original Message ------ From christoph.thiede@student.hpi.uni-potsdam.de To squeak-dev@lists.squeakfoundation.org Date 11/19/2023 7:04:35 PM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
thanks for looking into this!
[[^ 1] on: BlockCannotReturn do: #resume ] fork. "VM crash"
Indeed, this could and should be handled more robustly in the image!
[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork. "Illegal return from ^1"
Is this really illegal? Remember that resuming an exception is generally something special, and as this exception refers to a return instruction, resuming it is something I would definitely consider metaprogramming or worse. Thinking of ^ 1 as a syntactic sugar for "thisContext home return: 1", I would actually find it plausible that resuming from the exception would skip the #return: send. However, I have not read the entire conversation, so if Eliot says something different, please ignore this objection. :-)
Kernel-jar.1535:
- closureOrNil ifNotNil: [^self cannotReturn: result to: self home sender; push: pc; pc: nil].
Do I understand correctly that the pushed pc is only visible when manually inspecting the context? This is something very unexpected to me, it just feels as if you did not find any better place to store this information. Especially if there is no ready path available to access it later. Or am I wrong? Given the expected rareness of those events and the even greater rareness of multiple non-local returns from a single block context that has survived their home context, I wonder whether this information is actually required. If yes, why don't store it in the BlockCannotReturn exception instead?
Tools-jar.1240
Can you give me an example of where this extra notification adds any value for the user? If I run any of your two examples without the change in the Debugger, I just get a Computation has been terminated error while the #cannotReturn: stack is still available, which already seems to give me all information required to identify the origin of the error, in particular due to the extensive comment in this method.
Best, Christoph
Sent from Squeak Inbox Talk
On 2023-11-19T17:44:24+00:00, mail@jaromir.net wrote:
Hi Eliot, all,
I've sent Kernel-jar.1535 with a suggested fix dealing with the following two examples discussed in this thread:
[[^ 1] on: BlockCannotReturn do: #resume ] fork. "VM crash"
[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork. "Illegal return from ^1"
Now both examples work correctly.
In addition, Tools-jar.1240 is an attempt to facilitate debugging the resumption from the BCR exception. Currently the debugger opens with a confusing error as a consequence of decoding an instruction with nil index. In case you have a better idea where to place the fix, please let me know.
Thanks for your help,
best, Jaromir
-- Jaromir Matas
------ Original Message ------
From "Jaromir Matas" <mail(a)jaromir.net>
To "Eliot Miranda" <eliot.miranda(a)gmail.com>; squeak-dev(a)lists.squeakfoundation.org Date 11/18/2023 12:53:18 PM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Eliot,
------ Original Message ------ From "Jaromir Matas" <mail(a)jaromir.net> To "Eliot Miranda" <eliot.miranda(a)gmail.com>; squeak-dev(a)lists.squeakfoundation.org Date 11/18/2023 12:14:31 AM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Eliot,
How about to nil the pc just before making the return:
Context >> #cannotReturn: result self push: self pc. "backup the pc for the sake of debugging" closureOrNil ifNotNil: [^self cannotReturn: result to: self home sender; pc: nil]. Processor debugWithTitle: 'Computation has been terminated!' translated full: falseThe nilled pc should not even potentially interfere with the #isDead now.
I hope this is at least a step in the right direction :)
However, there's still a problem when debugging the resumption of #cannotReturn because the encoders expect a reasonable index. I haven't figured out yet where to place a nil check - #step, #stepToSendOrReturn... ?
This debugger issue has nothing to do with the proposed change... the debugging fails in the current trunk image too:
Run `[[^ 1] on: BlockCannotReturn do: [:ex | self halt. ex resume] ] fork` Click on the highlighted context Step into
So, if the suggested solution makes sense to you, it would make 'playing with fire' a bit safer :)
best, Jaromir
Thanks again, Jaromir
------ Original Message ------ From "Eliot Miranda" <eliot.miranda(a)gmail.com> To "Jaromir Matas" <mail(a)jaromir.net> Date 11/17/2023 8:36:50 PM Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception
>Hi Jaromir, > >>On Nov 17, 2023, at 7:05 AM, Jaromir Matas <mail(a)jaromir.net> wrote: >> >> >>Eliot, hi again, >> >>Please disregard my previous comment about nilling the contexts that >>have returned. We are indeed talking about the context directly >>under the #cannotReturn context which is totally different from the >>home context in another thread that's gone. >> >>I may still be confused but would nilling the pc of the context >>directly under the cannotReturn context help? Here's what I mean: >>``` >>Context >> #cannotReturn: result >> >> closureOrNil ifNotNil: [^self pc: nil; cannotReturn: result to: >>self home sender]. >> Processor debugWithTitle: 'Computation has been terminated!' >>translated full: false. >>``` >>Instead of crashing the VM invokes the debugger with the >>'Computation has been terminated!' message. >> >>Does this make sense? > >Nearly. But it loses the information on what the pc actually is, and >that’s potentially vital information. So IMO the ox should only be >nilled between the BlockCannotReturn exception being created and >raised. > >[But if you try this don’t be surprised if it causes a few temporary >problems. It looks to me that without a little refactoring this >could easily cause an infinite recursion around the sending of >isDead. I’m sure you’ll be able to fix the code to work correctly] > >>Thanks, >>Jaromir >> >> >>------ Original Message ------ >>From "Jaromir Matas" <mail(a)jaromir.net> >>To "Eliot Miranda" <eliot.miranda(a)gmail.com>; "The general-purpose >>Squeak developers list" <squeak-dev(a)lists.squeakfoundation.org> >>Date 11/17/2023 10:15:17 AM >>Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception >> >>>Hi Eliot, >>> >>> >>> >>>------ Original Message ------ >>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>To "Jaromir Matas" <mail(a)jaromir.net> >>>Cc "The general-purpose Squeak developers list" >>><squeak-dev(a)lists.squeakfoundation.org> >>>Date 11/16/2023 11:52:45 PM >>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn >>>exception >>> >>>>Hi Jaromir, >>>> >>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas <mail(a)jaromir.net> >>>>wrote: >>>>>Hi Nicolas, Eliot, >>>>> >>>>>here's what I understand is happening (see the enclosed >>>>>screenshot): >>>>> >>>>>1) we fork a new process to evaluate [^1] >>>>>2) the new process evaluates [^1] which means instruction 18 is >>>>>being evaluated, hence pc points to instruction 19 now >>>>>3) however, the home context where ^1 should return to is gone by >>>>>this time (the process that executed the fork has already >>>>>returned - notice the two up arrows in the debugger screenshot) >>>>>4) the VM can't finish the instruction and returns control to the >>>>>image via placing the #cannotReturn: context on top of the [^1] >>>>>context >>>>>5) #cannotReturn: evaluation results in signalling the BCR >>>>>exception which is then handled by the #resume handler >>>>> (in our debugged case the [:ex | self halt. ex resume] >>>>>handler) >>>>>6) ex resume is evaluated, however, this means requesting the VM >>>>>to evaluate instruction 19 of the [^1] context - which is past >>>>>the last instruction of the context and the crash ensues >>>>> >>>>>I wonder whether such situations could/should be prevented inside >>>>>the VM or whether such an expectation is wrong for some reason. >>>> >>>>As Nicolas says, IMO this is best done at the image level. >>>> >>>>It could be prevented in the VM, but at great cost, and only >>>>partially. The performance issue is that the last bytecode in a >>>>method is not marked in any way, and that to determine the last >>>>bytecode the bytecodes must be symbolically evaluated from the >>>>start of the method. See implementors of endPC at the image level >>>>(which defer to the method trailer) and implementors of endPCOf: >>>>in the VMMaker code. Doing this every time execution commences is >>>>prohibitively expensive. The "only partially" issue is that >>>>following the return instruction may be other valid bytecodes, but >>>>these are not a continuation. >>>> >>>> >>>>Consider the following code in some block: >>>> [self expression ifTrue: >>>> [^1]. >>>> ^2 >>>> >>>>The bytecodes for this are >>>> pushReceiver >>>> send #expression >>>> jumpFalse L1 >>>> push 1 >>>> methodReturnTop >>>>L1 >>>> push 2 >>>> methodReturnTop >>>> >>>>Clearly if expression is true these should be *no* continuation in >>>>which ^2 is executed. >>> >>>Well, in that case there's a bug because the computation in the >>>following example shouldn't continue past the [^1] block but it >>>silently does: >>>`[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork` >>> >>>The bytecodes are >>> push true >>> jumpFalse L1 >>> push 1 >>> returnTop >>>L1 >>> push nil >>> blockReturn >>> >>> >>> >>>> >>>>So even if the VM did try and detect whether the return was at the >>>>last block method, it would only work for special cases. >>>> >>>> >>>>It seems to me the issue is simply that the context that cannot be >>>>returned from should be marked as dead (see Context>>isDead) by >>>>setting its pc to nil at some point, presumably after copying the >>>>actual return pc into the BlockCannotReturn exception, to avoid >>>>ever trying to resume the context. >>> >>>Does this mean, in other words, that every context that returns >>>should nil its pc to avoid being "wrongly" reused/executed in the >>>future, which concerns primarily those being referenced somewhere >>>hence potentially executable in the future, is that right? >>>Hypothetical question: would nilling the pc during returns "fix" >>>the example? >>>Thanks a lot for helping me understand this. >>>Best, >>>Jaromir >>> >>> >>> >>>> >>>> >>>>> >>>>>Thanks, >>>>>Jaromir >>>>> >>>>><bdxuqalu.png> >>>>> >>>>>------ Original Message ------ >>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The general-purpose >>>>>Squeak developers list" <squeak-dev(a)lists.squeakfoundation.org> >>>>>Date 11/16/2023 6:48:43 PM >>>>>Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn >>>>>exception >>>>> >>>>>>Hi Jaromir, >>>>>> >>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas <mail(a)jaromir.net> >>>>>>>wrote: >>>>>>> >>>>>>> >>>>>>>Hi Nicloas, >>>>>>>No no, I don't have any practical scenario in mind, I'm just >>>>>>>trying to understand why the VM is implemented like this, >>>>>>>whether there were a reason to leave this possibility of a >>>>>>>crash, e.g. it would slow down the VM to try to prevent such a >>>>>>>dumb situation (who would resume from BCR in his right mind? :) >>>>>>>) - or perhaps I have overlooked some good reason to even keep >>>>>>>this behavior in the VM. That's all. >>>>>> >>>>>>Let’s first understand what’s really happening. Presumably at >>>>>>tone point a context is resumed those pc is already at the block >>>>>>return bytecode (effectively, because it crashes in JITted code, >>>>>>but I bet the stack vm will crash also, but not as cleanly - it >>>>>>will try and execute the bytes in the encoded method trailer). >>>>>>So which method actually sends resume, and to what, and what >>>>>>state is resume’s receiver when resume is sent? >>>>>> >>>>>> >>>>>>> >>>>>>>Thanks for your reply. >>>>>>>Regards, >>>>>>>Jaromir >>>>>>> >>>>>>> >>>>>>> >>>>>>> >>>>>>>------ Original Message ------ >>>>>>>From "Nicolas Cellier" <nicolas.cellier.aka.nice(a)gmail.com> >>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The general-purpose >>>>>>>Squeak developers list" <squeak-dev(a)lists.squeakfoundation.org> >>>>>>>Date 11/16/2023 7:20:20 AM >>>>>>>Subject Re: [squeak-dev] Resuming on BlockCannotReturn >>>>>>>exception >>>>>>> >>>>>>>>Hi Jaromir, >>>>>>>>Is there a scenario where it would make sense to resume a >>>>>>>>BlockCannotReturn? >>>>>>>>If not, I would suggest to protect at image side and override >>>>>>>>#resume. >>>>>>>> >>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas <mail(a)jaromir.net> >>>>>>>>a écrit : >>>>>>>>>Hi Eliot, Christoph, All, >>>>>>>>> >>>>>>>>>It's known the following example crashes the VM. Is this an >>>>>>>>>intended behavior or a "tolerated bug"? >>>>>>>>> >>>>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>>>>>>> >>>>>>>>>I understand why it crashes: the non-local return has nowhere >>>>>>>>>to return to and so resuming the computation leads to a >>>>>>>>>crash. But why not raise another BCR exception to prevent the >>>>>>>>>crash? Potential infinite loop? Perhaps I'm just missing the >>>>>>>>>purpose of this behavior... >>>>>>>>> >>>>>>>>>Thanks for an explanation. >>>>>>>>> >>>>>>>>>Best, >>>>>>>>>Jaromir >>>>>>>>> >>>>>>>>>-- >>>>>>>>> >>>>>>>>>Jaromir Matas >>>>>>>>> >>>>>>>>> >>>>>>> >>>> >>>> >>>>-- >>>>_,,,^..^,,,_ >>>>best, Eliot >><Context-cannotReturn.st>

Hi Christoph,
On Nov 19, 2023, at 10:23 AM, christoph.thiede@student.hpi.uni-potsdam.de wrote:
Hi Jaromir,
thanks for looking into this!
[[^ 1] on: BlockCannotReturn do: #resume ] fork. "VM crash"
Indeed, this could and should be handled more robustly in the image!
[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork. "Illegal return from ^1"
Is this really illegal? Remember that resuming an exception is generally something special, and as this exception refers to a return instruction, resuming it is something I would definitely consider metaprogramming or worse. Thinking of ^ 1 as a syntactic sugar for "thisContext home return: 1", I would actually find it plausible that resuming from the exception would skip the #return: send. However, I have not read the entire conversation, so if Eliot says something different, please ignore this objection. :-)
The point here is that the return is attempting a “side-ways return”. Because if the fork the home context is no longer on the block activation’s stack because the block activation is in a different process. So the return isn’t legal and it is never legal for anything to be returned from the home.
Yes, this is a convention but IIRC it is also in the ANDI standard. Anyway, in the blue book VM definition side-ways returns are not caught (because there was no unwind-protect in Smalltalk-80 v1 & v2. But on adding unwind-protect all implementations I am aware of decided at the same time to ban sideways returns. And Squeak is no exception.
Kernel-jar.1535:
- closureOrNil ifNotNil: [^self cannotReturn: result to: self home sender; push: pc; pc: nil].
Do I understand correctly that the pushed pc is only visible when manually inspecting the context? This is something very unexpected to me, it just feels as if you did not find any better place to store this information. Especially if there is no ready path available to access it later. Or am I wrong? Given the expected rareness of those events and the even greater rareness of multiple non-local returns from a single block context that has survived their home context, I wonder whether this information is actually required. If yes, why don't store it in the BlockCannotReturn exception instead?
Tools-jar.1240
Can you give me an example of where this extra notification adds any value for the user? If I run any of your two examples without the change in the Debugger, I just get a Computation has been terminated error while the #cannotReturn: stack is still available, which already seems to give me all information required to identify the origin of the error, in particular due to the extensive comment in this method.
Best, Christoph
Sent from Squeak Inbox Talk
On 2023-11-19T17:44:24+00:00, mail@jaromir.net wrote:
Hi Eliot, all,
I've sent Kernel-jar.1535 with a suggested fix dealing with the following two examples discussed in this thread:
[[^ 1] on: BlockCannotReturn do: #resume ] fork. "VM crash"
[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork. "Illegal return from ^1"
Now both examples work correctly.
In addition, Tools-jar.1240 is an attempt to facilitate debugging the resumption from the BCR exception. Currently the debugger opens with a confusing error as a consequence of decoding an instruction with nil index. In case you have a better idea where to place the fix, please let me know.
Thanks for your help,
best, Jaromir
-- Jaromir Matas
------ Original Message ------
From "Jaromir Matas" <mail(a)jaromir.net>
To "Eliot Miranda" <eliot.miranda(a)gmail.com>; squeak-dev(a)lists.squeakfoundation.org Date 11/18/2023 12:53:18 PM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Eliot,
------ Original Message ------ From "Jaromir Matas" <mail(a)jaromir.net> To "Eliot Miranda" <eliot.miranda(a)gmail.com>; squeak-dev(a)lists.squeakfoundation.org Date 11/18/2023 12:14:31 AM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Eliot,
How about to nil the pc just before making the return:
Context >> #cannotReturn: result self push: self pc. "backup the pc for the sake of debugging" closureOrNil ifNotNil: [^self cannotReturn: result to: self home sender; pc: nil]. Processor debugWithTitle: 'Computation has been terminated!' translated full: falseThe nilled pc should not even potentially interfere with the #isDead now.
I hope this is at least a step in the right direction :)
However, there's still a problem when debugging the resumption of #cannotReturn because the encoders expect a reasonable index. I haven't figured out yet where to place a nil check - #step, #stepToSendOrReturn... ?
This debugger issue has nothing to do with the proposed change... the debugging fails in the current trunk image too:
Run `[[^ 1] on: BlockCannotReturn do: [:ex | self halt. ex resume] ] fork` Click on the highlighted context Step into
So, if the suggested solution makes sense to you, it would make 'playing with fire' a bit safer :)
best, Jaromir
Thanks again, Jaromir
------ Original Message ------ From "Eliot Miranda" <eliot.miranda(a)gmail.com> To "Jaromir Matas" <mail(a)jaromir.net> Date 11/17/2023 8:36:50 PM Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On Nov 17, 2023, at 7:05 AM, Jaromir Matas <mail(a)jaromir.net> wrote:
Eliot, hi again,
Please disregard my previous comment about nilling the contexts that have returned. We are indeed talking about the context directly under the #cannotReturn context which is totally different from the home context in another thread that's gone.
I may still be confused but would nilling the pc of the context directly under the cannotReturn context help? Here's what I mean:
Context >> #cannotReturn: result closureOrNil ifNotNil: [^self pc: nil; cannotReturn: result to: self home sender]. Processor debugWithTitle: 'Computation has been terminated!' translated full: false.Instead of crashing the VM invokes the debugger with the 'Computation has been terminated!' message.
Does this make sense?
Nearly. But it loses the information on what the pc actually is, and that’s potentially vital information. So IMO the ox should only be nilled between the BlockCannotReturn exception being created and raised.
[But if you try this don’t be surprised if it causes a few temporary problems. It looks to me that without a little refactoring this could easily cause an infinite recursion around the sending of isDead. I’m sure you’ll be able to fix the code to work correctly]
Thanks, Jaromir
------ Original Message ------ From "Jaromir Matas" <mail(a)jaromir.net> To "Eliot Miranda" <eliot.miranda(a)gmail.com>; "The general-purpose Squeak developers list" <squeak-dev(a)lists.squeakfoundation.org> Date 11/17/2023 10:15:17 AM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
> Hi Eliot, > > > > ------ Original Message ------ > From "Eliot Miranda" <eliot.miranda(a)gmail.com> > To "Jaromir Matas" <mail(a)jaromir.net> > Cc "The general-purpose Squeak developers list" > <squeak-dev(a)lists.squeakfoundation.org> > Date 11/16/2023 11:52:45 PM > Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn > exception > >> Hi Jaromir, >> >> On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas <mail(a)jaromir.net> >> wrote: >>> Hi Nicolas, Eliot, >>> >>> here's what I understand is happening (see the enclosed >>> screenshot): >>> >>> 1) we fork a new process to evaluate [^1] >>> 2) the new process evaluates [^1] which means instruction 18 is >>> being evaluated, hence pc points to instruction 19 now >>> 3) however, the home context where ^1 should return to is gone by >>> this time (the process that executed the fork has already >>> returned - notice the two up arrows in the debugger screenshot) >>> 4) the VM can't finish the instruction and returns control to the >>> image via placing the #cannotReturn: context on top of the [^1] >>> context >>> 5) #cannotReturn: evaluation results in signalling the BCR >>> exception which is then handled by the #resume handler >>> (in our debugged case the [:ex | self halt. ex resume] >>> handler) >>> 6) ex resume is evaluated, however, this means requesting the VM >>> to evaluate instruction 19 of the [^1] context - which is past >>> the last instruction of the context and the crash ensues >>> >>> I wonder whether such situations could/should be prevented inside >>> the VM or whether such an expectation is wrong for some reason. >> >> As Nicolas says, IMO this is best done at the image level. >> >> It could be prevented in the VM, but at great cost, and only >> partially. The performance issue is that the last bytecode in a >> method is not marked in any way, and that to determine the last >> bytecode the bytecodes must be symbolically evaluated from the >> start of the method. See implementors of endPC at the image level >> (which defer to the method trailer) and implementors of endPCOf: >> in the VMMaker code. Doing this every time execution commences is >> prohibitively expensive. The "only partially" issue is that >> following the return instruction may be other valid bytecodes, but >> these are not a continuation. >> >> >> Consider the following code in some block: >> [self expression ifTrue: >> [^1]. >> ^2 >> >> The bytecodes for this are >> pushReceiver >> send #expression >> jumpFalse L1 >> push 1 >> methodReturnTop >> L1 >> push 2 >> methodReturnTop >> >> Clearly if expression is true these should be *no* continuation in >> which ^2 is executed. > > Well, in that case there's a bug because the computation in the > following example shouldn't continue past the [^1] block but it > silently does: > `[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork` > > The bytecodes are > push true > jumpFalse L1 > push 1 > returnTop > L1 > push nil > blockReturn > > > >> >> So even if the VM did try and detect whether the return was at the >> last block method, it would only work for special cases. >> >> >> It seems to me the issue is simply that the context that cannot be >> returned from should be marked as dead (see Context>>isDead) by >> setting its pc to nil at some point, presumably after copying the >> actual return pc into the BlockCannotReturn exception, to avoid >> ever trying to resume the context. > > Does this mean, in other words, that every context that returns > should nil its pc to avoid being "wrongly" reused/executed in the > future, which concerns primarily those being referenced somewhere > hence potentially executable in the future, is that right? > Hypothetical question: would nilling the pc during returns "fix" > the example? > Thanks a lot for helping me understand this. > Best, > Jaromir > > > >> >> >>> >>> Thanks, >>> Jaromir >>> >>> <bdxuqalu.png> >>> >>> ------ Original Message ------ >>> From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>> To "Jaromir Matas" <mail(a)jaromir.net>; "The general-purpose >>> Squeak developers list" <squeak-dev(a)lists.squeakfoundation.org> >>> Date 11/16/2023 6:48:43 PM >>> Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn >>> exception >>> >>>> Hi Jaromir, >>>> >>>>> On Nov 16, 2023, at 3:23 AM, Jaromir Matas <mail(a)jaromir.net> >>>>> wrote: >>>>> >>>>> >>>>> Hi Nicloas, >>>>> No no, I don't have any practical scenario in mind, I'm just >>>>> trying to understand why the VM is implemented like this, >>>>> whether there were a reason to leave this possibility of a >>>>> crash, e.g. it would slow down the VM to try to prevent such a >>>>> dumb situation (who would resume from BCR in his right mind? :) >>>>> ) - or perhaps I have overlooked some good reason to even keep >>>>> this behavior in the VM. That's all. >>>> >>>> Let’s first understand what’s really happening. Presumably at >>>> tone point a context is resumed those pc is already at the block >>>> return bytecode (effectively, because it crashes in JITted code, >>>> but I bet the stack vm will crash also, but not as cleanly - it >>>> will try and execute the bytes in the encoded method trailer). >>>> So which method actually sends resume, and to what, and what >>>> state is resume’s receiver when resume is sent? >>>> >>>> >>>>> >>>>> Thanks for your reply. >>>>> Regards, >>>>> Jaromir >>>>> >>>>> >>>>> >>>>> >>>>> ------ Original Message ------ >>>>> From "Nicolas Cellier" <nicolas.cellier.aka.nice(a)gmail.com> >>>>> To "Jaromir Matas" <mail(a)jaromir.net>; "The general-purpose >>>>> Squeak developers list" <squeak-dev(a)lists.squeakfoundation.org> >>>>> Date 11/16/2023 7:20:20 AM >>>>> Subject Re: [squeak-dev] Resuming on BlockCannotReturn >>>>> exception >>>>> >>>>>> Hi Jaromir, >>>>>> Is there a scenario where it would make sense to resume a >>>>>> BlockCannotReturn? >>>>>> If not, I would suggest to protect at image side and override >>>>>> #resume. >>>>>> >>>>>> Le mer. 15 nov. 2023, 23:42, Jaromir Matas <mail(a)jaromir.net> >>>>>> a écrit : >>>>>>> Hi Eliot, Christoph, All, >>>>>>> >>>>>>> It's known the following example crashes the VM. Is this an >>>>>>> intended behavior or a "tolerated bug"? >>>>>>> >>>>>>> `[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>>>>> >>>>>>> I understand why it crashes: the non-local return has nowhere >>>>>>> to return to and so resuming the computation leads to a >>>>>>> crash. But why not raise another BCR exception to prevent the >>>>>>> crash? Potential infinite loop? Perhaps I'm just missing the >>>>>>> purpose of this behavior... >>>>>>> >>>>>>> Thanks for an explanation. >>>>>>> >>>>>>> Best, >>>>>>> Jaromir >>>>>>> >>>>>>> -- >>>>>>> >>>>>>> Jaromir Matas >>>>>>> >>>>>>> >>>>> >> >> >> -- >> _,,,^..^,,,_ >> best, Eliot <Context-cannotReturn.st>
Hi Jaromir,
see Kernel-eem.1535 for what I was suggesting. This example now has an exception with the right pc value in it:
[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] fork
The fix is simply
*Context>>cannotReturn:* result *to:* homeContext
*"The receiver tried to return result to homeContext that cannot be returned from. Capture the return pc in a BlockCannotReturn. Nil the pc to prevent repeat attempts and/or invalid continuation. Answer the result of raising the exception."*
| exception | exception *:=* BlockCannotReturn new. exception result: result; deadHome: homeContext; pc: self previousPc. pc *:=* nil. ^exception signal
The VM crash is now avoided. The debugger displays the method, but does not highlight the offending pc, which is no big deal. A suitable defaultHandler for B lockCannotReturn may be able to get the debugger to highlight correctly on opening. Try the following examples:
[[^1] on: BlockCannotReturn do: #resume] fork.
[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] fork
[[^1] value] fork.
They al; seem to behave perfectly acceptably to me. Does this fix work for you?
On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas mail@jaromir.net wrote:
Hi Eliot,
How about to nil the pc just before making the return:
Context >> #cannotReturn: result self push: self pc. "backup the pc for the sake of debugging" closureOrNil ifNotNil: [^self cannotReturn: result to: self home sender; pc: nil]. Processor debugWithTitle: 'Computation has been terminated!' translated full: falseThe nilled pc should not even potentially interfere with the #isDead now.
I hope this is at least a step in the right direction :)
However, there's still a problem when debugging the resumption of #cannotReturn because the encoders expect a reasonable index. I haven't figured out yet where to place a nil check - #step, #stepToSendOrReturn... ?
Thanks again, Jaromir
------ Original Message ------ From "Eliot Miranda" eliot.miranda@gmail.com To "Jaromir Matas" mail@jaromir.net Date 11/17/2023 8:36:50 PM Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On Nov 17, 2023, at 7:05 AM, Jaromir Matas mail@jaromir.net wrote:
Eliot, hi again,
Please disregard my previous comment about nilling the contexts that have returned. We are indeed talking about the context directly under the #cannotReturn context which is totally different from the home context in another thread that's gone.
I may still be confused but would nilling the pc of the context directly under the cannotReturn context help? Here's what I mean:
Context >> #cannotReturn: result closureOrNil ifNotNil: [^self pc: nil; cannotReturn: result to: self home sender]. Processor debugWithTitle: 'Computation has been terminated!' translated full: false.Instead of crashing the VM invokes the debugger with the 'Computation has been terminated!' message.
Does this make sense?
Nearly. But it loses the information on what the pc actually is, and that’s potentially vital information. So IMO the ox should only be nilled between the BlockCannotReturn exception being created and raised.
[But if you try this don’t be surprised if it causes a few temporary problems. It looks to me that without a little refactoring this could easily cause an infinite recursion around the sending of isDead. I’m sure you’ll be able to fix the code to work correctly]
Thanks, Jaromir
------ Original Message ------ From "Jaromir Matas" mail@jaromir.net To "Eliot Miranda" eliot.miranda@gmail.com; "The general-purpose Squeak developers list" squeak-dev@lists.squeakfoundation.org Date 11/17/2023 10:15:17 AM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Eliot,
------ Original Message ------ From "Eliot Miranda" eliot.miranda@gmail.com To "Jaromir Matas" mail@jaromir.net Cc "The general-purpose Squeak developers list" < squeak-dev@lists.squeakfoundation.org> Date 11/16/2023 11:52:45 PM Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas mail@jaromir.net wrote:
Hi Nicolas, Eliot,
here's what I understand is happening (see the enclosed screenshot):
- we fork a new process to evaluate [^1]
- the new process evaluates [^1] which means instruction 18 is being
evaluated, hence pc points to instruction 19 now 3) however, the home context where ^1 should return to is gone by this time (the process that executed the fork has already returned - notice the two up arrows in the debugger screenshot) 4) the VM can't finish the instruction and returns control to the image via placing the #cannotReturn: context on top of the [^1] context 5) #cannotReturn: evaluation results in signalling the BCR exception which is then handled by the #resume handler (in our debugged case the [:ex | self halt. ex resume] handler) 6) ex resume is evaluated, however, this means requesting the VM to evaluate instruction 19 of the [^1] context - which is past the last instruction of the context and the crash ensues
I wonder whether such situations could/should be prevented inside the VM or whether such an expectation is wrong for some reason.
As Nicolas says, IMO this is best done at the image level.
It could be prevented in the VM, but at great cost, and only partially. The performance issue is that the last bytecode in a method is not marked in any way, and that to determine the last bytecode the bytecodes must be symbolically evaluated from the start of the method. See implementors of endPC at the image level (which defer to the method trailer) and implementors of endPCOf: in the VMMaker code. Doing this every time execution commences is prohibitively expensive. The "only partially" issue is that following the return instruction may be other valid bytecodes, but these are not a continuation.
Consider the following code in some block: [self expression ifTrue: [^1]. ^2
The bytecodes for this are pushReceiver send #expression jumpFalse L1 push 1 methodReturnTop L1 push 2 methodReturnTop
Clearly if expression is true these should be *no* continuation in which ^2 is executed.
Well, in that case there's a bug because the computation in the following example shouldn't continue past the [^1] block but it silently does: `[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork`
The bytecodes are push true jumpFalse L1 push 1 returnTop L1 push nil blockReturn
So even if the VM did try and detect whether the return was at the last block method, it would only work for special cases.
It seems to me the issue is simply that the context that cannot be returned from should be marked as dead (see Context>>isDead) by setting its pc to nil at some point, presumably after copying the actual return pc into the BlockCannotReturn exception, to avoid ever trying to resume the context.
Does this mean, in other words, that every context that returns should nil its pc to avoid being "wrongly" reused/executed in the future, which concerns primarily those being referenced somewhere hence potentially executable in the future, is that right? Hypothetical question: would nilling the pc during returns "fix" the example? Thanks a lot for helping me understand this. Best, Jaromir
Thanks, Jaromir
<bdxuqalu.png>
------ Original Message ------ From "Eliot Miranda" eliot.miranda@gmail.com To "Jaromir Matas" mail@jaromir.net; "The general-purpose Squeak developers list" squeak-dev@lists.squeakfoundation.org Date 11/16/2023 6:48:43 PM Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On Nov 16, 2023, at 3:23 AM, Jaromir Matas mail@jaromir.net wrote:
Hi Nicloas, No no, I don't have any practical scenario in mind, I'm just trying to understand why the VM is implemented like this, whether there were a reason to leave this possibility of a crash, e.g. it would slow down the VM to try to prevent such a dumb situation (who would resume from BCR in his right mind? :) ) - or perhaps I have overlooked some good reason to even keep this behavior in the VM. That's all.
Let’s first understand what’s really happening. Presumably at tone point a context is resumed those pc is already at the block return bytecode (effectively, because it crashes in JITted code, but I bet the stack vm will crash also, but not as cleanly - it will try and execute the bytes in the encoded method trailer). So which method actually sends resume, and to what, and what state is resume’s receiver when resume is sent?
Thanks for your reply. Regards, Jaromir
------ Original Message ------ From "Nicolas Cellier" nicolas.cellier.aka.nice@gmail.com To "Jaromir Matas" mail@jaromir.net; "The general-purpose Squeak developers list" squeak-dev@lists.squeakfoundation.org Date 11/16/2023 7:20:20 AM Subject Re: [squeak-dev] Resuming on BlockCannotReturn exception
Hi Jaromir, Is there a scenario where it would make sense to resume a BlockCannotReturn? If not, I would suggest to protect at image side and override #resume.
Le mer. 15 nov. 2023, 23:42, Jaromir Matas mail@jaromir.net a écrit :
Hi Eliot, Christoph, All,
It's known the following example crashes the VM. Is this an intended behavior or a "tolerated bug"?
`[[^ 1] on: BlockCannotReturn do: #resume] fork`
I understand why it crashes: the non-local return has nowhere to return to and so resuming the computation leads to a crash. But why not raise another BCR exception to prevent the crash? Potential infinite loop? Perhaps I'm just missing the purpose of this behavior...
Thanks for an explanation.
Best, Jaromir
--
Jaromir Matas
-- _,,,^..^,,,_ best, Eliot
<Context-cannotReturn.st>
Hi Eliot, Very elegant! Now I finally got what you meant exactly :) Thanks.
Two questions: 1. in order for the enclosed test to work I'd need an Error instead of Processor debugWithTitle:full: call in #cannotReturn:. Otherwise I don't know how to catch a plain invocation of the Debugger:
cannotReturn: result
closureOrNil ifNotNil: [^ self cannotReturn: result to: self home sender]. self error: 'Computation has been terminated!'
2. We are capturing a pc of self which is completely different context from homeContext indeed. Maybe we could capture self in the exception too to make it more clear/explicit what is going on: what context the captured pc is actually associated with. Just a thought...
Thanks again, Jaromir
------ Original Message ------ From "Eliot Miranda" eliot.miranda@gmail.com To "Jaromir Matas" mail@jaromir.net Cc squeak-dev@lists.squeakfoundation.org Date 11/21/2023 2:17:21 AM Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
see Kernel-eem.1535 for what I was suggesting. This example now has an exception with the right pc value in it:
[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] fork
The fix is simply
Context>>cannotReturn: result to: homeContext "The receiver tried to return result to homeContext that cannot be returned from. Capture the return pc in a BlockCannotReturn. Nil the pc to prevent repeat attempts and/or invalid continuation. Answer the result of raising the exception."
| exception | exception := BlockCannotReturn new. exception result: result; deadHome: homeContext; pc: self previousPc. pc := nil. ^exception signalThe VM crash is now avoided. The debugger displays the method, but does not highlight the offending pc, which is no big deal. A suitable defaultHandler for B lockCannotReturn may be able to get the debugger to highlight correctly on opening. Try the following examples:
[[^1] on: BlockCannotReturn do: #resume] fork.
[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] fork
[[^1] value] fork.
They al; seem to behave perfectly acceptably to me. Does this fix work for you?
On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas mail@jaromir.net wrote:
Hi Eliot,
How about to nil the pc just before making the return:
Context >> #cannotReturn: result self push: self pc. "backup the pc for the sake of debugging" closureOrNil ifNotNil: [^self cannotReturn: result to: self home sender; pc: nil]. Processor debugWithTitle: 'Computation has been terminated!' translated full: falseThe nilled pc should not even potentially interfere with the #isDead now.
I hope this is at least a step in the right direction :)
However, there's still a problem when debugging the resumption of #cannotReturn because the encoders expect a reasonable index. I haven't figured out yet where to place a nil check - #step, #stepToSendOrReturn... ?
Thanks again, Jaromir
------ Original Message ------ From "Eliot Miranda" eliot.miranda@gmail.com To "Jaromir Matas" mail@jaromir.net Date 11/17/2023 8:36:50 PM Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On Nov 17, 2023, at 7:05 AM, Jaromir Matas mail@jaromir.net wrote:
Eliot, hi again,
Please disregard my previous comment about nilling the contexts that have returned. We are indeed talking about the context directly under the #cannotReturn context which is totally different from the home context in another thread that's gone.
I may still be confused but would nilling the pc of the context directly under the cannotReturn context help? Here's what I mean:
Context >> #cannotReturn: result closureOrNil ifNotNil: [^self pc: nil; cannotReturn: result to: self home sender]. Processor debugWithTitle: 'Computation has been terminated!' translated full: false.Instead of crashing the VM invokes the debugger with the 'Computation has been terminated!' message.
Does this make sense?
Nearly. But it loses the information on what the pc actually is, and that’s potentially vital information. So IMO the ox should only be nilled between the BlockCannotReturn exception being created and raised.
[But if you try this don’t be surprised if it causes a few temporary problems. It looks to me that without a little refactoring this could easily cause an infinite recursion around the sending of isDead. I’m sure you’ll be able to fix the code to work correctly]
Thanks, Jaromir
------ Original Message ------ From "Jaromir Matas" mail@jaromir.net To "Eliot Miranda" eliot.miranda@gmail.com; "The general-purpose Squeak developers list" squeak-dev@lists.squeakfoundation.org Date 11/17/2023 10:15:17 AM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Eliot,
------ Original Message ------ From "Eliot Miranda" eliot.miranda@gmail.com To "Jaromir Matas" mail@jaromir.net Cc "The general-purpose Squeak developers list" squeak-dev@lists.squeakfoundation.org Date 11/16/2023 11:52:45 PM Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas mail@jaromir.net wrote: >Hi Nicolas, Eliot, > >here's what I understand is happening (see the enclosed >screenshot): > >1) we fork a new process to evaluate [^1] >2) the new process evaluates [^1] which means instruction 18 is >being evaluated, hence pc points to instruction 19 now >3) however, the home context where ^1 should return to is gone by >this time (the process that executed the fork has already >returned - notice the two up arrows in the debugger screenshot) >4) the VM can't finish the instruction and returns control to the >image via placing the #cannotReturn: context on top of the [^1] >context >5) #cannotReturn: evaluation results in signalling the BCR >exception which is then handled by the #resume handler > (in our debugged case the [:ex | self halt. ex resume] >handler) >6) ex resume is evaluated, however, this means requesting the VM >to evaluate instruction 19 of the [^1] context - which is past >the last instruction of the context and the crash ensues > >I wonder whether such situations could/should be prevented inside >the VM or whether such an expectation is wrong for some reason.
As Nicolas says, IMO this is best done at the image level.
It could be prevented in the VM, but at great cost, and only partially. The performance issue is that the last bytecode in a method is not marked in any way, and that to determine the last bytecode the bytecodes must be symbolically evaluated from the start of the method. See implementors of endPC at the image level (which defer to the method trailer) and implementors of endPCOf: in the VMMaker code. Doing this every time execution commences is prohibitively expensive. The "only partially" issue is that following the return instruction may be other valid bytecodes, but these are not a continuation.
Consider the following code in some block: [self expression ifTrue: [^1]. ^2
The bytecodes for this are pushReceiver send #expression jumpFalse L1 push 1 methodReturnTop L1 push 2 methodReturnTop
Clearly if expression is true these should be *no* continuation in which ^2 is executed.
Well, in that case there's a bug because the computation in the following example shouldn't continue past the [^1] block but it silently does: `[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork`
The bytecodes are push true jumpFalse L1 push 1 returnTop L1 push nil blockReturn
So even if the VM did try and detect whether the return was at the last block method, it would only work for special cases.
It seems to me the issue is simply that the context that cannot be returned from should be marked as dead (see Context>>isDead) by setting its pc to nil at some point, presumably after copying the actual return pc into the BlockCannotReturn exception, to avoid ever trying to resume the context.
Does this mean, in other words, that every context that returns should nil its pc to avoid being "wrongly" reused/executed in the future, which concerns primarily those being referenced somewhere hence potentially executable in the future, is that right? Hypothetical question: would nilling the pc during returns "fix" the example? Thanks a lot for helping me understand this. Best, Jaromir
> >Thanks, >Jaromir > ><bdxuqalu.png> > >------ Original Message ------ >From "Eliot Miranda" eliot.miranda@gmail.com >To "Jaromir Matas" mail@jaromir.net; "The general-purpose >Squeak developers list" squeak-dev@lists.squeakfoundation.org >Date 11/16/2023 6:48:43 PM >Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn >exception > >>Hi Jaromir, >> >>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas mail@jaromir.net >>>wrote: >>> >>> >>>Hi Nicloas, >>>No no, I don't have any practical scenario in mind, I'm just >>>trying to understand why the VM is implemented like this, >>>whether there were a reason to leave this possibility of a >>>crash, e.g. it would slow down the VM to try to prevent such a >>>dumb situation (who would resume from BCR in his right mind? :) >>>) - or perhaps I have overlooked some good reason to even keep >>>this behavior in the VM. That's all. >> >>Let’s first understand what’s really happening. Presumably at >>tone point a context is resumed those pc is already at the block >>return bytecode (effectively, because it crashes in JITted code, >>but I bet the stack vm will crash also, but not as cleanly - it >>will try and execute the bytes in the encoded method trailer). >>So which method actually sends resume, and to what, and what >>state is resume’s receiver when resume is sent? >> >> >>> >>>Thanks for your reply. >>>Regards, >>>Jaromir >>> >>> >>> >>> >>>------ Original Message ------ >>>From "Nicolas Cellier" nicolas.cellier.aka.nice@gmail.com >>>To "Jaromir Matas" mail@jaromir.net; "The general-purpose >>>Squeak developers list" squeak-dev@lists.squeakfoundation.org >>>Date 11/16/2023 7:20:20 AM >>>Subject Re: [squeak-dev] Resuming on BlockCannotReturn >>>exception >>> >>>>Hi Jaromir, >>>>Is there a scenario where it would make sense to resume a >>>>BlockCannotReturn? >>>>If not, I would suggest to protect at image side and override >>>>#resume. >>>> >>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas mail@jaromir.net >>>>a écrit : >>>>>Hi Eliot, Christoph, All, >>>>> >>>>>It's known the following example crashes the VM. Is this an >>>>>intended behavior or a "tolerated bug"? >>>>> >>>>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>>> >>>>>I understand why it crashes: the non-local return has nowhere >>>>>to return to and so resuming the computation leads to a >>>>>crash. But why not raise another BCR exception to prevent the >>>>>crash? Potential infinite loop? Perhaps I'm just missing the >>>>>purpose of this behavior... >>>>> >>>>>Thanks for an explanation. >>>>> >>>>>Best, >>>>>Jaromir >>>>> >>>>>-- >>>>> >>>>>Jaromir Matas >>>>> >>>>> >>>
-- _,,,^..^,,,_ best, Eliot
<Context-cannotReturn.st>
-- _,,,^..^,,,_ best, Eliot
Hi Eliot,
There seems to be a substantial difference between the two approaches when running the enclosed test:
1. In my uglier solution (see down below): If you remove the `self error` part from #cannotReturn and run the test, one assertion fails, if you remove the `pc: nil` bit the other assertion fails and the test won't crash the system.
2. If you do the same with your solution the test crashes the system when you remove the pc := nil bit and I cant't figure out why.
Can you understand the reason? It looks like adding the `push: #whatever` before returning from #cannotReturn:to: "fixes" your solution. Is it that the VM should do the push before returning control to the image and placing the #cannotReturn context on top of the stack?
``` Context >> cannotReturn: result to: homeContext "The receiver tried to return result to homeContext that cannot be returned from. Capture the return pc in a BlockCannotReturn. Nil the pc to prevent repeat attempts and/or invalid continuation. Answer the result of raising the exception."
| exception | exception := BlockCannotReturn new. exception result: result; deadHome: homeContext; pc: self previousPc. pc := nil. self push: nil. "<-------- this helps -------" ^exception signal ```
Best, Jaromir
``` Context >> cannotReturn: result
closureOrNil ifNotNil: [^ self cannotReturn: result to: self home sender; push: pc; pc: nil]. self error: 'Computation has been terminated!' ```
On 21-Nov-23 6:40:32 PM, "Eliot Miranda" eliot.miranda@gmail.com wrote:
Hi Jaromir,
On Nov 20, 2023, at 11:51 PM, Jaromir Matas mail@jaromir.net wrote:
Hi Eliot, Very elegant! Now I finally got what you meant exactly :) Thanks.
Two questions:
- in order for the enclosed test to work I'd need an Error instead of
Processor debugWithTitle:full: call in #cannotReturn:. Otherwise I don't know how to catch a plain invocation of the Debugger:
cannotReturn: result
closureOrNil ifNotNil: [^ self cannotReturn: result to: self homesender]. self error: 'Computation has been terminated!'
Much nicer.
- We are capturing a pc of self which is completely different context
from homeContext indeed.
Right. The return is attempted from a specific return bytecode in a specific block. This is the coordinate of the return that cannot be made. This is the relevant point of origin of the cannot return exception.
Why the return fails is another matter:
- the home context’s sender is a dead context (cannot be resumed)
- the home context’s sender is nil (home already returned from)
- the block activation’s home is nil rather than a context (should not
happen)
But in all these cases the pc of the home context is immaterial. The hike is being returned through/from, rather than from; the home’s pc is not relevant.
Maybe we could capture self in the exception too to make it more clear/explicit what is going on: what context the captured pc is actually associated with. Just a thought...
Yes, I like that. I also like the idea of somehow passing the block activation’s pc to the debugger so that the relevant return expression is highlighted in the debugger.
Thanks again, Jaromir
You’re welcome. I love working in this part of the system. Thanks for dragging me there. I’m in a slump right now and appreciate the fellowship.
------ Original Message ------ From "Eliot Miranda" eliot.miranda@gmail.com To "Jaromir Matas" mail@jaromir.net Cc squeak-dev@lists.squeakfoundation.org Date 11/21/2023 2:17:21 AM Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
see Kernel-eem.1535 for what I was suggesting. This example now has an exception with the right pc value in it:
[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] fork
The fix is simply
Context>>cannotReturn: result to: homeContext "The receiver tried to return result to homeContext that cannot be returned from. Capture the return pc in a BlockCannotReturn. Nil the pc to prevent repeat attempts and/or invalid continuation. Answer the result of raising the exception."
| exception | exception := BlockCannotReturn new. exception result: result; deadHome: homeContext; pc: self previousPc. pc := nil. ^exception signalThe VM crash is now avoided. The debugger displays the method, but does not highlight the offending pc, which is no big deal. A suitable defaultHandler for B lockCannotReturn may be able to get the debugger to highlight correctly on opening. Try the following examples:
[[^1] on: BlockCannotReturn do: #resume] fork.
[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] fork
[[^1] value] fork.
They al; seem to behave perfectly acceptably to me. Does this fix work for you?
On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas mail@jaromir.net wrote:
Hi Eliot,
How about to nil the pc just before making the return:
Context >> #cannotReturn: result self push: self pc. "backup the pc for the sake of debugging" closureOrNil ifNotNil: [^self cannotReturn: result to: self home sender; pc: nil]. Processor debugWithTitle: 'Computation has been terminated!' translated full: falseThe nilled pc should not even potentially interfere with the #isDead now.
I hope this is at least a step in the right direction :)
However, there's still a problem when debugging the resumption of #cannotReturn because the encoders expect a reasonable index. I haven't figured out yet where to place a nil check - #step, #stepToSendOrReturn... ?
Thanks again, Jaromir
------ Original Message ------ From "Eliot Miranda" eliot.miranda@gmail.com To "Jaromir Matas" mail@jaromir.net Date 11/17/2023 8:36:50 PM Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On Nov 17, 2023, at 7:05 AM, Jaromir Matas mail@jaromir.net wrote:
Eliot, hi again,
Please disregard my previous comment about nilling the contexts that have returned. We are indeed talking about the context directly under the #cannotReturn context which is totally different from the home context in another thread that's gone.
I may still be confused but would nilling the pc of the context directly under the cannotReturn context help? Here's what I mean:
Context >> #cannotReturn: result closureOrNil ifNotNil: [^self pc: nil; cannotReturn: result to: self home sender]. Processor debugWithTitle: 'Computation has been terminated!' translated full: false.Instead of crashing the VM invokes the debugger with the 'Computation has been terminated!' message.
Does this make sense?
Nearly. But it loses the information on what the pc actually is, and that’s potentially vital information. So IMO the ox should only be nilled between the BlockCannotReturn exception being created and raised.
[But if you try this don’t be surprised if it causes a few temporary problems. It looks to me that without a little refactoring this could easily cause an infinite recursion around the sending of isDead. I’m sure you’ll be able to fix the code to work correctly]
Thanks, Jaromir
------ Original Message ------ From "Jaromir Matas" mail@jaromir.net To "Eliot Miranda" eliot.miranda@gmail.com; "The general-purpose Squeak developers list" squeak-dev@lists.squeakfoundation.org Date 11/17/2023 10:15:17 AM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
>Hi Eliot, > > > >------ Original Message ------ >From "Eliot Miranda" eliot.miranda@gmail.com >To "Jaromir Matas" mail@jaromir.net >Cc "The general-purpose Squeak developers list" >squeak-dev@lists.squeakfoundation.org >Date 11/16/2023 11:52:45 PM >Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn >exception > >>Hi Jaromir, >> >>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas mail@jaromir.net >>wrote: >>>Hi Nicolas, Eliot, >>> >>>here's what I understand is happening (see the enclosed >>>screenshot): >>> >>>1) we fork a new process to evaluate [^1] >>>2) the new process evaluates [^1] which means instruction 18 is >>>being evaluated, hence pc points to instruction 19 now >>>3) however, the home context where ^1 should return to is gone >>>by this time (the process that executed the fork has already >>>returned - notice the two up arrows in the debugger screenshot) >>>4) the VM can't finish the instruction and returns control to >>>the image via placing the #cannotReturn: context on top of the >>>[^1] context >>>5) #cannotReturn: evaluation results in signalling the BCR >>>exception which is then handled by the #resume handler >>> (in our debugged case the [:ex | self halt. ex resume] >>>handler) >>>6) ex resume is evaluated, however, this means requesting the >>>VM to evaluate instruction 19 of the [^1] context - which is >>>past the last instruction of the context and the crash ensues >>> >>>I wonder whether such situations could/should be prevented >>>inside the VM or whether such an expectation is wrong for some >>>reason. >> >>As Nicolas says, IMO this is best done at the image level. >> >>It could be prevented in the VM, but at great cost, and only >>partially. The performance issue is that the last bytecode in a >>method is not marked in any way, and that to determine the last >>bytecode the bytecodes must be symbolically evaluated from the >>start of the method. See implementors of endPC at the image >>level (which defer to the method trailer) and implementors of >>endPCOf: in the VMMaker code. Doing this every time execution >>commences is prohibitively expensive. The "only partially" >>issue is that following the return instruction may be other >>valid bytecodes, but these are not a continuation. >> >> >>Consider the following code in some block: >> [self expression ifTrue: >> [^1]. >> ^2 >> >>The bytecodes for this are >> pushReceiver >> send #expression >> jumpFalse L1 >> push 1 >> methodReturnTop >>L1 >> push 2 >> methodReturnTop >> >>Clearly if expression is true these should be *no* continuation >>in which ^2 is executed. > >Well, in that case there's a bug because the computation in the >following example shouldn't continue past the [^1] block but it >silently does: >`[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork` > >The bytecodes are > push true > jumpFalse L1 > push 1 > returnTop >L1 > push nil > blockReturn > > > >> >>So even if the VM did try and detect whether the return was at >>the last block method, it would only work for special cases. >> >> >>It seems to me the issue is simply that the context that cannot >>be returned from should be marked as dead (see Context>>isDead) >>by setting its pc to nil at some point, presumably after copying >>the actual return pc into the BlockCannotReturn exception, to >>avoid ever trying to resume the context. > >Does this mean, in other words, that every context that returns >should nil its pc to avoid being "wrongly" reused/executed in the >future, which concerns primarily those being referenced somewhere >hence potentially executable in the future, is that right? >Hypothetical question: would nilling the pc during returns "fix" >the example? >Thanks a lot for helping me understand this. >Best, >Jaromir > > > >> >> >>> >>>Thanks, >>>Jaromir >>> >>><bdxuqalu.png> >>> >>>------ Original Message ------ >>>From "Eliot Miranda" eliot.miranda@gmail.com >>>To "Jaromir Matas" mail@jaromir.net; "The general-purpose >>>Squeak developers list" squeak-dev@lists.squeakfoundation.org >>>Date 11/16/2023 6:48:43 PM >>>Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn >>>exception >>> >>>>Hi Jaromir, >>>> >>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas mail@jaromir.net >>>>>wrote: >>>>> >>>>> >>>>>Hi Nicloas, >>>>>No no, I don't have any practical scenario in mind, I'm just >>>>>trying to understand why the VM is implemented like this, >>>>>whether there were a reason to leave this possibility of a >>>>>crash, e.g. it would slow down the VM to try to prevent such >>>>>a dumb situation (who would resume from BCR in his right >>>>>mind? :) ) - or perhaps I have overlooked some good reason to >>>>>even keep this behavior in the VM. That's all. >>>> >>>>Let’s first understand what’s really happening. Presumably at >>>>tone point a context is resumed those pc is already at the >>>>block return bytecode (effectively, because it crashes in >>>>JITted code, but I bet the stack vm will crash also, but not >>>>as cleanly - it will try and execute the bytes in the encoded >>>>method trailer). So which method actually sends resume, and to >>>>what, and what state is resume’s receiver when resume is sent? >>>> >>>> >>>>> >>>>>Thanks for your reply. >>>>>Regards, >>>>>Jaromir >>>>> >>>>> >>>>> >>>>> >>>>>------ Original Message ------ >>>>>From "Nicolas Cellier" nicolas.cellier.aka.nice@gmail.com >>>>>To "Jaromir Matas" mail@jaromir.net; "The general-purpose >>>>>Squeak developers list" >>>>>squeak-dev@lists.squeakfoundation.org >>>>>Date 11/16/2023 7:20:20 AM >>>>>Subject Re: [squeak-dev] Resuming on BlockCannotReturn >>>>>exception >>>>> >>>>>>Hi Jaromir, >>>>>>Is there a scenario where it would make sense to resume a >>>>>>BlockCannotReturn? >>>>>>If not, I would suggest to protect at image side and >>>>>>override #resume. >>>>>> >>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas >>>>>>mail@jaromir.net a écrit : >>>>>>>Hi Eliot, Christoph, All, >>>>>>> >>>>>>>It's known the following example crashes the VM. Is this an >>>>>>>intended behavior or a "tolerated bug"? >>>>>>> >>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>>>>> >>>>>>>I understand why it crashes: the non-local return has >>>>>>>nowhere to return to and so resuming the computation leads >>>>>>>to a crash. But why not raise another BCR exception to >>>>>>>prevent the crash? Potential infinite loop? Perhaps I'm >>>>>>>just missing the purpose of this behavior... >>>>>>> >>>>>>>Thanks for an explanation. >>>>>>> >>>>>>>Best, >>>>>>>Jaromir >>>>>>> >>>>>>>-- >>>>>>> >>>>>>>Jaromir Matas >>>>>>> >>>>>>> >>>>> >> >> >>-- >>_,,,^..^,,,_ >>best, Eliot <Context-cannotReturn.st>
-- _,,,^..^,,,_ best, Eliot
<ProcessTest-testResumeAfterBCR.st>
On Thu, Nov 23, 2023 at 4:37 AM Jaromir Matas mail@jaromir.net wrote:
Hi Eliot,
There seems to be a substantial difference between the two approaches when running the enclosed test:
- In my uglier solution (see down below): If you remove the `self error`
part from #cannotReturn and run the test, one assertion fails, if you remove the `pc: nil` bit the other assertion fails and the test won't crash the system.
- If you do the same with your solution the test crashes the system when
you remove the pc := nil bit and I cant't figure out why.
As far as I understand it, nilling the pc is essential to prevent the context continuing. If the pc is not nilled then the execution machinery will resume the context after the return instruction, which is wrong, even if valid bytecodes follow the pc.
Can you understand the reason? It looks like adding the `push: #whatever` before returning from #cannotReturn:to: "fixes" your solution. Is it that the VM should do the push before returning control to the image and placing the #cannotReturn context on top of the stack?
Pushing anything onto the stack makes no sense. It is nothing to do with the return instruction, nothing to do with normal execution of a cannot return error. IMO, it should be done. Given that my solution works if the pc is nilled I don't understand what you're trying to aschieve.
Context >> cannotReturn: result to: homeContext "The receiver tried to return result to homeContext that cannot be returned from. Capture the return pc in a BlockCannotReturn. Nil the pc to prevent repeat attempts and/or invalid continuation. Answer the result of raising the exception." | exception | exception := BlockCannotReturn new. exception result: result; deadHome: homeContext; pc: self previousPc. pc := nil. self push: nil. "<-------- this helps -------"
Maybe, but it makes no sense.
^exception signal
Best, JaromirContext >> cannotReturn: result
closureOrNil ifNotNil: [^ self cannotReturn: result to: self homesender; push: pc; pc: nil]. self error: 'Computation has been terminated!'
On 21-Nov-23 6:40:32 PM, "Eliot Miranda" <eliot.miranda@gmail.com> wrote: Hi Jaromir, On Nov 20, 2023, at 11:51 PM, Jaromir Matas <mail@jaromir.net> wrote: Hi Eliot, Very elegant! Now I finally got what you meant exactly :) Thanks. Two questions: 1. in order for the enclosed test to work I'd need an Error instead of Processor debugWithTitle:full: call in #cannotReturn:. Otherwise I don't know how to catch a plain invocation of the Debugger: cannotReturn: result closureOrNil ifNotNil: [^ self cannotReturn: result to: self home sender]. self error: 'Computation has been terminated!' Much nicer. 2. We are capturing a pc of self which is completely different context from homeContext indeed. Right. The return is attempted from a specific return bytecode in a specific block. This is the coordinate of the return that cannot be made. This is the relevant point of origin of the cannot return exception. Why the return fails is another matter: - the home context’s sender is a dead context (cannot be resumed) - the home context’s sender is nil (home already returned from) - the block activation’s home is nil rather than a context (should not happen) But in all these cases the pc of the home context is immaterial. The hike is being returned through/from, rather than from; the home’s pc is not relevant. Maybe we could capture self in the exception too to make it more clear/explicit what is going on: what context the captured pc is actually associated with. Just a thought... Yes, I like that. I also like the idea of somehow passing the block activation’s pc to the debugger so that the relevant return expression is highlighted in the debugger. Thanks again, Jaromir You’re welcome. I love working in this part of the system. Thanks for dragging me there. I’m in a slump right now and appreciate the fellowship. ------ Original Message ------ From "Eliot Miranda" <eliot.miranda@gmail.com> To "Jaromir Matas" <mail@jaromir.net> Cc squeak-dev@lists.squeakfoundation.org Date 11/21/2023 2:17:21 AM Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn exception Hi Jaromir, see Kernel-eem.1535 for what I was suggesting. This example now has an exception with the right pc value in it: [[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] fork The fix is simply *Context>>cannotReturn:* result *to:* homeContext *"The receiver tried to return result to homeContext that cannot be returned from. Capture the return pc in a BlockCannotReturn. Nil the pc to prevent repeat attempts and/or invalid continuation. Answer the result of raising the exception."* | exception | exception *:=* BlockCannotReturn new. exception result: result; deadHome: homeContext; pc: self previousPc. pc *:=* nil. ^exception signal The VM crash is now avoided. The debugger displays the method, but does not highlight the offending pc, which is no big deal. A suitable defaultHandler for B lockCannotReturn may be able to get the debugger to highlight correctly on opening. Try the following examples: [[^1] on: BlockCannotReturn do: #resume] fork. [[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] fork [[^1] value] fork. They al; seem to behave perfectly acceptably to me. Does this fix work for you? On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas <mail@jaromir.net> wrote: > Hi Eliot, > > How about to nil the pc just before making the return: > ``` > Context >> #cannotReturn: result > > self push: self pc. "backup the pc for the sake of debugging" > closureOrNil ifNotNil: [^self cannotReturn: result to: self home > sender; pc: nil]. > Processor debugWithTitle: 'Computation has been terminated!' > translated full: false > ``` > The nilled pc should not even potentially interfere with the #isDead now. > > I hope this is at least a step in the right direction :) > > However, there's still a problem when debugging the resumption of > #cannotReturn because the encoders expect a reasonable index. I haven't > figured out yet where to place a nil check - #step, #stepToSendOrReturn... ? > > Thanks again, > Jaromir > > > ------ Original Message ------ > From "Eliot Miranda" <eliot.miranda@gmail.com> > To "Jaromir Matas" <mail@jaromir.net> > Date 11/17/2023 8:36:50 PM > Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception > > Hi Jaromir, > > On Nov 17, 2023, at 7:05 AM, Jaromir Matas <mail@jaromir.net> wrote: > > > Eliot, hi again, > > Please disregard my previous comment about nilling the contexts that have > returned. We are indeed talking about the context directly under the > #cannotReturn context which is totally different from the home context in > another thread that's gone. > > I may still be confused but would nilling the pc of the context directly > under the cannotReturn context help? Here's what I mean: > ``` > Context >> #cannotReturn: result > > closureOrNil ifNotNil: [^self pc: nil; cannotReturn: result to: self > home sender]. > Processor debugWithTitle: 'Computation has been terminated!' > translated full: false. > ``` > Instead of crashing the VM invokes the debugger with the 'Computation has > been terminated!' message. > > Does this make sense? > > > Nearly. But it loses the information on what the pc actually is, and > that’s potentially vital information. So IMO the ox should only be nilled > between the BlockCannotReturn exception being created and raised. > > [But if you try this don’t be surprised if it causes a few temporary > problems. It looks to me that without a little refactoring this could > easily cause an infinite recursion around the sending of isDead. I’m sure > you’ll be able to fix the code to work correctly] > > Thanks, > Jaromir > > > ------ Original Message ------ > From "Jaromir Matas" <mail@jaromir.net> > To "Eliot Miranda" <eliot.miranda@gmail.com>; "The general-purpose > Squeak developers list" <squeak-dev@lists.squeakfoundation.org> > Date 11/17/2023 10:15:17 AM > Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception > > Hi Eliot, > > > > ------ Original Message ------ > From "Eliot Miranda" <eliot.miranda@gmail.com> > To "Jaromir Matas" <mail@jaromir.net> > Cc "The general-purpose Squeak developers list" < > squeak-dev@lists.squeakfoundation.org> > Date 11/16/2023 11:52:45 PM > Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn > exception > > Hi Jaromir, > > On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas <mail@jaromir.net> wrote: > >> Hi Nicolas, Eliot, >> >> here's what I understand is happening (see the enclosed screenshot): >> >> 1) we fork a new process to evaluate [^1] >> 2) the new process evaluates [^1] which means instruction 18 is being >> evaluated, hence pc points to instruction 19 now >> 3) however, the home context where ^1 should return to is gone by this >> time (the process that executed the fork has already returned - notice the >> two up arrows in the debugger screenshot) >> 4) the VM can't finish the instruction and returns control to the image >> via placing the #cannotReturn: context on top of the [^1] context >> 5) #cannotReturn: evaluation results in signalling the BCR exception >> which is then handled by the #resume handler >> (in our debugged case the [:ex | self halt. ex resume] handler) >> 6) ex resume is evaluated, however, this means requesting the VM to >> evaluate instruction 19 of the [^1] context - which is past the last >> instruction of the context and the crash ensues >> >> I wonder whether such situations could/should be prevented inside the VM >> or whether such an expectation is wrong for some reason. >> > > As Nicolas says, IMO this is best done at the image level. > > It could be prevented in the VM, but at great cost, and only partially. > The performance issue is that the last bytecode in a method is not marked > in any way, and that to determine the last bytecode the bytecodes must be > symbolically evaluated from the start of the method. See implementors of > endPC at the image level (which defer to the method trailer) and > implementors of endPCOf: in the VMMaker code. Doing this every time > execution commences is prohibitively expensive. The "only partially" issue > is that following the return instruction may be other valid bytecodes, but > these are not a continuation. > > > Consider the following code in some block: > [self expression ifTrue: > [^1]. > ^2 > > The bytecodes for this are > pushReceiver > send #expression > jumpFalse L1 > push 1 > methodReturnTop > L1 > push 2 > methodReturnTop > > Clearly if expression is true these should be *no* continuation in which > ^2 is executed. > > > Well, in that case there's a bug because the computation in the following > example shouldn't continue past the [^1] block but it silently does: > `[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork` > > The bytecodes are > push true > jumpFalse L1 > push 1 > returnTop > L1 > push nil > blockReturn > > > > > So even if the VM did try and detect whether the return was at the last > block method, it would only work for special cases. > > > It seems to me the issue is simply that the context that cannot be > returned from should be marked as dead (see Context>>isDead) by setting its > pc to nil at some point, presumably after copying the actual return pc into > the BlockCannotReturn exception, to avoid ever trying to resume the > context. > > > Does this mean, in other words, that every context that returns should > nil its pc to avoid being "wrongly" reused/executed in the future, which > concerns primarily those being referenced somewhere hence potentially > executable in the future, is that right? > Hypothetical question: would nilling the pc during returns "fix" the > example? > Thanks a lot for helping me understand this. > Best, > Jaromir > > > > > > >> >> Thanks, >> Jaromir >> >> <bdxuqalu.png> >> >> ------ Original Message ------ >> From "Eliot Miranda" <eliot.miranda@gmail.com> >> To "Jaromir Matas" <mail@jaromir.net>; "The general-purpose Squeak >> developers list" <squeak-dev@lists.squeakfoundation.org> >> Date 11/16/2023 6:48:43 PM >> Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception >> >> Hi Jaromir, >> >> On Nov 16, 2023, at 3:23 AM, Jaromir Matas <mail@jaromir.net> wrote: >> >> >> Hi Nicloas, >> No no, I don't have any practical scenario in mind, I'm just trying to >> understand why the VM is implemented like this, whether there were a reason >> to leave this possibility of a crash, e.g. it would slow down the VM to try >> to prevent such a dumb situation (who would resume from BCR in his right >> mind? :) ) - or perhaps I have overlooked some good reason to even keep >> this behavior in the VM. That's all. >> >> >> Let’s first understand what’s really happening. Presumably at tone point >> a context is resumed those pc is already at the block return bytecode >> (effectively, because it crashes in JITted code, but I bet the stack vm >> will crash also, but not as cleanly - it will try and execute the bytes in >> the encoded method trailer). So which method actually sends resume, and to >> what, and what state is resume’s receiver when resume is sent? >> >> >> >> Thanks for your reply. >> Regards, >> Jaromir >> >> >> >> >> ------ Original Message ------ >> From "Nicolas Cellier" <nicolas.cellier.aka.nice@gmail.com> >> To "Jaromir Matas" <mail@jaromir.net>; "The general-purpose Squeak >> developers list" <squeak-dev@lists.squeakfoundation.org> >> Date 11/16/2023 7:20:20 AM >> Subject Re: [squeak-dev] Resuming on BlockCannotReturn exception >> >> Hi Jaromir, >> Is there a scenario where it would make sense to resume a >> BlockCannotReturn? >> If not, I would suggest to protect at image side and override #resume. >> >> Le mer. 15 nov. 2023, 23:42, Jaromir Matas <mail@jaromir.net> a écrit : >> >>> Hi Eliot, Christoph, All, >>> >>> It's known the following example crashes the VM. Is this an intended >>> behavior or a "tolerated bug"? >>> >>> `[[^ 1] on: BlockCannotReturn do: #resume] fork` >>> >>> I understand why it crashes: the non-local return has nowhere to return >>> to and so resuming the computation leads to a crash. But why not raise >>> another BCR exception to prevent the crash? Potential infinite loop? Perhaps >>> I'm just missing the purpose of this behavior... >>> >>> Thanks for an explanation. >>> >>> Best, >>> Jaromir >>> >>> -- >>> >>> Jaromir Matas >>> >>> >>> >> > > -- > _,,,^..^,,,_ > best, Eliot > > <Context-cannotReturn.st> > > -- _,,,^..^,,,_ best, Eliot <ProcessTest-testResumeAfterBCR.st>
Hi Eliot,
Thanks for your reply,
On 24-Nov-23 12:18:17 AM, "Eliot Miranda" eliot.miranda@gmail.com wrote:
On Thu, Nov 23, 2023 at 4:37 AM Jaromir Matas mail@jaromir.net wrote:
Hi Eliot,
There seems to be a substantial difference between the two approaches when running the enclosed test:
- In my uglier solution (see down below): If you remove the `self
error` part from #cannotReturn and run the test, one assertion fails, if you remove the `pc: nil` bit the other assertion fails and the test won't crash the system.
- If you do the same with your solution the test crashes the system
when you remove the pc := nil bit and I cant't figure out why.
As far as I understand it, nilling the pc is essential to prevent the context continuing. If the pc is not nilled then the execution machinery will resume the context after the return instruction, which is wrong, even if valid bytecodes follow the pc.
Can you understand the reason? It looks like adding the `push: #whatever` before returning from #cannotReturn:to: "fixes" your solution. Is it that the VM should do the push before returning control to the image and placing the #cannotReturn context on top of the stack?
Pushing anything onto the stack makes no sense. It is nothing to do with the return instruction, nothing to do with normal execution of a cannot return error. IMO, it should be done. Given that my solution works if the pc is nilled I don't understand what you're trying to aschieve.
Well, more than anything else I'm trying to understand; in this case why pushing something makes such a difference. Never mind, I hoped it could have been something obvious for you but if not I'll keep trying :) Thanks, J
Context >> cannotReturn: result to: homeContext "The receiver tried to return result to homeContext that cannot be returned from. Capture the return pc in a BlockCannotReturn. Nil the pc to prevent repeat attempts and/or invalid continuation. Answer the result of raising the exception." | exception | exception := BlockCannotReturn new. exception result: result; deadHome: homeContext; pc: self previousPc. pc := nil. self push: nil. "<-------- this helps -------"Maybe, but it makes no sense.
^exception signalBest, JaromirContext >> cannotReturn: result
closureOrNil ifNotNil: [^ self cannotReturn: result to: self homesender; push: pc; pc: nil]. self error: 'Computation has been terminated!'
On 21-Nov-23 6:40:32 PM, "Eliot Miranda" <eliot.miranda@gmail.com> wrote: >Hi Jaromir, > >>On Nov 20, 2023, at 11:51 PM, Jaromir Matas <mail@jaromir.net> >>wrote: >> >> >>Hi Eliot, >>Very elegant! Now I finally got what you meant exactly :) Thanks. >> >>Two questions: >>1. in order for the enclosed test to work I'd need an Error instead >>of Processor debugWithTitle:full: call in #cannotReturn:. Otherwise >>I don't know how to catch a plain invocation of the Debugger: >> >>cannotReturn: result >> >> closureOrNil ifNotNil: [^ self cannotReturn: result to: self >>home sender]. >> self error: 'Computation has been terminated!' > >Much nicer. > >>2. We are capturing a pc of self which is completely different >>context from homeContext indeed. > >Right. The return is attempted from a specific return bytecode in a >specific block. This is the coordinate of the return that cannot be >made. This is the relevant point of origin of the cannot return >exception. > >Why the return fails is another matter: >- the home context’s sender is a dead context (cannot be resumed) >- the home context’s sender is nil (home already returned from) >- the block activation’s home is nil rather than a context (should >not happen) > >But in all these cases the pc of the home context is immaterial. The >hike is being returned through/from, rather than from; the home’s pc >is not relevant. > >>Maybe we could capture self in the exception too to make it more >>clear/explicit what is going on: what context the captured pc is >>actually associated with. Just a thought... > >Yes, I like that. I also like the idea of somehow passing the block >activation’s pc to the debugger so that the relevant return >expression is highlighted in the debugger. > >> >>Thanks again, >>Jaromir > >You’re welcome. I love working in this part of the system. Thanks >for dragging me there. I’m in a slump right now and appreciate the >fellowship. > >>------ Original Message ------ >>From "Eliot Miranda" <eliot.miranda@gmail.com> >>To "Jaromir Matas" <mail@jaromir.net> >>Cc squeak-dev@lists.squeakfoundation.org >>Date 11/21/2023 2:17:21 AM >>Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn >>exception >> >>>Hi Jaromir, >>> >>> see Kernel-eem.1535 for what I was suggesting. This example now >>>has an exception with the right pc value in it: >>> >>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] >>>fork >>> >>>The fix is simply >>> >>>Context>>cannotReturn: result to: homeContext >>> "The receiver tried to return result to homeContext that cannot >>>be returned from. >>> Capture the return pc in a BlockCannotReturn. Nil the pc to >>>prevent repeat >>> attempts and/or invalid continuation. Answer the result of >>>raising the exception." >>> >>> | exception | >>> exception := BlockCannotReturn new. >>> exception >>> result: result; >>> deadHome: homeContext; >>> pc: self previousPc. >>> pc := nil. >>> ^exception signal >>> >>> >>>The VM crash is now avoided. The debugger displays the method, but >>>does not highlight the offending pc, which is no big deal. A >>>suitable defaultHandler for B lockCannotReturn may be able to get >>>the debugger to highlight correctly on opening. Try the following >>>examples: >>> >>>[[^1] on: BlockCannotReturn do: #resume] fork. >>> >>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] >>>fork >>> >>>[[^1] value] fork. >>> >>>They al; seem to behave perfectly acceptably to me. Does this fix >>>work for you? >>> >>>On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas <mail@jaromir.net> >>>wrote: >>>>Hi Eliot, >>>> >>>>How about to nil the pc just before making the return: >>>>``` >>>>Context >> #cannotReturn: result >>>> >>>> self push: self pc. "backup the pc for the sake of debugging" >>>> closureOrNil ifNotNil: [^self cannotReturn: result to: self >>>>home sender; pc: nil]. >>>> Processor debugWithTitle: 'Computation has been terminated!' >>>>translated full: false >>>>``` >>>>The nilled pc should not even potentially interfere with the >>>>#isDead now. >>>> >>>>I hope this is at least a step in the right direction :) >>>> >>>>However, there's still a problem when debugging the resumption of >>>>#cannotReturn because the encoders expect a reasonable index. I >>>>haven't figured out yet where to place a nil check - #step, >>>>#stepToSendOrReturn... ? >>>> >>>>Thanks again, >>>>Jaromir >>>> >>>> >>>>------ Original Message ------ >>>>From "Eliot Miranda" <eliot.miranda@gmail.com> >>>>To "Jaromir Matas" <mail@jaromir.net> >>>>Date 11/17/2023 8:36:50 PM >>>>Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn >>>>exception >>>> >>>>>Hi Jaromir, >>>>> >>>>>>On Nov 17, 2023, at 7:05 AM, Jaromir Matas <mail@jaromir.net> >>>>>>wrote: >>>>>> >>>>>> >>>>>>Eliot, hi again, >>>>>> >>>>>>Please disregard my previous comment about nilling the contexts >>>>>>that have returned. We are indeed talking about the context >>>>>>directly under the #cannotReturn context which is totally >>>>>>different from the home context in another thread that's gone. >>>>>> >>>>>>I may still be confused but would nilling the pc of the context >>>>>>directly under the cannotReturn context help? Here's what I >>>>>>mean: >>>>>>``` >>>>>>Context >> #cannotReturn: result >>>>>> >>>>>> closureOrNil ifNotNil: [^self pc: nil; cannotReturn: result >>>>>>to: self home sender]. >>>>>> Processor debugWithTitle: 'Computation has been terminated!' >>>>>>translated full: false. >>>>>>``` >>>>>>Instead of crashing the VM invokes the debugger with the >>>>>>'Computation has been terminated!' message. >>>>>> >>>>>>Does this make sense? >>>>> >>>>>Nearly. But it loses the information on what the pc actually is, >>>>>and that’s potentially vital information. So IMO the ox should >>>>>only be nilled between the BlockCannotReturn exception being >>>>>created and raised. >>>>> >>>>>[But if you try this don’t be surprised if it causes a few >>>>>temporary problems. It looks to me that without a little >>>>>refactoring this could easily cause an infinite recursion around >>>>>the sending of isDead. I’m sure you’ll be able to fix the code >>>>>to work correctly] >>>>> >>>>>>Thanks, >>>>>>Jaromir >>>>>> >>>>>> >>>>>>------ Original Message ------ >>>>>>From "Jaromir Matas" <mail@jaromir.net> >>>>>>To "Eliot Miranda" <eliot.miranda@gmail.com>; "The >>>>>>general-purpose Squeak developers list" >>>>>><squeak-dev@lists.squeakfoundation.org> >>>>>>Date 11/17/2023 10:15:17 AM >>>>>>Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception >>>>>> >>>>>>>Hi Eliot, >>>>>>> >>>>>>> >>>>>>> >>>>>>>------ Original Message ------ >>>>>>>From "Eliot Miranda" <eliot.miranda@gmail.com> >>>>>>>To "Jaromir Matas" <mail@jaromir.net> >>>>>>>Cc "The general-purpose Squeak developers list" >>>>>>><squeak-dev@lists.squeakfoundation.org> >>>>>>>Date 11/16/2023 11:52:45 PM >>>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on >>>>>>>BlockCannotReturn exception >>>>>>> >>>>>>>>Hi Jaromir, >>>>>>>> >>>>>>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas >>>>>>>><mail@jaromir.net> wrote: >>>>>>>>>Hi Nicolas, Eliot, >>>>>>>>> >>>>>>>>>here's what I understand is happening (see the enclosed >>>>>>>>>screenshot): >>>>>>>>> >>>>>>>>>1) we fork a new process to evaluate [^1] >>>>>>>>>2) the new process evaluates [^1] which means instruction 18 >>>>>>>>>is being evaluated, hence pc points to instruction 19 now >>>>>>>>>3) however, the home context where ^1 should return to is >>>>>>>>>gone by this time (the process that executed the fork has >>>>>>>>>already returned - notice the two up arrows in the debugger >>>>>>>>>screenshot) >>>>>>>>>4) the VM can't finish the instruction and returns control to >>>>>>>>>the image via placing the #cannotReturn: context on top of >>>>>>>>>the [^1] context >>>>>>>>>5) #cannotReturn: evaluation results in signalling the BCR >>>>>>>>>exception which is then handled by the #resume handler >>>>>>>>> (in our debugged case the [:ex | self halt. ex resume] >>>>>>>>>handler) >>>>>>>>>6) ex resume is evaluated, however, this means requesting the >>>>>>>>>VM to evaluate instruction 19 of the [^1] context - which is >>>>>>>>>past the last instruction of the context and the crash ensues >>>>>>>>> >>>>>>>>>I wonder whether such situations could/should be prevented >>>>>>>>>inside the VM or whether such an expectation is wrong for >>>>>>>>>some reason. >>>>>>>> >>>>>>>>As Nicolas says, IMO this is best done at the image level. >>>>>>>> >>>>>>>>It could be prevented in the VM, but at great cost, and only >>>>>>>>partially. The performance issue is that the last bytecode in >>>>>>>>a method is not marked in any way, and that to determine the >>>>>>>>last bytecode the bytecodes must be symbolically evaluated >>>>>>>>from the start of the method. See implementors of endPC at >>>>>>>>the image level (which defer to the method trailer) and >>>>>>>>implementors of endPCOf: in the VMMaker code. Doing this every >>>>>>>>time execution commences is prohibitively expensive. The >>>>>>>>"only partially" issue is that following the return >>>>>>>>instruction may be other valid bytecodes, but these are not a >>>>>>>>continuation. >>>>>>>> >>>>>>>> >>>>>>>>Consider the following code in some block: >>>>>>>> [self expression ifTrue: >>>>>>>> [^1]. >>>>>>>> ^2 >>>>>>>> >>>>>>>>The bytecodes for this are >>>>>>>> pushReceiver >>>>>>>> send #expression >>>>>>>> jumpFalse L1 >>>>>>>> push 1 >>>>>>>> methodReturnTop >>>>>>>>L1 >>>>>>>> push 2 >>>>>>>> methodReturnTop >>>>>>>> >>>>>>>>Clearly if expression is true these should be *no* >>>>>>>>continuation in which ^2 is executed. >>>>>>> >>>>>>>Well, in that case there's a bug because the computation in the >>>>>>>following example shouldn't continue past the [^1] block but it >>>>>>>silently does: >>>>>>>`[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] >>>>>>>fork` >>>>>>> >>>>>>>The bytecodes are >>>>>>> push true >>>>>>> jumpFalse L1 >>>>>>> push 1 >>>>>>> returnTop >>>>>>>L1 >>>>>>> push nil >>>>>>> blockReturn >>>>>>> >>>>>>> >>>>>>> >>>>>>>> >>>>>>>>So even if the VM did try and detect whether the return was at >>>>>>>>the last block method, it would only work for special cases. >>>>>>>> >>>>>>>> >>>>>>>>It seems to me the issue is simply that the context that >>>>>>>>cannot be returned from should be marked as dead (see >>>>>>>>Context>>isDead) by setting its pc to nil at some point, >>>>>>>>presumably after copying the actual return pc into the >>>>>>>>BlockCannotReturn exception, to avoid ever trying to resume >>>>>>>>the context. >>>>>>> >>>>>>>Does this mean, in other words, that every context that returns >>>>>>>should nil its pc to avoid being "wrongly" reused/executed in >>>>>>>the future, which concerns primarily those being referenced >>>>>>>somewhere hence potentially executable in the future, is that >>>>>>>right? >>>>>>>Hypothetical question: would nilling the pc during returns >>>>>>>"fix" the example? >>>>>>>Thanks a lot for helping me understand this. >>>>>>>Best, >>>>>>>Jaromir >>>>>>> >>>>>>> >>>>>>> >>>>>>>> >>>>>>>> >>>>>>>>> >>>>>>>>>Thanks, >>>>>>>>>Jaromir >>>>>>>>> >>>>>>>>><bdxuqalu.png> >>>>>>>>> >>>>>>>>>------ Original Message ------ >>>>>>>>>From "Eliot Miranda" <eliot.miranda@gmail.com> >>>>>>>>>To "Jaromir Matas" <mail@jaromir.net>; "The general-purpose >>>>>>>>>Squeak developers list" >>>>>>>>><squeak-dev@lists.squeakfoundation.org> >>>>>>>>>Date 11/16/2023 6:48:43 PM >>>>>>>>>Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn >>>>>>>>>exception >>>>>>>>> >>>>>>>>>>Hi Jaromir, >>>>>>>>>> >>>>>>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas >>>>>>>>>>><mail@jaromir.net> wrote: >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>Hi Nicloas, >>>>>>>>>>>No no, I don't have any practical scenario in mind, I'm >>>>>>>>>>>just trying to understand why the VM is implemented like >>>>>>>>>>>this, whether there were a reason to leave this possibility >>>>>>>>>>>of a crash, e.g. it would slow down the VM to try to >>>>>>>>>>>prevent such a dumb situation (who would resume from BCR in >>>>>>>>>>>his right mind? :) ) - or perhaps I have overlooked some >>>>>>>>>>>good reason to even keep this behavior in the VM. That's >>>>>>>>>>>all. >>>>>>>>>> >>>>>>>>>>Let’s first understand what’s really happening. Presumably >>>>>>>>>>at tone point a context is resumed those pc is already at >>>>>>>>>>the block return bytecode (effectively, because it crashes >>>>>>>>>>in JITted code, but I bet the stack vm will crash also, but >>>>>>>>>>not as cleanly - it will try and execute the bytes in the >>>>>>>>>>encoded method trailer). So which method actually sends >>>>>>>>>>resume, and to what, and what state is resume’s receiver >>>>>>>>>>when resume is sent? >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>Thanks for your reply. >>>>>>>>>>>Regards, >>>>>>>>>>>Jaromir >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>------ Original Message ------ >>>>>>>>>>>From "Nicolas Cellier" <nicolas.cellier.aka.nice@gmail.com> >>>>>>>>>>>To "Jaromir Matas" <mail@jaromir.net>; "The general-purpose >>>>>>>>>>>Squeak developers list" >>>>>>>>>>><squeak-dev@lists.squeakfoundation.org> >>>>>>>>>>>Date 11/16/2023 7:20:20 AM >>>>>>>>>>>Subject Re: [squeak-dev] Resuming on BlockCannotReturn >>>>>>>>>>>exception >>>>>>>>>>> >>>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>>Is there a scenario where it would make sense to resume a >>>>>>>>>>>>BlockCannotReturn? >>>>>>>>>>>>If not, I would suggest to protect at image side and >>>>>>>>>>>>override #resume. >>>>>>>>>>>> >>>>>>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas >>>>>>>>>>>><mail@jaromir.net> a écrit : >>>>>>>>>>>>>Hi Eliot, Christoph, All, >>>>>>>>>>>>> >>>>>>>>>>>>>It's known the following example crashes the VM. Is this >>>>>>>>>>>>>an intended behavior or a "tolerated bug"? >>>>>>>>>>>>> >>>>>>>>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>>>>>>>>>>> >>>>>>>>>>>>>I understand why it crashes: the non-local return has >>>>>>>>>>>>>nowhere to return to and so resuming the computation >>>>>>>>>>>>>leads to a crash. But why not raise another BCR exception >>>>>>>>>>>>>to prevent the crash? Potential infinite loop? Perhaps >>>>>>>>>>>>>I'm just missing the purpose of this behavior... >>>>>>>>>>>>> >>>>>>>>>>>>>Thanks for an explanation. >>>>>>>>>>>>> >>>>>>>>>>>>>Best, >>>>>>>>>>>>>Jaromir >>>>>>>>>>>>> >>>>>>>>>>>>>-- >>>>>>>>>>>>> >>>>>>>>>>>>>Jaromir Matas >>>>>>>>>>>>> >>>>>>>>>>>>> >>>>>>>>>>> >>>>>>>> >>>>>>>> >>>>>>>>-- >>>>>>>>_,,,^..^,,,_ >>>>>>>>best, Eliot >>>>>><Context-cannotReturn.st> >>> >>> >>>-- >>>_,,,^..^,,,_ >>>best, Eliot >><ProcessTest-testResumeAfterBCR.st>-- _,,,^..^,,,_ best, Eliot
On Thu, Nov 23, 2023 at 3:46 PM Jaromir Matas mail@jaromir.net wrote:
Hi Eliot,
Thanks for your reply,
On 24-Nov-23 12:18:17 AM, "Eliot Miranda" eliot.miranda@gmail.com wrote:
On Thu, Nov 23, 2023 at 4:37 AM Jaromir Matas mail@jaromir.net wrote:
Hi Eliot,
There seems to be a substantial difference between the two approaches when running the enclosed test:
- In my uglier solution (see down below): If you remove the `self error`
part from #cannotReturn and run the test, one assertion fails, if you remove the `pc: nil` bit the other assertion fails and the test won't crash the system.
- If you do the same with your solution the test crashes the system when
you remove the pc := nil bit and I cant't figure out why.
As far as I understand it, nilling the pc is essential to prevent the context continuing. If the pc is not nilled then the execution machinery will resume the context after the return instruction, which is wrong, even if valid bytecodes follow the pc.
Can you understand the reason? It looks like adding the `push: #whatever` before returning from #cannotReturn:to: "fixes" your solution. Is it that the VM should do the push before returning control to the image and placing the #cannotReturn context on top of the stack?
Pushing anything onto the stack makes no sense. It is nothing to do with the return instruction, nothing to do with normal execution of a cannot return error. IMO, it should be done. Given that my solution works if the pc is nilled I don't understand what you're trying to aschieve.
Well, more than anything else I'm trying to understand; in this case why pushing something makes such a difference. Never mind, I hoped it could have been something obvious for you but if not I'll keep trying :)
Depending on the specific return bytecode, the top of stack might be popped before the cannotReturn:. So the stack pointer may be cut back to a zero or negative value.
Thanks,
J
Context >> cannotReturn: result to: homeContext "The receiver tried to return result to homeContext that cannot be returned from. Capture the return pc in a BlockCannotReturn. Nil the pc to prevent repeat attempts and/or invalid continuation. Answer the result of raising the exception." | exception | exception := BlockCannotReturn new. exception result: result; deadHome: homeContext; pc: self previousPc. pc := nil. self push: nil. "<-------- this helps -------"Maybe, but it makes no sense.
^exception signalBest, JaromirContext >> cannotReturn: result
closureOrNil ifNotNil: [^ self cannotReturn: result to: self homesender; push: pc; pc: nil]. self error: 'Computation has been terminated!'
On 21-Nov-23 6:40:32 PM, "Eliot Miranda" <eliot.miranda@gmail.com> wrote: Hi Jaromir, On Nov 20, 2023, at 11:51 PM, Jaromir Matas <mail@jaromir.net> wrote: Hi Eliot, Very elegant! Now I finally got what you meant exactly :) Thanks. Two questions: 1. in order for the enclosed test to work I'd need an Error instead of Processor debugWithTitle:full: call in #cannotReturn:. Otherwise I don't know how to catch a plain invocation of the Debugger: cannotReturn: result closureOrNil ifNotNil: [^ self cannotReturn: result to: self home sender]. self error: 'Computation has been terminated!' Much nicer. 2. We are capturing a pc of self which is completely different context from homeContext indeed. Right. The return is attempted from a specific return bytecode in a specific block. This is the coordinate of the return that cannot be made. This is the relevant point of origin of the cannot return exception. Why the return fails is another matter: - the home context’s sender is a dead context (cannot be resumed) - the home context’s sender is nil (home already returned from) - the block activation’s home is nil rather than a context (should not happen) But in all these cases the pc of the home context is immaterial. The hike is being returned through/from, rather than from; the home’s pc is not relevant. Maybe we could capture self in the exception too to make it more clear/explicit what is going on: what context the captured pc is actually associated with. Just a thought... Yes, I like that. I also like the idea of somehow passing the block activation’s pc to the debugger so that the relevant return expression is highlighted in the debugger. Thanks again, Jaromir You’re welcome. I love working in this part of the system. Thanks for dragging me there. I’m in a slump right now and appreciate the fellowship. ------ Original Message ------ From "Eliot Miranda" <eliot.miranda@gmail.com> To "Jaromir Matas" <mail@jaromir.net> Cc squeak-dev@lists.squeakfoundation.org Date 11/21/2023 2:17:21 AM Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn exception Hi Jaromir, see Kernel-eem.1535 for what I was suggesting. This example now has an exception with the right pc value in it: [[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] fork The fix is simply *Context>>cannotReturn:* result *to:* homeContext *"The receiver tried to return result to homeContext that cannot be returned from. Capture the return pc in a BlockCannotReturn. Nil the pc to prevent repeat attempts and/or invalid continuation. Answer the result of raising the exception."* | exception | exception *:=* BlockCannotReturn new. exception result: result; deadHome: homeContext; pc: self previousPc. pc *:=* nil. ^exception signal The VM crash is now avoided. The debugger displays the method, but does not highlight the offending pc, which is no big deal. A suitable defaultHandler for B lockCannotReturn may be able to get the debugger to highlight correctly on opening. Try the following examples: [[^1] on: BlockCannotReturn do: #resume] fork. [[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] fork [[^1] value] fork. They al; seem to behave perfectly acceptably to me. Does this fix work for you? On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas <mail@jaromir.net> wrote: > Hi Eliot, > > How about to nil the pc just before making the return: > ``` > Context >> #cannotReturn: result > > self push: self pc. "backup the pc for the sake of debugging" > closureOrNil ifNotNil: [^self cannotReturn: result to: self home > sender; pc: nil]. > Processor debugWithTitle: 'Computation has been terminated!' > translated full: false > ``` > The nilled pc should not even potentially interfere with the #isDead now. > > I hope this is at least a step in the right direction :) > > However, there's still a problem when debugging the resumption of > #cannotReturn because the encoders expect a reasonable index. I haven't > figured out yet where to place a nil check - #step, #stepToSendOrReturn... ? > > Thanks again, > Jaromir > > > ------ Original Message ------ > From "Eliot Miranda" <eliot.miranda@gmail.com> > To "Jaromir Matas" <mail@jaromir.net> > Date 11/17/2023 8:36:50 PM > Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception > > Hi Jaromir, > > On Nov 17, 2023, at 7:05 AM, Jaromir Matas <mail@jaromir.net> wrote: > > > Eliot, hi again, > > Please disregard my previous comment about nilling the contexts that > have returned. We are indeed talking about the context directly under the > #cannotReturn context which is totally different from the home context in > another thread that's gone. > > I may still be confused but would nilling the pc of the context directly > under the cannotReturn context help? Here's what I mean: > ``` > Context >> #cannotReturn: result > > closureOrNil ifNotNil: [^self pc: nil; cannotReturn: result to: self > home sender]. > Processor debugWithTitle: 'Computation has been terminated!' > translated full: false. > ``` > Instead of crashing the VM invokes the debugger with the 'Computation > has been terminated!' message. > > Does this make sense? > > > Nearly. But it loses the information on what the pc actually is, and > that’s potentially vital information. So IMO the ox should only be nilled > between the BlockCannotReturn exception being created and raised. > > [But if you try this don’t be surprised if it causes a few temporary > problems. It looks to me that without a little refactoring this could > easily cause an infinite recursion around the sending of isDead. I’m sure > you’ll be able to fix the code to work correctly] > > Thanks, > Jaromir > > > ------ Original Message ------ > From "Jaromir Matas" <mail@jaromir.net> > To "Eliot Miranda" <eliot.miranda@gmail.com>; "The general-purpose > Squeak developers list" <squeak-dev@lists.squeakfoundation.org> > Date 11/17/2023 10:15:17 AM > Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception > > Hi Eliot, > > > > ------ Original Message ------ > From "Eliot Miranda" <eliot.miranda@gmail.com> > To "Jaromir Matas" <mail@jaromir.net> > Cc "The general-purpose Squeak developers list" < > squeak-dev@lists.squeakfoundation.org> > Date 11/16/2023 11:52:45 PM > Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn > exception > > Hi Jaromir, > > On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas <mail@jaromir.net> wrote: > >> Hi Nicolas, Eliot, >> >> here's what I understand is happening (see the enclosed screenshot): >> >> 1) we fork a new process to evaluate [^1] >> 2) the new process evaluates [^1] which means instruction 18 is being >> evaluated, hence pc points to instruction 19 now >> 3) however, the home context where ^1 should return to is gone by this >> time (the process that executed the fork has already returned - notice the >> two up arrows in the debugger screenshot) >> 4) the VM can't finish the instruction and returns control to the image >> via placing the #cannotReturn: context on top of the [^1] context >> 5) #cannotReturn: evaluation results in signalling the BCR exception >> which is then handled by the #resume handler >> (in our debugged case the [:ex | self halt. ex resume] handler) >> 6) ex resume is evaluated, however, this means requesting the VM to >> evaluate instruction 19 of the [^1] context - which is past the last >> instruction of the context and the crash ensues >> >> I wonder whether such situations could/should be prevented inside the >> VM or whether such an expectation is wrong for some reason. >> > > As Nicolas says, IMO this is best done at the image level. > > It could be prevented in the VM, but at great cost, and only partially. > The performance issue is that the last bytecode in a method is not marked > in any way, and that to determine the last bytecode the bytecodes must be > symbolically evaluated from the start of the method. See implementors of > endPC at the image level (which defer to the method trailer) and > implementors of endPCOf: in the VMMaker code. Doing this every time > execution commences is prohibitively expensive. The "only partially" issue > is that following the return instruction may be other valid bytecodes, but > these are not a continuation. > > > Consider the following code in some block: > [self expression ifTrue: > [^1]. > ^2 > > The bytecodes for this are > pushReceiver > send #expression > jumpFalse L1 > push 1 > methodReturnTop > L1 > push 2 > methodReturnTop > > Clearly if expression is true these should be *no* continuation in which > ^2 is executed. > > > Well, in that case there's a bug because the computation in the > following example shouldn't continue past the [^1] block but it silently > does: > `[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork` > > The bytecodes are > push true > jumpFalse L1 > push 1 > returnTop > L1 > push nil > blockReturn > > > > > So even if the VM did try and detect whether the return was at the last > block method, it would only work for special cases. > > > It seems to me the issue is simply that the context that cannot be > returned from should be marked as dead (see Context>>isDead) by setting its > pc to nil at some point, presumably after copying the actual return pc into > the BlockCannotReturn exception, to avoid ever trying to resume the > context. > > > Does this mean, in other words, that every context that returns should > nil its pc to avoid being "wrongly" reused/executed in the future, which > concerns primarily those being referenced somewhere hence potentially > executable in the future, is that right? > Hypothetical question: would nilling the pc during returns "fix" the > example? > Thanks a lot for helping me understand this. > Best, > Jaromir > > > > > > >> >> Thanks, >> Jaromir >> >> <bdxuqalu.png> >> >> ------ Original Message ------ >> From "Eliot Miranda" <eliot.miranda@gmail.com> >> To "Jaromir Matas" <mail@jaromir.net>; "The general-purpose Squeak >> developers list" <squeak-dev@lists.squeakfoundation.org> >> Date 11/16/2023 6:48:43 PM >> Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception >> >> Hi Jaromir, >> >> On Nov 16, 2023, at 3:23 AM, Jaromir Matas <mail@jaromir.net> wrote: >> >> >> Hi Nicloas, >> No no, I don't have any practical scenario in mind, I'm just trying to >> understand why the VM is implemented like this, whether there were a reason >> to leave this possibility of a crash, e.g. it would slow down the VM to try >> to prevent such a dumb situation (who would resume from BCR in his right >> mind? :) ) - or perhaps I have overlooked some good reason to even keep >> this behavior in the VM. That's all. >> >> >> Let’s first understand what’s really happening. Presumably at tone >> point a context is resumed those pc is already at the block return bytecode >> (effectively, because it crashes in JITted code, but I bet the stack vm >> will crash also, but not as cleanly - it will try and execute the bytes in >> the encoded method trailer). So which method actually sends resume, and to >> what, and what state is resume’s receiver when resume is sent? >> >> >> >> Thanks for your reply. >> Regards, >> Jaromir >> >> >> >> >> ------ Original Message ------ >> From "Nicolas Cellier" <nicolas.cellier.aka.nice@gmail.com> >> To "Jaromir Matas" <mail@jaromir.net>; "The general-purpose Squeak >> developers list" <squeak-dev@lists.squeakfoundation.org> >> Date 11/16/2023 7:20:20 AM >> Subject Re: [squeak-dev] Resuming on BlockCannotReturn exception >> >> Hi Jaromir, >> Is there a scenario where it would make sense to resume a >> BlockCannotReturn? >> If not, I would suggest to protect at image side and override #resume. >> >> Le mer. 15 nov. 2023, 23:42, Jaromir Matas <mail@jaromir.net> a écrit : >> >>> Hi Eliot, Christoph, All, >>> >>> It's known the following example crashes the VM. Is this an intended >>> behavior or a "tolerated bug"? >>> >>> `[[^ 1] on: BlockCannotReturn do: #resume] fork` >>> >>> I understand why it crashes: the non-local return has nowhere to >>> return to and so resuming the computation leads to a crash. But why not >>> raise another BCR exception to prevent the crash? Potential infinite loop? Perhaps >>> I'm just missing the purpose of this behavior... >>> >>> Thanks for an explanation. >>> >>> Best, >>> Jaromir >>> >>> -- >>> >>> Jaromir Matas >>> >>> >>> >> > > -- > _,,,^..^,,,_ > best, Eliot > > <Context-cannotReturn.st> > > -- _,,,^..^,,,_ best, Eliot <ProcessTest-testResumeAfterBCR.st>-- _,,,^..^,,,_ best, Eliot
Hi Eliot, I guess I figured it out...
On 24-Nov-23 4:49:14 AM, "Eliot Miranda" eliot.miranda@gmail.com wrote:
On Thu, Nov 23, 2023 at 3:46 PM Jaromir Matas mail@jaromir.net wrote:
On 24-Nov-23 12:18:17 AM, "Eliot Miranda" eliot.miranda@gmail.com wrote:
On Thu, Nov 23, 2023 at 4:37 AM Jaromir Matas mail@jaromir.net wrote:
Hi Eliot,
There seems to be a substantial difference between the two approaches when running the enclosed test:
- In my uglier solution (see down below): If you remove the `self
error` part from #cannotReturn and run the test, one assertion fails, if you remove the `pc: nil` bit the other assertion fails and the test won't crash the system.
- If you do the same with your solution the test crashes the system
when you remove the pc := nil bit and I cant't figure out why.
As far as I understand it, nilling the pc is essential to prevent the context continuing. If the pc is not nilled then the execution machinery will resume the context after the return instruction, which is wrong, even if valid bytecodes follow the pc.
Can you understand the reason? It looks like adding the `push: #whatever` before returning from #cannotReturn:to: "fixes" your solution. Is it that the VM should do the push before returning control to the image and placing the #cannotReturn context on top of the stack?
Pushing anything onto the stack makes no sense. It is nothing to do with the return instruction, nothing to do with normal execution of a cannot return error. IMO, it should be done. Given that my solution works if the pc is nilled I don't understand what you're trying to aschieve.
Well, more than anything else I'm trying to understand; in this case why pushing something makes such a difference. Never mind, I hoped it could have been something obvious for you but if not I'll keep trying :)
Depending on the specific return bytecode, the top of stack might be popped before the cannotReturn:. So the stack pointer may be cut back to a zero or negative value.
Yes, that's my guess what's happening; the VM pops a context with stackp zero and it leads to a crash. If I push something to the stack the crash doesn't happen. I included an extra push in the BCR test KernelTests-jar.447 to prevent the crash if someone tries the test on an older image (it's fun seeing it really prevents the crash). So your solution is flawless indeed, and I have just accidentally stumbled upon this VM behavior which looks like popping an empty stack causing the crash; if this is really so, would that be a VM bug? I've sent a BCR resumption test and a modified #cannotReturn: to the Inbox (KernelTests-jar.447 and Kernel-jar.1537). I wonder if someone could kindly merge them if you're ok with them. I'd also like suggest adding the final context that caused the BCR to the exception - see the enclosed changeset.
Thanks for your feedback. Best, Jaromir
Thanks, J
Context >> cannotReturn: result to: homeContext "The receiver tried to return result to homeContext that cannot be returned from. Capture the return pc in a BlockCannotReturn. Nil the pc to prevent repeat attempts and/or invalid continuation. Answer the result of raising the exception." | exception | exception := BlockCannotReturn new. exception result: result; deadHome: homeContext; pc: self previousPc. pc := nil. self push: nil. "<-------- this helps -------"Maybe, but it makes no sense.
^exception signalBest, JaromirContext >> cannotReturn: result
closureOrNil ifNotNil: [^ self cannotReturn: result to: selfhome sender; push: pc; pc: nil]. self error: 'Computation has been terminated!'
On 21-Nov-23 6:40:32 PM, "Eliot Miranda" <eliot.miranda@gmail.com> wrote: >Hi Jaromir, > >>On Nov 20, 2023, at 11:51 PM, Jaromir Matas <mail@jaromir.net> >>wrote: >> >> >>Hi Eliot, >>Very elegant! Now I finally got what you meant exactly :) Thanks. >> >>Two questions: >>1. in order for the enclosed test to work I'd need an Error >>instead of Processor debugWithTitle:full: call in #cannotReturn:. >>Otherwise I don't know how to catch a plain invocation of the >>Debugger: >> >>cannotReturn: result >> >> closureOrNil ifNotNil: [^ self cannotReturn: result to: self >>home sender]. >> self error: 'Computation has been terminated!' > >Much nicer. > >>2. We are capturing a pc of self which is completely different >>context from homeContext indeed. > >Right. The return is attempted from a specific return bytecode in a >specific block. This is the coordinate of the return that cannot be >made. This is the relevant point of origin of the cannot return >exception. > >Why the return fails is another matter: >- the home context’s sender is a dead context (cannot be resumed) >- the home context’s sender is nil (home already returned from) >- the block activation’s home is nil rather than a context (should >not happen) > >But in all these cases the pc of the home context is immaterial. >The hike is being returned through/from, rather than from; the >home’s pc is not relevant. > >>Maybe we could capture self in the exception too to make it more >>clear/explicit what is going on: what context the captured pc is >>actually associated with. Just a thought... > >Yes, I like that. I also like the idea of somehow passing the >block activation’s pc to the debugger so that the relevant return >expression is highlighted in the debugger. > >> >>Thanks again, >>Jaromir > >You’re welcome. I love working in this part of the system. Thanks >for dragging me there. I’m in a slump right now and appreciate the >fellowship. > >>------ Original Message ------ >>From "Eliot Miranda" <eliot.miranda@gmail.com> >>To "Jaromir Matas" <mail@jaromir.net> >>Cc squeak-dev@lists.squeakfoundation.org >>Date 11/21/2023 2:17:21 AM >>Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn >>exception >> >>>Hi Jaromir, >>> >>> see Kernel-eem.1535 for what I was suggesting. This example >>>now has an exception with the right pc value in it: >>> >>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] >>>fork >>> >>>The fix is simply >>> >>>Context>>cannotReturn: result to: homeContext >>> "The receiver tried to return result to homeContext that >>>cannot be returned from. >>> Capture the return pc in a BlockCannotReturn. Nil the pc to >>>prevent repeat >>> attempts and/or invalid continuation. Answer the result of >>>raising the exception." >>> >>> | exception | >>> exception := BlockCannotReturn new. >>> exception >>> result: result; >>> deadHome: homeContext; >>> pc: self previousPc. >>> pc := nil. >>> ^exception signal >>> >>> >>>The VM crash is now avoided. The debugger displays the method, >>>but does not highlight the offending pc, which is no big deal. A >>>suitable defaultHandler for B lockCannotReturn may be able to get >>>the debugger to highlight correctly on opening. Try the >>>following examples: >>> >>>[[^1] on: BlockCannotReturn do: #resume] fork. >>> >>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] >>>fork >>> >>>[[^1] value] fork. >>> >>>They al; seem to behave perfectly acceptably to me. Does this >>>fix work for you? >>> >>>On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas <mail@jaromir.net> >>>wrote: >>>>Hi Eliot, >>>> >>>>How about to nil the pc just before making the return: >>>>``` >>>>Context >> #cannotReturn: result >>>> >>>> self push: self pc. "backup the pc for the sake of >>>>debugging" >>>> closureOrNil ifNotNil: [^self cannotReturn: result to: self >>>>home sender; pc: nil]. >>>> Processor debugWithTitle: 'Computation has been terminated!' >>>>translated full: false >>>>``` >>>>The nilled pc should not even potentially interfere with the >>>>#isDead now. >>>> >>>>I hope this is at least a step in the right direction :) >>>> >>>>However, there's still a problem when debugging the resumption >>>>of #cannotReturn because the encoders expect a reasonable index. >>>>I haven't figured out yet where to place a nil check - #step, >>>>#stepToSendOrReturn... ? >>>> >>>>Thanks again, >>>>Jaromir >>>> >>>> >>>>------ Original Message ------ >>>>From "Eliot Miranda" <eliot.miranda@gmail.com> >>>>To "Jaromir Matas" <mail@jaromir.net> >>>>Date 11/17/2023 8:36:50 PM >>>>Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn >>>>exception >>>> >>>>>Hi Jaromir, >>>>> >>>>>>On Nov 17, 2023, at 7:05 AM, Jaromir Matas <mail@jaromir.net> >>>>>>wrote: >>>>>> >>>>>> >>>>>>Eliot, hi again, >>>>>> >>>>>>Please disregard my previous comment about nilling the >>>>>>contexts that have returned. We are indeed talking about the >>>>>>context directly under the #cannotReturn context which is >>>>>>totally different from the home context in another thread >>>>>>that's gone. >>>>>> >>>>>>I may still be confused but would nilling the pc of the >>>>>>context directly under the cannotReturn context help? Here's >>>>>>what I mean: >>>>>>``` >>>>>>Context >> #cannotReturn: result >>>>>> >>>>>> closureOrNil ifNotNil: [^self pc: nil; cannotReturn: >>>>>>result to: self home sender]. >>>>>> Processor debugWithTitle: 'Computation has been >>>>>>terminated!' translated full: false. >>>>>>``` >>>>>>Instead of crashing the VM invokes the debugger with the >>>>>>'Computation has been terminated!' message. >>>>>> >>>>>>Does this make sense? >>>>> >>>>>Nearly. But it loses the information on what the pc actually >>>>>is, and that’s potentially vital information. So IMO the ox >>>>>should only be nilled between the BlockCannotReturn exception >>>>>being created and raised. >>>>> >>>>>[But if you try this don’t be surprised if it causes a few >>>>>temporary problems. It looks to me that without a little >>>>>refactoring this could easily cause an infinite recursion >>>>>around the sending of isDead. I’m sure you’ll be able to fix >>>>>the code to work correctly] >>>>> >>>>>>Thanks, >>>>>>Jaromir >>>>>> >>>>>> >>>>>>------ Original Message ------ >>>>>>From "Jaromir Matas" <mail@jaromir.net> >>>>>>To "Eliot Miranda" <eliot.miranda@gmail.com>; "The >>>>>>general-purpose Squeak developers list" >>>>>><squeak-dev@lists.squeakfoundation.org> >>>>>>Date 11/17/2023 10:15:17 AM >>>>>>Subject [squeak-dev] Re: Resuming on BlockCannotReturn >>>>>>exception >>>>>> >>>>>>>Hi Eliot, >>>>>>> >>>>>>> >>>>>>> >>>>>>>------ Original Message ------ >>>>>>>From "Eliot Miranda" <eliot.miranda@gmail.com> >>>>>>>To "Jaromir Matas" <mail@jaromir.net> >>>>>>>Cc "The general-purpose Squeak developers list" >>>>>>><squeak-dev@lists.squeakfoundation.org> >>>>>>>Date 11/16/2023 11:52:45 PM >>>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on >>>>>>>BlockCannotReturn exception >>>>>>> >>>>>>>>Hi Jaromir, >>>>>>>> >>>>>>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas >>>>>>>><mail@jaromir.net> wrote: >>>>>>>>>Hi Nicolas, Eliot, >>>>>>>>> >>>>>>>>>here's what I understand is happening (see the enclosed >>>>>>>>>screenshot): >>>>>>>>> >>>>>>>>>1) we fork a new process to evaluate [^1] >>>>>>>>>2) the new process evaluates [^1] which means instruction >>>>>>>>>18 is being evaluated, hence pc points to instruction 19 >>>>>>>>>now >>>>>>>>>3) however, the home context where ^1 should return to is >>>>>>>>>gone by this time (the process that executed the fork has >>>>>>>>>already returned - notice the two up arrows in the debugger >>>>>>>>>screenshot) >>>>>>>>>4) the VM can't finish the instruction and returns control >>>>>>>>>to the image via placing the #cannotReturn: context on top >>>>>>>>>of the [^1] context >>>>>>>>>5) #cannotReturn: evaluation results in signalling the BCR >>>>>>>>>exception which is then handled by the #resume handler >>>>>>>>> (in our debugged case the [:ex | self halt. ex resume] >>>>>>>>>handler) >>>>>>>>>6) ex resume is evaluated, however, this means requesting >>>>>>>>>the VM to evaluate instruction 19 of the [^1] context - >>>>>>>>>which is past the last instruction of the context and the >>>>>>>>>crash ensues >>>>>>>>> >>>>>>>>>I wonder whether such situations could/should be prevented >>>>>>>>>inside the VM or whether such an expectation is wrong for >>>>>>>>>some reason. >>>>>>>> >>>>>>>>As Nicolas says, IMO this is best done at the image level. >>>>>>>> >>>>>>>>It could be prevented in the VM, but at great cost, and only >>>>>>>>partially. The performance issue is that the last bytecode >>>>>>>>in a method is not marked in any way, and that to determine >>>>>>>>the last bytecode the bytecodes must be symbolically >>>>>>>>evaluated from the start of the method. See implementors of >>>>>>>>endPC at the image level (which defer to the method trailer) >>>>>>>>and implementors of endPCOf: in the VMMaker code. Doing this >>>>>>>>every time execution commences is prohibitively expensive. >>>>>>>>The "only partially" issue is that following the return >>>>>>>>instruction may be other valid bytecodes, but these are not >>>>>>>>a continuation. >>>>>>>> >>>>>>>> >>>>>>>>Consider the following code in some block: >>>>>>>> [self expression ifTrue: >>>>>>>> [^1]. >>>>>>>> ^2 >>>>>>>> >>>>>>>>The bytecodes for this are >>>>>>>> pushReceiver >>>>>>>> send #expression >>>>>>>> jumpFalse L1 >>>>>>>> push 1 >>>>>>>> methodReturnTop >>>>>>>>L1 >>>>>>>> push 2 >>>>>>>> methodReturnTop >>>>>>>> >>>>>>>>Clearly if expression is true these should be *no* >>>>>>>>continuation in which ^2 is executed. >>>>>>> >>>>>>>Well, in that case there's a bug because the computation in >>>>>>>the following example shouldn't continue past the [^1] block >>>>>>>but it silently does: >>>>>>>`[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] >>>>>>>fork` >>>>>>> >>>>>>>The bytecodes are >>>>>>> push true >>>>>>> jumpFalse L1 >>>>>>> push 1 >>>>>>> returnTop >>>>>>>L1 >>>>>>> push nil >>>>>>> blockReturn >>>>>>> >>>>>>> >>>>>>> >>>>>>>> >>>>>>>>So even if the VM did try and detect whether the return was >>>>>>>>at the last block method, it would only work for special >>>>>>>>cases. >>>>>>>> >>>>>>>> >>>>>>>>It seems to me the issue is simply that the context that >>>>>>>>cannot be returned from should be marked as dead (see >>>>>>>>Context>>isDead) by setting its pc to nil at some point, >>>>>>>>presumably after copying the actual return pc into the >>>>>>>>BlockCannotReturn exception, to avoid ever trying to resume >>>>>>>>the context. >>>>>>> >>>>>>>Does this mean, in other words, that every context that >>>>>>>returns should nil its pc to avoid being "wrongly" >>>>>>>reused/executed in the future, which concerns primarily those >>>>>>>being referenced somewhere hence potentially executable in >>>>>>>the future, is that right? >>>>>>>Hypothetical question: would nilling the pc during returns >>>>>>>"fix" the example? >>>>>>>Thanks a lot for helping me understand this. >>>>>>>Best, >>>>>>>Jaromir >>>>>>> >>>>>>> >>>>>>> >>>>>>>> >>>>>>>> >>>>>>>>> >>>>>>>>>Thanks, >>>>>>>>>Jaromir >>>>>>>>> >>>>>>>>><bdxuqalu.png> >>>>>>>>> >>>>>>>>>------ Original Message ------ >>>>>>>>>From "Eliot Miranda" <eliot.miranda@gmail.com> >>>>>>>>>To "Jaromir Matas" <mail@jaromir.net>; "The general-purpose >>>>>>>>>Squeak developers list" >>>>>>>>><squeak-dev@lists.squeakfoundation.org> >>>>>>>>>Date 11/16/2023 6:48:43 PM >>>>>>>>>Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn >>>>>>>>>exception >>>>>>>>> >>>>>>>>>>Hi Jaromir, >>>>>>>>>> >>>>>>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas >>>>>>>>>>><mail@jaromir.net> wrote: >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>Hi Nicloas, >>>>>>>>>>>No no, I don't have any practical scenario in mind, I'm >>>>>>>>>>>just trying to understand why the VM is implemented like >>>>>>>>>>>this, whether there were a reason to leave this >>>>>>>>>>>possibility of a crash, e.g. it would slow down the VM to >>>>>>>>>>>try to prevent such a dumb situation (who would resume >>>>>>>>>>>from BCR in his right mind? :) ) - or perhaps I have >>>>>>>>>>>overlooked some good reason to even keep this behavior in >>>>>>>>>>>the VM. That's all. >>>>>>>>>> >>>>>>>>>>Let’s first understand what’s really happening. Presumably >>>>>>>>>>at tone point a context is resumed those pc is already at >>>>>>>>>>the block return bytecode (effectively, because it crashes >>>>>>>>>>in JITted code, but I bet the stack vm will crash also, >>>>>>>>>>but not as cleanly - it will try and execute the bytes in >>>>>>>>>>the encoded method trailer). So which method actually >>>>>>>>>>sends resume, and to what, and what state is resume’s >>>>>>>>>>receiver when resume is sent? >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>Thanks for your reply. >>>>>>>>>>>Regards, >>>>>>>>>>>Jaromir >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>------ Original Message ------ >>>>>>>>>>>From "Nicolas Cellier" >>>>>>>>>>><nicolas.cellier.aka.nice@gmail.com> >>>>>>>>>>>To "Jaromir Matas" <mail@jaromir.net>; "The >>>>>>>>>>>general-purpose Squeak developers list" >>>>>>>>>>><squeak-dev@lists.squeakfoundation.org> >>>>>>>>>>>Date 11/16/2023 7:20:20 AM >>>>>>>>>>>Subject Re: [squeak-dev] Resuming on BlockCannotReturn >>>>>>>>>>>exception >>>>>>>>>>> >>>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>>Is there a scenario where it would make sense to resume >>>>>>>>>>>>a BlockCannotReturn? >>>>>>>>>>>>If not, I would suggest to protect at image side and >>>>>>>>>>>>override #resume. >>>>>>>>>>>> >>>>>>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas >>>>>>>>>>>><mail@jaromir.net> a écrit : >>>>>>>>>>>>>Hi Eliot, Christoph, All, >>>>>>>>>>>>> >>>>>>>>>>>>>It's known the following example crashes the VM. Is >>>>>>>>>>>>>this an intended behavior or a "tolerated bug"? >>>>>>>>>>>>> >>>>>>>>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>>>>>>>>>>> >>>>>>>>>>>>>I understand why it crashes: the non-local return has >>>>>>>>>>>>>nowhere to return to and so resuming the computation >>>>>>>>>>>>>leads to a crash. But why not raise another BCR >>>>>>>>>>>>>exception to prevent the crash? Potential infinite >>>>>>>>>>>>>loop? Perhaps I'm just missing the purpose of this >>>>>>>>>>>>>behavior... >>>>>>>>>>>>> >>>>>>>>>>>>>Thanks for an explanation. >>>>>>>>>>>>> >>>>>>>>>>>>>Best, >>>>>>>>>>>>>Jaromir >>>>>>>>>>>>> >>>>>>>>>>>>>-- >>>>>>>>>>>>> >>>>>>>>>>>>>Jaromir Matas >>>>>>>>>>>>> >>>>>>>>>>>>> >>>>>>>>>>> >>>>>>>> >>>>>>>> >>>>>>>>-- >>>>>>>>_,,,^..^,,,_ >>>>>>>>best, Eliot >>>>>><Context-cannotReturn.st> >>> >>> >>>-- >>>_,,,^..^,,,_ >>>best, Eliot >><ProcessTest-testResumeAfterBCR.st>-- _,,,^..^,,,_ best, Eliot
-- _,,,^..^,,,_ best, Eliot
Hi Eliot, Christoph, all
It looks like there are some more skeletons in the closet :/
If you run this example
[[self halt. ^ 1] on: BlockCannotReturn do: [:ex | ex resume] ] fork
and step over halt and then step over ^1 you get a nonsensical error as a result of decoding nil as an instruction.
It turns out that the root cause is in the #return:from: method: it only checks whether aSender is dead but ignores the possibility that aSender sender may be nil or dead in which cases the VM also responds with sending #cannotReturn, hence I assume the simulator should do the same. In addition, the VM nills the pc in such scenario, so I added the same functionality here too:
Context >> return: value from: aSender "For simulation. Roll back self to aSender and return value from it. Execute any unwind blocks on the way. ASSUMES aSender is a sender of self"
| newTop | newTop := aSender sender. (aSender isDead or: [newTop isNil or: [newTop isDead]]) ifTrue: "<--------- this is extended ------" [^self pc: nil; send: #cannotReturn: to: self with: {value}]. "<------ pc: nil is added ----" (self findNextUnwindContextUpTo: newTop) ifNotNil: "Send #aboutToReturn:through: with nil as the second argument to avoid this bug: Cannot #stepOver '^2' in example '[^2] ensure: []'. See http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html" [^self send: #aboutToReturn:through: to: self with: {value. nil}]. self releaseTo: newTop. newTop ifNotNil: [newTop push: value]. ^newTop
In order for this to work #cannotReturn: has to be modified as in Kernel-jar.1537:
Context >> cannotReturn: result
closureOrNil ifNotNil: [^ self cannotReturn: result to: self home sender]. self error: 'Computation has been terminated!' "<----------- this has to be an Error -----"
Then it almost works except when you keep stepping over in the example above, you get an MNU error on `self previousPc` in #cannotReturn:to:` with your solution of the VM crash. If you don't mind I've amended your solution and added the final context where the computation couldn't return along with the pc:
Context >> cannotReturn: result to: homeContext "The receiver tried to return result to homeContext that cannot be returned from. Capture the return context/pc in a BlockCannotReturn. Nil the pc to prevent repeat attempts and/or invalid continuation. Answer the result of raising the exception."
| exception previousPc | exception := BlockCannotReturn new. previousPc := pc ifNotNil: [self previousPc]. "<----- here's a fix ----" exception result: result; deadHome: homeContext; finalContext: self; "<----- here's the new state, if that's fine ----" pc: previousPc. pc := nil. ^exception signal
Unfortunately, this is still not the end of the story: there are situations where #runUntilErrorOrReturnFrom: places the two guard contexts below the bottom context. And that is a problem because when the method tries to remove the two guard contexts before returning at the end it uses #stepToCalee to do the job but this unforotunately was (ab)using the above bug in #return:from: - I'll explain: #return:from: didn't check whether aSender sender was nil and as a result it allowed to simulate a return to a "nil context" which was then (ab)used in the clean-up via #stepToCalee in the #runUntilErrorOrReturnFrom:.
When I fixed the #return:from: bug, the #runUntilErrorOrReturnFrom: cleanup of the guard contexts no longer works in that very special case where the guard contexts are below the bottom context. There's one case where this is being used: #terminateAggresively by Christoph.
If I'm right with this analysis, the #runUntilErrorOrReturnFrom: should get fixed too but I'll be away now for a few days and I won't be able to respond. If you or Christoph had a chance to take a look at Kernel-jar.1538 and Kernel-jar.1537 I'd be very grateful. I hope this super long message at least makes some sense :) Best, Jaromir
[1] Kernel-jar.1538, Kernel-jar.1537 [2] KernelTests-jar.447
PS: Christoph,
With Kernel-jar.1538 + Kernel-jar.1537 your example
process := [(c := thisContext) pc: nil. 2+3] newProcess. process runUntil: [:ctx | ctx selector = #cannotReturn:]. self assert: process suspendedContext sender sender = c. self assert: process suspendedContext arguments = {c}.
works fine, I've just corrected your first assert.
On 21-Nov-23 6:40:32 PM, "Eliot Miranda" eliot.miranda@gmail.com wrote:
Hi Jaromir,
On Nov 20, 2023, at 11:51 PM, Jaromir Matas mail@jaromir.net wrote:
Hi Eliot, Very elegant! Now I finally got what you meant exactly :) Thanks.
Two questions:
- in order for the enclosed test to work I'd need an Error instead of
Processor debugWithTitle:full: call in #cannotReturn:. Otherwise I don't know how to catch a plain invocation of the Debugger:
cannotReturn: result
closureOrNil ifNotNil: [^ self cannotReturn: result to: self homesender]. self error: 'Computation has been terminated!'
Much nicer.
- We are capturing a pc of self which is completely different context
from homeContext indeed.
Right. The return is attempted from a specific return bytecode in a specific block. This is the coordinate of the return that cannot be made. This is the relevant point of origin of the cannot return exception.
Why the return fails is another matter:
- the home context’s sender is a dead context (cannot be resumed)
- the home context’s sender is nil (home already returned from)
- the block activation’s home is nil rather than a context (should not
happen)
But in all these cases the pc of the home context is immaterial. The hike is being returned through/from, rather than from; the home’s pc is not relevant.
Maybe we could capture self in the exception too to make it more clear/explicit what is going on: what context the captured pc is actually associated with. Just a thought...
Yes, I like that. I also like the idea of somehow passing the block activation’s pc to the debugger so that the relevant return expression is highlighted in the debugger.
Thanks again, Jaromir
You’re welcome. I love working in this part of the system. Thanks for dragging me there. I’m in a slump right now and appreciate the fellowship.
------ Original Message ------ From "Eliot Miranda" eliot.miranda@gmail.com To "Jaromir Matas" mail@jaromir.net Cc squeak-dev@lists.squeakfoundation.org Date 11/21/2023 2:17:21 AM Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
see Kernel-eem.1535 for what I was suggesting. This example now has an exception with the right pc value in it:
[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] fork
The fix is simply
Context>>cannotReturn: result to: homeContext "The receiver tried to return result to homeContext that cannot be returned from. Capture the return pc in a BlockCannotReturn. Nil the pc to prevent repeat attempts and/or invalid continuation. Answer the result of raising the exception."
| exception | exception := BlockCannotReturn new. exception result: result; deadHome: homeContext; pc: self previousPc. pc := nil. ^exception signalThe VM crash is now avoided. The debugger displays the method, but does not highlight the offending pc, which is no big deal. A suitable defaultHandler for B lockCannotReturn may be able to get the debugger to highlight correctly on opening. Try the following examples:
[[^1] on: BlockCannotReturn do: #resume] fork.
[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] fork
[[^1] value] fork.
They al; seem to behave perfectly acceptably to me. Does this fix work for you?
On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas mail@jaromir.net wrote:
Hi Eliot,
How about to nil the pc just before making the return:
Context >> #cannotReturn: result self push: self pc. "backup the pc for the sake of debugging" closureOrNil ifNotNil: [^self cannotReturn: result to: self home sender; pc: nil]. Processor debugWithTitle: 'Computation has been terminated!' translated full: falseThe nilled pc should not even potentially interfere with the #isDead now.
I hope this is at least a step in the right direction :)
However, there's still a problem when debugging the resumption of #cannotReturn because the encoders expect a reasonable index. I haven't figured out yet where to place a nil check - #step, #stepToSendOrReturn... ?
Thanks again, Jaromir
------ Original Message ------ From "Eliot Miranda" eliot.miranda@gmail.com To "Jaromir Matas" mail@jaromir.net Date 11/17/2023 8:36:50 PM Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On Nov 17, 2023, at 7:05 AM, Jaromir Matas mail@jaromir.net wrote:
Eliot, hi again,
Please disregard my previous comment about nilling the contexts that have returned. We are indeed talking about the context directly under the #cannotReturn context which is totally different from the home context in another thread that's gone.
I may still be confused but would nilling the pc of the context directly under the cannotReturn context help? Here's what I mean:
Context >> #cannotReturn: result closureOrNil ifNotNil: [^self pc: nil; cannotReturn: result to: self home sender]. Processor debugWithTitle: 'Computation has been terminated!' translated full: false.Instead of crashing the VM invokes the debugger with the 'Computation has been terminated!' message.
Does this make sense?
Nearly. But it loses the information on what the pc actually is, and that’s potentially vital information. So IMO the ox should only be nilled between the BlockCannotReturn exception being created and raised.
[But if you try this don’t be surprised if it causes a few temporary problems. It looks to me that without a little refactoring this could easily cause an infinite recursion around the sending of isDead. I’m sure you’ll be able to fix the code to work correctly]
Thanks, Jaromir
------ Original Message ------ From "Jaromir Matas" mail@jaromir.net To "Eliot Miranda" eliot.miranda@gmail.com; "The general-purpose Squeak developers list" squeak-dev@lists.squeakfoundation.org Date 11/17/2023 10:15:17 AM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
>Hi Eliot, > > > >------ Original Message ------ >From "Eliot Miranda" eliot.miranda@gmail.com >To "Jaromir Matas" mail@jaromir.net >Cc "The general-purpose Squeak developers list" >squeak-dev@lists.squeakfoundation.org >Date 11/16/2023 11:52:45 PM >Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn >exception > >>Hi Jaromir, >> >>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas mail@jaromir.net >>wrote: >>>Hi Nicolas, Eliot, >>> >>>here's what I understand is happening (see the enclosed >>>screenshot): >>> >>>1) we fork a new process to evaluate [^1] >>>2) the new process evaluates [^1] which means instruction 18 is >>>being evaluated, hence pc points to instruction 19 now >>>3) however, the home context where ^1 should return to is gone >>>by this time (the process that executed the fork has already >>>returned - notice the two up arrows in the debugger screenshot) >>>4) the VM can't finish the instruction and returns control to >>>the image via placing the #cannotReturn: context on top of the >>>[^1] context >>>5) #cannotReturn: evaluation results in signalling the BCR >>>exception which is then handled by the #resume handler >>> (in our debugged case the [:ex | self halt. ex resume] >>>handler) >>>6) ex resume is evaluated, however, this means requesting the >>>VM to evaluate instruction 19 of the [^1] context - which is >>>past the last instruction of the context and the crash ensues >>> >>>I wonder whether such situations could/should be prevented >>>inside the VM or whether such an expectation is wrong for some >>>reason. >> >>As Nicolas says, IMO this is best done at the image level. >> >>It could be prevented in the VM, but at great cost, and only >>partially. The performance issue is that the last bytecode in a >>method is not marked in any way, and that to determine the last >>bytecode the bytecodes must be symbolically evaluated from the >>start of the method. See implementors of endPC at the image >>level (which defer to the method trailer) and implementors of >>endPCOf: in the VMMaker code. Doing this every time execution >>commences is prohibitively expensive. The "only partially" >>issue is that following the return instruction may be other >>valid bytecodes, but these are not a continuation. >> >> >>Consider the following code in some block: >> [self expression ifTrue: >> [^1]. >> ^2 >> >>The bytecodes for this are >> pushReceiver >> send #expression >> jumpFalse L1 >> push 1 >> methodReturnTop >>L1 >> push 2 >> methodReturnTop >> >>Clearly if expression is true these should be *no* continuation >>in which ^2 is executed. > >Well, in that case there's a bug because the computation in the >following example shouldn't continue past the [^1] block but it >silently does: >`[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork` > >The bytecodes are > push true > jumpFalse L1 > push 1 > returnTop >L1 > push nil > blockReturn > > > >> >>So even if the VM did try and detect whether the return was at >>the last block method, it would only work for special cases. >> >> >>It seems to me the issue is simply that the context that cannot >>be returned from should be marked as dead (see Context>>isDead) >>by setting its pc to nil at some point, presumably after copying >>the actual return pc into the BlockCannotReturn exception, to >>avoid ever trying to resume the context. > >Does this mean, in other words, that every context that returns >should nil its pc to avoid being "wrongly" reused/executed in the >future, which concerns primarily those being referenced somewhere >hence potentially executable in the future, is that right? >Hypothetical question: would nilling the pc during returns "fix" >the example? >Thanks a lot for helping me understand this. >Best, >Jaromir > > > >> >> >>> >>>Thanks, >>>Jaromir >>> >>><bdxuqalu.png> >>> >>>------ Original Message ------ >>>From "Eliot Miranda" eliot.miranda@gmail.com >>>To "Jaromir Matas" mail@jaromir.net; "The general-purpose >>>Squeak developers list" squeak-dev@lists.squeakfoundation.org >>>Date 11/16/2023 6:48:43 PM >>>Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn >>>exception >>> >>>>Hi Jaromir, >>>> >>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas mail@jaromir.net >>>>>wrote: >>>>> >>>>> >>>>>Hi Nicloas, >>>>>No no, I don't have any practical scenario in mind, I'm just >>>>>trying to understand why the VM is implemented like this, >>>>>whether there were a reason to leave this possibility of a >>>>>crash, e.g. it would slow down the VM to try to prevent such >>>>>a dumb situation (who would resume from BCR in his right >>>>>mind? :) ) - or perhaps I have overlooked some good reason to >>>>>even keep this behavior in the VM. That's all. >>>> >>>>Let’s first understand what’s really happening. Presumably at >>>>tone point a context is resumed those pc is already at the >>>>block return bytecode (effectively, because it crashes in >>>>JITted code, but I bet the stack vm will crash also, but not >>>>as cleanly - it will try and execute the bytes in the encoded >>>>method trailer). So which method actually sends resume, and to >>>>what, and what state is resume’s receiver when resume is sent? >>>> >>>> >>>>> >>>>>Thanks for your reply. >>>>>Regards, >>>>>Jaromir >>>>> >>>>> >>>>> >>>>> >>>>>------ Original Message ------ >>>>>From "Nicolas Cellier" nicolas.cellier.aka.nice@gmail.com >>>>>To "Jaromir Matas" mail@jaromir.net; "The general-purpose >>>>>Squeak developers list" >>>>>squeak-dev@lists.squeakfoundation.org >>>>>Date 11/16/2023 7:20:20 AM >>>>>Subject Re: [squeak-dev] Resuming on BlockCannotReturn >>>>>exception >>>>> >>>>>>Hi Jaromir, >>>>>>Is there a scenario where it would make sense to resume a >>>>>>BlockCannotReturn? >>>>>>If not, I would suggest to protect at image side and >>>>>>override #resume. >>>>>> >>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas >>>>>>mail@jaromir.net a écrit : >>>>>>>Hi Eliot, Christoph, All, >>>>>>> >>>>>>>It's known the following example crashes the VM. Is this an >>>>>>>intended behavior or a "tolerated bug"? >>>>>>> >>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>>>>> >>>>>>>I understand why it crashes: the non-local return has >>>>>>>nowhere to return to and so resuming the computation leads >>>>>>>to a crash. But why not raise another BCR exception to >>>>>>>prevent the crash? Potential infinite loop? Perhaps I'm >>>>>>>just missing the purpose of this behavior... >>>>>>> >>>>>>>Thanks for an explanation. >>>>>>> >>>>>>>Best, >>>>>>>Jaromir >>>>>>> >>>>>>>-- >>>>>>> >>>>>>>Jaromir Matas >>>>>>> >>>>>>> >>>>> >> >> >>-- >>_,,,^..^,,,_ >>best, Eliot <Context-cannotReturn.st>
-- _,,,^..^,,,_ best, Eliot
<ProcessTest-testResumeAfterBCR.st>
Hi Eliot, Marcel, all,
I've sent a fix Kernel-jar.1539 to the Inbox that solves the remaining bit of the chain of bugs described in the previous post. All tests are green now and I think the root cause has been found and fixed.
In this last bit I've created a version of stepToCallee that would identify a potential illegal return to a nil sender and avoid it.
Now this example can be debugged without any problems:
[[self halt. ^ 1] on: BlockCannotReturn do: #resume ] fork
If you're happy with the solution in Kernel-jar.1539, Kernel-jar.1538, Kernel-jar.1537 and the test in KernelTests-jar.447, could you please double-check and merge, please? (And remove Kernel-mt.1534 and Tools-jar.1240 from the Inbox)
Best, Jaromir
On 27-Nov-23 12:09:37 AM, "Jaromir Matas" mail@jaromir.net wrote:
Hi Eliot, Christoph, all
It looks like there are some more skeletons in the closet :/
If you run this example
[[self halt. ^ 1] on: BlockCannotReturn do: [:ex | ex resume] ] fork
and step over halt and then step over ^1 you get a nonsensical error as a result of decoding nil as an instruction.
It turns out that the root cause is in the #return:from: method: it only checks whether aSender is dead but ignores the possibility that aSender sender may be nil or dead in which cases the VM also responds with sending #cannotReturn, hence I assume the simulator should do the same. In addition, the VM nills the pc in such scenario, so I added the same functionality here too:
Context >> return: value from: aSender "For simulation. Roll back self to aSender and return value from it. Execute any unwind blocks on the way. ASSUMES aSender is a sender of self"
| newTop | newTop := aSender sender. (aSender isDead or: [newTop isNil or: [newTop isDead]]) ifTrue:"<--------- this is extended ------" [^self pc: nil; send: #cannotReturn: to: self with: {value}]. "<------ pc: nil is added ----" (self findNextUnwindContextUpTo: newTop) ifNotNil: "Send #aboutToReturn:through: with nil as the second argument to avoid this bug: Cannot #stepOver '^2' in example '[^2] ensure: []'. See http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html" [^self send: #aboutToReturn:through: to: self with: {value. nil}]. self releaseTo: newTop. newTop ifNotNil: [newTop push: value]. ^newTop
In order for this to work #cannotReturn: has to be modified as in Kernel-jar.1537:
Context >> cannotReturn: result
closureOrNil ifNotNil: [^ self cannotReturn: result to: self homesender]. self error: 'Computation has been terminated!' "<----------- this has to be an Error -----"
Then it almost works except when you keep stepping over in the example above, you get an MNU error on `self previousPc` in #cannotReturn:to:` with your solution of the VM crash. If you don't mind I've amended your solution and added the final context where the computation couldn't return along with the pc:
Context >> cannotReturn: result to: homeContext "The receiver tried to return result to homeContext that cannot be returned from. Capture the return context/pc in a BlockCannotReturn. Nil the pc to prevent repeat attempts and/or invalid continuation. Answer the result of raising the exception."
| exception previousPc | exception := BlockCannotReturn new. previousPc := pc ifNotNil: [self previousPc]. "<----- here's afix ----" exception result: result; deadHome: homeContext; finalContext: self; "<----- here's the new state, if that's fine ----" pc: previousPc. pc := nil. ^exception signal
Unfortunately, this is still not the end of the story: there are situations where #runUntilErrorOrReturnFrom: places the two guard contexts below the bottom context. And that is a problem because when the method tries to remove the two guard contexts before returning at the end it uses #stepToCalee to do the job but this unforotunately was (ab)using the above bug in #return:from: - I'll explain: #return:from: didn't check whether aSender sender was nil and as a result it allowed to simulate a return to a "nil context" which was then (ab)used in the clean-up via #stepToCalee in the #runUntilErrorOrReturnFrom:.
When I fixed the #return:from: bug, the #runUntilErrorOrReturnFrom: cleanup of the guard contexts no longer works in that very special case where the guard contexts are below the bottom context. There's one case where this is being used: #terminateAggresively by Christoph.
If I'm right with this analysis, the #runUntilErrorOrReturnFrom: should get fixed too but I'll be away now for a few days and I won't be able to respond. If you or Christoph had a chance to take a look at Kernel-jar.1538 and Kernel-jar.1537 I'd be very grateful. I hope this super long message at least makes some sense :) Best, Jaromir
[1] Kernel-jar.1538, Kernel-jar.1537 [2] KernelTests-jar.447
PS: Christoph,
With Kernel-jar.1538 + Kernel-jar.1537 your example
process := [(c := thisContext) pc: nil. 2+3] newProcess. process runUntil: [:ctx | ctx selector = #cannotReturn:]. self assert: process suspendedContext sender sender = c. self assert: process suspendedContext arguments = {c}.
works fine, I've just corrected your first assert.
On 21-Nov-23 6:40:32 PM, "Eliot Miranda" eliot.miranda@gmail.com wrote:
Hi Jaromir,
On Nov 20, 2023, at 11:51 PM, Jaromir Matas mail@jaromir.net wrote:
Hi Eliot, Very elegant! Now I finally got what you meant exactly :) Thanks.
Two questions:
- in order for the enclosed test to work I'd need an Error instead
of Processor debugWithTitle:full: call in #cannotReturn:. Otherwise I don't know how to catch a plain invocation of the Debugger:
cannotReturn: result
closureOrNil ifNotNil: [^ self cannotReturn: result to: self homesender]. self error: 'Computation has been terminated!'
Much nicer.
- We are capturing a pc of self which is completely different
context from homeContext indeed.
Right. The return is attempted from a specific return bytecode in a specific block. This is the coordinate of the return that cannot be made. This is the relevant point of origin of the cannot return exception.
Why the return fails is another matter:
- the home context’s sender is a dead context (cannot be resumed)
- the home context’s sender is nil (home already returned from)
- the block activation’s home is nil rather than a context (should not
happen)
But in all these cases the pc of the home context is immaterial. The hike is being returned through/from, rather than from; the home’s pc is not relevant.
Maybe we could capture self in the exception too to make it more clear/explicit what is going on: what context the captured pc is actually associated with. Just a thought...
Yes, I like that. I also like the idea of somehow passing the block activation’s pc to the debugger so that the relevant return expression is highlighted in the debugger.
Thanks again, Jaromir
You’re welcome. I love working in this part of the system. Thanks for dragging me there. I’m in a slump right now and appreciate the fellowship.
------ Original Message ------ From "Eliot Miranda" eliot.miranda@gmail.com To "Jaromir Matas" mail@jaromir.net Cc squeak-dev@lists.squeakfoundation.org Date 11/21/2023 2:17:21 AM Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
see Kernel-eem.1535 for what I was suggesting. This example now has an exception with the right pc value in it:
[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] fork
The fix is simply
Context>>cannotReturn: result to: homeContext "The receiver tried to return result to homeContext that cannot be returned from. Capture the return pc in a BlockCannotReturn. Nil the pc to prevent repeat attempts and/or invalid continuation. Answer the result of raising the exception."
| exception | exception := BlockCannotReturn new. exception result: result; deadHome: homeContext; pc: self previousPc. pc := nil. ^exception signalThe VM crash is now avoided. The debugger displays the method, but does not highlight the offending pc, which is no big deal. A suitable defaultHandler for B lockCannotReturn may be able to get the debugger to highlight correctly on opening. Try the following examples:
[[^1] on: BlockCannotReturn do: #resume] fork.
[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] fork
[[^1] value] fork.
They al; seem to behave perfectly acceptably to me. Does this fix work for you?
On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas mail@jaromir.net wrote:
Hi Eliot,
How about to nil the pc just before making the return:
Context >> #cannotReturn: result self push: self pc. "backup the pc for the sake of debugging" closureOrNil ifNotNil: [^self cannotReturn: result to: self home sender; pc: nil]. Processor debugWithTitle: 'Computation has been terminated!' translated full: falseThe nilled pc should not even potentially interfere with the #isDead now.
I hope this is at least a step in the right direction :)
However, there's still a problem when debugging the resumption of #cannotReturn because the encoders expect a reasonable index. I haven't figured out yet where to place a nil check - #step, #stepToSendOrReturn... ?
Thanks again, Jaromir
------ Original Message ------ From "Eliot Miranda" eliot.miranda@gmail.com To "Jaromir Matas" mail@jaromir.net Date 11/17/2023 8:36:50 PM Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
>On Nov 17, 2023, at 7:05 AM, Jaromir Matas mail@jaromir.net >wrote: > > >Eliot, hi again, > >Please disregard my previous comment about nilling the contexts >that have returned. We are indeed talking about the context >directly under the #cannotReturn context which is totally >different from the home context in another thread that's gone. > >I may still be confused but would nilling the pc of the context >directly under the cannotReturn context help? Here's what I mean: >``` >Context >> #cannotReturn: result > > closureOrNil ifNotNil: [^self pc: nil; cannotReturn: result >to: self home sender]. > Processor debugWithTitle: 'Computation has been terminated!' >translated full: false. >``` >Instead of crashing the VM invokes the debugger with the >'Computation has been terminated!' message. > >Does this make sense?
Nearly. But it loses the information on what the pc actually is, and that’s potentially vital information. So IMO the ox should only be nilled between the BlockCannotReturn exception being created and raised.
[But if you try this don’t be surprised if it causes a few temporary problems. It looks to me that without a little refactoring this could easily cause an infinite recursion around the sending of isDead. I’m sure you’ll be able to fix the code to work correctly]
>Thanks, >Jaromir > > >------ Original Message ------ >From "Jaromir Matas" mail@jaromir.net >To "Eliot Miranda" eliot.miranda@gmail.com; "The >general-purpose Squeak developers list" >squeak-dev@lists.squeakfoundation.org >Date 11/17/2023 10:15:17 AM >Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception > >>Hi Eliot, >> >> >> >>------ Original Message ------ >>From "Eliot Miranda" eliot.miranda@gmail.com >>To "Jaromir Matas" mail@jaromir.net >>Cc "The general-purpose Squeak developers list" >>squeak-dev@lists.squeakfoundation.org >>Date 11/16/2023 11:52:45 PM >>Subject Re: Re[2]: [squeak-dev] Re: Resuming on >>BlockCannotReturn exception >> >>>Hi Jaromir, >>> >>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas >>>mail@jaromir.net wrote: >>>>Hi Nicolas, Eliot, >>>> >>>>here's what I understand is happening (see the enclosed >>>>screenshot): >>>> >>>>1) we fork a new process to evaluate [^1] >>>>2) the new process evaluates [^1] which means instruction 18 >>>>is being evaluated, hence pc points to instruction 19 now >>>>3) however, the home context where ^1 should return to is gone >>>>by this time (the process that executed the fork has already >>>>returned - notice the two up arrows in the debugger >>>>screenshot) >>>>4) the VM can't finish the instruction and returns control to >>>>the image via placing the #cannotReturn: context on top of the >>>>[^1] context >>>>5) #cannotReturn: evaluation results in signalling the BCR >>>>exception which is then handled by the #resume handler >>>> (in our debugged case the [:ex | self halt. ex resume] >>>>handler) >>>>6) ex resume is evaluated, however, this means requesting the >>>>VM to evaluate instruction 19 of the [^1] context - which is >>>>past the last instruction of the context and the crash ensues >>>> >>>>I wonder whether such situations could/should be prevented >>>>inside the VM or whether such an expectation is wrong for some >>>>reason. >>> >>>As Nicolas says, IMO this is best done at the image level. >>> >>>It could be prevented in the VM, but at great cost, and only >>>partially. The performance issue is that the last bytecode in >>>a method is not marked in any way, and that to determine the >>>last bytecode the bytecodes must be symbolically evaluated from >>>the start of the method. See implementors of endPC at the >>>image level (which defer to the method trailer) and >>>implementors of endPCOf: in the VMMaker code. Doing this every >>>time execution commences is prohibitively expensive. The "only >>>partially" issue is that following the return instruction may >>>be other valid bytecodes, but these are not a continuation. >>> >>> >>>Consider the following code in some block: >>> [self expression ifTrue: >>> [^1]. >>> ^2 >>> >>>The bytecodes for this are >>> pushReceiver >>> send #expression >>> jumpFalse L1 >>> push 1 >>> methodReturnTop >>>L1 >>> push 2 >>> methodReturnTop >>> >>>Clearly if expression is true these should be *no* continuation >>>in which ^2 is executed. >> >>Well, in that case there's a bug because the computation in the >>following example shouldn't continue past the [^1] block but it >>silently does: >>`[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork` >> >>The bytecodes are >> push true >> jumpFalse L1 >> push 1 >> returnTop >>L1 >> push nil >> blockReturn >> >> >> >>> >>>So even if the VM did try and detect whether the return was at >>>the last block method, it would only work for special cases. >>> >>> >>>It seems to me the issue is simply that the context that cannot >>>be returned from should be marked as dead (see Context>>isDead) >>>by setting its pc to nil at some point, presumably after >>>copying the actual return pc into the BlockCannotReturn >>>exception, to avoid ever trying to resume the context. >> >>Does this mean, in other words, that every context that returns >>should nil its pc to avoid being "wrongly" reused/executed in >>the future, which concerns primarily those being referenced >>somewhere hence potentially executable in the future, is that >>right? >>Hypothetical question: would nilling the pc during returns "fix" >>the example? >>Thanks a lot for helping me understand this. >>Best, >>Jaromir >> >> >> >>> >>> >>>> >>>>Thanks, >>>>Jaromir >>>> >>>><bdxuqalu.png> >>>> >>>>------ Original Message ------ >>>>From "Eliot Miranda" eliot.miranda@gmail.com >>>>To "Jaromir Matas" mail@jaromir.net; "The general-purpose >>>>Squeak developers list" >>>>squeak-dev@lists.squeakfoundation.org >>>>Date 11/16/2023 6:48:43 PM >>>>Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn >>>>exception >>>> >>>>>Hi Jaromir, >>>>> >>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas >>>>>>mail@jaromir.net wrote: >>>>>> >>>>>> >>>>>>Hi Nicloas, >>>>>>No no, I don't have any practical scenario in mind, I'm just >>>>>>trying to understand why the VM is implemented like this, >>>>>>whether there were a reason to leave this possibility of a >>>>>>crash, e.g. it would slow down the VM to try to prevent such >>>>>>a dumb situation (who would resume from BCR in his right >>>>>>mind? :) ) - or perhaps I have overlooked some good reason >>>>>>to even keep this behavior in the VM. That's all. >>>>> >>>>>Let’s first understand what’s really happening. Presumably at >>>>>tone point a context is resumed those pc is already at the >>>>>block return bytecode (effectively, because it crashes in >>>>>JITted code, but I bet the stack vm will crash also, but not >>>>>as cleanly - it will try and execute the bytes in the encoded >>>>>method trailer). So which method actually sends resume, and >>>>>to what, and what state is resume’s receiver when resume is >>>>>sent? >>>>> >>>>> >>>>>> >>>>>>Thanks for your reply. >>>>>>Regards, >>>>>>Jaromir >>>>>> >>>>>> >>>>>> >>>>>> >>>>>>------ Original Message ------ >>>>>>From "Nicolas Cellier" nicolas.cellier.aka.nice@gmail.com >>>>>>To "Jaromir Matas" mail@jaromir.net; "The general-purpose >>>>>>Squeak developers list" >>>>>>squeak-dev@lists.squeakfoundation.org >>>>>>Date 11/16/2023 7:20:20 AM >>>>>>Subject Re: [squeak-dev] Resuming on BlockCannotReturn >>>>>>exception >>>>>> >>>>>>>Hi Jaromir, >>>>>>>Is there a scenario where it would make sense to resume a >>>>>>>BlockCannotReturn? >>>>>>>If not, I would suggest to protect at image side and >>>>>>>override #resume. >>>>>>> >>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas >>>>>>>mail@jaromir.net a écrit : >>>>>>>>Hi Eliot, Christoph, All, >>>>>>>> >>>>>>>>It's known the following example crashes the VM. Is this >>>>>>>>an intended behavior or a "tolerated bug"? >>>>>>>> >>>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>>>>>> >>>>>>>>I understand why it crashes: the non-local return has >>>>>>>>nowhere to return to and so resuming the computation leads >>>>>>>>to a crash. But why not raise another BCR exception to >>>>>>>>prevent the crash? Potential infinite loop? Perhaps I'm >>>>>>>>just missing the purpose of this behavior... >>>>>>>> >>>>>>>>Thanks for an explanation. >>>>>>>> >>>>>>>>Best, >>>>>>>>Jaromir >>>>>>>> >>>>>>>>-- >>>>>>>> >>>>>>>>Jaromir Matas >>>>>>>> >>>>>>>> >>>>>> >>> >>> >>>-- >>>_,,,^..^,,,_ >>>best, Eliot ><Context-cannotReturn.st>
-- _,,,^..^,,,_ best, Eliot
<ProcessTest-testResumeAfterBCR.st>

Hi all --
I just want to repeat what I said in that other thread here: - http://lists.squeakfoundation.org/archives/list/squeak-dev@lists.squeakfound...
1) I like the idea of keeping the exception object around during the debugging activity. We should store it in the process-to-debug. That's our current "debugger invocation cue" object, we already have.
2) We must ensure that the Debugger class remains replaceable. It is just a GUI tool. The control-flow mechanics are in Context/Process, Exception, ToolSet, Project.
Best, Marcel
Am 28.11.2023 01:29:39 schrieb Jaromir Matas mail@jaromir.net:
Hi Eliot, Marcel, all,
I've sent a fix Kernel-jar.1539 to the Inbox that solves the remaining bit of the chain of bugs described in the previous post. All tests are green now and I think the root cause has been found and fixed.
In this last bit I've created a version of stepToCallee that would identify a potential illegal return to a nil sender and avoid it.
Now this example can be debugged without any problems:
[[self halt. ^ 1] on: BlockCannotReturn do: #resume ] fork
If you're happy with the solution in Kernel-jar.1539, Kernel-jar.1538, Kernel-jar.1537 and the test in KernelTests-jar.447, could you please double-check and merge, please? (And remove Kernel-mt.1534 and Tools-jar.1240 from the Inbox)
Best, Jaromir
On 27-Nov-23 12:09:37 AM, "Jaromir Matas" <mail@jaromir.netmailto:mail@jaromir.net> wrote:
Hi Eliot, Christoph, all
It looks like there are some more skeletons in the closet :/
If you run this example
[[self halt. ^ 1] on: BlockCannotReturn do: [:ex | ex resume] ] fork
and step over halt and then step over ^1 you get a nonsensical error as a result of decoding nil as an instruction.
It turns out that the root cause is in the #return:from: method: it only checks whether aSender is dead but ignores the possibility that aSender sender may be nil or dead in which cases the VM also responds with sending #cannotReturn, hence I assume the simulator should do the same. In addition, the VM nills the pc in such scenario, so I added the same functionality here too:
Context >> return: value from: aSender "For simulation. Roll back self to aSender and return value from it. Execute any unwind blocks on the way. ASSUMES aSender is a sender of self"
| newTop | newTop := aSender sender. (aSender isDead or: [newTop isNil or: [newTop isDead]]) ifTrue: "<--------- this is extended ------" [^self pc: nil; send: #cannotReturn: to: self with: {value}]. "<------ pc: nil is added ----" (self findNextUnwindContextUpTo: newTop) ifNotNil: "Send #aboutToReturn:through: with nil as the second argument to avoid this bug: Cannot #stepOver '^2' in example '[^2] ensure: []'. See http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html" [^self send: #aboutToReturn:through: to: self with: {value. nil}]. self releaseTo: newTop. newTop ifNotNil: [newTop push: value]. ^newTop
In order for this to work #cannotReturn: has to be modified as in Kernel-jar.1537:
Context >> cannotReturn: result
closureOrNil ifNotNil: [^ self cannotReturn: result to: self home sender]. self error: 'Computation has been terminated!' "<----------- this has to be an Error -----"
Then it almost works except when you keep stepping over in the example above, you get an MNU error on `self previousPc` in #cannotReturn:to:` with your solution of the VM crash. If you don't mind I've amended your solution and added the final context where the computation couldn't return along with the pc:
Context >> cannotReturn: result to: homeContext "The receiver tried to return result to homeContext that cannot be returned from. Capture the return context/pc in a BlockCannotReturn. Nil the pc to prevent repeat attempts and/or invalid continuation. Answer the result of raising the exception."
| exception previousPc | exception := BlockCannotReturn new. previousPc := pc ifNotNil: [self previousPc]. "<----- here's a fix ----" exception result: result; deadHome: homeContext; finalContext: self; "<----- here's the new state, if that's fine ----" pc: previousPc. pc := nil. ^exception signal
Unfortunately, this is still not the end of the story: there are situations where #runUntilErrorOrReturnFrom: places the two guard contexts below the bottom context. And that is a problem because when the method tries to remove the two guard contexts before returning at the end it uses #stepToCalee to do the job but this unforotunately was (ab)using the above bug in #return:from: - I'll explain: #return:from: didn't check whether aSender sender was nil and as a result it allowed to simulate a return to a "nil context" which was then (ab)used in the clean-up via #stepToCalee in the #runUntilErrorOrReturnFrom:.
When I fixed the #return:from: bug, the #runUntilErrorOrReturnFrom: cleanup of the guard contexts no longer works in that very special case where the guard contexts are below the bottom context. There's one case where this is being used: #terminateAggresively by Christoph.
If I'm right with this analysis, the #runUntilErrorOrReturnFrom: should get fixed too but I'll be away now for a few days and I won't be able to respond. If you or Christoph had a chance to take a look at Kernel-jar.1538 and Kernel-jar.1537 I'd be very grateful. I hope this super long message at least makes some sense :) Best, Jaromir
[1] Kernel-jar.1538, Kernel-jar.1537 [2] KernelTests-jar.447
PS: Christoph,
With Kernel-jar.1538 + Kernel-jar.1537 your example
process := [(c := thisContext) pc: nil. 2+3] newProcess. process runUntil: [:ctx | ctx selector = #cannotReturn:]. self assert: process suspendedContext sender sender = c. self assert: process suspendedContext arguments = {c}.
works fine, I've just corrected your first assert.
On 21-Nov-23 6:40:32 PM, "Eliot Miranda" <eliot.miranda@gmail.commailto:eliot.miranda@gmail.com> wrote:
Hi Jaromir,
On Nov 20, 2023, at 11:51 PM, Jaromir Matas <mail@jaromir.netmailto:mail@jaromir.net> wrote:
Hi Eliot, Very elegant! Now I finally got what you meant exactly :) Thanks.
Two questions: 1. in order for the enclosed test to work I'd need an Error instead of Processor debugWithTitle:full: call in #cannotReturn:. Otherwise I don't know how to catch a plain invocation of the Debugger:
cannotReturn: result
closureOrNil ifNotNil: [^ self cannotReturn: result to: self home sender]. self error: 'Computation has been terminated!'
Much nicer.
2. We are capturing a pc of self which is completely different context from homeContext indeed.
Right. The return is attempted from a specific return bytecode in a specific block. This is the coordinate of the return that cannot be made. This is the relevant point of origin of the cannot return exception.
Why the return fails is another matter: - the home context’s sender is a dead context (cannot be resumed) - the home context’s sender is nil (home already returned from) - the block activation’s home is nil rather than a context (should not happen)
But in all these cases the pc of the home context is immaterial. The hike is being returned through/from, rather than from; the home’s pc is not relevant.
Maybe we could capture self in the exception too to make it more clear/explicit what is going on: what context the captured pc is actually associated with. Just a thought...
Yes, I like that. I also like the idea of somehow passing the block activation’s pc to the debugger so that the relevant return expression is highlighted in the debugger.
Thanks again, Jaromir
You’re welcome. I love working in this part of the system. Thanks for dragging me there. I’m in a slump right now and appreciate the fellowship.
------ Original Message ------ From "Eliot Miranda" <eliot.miranda@gmail.commailto:eliot.miranda@gmail.com> To "Jaromir Matas" <mail@jaromir.netmailto:mail@jaromir.net> Cc squeak-dev@lists.squeakfoundation.orgmailto:squeak-dev@lists.squeakfoundation.org Date 11/21/2023 2:17:21 AM Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
see Kernel-eem.1535 for what I was suggesting. This example now has an exception with the right pc value in it:
[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] fork
The fix is simply
Context>>cannotReturn: result to: homeContext "The receiver tried to return result to homeContext that cannot be returned from. Capture the return pc in a BlockCannotReturn. Nil the pc to prevent repeat attempts and/or invalid continuation. Answer the result of raising the exception."
| exception | exception := BlockCannotReturn new. exception result: result; deadHome: homeContext; pc: self previousPc. pc := nil. ^exception signal
The VM crash is now avoided. The debugger displays the method, but does not highlight the offending pc, which is no big deal. A suitable defaultHandler for B lockCannotReturn may be able to get the debugger to highlight correctly on opening. Try the following examples:
[[^1] on: BlockCannotReturn do: #resume] fork.
[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] fork
[[^1] value] fork.
They al; seem to behave perfectly acceptably to me. Does this fix work for you?
On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas <mail@jaromir.netmailto:mail@jaromir.net> wrote: Hi Eliot,
How about to nil the pc just before making the return: ``` Context >> #cannotReturn: result
self push: self pc. "backup the pc for the sake of debugging" closureOrNil ifNotNil: [^self cannotReturn: result to: self home sender; pc: nil]. Processor debugWithTitle: 'Computation has been terminated!' translated full: false ``` The nilled pc should not even potentially interfere with the #isDead now.
I hope this is at least a step in the right direction :)
However, there's still a problem when debugging the resumption of #cannotReturn because the encoders expect a reasonable index. I haven't figured out yet where to place a nil check - #step, #stepToSendOrReturn... ?
Thanks again, Jaromir
------ Original Message ------ From "Eliot Miranda" <eliot.miranda@gmail.commailto:eliot.miranda@gmail.com> To "Jaromir Matas" <mail@jaromir.netmailto:mail@jaromir.net> Date 11/17/2023 8:36:50 PM Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On Nov 17, 2023, at 7:05 AM, Jaromir Matas <mail@jaromir.netmailto:mail@jaromir.net> wrote:
Eliot, hi again,
Please disregard my previous comment about nilling the contexts that have returned. We are indeed talking about the context directly under the #cannotReturn context which is totally different from the home context in another thread that's gone.
I may still be confused but would nilling the pc of the context directly under the cannotReturn context help? Here's what I mean: ``` Context >> #cannotReturn: result
closureOrNil ifNotNil: [^self pc: nil; cannotReturn: result to: self home sender]. Processor debugWithTitle: 'Computation has been terminated!' translated full: false. ``` Instead of crashing the VM invokes the debugger with the 'Computation has been terminated!' message.
Does this make sense?
Nearly. But it loses the information on what the pc actually is, and that’s potentially vital information. So IMO the ox should only be nilled between the BlockCannotReturn exception being created and raised.
[But if you try this don’t be surprised if it causes a few temporary problems. It looks to me that without a little refactoring this could easily cause an infinite recursion around the sending of isDead. I’m sure you’ll be able to fix the code to work correctly]
Thanks, Jaromir
------ Original Message ------ From "Jaromir Matas" <mail@jaromir.netmailto:mail@jaromir.net> To "Eliot Miranda" <eliot.miranda@gmail.commailto:eliot.miranda@gmail.com>; "The general-purpose Squeak developers list" <squeak-dev@lists.squeakfoundation.orgmailto:squeak-dev@lists.squeakfoundation.org> Date 11/17/2023 10:15:17 AM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Eliot,
------ Original Message ------ From "Eliot Miranda" <eliot.miranda@gmail.commailto:eliot.miranda@gmail.com> To "Jaromir Matas" <mail@jaromir.netmailto:mail@jaromir.net> Cc "The general-purpose Squeak developers list" <squeak-dev@lists.squeakfoundation.orgmailto:squeak-dev@lists.squeakfoundation.org> Date 11/16/2023 11:52:45 PM Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas <mail@jaromir.netmailto:mail@jaromir.net> wrote: Hi Nicolas, Eliot,
here's what I understand is happening (see the enclosed screenshot):
1) we fork a new process to evaluate [^1] 2) the new process evaluates [^1] which means instruction 18 is being evaluated, hence pc points to instruction 19 now 3) however, the home context where ^1 should return to is gone by this time (the process that executed the fork has already returned - notice the two up arrows in the debugger screenshot) 4) the VM can't finish the instruction and returns control to the image via placing the #cannotReturn: context on top of the [^1] context 5) #cannotReturn: evaluation results in signalling the BCR exception which is then handled by the #resume handler (in our debugged case the [:ex | self halt. ex resume] handler) 6) ex resume is evaluated, however, this means requesting the VM to evaluate instruction 19 of the [^1] context - which is past the last instruction of the context and the crash ensues
I wonder whether such situations could/should be prevented inside the VM or whether such an expectation is wrong for some reason.
As Nicolas says, IMO this is best done at the image level.
It could be prevented in the VM, but at great cost, and only partially. The performance issue is that the last bytecode in a method is not marked in any way, and that to determine the last bytecode the bytecodes must be symbolically evaluated from the start of the method. See implementors of endPC at the image level (which defer to the method trailer) and implementors of endPCOf: in the VMMaker code. Doing this every time execution commences is prohibitively expensive. The "only partially" issue is that following the return instruction may be other valid bytecodes, but these are not a continuation.
Consider the following code in some block: [self expression ifTrue: [^1]. ^2
The bytecodes for this are pushReceiver send #expression jumpFalse L1 push 1 methodReturnTop L1 push 2 methodReturnTop
Clearly if expression is true these should be *no* continuation in which ^2 is executed.
Well, in that case there's a bug because the computation in the following example shouldn't continue past the [^1] block but it silently does: `[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork`
The bytecodes are push true jumpFalse L1 push 1 returnTop L1 push nil blockReturn
So even if the VM did try and detect whether the return was at the last block method, it would only work for special cases.
It seems to me the issue is simply that the context that cannot be returned from should be marked as dead (see Context>>isDead) by setting its pc to nil at some point, presumably after copying the actual return pc into the BlockCannotReturn exception, to avoid ever trying to resume the context.
Does this mean, in other words, that every context that returns should nil its pc to avoid being "wrongly" reused/executed in the future, which concerns primarily those being referenced somewhere hence potentially executable in the future, is that right? Hypothetical question: would nilling the pc during returns "fix" the example? Thanks a lot for helping me understand this. Best, Jaromir
Thanks, Jaromir
<bdxuqalu.png>
------ Original Message ------ From "Eliot Miranda" <eliot.miranda@gmail.commailto:eliot.miranda@gmail.com> To "Jaromir Matas" <mail@jaromir.netmailto:mail@jaromir.net>; "The general-purpose Squeak developers list" <squeak-dev@lists.squeakfoundation.orgmailto:squeak-dev@lists.squeakfoundation.org> Date 11/16/2023 6:48:43 PM Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On Nov 16, 2023, at 3:23 AM, Jaromir Matas <mail@jaromir.netmailto:mail@jaromir.net> wrote:
Hi Nicloas, No no, I don't have any practical scenario in mind, I'm just trying to understand why the VM is implemented like this, whether there were a reason to leave this possibility of a crash, e.g. it would slow down the VM to try to prevent such a dumb situation (who would resume from BCR in his right mind? :) ) - or perhaps I have overlooked some good reason to even keep this behavior in the VM. That's all.
Let’s first understand what’s really happening. Presumably at tone point a context is resumed those pc is already at the block return bytecode (effectively, because it crashes in JITted code, but I bet the stack vm will crash also, but not as cleanly - it will try and execute the bytes in the encoded method trailer). So which method actually sends resume, and to what, and what state is resume’s receiver when resume is sent?
Thanks for your reply. Regards, Jaromir
------ Original Message ------ From "Nicolas Cellier" <nicolas.cellier.aka.nice@gmail.commailto:nicolas.cellier.aka.nice@gmail.com> To "Jaromir Matas" <mail@jaromir.netmailto:mail@jaromir.net>; "The general-purpose Squeak developers list" <squeak-dev@lists.squeakfoundation.orgmailto:squeak-dev@lists.squeakfoundation.org> Date 11/16/2023 7:20:20 AM Subject Re: [squeak-dev] Resuming on BlockCannotReturn exception
Hi Jaromir, Is there a scenario where it would make sense to resume a BlockCannotReturn? If not, I would suggest to protect at image side and override #resume.
Le mer. 15 nov. 2023, 23:42, Jaromir Matas <mail@jaromir.netmailto:mail@jaromir.net> a écrit : Hi Eliot, Christoph, All,
It's known the following example crashes the VM. Is this an intended behavior or a "tolerated bug"?
`[[^ 1] on: BlockCannotReturn do: #resume] fork`
I understand why it crashes: the non-local return has nowhere to return to and so resuming the computation leads to a crash. But why not raise another BCR exception to prevent the crash? Potential infinite loop? Perhaps I'm just missing the purpose of this behavior...
Thanks for an explanation.
Best, Jaromir
--
Jaromir Matas
-- _,,,^..^,,,_ best, Eliot <Context-cannotReturn.st>
-- _,,,^..^,,,_ best, Eliot <ProcessTest-testResumeAfterBCR.st>
Hi Eliot, hi all --
Done. See Tools-mt.1241 and System-mt.1436.
To make use of this new possibility, see senders of #todoDebugger.
StandardToolSet class >> #handleError: StandardToolSet class >> #handleWarning: Debugger class >> #openOnCue:
Put new stuff into DebuggerInvocationCue in #handleError: and/or #handleWarning: and extract it in the debugger's #openOnCue:.
Happy Squeaking! :-)
Best, Marcel
Am 28.11.2023 08:45:07 schrieb Marcel marcel.taeumel@hpi.uni-potsdam.de:
Hi all --
I just want to repeat what I said in that other thread here: - http://lists.squeakfoundation.org/archives/list/squeak-dev@lists.squeakfound...
1) I like the idea of keeping the exception object around during the debugging activity. We should store it in the process-to-debug. That's our current "debugger invocation cue" object, we already have.
2) We must ensure that the Debugger class remains replaceable. It is just a GUI tool. The control-flow mechanics are in Context/Process, Exception, ToolSet, Project.
Best, Marcel
Am 28.11.2023 01:29:39 schrieb Jaromir Matas mail@jaromir.net:
Hi Eliot, Marcel, all,
I've sent a fix Kernel-jar.1539 to the Inbox that solves the remaining bit of the chain of bugs described in the previous post. All tests are green now and I think the root cause has been found and fixed.
In this last bit I've created a version of stepToCallee that would identify a potential illegal return to a nil sender and avoid it.
Now this example can be debugged without any problems:
[[self halt. ^ 1] on: BlockCannotReturn do: #resume ] fork
If you're happy with the solution in Kernel-jar.1539, Kernel-jar.1538, Kernel-jar.1537 and the test in KernelTests-jar.447, could you please double-check and merge, please? (And remove Kernel-mt.1534 and Tools-jar.1240 from the Inbox)
Best, Jaromir
On 27-Nov-23 12:09:37 AM, "Jaromir Matas" <mail@jaromir.netmailto:mail@jaromir.net> wrote:
Hi Eliot, Christoph, all
It looks like there are some more skeletons in the closet :/
If you run this example
[[self halt. ^ 1] on: BlockCannotReturn do: [:ex | ex resume] ] fork
and step over halt and then step over ^1 you get a nonsensical error as a result of decoding nil as an instruction.
It turns out that the root cause is in the #return:from: method: it only checks whether aSender is dead but ignores the possibility that aSender sender may be nil or dead in which cases the VM also responds with sending #cannotReturn, hence I assume the simulator should do the same. In addition, the VM nills the pc in such scenario, so I added the same functionality here too:
Context >> return: value from: aSender "For simulation. Roll back self to aSender and return value from it. Execute any unwind blocks on the way. ASSUMES aSender is a sender of self"
| newTop | newTop := aSender sender. (aSender isDead or: [newTop isNil or: [newTop isDead]]) ifTrue: "<--------- this is extended ------" [^self pc: nil; send: #cannotReturn: to: self with: {value}]. "<------ pc: nil is added ----" (self findNextUnwindContextUpTo: newTop) ifNotNil: "Send #aboutToReturn:through: with nil as the second argument to avoid this bug: Cannot #stepOver '^2' in example '[^2] ensure: []'. See http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html" [^self send: #aboutToReturn:through: to: self with: {value. nil}]. self releaseTo: newTop. newTop ifNotNil: [newTop push: value]. ^newTop
In order for this to work #cannotReturn: has to be modified as in Kernel-jar.1537:
Context >> cannotReturn: result
closureOrNil ifNotNil: [^ self cannotReturn: result to: self home sender]. self error: 'Computation has been terminated!' "<----------- this has to be an Error -----"
Then it almost works except when you keep stepping over in the example above, you get an MNU error on `self previousPc` in #cannotReturn:to:` with your solution of the VM crash. If you don't mind I've amended your solution and added the final context where the computation couldn't return along with the pc:
Context >> cannotReturn: result to: homeContext "The receiver tried to return result to homeContext that cannot be returned from. Capture the return context/pc in a BlockCannotReturn. Nil the pc to prevent repeat attempts and/or invalid continuation. Answer the result of raising the exception."
| exception previousPc | exception := BlockCannotReturn new. previousPc := pc ifNotNil: [self previousPc]. "<----- here's a fix ----" exception result: result; deadHome: homeContext; finalContext: self; "<----- here's the new state, if that's fine ----" pc: previousPc. pc := nil. ^exception signal
Unfortunately, this is still not the end of the story: there are situations where #runUntilErrorOrReturnFrom: places the two guard contexts below the bottom context. And that is a problem because when the method tries to remove the two guard contexts before returning at the end it uses #stepToCalee to do the job but this unforotunately was (ab)using the above bug in #return:from: - I'll explain: #return:from: didn't check whether aSender sender was nil and as a result it allowed to simulate a return to a "nil context" which was then (ab)used in the clean-up via #stepToCalee in the #runUntilErrorOrReturnFrom:.
When I fixed the #return:from: bug, the #runUntilErrorOrReturnFrom: cleanup of the guard contexts no longer works in that very special case where the guard contexts are below the bottom context. There's one case where this is being used: #terminateAggresively by Christoph.
If I'm right with this analysis, the #runUntilErrorOrReturnFrom: should get fixed too but I'll be away now for a few days and I won't be able to respond. If you or Christoph had a chance to take a look at Kernel-jar.1538 and Kernel-jar.1537 I'd be very grateful. I hope this super long message at least makes some sense :) Best, Jaromir
[1] Kernel-jar.1538, Kernel-jar.1537 [2] KernelTests-jar.447
PS: Christoph,
With Kernel-jar.1538 + Kernel-jar.1537 your example
process := [(c := thisContext) pc: nil. 2+3] newProcess. process runUntil: [:ctx | ctx selector = #cannotReturn:]. self assert: process suspendedContext sender sender = c. self assert: process suspendedContext arguments = {c}.
works fine, I've just corrected your first assert.
On 21-Nov-23 6:40:32 PM, "Eliot Miranda" <eliot.miranda@gmail.commailto:eliot.miranda@gmail.com> wrote:
Hi Jaromir,
On Nov 20, 2023, at 11:51 PM, Jaromir Matas <mail@jaromir.netmailto:mail@jaromir.net> wrote:
Hi Eliot, Very elegant! Now I finally got what you meant exactly :) Thanks.
Two questions: 1. in order for the enclosed test to work I'd need an Error instead of Processor debugWithTitle:full: call in #cannotReturn:. Otherwise I don't know how to catch a plain invocation of the Debugger:
cannotReturn: result
closureOrNil ifNotNil: [^ self cannotReturn: result to: self home sender]. self error: 'Computation has been terminated!'
Much nicer.
2. We are capturing a pc of self which is completely different context from homeContext indeed.
Right. The return is attempted from a specific return bytecode in a specific block. This is the coordinate of the return that cannot be made. This is the relevant point of origin of the cannot return exception.
Why the return fails is another matter: - the home context’s sender is a dead context (cannot be resumed) - the home context’s sender is nil (home already returned from) - the block activation’s home is nil rather than a context (should not happen)
But in all these cases the pc of the home context is immaterial. The hike is being returned through/from, rather than from; the home’s pc is not relevant.
Maybe we could capture self in the exception too to make it more clear/explicit what is going on: what context the captured pc is actually associated with. Just a thought...
Yes, I like that. I also like the idea of somehow passing the block activation’s pc to the debugger so that the relevant return expression is highlighted in the debugger.
Thanks again, Jaromir
You’re welcome. I love working in this part of the system. Thanks for dragging me there. I’m in a slump right now and appreciate the fellowship.
------ Original Message ------ From "Eliot Miranda" <eliot.miranda@gmail.commailto:eliot.miranda@gmail.com> To "Jaromir Matas" <mail@jaromir.netmailto:mail@jaromir.net> Cc squeak-dev@lists.squeakfoundation.orgmailto:squeak-dev@lists.squeakfoundation.org Date 11/21/2023 2:17:21 AM Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
see Kernel-eem.1535 for what I was suggesting. This example now has an exception with the right pc value in it:
[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] fork
The fix is simply
Context>>cannotReturn: result to: homeContext "The receiver tried to return result to homeContext that cannot be returned from. Capture the return pc in a BlockCannotReturn. Nil the pc to prevent repeat attempts and/or invalid continuation. Answer the result of raising the exception."
| exception | exception := BlockCannotReturn new. exception result: result; deadHome: homeContext; pc: self previousPc. pc := nil. ^exception signal
The VM crash is now avoided. The debugger displays the method, but does not highlight the offending pc, which is no big deal. A suitable defaultHandler for B lockCannotReturn may be able to get the debugger to highlight correctly on opening. Try the following examples:
[[^1] on: BlockCannotReturn do: #resume] fork.
[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] fork
[[^1] value] fork.
They al; seem to behave perfectly acceptably to me. Does this fix work for you?
On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas <mail@jaromir.netmailto:mail@jaromir.net> wrote: Hi Eliot,
How about to nil the pc just before making the return: ``` Context >> #cannotReturn: result
self push: self pc. "backup the pc for the sake of debugging" closureOrNil ifNotNil: [^self cannotReturn: result to: self home sender; pc: nil]. Processor debugWithTitle: 'Computation has been terminated!' translated full: false ``` The nilled pc should not even potentially interfere with the #isDead now.
I hope this is at least a step in the right direction :)
However, there's still a problem when debugging the resumption of #cannotReturn because the encoders expect a reasonable index. I haven't figured out yet where to place a nil check - #step, #stepToSendOrReturn... ?
Thanks again, Jaromir
------ Original Message ------ From "Eliot Miranda" <eliot.miranda@gmail.commailto:eliot.miranda@gmail.com> To "Jaromir Matas" <mail@jaromir.netmailto:mail@jaromir.net> Date 11/17/2023 8:36:50 PM Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On Nov 17, 2023, at 7:05 AM, Jaromir Matas <mail@jaromir.netmailto:mail@jaromir.net> wrote:
Eliot, hi again,
Please disregard my previous comment about nilling the contexts that have returned. We are indeed talking about the context directly under the #cannotReturn context which is totally different from the home context in another thread that's gone.
I may still be confused but would nilling the pc of the context directly under the cannotReturn context help? Here's what I mean: ``` Context >> #cannotReturn: result
closureOrNil ifNotNil: [^self pc: nil; cannotReturn: result to: self home sender]. Processor debugWithTitle: 'Computation has been terminated!' translated full: false. ``` Instead of crashing the VM invokes the debugger with the 'Computation has been terminated!' message.
Does this make sense?
Nearly. But it loses the information on what the pc actually is, and that’s potentially vital information. So IMO the ox should only be nilled between the BlockCannotReturn exception being created and raised.
[But if you try this don’t be surprised if it causes a few temporary problems. It looks to me that without a little refactoring this could easily cause an infinite recursion around the sending of isDead. I’m sure you’ll be able to fix the code to work correctly]
Thanks, Jaromir
------ Original Message ------ From "Jaromir Matas" <mail@jaromir.netmailto:mail@jaromir.net> To "Eliot Miranda" <eliot.miranda@gmail.commailto:eliot.miranda@gmail.com>; "The general-purpose Squeak developers list" <squeak-dev@lists.squeakfoundation.orgmailto:squeak-dev@lists.squeakfoundation.org> Date 11/17/2023 10:15:17 AM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Eliot,
------ Original Message ------ From "Eliot Miranda" <eliot.miranda@gmail.commailto:eliot.miranda@gmail.com> To "Jaromir Matas" <mail@jaromir.netmailto:mail@jaromir.net> Cc "The general-purpose Squeak developers list" <squeak-dev@lists.squeakfoundation.orgmailto:squeak-dev@lists.squeakfoundation.org> Date 11/16/2023 11:52:45 PM Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas <mail@jaromir.netmailto:mail@jaromir.net> wrote: Hi Nicolas, Eliot,
here's what I understand is happening (see the enclosed screenshot):
1) we fork a new process to evaluate [^1] 2) the new process evaluates [^1] which means instruction 18 is being evaluated, hence pc points to instruction 19 now 3) however, the home context where ^1 should return to is gone by this time (the process that executed the fork has already returned - notice the two up arrows in the debugger screenshot) 4) the VM can't finish the instruction and returns control to the image via placing the #cannotReturn: context on top of the [^1] context 5) #cannotReturn: evaluation results in signalling the BCR exception which is then handled by the #resume handler (in our debugged case the [:ex | self halt. ex resume] handler) 6) ex resume is evaluated, however, this means requesting the VM to evaluate instruction 19 of the [^1] context - which is past the last instruction of the context and the crash ensues
I wonder whether such situations could/should be prevented inside the VM or whether such an expectation is wrong for some reason.
As Nicolas says, IMO this is best done at the image level.
It could be prevented in the VM, but at great cost, and only partially. The performance issue is that the last bytecode in a method is not marked in any way, and that to determine the last bytecode the bytecodes must be symbolically evaluated from the start of the method. See implementors of endPC at the image level (which defer to the method trailer) and implementors of endPCOf: in the VMMaker code. Doing this every time execution commences is prohibitively expensive. The "only partially" issue is that following the return instruction may be other valid bytecodes, but these are not a continuation.
Consider the following code in some block: [self expression ifTrue: [^1]. ^2
The bytecodes for this are pushReceiver send #expression jumpFalse L1 push 1 methodReturnTop L1 push 2 methodReturnTop
Clearly if expression is true these should be *no* continuation in which ^2 is executed.
Well, in that case there's a bug because the computation in the following example shouldn't continue past the [^1] block but it silently does: `[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork`
The bytecodes are push true jumpFalse L1 push 1 returnTop L1 push nil blockReturn
So even if the VM did try and detect whether the return was at the last block method, it would only work for special cases.
It seems to me the issue is simply that the context that cannot be returned from should be marked as dead (see Context>>isDead) by setting its pc to nil at some point, presumably after copying the actual return pc into the BlockCannotReturn exception, to avoid ever trying to resume the context.
Does this mean, in other words, that every context that returns should nil its pc to avoid being "wrongly" reused/executed in the future, which concerns primarily those being referenced somewhere hence potentially executable in the future, is that right? Hypothetical question: would nilling the pc during returns "fix" the example? Thanks a lot for helping me understand this. Best, Jaromir
Thanks, Jaromir
<bdxuqalu.png>
------ Original Message ------ From "Eliot Miranda" <eliot.miranda@gmail.commailto:eliot.miranda@gmail.com> To "Jaromir Matas" <mail@jaromir.netmailto:mail@jaromir.net>; "The general-purpose Squeak developers list" <squeak-dev@lists.squeakfoundation.orgmailto:squeak-dev@lists.squeakfoundation.org> Date 11/16/2023 6:48:43 PM Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On Nov 16, 2023, at 3:23 AM, Jaromir Matas <mail@jaromir.netmailto:mail@jaromir.net> wrote:
Hi Nicloas, No no, I don't have any practical scenario in mind, I'm just trying to understand why the VM is implemented like this, whether there were a reason to leave this possibility of a crash, e.g. it would slow down the VM to try to prevent such a dumb situation (who would resume from BCR in his right mind? :) ) - or perhaps I have overlooked some good reason to even keep this behavior in the VM. That's all.
Let’s first understand what’s really happening. Presumably at tone point a context is resumed those pc is already at the block return bytecode (effectively, because it crashes in JITted code, but I bet the stack vm will crash also, but not as cleanly - it will try and execute the bytes in the encoded method trailer). So which method actually sends resume, and to what, and what state is resume’s receiver when resume is sent?
Thanks for your reply. Regards, Jaromir
------ Original Message ------ From "Nicolas Cellier" <nicolas.cellier.aka.nice@gmail.commailto:nicolas.cellier.aka.nice@gmail.com> To "Jaromir Matas" <mail@jaromir.netmailto:mail@jaromir.net>; "The general-purpose Squeak developers list" <squeak-dev@lists.squeakfoundation.orgmailto:squeak-dev@lists.squeakfoundation.org> Date 11/16/2023 7:20:20 AM Subject Re: [squeak-dev] Resuming on BlockCannotReturn exception
Hi Jaromir, Is there a scenario where it would make sense to resume a BlockCannotReturn? If not, I would suggest to protect at image side and override #resume.
Le mer. 15 nov. 2023, 23:42, Jaromir Matas <mail@jaromir.netmailto:mail@jaromir.net> a écrit : Hi Eliot, Christoph, All,
It's known the following example crashes the VM. Is this an intended behavior or a "tolerated bug"?
`[[^ 1] on: BlockCannotReturn do: #resume] fork`
I understand why it crashes: the non-local return has nowhere to return to and so resuming the computation leads to a crash. But why not raise another BCR exception to prevent the crash? Potential infinite loop? Perhaps I'm just missing the purpose of this behavior...
Thanks for an explanation.
Best, Jaromir
--
Jaromir Matas
-- _,,,^..^,,,_ best, Eliot <Context-cannotReturn.st>
-- _,,,^..^,,,_ best, Eliot <ProcessTest-testResumeAfterBCR.st>
Hi Jaromir --
Looks good. Still, what about that #test16HandleSimulationError now? :-) It is failing with your changes ... how would you adapt it?
[cid:56402995-0457-43bc-933e-b41f524594f7]
Best, Marcel
Am 28.11.2023 01:29:39 schrieb Jaromir Matas mail@jaromir.net:
Hi Eliot, Marcel, all,
I've sent a fix Kernel-jar.1539 to the Inbox that solves the remaining bit of the chain of bugs described in the previous post. All tests are green now and I think the root cause has been found and fixed.
In this last bit I've created a version of stepToCallee that would identify a potential illegal return to a nil sender and avoid it.
Now this example can be debugged without any problems:
[[self halt. ^ 1] on: BlockCannotReturn do: #resume ] fork
If you're happy with the solution in Kernel-jar.1539, Kernel-jar.1538, Kernel-jar.1537 and the test in KernelTests-jar.447, could you please double-check and merge, please? (And remove Kernel-mt.1534 and Tools-jar.1240 from the Inbox)
Best, Jaromir
On 27-Nov-23 12:09:37 AM, "Jaromir Matas" <mail@jaromir.netmailto:mail@jaromir.net> wrote:
Hi Eliot, Christoph, all
It looks like there are some more skeletons in the closet :/
If you run this example
[[self halt. ^ 1] on: BlockCannotReturn do: [:ex | ex resume] ] fork
and step over halt and then step over ^1 you get a nonsensical error as a result of decoding nil as an instruction.
It turns out that the root cause is in the #return:from: method: it only checks whether aSender is dead but ignores the possibility that aSender sender may be nil or dead in which cases the VM also responds with sending #cannotReturn, hence I assume the simulator should do the same. In addition, the VM nills the pc in such scenario, so I added the same functionality here too:
Context >> return: value from: aSender "For simulation. Roll back self to aSender and return value from it. Execute any unwind blocks on the way. ASSUMES aSender is a sender of self"
| newTop | newTop := aSender sender. (aSender isDead or: [newTop isNil or: [newTop isDead]]) ifTrue: "<--------- this is extended ------" [^self pc: nil; send: #cannotReturn: to: self with: {value}]. "<------ pc: nil is added ----" (self findNextUnwindContextUpTo: newTop) ifNotNil: "Send #aboutToReturn:through: with nil as the second argument to avoid this bug: Cannot #stepOver '^2' in example '[^2] ensure: []'. See http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html" [^self send: #aboutToReturn:through: to: self with: {value. nil}]. self releaseTo: newTop. newTop ifNotNil: [newTop push: value]. ^newTop
In order for this to work #cannotReturn: has to be modified as in Kernel-jar.1537:
Context >> cannotReturn: result
closureOrNil ifNotNil: [^ self cannotReturn: result to: self home sender]. self error: 'Computation has been terminated!' "<----------- this has to be an Error -----"
Then it almost works except when you keep stepping over in the example above, you get an MNU error on `self previousPc` in #cannotReturn:to:` with your solution of the VM crash. If you don't mind I've amended your solution and added the final context where the computation couldn't return along with the pc:
Context >> cannotReturn: result to: homeContext "The receiver tried to return result to homeContext that cannot be returned from. Capture the return context/pc in a BlockCannotReturn. Nil the pc to prevent repeat attempts and/or invalid continuation. Answer the result of raising the exception."
| exception previousPc | exception := BlockCannotReturn new. previousPc := pc ifNotNil: [self previousPc]. "<----- here's a fix ----" exception result: result; deadHome: homeContext; finalContext: self; "<----- here's the new state, if that's fine ----" pc: previousPc. pc := nil. ^exception signal
Unfortunately, this is still not the end of the story: there are situations where #runUntilErrorOrReturnFrom: places the two guard contexts below the bottom context. And that is a problem because when the method tries to remove the two guard contexts before returning at the end it uses #stepToCalee to do the job but this unforotunately was (ab)using the above bug in #return:from: - I'll explain: #return:from: didn't check whether aSender sender was nil and as a result it allowed to simulate a return to a "nil context" which was then (ab)used in the clean-up via #stepToCalee in the #runUntilErrorOrReturnFrom:.
When I fixed the #return:from: bug, the #runUntilErrorOrReturnFrom: cleanup of the guard contexts no longer works in that very special case where the guard contexts are below the bottom context. There's one case where this is being used: #terminateAggresively by Christoph.
If I'm right with this analysis, the #runUntilErrorOrReturnFrom: should get fixed too but I'll be away now for a few days and I won't be able to respond. If you or Christoph had a chance to take a look at Kernel-jar.1538 and Kernel-jar.1537 I'd be very grateful. I hope this super long message at least makes some sense :) Best, Jaromir
[1] Kernel-jar.1538, Kernel-jar.1537 [2] KernelTests-jar.447
PS: Christoph,
With Kernel-jar.1538 + Kernel-jar.1537 your example
process := [(c := thisContext) pc: nil. 2+3] newProcess. process runUntil: [:ctx | ctx selector = #cannotReturn:]. self assert: process suspendedContext sender sender = c. self assert: process suspendedContext arguments = {c}.
works fine, I've just corrected your first assert.
On 21-Nov-23 6:40:32 PM, "Eliot Miranda" <eliot.miranda@gmail.commailto:eliot.miranda@gmail.com> wrote:
Hi Jaromir,
On Nov 20, 2023, at 11:51 PM, Jaromir Matas <mail@jaromir.netmailto:mail@jaromir.net> wrote:
Hi Eliot, Very elegant! Now I finally got what you meant exactly :) Thanks.
Two questions: 1. in order for the enclosed test to work I'd need an Error instead of Processor debugWithTitle:full: call in #cannotReturn:. Otherwise I don't know how to catch a plain invocation of the Debugger:
cannotReturn: result
closureOrNil ifNotNil: [^ self cannotReturn: result to: self home sender]. self error: 'Computation has been terminated!'
Much nicer.
2. We are capturing a pc of self which is completely different context from homeContext indeed.
Right. The return is attempted from a specific return bytecode in a specific block. This is the coordinate of the return that cannot be made. This is the relevant point of origin of the cannot return exception.
Why the return fails is another matter: - the home context’s sender is a dead context (cannot be resumed) - the home context’s sender is nil (home already returned from) - the block activation’s home is nil rather than a context (should not happen)
But in all these cases the pc of the home context is immaterial. The hike is being returned through/from, rather than from; the home’s pc is not relevant.
Maybe we could capture self in the exception too to make it more clear/explicit what is going on: what context the captured pc is actually associated with. Just a thought...
Yes, I like that. I also like the idea of somehow passing the block activation’s pc to the debugger so that the relevant return expression is highlighted in the debugger.
Thanks again, Jaromir
You’re welcome. I love working in this part of the system. Thanks for dragging me there. I’m in a slump right now and appreciate the fellowship.
------ Original Message ------ From "Eliot Miranda" <eliot.miranda@gmail.commailto:eliot.miranda@gmail.com> To "Jaromir Matas" <mail@jaromir.netmailto:mail@jaromir.net> Cc squeak-dev@lists.squeakfoundation.orgmailto:squeak-dev@lists.squeakfoundation.org Date 11/21/2023 2:17:21 AM Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
see Kernel-eem.1535 for what I was suggesting. This example now has an exception with the right pc value in it:
[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] fork
The fix is simply
Context>>cannotReturn: result to: homeContext "The receiver tried to return result to homeContext that cannot be returned from. Capture the return pc in a BlockCannotReturn. Nil the pc to prevent repeat attempts and/or invalid continuation. Answer the result of raising the exception."
| exception | exception := BlockCannotReturn new. exception result: result; deadHome: homeContext; pc: self previousPc. pc := nil. ^exception signal
The VM crash is now avoided. The debugger displays the method, but does not highlight the offending pc, which is no big deal. A suitable defaultHandler for B lockCannotReturn may be able to get the debugger to highlight correctly on opening. Try the following examples:
[[^1] on: BlockCannotReturn do: #resume] fork.
[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] fork
[[^1] value] fork.
They al; seem to behave perfectly acceptably to me. Does this fix work for you?
On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas <mail@jaromir.netmailto:mail@jaromir.net> wrote: Hi Eliot,
How about to nil the pc just before making the return: ``` Context >> #cannotReturn: result
self push: self pc. "backup the pc for the sake of debugging" closureOrNil ifNotNil: [^self cannotReturn: result to: self home sender; pc: nil]. Processor debugWithTitle: 'Computation has been terminated!' translated full: false ``` The nilled pc should not even potentially interfere with the #isDead now.
I hope this is at least a step in the right direction :)
However, there's still a problem when debugging the resumption of #cannotReturn because the encoders expect a reasonable index. I haven't figured out yet where to place a nil check - #step, #stepToSendOrReturn... ?
Thanks again, Jaromir
------ Original Message ------ From "Eliot Miranda" <eliot.miranda@gmail.commailto:eliot.miranda@gmail.com> To "Jaromir Matas" <mail@jaromir.netmailto:mail@jaromir.net> Date 11/17/2023 8:36:50 PM Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On Nov 17, 2023, at 7:05 AM, Jaromir Matas <mail@jaromir.netmailto:mail@jaromir.net> wrote:
Eliot, hi again,
Please disregard my previous comment about nilling the contexts that have returned. We are indeed talking about the context directly under the #cannotReturn context which is totally different from the home context in another thread that's gone.
I may still be confused but would nilling the pc of the context directly under the cannotReturn context help? Here's what I mean: ``` Context >> #cannotReturn: result
closureOrNil ifNotNil: [^self pc: nil; cannotReturn: result to: self home sender]. Processor debugWithTitle: 'Computation has been terminated!' translated full: false. ``` Instead of crashing the VM invokes the debugger with the 'Computation has been terminated!' message.
Does this make sense?
Nearly. But it loses the information on what the pc actually is, and that’s potentially vital information. So IMO the ox should only be nilled between the BlockCannotReturn exception being created and raised.
[But if you try this don’t be surprised if it causes a few temporary problems. It looks to me that without a little refactoring this could easily cause an infinite recursion around the sending of isDead. I’m sure you’ll be able to fix the code to work correctly]
Thanks, Jaromir
------ Original Message ------ From "Jaromir Matas" <mail@jaromir.netmailto:mail@jaromir.net> To "Eliot Miranda" <eliot.miranda@gmail.commailto:eliot.miranda@gmail.com>; "The general-purpose Squeak developers list" <squeak-dev@lists.squeakfoundation.orgmailto:squeak-dev@lists.squeakfoundation.org> Date 11/17/2023 10:15:17 AM Subject [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Eliot,
------ Original Message ------ From "Eliot Miranda" <eliot.miranda@gmail.commailto:eliot.miranda@gmail.com> To "Jaromir Matas" <mail@jaromir.netmailto:mail@jaromir.net> Cc "The general-purpose Squeak developers list" <squeak-dev@lists.squeakfoundation.orgmailto:squeak-dev@lists.squeakfoundation.org> Date 11/16/2023 11:52:45 PM Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas <mail@jaromir.netmailto:mail@jaromir.net> wrote: Hi Nicolas, Eliot,
here's what I understand is happening (see the enclosed screenshot):
1) we fork a new process to evaluate [^1] 2) the new process evaluates [^1] which means instruction 18 is being evaluated, hence pc points to instruction 19 now 3) however, the home context where ^1 should return to is gone by this time (the process that executed the fork has already returned - notice the two up arrows in the debugger screenshot) 4) the VM can't finish the instruction and returns control to the image via placing the #cannotReturn: context on top of the [^1] context 5) #cannotReturn: evaluation results in signalling the BCR exception which is then handled by the #resume handler (in our debugged case the [:ex | self halt. ex resume] handler) 6) ex resume is evaluated, however, this means requesting the VM to evaluate instruction 19 of the [^1] context - which is past the last instruction of the context and the crash ensues
I wonder whether such situations could/should be prevented inside the VM or whether such an expectation is wrong for some reason.
As Nicolas says, IMO this is best done at the image level.
It could be prevented in the VM, but at great cost, and only partially. The performance issue is that the last bytecode in a method is not marked in any way, and that to determine the last bytecode the bytecodes must be symbolically evaluated from the start of the method. See implementors of endPC at the image level (which defer to the method trailer) and implementors of endPCOf: in the VMMaker code. Doing this every time execution commences is prohibitively expensive. The "only partially" issue is that following the return instruction may be other valid bytecodes, but these are not a continuation.
Consider the following code in some block: [self expression ifTrue: [^1]. ^2
The bytecodes for this are pushReceiver send #expression jumpFalse L1 push 1 methodReturnTop L1 push 2 methodReturnTop
Clearly if expression is true these should be *no* continuation in which ^2 is executed.
Well, in that case there's a bug because the computation in the following example shouldn't continue past the [^1] block but it silently does: `[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] fork`
The bytecodes are push true jumpFalse L1 push 1 returnTop L1 push nil blockReturn
So even if the VM did try and detect whether the return was at the last block method, it would only work for special cases.
It seems to me the issue is simply that the context that cannot be returned from should be marked as dead (see Context>>isDead) by setting its pc to nil at some point, presumably after copying the actual return pc into the BlockCannotReturn exception, to avoid ever trying to resume the context.
Does this mean, in other words, that every context that returns should nil its pc to avoid being "wrongly" reused/executed in the future, which concerns primarily those being referenced somewhere hence potentially executable in the future, is that right? Hypothetical question: would nilling the pc during returns "fix" the example? Thanks a lot for helping me understand this. Best, Jaromir
Thanks, Jaromir
<bdxuqalu.png>
------ Original Message ------ From "Eliot Miranda" <eliot.miranda@gmail.commailto:eliot.miranda@gmail.com> To "Jaromir Matas" <mail@jaromir.netmailto:mail@jaromir.net>; "The general-purpose Squeak developers list" <squeak-dev@lists.squeakfoundation.orgmailto:squeak-dev@lists.squeakfoundation.org> Date 11/16/2023 6:48:43 PM Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
On Nov 16, 2023, at 3:23 AM, Jaromir Matas <mail@jaromir.netmailto:mail@jaromir.net> wrote:
Hi Nicloas, No no, I don't have any practical scenario in mind, I'm just trying to understand why the VM is implemented like this, whether there were a reason to leave this possibility of a crash, e.g. it would slow down the VM to try to prevent such a dumb situation (who would resume from BCR in his right mind? :) ) - or perhaps I have overlooked some good reason to even keep this behavior in the VM. That's all.
Let’s first understand what’s really happening. Presumably at tone point a context is resumed those pc is already at the block return bytecode (effectively, because it crashes in JITted code, but I bet the stack vm will crash also, but not as cleanly - it will try and execute the bytes in the encoded method trailer). So which method actually sends resume, and to what, and what state is resume’s receiver when resume is sent?
Thanks for your reply. Regards, Jaromir
------ Original Message ------ From "Nicolas Cellier" <nicolas.cellier.aka.nice@gmail.commailto:nicolas.cellier.aka.nice@gmail.com> To "Jaromir Matas" <mail@jaromir.netmailto:mail@jaromir.net>; "The general-purpose Squeak developers list" <squeak-dev@lists.squeakfoundation.orgmailto:squeak-dev@lists.squeakfoundation.org> Date 11/16/2023 7:20:20 AM Subject Re: [squeak-dev] Resuming on BlockCannotReturn exception
Hi Jaromir, Is there a scenario where it would make sense to resume a BlockCannotReturn? If not, I would suggest to protect at image side and override #resume.
Le mer. 15 nov. 2023, 23:42, Jaromir Matas <mail@jaromir.netmailto:mail@jaromir.net> a écrit : Hi Eliot, Christoph, All,
It's known the following example crashes the VM. Is this an intended behavior or a "tolerated bug"?
`[[^ 1] on: BlockCannotReturn do: #resume] fork`
I understand why it crashes: the non-local return has nowhere to return to and so resuming the computation leads to a crash. But why not raise another BCR exception to prevent the crash? Potential infinite loop? Perhaps I'm just missing the purpose of this behavior...
Thanks for an explanation.
Best, Jaromir
--
Jaromir Matas
-- _,,,^..^,,,_ best, Eliot <Context-cannotReturn.st>
-- _,,,^..^,,,_ best, Eliot <ProcessTest-testResumeAfterBCR.st>
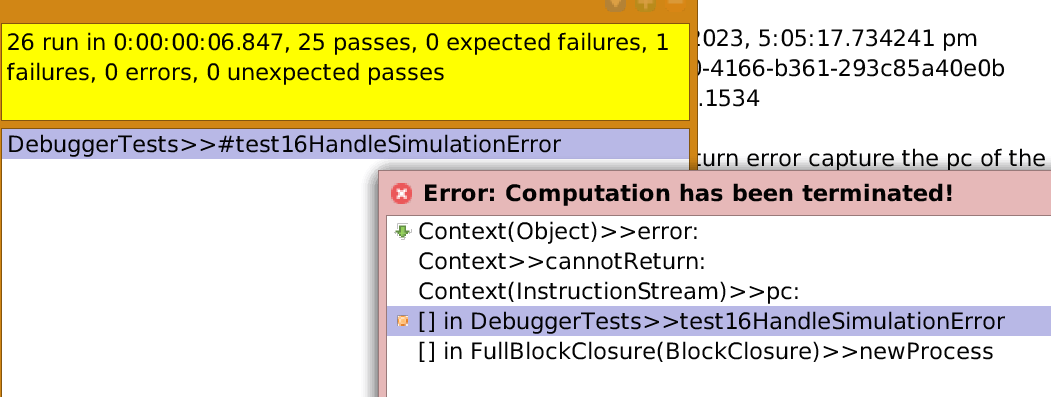{kind=link}
Thanks Marcel! This test somehow slipped my attention :)
The test can no longer work as is. It takes advantage of the erroneous behavior of #return:from: in the sense that if you simulate
thisContext pc: nil
it'll happily return to a dead context (i.e. to thisContext from #pc: nil context) - which is not what the VM does during runtime. It should immediately raise an illegal return exception not only during runtime but also during simulation.
The test mentions a patch for an infinite debugger chain (http://forum.world.st/I-broke-the-debugger-td5110752.html). I wonder whether the problem could have something to do with this simulation bug in return:from:; and a terrible idea occurred to me whether the patch would have been necessary should the #return:from: had been fixed then ;O
We may potentially come up with more examples like this, even in the trunk, where the bug from #return:from: propagated and was taken advantage of. I've found and fixed #runUntilErrorOrReturnFrom: but more can still be surviving undetected...
I'd place the test into #expectedFailures for now but maybe it's time to remove it; Christoph should decide :)
Thanks again, Jaromir
On 29-Nov-23 10:28:38 AM, "Taeumel, Marcel via Squeak-dev" squeak-dev@lists.squeakfoundation.org wrote:
Hi Jaromir --
Looks good. Still, what about that #test16HandleSimulationError now? :-) It is failing with your changes ... how would you adapt it?
Best, Marcel
Am 28.11.2023 01:29:39 schrieb Jaromir Matas mail@jaromir.net:
Hi Eliot, Marcel, all,
I've sent a fix Kernel-jar.1539 to the Inbox that solves the remaining bit of the chain of bugs described in the previous post. All tests are green now and I think the root cause has been found and fixed.
In this last bit I've created a version of stepToCallee that would identify a potential illegal return to a nil sender and avoid it.
Now this example can be debugged without any problems:
[[self halt. ^ 1] on: BlockCannotReturn do: #resume ] fork
If you're happy with the solution in Kernel-jar.1539, Kernel-jar.1538, Kernel-jar.1537 and the test in KernelTests-jar.447, could you please double-check and merge, please? (And remove Kernel-mt.1534 and Tools-jar.1240 from the Inbox)
Best, Jaromir
On 27-Nov-23 12:09:37 AM, "Jaromir Matas" mail@jaromir.net wrote:
Hi Eliot, Christoph, all
It looks like there are some more skeletons in the closet :/
If you run this example
[[self halt. ^ 1] on: BlockCannotReturn do: [:ex | ex resume] ] fork
and step over halt and then step over ^1 you get a nonsensical error as a result of decoding nil as an instruction.
It turns out that the root cause is in the #return:from: method: it only checks whether aSender is dead but ignores the possibility that aSender sender may be nil or dead in which cases the VM also responds with sending #cannotReturn, hence I assume the simulator should do the same. In addition, the VM nills the pc in such scenario, so I added the same functionality here too:
Context >> return: value from: aSender "For simulation. Roll back self to aSender and return value from it. Execute any unwind blocks on the way. ASSUMES aSender is a sender of self"
| newTop | newTop := aSender sender. (aSender isDead or: [newTop isNil or: [newTop isDead]]) ifTrue:"<--------- this is extended ------" [^self pc: nil; send: #cannotReturn: to: self with: {value}]. "<------ pc: nil is added ----" (self findNextUnwindContextUpTo: newTop) ifNotNil: "Send #aboutToReturn:through: with nil as the second argument to avoid this bug: Cannot #stepOver '^2' in example '[^2] ensure: []'. See http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html" [^self send: #aboutToReturn:through: to: self with: {value. nil}]. self releaseTo: newTop. newTop ifNotNil: [newTop push: value]. ^newTop
In order for this to work #cannotReturn: has to be modified as in Kernel-jar.1537:
Context >> cannotReturn: result
closureOrNil ifNotNil: [^ self cannotReturn: result to: self homesender]. self error: 'Computation has been terminated!' "<----------- this has to be an Error -----"
Then it almost works except when you keep stepping over in the example above, you get an MNU error on `self previousPc` in #cannotReturn:to:` with your solution of the VM crash. If you don't mind I've amended your solution and added the final context where the computation couldn't return along with the pc:
Context >> cannotReturn: result to: homeContext "The receiver tried to return result to homeContext that cannot be returned from. Capture the return context/pc in a BlockCannotReturn. Nil the pc to prevent repeat attempts and/or invalid continuation. Answer the result of raising the exception."
| exception previousPc | exception := BlockCannotReturn new. previousPc := pc ifNotNil: [self previousPc]. "<----- here's afix ----" exception result: result; deadHome: homeContext; finalContext: self; "<----- here's the new state, if that's fine ----" pc: previousPc. pc := nil. ^exception signal
Unfortunately, this is still not the end of the story: there are situations where #runUntilErrorOrReturnFrom: places the two guard contexts below the bottom context. And that is a problem because when the method tries to remove the two guard contexts before returning at the end it uses #stepToCalee to do the job but this unforotunately was (ab)using the above bug in #return:from: - I'll explain: #return:from: didn't check whether aSender sender was nil and as a result it allowed to simulate a return to a "nil context" which was then (ab)used in the clean-up via #stepToCalee in the #runUntilErrorOrReturnFrom:.
When I fixed the #return:from: bug, the #runUntilErrorOrReturnFrom: cleanup of the guard contexts no longer works in that very special case where the guard contexts are below the bottom context. There's one case where this is being used: #terminateAggresively by Christoph.
If I'm right with this analysis, the #runUntilErrorOrReturnFrom: should get fixed too but I'll be away now for a few days and I won't be able to respond. If you or Christoph had a chance to take a look at Kernel-jar.1538 and Kernel-jar.1537 I'd be very grateful. I hope this super long message at least makes some sense :) Best, Jaromir
[1] Kernel-jar.1538, Kernel-jar.1537 [2] KernelTests-jar.447
PS: Christoph,
With Kernel-jar.1538 + Kernel-jar.1537 your example
process := [(c := thisContext) pc: nil. 2+3] newProcess. process runUntil: [:ctx | ctx selector = #cannotReturn:]. self assert: process suspendedContext sender sender = c. self assert: process suspendedContext arguments = {c}.
works fine, I've just corrected your first assert.
On 21-Nov-23 6:40:32 PM, "Eliot Miranda" eliot.miranda@gmail.com wrote:
Hi Jaromir,
On Nov 20, 2023, at 11:51 PM, Jaromir Matas mail@jaromir.net wrote:
Hi Eliot, Very elegant! Now I finally got what you meant exactly :) Thanks.
Two questions:
- in order for the enclosed test to work I'd need an Error instead
of Processor debugWithTitle:full: call in #cannotReturn:. Otherwise I don't know how to catch a plain invocation of the Debugger:
cannotReturn: result
closureOrNil ifNotNil: [^ self cannotReturn: result to: selfhome sender]. self error: 'Computation has been terminated!'
Much nicer.
- We are capturing a pc of self which is completely different
context from homeContext indeed.
Right. The return is attempted from a specific return bytecode in a specific block. This is the coordinate of the return that cannot be made. This is the relevant point of origin of the cannot return exception.
Why the return fails is another matter:
- the home context’s sender is a dead context (cannot be resumed)
- the home context’s sender is nil (home already returned from)
- the block activation’s home is nil rather than a context (should
not happen)
But in all these cases the pc of the home context is immaterial. The hike is being returned through/from, rather than from; the home’s pc is not relevant.
Maybe we could capture self in the exception too to make it more clear/explicit what is going on: what context the captured pc is actually associated with. Just a thought...
Yes, I like that. I also like the idea of somehow passing the block activation’s pc to the debugger so that the relevant return expression is highlighted in the debugger.
Thanks again, Jaromir
You’re welcome. I love working in this part of the system. Thanks for dragging me there. I’m in a slump right now and appreciate the fellowship.
------ Original Message ------ From "Eliot Miranda" eliot.miranda@gmail.com To "Jaromir Matas" mail@jaromir.net Cc squeak-dev@lists.squeakfoundation.org Date 11/21/2023 2:17:21 AM Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn exception
Hi Jaromir,
see Kernel-eem.1535 for what I was suggesting. This example now has an exception with the right pc value in it:
[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] fork
The fix is simply
Context>>cannotReturn: result to: homeContext "The receiver tried to return result to homeContext that cannot be returned from. Capture the return pc in a BlockCannotReturn. Nil the pc to prevent repeat attempts and/or invalid continuation. Answer the result of raising the exception."
| exception | exception := BlockCannotReturn new. exception result: result; deadHome: homeContext; pc: self previousPc. pc := nil. ^exception signalThe VM crash is now avoided. The debugger displays the method, but does not highlight the offending pc, which is no big deal. A suitable defaultHandler for B lockCannotReturn may be able to get the debugger to highlight correctly on opening. Try the following examples:
[[^1] on: BlockCannotReturn do: #resume] fork.
[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] fork
[[^1] value] fork.
They al; seem to behave perfectly acceptably to me. Does this fix work for you?
On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas mail@jaromir.net wrote: >Hi Eliot, > >How about to nil the pc just before making the return: >``` >Context >> #cannotReturn: result > > self push: self pc. "backup the pc for the sake of >debugging" > closureOrNil ifNotNil: [^self cannotReturn: result to: self >home sender; pc: nil]. > Processor debugWithTitle: 'Computation has been terminated!' >translated full: false >``` >The nilled pc should not even potentially interfere with the >#isDead now. > >I hope this is at least a step in the right direction :) > >However, there's still a problem when debugging the resumption of >#cannotReturn because the encoders expect a reasonable index. I >haven't figured out yet where to place a nil check - #step, >#stepToSendOrReturn... ? > >Thanks again, >Jaromir > > >------ Original Message ------ >From "Eliot Miranda" eliot.miranda@gmail.com >To "Jaromir Matas" mail@jaromir.net >Date 11/17/2023 8:36:50 PM >Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn >exception > >>Hi Jaromir, >> >>>On Nov 17, 2023, at 7:05 AM, Jaromir Matas mail@jaromir.net >>>wrote: >>> >>> >>>Eliot, hi again, >>> >>>Please disregard my previous comment about nilling the contexts >>>that have returned. We are indeed talking about the context >>>directly under the #cannotReturn context which is totally >>>different from the home context in another thread that's gone. >>> >>>I may still be confused but would nilling the pc of the context >>>directly under the cannotReturn context help? Here's what I >>>mean: >>>``` >>>Context >> #cannotReturn: result >>> >>> closureOrNil ifNotNil: [^self pc: nil; cannotReturn: result >>>to: self home sender]. >>> Processor debugWithTitle: 'Computation has been >>>terminated!' translated full: false. >>>``` >>>Instead of crashing the VM invokes the debugger with the >>>'Computation has been terminated!' message. >>> >>>Does this make sense? >> >>Nearly. But it loses the information on what the pc actually is, >>and that’s potentially vital information. So IMO the ox should >>only be nilled between the BlockCannotReturn exception being >>created and raised. >> >>[But if you try this don’t be surprised if it causes a few >>temporary problems. It looks to me that without a little >>refactoring this could easily cause an infinite recursion around >>the sending of isDead. I’m sure you’ll be able to fix the code >>to work correctly] >> >>>Thanks, >>>Jaromir >>> >>> >>>------ Original Message ------ >>>From "Jaromir Matas" mail@jaromir.net >>>To "Eliot Miranda" eliot.miranda@gmail.com; "The >>>general-purpose Squeak developers list" >>>squeak-dev@lists.squeakfoundation.org >>>Date 11/17/2023 10:15:17 AM >>>Subject [squeak-dev] Re: Resuming on BlockCannotReturn >>>exception >>> >>>>Hi Eliot, >>>> >>>> >>>> >>>>------ Original Message ------ >>>>From "Eliot Miranda" eliot.miranda@gmail.com >>>>To "Jaromir Matas" mail@jaromir.net >>>>Cc "The general-purpose Squeak developers list" >>>>squeak-dev@lists.squeakfoundation.org >>>>Date 11/16/2023 11:52:45 PM >>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on >>>>BlockCannotReturn exception >>>> >>>>>Hi Jaromir, >>>>> >>>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas >>>>>mail@jaromir.net wrote: >>>>>>Hi Nicolas, Eliot, >>>>>> >>>>>>here's what I understand is happening (see the enclosed >>>>>>screenshot): >>>>>> >>>>>>1) we fork a new process to evaluate [^1] >>>>>>2) the new process evaluates [^1] which means instruction 18 >>>>>>is being evaluated, hence pc points to instruction 19 now >>>>>>3) however, the home context where ^1 should return to is >>>>>>gone by this time (the process that executed the fork has >>>>>>already returned - notice the two up arrows in the debugger >>>>>>screenshot) >>>>>>4) the VM can't finish the instruction and returns control >>>>>>to the image via placing the #cannotReturn: context on top >>>>>>of the [^1] context >>>>>>5) #cannotReturn: evaluation results in signalling the BCR >>>>>>exception which is then handled by the #resume handler >>>>>> (in our debugged case the [:ex | self halt. ex resume] >>>>>>handler) >>>>>>6) ex resume is evaluated, however, this means requesting >>>>>>the VM to evaluate instruction 19 of the [^1] context - >>>>>>which is past the last instruction of the context and the >>>>>>crash ensues >>>>>> >>>>>>I wonder whether such situations could/should be prevented >>>>>>inside the VM or whether such an expectation is wrong for >>>>>>some reason. >>>>> >>>>>As Nicolas says, IMO this is best done at the image level. >>>>> >>>>>It could be prevented in the VM, but at great cost, and only >>>>>partially. The performance issue is that the last bytecode >>>>>in a method is not marked in any way, and that to determine >>>>>the last bytecode the bytecodes must be symbolically >>>>>evaluated from the start of the method. See implementors of >>>>>endPC at the image level (which defer to the method trailer) >>>>>and implementors of endPCOf: in the VMMaker code. Doing this >>>>>every time execution commences is prohibitively expensive. >>>>>The "only partially" issue is that following the return >>>>>instruction may be other valid bytecodes, but these are not a >>>>>continuation. >>>>> >>>>> >>>>>Consider the following code in some block: >>>>> [self expression ifTrue: >>>>> [^1]. >>>>> ^2 >>>>> >>>>>The bytecodes for this are >>>>> pushReceiver >>>>> send #expression >>>>> jumpFalse L1 >>>>> push 1 >>>>> methodReturnTop >>>>>L1 >>>>> push 2 >>>>> methodReturnTop >>>>> >>>>>Clearly if expression is true these should be *no* >>>>>continuation in which ^2 is executed. >>>> >>>>Well, in that case there's a bug because the computation in >>>>the following example shouldn't continue past the [^1] block >>>>but it silently does: >>>>`[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] >>>>fork` >>>> >>>>The bytecodes are >>>> push true >>>> jumpFalse L1 >>>> push 1 >>>> returnTop >>>>L1 >>>> push nil >>>> blockReturn >>>> >>>> >>>> >>>>> >>>>>So even if the VM did try and detect whether the return was >>>>>at the last block method, it would only work for special >>>>>cases. >>>>> >>>>> >>>>>It seems to me the issue is simply that the context that >>>>>cannot be returned from should be marked as dead (see >>>>>Context>>isDead) by setting its pc to nil at some point, >>>>>presumably after copying the actual return pc into the >>>>>BlockCannotReturn exception, to avoid ever trying to resume >>>>>the context. >>>> >>>>Does this mean, in other words, that every context that >>>>returns should nil its pc to avoid being "wrongly" >>>>reused/executed in the future, which concerns primarily those >>>>being referenced somewhere hence potentially executable in the >>>>future, is that right? >>>>Hypothetical question: would nilling the pc during returns >>>>"fix" the example? >>>>Thanks a lot for helping me understand this. >>>>Best, >>>>Jaromir >>>> >>>> >>>> >>>>> >>>>> >>>>>> >>>>>>Thanks, >>>>>>Jaromir >>>>>> >>>>>><bdxuqalu.png> >>>>>> >>>>>>------ Original Message ------ >>>>>>From "Eliot Miranda" eliot.miranda@gmail.com >>>>>>To "Jaromir Matas" mail@jaromir.net; "The general-purpose >>>>>>Squeak developers list" >>>>>>squeak-dev@lists.squeakfoundation.org >>>>>>Date 11/16/2023 6:48:43 PM >>>>>>Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn >>>>>>exception >>>>>> >>>>>>>Hi Jaromir, >>>>>>> >>>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas >>>>>>>>mail@jaromir.net wrote: >>>>>>>> >>>>>>>> >>>>>>>>Hi Nicloas, >>>>>>>>No no, I don't have any practical scenario in mind, I'm >>>>>>>>just trying to understand why the VM is implemented like >>>>>>>>this, whether there were a reason to leave this >>>>>>>>possibility of a crash, e.g. it would slow down the VM to >>>>>>>>try to prevent such a dumb situation (who would resume >>>>>>>>from BCR in his right mind? :) ) - or perhaps I have >>>>>>>>overlooked some good reason to even keep this behavior in >>>>>>>>the VM. That's all. >>>>>>> >>>>>>>Let’s first understand what’s really happening. Presumably >>>>>>>at tone point a context is resumed those pc is already at >>>>>>>the block return bytecode (effectively, because it crashes >>>>>>>in JITted code, but I bet the stack vm will crash also, but >>>>>>>not as cleanly - it will try and execute the bytes in the >>>>>>>encoded method trailer). So which method actually sends >>>>>>>resume, and to what, and what state is resume’s receiver >>>>>>>when resume is sent? >>>>>>> >>>>>>> >>>>>>>> >>>>>>>>Thanks for your reply. >>>>>>>>Regards, >>>>>>>>Jaromir >>>>>>>> >>>>>>>> >>>>>>>> >>>>>>>> >>>>>>>>------ Original Message ------ >>>>>>>>From "Nicolas Cellier" >>>>>>>>nicolas.cellier.aka.nice@gmail.com >>>>>>>>To "Jaromir Matas" mail@jaromir.net; "The >>>>>>>>general-purpose Squeak developers list" >>>>>>>>squeak-dev@lists.squeakfoundation.org >>>>>>>>Date 11/16/2023 7:20:20 AM >>>>>>>>Subject Re: [squeak-dev] Resuming on BlockCannotReturn >>>>>>>>exception >>>>>>>> >>>>>>>>>Hi Jaromir, >>>>>>>>>Is there a scenario where it would make sense to resume a >>>>>>>>>BlockCannotReturn? >>>>>>>>>If not, I would suggest to protect at image side and >>>>>>>>>override #resume. >>>>>>>>> >>>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas >>>>>>>>>mail@jaromir.net a écrit : >>>>>>>>>>Hi Eliot, Christoph, All, >>>>>>>>>> >>>>>>>>>>It's known the following example crashes the VM. Is this >>>>>>>>>>an intended behavior or a "tolerated bug"? >>>>>>>>>> >>>>>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>>>>>>>> >>>>>>>>>>I understand why it crashes: the non-local return has >>>>>>>>>>nowhere to return to and so resuming the computation >>>>>>>>>>leads to a crash. But why not raise another BCR >>>>>>>>>>exception to prevent the crash? Potential infinite loop? >>>>>>>>>>Perhaps I'm just missing the purpose of this behavior... >>>>>>>>>> >>>>>>>>>>Thanks for an explanation. >>>>>>>>>> >>>>>>>>>>Best, >>>>>>>>>>Jaromir >>>>>>>>>> >>>>>>>>>>-- >>>>>>>>>> >>>>>>>>>>Jaromir Matas >>>>>>>>>> >>>>>>>>>> >>>>>>>> >>>>> >>>>> >>>>>-- >>>>>_,,,^..^,,,_ >>>>>best, Eliot >>><Context-cannotReturn.st>
-- _,,,^..^,,,_ best, Eliot
<ProcessTest-testResumeAfterBCR.st>
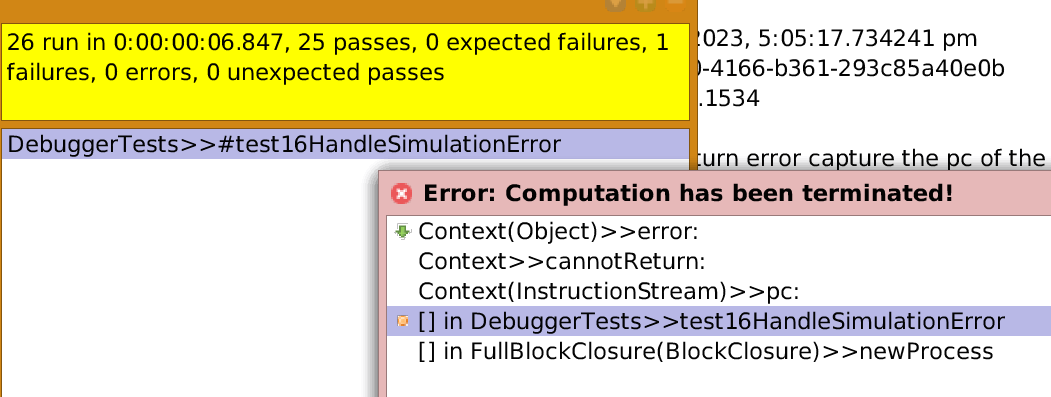{kind=link}
Hi Marcel,
[myself] whether the patch would have been necessary should the
#return:from: had been fixed then
Nonsense, I just mixed it up with another issue :)
On 29-Nov-23 1:51:21 PM, "Jaromir Matas" mail@jaromir.net wrote:
Thanks Marcel! This test somehow slipped my attention :)
The test can no longer work as is. It takes advantage of the erroneous behavior of #return:from: in the sense that if you simulate
thisContext pc: nilit'll happily return to a dead context (i.e. to thisContext from #pc: nil context) - which is not what the VM does during runtime. It should immediately raise an illegal return exception not only during runtime but also during simulation.
The test mentions a patch for an infinite debugger chain (http://forum.world.st/I-broke-the-debugger-td5110752.html). I wonder whether the problem could have something to do with this simulation bug in return:from:; and a terrible idea occurred to me whether the patch would have been necessary should the #return:from: had been fixed then ;O
We may potentially come up with more examples like this, even in the trunk, where the bug from #return:from: propagated and was taken advantage of. I've found and fixed #runUntilErrorOrReturnFrom: but more can still be surviving undetected...
I'd place the test into #expectedFailures for now but maybe it's time to remove it; Christoph should decide :)
Thanks again, Jaromir
On 29-Nov-23 10:28:38 AM, "Taeumel, Marcel via Squeak-dev" squeak-dev@lists.squeakfoundation.org wrote:
Hi Jaromir --
Looks good. Still, what about that #test16HandleSimulationError now? :-) It is failing with your changes ... how would you adapt it?
Best, Marcel
Am 28.11.2023 01:29:39 schrieb Jaromir Matas mail@jaromir.net:
Hi Eliot, Marcel, all,
I've sent a fix Kernel-jar.1539 to the Inbox that solves the remaining bit of the chain of bugs described in the previous post. All tests are green now and I think the root cause has been found and fixed.
In this last bit I've created a version of stepToCallee that would identify a potential illegal return to a nil sender and avoid it.
Now this example can be debugged without any problems:
[[self halt. ^ 1] on: BlockCannotReturn do: #resume ] fork
If you're happy with the solution in Kernel-jar.1539, Kernel-jar.1538, Kernel-jar.1537 and the test in KernelTests-jar.447, could you please double-check and merge, please? (And remove Kernel-mt.1534 and Tools-jar.1240 from the Inbox)
Best, Jaromir
On 27-Nov-23 12:09:37 AM, "Jaromir Matas" mail@jaromir.net wrote:
Hi Eliot, Christoph, all
It looks like there are some more skeletons in the closet :/
If you run this example
[[self halt. ^ 1] on: BlockCannotReturn do: [:ex | ex resume] ] fork
and step over halt and then step over ^1 you get a nonsensical error as a result of decoding nil as an instruction.
It turns out that the root cause is in the #return:from: method: it only checks whether aSender is dead but ignores the possibility that aSender sender may be nil or dead in which cases the VM also responds with sending #cannotReturn, hence I assume the simulator should do the same. In addition, the VM nills the pc in such scenario, so I added the same functionality here too:
Context >> return: value from: aSender "For simulation. Roll back self to aSender and return value from it. Execute any unwind blocks on the way. ASSUMES aSender is a sender of self"
| newTop | newTop := aSender sender. (aSender isDead or: [newTop isNil or: [newTop isDead]]) ifTrue:"<--------- this is extended ------" [^self pc: nil; send: #cannotReturn: to: self with: {value}]. "<------ pc: nil is added ----" (self findNextUnwindContextUpTo: newTop) ifNotNil: "Send #aboutToReturn:through: with nil as the second argument to avoid this bug: Cannot #stepOver '^2' in example '[^2] ensure: []'. See http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html" [^self send: #aboutToReturn:through: to: self with: {value. nil}]. self releaseTo: newTop. newTop ifNotNil: [newTop push: value]. ^newTop
In order for this to work #cannotReturn: has to be modified as in Kernel-jar.1537:
Context >> cannotReturn: result
closureOrNil ifNotNil: [^ self cannotReturn: result to: selfhome sender]. self error: 'Computation has been terminated!' "<----------- this has to be an Error -----"
Then it almost works except when you keep stepping over in the example above, you get an MNU error on `self previousPc` in #cannotReturn:to:` with your solution of the VM crash. If you don't mind I've amended your solution and added the final context where the computation couldn't return along with the pc:
Context >> cannotReturn: result to: homeContext "The receiver tried to return result to homeContext that cannot be returned from. Capture the return context/pc in a BlockCannotReturn. Nil the pc to prevent repeat attempts and/or invalid continuation. Answer the result of raising the exception."
| exception previousPc | exception := BlockCannotReturn new. previousPc := pc ifNotNil: [self previousPc]. "<----- here's afix ----" exception result: result; deadHome: homeContext; finalContext: self; "<----- here's the new state, if that's fine ----" pc: previousPc. pc := nil. ^exception signal
Unfortunately, this is still not the end of the story: there are situations where #runUntilErrorOrReturnFrom: places the two guard contexts below the bottom context. And that is a problem because when the method tries to remove the two guard contexts before returning at the end it uses #stepToCalee to do the job but this unforotunately was (ab)using the above bug in #return:from: - I'll explain: #return:from: didn't check whether aSender sender was nil and as a result it allowed to simulate a return to a "nil context" which was then (ab)used in the clean-up via #stepToCalee in the #runUntilErrorOrReturnFrom:.
When I fixed the #return:from: bug, the #runUntilErrorOrReturnFrom: cleanup of the guard contexts no longer works in that very special case where the guard contexts are below the bottom context. There's one case where this is being used: #terminateAggresively by Christoph.
If I'm right with this analysis, the #runUntilErrorOrReturnFrom: should get fixed too but I'll be away now for a few days and I won't be able to respond. If you or Christoph had a chance to take a look at Kernel-jar.1538 and Kernel-jar.1537 I'd be very grateful. I hope this super long message at least makes some sense :) Best, Jaromir
[1] Kernel-jar.1538, Kernel-jar.1537 [2] KernelTests-jar.447
PS: Christoph,
With Kernel-jar.1538 + Kernel-jar.1537 your example
process := [(c := thisContext) pc: nil. 2+3] newProcess. process runUntil: [:ctx | ctx selector = #cannotReturn:]. self assert: process suspendedContext sender sender = c. self assert: process suspendedContext arguments = {c}.
works fine, I've just corrected your first assert.
On 21-Nov-23 6:40:32 PM, "Eliot Miranda" eliot.miranda@gmail.com wrote:
Hi Jaromir,
On Nov 20, 2023, at 11:51 PM, Jaromir Matas mail@jaromir.net wrote:
Hi Eliot, Very elegant! Now I finally got what you meant exactly :) Thanks.
Two questions:
- in order for the enclosed test to work I'd need an Error
instead of Processor debugWithTitle:full: call in #cannotReturn:. Otherwise I don't know how to catch a plain invocation of the Debugger:
cannotReturn: result
closureOrNil ifNotNil: [^ self cannotReturn: result to: selfhome sender]. self error: 'Computation has been terminated!'
Much nicer.
- We are capturing a pc of self which is completely different
context from homeContext indeed.
Right. The return is attempted from a specific return bytecode in a specific block. This is the coordinate of the return that cannot be made. This is the relevant point of origin of the cannot return exception.
Why the return fails is another matter:
- the home context’s sender is a dead context (cannot be resumed)
- the home context’s sender is nil (home already returned from)
- the block activation’s home is nil rather than a context (should
not happen)
But in all these cases the pc of the home context is immaterial. The hike is being returned through/from, rather than from; the home’s pc is not relevant.
Maybe we could capture self in the exception too to make it more clear/explicit what is going on: what context the captured pc is actually associated with. Just a thought...
Yes, I like that. I also like the idea of somehow passing the block activation’s pc to the debugger so that the relevant return expression is highlighted in the debugger.
Thanks again, Jaromir
You’re welcome. I love working in this part of the system. Thanks for dragging me there. I’m in a slump right now and appreciate the fellowship.
------ Original Message ------ From "Eliot Miranda" eliot.miranda@gmail.com To "Jaromir Matas" mail@jaromir.net Cc squeak-dev@lists.squeakfoundation.org Date 11/21/2023 2:17:21 AM Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn exception
>Hi Jaromir, > > see Kernel-eem.1535 for what I was suggesting. This example >now has an exception with the right pc value in it: > >[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] >fork > >The fix is simply > >Context>>cannotReturn: result to: homeContext > "The receiver tried to return result to homeContext that >cannot be returned from. > Capture the return pc in a BlockCannotReturn. Nil the pc to >prevent repeat > attempts and/or invalid continuation. Answer the result of >raising the exception." > > | exception | > exception := BlockCannotReturn new. > exception > result: result; > deadHome: homeContext; > pc: self previousPc. > pc := nil. > ^exception signal > > >The VM crash is now avoided. The debugger displays the method, >but does not highlight the offending pc, which is no big deal. A >suitable defaultHandler for B lockCannotReturn may be able to get >the debugger to highlight correctly on opening. Try the >following examples: > >[[^1] on: BlockCannotReturn do: #resume] fork. > >[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] >fork > >[[^1] value] fork. > >They al; seem to behave perfectly acceptably to me. Does this >fix work for you? > >On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas mail@jaromir.net >wrote: >>Hi Eliot, >> >>How about to nil the pc just before making the return: >>``` >>Context >> #cannotReturn: result >> >> self push: self pc. "backup the pc for the sake of >>debugging" >> closureOrNil ifNotNil: [^self cannotReturn: result to: self >>home sender; pc: nil]. >> Processor debugWithTitle: 'Computation has been terminated!' >>translated full: false >>``` >>The nilled pc should not even potentially interfere with the >>#isDead now. >> >>I hope this is at least a step in the right direction :) >> >>However, there's still a problem when debugging the resumption >>of #cannotReturn because the encoders expect a reasonable index. >>I haven't figured out yet where to place a nil check - #step, >>#stepToSendOrReturn... ? >> >>Thanks again, >>Jaromir >> >> >>------ Original Message ------ >>From "Eliot Miranda" eliot.miranda@gmail.com >>To "Jaromir Matas" mail@jaromir.net >>Date 11/17/2023 8:36:50 PM >>Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn >>exception >> >>>Hi Jaromir, >>> >>>>On Nov 17, 2023, at 7:05 AM, Jaromir Matas mail@jaromir.net >>>>wrote: >>>> >>>> >>>>Eliot, hi again, >>>> >>>>Please disregard my previous comment about nilling the >>>>contexts that have returned. We are indeed talking about the >>>>context directly under the #cannotReturn context which is >>>>totally different from the home context in another thread >>>>that's gone. >>>> >>>>I may still be confused but would nilling the pc of the >>>>context directly under the cannotReturn context help? Here's >>>>what I mean: >>>>``` >>>>Context >> #cannotReturn: result >>>> >>>> closureOrNil ifNotNil: [^self pc: nil; cannotReturn: >>>>result to: self home sender]. >>>> Processor debugWithTitle: 'Computation has been >>>>terminated!' translated full: false. >>>>``` >>>>Instead of crashing the VM invokes the debugger with the >>>>'Computation has been terminated!' message. >>>> >>>>Does this make sense? >>> >>>Nearly. But it loses the information on what the pc actually >>>is, and that’s potentially vital information. So IMO the ox >>>should only be nilled between the BlockCannotReturn exception >>>being created and raised. >>> >>>[But if you try this don’t be surprised if it causes a few >>>temporary problems. It looks to me that without a little >>>refactoring this could easily cause an infinite recursion >>>around the sending of isDead. I’m sure you’ll be able to fix >>>the code to work correctly] >>> >>>>Thanks, >>>>Jaromir >>>> >>>> >>>>------ Original Message ------ >>>>From "Jaromir Matas" mail@jaromir.net >>>>To "Eliot Miranda" eliot.miranda@gmail.com; "The >>>>general-purpose Squeak developers list" >>>>squeak-dev@lists.squeakfoundation.org >>>>Date 11/17/2023 10:15:17 AM >>>>Subject [squeak-dev] Re: Resuming on BlockCannotReturn >>>>exception >>>> >>>>>Hi Eliot, >>>>> >>>>> >>>>> >>>>>------ Original Message ------ >>>>>From "Eliot Miranda" eliot.miranda@gmail.com >>>>>To "Jaromir Matas" mail@jaromir.net >>>>>Cc "The general-purpose Squeak developers list" >>>>>squeak-dev@lists.squeakfoundation.org >>>>>Date 11/16/2023 11:52:45 PM >>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on >>>>>BlockCannotReturn exception >>>>> >>>>>>Hi Jaromir, >>>>>> >>>>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas >>>>>>mail@jaromir.net wrote: >>>>>>>Hi Nicolas, Eliot, >>>>>>> >>>>>>>here's what I understand is happening (see the enclosed >>>>>>>screenshot): >>>>>>> >>>>>>>1) we fork a new process to evaluate [^1] >>>>>>>2) the new process evaluates [^1] which means instruction >>>>>>>18 is being evaluated, hence pc points to instruction 19 >>>>>>>now >>>>>>>3) however, the home context where ^1 should return to is >>>>>>>gone by this time (the process that executed the fork has >>>>>>>already returned - notice the two up arrows in the debugger >>>>>>>screenshot) >>>>>>>4) the VM can't finish the instruction and returns control >>>>>>>to the image via placing the #cannotReturn: context on top >>>>>>>of the [^1] context >>>>>>>5) #cannotReturn: evaluation results in signalling the BCR >>>>>>>exception which is then handled by the #resume handler >>>>>>> (in our debugged case the [:ex | self halt. ex resume] >>>>>>>handler) >>>>>>>6) ex resume is evaluated, however, this means requesting >>>>>>>the VM to evaluate instruction 19 of the [^1] context - >>>>>>>which is past the last instruction of the context and the >>>>>>>crash ensues >>>>>>> >>>>>>>I wonder whether such situations could/should be prevented >>>>>>>inside the VM or whether such an expectation is wrong for >>>>>>>some reason. >>>>>> >>>>>>As Nicolas says, IMO this is best done at the image level. >>>>>> >>>>>>It could be prevented in the VM, but at great cost, and only >>>>>>partially. The performance issue is that the last bytecode >>>>>>in a method is not marked in any way, and that to determine >>>>>>the last bytecode the bytecodes must be symbolically >>>>>>evaluated from the start of the method. See implementors of >>>>>>endPC at the image level (which defer to the method trailer) >>>>>>and implementors of endPCOf: in the VMMaker code. Doing this >>>>>>every time execution commences is prohibitively expensive. >>>>>>The "only partially" issue is that following the return >>>>>>instruction may be other valid bytecodes, but these are not >>>>>>a continuation. >>>>>> >>>>>> >>>>>>Consider the following code in some block: >>>>>> [self expression ifTrue: >>>>>> [^1]. >>>>>> ^2 >>>>>> >>>>>>The bytecodes for this are >>>>>> pushReceiver >>>>>> send #expression >>>>>> jumpFalse L1 >>>>>> push 1 >>>>>> methodReturnTop >>>>>>L1 >>>>>> push 2 >>>>>> methodReturnTop >>>>>> >>>>>>Clearly if expression is true these should be *no* >>>>>>continuation in which ^2 is executed. >>>>> >>>>>Well, in that case there's a bug because the computation in >>>>>the following example shouldn't continue past the [^1] block >>>>>but it silently does: >>>>>`[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] >>>>>fork` >>>>> >>>>>The bytecodes are >>>>> push true >>>>> jumpFalse L1 >>>>> push 1 >>>>> returnTop >>>>>L1 >>>>> push nil >>>>> blockReturn >>>>> >>>>> >>>>> >>>>>> >>>>>>So even if the VM did try and detect whether the return was >>>>>>at the last block method, it would only work for special >>>>>>cases. >>>>>> >>>>>> >>>>>>It seems to me the issue is simply that the context that >>>>>>cannot be returned from should be marked as dead (see >>>>>>Context>>isDead) by setting its pc to nil at some point, >>>>>>presumably after copying the actual return pc into the >>>>>>BlockCannotReturn exception, to avoid ever trying to resume >>>>>>the context. >>>>> >>>>>Does this mean, in other words, that every context that >>>>>returns should nil its pc to avoid being "wrongly" >>>>>reused/executed in the future, which concerns primarily those >>>>>being referenced somewhere hence potentially executable in >>>>>the future, is that right? >>>>>Hypothetical question: would nilling the pc during returns >>>>>"fix" the example? >>>>>Thanks a lot for helping me understand this. >>>>>Best, >>>>>Jaromir >>>>> >>>>> >>>>> >>>>>> >>>>>> >>>>>>> >>>>>>>Thanks, >>>>>>>Jaromir >>>>>>> >>>>>>><bdxuqalu.png> >>>>>>> >>>>>>>------ Original Message ------ >>>>>>>From "Eliot Miranda" eliot.miranda@gmail.com >>>>>>>To "Jaromir Matas" mail@jaromir.net; "The general-purpose >>>>>>>Squeak developers list" >>>>>>>squeak-dev@lists.squeakfoundation.org >>>>>>>Date 11/16/2023 6:48:43 PM >>>>>>>Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn >>>>>>>exception >>>>>>> >>>>>>>>Hi Jaromir, >>>>>>>> >>>>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas >>>>>>>>>mail@jaromir.net wrote: >>>>>>>>> >>>>>>>>> >>>>>>>>>Hi Nicloas, >>>>>>>>>No no, I don't have any practical scenario in mind, I'm >>>>>>>>>just trying to understand why the VM is implemented like >>>>>>>>>this, whether there were a reason to leave this >>>>>>>>>possibility of a crash, e.g. it would slow down the VM to >>>>>>>>>try to prevent such a dumb situation (who would resume >>>>>>>>>from BCR in his right mind? :) ) - or perhaps I have >>>>>>>>>overlooked some good reason to even keep this behavior in >>>>>>>>>the VM. That's all. >>>>>>>> >>>>>>>>Let’s first understand what’s really happening. Presumably >>>>>>>>at tone point a context is resumed those pc is already at >>>>>>>>the block return bytecode (effectively, because it crashes >>>>>>>>in JITted code, but I bet the stack vm will crash also, >>>>>>>>but not as cleanly - it will try and execute the bytes in >>>>>>>>the encoded method trailer). So which method actually >>>>>>>>sends resume, and to what, and what state is resume’s >>>>>>>>receiver when resume is sent? >>>>>>>> >>>>>>>> >>>>>>>>> >>>>>>>>>Thanks for your reply. >>>>>>>>>Regards, >>>>>>>>>Jaromir >>>>>>>>> >>>>>>>>> >>>>>>>>> >>>>>>>>> >>>>>>>>>------ Original Message ------ >>>>>>>>>From "Nicolas Cellier" >>>>>>>>>nicolas.cellier.aka.nice@gmail.com >>>>>>>>>To "Jaromir Matas" mail@jaromir.net; "The >>>>>>>>>general-purpose Squeak developers list" >>>>>>>>>squeak-dev@lists.squeakfoundation.org >>>>>>>>>Date 11/16/2023 7:20:20 AM >>>>>>>>>Subject Re: [squeak-dev] Resuming on BlockCannotReturn >>>>>>>>>exception >>>>>>>>> >>>>>>>>>>Hi Jaromir, >>>>>>>>>>Is there a scenario where it would make sense to resume >>>>>>>>>>a BlockCannotReturn? >>>>>>>>>>If not, I would suggest to protect at image side and >>>>>>>>>>override #resume. >>>>>>>>>> >>>>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas >>>>>>>>>>mail@jaromir.net a écrit : >>>>>>>>>>>Hi Eliot, Christoph, All, >>>>>>>>>>> >>>>>>>>>>>It's known the following example crashes the VM. Is >>>>>>>>>>>this an intended behavior or a "tolerated bug"? >>>>>>>>>>> >>>>>>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>>>>>>>>> >>>>>>>>>>>I understand why it crashes: the non-local return has >>>>>>>>>>>nowhere to return to and so resuming the computation >>>>>>>>>>>leads to a crash. But why not raise another BCR >>>>>>>>>>>exception to prevent the crash? Potential infinite >>>>>>>>>>>loop? Perhaps I'm just missing the purpose of this >>>>>>>>>>>behavior... >>>>>>>>>>> >>>>>>>>>>>Thanks for an explanation. >>>>>>>>>>> >>>>>>>>>>>Best, >>>>>>>>>>>Jaromir >>>>>>>>>>> >>>>>>>>>>>-- >>>>>>>>>>> >>>>>>>>>>>Jaromir Matas >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>> >>>>>> >>>>>> >>>>>>-- >>>>>>_,,,^..^,,,_ >>>>>>best, Eliot >>>><Context-cannotReturn.st> > > >-- >_,,,^..^,,,_ >best, Eliot <ProcessTest-testResumeAfterBCR.st>
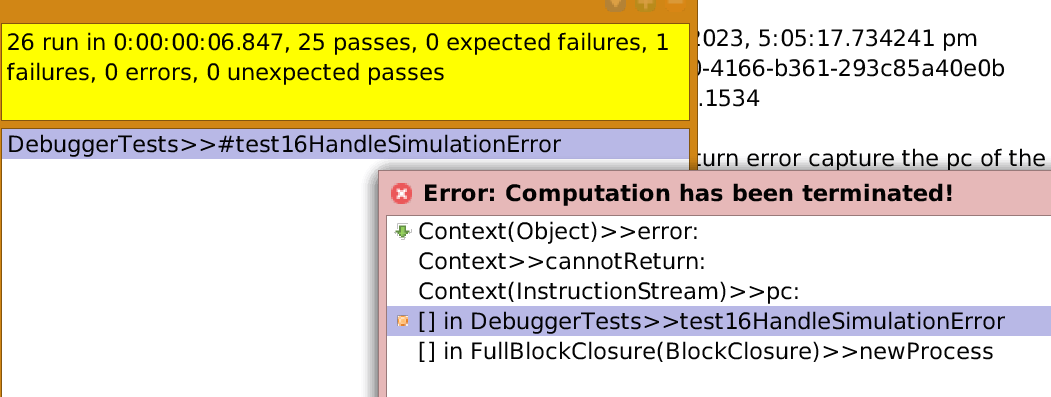{kind=link}
Hi Jaromir, hi all,
finally I have found the time to review these suggestions. Kernel-jar.1537, Kernel-jar.1538, and Kernel-jar.1539 look excellent to me as well. Clear, straightforward, useful. :-) I have merged them into the trunk via Kernel-ct.1545.
Regarding DebuggerTests>>test16HandleSimulationError, I have patched it via ToolsTests-ct.125. Nothing to rack your brains over: "thisContext pc: nil" just mimicks any kind of unhandled error inside the simulator - since we now gently handle this via #cannotReturn:, I just replaced it with "thisContext pc: false". :-) Sorry for not clarifying that earlier and letting you speculate.
Thanks for your work, and I already wish you a happy new year!
Best, Christoph
--- Sent from Squeak Inbox Talk
On 2023-11-29T13:31:09+00:00, mail@jaromir.net wrote:
Hi Marcel,
[myself] whether the patch would have been necessary should the
#return:from: had been fixed then
Nonsense, I just mixed it up with another issue :)
On 29-Nov-23 1:51:21 PM, "Jaromir Matas" <mail(a)jaromir.net> wrote:
Thanks Marcel! This test somehow slipped my attention :)
The test can no longer work as is. It takes advantage of the erroneous behavior of #return:from: in the sense that if you simulate
thisContext pc: nil
it'll happily return to a dead context (i.e. to thisContext from #pc: nil context) - which is not what the VM does during runtime. It should immediately raise an illegal return exception not only during runtime but also during simulation.
The test mentions a patch for an infinite debugger chain (http://forum.world.st/I-broke-the-debugger-td5110752.html). I wonder whether the problem could have something to do with this simulation bug in return:from:; and a terrible idea occurred to me whether the patch would have been necessary should the #return:from: had been fixed then ;O
We may potentially come up with more examples like this, even in the trunk, where the bug from #return:from: propagated and was taken advantage of. I've found and fixed #runUntilErrorOrReturnFrom: but more can still be surviving undetected...
I'd place the test into #expectedFailures for now but maybe it's time to remove it; Christoph should decide :)
Thanks again, Jaromir
On 29-Nov-23 10:28:38 AM, "Taeumel, Marcel via Squeak-dev" <squeak-dev(a)lists.squeakfoundation.org> wrote:
Hi Jaromir --
Looks good. Still, what about that #test16HandleSimulationError now? :-) It is failing with your changes ... how would you adapt it?
Best, Marcel
Am 28.11.2023 01:29:39 schrieb Jaromir Matas <mail(a)jaromir.net>:
Hi Eliot, Marcel, all,
I've sent a fix Kernel-jar.1539 to the Inbox that solves the remaining bit of the chain of bugs described in the previous post. All tests are green now and I think the root cause has been found and fixed.
In this last bit I've created a version of stepToCallee that would identify a potential illegal return to a nil sender and avoid it.
Now this example can be debugged without any problems:
[[self halt. ^ 1] on: BlockCannotReturn do: #resume ] fork
If you're happy with the solution in Kernel-jar.1539, Kernel-jar.1538, Kernel-jar.1537 and the test in KernelTests-jar.447, could you please double-check and merge, please? (And remove Kernel-mt.1534 and Tools-jar.1240 from the Inbox)
Best, Jaromir
On 27-Nov-23 12:09:37 AM, "Jaromir Matas" <mail(a)jaromir.net> wrote:
Hi Eliot, Christoph, all
It looks like there are some more skeletons in the closet :/
If you run this example
[[self halt. ^ 1] on: BlockCannotReturn do: [:ex | ex resume] ] fork
and step over halt and then step over ^1 you get a nonsensical error as a result of decoding nil as an instruction.
It turns out that the root cause is in the #return:from: method: it only checks whether aSender is dead but ignores the possibility that aSender sender may be nil or dead in which cases the VM also responds with sending #cannotReturn, hence I assume the simulator should do the same. In addition, the VM nills the pc in such scenario, so I added the same functionality here too:
Context >> return: value from: aSender "For simulation. Roll back self to aSender and return value from it. Execute any unwind blocks on the way. ASSUMES aSender is a sender of self"
| newTop | newTop := aSender sender. (aSender isDead or: [newTop isNil or: [newTop isDead]]) ifTrue: "<--------- this is extended ------" [^self pc: nil; send: #cannotReturn: to: self with: {value}]. "<------ pc: nil is added ----" (self findNextUnwindContextUpTo: newTop) ifNotNil: "Send #aboutToReturn:through: with nil as the second argument to avoid this bug: Cannot #stepOver '^2' in example '[^2] ensure: []'. See http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html" [^self send: #aboutToReturn:through: to: self with: {value. nil}]. self releaseTo: newTop. newTop ifNotNil: [newTop push: value]. ^newTop
In order for this to work #cannotReturn: has to be modified as in Kernel-jar.1537:
Context >> cannotReturn: result
closureOrNil ifNotNil: [^ self cannotReturn: result to: self home sender]. self error: 'Computation has been terminated!' "<----------- this has to be an Error -----"
Then it almost works except when you keep stepping over in the example above, you get an MNU error on `self previousPc` in #cannotReturn:to:` with your solution of the VM crash. If you don't mind I've amended your solution and added the final context where the computation couldn't return along with the pc:
Context >> cannotReturn: result to: homeContext "The receiver tried to return result to homeContext that cannot be returned from. Capture the return context/pc in a BlockCannotReturn. Nil the pc to prevent repeat attempts and/or invalid continuation. Answer the result of raising the exception."
| exception previousPc | exception := BlockCannotReturn new. previousPc := pc ifNotNil: [self previousPc]. "<----- here's a fix ----" exception result: result; deadHome: homeContext; finalContext: self; "<----- here's the new state, if that's fine ----" pc: previousPc. pc := nil. ^exception signal
Unfortunately, this is still not the end of the story: there are situations where #runUntilErrorOrReturnFrom: places the two guard contexts below the bottom context. And that is a problem because when the method tries to remove the two guard contexts before returning at the end it uses #stepToCalee to do the job but this unforotunately was (ab)using the above bug in #return:from: - I'll explain: #return:from: didn't check whether aSender sender was nil and as a result it allowed to simulate a return to a "nil context" which was then (ab)used in the clean-up via #stepToCalee in the #runUntilErrorOrReturnFrom:.
When I fixed the #return:from: bug, the #runUntilErrorOrReturnFrom: cleanup of the guard contexts no longer works in that very special case where the guard contexts are below the bottom context. There's one case where this is being used: #terminateAggresively by Christoph.
If I'm right with this analysis, the #runUntilErrorOrReturnFrom: should get fixed too but I'll be away now for a few days and I won't be able to respond. If you or Christoph had a chance to take a look at Kernel-jar.1538 and Kernel-jar.1537 I'd be very grateful. I hope this super long message at least makes some sense :) Best, Jaromir
[1] Kernel-jar.1538, Kernel-jar.1537 [2] KernelTests-jar.447
PS: Christoph,
With Kernel-jar.1538 + Kernel-jar.1537 your example
process := [(c := thisContext) pc: nil. 2+3] newProcess. process runUntil: [:ctx | ctx selector = #cannotReturn:]. self assert: process suspendedContext sender sender = c. self assert: process suspendedContext arguments = {c}.
works fine, I've just corrected your first assert.
On 21-Nov-23 6:40:32 PM, "Eliot Miranda" <eliot.miranda(a)gmail.com> wrote:
Hi Jaromir,
>On Nov 20, 2023, at 11:51 PM, Jaromir Matas <mail(a)jaromir.net> >wrote: > > >Hi Eliot, >Very elegant! Now I finally got what you meant exactly :) Thanks. > >Two questions: >1. in order for the enclosed test to work I'd need an Error >instead of Processor debugWithTitle:full: call in #cannotReturn:. >Otherwise I don't know how to catch a plain invocation of the >Debugger: > >cannotReturn: result > > closureOrNil ifNotNil: [^ self cannotReturn: result to: self >home sender]. > self error: 'Computation has been terminated!'
Much nicer.
>2. We are capturing a pc of self which is completely different >context from homeContext indeed.
Right. The return is attempted from a specific return bytecode in a specific block. This is the coordinate of the return that cannot be made. This is the relevant point of origin of the cannot return exception.
Why the return fails is another matter:
- the home context’s sender is a dead context (cannot be resumed)
- the home context’s sender is nil (home already returned from)
- the block activation’s home is nil rather than a context (should
not happen)
But in all these cases the pc of the home context is immaterial. The hike is being returned through/from, rather than from; the home’s pc is not relevant.
>Maybe we could capture self in the exception too to make it more >clear/explicit what is going on: what context the captured pc is >actually associated with. Just a thought...
Yes, I like that. I also like the idea of somehow passing the block activation’s pc to the debugger so that the relevant return expression is highlighted in the debugger.
> >Thanks again, >Jaromir
You’re welcome. I love working in this part of the system. Thanks for dragging me there. I’m in a slump right now and appreciate the fellowship.
>------ Original Message ------ >From "Eliot Miranda" <eliot.miranda(a)gmail.com> >To "Jaromir Matas" <mail(a)jaromir.net> >Cc squeak-dev(a)lists.squeakfoundation.org >Date 11/21/2023 2:17:21 AM >Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn >exception > >>Hi Jaromir, >> >> see Kernel-eem.1535 for what I was suggesting. This example >>now has an exception with the right pc value in it: >> >>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] >>fork >> >>The fix is simply >> >>Context>>cannotReturn: result to: homeContext >> "The receiver tried to return result to homeContext that >>cannot be returned from. >> Capture the return pc in a BlockCannotReturn. Nil the pc to >>prevent repeat >> attempts and/or invalid continuation. Answer the result of >>raising the exception." >> >> | exception | >> exception := BlockCannotReturn new. >> exception >> result: result; >> deadHome: homeContext; >> pc: self previousPc. >> pc := nil. >> ^exception signal >> >> >>The VM crash is now avoided. The debugger displays the method, >>but does not highlight the offending pc, which is no big deal. A >>suitable defaultHandler for B lockCannotReturn may be able to get >>the debugger to highlight correctly on opening. Try the >>following examples: >> >>[[^1] on: BlockCannotReturn do: #resume] fork. >> >>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex resume]] >>fork >> >>[[^1] value] fork. >> >>They al; seem to behave perfectly acceptably to me. Does this >>fix work for you? >> >>On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas <mail(a)jaromir.net> >>wrote: >>>Hi Eliot, >>> >>>How about to nil the pc just before making the return: >>>``` >>>Context >> #cannotReturn: result >>> >>> self push: self pc. "backup the pc for the sake of >>>debugging" >>> closureOrNil ifNotNil: [^self cannotReturn: result to: self >>>home sender; pc: nil]. >>> Processor debugWithTitle: 'Computation has been terminated!' >>>translated full: false >>>``` >>>The nilled pc should not even potentially interfere with the >>>#isDead now. >>> >>>I hope this is at least a step in the right direction :) >>> >>>However, there's still a problem when debugging the resumption >>>of #cannotReturn because the encoders expect a reasonable index. >>>I haven't figured out yet where to place a nil check - #step, >>>#stepToSendOrReturn... ? >>> >>>Thanks again, >>>Jaromir >>> >>> >>>------ Original Message ------ >>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>To "Jaromir Matas" <mail(a)jaromir.net> >>>Date 11/17/2023 8:36:50 PM >>>Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn >>>exception >>> >>>>Hi Jaromir, >>>> >>>>>On Nov 17, 2023, at 7:05 AM, Jaromir Matas <mail(a)jaromir.net> >>>>>wrote: >>>>> >>>>> >>>>>Eliot, hi again, >>>>> >>>>>Please disregard my previous comment about nilling the >>>>>contexts that have returned. We are indeed talking about the >>>>>context directly under the #cannotReturn context which is >>>>>totally different from the home context in another thread >>>>>that's gone. >>>>> >>>>>I may still be confused but would nilling the pc of the >>>>>context directly under the cannotReturn context help? Here's >>>>>what I mean: >>>>>``` >>>>>Context >> #cannotReturn: result >>>>> >>>>> closureOrNil ifNotNil: [^self pc: nil; cannotReturn: >>>>>result to: self home sender]. >>>>> Processor debugWithTitle: 'Computation has been >>>>>terminated!' translated full: false. >>>>>``` >>>>>Instead of crashing the VM invokes the debugger with the >>>>>'Computation has been terminated!' message. >>>>> >>>>>Does this make sense? >>>> >>>>Nearly. But it loses the information on what the pc actually >>>>is, and that’s potentially vital information. So IMO the ox >>>>should only be nilled between the BlockCannotReturn exception >>>>being created and raised. >>>> >>>>[But if you try this don’t be surprised if it causes a few >>>>temporary problems. It looks to me that without a little >>>>refactoring this could easily cause an infinite recursion >>>>around the sending of isDead. I’m sure you’ll be able to fix >>>>the code to work correctly] >>>> >>>>>Thanks, >>>>>Jaromir >>>>> >>>>> >>>>>------ Original Message ------ >>>>>From "Jaromir Matas" <mail(a)jaromir.net> >>>>>To "Eliot Miranda" <eliot.miranda(a)gmail.com>; "The >>>>>general-purpose Squeak developers list" >>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>Date 11/17/2023 10:15:17 AM >>>>>Subject [squeak-dev] Re: Resuming on BlockCannotReturn >>>>>exception >>>>> >>>>>>Hi Eliot, >>>>>> >>>>>> >>>>>> >>>>>>------ Original Message ------ >>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>>Cc "The general-purpose Squeak developers list" >>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>Date 11/16/2023 11:52:45 PM >>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on >>>>>>BlockCannotReturn exception >>>>>> >>>>>>>Hi Jaromir, >>>>>>> >>>>>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas >>>>>>><mail(a)jaromir.net> wrote: >>>>>>>>Hi Nicolas, Eliot, >>>>>>>> >>>>>>>>here's what I understand is happening (see the enclosed >>>>>>>>screenshot): >>>>>>>> >>>>>>>>1) we fork a new process to evaluate [^1] >>>>>>>>2) the new process evaluates [^1] which means instruction >>>>>>>>18 is being evaluated, hence pc points to instruction 19 >>>>>>>>now >>>>>>>>3) however, the home context where ^1 should return to is >>>>>>>>gone by this time (the process that executed the fork has >>>>>>>>already returned - notice the two up arrows in the debugger >>>>>>>>screenshot) >>>>>>>>4) the VM can't finish the instruction and returns control >>>>>>>>to the image via placing the #cannotReturn: context on top >>>>>>>>of the [^1] context >>>>>>>>5) #cannotReturn: evaluation results in signalling the BCR >>>>>>>>exception which is then handled by the #resume handler >>>>>>>> (in our debugged case the [:ex | self halt. ex resume] >>>>>>>>handler) >>>>>>>>6) ex resume is evaluated, however, this means requesting >>>>>>>>the VM to evaluate instruction 19 of the [^1] context - >>>>>>>>which is past the last instruction of the context and the >>>>>>>>crash ensues >>>>>>>> >>>>>>>>I wonder whether such situations could/should be prevented >>>>>>>>inside the VM or whether such an expectation is wrong for >>>>>>>>some reason. >>>>>>> >>>>>>>As Nicolas says, IMO this is best done at the image level. >>>>>>> >>>>>>>It could be prevented in the VM, but at great cost, and only >>>>>>>partially. The performance issue is that the last bytecode >>>>>>>in a method is not marked in any way, and that to determine >>>>>>>the last bytecode the bytecodes must be symbolically >>>>>>>evaluated from the start of the method. See implementors of >>>>>>>endPC at the image level (which defer to the method trailer) >>>>>>>and implementors of endPCOf: in the VMMaker code. Doing this >>>>>>>every time execution commences is prohibitively expensive. >>>>>>>The "only partially" issue is that following the return >>>>>>>instruction may be other valid bytecodes, but these are not >>>>>>>a continuation. >>>>>>> >>>>>>> >>>>>>>Consider the following code in some block: >>>>>>> [self expression ifTrue: >>>>>>> [^1]. >>>>>>> ^2 >>>>>>> >>>>>>>The bytecodes for this are >>>>>>> pushReceiver >>>>>>> send #expression >>>>>>> jumpFalse L1 >>>>>>> push 1 >>>>>>> methodReturnTop >>>>>>>L1 >>>>>>> push 2 >>>>>>> methodReturnTop >>>>>>> >>>>>>>Clearly if expression is true these should be *no* >>>>>>>continuation in which ^2 is executed. >>>>>> >>>>>>Well, in that case there's a bug because the computation in >>>>>>the following example shouldn't continue past the [^1] block >>>>>>but it silently does: >>>>>>`[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] >>>>>>fork` >>>>>> >>>>>>The bytecodes are >>>>>> push true >>>>>> jumpFalse L1 >>>>>> push 1 >>>>>> returnTop >>>>>>L1 >>>>>> push nil >>>>>> blockReturn >>>>>> >>>>>> >>>>>> >>>>>>> >>>>>>>So even if the VM did try and detect whether the return was >>>>>>>at the last block method, it would only work for special >>>>>>>cases. >>>>>>> >>>>>>> >>>>>>>It seems to me the issue is simply that the context that >>>>>>>cannot be returned from should be marked as dead (see >>>>>>>Context>>isDead) by setting its pc to nil at some point, >>>>>>>presumably after copying the actual return pc into the >>>>>>>BlockCannotReturn exception, to avoid ever trying to resume >>>>>>>the context. >>>>>> >>>>>>Does this mean, in other words, that every context that >>>>>>returns should nil its pc to avoid being "wrongly" >>>>>>reused/executed in the future, which concerns primarily those >>>>>>being referenced somewhere hence potentially executable in >>>>>>the future, is that right? >>>>>>Hypothetical question: would nilling the pc during returns >>>>>>"fix" the example? >>>>>>Thanks a lot for helping me understand this. >>>>>>Best, >>>>>>Jaromir >>>>>> >>>>>> >>>>>> >>>>>>> >>>>>>> >>>>>>>> >>>>>>>>Thanks, >>>>>>>>Jaromir >>>>>>>> >>>>>>>><bdxuqalu.png> >>>>>>>> >>>>>>>>------ Original Message ------ >>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The general-purpose >>>>>>>>Squeak developers list" >>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>Date 11/16/2023 6:48:43 PM >>>>>>>>Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn >>>>>>>>exception >>>>>>>> >>>>>>>>>Hi Jaromir, >>>>>>>>> >>>>>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas >>>>>>>>>><mail(a)jaromir.net> wrote: >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>Hi Nicloas, >>>>>>>>>>No no, I don't have any practical scenario in mind, I'm >>>>>>>>>>just trying to understand why the VM is implemented like >>>>>>>>>>this, whether there were a reason to leave this >>>>>>>>>>possibility of a crash, e.g. it would slow down the VM to >>>>>>>>>>try to prevent such a dumb situation (who would resume >>>>>>>>>>from BCR in his right mind? :) ) - or perhaps I have >>>>>>>>>>overlooked some good reason to even keep this behavior in >>>>>>>>>>the VM. That's all. >>>>>>>>> >>>>>>>>>Let’s first understand what’s really happening. Presumably >>>>>>>>>at tone point a context is resumed those pc is already at >>>>>>>>>the block return bytecode (effectively, because it crashes >>>>>>>>>in JITted code, but I bet the stack vm will crash also, >>>>>>>>>but not as cleanly - it will try and execute the bytes in >>>>>>>>>the encoded method trailer). So which method actually >>>>>>>>>sends resume, and to what, and what state is resume’s >>>>>>>>>receiver when resume is sent? >>>>>>>>> >>>>>>>>> >>>>>>>>>> >>>>>>>>>>Thanks for your reply. >>>>>>>>>>Regards, >>>>>>>>>>Jaromir >>>>>>>>>> >>>>>>>>>> >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>------ Original Message ------ >>>>>>>>>>From "Nicolas Cellier" >>>>>>>>>><nicolas.cellier.aka.nice(a)gmail.com> >>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The >>>>>>>>>>general-purpose Squeak developers list" >>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>Date 11/16/2023 7:20:20 AM >>>>>>>>>>Subject Re: [squeak-dev] Resuming on BlockCannotReturn >>>>>>>>>>exception >>>>>>>>>> >>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>Is there a scenario where it would make sense to resume >>>>>>>>>>>a BlockCannotReturn? >>>>>>>>>>>If not, I would suggest to protect at image side and >>>>>>>>>>>override #resume. >>>>>>>>>>> >>>>>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas >>>>>>>>>>><mail(a)jaromir.net> a écrit : >>>>>>>>>>>>Hi Eliot, Christoph, All, >>>>>>>>>>>> >>>>>>>>>>>>It's known the following example crashes the VM. Is >>>>>>>>>>>>this an intended behavior or a "tolerated bug"? >>>>>>>>>>>> >>>>>>>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>>>>>>>>>> >>>>>>>>>>>>I understand why it crashes: the non-local return has >>>>>>>>>>>>nowhere to return to and so resuming the computation >>>>>>>>>>>>leads to a crash. But why not raise another BCR >>>>>>>>>>>>exception to prevent the crash? Potential infinite >>>>>>>>>>>>loop? Perhaps I'm just missing the purpose of this >>>>>>>>>>>>behavior... >>>>>>>>>>>> >>>>>>>>>>>>Thanks for an explanation. >>>>>>>>>>>> >>>>>>>>>>>>Best, >>>>>>>>>>>>Jaromir >>>>>>>>>>>> >>>>>>>>>>>>-- >>>>>>>>>>>> >>>>>>>>>>>>Jaromir Matas >>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>> >>>>>>> >>>>>>> >>>>>>>-- >>>>>>>_,,,^..^,,,_ >>>>>>>best, Eliot >>>>><Context-cannotReturn.st> >> >> >>-- >>_,,,^..^,,,_ >>best, Eliot ><ProcessTest-testResumeAfterBCR.st>
Hi Christoph,
Thanks for merging the fixes; I've just sent another test in KernelTests-jar.448 to complement them.
Please take a look and if ok I'd appreciate it if you could merge it as well.
Best regards and Happy New Year to you too! Jaromir
On 30-Dec-23 6:15:25 PM, christoph.thiede@student.hpi.uni-potsdam.de wrote:
Hi Jaromir, hi all,
finally I have found the time to review these suggestions. Kernel-jar.1537, Kernel-jar.1538, and Kernel-jar.1539 look excellent to me as well. Clear, straightforward, useful. :-) I have merged them into the trunk via Kernel-ct.1545.
Regarding DebuggerTests>>test16HandleSimulationError, I have patched it via ToolsTests-ct.125. Nothing to rack your brains over: "thisContext pc: nil" just mimicks any kind of unhandled error inside the simulator
- since we now gently handle this via #cannotReturn:, I just replaced
it with "thisContext pc: false". :-) Sorry for not clarifying that earlier and letting you speculate.
Thanks for your work, and I already wish you a happy new year!
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-11-29T13:31:09+00:00, mail@jaromir.net wrote:
Hi Marcel,
[myself] whether the patch would have been necessary should the
#return:from: had been fixed then
Nonsense, I just mixed it up with another issue :)
On 29-Nov-23 1:51:21 PM, "Jaromir Matas" <mail(a)jaromir.net> wrote:
Thanks Marcel! This test somehow slipped my attention :)
The test can no longer work as is. It takes advantage of the
erroneous
behavior of #return:from: in the sense that if you simulate
thisContext pc: nil
it'll happily return to a dead context (i.e. to thisContext from
#pc:
nil context) - which is not what the VM does during runtime. It
should
immediately raise an illegal return exception not only during
runtime
but also during simulation.
The test mentions a patch for an infinite debugger chain (http://forum.world.st/I-broke-the-debugger-td5110752.html). I
wonder
whether the problem could have something to do with this simulation
bug
in return:from:; and a terrible idea occurred to me whether the
patch
would have been necessary should the #return:from: had been fixed
then
;O
We may potentially come up with more examples like this, even in the trunk, where the bug from #return:from: propagated and was taken advantage of. I've found and fixed #runUntilErrorOrReturnFrom: but
more
can still be surviving undetected...
I'd place the test into #expectedFailures for now but maybe it's
time
to remove it; Christoph should decide :)
Thanks again, Jaromir
On 29-Nov-23 10:28:38 AM, "Taeumel, Marcel via Squeak-dev" <squeak-dev(a)lists.squeakfoundation.org> wrote:
Hi Jaromir --
Looks good. Still, what about that #test16HandleSimulationError
now?
:-) It is failing with your changes ... how would you adapt it?
Best, Marcel
Am 28.11.2023 01:29:39 schrieb Jaromir Matas <mail(a)jaromir.net>:
Hi Eliot, Marcel, all,
I've sent a fix Kernel-jar.1539 to the Inbox that solves the remaining bit of the chain of bugs described in the previous post. All tests are green now and I think the root cause has been found
and
fixed.
In this last bit I've created a version of stepToCallee that would identify a potential illegal return to a nil sender and avoid it.
Now this example can be debugged without any problems:
[[self halt. ^ 1] on: BlockCannotReturn do: #resume ] fork
If you're happy with the solution in Kernel-jar.1539, Kernel-jar.1538, Kernel-jar.1537 and the test in
KernelTests-jar.447,
could you please double-check and merge, please? (And remove Kernel-mt.1534 and Tools-jar.1240 from the Inbox)
Best, Jaromir
On 27-Nov-23 12:09:37 AM, "Jaromir Matas" <mail(a)jaromir.net>
wrote:
Hi Eliot, Christoph, all
It looks like there are some more skeletons in the closet :/
If you run this example
[[self halt. ^ 1] on: BlockCannotReturn do: [:ex | ex resume] ]
fork
and step over halt and then step over ^1 you get a nonsensical
error
as a result of decoding nil as an instruction.
It turns out that the root cause is in the #return:from: method:
it
only checks whether aSender is dead but ignores the possibility
that
aSender sender may be nil or dead in which cases the VM also responds with sending #cannotReturn, hence I assume the simulator should do the same. In addition, the VM nills the pc in such scenario, so I added the same functionality here too:
Context >> return: value from: aSender "For simulation. Roll back self to aSender and return value from it. Execute any unwind blocks on the way. ASSUMES aSender is a sender of self"
| newTop | newTop := aSender sender. (aSender isDead or: [newTop isNil or: [newTop isDead]]) ifTrue: "<--------- this is extended ------" [^self pc: nil; send: #cannotReturn: to: self with: {value}]. "<------ pc: nil is added ----" (self findNextUnwindContextUpTo: newTop) ifNotNil: "Send #aboutToReturn:through: with nil as the second argument to avoid this bug: Cannot #stepOver '^2' in example '[^2] ensure: []'. See
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html"
[^self send: #aboutToReturn:through: to: self with: {value. nil}]. self releaseTo: newTop. newTop ifNotNil: [newTop push: value]. ^newTop
In order for this to work #cannotReturn: has to be modified as in Kernel-jar.1537:
Context >> cannotReturn: result
closureOrNil ifNotNil: [^ self cannotReturn: result to: self home sender]. self error: 'Computation has been terminated!' "<----------- this has to be an Error -----"
Then it almost works except when you keep stepping over in the example above, you get an MNU error on `self previousPc` in #cannotReturn:to:` with your solution of the VM crash. If you
don't
mind I've amended your solution and added the final context where the computation couldn't return along with the pc:
Context >> cannotReturn: result to: homeContext "The receiver tried to return result to homeContext that cannot be returned from. Capture the return context/pc in a BlockCannotReturn. Nil the pc to prevent repeat attempts and/or invalid continuation. Answer the result of raising the exception."
| exception previousPc | exception := BlockCannotReturn new. previousPc := pc ifNotNil: [self previousPc]. "<----- here's a fix ----" exception result: result; deadHome: homeContext; finalContext: self; "<----- here's the new state, if that's fine ----" pc: previousPc. pc := nil. ^exception signal
Unfortunately, this is still not the end of the story: there are situations where #runUntilErrorOrReturnFrom: places the two guard contexts below the bottom context. And that is a problem because when the method tries to remove the two guard contexts before returning at the end it uses #stepToCalee to do the job but this unforotunately was (ab)using the above bug in #return:from: -
I'll
explain: #return:from: didn't check whether aSender sender was
nil
and as a result it allowed to simulate a return to a "nil
context"
which was then (ab)used in the clean-up via #stepToCalee in the #runUntilErrorOrReturnFrom:.
When I fixed the #return:from: bug, the
#runUntilErrorOrReturnFrom:
cleanup of the guard contexts no longer works in that very
special
case where the guard contexts are below the bottom context.
There's
one case where this is being used: #terminateAggresively by Christoph.
If I'm right with this analysis, the #runUntilErrorOrReturnFrom: should get fixed too but I'll be away now for a few days and I
won't
be able to respond. If you or Christoph had a chance to take a
look
at Kernel-jar.1538 and Kernel-jar.1537 I'd be very grateful. I
hope
this super long message at least makes some sense :) Best, Jaromir
[1] Kernel-jar.1538, Kernel-jar.1537 [2] KernelTests-jar.447
PS: Christoph,
With Kernel-jar.1538 + Kernel-jar.1537 your example
process := [(c := thisContext) pc: nil. 2+3] newProcess. process runUntil: [:ctx | ctx selector = #cannotReturn:]. self assert: process suspendedContext sender sender = c. self assert: process suspendedContext arguments = {c}.
works fine, I've just corrected your first assert.
On 21-Nov-23 6:40:32 PM, "Eliot Miranda"
<eliot.miranda(a)gmail.com>
wrote:
>Hi Jaromir, > >>On Nov 20, 2023, at 11:51 PM, Jaromir Matas
<mail(a)jaromir.net>
>>wrote: >> >> >>Hi Eliot, >>Very elegant! Now I finally got what you meant exactly :)
Thanks.
>> >>Two questions: >>1. in order for the enclosed test to work I'd need an Error >>instead of Processor debugWithTitle:full: call in
#cannotReturn:.
>>Otherwise I don't know how to catch a plain invocation of the >>Debugger: >> >>cannotReturn: result >> >> closureOrNil ifNotNil: [^ self cannotReturn: result to: self >>home sender]. >> self error: 'Computation has been terminated!' > >Much nicer. > >>2. We are capturing a pc of self which is completely different >>context from homeContext indeed. > >Right. The return is attempted from a specific return bytecode
in a
>specific block. This is the coordinate of the return that cannot
be
>made. This is the relevant point of origin of the cannot return >exception. > >Why the return fails is another matter: >- the home context’s sender is a dead context (cannot be
resumed)
>- the home context’s sender is nil (home already returned from) >- the block activation’s home is nil rather than a context
(should
>not happen) > >But in all these cases the pc of the home context is immaterial. >The hike is being returned through/from, rather than from; the >home’s pc is not relevant. > >>Maybe we could capture self in the exception too to make it
more
>>clear/explicit what is going on: what context the captured pc
is
>>actually associated with. Just a thought... > >Yes, I like that. I also like the idea of somehow passing the >block activation’s pc to the debugger so that the relevant
return
>expression is highlighted in the debugger. > >> >>Thanks again, >>Jaromir > >You’re welcome. I love working in this part of the system.
Thanks
>for dragging me there. I’m in a slump right now and appreciate
the
>fellowship. > >>------ Original Message ------ >>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>To "Jaromir Matas" <mail(a)jaromir.net> >>Cc squeak-dev(a)lists.squeakfoundation.org >>Date 11/21/2023 2:17:21 AM >>Subject Re: Re[2]: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>exception >> >>>Hi Jaromir, >>> >>> see Kernel-eem.1535 for what I was suggesting. This example >>>now has an exception with the right pc value in it: >>> >>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex
resume]]
>>>fork >>> >>>The fix is simply >>> >>>Context>>cannotReturn: result to: homeContext >>> "The receiver tried to return result to homeContext that >>>cannot be returned from. >>> Capture the return pc in a BlockCannotReturn. Nil the pc to >>>prevent repeat >>> attempts and/or invalid continuation. Answer the result of >>>raising the exception." >>> >>> | exception | >>> exception := BlockCannotReturn new. >>> exception >>> result: result; >>> deadHome: homeContext; >>> pc: self previousPc. >>> pc := nil. >>> ^exception signal >>> >>> >>>The VM crash is now avoided. The debugger displays the method, >>>but does not highlight the offending pc, which is no big deal.
A
>>>suitable defaultHandler for B lockCannotReturn may be able to
get
>>>the debugger to highlight correctly on opening. Try the >>>following examples: >>> >>>[[^1] on: BlockCannotReturn do: #resume] fork. >>> >>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex
resume]]
>>>fork >>> >>>[[^1] value] fork. >>> >>>They al; seem to behave perfectly acceptably to me. Does this >>>fix work for you? >>> >>>On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas
<mail(a)jaromir.net>
>>>wrote: >>>>Hi Eliot, >>>> >>>>How about to nil the pc just before making the return: >>>>``` >>>>Context >> #cannotReturn: result >>>> >>>> self push: self pc. "backup the pc for the sake of >>>>debugging" >>>> closureOrNil ifNotNil: [^self cannotReturn: result to: self >>>>home sender; pc: nil]. >>>> Processor debugWithTitle: 'Computation has been terminated!' >>>>translated full: false >>>>``` >>>>The nilled pc should not even potentially interfere with the >>>>#isDead now. >>>> >>>>I hope this is at least a step in the right direction :) >>>> >>>>However, there's still a problem when debugging the
resumption
>>>>of #cannotReturn because the encoders expect a reasonable
index.
>>>>I haven't figured out yet where to place a nil check - #step, >>>>#stepToSendOrReturn... ? >>>> >>>>Thanks again, >>>>Jaromir >>>> >>>> >>>>------ Original Message ------ >>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>Date 11/17/2023 8:36:50 PM >>>>Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn >>>>exception >>>> >>>>>Hi Jaromir, >>>>> >>>>>>On Nov 17, 2023, at 7:05 AM, Jaromir Matas
<mail(a)jaromir.net>
>>>>>>wrote: >>>>>> >>>>>> >>>>>>Eliot, hi again, >>>>>> >>>>>>Please disregard my previous comment about nilling the >>>>>>contexts that have returned. We are indeed talking about
the
>>>>>>context directly under the #cannotReturn context which is >>>>>>totally different from the home context in another thread >>>>>>that's gone. >>>>>> >>>>>>I may still be confused but would nilling the pc of the >>>>>>context directly under the cannotReturn context help?
Here's
>>>>>>what I mean: >>>>>>``` >>>>>>Context >> #cannotReturn: result >>>>>> >>>>>> closureOrNil ifNotNil: [^self pc: nil; cannotReturn: >>>>>>result to: self home sender]. >>>>>> Processor debugWithTitle: 'Computation has been >>>>>>terminated!' translated full: false. >>>>>>``` >>>>>>Instead of crashing the VM invokes the debugger with the >>>>>>'Computation has been terminated!' message. >>>>>> >>>>>>Does this make sense? >>>>> >>>>>Nearly. But it loses the information on what the pc actually >>>>>is, and that’s potentially vital information. So IMO the ox >>>>>should only be nilled between the BlockCannotReturn
exception
>>>>>being created and raised. >>>>> >>>>>[But if you try this don’t be surprised if it causes a few >>>>>temporary problems. It looks to me that without a little >>>>>refactoring this could easily cause an infinite recursion >>>>>around the sending of isDead. I’m sure you’ll be able to fix >>>>>the code to work correctly] >>>>> >>>>>>Thanks, >>>>>>Jaromir >>>>>> >>>>>> >>>>>>------ Original Message ------ >>>>>>From "Jaromir Matas" <mail(a)jaromir.net> >>>>>>To "Eliot Miranda" <eliot.miranda(a)gmail.com>; "The >>>>>>general-purpose Squeak developers list" >>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>Date 11/17/2023 10:15:17 AM >>>>>>Subject [squeak-dev] Re: Resuming on BlockCannotReturn >>>>>>exception >>>>>> >>>>>>>Hi Eliot, >>>>>>> >>>>>>> >>>>>>> >>>>>>>------ Original Message ------ >>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>Cc "The general-purpose Squeak developers list" >>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>Date 11/16/2023 11:52:45 PM >>>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on >>>>>>>BlockCannotReturn exception >>>>>>> >>>>>>>>Hi Jaromir, >>>>>>>> >>>>>>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas >>>>>>>><mail(a)jaromir.net> wrote: >>>>>>>>>Hi Nicolas, Eliot, >>>>>>>>> >>>>>>>>>here's what I understand is happening (see the enclosed >>>>>>>>>screenshot): >>>>>>>>> >>>>>>>>>1) we fork a new process to evaluate [^1] >>>>>>>>>2) the new process evaluates [^1] which means
instruction
>>>>>>>>>18 is being evaluated, hence pc points to instruction 19 >>>>>>>>>now >>>>>>>>>3) however, the home context where ^1 should return to
is
>>>>>>>>>gone by this time (the process that executed the fork
has
>>>>>>>>>already returned - notice the two up arrows in the
debugger
>>>>>>>>>screenshot) >>>>>>>>>4) the VM can't finish the instruction and returns
control
>>>>>>>>>to the image via placing the #cannotReturn: context on
top
>>>>>>>>>of the [^1] context >>>>>>>>>5) #cannotReturn: evaluation results in signalling the
BCR
>>>>>>>>>exception which is then handled by the #resume handler >>>>>>>>> (in our debugged case the [:ex | self halt. ex resume] >>>>>>>>>handler) >>>>>>>>>6) ex resume is evaluated, however, this means
requesting
>>>>>>>>>the VM to evaluate instruction 19 of the [^1] context - >>>>>>>>>which is past the last instruction of the context and
the
>>>>>>>>>crash ensues >>>>>>>>> >>>>>>>>>I wonder whether such situations could/should be
prevented
>>>>>>>>>inside the VM or whether such an expectation is wrong
for
>>>>>>>>>some reason. >>>>>>>> >>>>>>>>As Nicolas says, IMO this is best done at the image
level.
>>>>>>>> >>>>>>>>It could be prevented in the VM, but at great cost, and
only
>>>>>>>>partially. The performance issue is that the last
bytecode
>>>>>>>>in a method is not marked in any way, and that to
determine
>>>>>>>>the last bytecode the bytecodes must be symbolically >>>>>>>>evaluated from the start of the method. See implementors
of
>>>>>>>>endPC at the image level (which defer to the method
trailer)
>>>>>>>>and implementors of endPCOf: in the VMMaker code. Doing
this
>>>>>>>>every time execution commences is prohibitively
expensive.
>>>>>>>>The "only partially" issue is that following the return >>>>>>>>instruction may be other valid bytecodes, but these are
not
>>>>>>>>a continuation. >>>>>>>> >>>>>>>> >>>>>>>>Consider the following code in some block: >>>>>>>> [self expression ifTrue: >>>>>>>> [^1]. >>>>>>>> ^2 >>>>>>>> >>>>>>>>The bytecodes for this are >>>>>>>> pushReceiver >>>>>>>> send #expression >>>>>>>> jumpFalse L1 >>>>>>>> push 1 >>>>>>>> methodReturnTop >>>>>>>>L1 >>>>>>>> push 2 >>>>>>>> methodReturnTop >>>>>>>> >>>>>>>>Clearly if expression is true these should be *no* >>>>>>>>continuation in which ^2 is executed. >>>>>>> >>>>>>>Well, in that case there's a bug because the computation
in
>>>>>>>the following example shouldn't continue past the [^1]
block
>>>>>>>but it silently does: >>>>>>>`[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] >>>>>>>fork` >>>>>>> >>>>>>>The bytecodes are >>>>>>> push true >>>>>>> jumpFalse L1 >>>>>>> push 1 >>>>>>> returnTop >>>>>>>L1 >>>>>>> push nil >>>>>>> blockReturn >>>>>>> >>>>>>> >>>>>>> >>>>>>>> >>>>>>>>So even if the VM did try and detect whether the return
was
>>>>>>>>at the last block method, it would only work for special >>>>>>>>cases. >>>>>>>> >>>>>>>> >>>>>>>>It seems to me the issue is simply that the context that >>>>>>>>cannot be returned from should be marked as dead (see >>>>>>>>Context>>isDead) by setting its pc to nil at some point, >>>>>>>>presumably after copying the actual return pc into the >>>>>>>>BlockCannotReturn exception, to avoid ever trying to
resume
>>>>>>>>the context. >>>>>>> >>>>>>>Does this mean, in other words, that every context that >>>>>>>returns should nil its pc to avoid being "wrongly" >>>>>>>reused/executed in the future, which concerns primarily
those
>>>>>>>being referenced somewhere hence potentially executable in >>>>>>>the future, is that right? >>>>>>>Hypothetical question: would nilling the pc during returns >>>>>>>"fix" the example? >>>>>>>Thanks a lot for helping me understand this. >>>>>>>Best, >>>>>>>Jaromir >>>>>>> >>>>>>> >>>>>>> >>>>>>>> >>>>>>>> >>>>>>>>> >>>>>>>>>Thanks, >>>>>>>>>Jaromir >>>>>>>>> >>>>>>>>><bdxuqalu.png> >>>>>>>>> >>>>>>>>>------ Original Message ------ >>>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The
general-purpose
>>>>>>>>>Squeak developers list" >>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>Date 11/16/2023 6:48:43 PM >>>>>>>>>Subject Re: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>>>>>exception >>>>>>>>> >>>>>>>>>>Hi Jaromir, >>>>>>>>>> >>>>>>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas >>>>>>>>>>><mail(a)jaromir.net> wrote: >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>Hi Nicloas, >>>>>>>>>>>No no, I don't have any practical scenario in mind,
I'm
>>>>>>>>>>>just trying to understand why the VM is implemented
like
>>>>>>>>>>>this, whether there were a reason to leave this >>>>>>>>>>>possibility of a crash, e.g. it would slow down the VM
to
>>>>>>>>>>>try to prevent such a dumb situation (who would resume >>>>>>>>>>>from BCR in his right mind? :) ) - or perhaps I have >>>>>>>>>>>overlooked some good reason to even keep this behavior
in
>>>>>>>>>>>the VM. That's all. >>>>>>>>>> >>>>>>>>>>Let’s first understand what’s really happening.
Presumably
>>>>>>>>>>at tone point a context is resumed those pc is already
at
>>>>>>>>>>the block return bytecode (effectively, because it
crashes
>>>>>>>>>>in JITted code, but I bet the stack vm will crash also, >>>>>>>>>>but not as cleanly - it will try and execute the bytes
in
>>>>>>>>>>the encoded method trailer). So which method actually >>>>>>>>>>sends resume, and to what, and what state is resume’s >>>>>>>>>>receiver when resume is sent? >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>Thanks for your reply. >>>>>>>>>>>Regards, >>>>>>>>>>>Jaromir >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>------ Original Message ------ >>>>>>>>>>>From "Nicolas Cellier" >>>>>>>>>>><nicolas.cellier.aka.nice(a)gmail.com> >>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The >>>>>>>>>>>general-purpose Squeak developers list" >>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>>Date 11/16/2023 7:20:20 AM >>>>>>>>>>>Subject Re: [squeak-dev] Resuming on BlockCannotReturn >>>>>>>>>>>exception >>>>>>>>>>> >>>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>>Is there a scenario where it would make sense to
resume
>>>>>>>>>>>>a BlockCannotReturn? >>>>>>>>>>>>If not, I would suggest to protect at image side and >>>>>>>>>>>>override #resume. >>>>>>>>>>>> >>>>>>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas >>>>>>>>>>>><mail(a)jaromir.net> a écrit : >>>>>>>>>>>>>Hi Eliot, Christoph, All, >>>>>>>>>>>>> >>>>>>>>>>>>>It's known the following example crashes the VM. Is >>>>>>>>>>>>>this an intended behavior or a "tolerated bug"? >>>>>>>>>>>>> >>>>>>>>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>>>>>>>>>>> >>>>>>>>>>>>>I understand why it crashes: the non-local return
has
>>>>>>>>>>>>>nowhere to return to and so resuming the computation >>>>>>>>>>>>>leads to a crash. But why not raise another BCR >>>>>>>>>>>>>exception to prevent the crash? Potential infinite >>>>>>>>>>>>>loop? Perhaps I'm just missing the purpose of this >>>>>>>>>>>>>behavior... >>>>>>>>>>>>> >>>>>>>>>>>>>Thanks for an explanation. >>>>>>>>>>>>> >>>>>>>>>>>>>Best, >>>>>>>>>>>>>Jaromir >>>>>>>>>>>>> >>>>>>>>>>>>>-- >>>>>>>>>>>>> >>>>>>>>>>>>>Jaromir Matas >>>>>>>>>>>>> >>>>>>>>>>>>> >>>>>>>>>>> >>>>>>>> >>>>>>>> >>>>>>>>-- >>>>>>>>_,,,^..^,,,_ >>>>>>>>best, Eliot >>>>>><Context-cannotReturn.st> >>> >>> >>>-- >>>_,,,^..^,,,_ >>>best, Eliot >><ProcessTest-testResumeAfterBCR.st>
nit: You mixed up the order of arguments for #assert:equals: (it is assert: expected equals: actual) and could have used it in the final assert again, but that's clearly no reason to hold back a useful test. ;-) Merged, thanks! :-)
Best, Christoph
--- Sent from Squeak Inbox Talk
On 2023-12-30T17:33:08+00:00, mail@jaromir.net wrote:
Hi Christoph,
Thanks for merging the fixes; I've just sent another test in KernelTests-jar.448 to complement them.
Please take a look and if ok I'd appreciate it if you could merge it as well.
Best regards and Happy New Year to you too! Jaromir
On 30-Dec-23 6:15:25 PM, christoph.thiede(a)student.hpi.uni-potsdam.de wrote:
Hi Jaromir, hi all,
finally I have found the time to review these suggestions. Kernel-jar.1537, Kernel-jar.1538, and Kernel-jar.1539 look excellent to me as well. Clear, straightforward, useful. :-) I have merged them into the trunk via Kernel-ct.1545.
Regarding DebuggerTests>>test16HandleSimulationError, I have patched it via ToolsTests-ct.125. Nothing to rack your brains over: "thisContext pc: nil" just mimicks any kind of unhandled error inside the simulator
- since we now gently handle this via #cannotReturn:, I just replaced
it with "thisContext pc: false". :-) Sorry for not clarifying that earlier and letting you speculate.
Thanks for your work, and I already wish you a happy new year!
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-11-29T13:31:09+00:00, mail(a)jaromir.net wrote:
Hi Marcel,
[myself] whether the patch would have been necessary should the
#return:from: had been fixed then
Nonsense, I just mixed it up with another issue :)
On 29-Nov-23 1:51:21 PM, "Jaromir Matas" <mail(a)jaromir.net> wrote:
Thanks Marcel! This test somehow slipped my attention :)
The test can no longer work as is. It takes advantage of the
erroneous
behavior of #return:from: in the sense that if you simulate
thisContext pc: nil
it'll happily return to a dead context (i.e. to thisContext from
#pc:
nil context) - which is not what the VM does during runtime. It
should
immediately raise an illegal return exception not only during
runtime
but also during simulation.
The test mentions a patch for an infinite debugger chain (http://forum.world.st/I-broke-the-debugger-td5110752.html). I
wonder
whether the problem could have something to do with this simulation
bug
in return:from:; and a terrible idea occurred to me whether the
patch
would have been necessary should the #return:from: had been fixed
then
;O
We may potentially come up with more examples like this, even in the trunk, where the bug from #return:from: propagated and was taken advantage of. I've found and fixed #runUntilErrorOrReturnFrom: but
more
can still be surviving undetected...
I'd place the test into #expectedFailures for now but maybe it's
time
to remove it; Christoph should decide :)
Thanks again, Jaromir
On 29-Nov-23 10:28:38 AM, "Taeumel, Marcel via Squeak-dev" <squeak-dev(a)lists.squeakfoundation.org> wrote:
Hi Jaromir --
Looks good. Still, what about that #test16HandleSimulationError
now?
:-) It is failing with your changes ... how would you adapt it?
Best, Marcel
Am 28.11.2023 01:29:39 schrieb Jaromir Matas <mail(a)jaromir.net>:
Hi Eliot, Marcel, all,
I've sent a fix Kernel-jar.1539 to the Inbox that solves the remaining bit of the chain of bugs described in the previous post. All tests are green now and I think the root cause has been found
and
fixed.
In this last bit I've created a version of stepToCallee that would identify a potential illegal return to a nil sender and avoid it.
Now this example can be debugged without any problems:
[[self halt. ^ 1] on: BlockCannotReturn do: #resume ] fork
If you're happy with the solution in Kernel-jar.1539, Kernel-jar.1538, Kernel-jar.1537 and the test in
KernelTests-jar.447,
could you please double-check and merge, please? (And remove Kernel-mt.1534 and Tools-jar.1240 from the Inbox)
Best, Jaromir
On 27-Nov-23 12:09:37 AM, "Jaromir Matas" <mail(a)jaromir.net>
wrote:
>Hi Eliot, Christoph, all > >It looks like there are some more skeletons in the closet :/ > >If you run this example > >[[self halt. ^ 1] on: BlockCannotReturn do: [:ex | ex resume] ]
fork
> >and step over halt and then step over ^1 you get a nonsensical
error
>as a result of decoding nil as an instruction. > >It turns out that the root cause is in the #return:from: method:
it
>only checks whether aSender is dead but ignores the possibility
that
>aSender sender may be nil or dead in which cases the VM also >responds with sending #cannotReturn, hence I assume the simulator >should do the same. In addition, the VM nills the pc in such >scenario, so I added the same functionality here too: > >Context >> return: value from: aSender > "For simulation. Roll back self to aSender and return value >from it. Execute any unwind blocks on the way. ASSUMES aSender is >a sender of self" > > | newTop | > newTop := aSender sender. > (aSender isDead or: [newTop isNil or: [newTop isDead]]) ifTrue: > "<--------- this is extended ------" > [^self pc: nil; send: #cannotReturn: to: self with: >{value}]. "<------ pc: nil is added ----" > (self findNextUnwindContextUpTo: newTop) ifNotNil: > "Send #aboutToReturn:through: with nil as the second >argument to avoid this bug: > Cannot #stepOver '^2' in example '[^2] ensure: []'. > See
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html" > [^self send: #aboutToReturn:through: to: self with: {value. >nil}]. > self releaseTo: newTop. > newTop ifNotNil: [newTop push: value]. > ^newTop > >In order for this to work #cannotReturn: has to be modified as in >Kernel-jar.1537: > >Context >> cannotReturn: result > > closureOrNil ifNotNil: [^ self cannotReturn: result to: self >home sender]. > self error: 'Computation has been terminated!' >"<----------- this has to be an Error -----" > >Then it almost works except when you keep stepping over in the >example above, you get an MNU error on `self previousPc` in >#cannotReturn:to:` with your solution of the VM crash. If you
don't
>mind I've amended your solution and added the final context where >the computation couldn't return along with the pc: > >Context >> cannotReturn: result to: homeContext > "The receiver tried to return result to homeContext that cannot >be returned from. > Capture the return context/pc in a BlockCannotReturn. Nil the pc >to prevent repeat > attempts and/or invalid continuation. Answer the result of >raising the exception." > > | exception previousPc | > exception := BlockCannotReturn new. > previousPc := pc ifNotNil: [self previousPc]. "<----- here's a >fix ----" > exception > result: result; > deadHome: homeContext; > finalContext: self; "<----- here's the new state, if >that's fine ----" > pc: previousPc. > pc := nil. > ^exception signal > >Unfortunately, this is still not the end of the story: there are >situations where #runUntilErrorOrReturnFrom: places the two guard >contexts below the bottom context. And that is a problem because >when the method tries to remove the two guard contexts before >returning at the end it uses #stepToCalee to do the job but this >unforotunately was (ab)using the above bug in #return:from: -
I'll
>explain: #return:from: didn't check whether aSender sender was
nil
>and as a result it allowed to simulate a return to a "nil
context"
>which was then (ab)used in the clean-up via #stepToCalee in the >#runUntilErrorOrReturnFrom:. > >When I fixed the #return:from: bug, the
#runUntilErrorOrReturnFrom:
>cleanup of the guard contexts no longer works in that very
special
>case where the guard contexts are below the bottom context.
There's
>one case where this is being used: #terminateAggresively by >Christoph. > >If I'm right with this analysis, the #runUntilErrorOrReturnFrom: >should get fixed too but I'll be away now for a few days and I
won't
>be able to respond. If you or Christoph had a chance to take a
look
>at Kernel-jar.1538 and Kernel-jar.1537 I'd be very grateful. I
hope
>this super long message at least makes some sense :) >Best, >Jaromir > >[1] Kernel-jar.1538, Kernel-jar.1537 >[2] KernelTests-jar.447 > > >PS: Christoph, > >With Kernel-jar.1538 + Kernel-jar.1537 your example > >process := > [(c := thisContext) pc: nil. > 2+3] newProcess. >process runUntil: [:ctx | ctx selector = #cannotReturn:]. >self assert: process suspendedContext sender sender = c. >self assert: process suspendedContext arguments = {c}. > >works fine, I've just corrected your first assert. > > > > > >On 21-Nov-23 6:40:32 PM, "Eliot Miranda"
<eliot.miranda(a)gmail.com>
>wrote: > >>Hi Jaromir, >> >>>On Nov 20, 2023, at 11:51 PM, Jaromir Matas
<mail(a)jaromir.net>
>>>wrote: >>> >>> >>>Hi Eliot, >>>Very elegant! Now I finally got what you meant exactly :)
Thanks.
>>> >>>Two questions: >>>1. in order for the enclosed test to work I'd need an Error >>>instead of Processor debugWithTitle:full: call in
#cannotReturn:.
>>>Otherwise I don't know how to catch a plain invocation of the >>>Debugger: >>> >>>cannotReturn: result >>> >>> closureOrNil ifNotNil: [^ self cannotReturn: result to: self >>>home sender]. >>> self error: 'Computation has been terminated!' >> >>Much nicer. >> >>>2. We are capturing a pc of self which is completely different >>>context from homeContext indeed. >> >>Right. The return is attempted from a specific return bytecode
in a
>>specific block. This is the coordinate of the return that cannot
be
>>made. This is the relevant point of origin of the cannot return >>exception. >> >>Why the return fails is another matter: >>- the home context’s sender is a dead context (cannot be
resumed)
>>- the home context’s sender is nil (home already returned from) >>- the block activation’s home is nil rather than a context
(should
>>not happen) >> >>But in all these cases the pc of the home context is immaterial. >>The hike is being returned through/from, rather than from; the >>home’s pc is not relevant. >> >>>Maybe we could capture self in the exception too to make it
more
>>>clear/explicit what is going on: what context the captured pc
is
>>>actually associated with. Just a thought... >> >>Yes, I like that. I also like the idea of somehow passing the >>block activation’s pc to the debugger so that the relevant
return
>>expression is highlighted in the debugger. >> >>> >>>Thanks again, >>>Jaromir >> >>You’re welcome. I love working in this part of the system.
Thanks
>>for dragging me there. I’m in a slump right now and appreciate
the
>>fellowship. >> >>>------ Original Message ------ >>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>To "Jaromir Matas" <mail(a)jaromir.net> >>>Cc squeak-dev(a)lists.squeakfoundation.org >>>Date 11/21/2023 2:17:21 AM >>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>exception >>> >>>>Hi Jaromir, >>>> >>>> see Kernel-eem.1535 for what I was suggesting. This example >>>>now has an exception with the right pc value in it: >>>> >>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex
resume]]
>>>>fork >>>> >>>>The fix is simply >>>> >>>>Context>>cannotReturn: result to: homeContext >>>> "The receiver tried to return result to homeContext that >>>>cannot be returned from. >>>> Capture the return pc in a BlockCannotReturn. Nil the pc to >>>>prevent repeat >>>> attempts and/or invalid continuation. Answer the result of >>>>raising the exception." >>>> >>>> | exception | >>>> exception := BlockCannotReturn new. >>>> exception >>>> result: result; >>>> deadHome: homeContext; >>>> pc: self previousPc. >>>> pc := nil. >>>> ^exception signal >>>> >>>> >>>>The VM crash is now avoided. The debugger displays the method, >>>>but does not highlight the offending pc, which is no big deal.
A
>>>>suitable defaultHandler for B lockCannotReturn may be able to
get
>>>>the debugger to highlight correctly on opening. Try the >>>>following examples: >>>> >>>>[[^1] on: BlockCannotReturn do: #resume] fork. >>>> >>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex
resume]]
>>>>fork >>>> >>>>[[^1] value] fork. >>>> >>>>They al; seem to behave perfectly acceptably to me. Does this >>>>fix work for you? >>>> >>>>On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas
<mail(a)jaromir.net>
>>>>wrote: >>>>>Hi Eliot, >>>>> >>>>>How about to nil the pc just before making the return: >>>>>``` >>>>>Context >> #cannotReturn: result >>>>> >>>>> self push: self pc. "backup the pc for the sake of >>>>>debugging" >>>>> closureOrNil ifNotNil: [^self cannotReturn: result to: self >>>>>home sender; pc: nil]. >>>>> Processor debugWithTitle: 'Computation has been terminated!' >>>>>translated full: false >>>>>``` >>>>>The nilled pc should not even potentially interfere with the >>>>>#isDead now. >>>>> >>>>>I hope this is at least a step in the right direction :) >>>>> >>>>>However, there's still a problem when debugging the
resumption
>>>>>of #cannotReturn because the encoders expect a reasonable
index.
>>>>>I haven't figured out yet where to place a nil check - #step, >>>>>#stepToSendOrReturn... ? >>>>> >>>>>Thanks again, >>>>>Jaromir >>>>> >>>>> >>>>>------ Original Message ------ >>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>Date 11/17/2023 8:36:50 PM >>>>>Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn >>>>>exception >>>>> >>>>>>Hi Jaromir, >>>>>> >>>>>>>On Nov 17, 2023, at 7:05 AM, Jaromir Matas
<mail(a)jaromir.net>
>>>>>>>wrote: >>>>>>> >>>>>>> >>>>>>>Eliot, hi again, >>>>>>> >>>>>>>Please disregard my previous comment about nilling the >>>>>>>contexts that have returned. We are indeed talking about
the
>>>>>>>context directly under the #cannotReturn context which is >>>>>>>totally different from the home context in another thread >>>>>>>that's gone. >>>>>>> >>>>>>>I may still be confused but would nilling the pc of the >>>>>>>context directly under the cannotReturn context help?
Here's
>>>>>>>what I mean: >>>>>>>``` >>>>>>>Context >> #cannotReturn: result >>>>>>> >>>>>>> closureOrNil ifNotNil: [^self pc: nil; cannotReturn: >>>>>>>result to: self home sender]. >>>>>>> Processor debugWithTitle: 'Computation has been >>>>>>>terminated!' translated full: false. >>>>>>>``` >>>>>>>Instead of crashing the VM invokes the debugger with the >>>>>>>'Computation has been terminated!' message. >>>>>>> >>>>>>>Does this make sense? >>>>>> >>>>>>Nearly. But it loses the information on what the pc actually >>>>>>is, and that’s potentially vital information. So IMO the ox >>>>>>should only be nilled between the BlockCannotReturn
exception
>>>>>>being created and raised. >>>>>> >>>>>>[But if you try this don’t be surprised if it causes a few >>>>>>temporary problems. It looks to me that without a little >>>>>>refactoring this could easily cause an infinite recursion >>>>>>around the sending of isDead. I’m sure you’ll be able to fix >>>>>>the code to work correctly] >>>>>> >>>>>>>Thanks, >>>>>>>Jaromir >>>>>>> >>>>>>> >>>>>>>------ Original Message ------ >>>>>>>From "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>To "Eliot Miranda" <eliot.miranda(a)gmail.com>; "The >>>>>>>general-purpose Squeak developers list" >>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>Date 11/17/2023 10:15:17 AM >>>>>>>Subject [squeak-dev] Re: Resuming on BlockCannotReturn >>>>>>>exception >>>>>>> >>>>>>>>Hi Eliot, >>>>>>>> >>>>>>>> >>>>>>>> >>>>>>>>------ Original Message ------ >>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>>Cc "The general-purpose Squeak developers list" >>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>Date 11/16/2023 11:52:45 PM >>>>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on >>>>>>>>BlockCannotReturn exception >>>>>>>> >>>>>>>>>Hi Jaromir, >>>>>>>>> >>>>>>>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas >>>>>>>>><mail(a)jaromir.net> wrote: >>>>>>>>>>Hi Nicolas, Eliot, >>>>>>>>>> >>>>>>>>>>here's what I understand is happening (see the enclosed >>>>>>>>>>screenshot): >>>>>>>>>> >>>>>>>>>>1) we fork a new process to evaluate [^1] >>>>>>>>>>2) the new process evaluates [^1] which means
instruction
>>>>>>>>>>18 is being evaluated, hence pc points to instruction 19 >>>>>>>>>>now >>>>>>>>>>3) however, the home context where ^1 should return to
is
>>>>>>>>>>gone by this time (the process that executed the fork
has
>>>>>>>>>>already returned - notice the two up arrows in the
debugger
>>>>>>>>>>screenshot) >>>>>>>>>>4) the VM can't finish the instruction and returns
control
>>>>>>>>>>to the image via placing the #cannotReturn: context on
top
>>>>>>>>>>of the [^1] context >>>>>>>>>>5) #cannotReturn: evaluation results in signalling the
BCR
>>>>>>>>>>exception which is then handled by the #resume handler >>>>>>>>>> (in our debugged case the [:ex | self halt. ex resume] >>>>>>>>>>handler) >>>>>>>>>>6) ex resume is evaluated, however, this means
requesting
>>>>>>>>>>the VM to evaluate instruction 19 of the [^1] context - >>>>>>>>>>which is past the last instruction of the context and
the
>>>>>>>>>>crash ensues >>>>>>>>>> >>>>>>>>>>I wonder whether such situations could/should be
prevented
>>>>>>>>>>inside the VM or whether such an expectation is wrong
for
>>>>>>>>>>some reason. >>>>>>>>> >>>>>>>>>As Nicolas says, IMO this is best done at the image
level.
>>>>>>>>> >>>>>>>>>It could be prevented in the VM, but at great cost, and
only
>>>>>>>>>partially. The performance issue is that the last
bytecode
>>>>>>>>>in a method is not marked in any way, and that to
determine
>>>>>>>>>the last bytecode the bytecodes must be symbolically >>>>>>>>>evaluated from the start of the method. See implementors
of
>>>>>>>>>endPC at the image level (which defer to the method
trailer)
>>>>>>>>>and implementors of endPCOf: in the VMMaker code. Doing
this
>>>>>>>>>every time execution commences is prohibitively
expensive.
>>>>>>>>>The "only partially" issue is that following the return >>>>>>>>>instruction may be other valid bytecodes, but these are
not
>>>>>>>>>a continuation. >>>>>>>>> >>>>>>>>> >>>>>>>>>Consider the following code in some block: >>>>>>>>> [self expression ifTrue: >>>>>>>>> [^1]. >>>>>>>>> ^2 >>>>>>>>> >>>>>>>>>The bytecodes for this are >>>>>>>>> pushReceiver >>>>>>>>> send #expression >>>>>>>>> jumpFalse L1 >>>>>>>>> push 1 >>>>>>>>> methodReturnTop >>>>>>>>>L1 >>>>>>>>> push 2 >>>>>>>>> methodReturnTop >>>>>>>>> >>>>>>>>>Clearly if expression is true these should be *no* >>>>>>>>>continuation in which ^2 is executed. >>>>>>>> >>>>>>>>Well, in that case there's a bug because the computation
in
>>>>>>>>the following example shouldn't continue past the [^1]
block
>>>>>>>>but it silently does: >>>>>>>>`[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] >>>>>>>>fork` >>>>>>>> >>>>>>>>The bytecodes are >>>>>>>> push true >>>>>>>> jumpFalse L1 >>>>>>>> push 1 >>>>>>>> returnTop >>>>>>>>L1 >>>>>>>> push nil >>>>>>>> blockReturn >>>>>>>> >>>>>>>> >>>>>>>> >>>>>>>>> >>>>>>>>>So even if the VM did try and detect whether the return
was
>>>>>>>>>at the last block method, it would only work for special >>>>>>>>>cases. >>>>>>>>> >>>>>>>>> >>>>>>>>>It seems to me the issue is simply that the context that >>>>>>>>>cannot be returned from should be marked as dead (see >>>>>>>>>Context>>isDead) by setting its pc to nil at some point, >>>>>>>>>presumably after copying the actual return pc into the >>>>>>>>>BlockCannotReturn exception, to avoid ever trying to
resume
>>>>>>>>>the context. >>>>>>>> >>>>>>>>Does this mean, in other words, that every context that >>>>>>>>returns should nil its pc to avoid being "wrongly" >>>>>>>>reused/executed in the future, which concerns primarily
those
>>>>>>>>being referenced somewhere hence potentially executable in >>>>>>>>the future, is that right? >>>>>>>>Hypothetical question: would nilling the pc during returns >>>>>>>>"fix" the example? >>>>>>>>Thanks a lot for helping me understand this. >>>>>>>>Best, >>>>>>>>Jaromir >>>>>>>> >>>>>>>> >>>>>>>> >>>>>>>>> >>>>>>>>> >>>>>>>>>> >>>>>>>>>>Thanks, >>>>>>>>>>Jaromir >>>>>>>>>> >>>>>>>>>><bdxuqalu.png> >>>>>>>>>> >>>>>>>>>>------ Original Message ------ >>>>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The
general-purpose
>>>>>>>>>>Squeak developers list" >>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>Date 11/16/2023 6:48:43 PM >>>>>>>>>>Subject Re: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>>>>>>exception >>>>>>>>>> >>>>>>>>>>>Hi Jaromir, >>>>>>>>>>> >>>>>>>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas >>>>>>>>>>>><mail(a)jaromir.net> wrote: >>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>Hi Nicloas, >>>>>>>>>>>>No no, I don't have any practical scenario in mind,
I'm
>>>>>>>>>>>>just trying to understand why the VM is implemented
like
>>>>>>>>>>>>this, whether there were a reason to leave this >>>>>>>>>>>>possibility of a crash, e.g. it would slow down the VM
to
>>>>>>>>>>>>try to prevent such a dumb situation (who would resume >>>>>>>>>>>>from BCR in his right mind? :) ) - or perhaps I have >>>>>>>>>>>>overlooked some good reason to even keep this behavior
in
>>>>>>>>>>>>the VM. That's all. >>>>>>>>>>> >>>>>>>>>>>Let’s first understand what’s really happening.
Presumably
>>>>>>>>>>>at tone point a context is resumed those pc is already
at
>>>>>>>>>>>the block return bytecode (effectively, because it
crashes
>>>>>>>>>>>in JITted code, but I bet the stack vm will crash also, >>>>>>>>>>>but not as cleanly - it will try and execute the bytes
in
>>>>>>>>>>>the encoded method trailer). So which method actually >>>>>>>>>>>sends resume, and to what, and what state is resume’s >>>>>>>>>>>receiver when resume is sent? >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>Thanks for your reply. >>>>>>>>>>>>Regards, >>>>>>>>>>>>Jaromir >>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>------ Original Message ------ >>>>>>>>>>>>From "Nicolas Cellier" >>>>>>>>>>>><nicolas.cellier.aka.nice(a)gmail.com> >>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The >>>>>>>>>>>>general-purpose Squeak developers list" >>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>>>Date 11/16/2023 7:20:20 AM >>>>>>>>>>>>Subject Re: [squeak-dev] Resuming on BlockCannotReturn >>>>>>>>>>>>exception >>>>>>>>>>>> >>>>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>>>Is there a scenario where it would make sense to
resume
>>>>>>>>>>>>>a BlockCannotReturn? >>>>>>>>>>>>>If not, I would suggest to protect at image side and >>>>>>>>>>>>>override #resume. >>>>>>>>>>>>> >>>>>>>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas >>>>>>>>>>>>><mail(a)jaromir.net> a écrit : >>>>>>>>>>>>>>Hi Eliot, Christoph, All, >>>>>>>>>>>>>> >>>>>>>>>>>>>>It's known the following example crashes the VM. Is >>>>>>>>>>>>>>this an intended behavior or a "tolerated bug"? >>>>>>>>>>>>>> >>>>>>>>>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>>>>>>>>>>>> >>>>>>>>>>>>>>I understand why it crashes: the non-local return
has
>>>>>>>>>>>>>>nowhere to return to and so resuming the computation >>>>>>>>>>>>>>leads to a crash. But why not raise another BCR >>>>>>>>>>>>>>exception to prevent the crash? Potential infinite >>>>>>>>>>>>>>loop? Perhaps I'm just missing the purpose of this >>>>>>>>>>>>>>behavior... >>>>>>>>>>>>>> >>>>>>>>>>>>>>Thanks for an explanation. >>>>>>>>>>>>>> >>>>>>>>>>>>>>Best, >>>>>>>>>>>>>>Jaromir >>>>>>>>>>>>>> >>>>>>>>>>>>>>-- >>>>>>>>>>>>>> >>>>>>>>>>>>>>Jaromir Matas >>>>>>>>>>>>>> >>>>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>> >>>>>>>>> >>>>>>>>>-- >>>>>>>>>_,,,^..^,,,_ >>>>>>>>>best, Eliot >>>>>>><Context-cannotReturn.st> >>>> >>>> >>>>-- >>>>_,,,^..^,,,_ >>>>best, Eliot >>><ProcessTest-testResumeAfterBCR.st>
nit: You mixed up the order of arguments for #assert:equals:
oops, sorry :) It happens to me all the time; I've never actually understood why the strange, almost Yodaesque, order... as if you asked in English:
"Make sure 18 is his age."
Thanks, Jaromir
On 30-Dec-23 9:13:56 PM, christoph.thiede@student.hpi.uni-potsdam.de wrote:
nit: You mixed up the order of arguments for #assert:equals: (it is assert: expected equals: actual) and could have used it in the final assert again, but that's clearly no reason to hold back a useful test. ;-) Merged, thanks! :-)
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-12-30T17:33:08+00:00, mail@jaromir.net wrote:
Hi Christoph,
Thanks for merging the fixes; I've just sent another test in KernelTests-jar.448 to complement them.
Please take a look and if ok I'd appreciate it if you could merge it
as
well.
Best regards and Happy New Year to you too! Jaromir
On 30-Dec-23 6:15:25 PM,
christoph.thiede(a)student.hpi.uni-potsdam.de
wrote:
Hi Jaromir, hi all,
finally I have found the time to review these suggestions. Kernel-jar.1537, Kernel-jar.1538, and Kernel-jar.1539 look excellent
to
me as well. Clear, straightforward, useful. :-) I have merged them
into
the trunk via Kernel-ct.1545.
Regarding DebuggerTests>>test16HandleSimulationError, I have patched
it
via ToolsTests-ct.125. Nothing to rack your brains over:
"thisContext
pc: nil" just mimicks any kind of unhandled error inside the
simulator
- since we now gently handle this via #cannotReturn:, I just
replaced
it with "thisContext pc: false". :-) Sorry for not clarifying that earlier and letting you speculate.
Thanks for your work, and I already wish you a happy new year!
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-11-29T13:31:09+00:00, mail(a)jaromir.net wrote:
Hi Marcel,
[myself] whether the patch would have been necessary should the
#return:from: had been fixed then
Nonsense, I just mixed it up with another issue :)
On 29-Nov-23 1:51:21 PM, "Jaromir Matas" <mail(a)jaromir.net>
wrote:
Thanks Marcel! This test somehow slipped my attention :)
The test can no longer work as is. It takes advantage of the
erroneous
behavior of #return:from: in the sense that if you simulate
thisContext pc: nil
it'll happily return to a dead context (i.e. to thisContext from
#pc:
nil context) - which is not what the VM does during runtime. It
should
immediately raise an illegal return exception not only during
runtime
but also during simulation.
The test mentions a patch for an infinite debugger chain (http://forum.world.st/I-broke-the-debugger-td5110752.html). I
wonder
whether the problem could have something to do with this
simulation
bug
in return:from:; and a terrible idea occurred to me whether the
patch
would have been necessary should the #return:from: had been
fixed
then
;O
We may potentially come up with more examples like this, even in
the
trunk, where the bug from #return:from: propagated and was taken advantage of. I've found and fixed #runUntilErrorOrReturnFrom:
but
more
can still be surviving undetected...
I'd place the test into #expectedFailures for now but maybe it's
time
to remove it; Christoph should decide :)
Thanks again, Jaromir
On 29-Nov-23 10:28:38 AM, "Taeumel, Marcel via Squeak-dev" <squeak-dev(a)lists.squeakfoundation.org> wrote:
Hi Jaromir --
Looks good. Still, what about that #test16HandleSimulationError
now?
:-) It is failing with your changes ... how would you adapt it?
Best, Marcel >Am 28.11.2023 01:29:39 schrieb Jaromir Matas
<mail(a)jaromir.net>:
> >Hi Eliot, Marcel, all, > >I've sent a fix Kernel-jar.1539 to the Inbox that solves the >remaining bit of the chain of bugs described in the previous
post.
>All tests are green now and I think the root cause has been
found
and
>fixed. > >In this last bit I've created a version of stepToCallee that
would
>identify a potential illegal return to a nil sender and avoid
it.
> >Now this example can be debugged without any problems: > >[[self halt. ^ 1] on: BlockCannotReturn do: #resume ] fork > >If you're happy with the solution in Kernel-jar.1539, >Kernel-jar.1538, Kernel-jar.1537 and the test in
KernelTests-jar.447,
>could you please double-check and merge, please? (And remove >Kernel-mt.1534 and Tools-jar.1240 from the Inbox) > >Best, >Jaromir > > > >On 27-Nov-23 12:09:37 AM, "Jaromir Matas" <mail(a)jaromir.net>
wrote:
> >>Hi Eliot, Christoph, all >> >>It looks like there are some more skeletons in the closet :/ >> >>If you run this example >> >>[[self halt. ^ 1] on: BlockCannotReturn do: [:ex | ex resume]
]
fork
>> >>and step over halt and then step over ^1 you get a
nonsensical
error
>>as a result of decoding nil as an instruction. >> >>It turns out that the root cause is in the #return:from:
method:
it
>>only checks whether aSender is dead but ignores the
possibility
that
>>aSender sender may be nil or dead in which cases the VM also >>responds with sending #cannotReturn, hence I assume the
simulator
>>should do the same. In addition, the VM nills the pc in such >>scenario, so I added the same functionality here too: >> >>Context >> return: value from: aSender >> "For simulation. Roll back self to aSender and return value >>from it. Execute any unwind blocks on the way. ASSUMES
aSender is
>>a sender of self" >> >> | newTop | >> newTop := aSender sender. >> (aSender isDead or: [newTop isNil or: [newTop isDead]])
ifTrue:
>> "<--------- this is extended ------" >> [^self pc: nil; send: #cannotReturn: to: self with: >>{value}]. "<------ pc: nil is added ----" >> (self findNextUnwindContextUpTo: newTop) ifNotNil: >> "Send #aboutToReturn:through: with nil as the second >>argument to avoid this bug: >> Cannot #stepOver '^2' in example '[^2] ensure: []'. >> See
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html"
>> [^self send: #aboutToReturn:through: to: self with: {value. >>nil}]. >> self releaseTo: newTop. >> newTop ifNotNil: [newTop push: value]. >> ^newTop >> >>In order for this to work #cannotReturn: has to be modified
as in
>>Kernel-jar.1537: >> >>Context >> cannotReturn: result >> >> closureOrNil ifNotNil: [^ self cannotReturn: result to: self >>home sender]. >> self error: 'Computation has been terminated!' >>"<----------- this has to be an Error -----" >> >>Then it almost works except when you keep stepping over in
the
>>example above, you get an MNU error on `self previousPc` in >>#cannotReturn:to:` with your solution of the VM crash. If you
don't
>>mind I've amended your solution and added the final context
where
>>the computation couldn't return along with the pc: >> >>Context >> cannotReturn: result to: homeContext >> "The receiver tried to return result to homeContext that
cannot
>>be returned from. >> Capture the return context/pc in a BlockCannotReturn. Nil
the pc
>>to prevent repeat >> attempts and/or invalid continuation. Answer the result of >>raising the exception." >> >> | exception previousPc | >> exception := BlockCannotReturn new. >> previousPc := pc ifNotNil: [self previousPc]. "<----- here's
a
>>fix ----" >> exception >> result: result; >> deadHome: homeContext; >> finalContext: self; "<----- here's the new state, if >>that's fine ----" >> pc: previousPc. >> pc := nil. >> ^exception signal >> >>Unfortunately, this is still not the end of the story: there
are
>>situations where #runUntilErrorOrReturnFrom: places the two
guard
>>contexts below the bottom context. And that is a problem
because
>>when the method tries to remove the two guard contexts before >>returning at the end it uses #stepToCalee to do the job but
this
>>unforotunately was (ab)using the above bug in #return:from: -
I'll
>>explain: #return:from: didn't check whether aSender sender
was
nil
>>and as a result it allowed to simulate a return to a "nil
context"
>>which was then (ab)used in the clean-up via #stepToCalee in
the
>>#runUntilErrorOrReturnFrom:. >> >>When I fixed the #return:from: bug, the
#runUntilErrorOrReturnFrom:
>>cleanup of the guard contexts no longer works in that very
special
>>case where the guard contexts are below the bottom context.
There's
>>one case where this is being used: #terminateAggresively by >>Christoph. >> >>If I'm right with this analysis, the
#runUntilErrorOrReturnFrom:
>>should get fixed too but I'll be away now for a few days and
I
won't
>>be able to respond. If you or Christoph had a chance to take
a
look
>>at Kernel-jar.1538 and Kernel-jar.1537 I'd be very grateful.
I
hope
>>this super long message at least makes some sense :) >>Best, >>Jaromir >> >>[1] Kernel-jar.1538, Kernel-jar.1537 >>[2] KernelTests-jar.447 >> >> >>PS: Christoph, >> >>With Kernel-jar.1538 + Kernel-jar.1537 your example >> >>process := >> [(c := thisContext) pc: nil. >> 2+3] newProcess. >>process runUntil: [:ctx | ctx selector = #cannotReturn:]. >>self assert: process suspendedContext sender sender = c. >>self assert: process suspendedContext arguments = {c}. >> >>works fine, I've just corrected your first assert. >> >> >> >> >> >>On 21-Nov-23 6:40:32 PM, "Eliot Miranda"
<eliot.miranda(a)gmail.com>
>>wrote: >> >>>Hi Jaromir, >>> >>>>On Nov 20, 2023, at 11:51 PM, Jaromir Matas
<mail(a)jaromir.net>
>>>>wrote: >>>> >>>> >>>>Hi Eliot, >>>>Very elegant! Now I finally got what you meant exactly :)
Thanks.
>>>> >>>>Two questions: >>>>1. in order for the enclosed test to work I'd need an Error >>>>instead of Processor debugWithTitle:full: call in
#cannotReturn:.
>>>>Otherwise I don't know how to catch a plain invocation of
the
>>>>Debugger: >>>> >>>>cannotReturn: result >>>> >>>> closureOrNil ifNotNil: [^ self cannotReturn: result to:
self
>>>>home sender]. >>>> self error: 'Computation has been terminated!' >>> >>>Much nicer. >>> >>>>2. We are capturing a pc of self which is completely
different
>>>>context from homeContext indeed. >>> >>>Right. The return is attempted from a specific return
bytecode
in a
>>>specific block. This is the coordinate of the return that
cannot
be
>>>made. This is the relevant point of origin of the cannot
return
>>>exception. >>> >>>Why the return fails is another matter: >>>- the home context’s sender is a dead context (cannot be
resumed)
>>>- the home context’s sender is nil (home already returned
from)
>>>- the block activation’s home is nil rather than a context
(should
>>>not happen) >>> >>>But in all these cases the pc of the home context is
immaterial.
>>>The hike is being returned through/from, rather than from;
the
>>>home’s pc is not relevant. >>> >>>>Maybe we could capture self in the exception too to make it
more
>>>>clear/explicit what is going on: what context the captured
pc
is
>>>>actually associated with. Just a thought... >>> >>>Yes, I like that. I also like the idea of somehow passing
the
>>>block activation’s pc to the debugger so that the relevant
return
>>>expression is highlighted in the debugger. >>> >>>> >>>>Thanks again, >>>>Jaromir >>> >>>You’re welcome. I love working in this part of the system.
Thanks
>>>for dragging me there. I’m in a slump right now and
appreciate
the
>>>fellowship. >>> >>>>------ Original Message ------ >>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>Cc squeak-dev(a)lists.squeakfoundation.org >>>>Date 11/21/2023 2:17:21 AM >>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>exception >>>> >>>>>Hi Jaromir, >>>>> >>>>> see Kernel-eem.1535 for what I was suggesting. This
example
>>>>>now has an exception with the right pc value in it: >>>>> >>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex
resume]]
>>>>>fork >>>>> >>>>>The fix is simply >>>>> >>>>>Context>>cannotReturn: result to: homeContext >>>>> "The receiver tried to return result to homeContext that >>>>>cannot be returned from. >>>>> Capture the return pc in a BlockCannotReturn. Nil the pc
to
>>>>>prevent repeat >>>>> attempts and/or invalid continuation. Answer the result
of
>>>>>raising the exception." >>>>> >>>>> | exception | >>>>> exception := BlockCannotReturn new. >>>>> exception >>>>> result: result; >>>>> deadHome: homeContext; >>>>> pc: self previousPc. >>>>> pc := nil. >>>>> ^exception signal >>>>> >>>>> >>>>>The VM crash is now avoided. The debugger displays the
method,
>>>>>but does not highlight the offending pc, which is no big
deal.
A
>>>>>suitable defaultHandler for B lockCannotReturn may be able
to
get
>>>>>the debugger to highlight correctly on opening. Try the >>>>>following examples: >>>>> >>>>>[[^1] on: BlockCannotReturn do: #resume] fork. >>>>> >>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex
resume]]
>>>>>fork >>>>> >>>>>[[^1] value] fork. >>>>> >>>>>They al; seem to behave perfectly acceptably to me. Does
this
>>>>>fix work for you? >>>>> >>>>>On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas
<mail(a)jaromir.net>
>>>>>wrote: >>>>>>Hi Eliot, >>>>>> >>>>>>How about to nil the pc just before making the return: >>>>>>``` >>>>>>Context >> #cannotReturn: result >>>>>> >>>>>> self push: self pc. "backup the pc for the sake of >>>>>>debugging" >>>>>> closureOrNil ifNotNil: [^self cannotReturn: result to:
self
>>>>>>home sender; pc: nil]. >>>>>> Processor debugWithTitle: 'Computation has been
terminated!'
>>>>>>translated full: false >>>>>>``` >>>>>>The nilled pc should not even potentially interfere with
the
>>>>>>#isDead now. >>>>>> >>>>>>I hope this is at least a step in the right direction :) >>>>>> >>>>>>However, there's still a problem when debugging the
resumption
>>>>>>of #cannotReturn because the encoders expect a reasonable
index.
>>>>>>I haven't figured out yet where to place a nil check -
#step,
>>>>>>#stepToSendOrReturn... ? >>>>>> >>>>>>Thanks again, >>>>>>Jaromir >>>>>> >>>>>> >>>>>>------ Original Message ------ >>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>>Date 11/17/2023 8:36:50 PM >>>>>>Subject Re: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>>exception >>>>>> >>>>>>>Hi Jaromir, >>>>>>> >>>>>>>>On Nov 17, 2023, at 7:05 AM, Jaromir Matas
<mail(a)jaromir.net>
>>>>>>>>wrote: >>>>>>>> >>>>>>>> >>>>>>>>Eliot, hi again, >>>>>>>> >>>>>>>>Please disregard my previous comment about nilling the >>>>>>>>contexts that have returned. We are indeed talking
about
the
>>>>>>>>context directly under the #cannotReturn context which
is
>>>>>>>>totally different from the home context in another
thread
>>>>>>>>that's gone. >>>>>>>> >>>>>>>>I may still be confused but would nilling the pc of the >>>>>>>>context directly under the cannotReturn context help?
Here's
>>>>>>>>what I mean: >>>>>>>>``` >>>>>>>>Context >> #cannotReturn: result >>>>>>>> >>>>>>>> closureOrNil ifNotNil: [^self pc: nil; cannotReturn: >>>>>>>>result to: self home sender]. >>>>>>>> Processor debugWithTitle: 'Computation has been >>>>>>>>terminated!' translated full: false. >>>>>>>>``` >>>>>>>>Instead of crashing the VM invokes the debugger with
the
>>>>>>>>'Computation has been terminated!' message. >>>>>>>> >>>>>>>>Does this make sense? >>>>>>> >>>>>>>Nearly. But it loses the information on what the pc
actually
>>>>>>>is, and that’s potentially vital information. So IMO the
ox
>>>>>>>should only be nilled between the BlockCannotReturn
exception
>>>>>>>being created and raised. >>>>>>> >>>>>>>[But if you try this don’t be surprised if it causes a
few
>>>>>>>temporary problems. It looks to me that without a little >>>>>>>refactoring this could easily cause an infinite
recursion
>>>>>>>around the sending of isDead. I’m sure you’ll be able to
fix
>>>>>>>the code to work correctly] >>>>>>> >>>>>>>>Thanks, >>>>>>>>Jaromir >>>>>>>> >>>>>>>> >>>>>>>>------ Original Message ------ >>>>>>>>From "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>>To "Eliot Miranda" <eliot.miranda(a)gmail.com>; "The >>>>>>>>general-purpose Squeak developers list" >>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>Date 11/17/2023 10:15:17 AM >>>>>>>>Subject [squeak-dev] Re: Resuming on BlockCannotReturn >>>>>>>>exception >>>>>>>> >>>>>>>>>Hi Eliot, >>>>>>>>> >>>>>>>>> >>>>>>>>> >>>>>>>>>------ Original Message ------ >>>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>>>Cc "The general-purpose Squeak developers list" >>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>Date 11/16/2023 11:52:45 PM >>>>>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on >>>>>>>>>BlockCannotReturn exception >>>>>>>>> >>>>>>>>>>Hi Jaromir, >>>>>>>>>> >>>>>>>>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas >>>>>>>>>><mail(a)jaromir.net> wrote: >>>>>>>>>>>Hi Nicolas, Eliot, >>>>>>>>>>> >>>>>>>>>>>here's what I understand is happening (see the
enclosed
>>>>>>>>>>>screenshot): >>>>>>>>>>> >>>>>>>>>>>1) we fork a new process to evaluate [^1] >>>>>>>>>>>2) the new process evaluates [^1] which means
instruction
>>>>>>>>>>>18 is being evaluated, hence pc points to
instruction 19
>>>>>>>>>>>now >>>>>>>>>>>3) however, the home context where ^1 should return
to
is
>>>>>>>>>>>gone by this time (the process that executed the
fork
has
>>>>>>>>>>>already returned - notice the two up arrows in the
debugger
>>>>>>>>>>>screenshot) >>>>>>>>>>>4) the VM can't finish the instruction and returns
control
>>>>>>>>>>>to the image via placing the #cannotReturn: context
on
top
>>>>>>>>>>>of the [^1] context >>>>>>>>>>>5) #cannotReturn: evaluation results in signalling
the
BCR
>>>>>>>>>>>exception which is then handled by the #resume
handler
>>>>>>>>>>> (in our debugged case the [:ex | self halt. ex
resume]
>>>>>>>>>>>handler) >>>>>>>>>>>6) ex resume is evaluated, however, this means
requesting
>>>>>>>>>>>the VM to evaluate instruction 19 of the [^1]
context -
>>>>>>>>>>>which is past the last instruction of the context
and
the
>>>>>>>>>>>crash ensues >>>>>>>>>>> >>>>>>>>>>>I wonder whether such situations could/should be
prevented
>>>>>>>>>>>inside the VM or whether such an expectation is
wrong
for
>>>>>>>>>>>some reason. >>>>>>>>>> >>>>>>>>>>As Nicolas says, IMO this is best done at the image
level.
>>>>>>>>>> >>>>>>>>>>It could be prevented in the VM, but at great cost,
and
only
>>>>>>>>>>partially. The performance issue is that the last
bytecode
>>>>>>>>>>in a method is not marked in any way, and that to
determine
>>>>>>>>>>the last bytecode the bytecodes must be symbolically >>>>>>>>>>evaluated from the start of the method. See
implementors
of
>>>>>>>>>>endPC at the image level (which defer to the method
trailer)
>>>>>>>>>>and implementors of endPCOf: in the VMMaker code.
Doing
this
>>>>>>>>>>every time execution commences is prohibitively
expensive.
>>>>>>>>>>The "only partially" issue is that following the
return
>>>>>>>>>>instruction may be other valid bytecodes, but these
are
not
>>>>>>>>>>a continuation. >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>Consider the following code in some block: >>>>>>>>>> [self expression ifTrue: >>>>>>>>>> [^1]. >>>>>>>>>> ^2 >>>>>>>>>> >>>>>>>>>>The bytecodes for this are >>>>>>>>>> pushReceiver >>>>>>>>>> send #expression >>>>>>>>>> jumpFalse L1 >>>>>>>>>> push 1 >>>>>>>>>> methodReturnTop >>>>>>>>>>L1 >>>>>>>>>> push 2 >>>>>>>>>> methodReturnTop >>>>>>>>>> >>>>>>>>>>Clearly if expression is true these should be *no* >>>>>>>>>>continuation in which ^2 is executed. >>>>>>>>> >>>>>>>>>Well, in that case there's a bug because the
computation
in
>>>>>>>>>the following example shouldn't continue past the [^1]
block
>>>>>>>>>but it silently does: >>>>>>>>>`[[true ifTrue: [^ 1]] on: BlockCannotReturn do:
#resume ]
>>>>>>>>>fork` >>>>>>>>> >>>>>>>>>The bytecodes are >>>>>>>>> push true >>>>>>>>> jumpFalse L1 >>>>>>>>> push 1 >>>>>>>>> returnTop >>>>>>>>>L1 >>>>>>>>> push nil >>>>>>>>> blockReturn >>>>>>>>> >>>>>>>>> >>>>>>>>> >>>>>>>>>> >>>>>>>>>>So even if the VM did try and detect whether the
return
was
>>>>>>>>>>at the last block method, it would only work for
special
>>>>>>>>>>cases. >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>It seems to me the issue is simply that the context
that
>>>>>>>>>>cannot be returned from should be marked as dead (see >>>>>>>>>>Context>>isDead) by setting its pc to nil at some
point,
>>>>>>>>>>presumably after copying the actual return pc into
the
>>>>>>>>>>BlockCannotReturn exception, to avoid ever trying to
resume
>>>>>>>>>>the context. >>>>>>>>> >>>>>>>>>Does this mean, in other words, that every context
that
>>>>>>>>>returns should nil its pc to avoid being "wrongly" >>>>>>>>>reused/executed in the future, which concerns
primarily
those
>>>>>>>>>being referenced somewhere hence potentially
executable in
>>>>>>>>>the future, is that right? >>>>>>>>>Hypothetical question: would nilling the pc during
returns
>>>>>>>>>"fix" the example? >>>>>>>>>Thanks a lot for helping me understand this. >>>>>>>>>Best, >>>>>>>>>Jaromir >>>>>>>>> >>>>>>>>> >>>>>>>>> >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>Thanks, >>>>>>>>>>>Jaromir >>>>>>>>>>> >>>>>>>>>>><bdxuqalu.png> >>>>>>>>>>> >>>>>>>>>>>------ Original Message ------ >>>>>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The
general-purpose
>>>>>>>>>>>Squeak developers list" >>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>>Date 11/16/2023 6:48:43 PM >>>>>>>>>>>Subject Re: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>>>>>>>exception >>>>>>>>>>> >>>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>> >>>>>>>>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas >>>>>>>>>>>>><mail(a)jaromir.net> wrote: >>>>>>>>>>>>> >>>>>>>>>>>>> >>>>>>>>>>>>>Hi Nicloas, >>>>>>>>>>>>>No no, I don't have any practical scenario in
mind,
I'm
>>>>>>>>>>>>>just trying to understand why the VM is
implemented
like
>>>>>>>>>>>>>this, whether there were a reason to leave this >>>>>>>>>>>>>possibility of a crash, e.g. it would slow down
the VM
to
>>>>>>>>>>>>>try to prevent such a dumb situation (who would
resume
>>>>>>>>>>>>>from BCR in his right mind? :) ) - or perhaps I
have
>>>>>>>>>>>>>overlooked some good reason to even keep this
behavior
in
>>>>>>>>>>>>>the VM. That's all. >>>>>>>>>>>> >>>>>>>>>>>>Let’s first understand what’s really happening.
Presumably
>>>>>>>>>>>>at tone point a context is resumed those pc is
already
at
>>>>>>>>>>>>the block return bytecode (effectively, because it
crashes
>>>>>>>>>>>>in JITted code, but I bet the stack vm will crash
also,
>>>>>>>>>>>>but not as cleanly - it will try and execute the
bytes
in
>>>>>>>>>>>>the encoded method trailer). So which method
actually
>>>>>>>>>>>>sends resume, and to what, and what state is
resume’s
>>>>>>>>>>>>receiver when resume is sent? >>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>> >>>>>>>>>>>>>Thanks for your reply. >>>>>>>>>>>>>Regards, >>>>>>>>>>>>>Jaromir >>>>>>>>>>>>> >>>>>>>>>>>>> >>>>>>>>>>>>> >>>>>>>>>>>>> >>>>>>>>>>>>>------ Original Message ------ >>>>>>>>>>>>>From "Nicolas Cellier" >>>>>>>>>>>>><nicolas.cellier.aka.nice(a)gmail.com> >>>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The >>>>>>>>>>>>>general-purpose Squeak developers list" >>>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>>>>Date 11/16/2023 7:20:20 AM >>>>>>>>>>>>>Subject Re: [squeak-dev] Resuming on
BlockCannotReturn
>>>>>>>>>>>>>exception >>>>>>>>>>>>> >>>>>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>>>>Is there a scenario where it would make sense to
resume
>>>>>>>>>>>>>>a BlockCannotReturn? >>>>>>>>>>>>>>If not, I would suggest to protect at image side
and
>>>>>>>>>>>>>>override #resume. >>>>>>>>>>>>>> >>>>>>>>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas >>>>>>>>>>>>>><mail(a)jaromir.net> a écrit : >>>>>>>>>>>>>>>Hi Eliot, Christoph, All, >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>It's known the following example crashes the VM.
Is
>>>>>>>>>>>>>>>this an intended behavior or a "tolerated bug"? >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>I understand why it crashes: the non-local
return
has
>>>>>>>>>>>>>>>nowhere to return to and so resuming the
computation
>>>>>>>>>>>>>>>leads to a crash. But why not raise another BCR >>>>>>>>>>>>>>>exception to prevent the crash? Potential
infinite
>>>>>>>>>>>>>>>loop? Perhaps I'm just missing the purpose of
this
>>>>>>>>>>>>>>>behavior... >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>Thanks for an explanation. >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>Best, >>>>>>>>>>>>>>>Jaromir >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>-- >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>Jaromir Matas >>>>>>>>>>>>>>> >>>>>>>>>>>>>>> >>>>>>>>>>>>> >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>-- >>>>>>>>>>_,,,^..^,,,_ >>>>>>>>>>best, Eliot >>>>>>>><Context-cannotReturn.st> >>>>> >>>>> >>>>>-- >>>>>_,,,^..^,,,_ >>>>>best, Eliot >>>><ProcessTest-testResumeAfterBCR.st>
Hi Jaromir,
I found a breaking change in the new behavior of Context>>#return:from: while using the TraceDebugger:
In the past we could say:
c := [2+3] asContext. [c] whileNotNil: [c := c step].
With your change, the script runs forever because the last step does not answer nil as before but activates a new #cannotReturn:.
This behavior seems not be expected anywhere in the trunk (if my first search was complete), and you are right that the new behavior aligns closer to the VM behavior. Still, the old code seemed to explicitly intend this - see the "newTop ifNotNil:" at the bottom of the method.
I wonder whether we should keep this. For me it is not a big deal; I can just change my script like this:
c := [2+3] asContext. [c sender isNil and: [c willReturn]] whileNotNil: [c := c step].
I just wonder whether this could a breaking or unintended change for anything else. For [^2] ensure: [] it would not be a big deal, we could just change the check in question to (aSender isDead or: [newTop notNil and: [newTop isDead]]) ifTrue:. I am tending against restoring the old behavior, but I am unsure. What is your opinion on this?
Best, Christoph
--- Sent from Squeak Inbox Talk
On 2023-12-30T21:13:37+00:00, mail@jaromir.net wrote:
nit: You mixed up the order of arguments for #assert:equals:
oops, sorry :) It happens to me all the time; I've never actually understood why the strange, almost Yodaesque, order... as if you asked in English:
"Make sure 18 is his age."
Thanks, Jaromir
On 30-Dec-23 9:13:56 PM, christoph.thiede(a)student.hpi.uni-potsdam.de wrote:
nit: You mixed up the order of arguments for #assert:equals: (it is assert: expected equals: actual) and could have used it in the final assert again, but that's clearly no reason to hold back a useful test. ;-) Merged, thanks! :-)
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-12-30T17:33:08+00:00, mail(a)jaromir.net wrote:
Hi Christoph,
Thanks for merging the fixes; I've just sent another test in KernelTests-jar.448 to complement them.
Please take a look and if ok I'd appreciate it if you could merge it
as
well.
Best regards and Happy New Year to you too! Jaromir
On 30-Dec-23 6:15:25 PM,
christoph.thiede(a)student.hpi.uni-potsdam.de
wrote:
Hi Jaromir, hi all,
finally I have found the time to review these suggestions. Kernel-jar.1537, Kernel-jar.1538, and Kernel-jar.1539 look excellent
to
me as well. Clear, straightforward, useful. :-) I have merged them
into
the trunk via Kernel-ct.1545.
Regarding DebuggerTests>>test16HandleSimulationError, I have patched
it
via ToolsTests-ct.125. Nothing to rack your brains over:
"thisContext
pc: nil" just mimicks any kind of unhandled error inside the
simulator
- since we now gently handle this via #cannotReturn:, I just
replaced
it with "thisContext pc: false". :-) Sorry for not clarifying that earlier and letting you speculate.
Thanks for your work, and I already wish you a happy new year!
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-11-29T13:31:09+00:00, mail(a)jaromir.net wrote:
Hi Marcel,
[myself] whether the patch would have been necessary should the
#return:from: had been fixed then
Nonsense, I just mixed it up with another issue :)
On 29-Nov-23 1:51:21 PM, "Jaromir Matas" <mail(a)jaromir.net>
wrote:
Thanks Marcel! This test somehow slipped my attention :)
The test can no longer work as is. It takes advantage of the
erroneous
behavior of #return:from: in the sense that if you simulate
thisContext pc: nil
it'll happily return to a dead context (i.e. to thisContext from
#pc:
nil context) - which is not what the VM does during runtime. It
should
immediately raise an illegal return exception not only during
runtime
but also during simulation.
The test mentions a patch for an infinite debugger chain (http://forum.world.st/I-broke-the-debugger-td5110752.html). I
wonder
whether the problem could have something to do with this
simulation
bug
in return:from:; and a terrible idea occurred to me whether the
patch
would have been necessary should the #return:from: had been
fixed
then
;O
We may potentially come up with more examples like this, even in
the
trunk, where the bug from #return:from: propagated and was taken advantage of. I've found and fixed #runUntilErrorOrReturnFrom:
but
more
can still be surviving undetected...
I'd place the test into #expectedFailures for now but maybe it's
time
to remove it; Christoph should decide :)
Thanks again, Jaromir
On 29-Nov-23 10:28:38 AM, "Taeumel, Marcel via Squeak-dev" <squeak-dev(a)lists.squeakfoundation.org> wrote:
>Hi Jaromir -- > >Looks good. Still, what about that #test16HandleSimulationError
now?
>:-) It is failing with your changes ... how would you adapt it? > > > >Best, >Marcel >>Am 28.11.2023 01:29:39 schrieb Jaromir Matas
<mail(a)jaromir.net>:
>> >>Hi Eliot, Marcel, all, >> >>I've sent a fix Kernel-jar.1539 to the Inbox that solves the >>remaining bit of the chain of bugs described in the previous
post.
>>All tests are green now and I think the root cause has been
found
and
>>fixed. >> >>In this last bit I've created a version of stepToCallee that
would
>>identify a potential illegal return to a nil sender and avoid
it.
>> >>Now this example can be debugged without any problems: >> >>[[self halt. ^ 1] on: BlockCannotReturn do: #resume ] fork >> >>If you're happy with the solution in Kernel-jar.1539, >>Kernel-jar.1538, Kernel-jar.1537 and the test in
KernelTests-jar.447,
>>could you please double-check and merge, please? (And remove >>Kernel-mt.1534 and Tools-jar.1240 from the Inbox) >> >>Best, >>Jaromir >> >> >> >>On 27-Nov-23 12:09:37 AM, "Jaromir Matas" <mail(a)jaromir.net>
wrote:
>> >>>Hi Eliot, Christoph, all >>> >>>It looks like there are some more skeletons in the closet :/ >>> >>>If you run this example >>> >>>[[self halt. ^ 1] on: BlockCannotReturn do: [:ex | ex resume]
]
fork
>>> >>>and step over halt and then step over ^1 you get a
nonsensical
error
>>>as a result of decoding nil as an instruction. >>> >>>It turns out that the root cause is in the #return:from:
method:
it
>>>only checks whether aSender is dead but ignores the
possibility
that
>>>aSender sender may be nil or dead in which cases the VM also >>>responds with sending #cannotReturn, hence I assume the
simulator
>>>should do the same. In addition, the VM nills the pc in such >>>scenario, so I added the same functionality here too: >>> >>>Context >> return: value from: aSender >>> "For simulation. Roll back self to aSender and return value >>>from it. Execute any unwind blocks on the way. ASSUMES
aSender is
>>>a sender of self" >>> >>> | newTop | >>> newTop := aSender sender. >>> (aSender isDead or: [newTop isNil or: [newTop isDead]])
ifTrue:
>>> "<--------- this is extended ------" >>> [^self pc: nil; send: #cannotReturn: to: self with: >>>{value}]. "<------ pc: nil is added ----" >>> (self findNextUnwindContextUpTo: newTop) ifNotNil: >>> "Send #aboutToReturn:through: with nil as the second >>>argument to avoid this bug: >>> Cannot #stepOver '^2' in example '[^2] ensure: []'. >>> See
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html" >>> [^self send: #aboutToReturn:through: to: self with: {value. >>>nil}]. >>> self releaseTo: newTop. >>> newTop ifNotNil: [newTop push: value]. >>> ^newTop >>> >>>In order for this to work #cannotReturn: has to be modified
as in
>>>Kernel-jar.1537: >>> >>>Context >> cannotReturn: result >>> >>> closureOrNil ifNotNil: [^ self cannotReturn: result to: self >>>home sender]. >>> self error: 'Computation has been terminated!' >>>"<----------- this has to be an Error -----" >>> >>>Then it almost works except when you keep stepping over in
the
>>>example above, you get an MNU error on `self previousPc` in >>>#cannotReturn:to:` with your solution of the VM crash. If you
don't
>>>mind I've amended your solution and added the final context
where
>>>the computation couldn't return along with the pc: >>> >>>Context >> cannotReturn: result to: homeContext >>> "The receiver tried to return result to homeContext that
cannot
>>>be returned from. >>> Capture the return context/pc in a BlockCannotReturn. Nil
the pc
>>>to prevent repeat >>> attempts and/or invalid continuation. Answer the result of >>>raising the exception." >>> >>> | exception previousPc | >>> exception := BlockCannotReturn new. >>> previousPc := pc ifNotNil: [self previousPc]. "<----- here's
a
>>>fix ----" >>> exception >>> result: result; >>> deadHome: homeContext; >>> finalContext: self; "<----- here's the new state, if >>>that's fine ----" >>> pc: previousPc. >>> pc := nil. >>> ^exception signal >>> >>>Unfortunately, this is still not the end of the story: there
are
>>>situations where #runUntilErrorOrReturnFrom: places the two
guard
>>>contexts below the bottom context. And that is a problem
because
>>>when the method tries to remove the two guard contexts before >>>returning at the end it uses #stepToCalee to do the job but
this
>>>unforotunately was (ab)using the above bug in #return:from: -
I'll
>>>explain: #return:from: didn't check whether aSender sender
was
nil
>>>and as a result it allowed to simulate a return to a "nil
context"
>>>which was then (ab)used in the clean-up via #stepToCalee in
the
>>>#runUntilErrorOrReturnFrom:. >>> >>>When I fixed the #return:from: bug, the
#runUntilErrorOrReturnFrom:
>>>cleanup of the guard contexts no longer works in that very
special
>>>case where the guard contexts are below the bottom context.
There's
>>>one case where this is being used: #terminateAggresively by >>>Christoph. >>> >>>If I'm right with this analysis, the
#runUntilErrorOrReturnFrom:
>>>should get fixed too but I'll be away now for a few days and
I
won't
>>>be able to respond. If you or Christoph had a chance to take
a
look
>>>at Kernel-jar.1538 and Kernel-jar.1537 I'd be very grateful.
I
hope
>>>this super long message at least makes some sense :) >>>Best, >>>Jaromir >>> >>>[1] Kernel-jar.1538, Kernel-jar.1537 >>>[2] KernelTests-jar.447 >>> >>> >>>PS: Christoph, >>> >>>With Kernel-jar.1538 + Kernel-jar.1537 your example >>> >>>process := >>> [(c := thisContext) pc: nil. >>> 2+3] newProcess. >>>process runUntil: [:ctx | ctx selector = #cannotReturn:]. >>>self assert: process suspendedContext sender sender = c. >>>self assert: process suspendedContext arguments = {c}. >>> >>>works fine, I've just corrected your first assert. >>> >>> >>> >>> >>> >>>On 21-Nov-23 6:40:32 PM, "Eliot Miranda"
<eliot.miranda(a)gmail.com>
>>>wrote: >>> >>>>Hi Jaromir, >>>> >>>>>On Nov 20, 2023, at 11:51 PM, Jaromir Matas
<mail(a)jaromir.net>
>>>>>wrote: >>>>> >>>>> >>>>>Hi Eliot, >>>>>Very elegant! Now I finally got what you meant exactly :)
Thanks.
>>>>> >>>>>Two questions: >>>>>1. in order for the enclosed test to work I'd need an Error >>>>>instead of Processor debugWithTitle:full: call in
#cannotReturn:.
>>>>>Otherwise I don't know how to catch a plain invocation of
the
>>>>>Debugger: >>>>> >>>>>cannotReturn: result >>>>> >>>>> closureOrNil ifNotNil: [^ self cannotReturn: result to:
self
>>>>>home sender]. >>>>> self error: 'Computation has been terminated!' >>>> >>>>Much nicer. >>>> >>>>>2. We are capturing a pc of self which is completely
different
>>>>>context from homeContext indeed. >>>> >>>>Right. The return is attempted from a specific return
bytecode
in a
>>>>specific block. This is the coordinate of the return that
cannot
be
>>>>made. This is the relevant point of origin of the cannot
return
>>>>exception. >>>> >>>>Why the return fails is another matter: >>>>- the home context’s sender is a dead context (cannot be
resumed)
>>>>- the home context’s sender is nil (home already returned
from)
>>>>- the block activation’s home is nil rather than a context
(should
>>>>not happen) >>>> >>>>But in all these cases the pc of the home context is
immaterial.
>>>>The hike is being returned through/from, rather than from;
the
>>>>home’s pc is not relevant. >>>> >>>>>Maybe we could capture self in the exception too to make it
more
>>>>>clear/explicit what is going on: what context the captured
pc
is
>>>>>actually associated with. Just a thought... >>>> >>>>Yes, I like that. I also like the idea of somehow passing
the
>>>>block activation’s pc to the debugger so that the relevant
return
>>>>expression is highlighted in the debugger. >>>> >>>>> >>>>>Thanks again, >>>>>Jaromir >>>> >>>>You’re welcome. I love working in this part of the system.
Thanks
>>>>for dragging me there. I’m in a slump right now and
appreciate
the
>>>>fellowship. >>>> >>>>>------ Original Message ------ >>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>Cc squeak-dev(a)lists.squeakfoundation.org >>>>>Date 11/21/2023 2:17:21 AM >>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>exception >>>>> >>>>>>Hi Jaromir, >>>>>> >>>>>> see Kernel-eem.1535 for what I was suggesting. This
example
>>>>>>now has an exception with the right pc value in it: >>>>>> >>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex
resume]]
>>>>>>fork >>>>>> >>>>>>The fix is simply >>>>>> >>>>>>Context>>cannotReturn: result to: homeContext >>>>>> "The receiver tried to return result to homeContext that >>>>>>cannot be returned from. >>>>>> Capture the return pc in a BlockCannotReturn. Nil the pc
to
>>>>>>prevent repeat >>>>>> attempts and/or invalid continuation. Answer the result
of
>>>>>>raising the exception." >>>>>> >>>>>> | exception | >>>>>> exception := BlockCannotReturn new. >>>>>> exception >>>>>> result: result; >>>>>> deadHome: homeContext; >>>>>> pc: self previousPc. >>>>>> pc := nil. >>>>>> ^exception signal >>>>>> >>>>>> >>>>>>The VM crash is now avoided. The debugger displays the
method,
>>>>>>but does not highlight the offending pc, which is no big
deal.
A
>>>>>>suitable defaultHandler for B lockCannotReturn may be able
to
get
>>>>>>the debugger to highlight correctly on opening. Try the >>>>>>following examples: >>>>>> >>>>>>[[^1] on: BlockCannotReturn do: #resume] fork. >>>>>> >>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex
resume]]
>>>>>>fork >>>>>> >>>>>>[[^1] value] fork. >>>>>> >>>>>>They al; seem to behave perfectly acceptably to me. Does
this
>>>>>>fix work for you? >>>>>> >>>>>>On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas
<mail(a)jaromir.net>
>>>>>>wrote: >>>>>>>Hi Eliot, >>>>>>> >>>>>>>How about to nil the pc just before making the return: >>>>>>>``` >>>>>>>Context >> #cannotReturn: result >>>>>>> >>>>>>> self push: self pc. "backup the pc for the sake of >>>>>>>debugging" >>>>>>> closureOrNil ifNotNil: [^self cannotReturn: result to:
self
>>>>>>>home sender; pc: nil]. >>>>>>> Processor debugWithTitle: 'Computation has been
terminated!'
>>>>>>>translated full: false >>>>>>>``` >>>>>>>The nilled pc should not even potentially interfere with
the
>>>>>>>#isDead now. >>>>>>> >>>>>>>I hope this is at least a step in the right direction :) >>>>>>> >>>>>>>However, there's still a problem when debugging the
resumption
>>>>>>>of #cannotReturn because the encoders expect a reasonable
index.
>>>>>>>I haven't figured out yet where to place a nil check -
#step,
>>>>>>>#stepToSendOrReturn... ? >>>>>>> >>>>>>>Thanks again, >>>>>>>Jaromir >>>>>>> >>>>>>> >>>>>>>------ Original Message ------ >>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>Date 11/17/2023 8:36:50 PM >>>>>>>Subject Re: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>>>exception >>>>>>> >>>>>>>>Hi Jaromir, >>>>>>>> >>>>>>>>>On Nov 17, 2023, at 7:05 AM, Jaromir Matas
<mail(a)jaromir.net>
>>>>>>>>>wrote: >>>>>>>>> >>>>>>>>> >>>>>>>>>Eliot, hi again, >>>>>>>>> >>>>>>>>>Please disregard my previous comment about nilling the >>>>>>>>>contexts that have returned. We are indeed talking
about
the
>>>>>>>>>context directly under the #cannotReturn context which
is
>>>>>>>>>totally different from the home context in another
thread
>>>>>>>>>that's gone. >>>>>>>>> >>>>>>>>>I may still be confused but would nilling the pc of the >>>>>>>>>context directly under the cannotReturn context help?
Here's
>>>>>>>>>what I mean: >>>>>>>>>``` >>>>>>>>>Context >> #cannotReturn: result >>>>>>>>> >>>>>>>>> closureOrNil ifNotNil: [^self pc: nil; cannotReturn: >>>>>>>>>result to: self home sender]. >>>>>>>>> Processor debugWithTitle: 'Computation has been >>>>>>>>>terminated!' translated full: false. >>>>>>>>>``` >>>>>>>>>Instead of crashing the VM invokes the debugger with
the
>>>>>>>>>'Computation has been terminated!' message. >>>>>>>>> >>>>>>>>>Does this make sense? >>>>>>>> >>>>>>>>Nearly. But it loses the information on what the pc
actually
>>>>>>>>is, and that’s potentially vital information. So IMO the
ox
>>>>>>>>should only be nilled between the BlockCannotReturn
exception
>>>>>>>>being created and raised. >>>>>>>> >>>>>>>>[But if you try this don’t be surprised if it causes a
few
>>>>>>>>temporary problems. It looks to me that without a little >>>>>>>>refactoring this could easily cause an infinite
recursion
>>>>>>>>around the sending of isDead. I’m sure you’ll be able to
fix
>>>>>>>>the code to work correctly] >>>>>>>> >>>>>>>>>Thanks, >>>>>>>>>Jaromir >>>>>>>>> >>>>>>>>> >>>>>>>>>------ Original Message ------ >>>>>>>>>From "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>>>To "Eliot Miranda" <eliot.miranda(a)gmail.com>; "The >>>>>>>>>general-purpose Squeak developers list" >>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>Date 11/17/2023 10:15:17 AM >>>>>>>>>Subject [squeak-dev] Re: Resuming on BlockCannotReturn >>>>>>>>>exception >>>>>>>>> >>>>>>>>>>Hi Eliot, >>>>>>>>>> >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>------ Original Message ------ >>>>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>>>>Cc "The general-purpose Squeak developers list" >>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>Date 11/16/2023 11:52:45 PM >>>>>>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on >>>>>>>>>>BlockCannotReturn exception >>>>>>>>>> >>>>>>>>>>>Hi Jaromir, >>>>>>>>>>> >>>>>>>>>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas >>>>>>>>>>><mail(a)jaromir.net> wrote: >>>>>>>>>>>>Hi Nicolas, Eliot, >>>>>>>>>>>> >>>>>>>>>>>>here's what I understand is happening (see the
enclosed
>>>>>>>>>>>>screenshot): >>>>>>>>>>>> >>>>>>>>>>>>1) we fork a new process to evaluate [^1] >>>>>>>>>>>>2) the new process evaluates [^1] which means
instruction
>>>>>>>>>>>>18 is being evaluated, hence pc points to
instruction 19
>>>>>>>>>>>>now >>>>>>>>>>>>3) however, the home context where ^1 should return
to
is
>>>>>>>>>>>>gone by this time (the process that executed the
fork
has
>>>>>>>>>>>>already returned - notice the two up arrows in the
debugger
>>>>>>>>>>>>screenshot) >>>>>>>>>>>>4) the VM can't finish the instruction and returns
control
>>>>>>>>>>>>to the image via placing the #cannotReturn: context
on
top
>>>>>>>>>>>>of the [^1] context >>>>>>>>>>>>5) #cannotReturn: evaluation results in signalling
the
BCR
>>>>>>>>>>>>exception which is then handled by the #resume
handler
>>>>>>>>>>>> (in our debugged case the [:ex | self halt. ex
resume]
>>>>>>>>>>>>handler) >>>>>>>>>>>>6) ex resume is evaluated, however, this means
requesting
>>>>>>>>>>>>the VM to evaluate instruction 19 of the [^1]
context -
>>>>>>>>>>>>which is past the last instruction of the context
and
the
>>>>>>>>>>>>crash ensues >>>>>>>>>>>> >>>>>>>>>>>>I wonder whether such situations could/should be
prevented
>>>>>>>>>>>>inside the VM or whether such an expectation is
wrong
for
>>>>>>>>>>>>some reason. >>>>>>>>>>> >>>>>>>>>>>As Nicolas says, IMO this is best done at the image
level.
>>>>>>>>>>> >>>>>>>>>>>It could be prevented in the VM, but at great cost,
and
only
>>>>>>>>>>>partially. The performance issue is that the last
bytecode
>>>>>>>>>>>in a method is not marked in any way, and that to
determine
>>>>>>>>>>>the last bytecode the bytecodes must be symbolically >>>>>>>>>>>evaluated from the start of the method. See
implementors
of
>>>>>>>>>>>endPC at the image level (which defer to the method
trailer)
>>>>>>>>>>>and implementors of endPCOf: in the VMMaker code.
Doing
this
>>>>>>>>>>>every time execution commences is prohibitively
expensive.
>>>>>>>>>>>The "only partially" issue is that following the
return
>>>>>>>>>>>instruction may be other valid bytecodes, but these
are
not
>>>>>>>>>>>a continuation. >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>Consider the following code in some block: >>>>>>>>>>> [self expression ifTrue: >>>>>>>>>>> [^1]. >>>>>>>>>>> ^2 >>>>>>>>>>> >>>>>>>>>>>The bytecodes for this are >>>>>>>>>>> pushReceiver >>>>>>>>>>> send #expression >>>>>>>>>>> jumpFalse L1 >>>>>>>>>>> push 1 >>>>>>>>>>> methodReturnTop >>>>>>>>>>>L1 >>>>>>>>>>> push 2 >>>>>>>>>>> methodReturnTop >>>>>>>>>>> >>>>>>>>>>>Clearly if expression is true these should be *no* >>>>>>>>>>>continuation in which ^2 is executed. >>>>>>>>>> >>>>>>>>>>Well, in that case there's a bug because the
computation
in
>>>>>>>>>>the following example shouldn't continue past the [^1]
block
>>>>>>>>>>but it silently does: >>>>>>>>>>`[[true ifTrue: [^ 1]] on: BlockCannotReturn do:
#resume ]
>>>>>>>>>>fork` >>>>>>>>>> >>>>>>>>>>The bytecodes are >>>>>>>>>> push true >>>>>>>>>> jumpFalse L1 >>>>>>>>>> push 1 >>>>>>>>>> returnTop >>>>>>>>>>L1 >>>>>>>>>> push nil >>>>>>>>>> blockReturn >>>>>>>>>> >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>So even if the VM did try and detect whether the
return
was
>>>>>>>>>>>at the last block method, it would only work for
special
>>>>>>>>>>>cases. >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>It seems to me the issue is simply that the context
that
>>>>>>>>>>>cannot be returned from should be marked as dead (see >>>>>>>>>>>Context>>isDead) by setting its pc to nil at some
point,
>>>>>>>>>>>presumably after copying the actual return pc into
the
>>>>>>>>>>>BlockCannotReturn exception, to avoid ever trying to
resume
>>>>>>>>>>>the context. >>>>>>>>>> >>>>>>>>>>Does this mean, in other words, that every context
that
>>>>>>>>>>returns should nil its pc to avoid being "wrongly" >>>>>>>>>>reused/executed in the future, which concerns
primarily
those
>>>>>>>>>>being referenced somewhere hence potentially
executable in
>>>>>>>>>>the future, is that right? >>>>>>>>>>Hypothetical question: would nilling the pc during
returns
>>>>>>>>>>"fix" the example? >>>>>>>>>>Thanks a lot for helping me understand this. >>>>>>>>>>Best, >>>>>>>>>>Jaromir >>>>>>>>>> >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>Thanks, >>>>>>>>>>>>Jaromir >>>>>>>>>>>> >>>>>>>>>>>><bdxuqalu.png> >>>>>>>>>>>> >>>>>>>>>>>>------ Original Message ------ >>>>>>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The
general-purpose
>>>>>>>>>>>>Squeak developers list" >>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>>>Date 11/16/2023 6:48:43 PM >>>>>>>>>>>>Subject Re: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>>>>>>>>exception >>>>>>>>>>>> >>>>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>>> >>>>>>>>>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas >>>>>>>>>>>>>><mail(a)jaromir.net> wrote: >>>>>>>>>>>>>> >>>>>>>>>>>>>> >>>>>>>>>>>>>>Hi Nicloas, >>>>>>>>>>>>>>No no, I don't have any practical scenario in
mind,
I'm
>>>>>>>>>>>>>>just trying to understand why the VM is
implemented
like
>>>>>>>>>>>>>>this, whether there were a reason to leave this >>>>>>>>>>>>>>possibility of a crash, e.g. it would slow down
the VM
to
>>>>>>>>>>>>>>try to prevent such a dumb situation (who would
resume
>>>>>>>>>>>>>>from BCR in his right mind? :) ) - or perhaps I
have
>>>>>>>>>>>>>>overlooked some good reason to even keep this
behavior
in
>>>>>>>>>>>>>>the VM. That's all. >>>>>>>>>>>>> >>>>>>>>>>>>>Let’s first understand what’s really happening.
Presumably
>>>>>>>>>>>>>at tone point a context is resumed those pc is
already
at
>>>>>>>>>>>>>the block return bytecode (effectively, because it
crashes
>>>>>>>>>>>>>in JITted code, but I bet the stack vm will crash
also,
>>>>>>>>>>>>>but not as cleanly - it will try and execute the
bytes
in
>>>>>>>>>>>>>the encoded method trailer). So which method
actually
>>>>>>>>>>>>>sends resume, and to what, and what state is
resume’s
>>>>>>>>>>>>>receiver when resume is sent? >>>>>>>>>>>>> >>>>>>>>>>>>> >>>>>>>>>>>>>> >>>>>>>>>>>>>>Thanks for your reply. >>>>>>>>>>>>>>Regards, >>>>>>>>>>>>>>Jaromir >>>>>>>>>>>>>> >>>>>>>>>>>>>> >>>>>>>>>>>>>> >>>>>>>>>>>>>> >>>>>>>>>>>>>>------ Original Message ------ >>>>>>>>>>>>>>From "Nicolas Cellier" >>>>>>>>>>>>>><nicolas.cellier.aka.nice(a)gmail.com> >>>>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The >>>>>>>>>>>>>>general-purpose Squeak developers list" >>>>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>>>>>Date 11/16/2023 7:20:20 AM >>>>>>>>>>>>>>Subject Re: [squeak-dev] Resuming on
BlockCannotReturn
>>>>>>>>>>>>>>exception >>>>>>>>>>>>>> >>>>>>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>>>>>Is there a scenario where it would make sense to
resume
>>>>>>>>>>>>>>>a BlockCannotReturn? >>>>>>>>>>>>>>>If not, I would suggest to protect at image side
and
>>>>>>>>>>>>>>>override #resume. >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas >>>>>>>>>>>>>>><mail(a)jaromir.net> a écrit : >>>>>>>>>>>>>>>>Hi Eliot, Christoph, All, >>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>It's known the following example crashes the VM.
Is
>>>>>>>>>>>>>>>>this an intended behavior or a "tolerated bug"? >>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>I understand why it crashes: the non-local
return
has
>>>>>>>>>>>>>>>>nowhere to return to and so resuming the
computation
>>>>>>>>>>>>>>>>leads to a crash. But why not raise another BCR >>>>>>>>>>>>>>>>exception to prevent the crash? Potential
infinite
>>>>>>>>>>>>>>>>loop? Perhaps I'm just missing the purpose of
this
>>>>>>>>>>>>>>>>behavior... >>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>Thanks for an explanation. >>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>Best, >>>>>>>>>>>>>>>>Jaromir >>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>-- >>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>Jaromir Matas >>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>> >>>>>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>-- >>>>>>>>>>>_,,,^..^,,,_ >>>>>>>>>>>best, Eliot >>>>>>>>><Context-cannotReturn.st> >>>>>> >>>>>> >>>>>>-- >>>>>>_,,,^..^,,,_ >>>>>>best, Eliot >>>>><ProcessTest-testResumeAfterBCR.st>
On 2023-12-30T23:07:54+01:00, christoph.thiede@student.hpi.uni-potsdam.de wrote:
Hi Jaromir,
I found a breaking change in the new behavior of Context>>#return:from: while using the TraceDebugger:
In the past we could say:
c := [2+3] asContext. [c] whileNotNil: [c := c step].
With your change, the script runs forever because the last step does not answer nil as before but activates a new #cannotReturn:.
This behavior seems not be expected anywhere in the trunk (if my first search was complete), and you are right that the new behavior aligns closer to the VM behavior. Still, the old code seemed to explicitly intend this - see the "newTop ifNotNil:" at the bottom of the method.
I wonder whether we should keep this. For me it is not a big deal; I can just change my script like this:
c := [2+3] asContext. [c sender isNil and: [c willReturn]] whileNotNil: [c := c step].
#whileFalse:, not #whileNotNil:, of course:
c := [2+3] asContext. [c sender isNil and: [c willReturn]] whileFalse: [c := c step].
I just wonder whether this could a breaking or unintended change for anything else. For [^2] ensure: [] it would not be a big deal, we could just change the check in question to (aSender isDead or: [newTop notNil and: [newTop isDead]]) ifTrue:. I am tending against restoring the old behavior, but I am unsure. What is your opinion on this?
Best, Christoph
Sent from Squeak Inbox Talk
On 2023-12-30T21:13:37+00:00, mail(a)jaromir.net wrote:
nit: You mixed up the order of arguments for #assert:equals:
oops, sorry :) It happens to me all the time; I've never actually understood why the strange, almost Yodaesque, order... as if you asked in English:
"Make sure 18 is his age."
Thanks, Jaromir
On 30-Dec-23 9:13:56 PM, christoph.thiede(a)student.hpi.uni-potsdam.de wrote:
nit: You mixed up the order of arguments for #assert:equals: (it is assert: expected equals: actual) and could have used it in the final assert again, but that's clearly no reason to hold back a useful test. ;-) Merged, thanks! :-)
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-12-30T17:33:08+00:00, mail(a)jaromir.net wrote:
Hi Christoph,
Thanks for merging the fixes; I've just sent another test in KernelTests-jar.448 to complement them.
Please take a look and if ok I'd appreciate it if you could merge it
as
well.
Best regards and Happy New Year to you too! Jaromir
On 30-Dec-23 6:15:25 PM,
christoph.thiede(a)student.hpi.uni-potsdam.de
wrote:
Hi Jaromir, hi all,
finally I have found the time to review these suggestions. Kernel-jar.1537, Kernel-jar.1538, and Kernel-jar.1539 look excellent
to
me as well. Clear, straightforward, useful. :-) I have merged them
into
the trunk via Kernel-ct.1545.
Regarding DebuggerTests>>test16HandleSimulationError, I have patched
it
via ToolsTests-ct.125. Nothing to rack your brains over:
"thisContext
pc: nil" just mimicks any kind of unhandled error inside the
simulator
- since we now gently handle this via #cannotReturn:, I just
replaced
it with "thisContext pc: false". :-) Sorry for not clarifying that earlier and letting you speculate.
Thanks for your work, and I already wish you a happy new year!
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-11-29T13:31:09+00:00, mail(a)jaromir.net wrote:
Hi Marcel,
> [myself] whether the patch would have been necessary should the #return:from: had been fixed then
Nonsense, I just mixed it up with another issue :)
On 29-Nov-23 1:51:21 PM, "Jaromir Matas" <mail(a)jaromir.net>
wrote:
>Thanks Marcel! This test somehow slipped my attention :) > >The test can no longer work as is. It takes advantage of the
erroneous
>behavior of #return:from: in the sense that if you simulate > > thisContext pc: nil > >it'll happily return to a dead context (i.e. to thisContext from
#pc:
>nil context) - which is not what the VM does during runtime. It
should
>immediately raise an illegal return exception not only during
runtime
>but also during simulation. > >The test mentions a patch for an infinite debugger chain >(http://forum.world.st/I-broke-the-debugger-td5110752.html). I
wonder
>whether the problem could have something to do with this
simulation
bug
>in return:from:; and a terrible idea occurred to me whether the
patch
>would have been necessary should the #return:from: had been
fixed
then
>;O > >We may potentially come up with more examples like this, even in
the
>trunk, where the bug from #return:from: propagated and was taken >advantage of. I've found and fixed #runUntilErrorOrReturnFrom:
but
more
>can still be surviving undetected... > >I'd place the test into #expectedFailures for now but maybe it's
time
>to remove it; Christoph should decide :) > >Thanks again, >Jaromir > > >On 29-Nov-23 10:28:38 AM, "Taeumel, Marcel via Squeak-dev" ><squeak-dev(a)lists.squeakfoundation.org> wrote: > >>Hi Jaromir -- >> >>Looks good. Still, what about that #test16HandleSimulationError
now?
>>:-) It is failing with your changes ... how would you adapt it? >> >> >> >>Best, >>Marcel >>>Am 28.11.2023 01:29:39 schrieb Jaromir Matas
<mail(a)jaromir.net>:
>>> >>>Hi Eliot, Marcel, all, >>> >>>I've sent a fix Kernel-jar.1539 to the Inbox that solves the >>>remaining bit of the chain of bugs described in the previous
post.
>>>All tests are green now and I think the root cause has been
found
and
>>>fixed. >>> >>>In this last bit I've created a version of stepToCallee that
would
>>>identify a potential illegal return to a nil sender and avoid
it.
>>> >>>Now this example can be debugged without any problems: >>> >>>[[self halt. ^ 1] on: BlockCannotReturn do: #resume ] fork >>> >>>If you're happy with the solution in Kernel-jar.1539, >>>Kernel-jar.1538, Kernel-jar.1537 and the test in
KernelTests-jar.447,
>>>could you please double-check and merge, please? (And remove >>>Kernel-mt.1534 and Tools-jar.1240 from the Inbox) >>> >>>Best, >>>Jaromir >>> >>> >>> >>>On 27-Nov-23 12:09:37 AM, "Jaromir Matas" <mail(a)jaromir.net>
wrote:
>>> >>>>Hi Eliot, Christoph, all >>>> >>>>It looks like there are some more skeletons in the closet :/ >>>> >>>>If you run this example >>>> >>>>[[self halt. ^ 1] on: BlockCannotReturn do: [:ex | ex resume]
]
fork
>>>> >>>>and step over halt and then step over ^1 you get a
nonsensical
error
>>>>as a result of decoding nil as an instruction. >>>> >>>>It turns out that the root cause is in the #return:from:
method:
it
>>>>only checks whether aSender is dead but ignores the
possibility
that
>>>>aSender sender may be nil or dead in which cases the VM also >>>>responds with sending #cannotReturn, hence I assume the
simulator
>>>>should do the same. In addition, the VM nills the pc in such >>>>scenario, so I added the same functionality here too: >>>> >>>>Context >> return: value from: aSender >>>> "For simulation. Roll back self to aSender and return value >>>>from it. Execute any unwind blocks on the way. ASSUMES
aSender is
>>>>a sender of self" >>>> >>>> | newTop | >>>> newTop := aSender sender. >>>> (aSender isDead or: [newTop isNil or: [newTop isDead]])
ifTrue:
>>>> "<--------- this is extended ------" >>>> [^self pc: nil; send: #cannotReturn: to: self with: >>>>{value}]. "<------ pc: nil is added ----" >>>> (self findNextUnwindContextUpTo: newTop) ifNotNil: >>>> "Send #aboutToReturn:through: with nil as the second >>>>argument to avoid this bug: >>>> Cannot #stepOver '^2' in example '[^2] ensure: []'. >>>> See
>http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html
>http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html" >>>> [^self send: #aboutToReturn:through: to: self with: {value. >>>>nil}]. >>>> self releaseTo: newTop. >>>> newTop ifNotNil: [newTop push: value]. >>>> ^newTop >>>> >>>>In order for this to work #cannotReturn: has to be modified
as in
>>>>Kernel-jar.1537: >>>> >>>>Context >> cannotReturn: result >>>> >>>> closureOrNil ifNotNil: [^ self cannotReturn: result to: self >>>>home sender]. >>>> self error: 'Computation has been terminated!' >>>>"<----------- this has to be an Error -----" >>>> >>>>Then it almost works except when you keep stepping over in
the
>>>>example above, you get an MNU error on `self previousPc` in >>>>#cannotReturn:to:` with your solution of the VM crash. If you
don't
>>>>mind I've amended your solution and added the final context
where
>>>>the computation couldn't return along with the pc: >>>> >>>>Context >> cannotReturn: result to: homeContext >>>> "The receiver tried to return result to homeContext that
cannot
>>>>be returned from. >>>> Capture the return context/pc in a BlockCannotReturn. Nil
the pc
>>>>to prevent repeat >>>> attempts and/or invalid continuation. Answer the result of >>>>raising the exception." >>>> >>>> | exception previousPc | >>>> exception := BlockCannotReturn new. >>>> previousPc := pc ifNotNil: [self previousPc]. "<----- here's
a
>>>>fix ----" >>>> exception >>>> result: result; >>>> deadHome: homeContext; >>>> finalContext: self; "<----- here's the new state, if >>>>that's fine ----" >>>> pc: previousPc. >>>> pc := nil. >>>> ^exception signal >>>> >>>>Unfortunately, this is still not the end of the story: there
are
>>>>situations where #runUntilErrorOrReturnFrom: places the two
guard
>>>>contexts below the bottom context. And that is a problem
because
>>>>when the method tries to remove the two guard contexts before >>>>returning at the end it uses #stepToCalee to do the job but
this
>>>>unforotunately was (ab)using the above bug in #return:from: -
I'll
>>>>explain: #return:from: didn't check whether aSender sender
was
nil
>>>>and as a result it allowed to simulate a return to a "nil
context"
>>>>which was then (ab)used in the clean-up via #stepToCalee in
the
>>>>#runUntilErrorOrReturnFrom:. >>>> >>>>When I fixed the #return:from: bug, the
#runUntilErrorOrReturnFrom:
>>>>cleanup of the guard contexts no longer works in that very
special
>>>>case where the guard contexts are below the bottom context.
There's
>>>>one case where this is being used: #terminateAggresively by >>>>Christoph. >>>> >>>>If I'm right with this analysis, the
#runUntilErrorOrReturnFrom:
>>>>should get fixed too but I'll be away now for a few days and
I
won't
>>>>be able to respond. If you or Christoph had a chance to take
a
look
>>>>at Kernel-jar.1538 and Kernel-jar.1537 I'd be very grateful.
I
hope
>>>>this super long message at least makes some sense :) >>>>Best, >>>>Jaromir >>>> >>>>[1] Kernel-jar.1538, Kernel-jar.1537 >>>>[2] KernelTests-jar.447 >>>> >>>> >>>>PS: Christoph, >>>> >>>>With Kernel-jar.1538 + Kernel-jar.1537 your example >>>> >>>>process := >>>> [(c := thisContext) pc: nil. >>>> 2+3] newProcess. >>>>process runUntil: [:ctx | ctx selector = #cannotReturn:]. >>>>self assert: process suspendedContext sender sender = c. >>>>self assert: process suspendedContext arguments = {c}. >>>> >>>>works fine, I've just corrected your first assert. >>>> >>>> >>>> >>>> >>>> >>>>On 21-Nov-23 6:40:32 PM, "Eliot Miranda"
<eliot.miranda(a)gmail.com>
>>>>wrote: >>>> >>>>>Hi Jaromir, >>>>> >>>>>>On Nov 20, 2023, at 11:51 PM, Jaromir Matas
<mail(a)jaromir.net>
>>>>>>wrote: >>>>>> >>>>>> >>>>>>Hi Eliot, >>>>>>Very elegant! Now I finally got what you meant exactly :)
Thanks.
>>>>>> >>>>>>Two questions: >>>>>>1. in order for the enclosed test to work I'd need an Error >>>>>>instead of Processor debugWithTitle:full: call in
#cannotReturn:.
>>>>>>Otherwise I don't know how to catch a plain invocation of
the
>>>>>>Debugger: >>>>>> >>>>>>cannotReturn: result >>>>>> >>>>>> closureOrNil ifNotNil: [^ self cannotReturn: result to:
self
>>>>>>home sender]. >>>>>> self error: 'Computation has been terminated!' >>>>> >>>>>Much nicer. >>>>> >>>>>>2. We are capturing a pc of self which is completely
different
>>>>>>context from homeContext indeed. >>>>> >>>>>Right. The return is attempted from a specific return
bytecode
in a
>>>>>specific block. This is the coordinate of the return that
cannot
be
>>>>>made. This is the relevant point of origin of the cannot
return
>>>>>exception. >>>>> >>>>>Why the return fails is another matter: >>>>>- the home context’s sender is a dead context (cannot be
resumed)
>>>>>- the home context’s sender is nil (home already returned
from)
>>>>>- the block activation’s home is nil rather than a context
(should
>>>>>not happen) >>>>> >>>>>But in all these cases the pc of the home context is
immaterial.
>>>>>The hike is being returned through/from, rather than from;
the
>>>>>home’s pc is not relevant. >>>>> >>>>>>Maybe we could capture self in the exception too to make it
more
>>>>>>clear/explicit what is going on: what context the captured
pc
is
>>>>>>actually associated with. Just a thought... >>>>> >>>>>Yes, I like that. I also like the idea of somehow passing
the
>>>>>block activation’s pc to the debugger so that the relevant
return
>>>>>expression is highlighted in the debugger. >>>>> >>>>>> >>>>>>Thanks again, >>>>>>Jaromir >>>>> >>>>>You’re welcome. I love working in this part of the system.
Thanks
>>>>>for dragging me there. I’m in a slump right now and
appreciate
the
>>>>>fellowship. >>>>> >>>>>>------ Original Message ------ >>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>>Cc squeak-dev(a)lists.squeakfoundation.org >>>>>>Date 11/21/2023 2:17:21 AM >>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>>exception >>>>>> >>>>>>>Hi Jaromir, >>>>>>> >>>>>>> see Kernel-eem.1535 for what I was suggesting. This
example
>>>>>>>now has an exception with the right pc value in it: >>>>>>> >>>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex
resume]]
>>>>>>>fork >>>>>>> >>>>>>>The fix is simply >>>>>>> >>>>>>>Context>>cannotReturn: result to: homeContext >>>>>>> "The receiver tried to return result to homeContext that >>>>>>>cannot be returned from. >>>>>>> Capture the return pc in a BlockCannotReturn. Nil the pc
to
>>>>>>>prevent repeat >>>>>>> attempts and/or invalid continuation. Answer the result
of
>>>>>>>raising the exception." >>>>>>> >>>>>>> | exception | >>>>>>> exception := BlockCannotReturn new. >>>>>>> exception >>>>>>> result: result; >>>>>>> deadHome: homeContext; >>>>>>> pc: self previousPc. >>>>>>> pc := nil. >>>>>>> ^exception signal >>>>>>> >>>>>>> >>>>>>>The VM crash is now avoided. The debugger displays the
method,
>>>>>>>but does not highlight the offending pc, which is no big
deal.
A
>>>>>>>suitable defaultHandler for B lockCannotReturn may be able
to
get
>>>>>>>the debugger to highlight correctly on opening. Try the >>>>>>>following examples: >>>>>>> >>>>>>>[[^1] on: BlockCannotReturn do: #resume] fork. >>>>>>> >>>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex
resume]]
>>>>>>>fork >>>>>>> >>>>>>>[[^1] value] fork. >>>>>>> >>>>>>>They al; seem to behave perfectly acceptably to me. Does
this
>>>>>>>fix work for you? >>>>>>> >>>>>>>On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas
<mail(a)jaromir.net>
>>>>>>>wrote: >>>>>>>>Hi Eliot, >>>>>>>> >>>>>>>>How about to nil the pc just before making the return: >>>>>>>>``` >>>>>>>>Context >> #cannotReturn: result >>>>>>>> >>>>>>>> self push: self pc. "backup the pc for the sake of >>>>>>>>debugging" >>>>>>>> closureOrNil ifNotNil: [^self cannotReturn: result to:
self
>>>>>>>>home sender; pc: nil]. >>>>>>>> Processor debugWithTitle: 'Computation has been
terminated!'
>>>>>>>>translated full: false >>>>>>>>``` >>>>>>>>The nilled pc should not even potentially interfere with
the
>>>>>>>>#isDead now. >>>>>>>> >>>>>>>>I hope this is at least a step in the right direction :) >>>>>>>> >>>>>>>>However, there's still a problem when debugging the
resumption
>>>>>>>>of #cannotReturn because the encoders expect a reasonable
index.
>>>>>>>>I haven't figured out yet where to place a nil check -
#step,
>>>>>>>>#stepToSendOrReturn... ? >>>>>>>> >>>>>>>>Thanks again, >>>>>>>>Jaromir >>>>>>>> >>>>>>>> >>>>>>>>------ Original Message ------ >>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>>Date 11/17/2023 8:36:50 PM >>>>>>>>Subject Re: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>>>>exception >>>>>>>> >>>>>>>>>Hi Jaromir, >>>>>>>>> >>>>>>>>>>On Nov 17, 2023, at 7:05 AM, Jaromir Matas
<mail(a)jaromir.net>
>>>>>>>>>>wrote: >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>Eliot, hi again, >>>>>>>>>> >>>>>>>>>>Please disregard my previous comment about nilling the >>>>>>>>>>contexts that have returned. We are indeed talking
about
the
>>>>>>>>>>context directly under the #cannotReturn context which
is
>>>>>>>>>>totally different from the home context in another
thread
>>>>>>>>>>that's gone. >>>>>>>>>> >>>>>>>>>>I may still be confused but would nilling the pc of the >>>>>>>>>>context directly under the cannotReturn context help?
Here's
>>>>>>>>>>what I mean: >>>>>>>>>>``` >>>>>>>>>>Context >> #cannotReturn: result >>>>>>>>>> >>>>>>>>>> closureOrNil ifNotNil: [^self pc: nil; cannotReturn: >>>>>>>>>>result to: self home sender]. >>>>>>>>>> Processor debugWithTitle: 'Computation has been >>>>>>>>>>terminated!' translated full: false. >>>>>>>>>>``` >>>>>>>>>>Instead of crashing the VM invokes the debugger with
the
>>>>>>>>>>'Computation has been terminated!' message. >>>>>>>>>> >>>>>>>>>>Does this make sense? >>>>>>>>> >>>>>>>>>Nearly. But it loses the information on what the pc
actually
>>>>>>>>>is, and that’s potentially vital information. So IMO the
ox
>>>>>>>>>should only be nilled between the BlockCannotReturn
exception
>>>>>>>>>being created and raised. >>>>>>>>> >>>>>>>>>[But if you try this don’t be surprised if it causes a
few
>>>>>>>>>temporary problems. It looks to me that without a little >>>>>>>>>refactoring this could easily cause an infinite
recursion
>>>>>>>>>around the sending of isDead. I’m sure you’ll be able to
fix
>>>>>>>>>the code to work correctly] >>>>>>>>> >>>>>>>>>>Thanks, >>>>>>>>>>Jaromir >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>------ Original Message ------ >>>>>>>>>>From "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>>>>To "Eliot Miranda" <eliot.miranda(a)gmail.com>; "The >>>>>>>>>>general-purpose Squeak developers list" >>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>Date 11/17/2023 10:15:17 AM >>>>>>>>>>Subject [squeak-dev] Re: Resuming on BlockCannotReturn >>>>>>>>>>exception >>>>>>>>>> >>>>>>>>>>>Hi Eliot, >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>------ Original Message ------ >>>>>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>>>>>Cc "The general-purpose Squeak developers list" >>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>>Date 11/16/2023 11:52:45 PM >>>>>>>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on >>>>>>>>>>>BlockCannotReturn exception >>>>>>>>>>> >>>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>> >>>>>>>>>>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas >>>>>>>>>>>><mail(a)jaromir.net> wrote: >>>>>>>>>>>>>Hi Nicolas, Eliot, >>>>>>>>>>>>> >>>>>>>>>>>>>here's what I understand is happening (see the
enclosed
>>>>>>>>>>>>>screenshot): >>>>>>>>>>>>> >>>>>>>>>>>>>1) we fork a new process to evaluate [^1] >>>>>>>>>>>>>2) the new process evaluates [^1] which means
instruction
>>>>>>>>>>>>>18 is being evaluated, hence pc points to
instruction 19
>>>>>>>>>>>>>now >>>>>>>>>>>>>3) however, the home context where ^1 should return
to
is
>>>>>>>>>>>>>gone by this time (the process that executed the
fork
has
>>>>>>>>>>>>>already returned - notice the two up arrows in the
debugger
>>>>>>>>>>>>>screenshot) >>>>>>>>>>>>>4) the VM can't finish the instruction and returns
control
>>>>>>>>>>>>>to the image via placing the #cannotReturn: context
on
top
>>>>>>>>>>>>>of the [^1] context >>>>>>>>>>>>>5) #cannotReturn: evaluation results in signalling
the
BCR
>>>>>>>>>>>>>exception which is then handled by the #resume
handler
>>>>>>>>>>>>> (in our debugged case the [:ex | self halt. ex
resume]
>>>>>>>>>>>>>handler) >>>>>>>>>>>>>6) ex resume is evaluated, however, this means
requesting
>>>>>>>>>>>>>the VM to evaluate instruction 19 of the [^1]
context -
>>>>>>>>>>>>>which is past the last instruction of the context
and
the
>>>>>>>>>>>>>crash ensues >>>>>>>>>>>>> >>>>>>>>>>>>>I wonder whether such situations could/should be
prevented
>>>>>>>>>>>>>inside the VM or whether such an expectation is
wrong
for
>>>>>>>>>>>>>some reason. >>>>>>>>>>>> >>>>>>>>>>>>As Nicolas says, IMO this is best done at the image
level.
>>>>>>>>>>>> >>>>>>>>>>>>It could be prevented in the VM, but at great cost,
and
only
>>>>>>>>>>>>partially. The performance issue is that the last
bytecode
>>>>>>>>>>>>in a method is not marked in any way, and that to
determine
>>>>>>>>>>>>the last bytecode the bytecodes must be symbolically >>>>>>>>>>>>evaluated from the start of the method. See
implementors
of
>>>>>>>>>>>>endPC at the image level (which defer to the method
trailer)
>>>>>>>>>>>>and implementors of endPCOf: in the VMMaker code.
Doing
this
>>>>>>>>>>>>every time execution commences is prohibitively
expensive.
>>>>>>>>>>>>The "only partially" issue is that following the
return
>>>>>>>>>>>>instruction may be other valid bytecodes, but these
are
not
>>>>>>>>>>>>a continuation. >>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>Consider the following code in some block: >>>>>>>>>>>> [self expression ifTrue: >>>>>>>>>>>> [^1]. >>>>>>>>>>>> ^2 >>>>>>>>>>>> >>>>>>>>>>>>The bytecodes for this are >>>>>>>>>>>> pushReceiver >>>>>>>>>>>> send #expression >>>>>>>>>>>> jumpFalse L1 >>>>>>>>>>>> push 1 >>>>>>>>>>>> methodReturnTop >>>>>>>>>>>>L1 >>>>>>>>>>>> push 2 >>>>>>>>>>>> methodReturnTop >>>>>>>>>>>> >>>>>>>>>>>>Clearly if expression is true these should be *no* >>>>>>>>>>>>continuation in which ^2 is executed. >>>>>>>>>>> >>>>>>>>>>>Well, in that case there's a bug because the
computation
in
>>>>>>>>>>>the following example shouldn't continue past the [^1]
block
>>>>>>>>>>>but it silently does: >>>>>>>>>>>`[[true ifTrue: [^ 1]] on: BlockCannotReturn do:
#resume ]
>>>>>>>>>>>fork` >>>>>>>>>>> >>>>>>>>>>>The bytecodes are >>>>>>>>>>> push true >>>>>>>>>>> jumpFalse L1 >>>>>>>>>>> push 1 >>>>>>>>>>> returnTop >>>>>>>>>>>L1 >>>>>>>>>>> push nil >>>>>>>>>>> blockReturn >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>So even if the VM did try and detect whether the
return
was
>>>>>>>>>>>>at the last block method, it would only work for
special
>>>>>>>>>>>>cases. >>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>It seems to me the issue is simply that the context
that
>>>>>>>>>>>>cannot be returned from should be marked as dead (see >>>>>>>>>>>>Context>>isDead) by setting its pc to nil at some
point,
>>>>>>>>>>>>presumably after copying the actual return pc into
the
>>>>>>>>>>>>BlockCannotReturn exception, to avoid ever trying to
resume
>>>>>>>>>>>>the context. >>>>>>>>>>> >>>>>>>>>>>Does this mean, in other words, that every context
that
>>>>>>>>>>>returns should nil its pc to avoid being "wrongly" >>>>>>>>>>>reused/executed in the future, which concerns
primarily
those
>>>>>>>>>>>being referenced somewhere hence potentially
executable in
>>>>>>>>>>>the future, is that right? >>>>>>>>>>>Hypothetical question: would nilling the pc during
returns
>>>>>>>>>>>"fix" the example? >>>>>>>>>>>Thanks a lot for helping me understand this. >>>>>>>>>>>Best, >>>>>>>>>>>Jaromir >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>> >>>>>>>>>>>>>Thanks, >>>>>>>>>>>>>Jaromir >>>>>>>>>>>>> >>>>>>>>>>>>><bdxuqalu.png> >>>>>>>>>>>>> >>>>>>>>>>>>>------ Original Message ------ >>>>>>>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The
general-purpose
>>>>>>>>>>>>>Squeak developers list" >>>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>>>>Date 11/16/2023 6:48:43 PM >>>>>>>>>>>>>Subject Re: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>>>>>>>>>exception >>>>>>>>>>>>> >>>>>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>>>> >>>>>>>>>>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas >>>>>>>>>>>>>>><mail(a)jaromir.net> wrote: >>>>>>>>>>>>>>> >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>Hi Nicloas, >>>>>>>>>>>>>>>No no, I don't have any practical scenario in
mind,
I'm
>>>>>>>>>>>>>>>just trying to understand why the VM is
implemented
like
>>>>>>>>>>>>>>>this, whether there were a reason to leave this >>>>>>>>>>>>>>>possibility of a crash, e.g. it would slow down
the VM
to
>>>>>>>>>>>>>>>try to prevent such a dumb situation (who would
resume
>>>>>>>>>>>>>>>from BCR in his right mind? :) ) - or perhaps I
have
>>>>>>>>>>>>>>>overlooked some good reason to even keep this
behavior
in
>>>>>>>>>>>>>>>the VM. That's all. >>>>>>>>>>>>>> >>>>>>>>>>>>>>Let’s first understand what’s really happening.
Presumably
>>>>>>>>>>>>>>at tone point a context is resumed those pc is
already
at
>>>>>>>>>>>>>>the block return bytecode (effectively, because it
crashes
>>>>>>>>>>>>>>in JITted code, but I bet the stack vm will crash
also,
>>>>>>>>>>>>>>but not as cleanly - it will try and execute the
bytes
in
>>>>>>>>>>>>>>the encoded method trailer). So which method
actually
>>>>>>>>>>>>>>sends resume, and to what, and what state is
resume’s
>>>>>>>>>>>>>>receiver when resume is sent? >>>>>>>>>>>>>> >>>>>>>>>>>>>> >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>Thanks for your reply. >>>>>>>>>>>>>>>Regards, >>>>>>>>>>>>>>>Jaromir >>>>>>>>>>>>>>> >>>>>>>>>>>>>>> >>>>>>>>>>>>>>> >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>------ Original Message ------ >>>>>>>>>>>>>>>From "Nicolas Cellier" >>>>>>>>>>>>>>><nicolas.cellier.aka.nice(a)gmail.com> >>>>>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The >>>>>>>>>>>>>>>general-purpose Squeak developers list" >>>>>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>>>>>>Date 11/16/2023 7:20:20 AM >>>>>>>>>>>>>>>Subject Re: [squeak-dev] Resuming on
BlockCannotReturn
>>>>>>>>>>>>>>>exception >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>>>>>>Is there a scenario where it would make sense to
resume
>>>>>>>>>>>>>>>>a BlockCannotReturn? >>>>>>>>>>>>>>>>If not, I would suggest to protect at image side
and
>>>>>>>>>>>>>>>>override #resume. >>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas >>>>>>>>>>>>>>>><mail(a)jaromir.net> a écrit : >>>>>>>>>>>>>>>>>Hi Eliot, Christoph, All, >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>It's known the following example crashes the VM.
Is
>>>>>>>>>>>>>>>>>this an intended behavior or a "tolerated bug"? >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>I understand why it crashes: the non-local
return
has
>>>>>>>>>>>>>>>>>nowhere to return to and so resuming the
computation
>>>>>>>>>>>>>>>>>leads to a crash. But why not raise another BCR >>>>>>>>>>>>>>>>>exception to prevent the crash? Potential
infinite
>>>>>>>>>>>>>>>>>loop? Perhaps I'm just missing the purpose of
this
>>>>>>>>>>>>>>>>>behavior... >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>Thanks for an explanation. >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>Best, >>>>>>>>>>>>>>>>>Jaromir >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>-- >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>Jaromir Matas >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>-- >>>>>>>>>>>>_,,,^..^,,,_ >>>>>>>>>>>>best, Eliot >>>>>>>>>><Context-cannotReturn.st> >>>>>>> >>>>>>> >>>>>>>-- >>>>>>>_,,,^..^,,,_ >>>>>>>best, Eliot >>>>>><ProcessTest-testResumeAfterBCR.st>
--- Sent from Squeak Inbox Talk
Hi Christoph,
Yes, that's exactly what I was talking about - the #return:from: fix changes slightly (perhaps it's better to say corrects) the semantics of some stepping methods - #step and #stepToCallee, which allowed illegally stepping into a dead or nil context. They can no longer be used in the manner you showed. Another example was #runUntilErrorOrReturnFrom: - it used #stepToCallee this way so as a workaround I created the #stepToCalleeOrNil method and used in #runUntilErrorOrReturnFrom:
[ctxt isDead or: [topContext isNil]] whileFalse: [topContext := topContext stepToCalleeOrNil].
Theoretically there might be some external code (mis)using the incorrect stepping semantics. In Pharo's trunk they were mainly tests and #stepToHome but I haven't checked any external code. But all their tests are green with this change and I guess it's not widespread.
This is also why I checked Jakob's Git Browser and all tests seem fine.
My opinion is to keep the correct simulation semantics and deal with potential consequences as/if they come. However I don't expect a huge impact as the change only affects border situations.
In general, some methods are "pure simulation" methods intended to mimic the VM behavior (#step etc) but nothing prevents one from using them for other purposes - like what #runUntilErrorOrReturnFrom: did: to just get rid of some contexts). Is it ok to do that? I tend to think it's not; it's confusing. That's why I made #stepToCalleeOrNil a private method because it's not a "true" simulation method but a sort of hybrid.
What do you think?
Thanks for reviewing the fix! Best, Jaromir
On 30-Dec-23 11:07:54 PM, christoph.thiede@student.hpi.uni-potsdam.de wrote:
Hi Jaromir,
I found a breaking change in the new behavior of Context>>#return:from: while using the TraceDebugger:
In the past we could say:
c:=[2+3]asContext. [c]whileNotNil:[c:=cstep].
With your change, the script runs forever because the last step does not answer nil as before but activates a new #cannotReturn:.
This behavior seems not be expected anywhere in the trunk (if my first search was complete), and you are right that the new behavior aligns closer to the VM behavior. Still, the old code seemed to explicitly intend this - see the "newTop ifNotNil:" at the bottom of the method.
I wonder whether we should keep this. For me it is not a big deal; I can just change my script like this:
c:=[2+3]asContext. [csenderisNiland:[cwillReturn]]whileNotNil:[c:=cstep].
I just wonder whether this could a breaking or unintended change for anything else. For [^2] ensure: [] it would not be a big deal, we could just change the check in question to (aSenderisDeador:[newTopnotNiland:[newTopisDead]])ifTrue:. I am tending against restoring the old behavior, but I am unsure. What is your opinion on this?
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-12-30T21:13:37+00:00, mail@jaromir.net wrote:
nit: You mixed up the order of arguments for #assert:equals:
oops, sorry :) It happens to me all the time; I've never actually understood why the strange, almost Yodaesque, order... as if you
asked
in English:
"Make sure 18 is his age."
Thanks, Jaromir
On 30-Dec-23 9:13:56 PM,
christoph.thiede(a)student.hpi.uni-potsdam.de
wrote:
nit: You mixed up the order of arguments for #assert:equals: (it is assert: expected equals: actual) and could have used it in the final assert again, but that's clearly no reason to hold back a useful
test.
;-) Merged, thanks! :-)
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-12-30T17:33:08+00:00, mail(a)jaromir.net wrote:
Hi Christoph,
Thanks for merging the fixes; I've just sent another test in KernelTests-jar.448 to complement them.
Please take a look and if ok I'd appreciate it if you could merge
it
as
well.
Best regards and Happy New Year to you too! Jaromir
On 30-Dec-23 6:15:25 PM,
christoph.thiede(a)student.hpi.uni-potsdam.de
wrote:
Hi Jaromir, hi all,
finally I have found the time to review these suggestions. Kernel-jar.1537, Kernel-jar.1538, and Kernel-jar.1539 look
excellent
to
me as well. Clear, straightforward, useful. :-) I have merged
them
into
the trunk via Kernel-ct.1545.
Regarding DebuggerTests>>test16HandleSimulationError, I have
patched
it
via ToolsTests-ct.125. Nothing to rack your brains over:
"thisContext
pc: nil" just mimicks any kind of unhandled error inside the
simulator
- since we now gently handle this via #cannotReturn:, I just
replaced
it with "thisContext pc: false". :-) Sorry for not clarifying
that
earlier and letting you speculate.
Thanks for your work, and I already wish you a happy new year!
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-11-29T13:31:09+00:00, mail(a)jaromir.net wrote:
Hi Marcel,
> [myself] whether the patch would have been necessary should
the
#return:from: had been fixed then
Nonsense, I just mixed it up with another issue :)
On 29-Nov-23 1:51:21 PM, "Jaromir Matas" <mail(a)jaromir.net>
wrote:
>Thanks Marcel! This test somehow slipped my attention :) > >The test can no longer work as is. It takes advantage of the
erroneous
>behavior of #return:from: in the sense that if you simulate > > thisContext pc: nil > >it'll happily return to a dead context (i.e. to thisContext
from
#pc:
>nil context) - which is not what the VM does during runtime.
It
should
>immediately raise an illegal return exception not only
during
runtime
>but also during simulation. > >The test mentions a patch for an infinite debugger chain >(http://forum.world.st/I-broke-the-debugger-td5110752.html).
I
wonder
>whether the problem could have something to do with this
simulation
bug
>in return:from:; and a terrible idea occurred to me whether
the
patch
>would have been necessary should the #return:from: had been
fixed
then
>;O > >We may potentially come up with more examples like this,
even in
the
>trunk, where the bug from #return:from: propagated and was
taken
>advantage of. I've found and fixed
#runUntilErrorOrReturnFrom:
but
more
>can still be surviving undetected... > >I'd place the test into #expectedFailures for now but maybe
it's
time
>to remove it; Christoph should decide :) > >Thanks again, >Jaromir > > >On 29-Nov-23 10:28:38 AM, "Taeumel, Marcel via Squeak-dev" ><squeak-dev(a)lists.squeakfoundation.org> wrote: > >>Hi Jaromir -- >> >>Looks good. Still, what about that
#test16HandleSimulationError
now?
>>:-) It is failing with your changes ... how would you adapt
it?
>> >> >> >>Best, >>Marcel >>>Am 28.11.2023 01:29:39 schrieb Jaromir Matas
<mail(a)jaromir.net>:
>>> >>>Hi Eliot, Marcel, all, >>> >>>I've sent a fix Kernel-jar.1539 to the Inbox that solves
the
>>>remaining bit of the chain of bugs described in the
previous
post.
>>>All tests are green now and I think the root cause has
been
found
and
>>>fixed. >>> >>>In this last bit I've created a version of stepToCallee
that
would
>>>identify a potential illegal return to a nil sender and
avoid
it.
>>> >>>Now this example can be debugged without any problems: >>> >>>[[self halt. ^ 1] on: BlockCannotReturn do: #resume ] fork >>> >>>If you're happy with the solution in Kernel-jar.1539, >>>Kernel-jar.1538, Kernel-jar.1537 and the test in
KernelTests-jar.447,
>>>could you please double-check and merge, please? (And
remove
>>>Kernel-mt.1534 and Tools-jar.1240 from the Inbox) >>> >>>Best, >>>Jaromir >>> >>> >>> >>>On 27-Nov-23 12:09:37 AM, "Jaromir Matas"
<mail(a)jaromir.net>
wrote:
>>> >>>>Hi Eliot, Christoph, all >>>> >>>>It looks like there are some more skeletons in the closet
:/
>>>> >>>>If you run this example >>>> >>>>[[self halt. ^ 1] on: BlockCannotReturn do: [:ex | ex
resume]
]
fork
>>>> >>>>and step over halt and then step over ^1 you get a
nonsensical
error
>>>>as a result of decoding nil as an instruction. >>>> >>>>It turns out that the root cause is in the #return:from:
method:
it
>>>>only checks whether aSender is dead but ignores the
possibility
that
>>>>aSender sender may be nil or dead in which cases the VM
also
>>>>responds with sending #cannotReturn, hence I assume the
simulator
>>>>should do the same. In addition, the VM nills the pc in
such
>>>>scenario, so I added the same functionality here too: >>>> >>>>Context >> return: value from: aSender >>>> "For simulation. Roll back self to aSender and return
value
>>>>from it. Execute any unwind blocks on the way. ASSUMES
aSender is
>>>>a sender of self" >>>> >>>> | newTop | >>>> newTop := aSender sender. >>>> (aSender isDead or: [newTop isNil or: [newTop isDead]])
ifTrue:
>>>> "<--------- this is extended ------" >>>> [^self pc: nil; send: #cannotReturn: to: self with: >>>>{value}]. "<------ pc: nil is added ----" >>>> (self findNextUnwindContextUpTo: newTop) ifNotNil: >>>> "Send #aboutToReturn:through: with nil as the second >>>>argument to avoid this bug: >>>> Cannot #stepOver '^2' in example '[^2] ensure: []'. >>>> See
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html"
>>>> [^self send: #aboutToReturn:through: to: self with:
{value.
>>>>nil}]. >>>> self releaseTo: newTop. >>>> newTop ifNotNil: [newTop push: value]. >>>> ^newTop >>>> >>>>In order for this to work #cannotReturn: has to be
modified
as in
>>>>Kernel-jar.1537: >>>> >>>>Context >> cannotReturn: result >>>> >>>> closureOrNil ifNotNil: [^ self cannotReturn: result to:
self
>>>>home sender]. >>>> self error: 'Computation has been terminated!' >>>>"<----------- this has to be an Error -----" >>>> >>>>Then it almost works except when you keep stepping over
in
the
>>>>example above, you get an MNU error on `self previousPc`
in
>>>>#cannotReturn:to:` with your solution of the VM crash. If
you
don't
>>>>mind I've amended your solution and added the final
context
where
>>>>the computation couldn't return along with the pc: >>>> >>>>Context >> cannotReturn: result to: homeContext >>>> "The receiver tried to return result to homeContext that
cannot
>>>>be returned from. >>>> Capture the return context/pc in a BlockCannotReturn.
Nil
the pc
>>>>to prevent repeat >>>> attempts and/or invalid continuation. Answer the result
of
>>>>raising the exception." >>>> >>>> | exception previousPc | >>>> exception := BlockCannotReturn new. >>>> previousPc := pc ifNotNil: [self previousPc]. "<-----
here's
a
>>>>fix ----" >>>> exception >>>> result: result; >>>> deadHome: homeContext; >>>> finalContext: self; "<----- here's the new state, if >>>>that's fine ----" >>>> pc: previousPc. >>>> pc := nil. >>>> ^exception signal >>>> >>>>Unfortunately, this is still not the end of the story:
there
are
>>>>situations where #runUntilErrorOrReturnFrom: places the
two
guard
>>>>contexts below the bottom context. And that is a problem
because
>>>>when the method tries to remove the two guard contexts
before
>>>>returning at the end it uses #stepToCalee to do the job
but
this
>>>>unforotunately was (ab)using the above bug in
#return:from: -
I'll
>>>>explain: #return:from: didn't check whether aSender
sender
was
nil
>>>>and as a result it allowed to simulate a return to a "nil
context"
>>>>which was then (ab)used in the clean-up via #stepToCalee
in
the
>>>>#runUntilErrorOrReturnFrom:. >>>> >>>>When I fixed the #return:from: bug, the
#runUntilErrorOrReturnFrom:
>>>>cleanup of the guard contexts no longer works in that
very
special
>>>>case where the guard contexts are below the bottom
context.
There's
>>>>one case where this is being used: #terminateAggresively
by
>>>>Christoph. >>>> >>>>If I'm right with this analysis, the
#runUntilErrorOrReturnFrom:
>>>>should get fixed too but I'll be away now for a few days
and
I
won't
>>>>be able to respond. If you or Christoph had a chance to
take
a
look
>>>>at Kernel-jar.1538 and Kernel-jar.1537 I'd be very
grateful.
I
hope
>>>>this super long message at least makes some sense :) >>>>Best, >>>>Jaromir >>>> >>>>[1] Kernel-jar.1538, Kernel-jar.1537 >>>>[2] KernelTests-jar.447 >>>> >>>> >>>>PS: Christoph, >>>> >>>>With Kernel-jar.1538 + Kernel-jar.1537 your example >>>> >>>>process := >>>> [(c := thisContext) pc: nil. >>>> 2+3] newProcess. >>>>process runUntil: [:ctx | ctx selector = #cannotReturn:]. >>>>self assert: process suspendedContext sender sender = c. >>>>self assert: process suspendedContext arguments = {c}. >>>> >>>>works fine, I've just corrected your first assert. >>>> >>>> >>>> >>>> >>>> >>>>On 21-Nov-23 6:40:32 PM, "Eliot Miranda"
<eliot.miranda(a)gmail.com>
>>>>wrote: >>>> >>>>>Hi Jaromir, >>>>> >>>>>>On Nov 20, 2023, at 11:51 PM, Jaromir Matas
<mail(a)jaromir.net>
>>>>>>wrote: >>>>>> >>>>>> >>>>>>Hi Eliot, >>>>>>Very elegant! Now I finally got what you meant exactly
:)
Thanks.
>>>>>> >>>>>>Two questions: >>>>>>1. in order for the enclosed test to work I'd need an
Error
>>>>>>instead of Processor debugWithTitle:full: call in
#cannotReturn:.
>>>>>>Otherwise I don't know how to catch a plain invocation
of
the
>>>>>>Debugger: >>>>>> >>>>>>cannotReturn: result >>>>>> >>>>>> closureOrNil ifNotNil: [^ self cannotReturn: result
to:
self
>>>>>>home sender]. >>>>>> self error: 'Computation has been terminated!' >>>>> >>>>>Much nicer. >>>>> >>>>>>2. We are capturing a pc of self which is completely
different
>>>>>>context from homeContext indeed. >>>>> >>>>>Right. The return is attempted from a specific return
bytecode
in a
>>>>>specific block. This is the coordinate of the return
that
cannot
be
>>>>>made. This is the relevant point of origin of the cannot
return
>>>>>exception. >>>>> >>>>>Why the return fails is another matter: >>>>>- the home context’s sender is a dead context (cannot be
resumed)
>>>>>- the home context’s sender is nil (home already
returned
from)
>>>>>- the block activation’s home is nil rather than a
context
(should
>>>>>not happen) >>>>> >>>>>But in all these cases the pc of the home context is
immaterial.
>>>>>The hike is being returned through/from, rather than
from;
the
>>>>>home’s pc is not relevant. >>>>> >>>>>>Maybe we could capture self in the exception too to
make it
more
>>>>>>clear/explicit what is going on: what context the
captured
pc
is
>>>>>>actually associated with. Just a thought... >>>>> >>>>>Yes, I like that. I also like the idea of somehow
passing
the
>>>>>block activation’s pc to the debugger so that the
relevant
return
>>>>>expression is highlighted in the debugger. >>>>> >>>>>> >>>>>>Thanks again, >>>>>>Jaromir >>>>> >>>>>You’re welcome. I love working in this part of the
system.
Thanks
>>>>>for dragging me there. I’m in a slump right now and
appreciate
the
>>>>>fellowship. >>>>> >>>>>>------ Original Message ------ >>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>>Cc squeak-dev(a)lists.squeakfoundation.org >>>>>>Date 11/21/2023 2:17:21 AM >>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>>exception >>>>>> >>>>>>>Hi Jaromir, >>>>>>> >>>>>>> see Kernel-eem.1535 for what I was suggesting. This
example
>>>>>>>now has an exception with the right pc value in it: >>>>>>> >>>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect.
ex
resume]]
>>>>>>>fork >>>>>>> >>>>>>>The fix is simply >>>>>>> >>>>>>>Context>>cannotReturn: result to: homeContext >>>>>>> "The receiver tried to return result to homeContext
that
>>>>>>>cannot be returned from. >>>>>>> Capture the return pc in a BlockCannotReturn. Nil the
pc
to
>>>>>>>prevent repeat >>>>>>> attempts and/or invalid continuation. Answer the
result
of
>>>>>>>raising the exception." >>>>>>> >>>>>>> | exception | >>>>>>> exception := BlockCannotReturn new. >>>>>>> exception >>>>>>> result: result; >>>>>>> deadHome: homeContext; >>>>>>> pc: self previousPc. >>>>>>> pc := nil. >>>>>>> ^exception signal >>>>>>> >>>>>>> >>>>>>>The VM crash is now avoided. The debugger displays the
method,
>>>>>>>but does not highlight the offending pc, which is no
big
deal.
A
>>>>>>>suitable defaultHandler for B lockCannotReturn may be
able
to
get
>>>>>>>the debugger to highlight correctly on opening. Try
the
>>>>>>>following examples: >>>>>>> >>>>>>>[[^1] on: BlockCannotReturn do: #resume] fork. >>>>>>> >>>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect.
ex
resume]]
>>>>>>>fork >>>>>>> >>>>>>>[[^1] value] fork. >>>>>>> >>>>>>>They al; seem to behave perfectly acceptably to me.
Does
this
>>>>>>>fix work for you? >>>>>>> >>>>>>>On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas
<mail(a)jaromir.net>
>>>>>>>wrote: >>>>>>>>Hi Eliot, >>>>>>>> >>>>>>>>How about to nil the pc just before making the
return:
>>>>>>>>``` >>>>>>>>Context >> #cannotReturn: result >>>>>>>> >>>>>>>> self push: self pc. "backup the pc for the sake of >>>>>>>>debugging" >>>>>>>> closureOrNil ifNotNil: [^self cannotReturn: result
to:
self
>>>>>>>>home sender; pc: nil]. >>>>>>>> Processor debugWithTitle: 'Computation has been
terminated!'
>>>>>>>>translated full: false >>>>>>>>``` >>>>>>>>The nilled pc should not even potentially interfere
with
the
>>>>>>>>#isDead now. >>>>>>>> >>>>>>>>I hope this is at least a step in the right direction
:)
>>>>>>>> >>>>>>>>However, there's still a problem when debugging the
resumption
>>>>>>>>of #cannotReturn because the encoders expect a
reasonable
index.
>>>>>>>>I haven't figured out yet where to place a nil check
#step,
>>>>>>>>#stepToSendOrReturn... ? >>>>>>>> >>>>>>>>Thanks again, >>>>>>>>Jaromir >>>>>>>> >>>>>>>> >>>>>>>>------ Original Message ------ >>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>>Date 11/17/2023 8:36:50 PM >>>>>>>>Subject Re: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>>>>exception >>>>>>>> >>>>>>>>>Hi Jaromir, >>>>>>>>> >>>>>>>>>>On Nov 17, 2023, at 7:05 AM, Jaromir Matas
<mail(a)jaromir.net>
>>>>>>>>>>wrote: >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>Eliot, hi again, >>>>>>>>>> >>>>>>>>>>Please disregard my previous comment about nilling
the
>>>>>>>>>>contexts that have returned. We are indeed talking
about
the
>>>>>>>>>>context directly under the #cannotReturn context
which
is
>>>>>>>>>>totally different from the home context in another
thread
>>>>>>>>>>that's gone. >>>>>>>>>> >>>>>>>>>>I may still be confused but would nilling the pc of
the
>>>>>>>>>>context directly under the cannotReturn context
help?
Here's
>>>>>>>>>>what I mean: >>>>>>>>>>``` >>>>>>>>>>Context >> #cannotReturn: result >>>>>>>>>> >>>>>>>>>> closureOrNil ifNotNil: [^self pc: nil;
cannotReturn:
>>>>>>>>>>result to: self home sender]. >>>>>>>>>> Processor debugWithTitle: 'Computation has been >>>>>>>>>>terminated!' translated full: false. >>>>>>>>>>``` >>>>>>>>>>Instead of crashing the VM invokes the debugger
with
the
>>>>>>>>>>'Computation has been terminated!' message. >>>>>>>>>> >>>>>>>>>>Does this make sense? >>>>>>>>> >>>>>>>>>Nearly. But it loses the information on what the pc
actually
>>>>>>>>>is, and that’s potentially vital information. So IMO
the
ox
>>>>>>>>>should only be nilled between the BlockCannotReturn
exception
>>>>>>>>>being created and raised. >>>>>>>>> >>>>>>>>>[But if you try this don’t be surprised if it causes
a
few
>>>>>>>>>temporary problems. It looks to me that without a
little
>>>>>>>>>refactoring this could easily cause an infinite
recursion
>>>>>>>>>around the sending of isDead. I’m sure you’ll be
able to
fix
>>>>>>>>>the code to work correctly] >>>>>>>>> >>>>>>>>>>Thanks, >>>>>>>>>>Jaromir >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>------ Original Message ------ >>>>>>>>>>From "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>>>>To "Eliot Miranda" <eliot.miranda(a)gmail.com>;
"The
>>>>>>>>>>general-purpose Squeak developers list" >>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>Date 11/17/2023 10:15:17 AM >>>>>>>>>>Subject [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>>>>>>exception >>>>>>>>>> >>>>>>>>>>>Hi Eliot, >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>------ Original Message ------ >>>>>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>>>>>Cc "The general-purpose Squeak developers list" >>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>>Date 11/16/2023 11:52:45 PM >>>>>>>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on >>>>>>>>>>>BlockCannotReturn exception >>>>>>>>>>> >>>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>> >>>>>>>>>>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas >>>>>>>>>>>><mail(a)jaromir.net> wrote: >>>>>>>>>>>>>Hi Nicolas, Eliot, >>>>>>>>>>>>> >>>>>>>>>>>>>here's what I understand is happening (see the
enclosed
>>>>>>>>>>>>>screenshot): >>>>>>>>>>>>> >>>>>>>>>>>>>1) we fork a new process to evaluate [^1] >>>>>>>>>>>>>2) the new process evaluates [^1] which means
instruction
>>>>>>>>>>>>>18 is being evaluated, hence pc points to
instruction 19
>>>>>>>>>>>>>now >>>>>>>>>>>>>3) however, the home context where ^1 should
return
to
is
>>>>>>>>>>>>>gone by this time (the process that executed the
fork
has
>>>>>>>>>>>>>already returned - notice the two up arrows in
the
debugger
>>>>>>>>>>>>>screenshot) >>>>>>>>>>>>>4) the VM can't finish the instruction and
returns
control
>>>>>>>>>>>>>to the image via placing the #cannotReturn:
context
on
top
>>>>>>>>>>>>>of the [^1] context >>>>>>>>>>>>>5) #cannotReturn: evaluation results in
signalling
the
BCR
>>>>>>>>>>>>>exception which is then handled by the #resume
handler
>>>>>>>>>>>>> (in our debugged case the [:ex | self halt. ex
resume]
>>>>>>>>>>>>>handler) >>>>>>>>>>>>>6) ex resume is evaluated, however, this means
requesting
>>>>>>>>>>>>>the VM to evaluate instruction 19 of the [^1]
context -
>>>>>>>>>>>>>which is past the last instruction of the
context
and
the
>>>>>>>>>>>>>crash ensues >>>>>>>>>>>>> >>>>>>>>>>>>>I wonder whether such situations could/should be
prevented
>>>>>>>>>>>>>inside the VM or whether such an expectation is
wrong
for
>>>>>>>>>>>>>some reason. >>>>>>>>>>>> >>>>>>>>>>>>As Nicolas says, IMO this is best done at the
image
level.
>>>>>>>>>>>> >>>>>>>>>>>>It could be prevented in the VM, but at great
cost,
and
only
>>>>>>>>>>>>partially. The performance issue is that the last
bytecode
>>>>>>>>>>>>in a method is not marked in any way, and that to
determine
>>>>>>>>>>>>the last bytecode the bytecodes must be
symbolically
>>>>>>>>>>>>evaluated from the start of the method. See
implementors
of
>>>>>>>>>>>>endPC at the image level (which defer to the
method
trailer)
>>>>>>>>>>>>and implementors of endPCOf: in the VMMaker code.
Doing
this
>>>>>>>>>>>>every time execution commences is prohibitively
expensive.
>>>>>>>>>>>>The "only partially" issue is that following the
return
>>>>>>>>>>>>instruction may be other valid bytecodes, but
these
are
not
>>>>>>>>>>>>a continuation. >>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>Consider the following code in some block: >>>>>>>>>>>> [self expression ifTrue: >>>>>>>>>>>> [^1]. >>>>>>>>>>>> ^2 >>>>>>>>>>>> >>>>>>>>>>>>The bytecodes for this are >>>>>>>>>>>> pushReceiver >>>>>>>>>>>> send #expression >>>>>>>>>>>> jumpFalse L1 >>>>>>>>>>>> push 1 >>>>>>>>>>>> methodReturnTop >>>>>>>>>>>>L1 >>>>>>>>>>>> push 2 >>>>>>>>>>>> methodReturnTop >>>>>>>>>>>> >>>>>>>>>>>>Clearly if expression is true these should be
*no*
>>>>>>>>>>>>continuation in which ^2 is executed. >>>>>>>>>>> >>>>>>>>>>>Well, in that case there's a bug because the
computation
in
>>>>>>>>>>>the following example shouldn't continue past the
[^1]
block
>>>>>>>>>>>but it silently does: >>>>>>>>>>>`[[true ifTrue: [^ 1]] on: BlockCannotReturn do:
#resume ]
>>>>>>>>>>>fork` >>>>>>>>>>> >>>>>>>>>>>The bytecodes are >>>>>>>>>>> push true >>>>>>>>>>> jumpFalse L1 >>>>>>>>>>> push 1 >>>>>>>>>>> returnTop >>>>>>>>>>>L1 >>>>>>>>>>> push nil >>>>>>>>>>> blockReturn >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>So even if the VM did try and detect whether the
return
was
>>>>>>>>>>>>at the last block method, it would only work for
special
>>>>>>>>>>>>cases. >>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>It seems to me the issue is simply that the
context
that
>>>>>>>>>>>>cannot be returned from should be marked as dead
(see
>>>>>>>>>>>>Context>>isDead) by setting its pc to nil at some
point,
>>>>>>>>>>>>presumably after copying the actual return pc
into
the
>>>>>>>>>>>>BlockCannotReturn exception, to avoid ever trying
to
resume
>>>>>>>>>>>>the context. >>>>>>>>>>> >>>>>>>>>>>Does this mean, in other words, that every context
that
>>>>>>>>>>>returns should nil its pc to avoid being "wrongly" >>>>>>>>>>>reused/executed in the future, which concerns
primarily
those
>>>>>>>>>>>being referenced somewhere hence potentially
executable in
>>>>>>>>>>>the future, is that right? >>>>>>>>>>>Hypothetical question: would nilling the pc during
returns
>>>>>>>>>>>"fix" the example? >>>>>>>>>>>Thanks a lot for helping me understand this. >>>>>>>>>>>Best, >>>>>>>>>>>Jaromir >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>> >>>>>>>>>>>>>Thanks, >>>>>>>>>>>>>Jaromir >>>>>>>>>>>>> >>>>>>>>>>>>><bdxuqalu.png> >>>>>>>>>>>>> >>>>>>>>>>>>>------ Original Message ------ >>>>>>>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The
general-purpose
>>>>>>>>>>>>>Squeak developers list" >>>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>>>>Date 11/16/2023 6:48:43 PM >>>>>>>>>>>>>Subject Re: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>>>>>>>>>exception >>>>>>>>>>>>> >>>>>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>>>> >>>>>>>>>>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas >>>>>>>>>>>>>>><mail(a)jaromir.net> wrote: >>>>>>>>>>>>>>> >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>Hi Nicloas, >>>>>>>>>>>>>>>No no, I don't have any practical scenario in
mind,
I'm
>>>>>>>>>>>>>>>just trying to understand why the VM is
implemented
like
>>>>>>>>>>>>>>>this, whether there were a reason to leave
this
>>>>>>>>>>>>>>>possibility of a crash, e.g. it would slow
down
the VM
to
>>>>>>>>>>>>>>>try to prevent such a dumb situation (who
would
resume
>>>>>>>>>>>>>>>from BCR in his right mind? :) ) - or perhaps
I
have
>>>>>>>>>>>>>>>overlooked some good reason to even keep this
behavior
in
>>>>>>>>>>>>>>>the VM. That's all. >>>>>>>>>>>>>> >>>>>>>>>>>>>>Let’s first understand what’s really happening.
Presumably
>>>>>>>>>>>>>>at tone point a context is resumed those pc is
already
at
>>>>>>>>>>>>>>the block return bytecode (effectively, because
it
crashes
>>>>>>>>>>>>>>in JITted code, but I bet the stack vm will
crash
also,
>>>>>>>>>>>>>>but not as cleanly - it will try and execute
the
bytes
in
>>>>>>>>>>>>>>the encoded method trailer). So which method
actually
>>>>>>>>>>>>>>sends resume, and to what, and what state is
resume’s
>>>>>>>>>>>>>>receiver when resume is sent? >>>>>>>>>>>>>> >>>>>>>>>>>>>> >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>Thanks for your reply. >>>>>>>>>>>>>>>Regards, >>>>>>>>>>>>>>>Jaromir >>>>>>>>>>>>>>> >>>>>>>>>>>>>>> >>>>>>>>>>>>>>> >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>------ Original Message ------ >>>>>>>>>>>>>>>From "Nicolas Cellier" >>>>>>>>>>>>>>><nicolas.cellier.aka.nice(a)gmail.com> >>>>>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The >>>>>>>>>>>>>>>general-purpose Squeak developers list" >>>>>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>>>>>>Date 11/16/2023 7:20:20 AM >>>>>>>>>>>>>>>Subject Re: [squeak-dev] Resuming on
BlockCannotReturn
>>>>>>>>>>>>>>>exception >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>>>>>>Is there a scenario where it would make sense
to
resume
>>>>>>>>>>>>>>>>a BlockCannotReturn? >>>>>>>>>>>>>>>>If not, I would suggest to protect at image
side
and
>>>>>>>>>>>>>>>>override #resume. >>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas >>>>>>>>>>>>>>>><mail(a)jaromir.net> a écrit : >>>>>>>>>>>>>>>>>Hi Eliot, Christoph, All, >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>It's known the following example crashes the
VM.
Is
>>>>>>>>>>>>>>>>>this an intended behavior or a "tolerated
bug"?
>>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume]
fork`
>>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>I understand why it crashes: the non-local
return
has
>>>>>>>>>>>>>>>>>nowhere to return to and so resuming the
computation
>>>>>>>>>>>>>>>>>leads to a crash. But why not raise another
BCR
>>>>>>>>>>>>>>>>>exception to prevent the crash? Potential
infinite
>>>>>>>>>>>>>>>>>loop? Perhaps I'm just missing the purpose
of
this
>>>>>>>>>>>>>>>>>behavior... >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>Thanks for an explanation. >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>Best, >>>>>>>>>>>>>>>>>Jaromir >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>-- >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>Jaromir Matas >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>-- >>>>>>>>>>>>_,,,^..^,,,_ >>>>>>>>>>>>best, Eliot >>>>>>>>>><Context-cannotReturn.st> >>>>>>> >>>>>>> >>>>>>>-- >>>>>>>_,,,^..^,,,_ >>>>>>>best, Eliot >>>>>><ProcessTest-testResumeAfterBCR.st>
Hi Christoph,
correct me if I'm wrong: with the corrected #step semantics (the #return:from: fix) one should no longer need to do things like:
self step ifNil: [^ self]
because #step should always return a context, even if attempting to step to a nil context:
[] asContext step
In this case it correctly returns the #cannotReturn: context.
I've noticed these nil checks in Trace debugger's #doStepOver or #stepToHome.
I hope I haven't overlooked anything :)
Thanks for your thoughts, Jaromir
On 31-Dec-23 10:42:54 AM, "Jaromir Matas" mail@jaromir.net wrote:
Hi Christoph,
Yes, that's exactly what I was talking about - the #return:from: fix changes slightly (perhaps it's better to say corrects) the semantics of some stepping methods - #step and #stepToCallee, which allowed illegally stepping into a dead or nil context. They can no longer be used in the manner you showed. Another example was #runUntilErrorOrReturnFrom: - it used #stepToCallee this way so as a workaround I created the #stepToCalleeOrNil method and used in #runUntilErrorOrReturnFrom:
[ctxt isDead or: [topContext isNil]] whileFalse: [topContext :=topContext stepToCalleeOrNil].
Theoretically there might be some external code (mis)using the incorrect stepping semantics. In Pharo's trunk they were mainly tests and #stepToHome but I haven't checked any external code. But all their tests are green with this change and I guess it's not widespread.
This is also why I checked Jakob's Git Browser and all tests seem fine.
My opinion is to keep the correct simulation semantics and deal with potential consequences as/if they come. However I don't expect a huge impact as the change only affects border situations.
In general, some methods are "pure simulation" methods intended to mimic the VM behavior (#step etc) but nothing prevents one from using them for other purposes - like what #runUntilErrorOrReturnFrom: did: to just get rid of some contexts). Is it ok to do that? I tend to think it's not; it's confusing. That's why I made #stepToCalleeOrNil a private method because it's not a "true" simulation method but a sort of hybrid.
What do you think?
Thanks for reviewing the fix! Best, Jaromir
On 30-Dec-23 11:07:54 PM, christoph.thiede@student.hpi.uni-potsdam.de wrote:
Hi Jaromir,
I found a breaking change in the new behavior of Context>>#return:from: while using the TraceDebugger:
In the past we could say:
c:=[2+3]asContext. [c]whileNotNil:[c:=cstep].
With your change, the script runs forever because the last step does not answer nil as before but activates a new #cannotReturn:.
This behavior seems not be expected anywhere in the trunk (if my first search was complete), and you are right that the new behavior aligns closer to the VM behavior. Still, the old code seemed to explicitly intend this - see the "newTop ifNotNil:" at the bottom of the method.
I wonder whether we should keep this. For me it is not a big deal; I can just change my script like this:
c:=[2+3]asContext. [csenderisNiland:[cwillReturn]]whileNotNil:[c:=cstep].
I just wonder whether this could a breaking or unintended change for anything else. For [^2] ensure: [] it would not be a big deal, we could just change the check in question to (aSenderisDeador:[newTopnotNiland:[newTopisDead]])ifTrue:. I am tending against restoring the old behavior, but I am unsure. What is your opinion on this?
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-12-30T21:13:37+00:00, mail@jaromir.net wrote:
nit: You mixed up the order of arguments for #assert:equals:
oops, sorry :) It happens to me all the time; I've never actually understood why the strange, almost Yodaesque, order... as if you
asked
in English:
"Make sure 18 is his age."
Thanks, Jaromir
On 30-Dec-23 9:13:56 PM,
christoph.thiede(a)student.hpi.uni-potsdam.de
wrote:
nit: You mixed up the order of arguments for #assert:equals: (it is assert: expected equals: actual) and could have used it in the
final
assert again, but that's clearly no reason to hold back a useful
test.
;-) Merged, thanks! :-)
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-12-30T17:33:08+00:00, mail(a)jaromir.net wrote:
Hi Christoph,
Thanks for merging the fixes; I've just sent another test in KernelTests-jar.448 to complement them.
Please take a look and if ok I'd appreciate it if you could
merge it
as
well.
Best regards and Happy New Year to you too! Jaromir
On 30-Dec-23 6:15:25 PM,
christoph.thiede(a)student.hpi.uni-potsdam.de
wrote:
Hi Jaromir, hi all,
finally I have found the time to review these suggestions. Kernel-jar.1537, Kernel-jar.1538, and Kernel-jar.1539 look
excellent
to
me as well. Clear, straightforward, useful. :-) I have merged
them
into
the trunk via Kernel-ct.1545.
Regarding DebuggerTests>>test16HandleSimulationError, I have
patched
it
via ToolsTests-ct.125. Nothing to rack your brains over:
"thisContext
pc: nil" just mimicks any kind of unhandled error inside the
simulator
- since we now gently handle this via #cannotReturn:, I just
replaced
it with "thisContext pc: false". :-) Sorry for not clarifying
that
earlier and letting you speculate.
Thanks for your work, and I already wish you a happy new year!
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-11-29T13:31:09+00:00, mail(a)jaromir.net wrote:
> Hi Marcel, > > > [myself] whether the patch would have been necessary
should the
> #return:from: had been fixed then > > Nonsense, I just mixed it up with another issue :) > > > On 29-Nov-23 1:51:21 PM, "Jaromir Matas"
<mail(a)jaromir.net>
wrote:
> > >Thanks Marcel! This test somehow slipped my attention :) > > > >The test can no longer work as is. It takes advantage of
the
erroneous > >behavior of #return:from: in the sense that if you simulate > > > > thisContext pc: nil > > > >it'll happily return to a dead context (i.e. to thisContext
from
#pc: > >nil context) - which is not what the VM does during
runtime. It
should > >immediately raise an illegal return exception not only
during
runtime > >but also during simulation. > > > >The test mentions a patch for an infinite debugger chain >
(http://forum.world.st/I-broke-the-debugger-td5110752.html). I
wonder > >whether the problem could have something to do with this
simulation
bug > >in return:from:; and a terrible idea occurred to me whether
the
patch > >would have been necessary should the #return:from: had been
fixed
then > >;O > > > >We may potentially come up with more examples like this,
even in
the
> >trunk, where the bug from #return:from: propagated and was
taken
> >advantage of. I've found and fixed
#runUntilErrorOrReturnFrom:
but
more > >can still be surviving undetected... > > > >I'd place the test into #expectedFailures for now but maybe
it's
time > >to remove it; Christoph should decide :) > > > >Thanks again, > >Jaromir > > > > > >On 29-Nov-23 10:28:38 AM, "Taeumel, Marcel via Squeak-dev" > ><squeak-dev(a)lists.squeakfoundation.org> wrote: > > > >>Hi Jaromir -- > >> > >>Looks good. Still, what about that
#test16HandleSimulationError
now? > >>:-) It is failing with your changes ... how would you
adapt it?
> >> > >> > >> > >>Best, > >>Marcel > >>>Am 28.11.2023 01:29:39 schrieb Jaromir Matas
<mail(a)jaromir.net>:
> >>> > >>>Hi Eliot, Marcel, all, > >>> > >>>I've sent a fix Kernel-jar.1539 to the Inbox that solves
the
> >>>remaining bit of the chain of bugs described in the
previous
post.
> >>>All tests are green now and I think the root cause has
been
found
and > >>>fixed. > >>> > >>>In this last bit I've created a version of stepToCallee
that
would
> >>>identify a potential illegal return to a nil sender and
avoid
it.
> >>> > >>>Now this example can be debugged without any problems: > >>> > >>>[[self halt. ^ 1] on: BlockCannotReturn do: #resume ]
fork
> >>> > >>>If you're happy with the solution in Kernel-jar.1539, > >>>Kernel-jar.1538, Kernel-jar.1537 and the test in KernelTests-jar.447, > >>>could you please double-check and merge, please? (And
remove
> >>>Kernel-mt.1534 and Tools-jar.1240 from the Inbox) > >>> > >>>Best, > >>>Jaromir > >>> > >>> > >>> > >>>On 27-Nov-23 12:09:37 AM, "Jaromir Matas"
<mail(a)jaromir.net>
wrote: > >>> > >>>>Hi Eliot, Christoph, all > >>>> > >>>>It looks like there are some more skeletons in the
closet :/
> >>>> > >>>>If you run this example > >>>> > >>>>[[self halt. ^ 1] on: BlockCannotReturn do: [:ex | ex
resume]
]
fork > >>>> > >>>>and step over halt and then step over ^1 you get a
nonsensical
error > >>>>as a result of decoding nil as an instruction. > >>>> > >>>>It turns out that the root cause is in the #return:from:
method:
it > >>>>only checks whether aSender is dead but ignores the
possibility
that > >>>>aSender sender may be nil or dead in which cases the VM
also
> >>>>responds with sending #cannotReturn, hence I assume the
simulator
> >>>>should do the same. In addition, the VM nills the pc in
such
> >>>>scenario, so I added the same functionality here too: > >>>> > >>>>Context >> return: value from: aSender > >>>> "For simulation. Roll back self to aSender and return
value
> >>>>from it. Execute any unwind blocks on the way. ASSUMES
aSender is
> >>>>a sender of self" > >>>> > >>>> | newTop | > >>>> newTop := aSender sender. > >>>> (aSender isDead or: [newTop isNil or: [newTop isDead]])
ifTrue:
> >>>> "<--------- this is extended ------" > >>>> [^self pc: nil; send: #cannotReturn: to: self with: > >>>>{value}]. "<------ pc: nil is added ----" > >>>> (self findNextUnwindContextUpTo: newTop) ifNotNil: > >>>> "Send #aboutToReturn:through: with nil as the second > >>>>argument to avoid this bug: > >>>> Cannot #stepOver '^2' in example '[^2] ensure: []'. > >>>> See >
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html >
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html" > >>>> [^self send: #aboutToReturn:through: to: self with:
{value.
> >>>>nil}]. > >>>> self releaseTo: newTop. > >>>> newTop ifNotNil: [newTop push: value]. > >>>> ^newTop > >>>> > >>>>In order for this to work #cannotReturn: has to be
modified
as in
> >>>>Kernel-jar.1537: > >>>> > >>>>Context >> cannotReturn: result > >>>> > >>>> closureOrNil ifNotNil: [^ self cannotReturn: result to:
self
> >>>>home sender]. > >>>> self error: 'Computation has been terminated!' > >>>>"<----------- this has to be an Error -----" > >>>> > >>>>Then it almost works except when you keep stepping over
in
the
> >>>>example above, you get an MNU error on `self previousPc`
in
> >>>>#cannotReturn:to:` with your solution of the VM crash.
If you
don't > >>>>mind I've amended your solution and added the final
context
where
> >>>>the computation couldn't return along with the pc: > >>>> > >>>>Context >> cannotReturn: result to: homeContext > >>>> "The receiver tried to return result to homeContext
that
cannot
> >>>>be returned from. > >>>> Capture the return context/pc in a BlockCannotReturn.
Nil
the pc
> >>>>to prevent repeat > >>>> attempts and/or invalid continuation. Answer the result
of
> >>>>raising the exception." > >>>> > >>>> | exception previousPc | > >>>> exception := BlockCannotReturn new. > >>>> previousPc := pc ifNotNil: [self previousPc]. "<-----
here's
a
> >>>>fix ----" > >>>> exception > >>>> result: result; > >>>> deadHome: homeContext; > >>>> finalContext: self; "<----- here's the new state, if > >>>>that's fine ----" > >>>> pc: previousPc. > >>>> pc := nil. > >>>> ^exception signal > >>>> > >>>>Unfortunately, this is still not the end of the story:
there
are
> >>>>situations where #runUntilErrorOrReturnFrom: places the
two
guard
> >>>>contexts below the bottom context. And that is a problem
because
> >>>>when the method tries to remove the two guard contexts
before
> >>>>returning at the end it uses #stepToCalee to do the job
but
this
> >>>>unforotunately was (ab)using the above bug in
#return:from: -
I'll > >>>>explain: #return:from: didn't check whether aSender
sender
was
nil > >>>>and as a result it allowed to simulate a return to a
"nil
context" > >>>>which was then (ab)used in the clean-up via #stepToCalee
in
the
> >>>>#runUntilErrorOrReturnFrom:. > >>>> > >>>>When I fixed the #return:from: bug, the #runUntilErrorOrReturnFrom: > >>>>cleanup of the guard contexts no longer works in that
very
special > >>>>case where the guard contexts are below the bottom
context.
There's > >>>>one case where this is being used: #terminateAggresively
by
> >>>>Christoph. > >>>> > >>>>If I'm right with this analysis, the
#runUntilErrorOrReturnFrom:
> >>>>should get fixed too but I'll be away now for a few days
and
I
won't > >>>>be able to respond. If you or Christoph had a chance to
take
a
look > >>>>at Kernel-jar.1538 and Kernel-jar.1537 I'd be very
grateful.
I
hope > >>>>this super long message at least makes some sense :) > >>>>Best, > >>>>Jaromir > >>>> > >>>>[1] Kernel-jar.1538, Kernel-jar.1537 > >>>>[2] KernelTests-jar.447 > >>>> > >>>> > >>>>PS: Christoph, > >>>> > >>>>With Kernel-jar.1538 + Kernel-jar.1537 your example > >>>> > >>>>process := > >>>> [(c := thisContext) pc: nil. > >>>> 2+3] newProcess. > >>>>process runUntil: [:ctx | ctx selector =
#cannotReturn:].
> >>>>self assert: process suspendedContext sender sender = c. > >>>>self assert: process suspendedContext arguments = {c}. > >>>> > >>>>works fine, I've just corrected your first assert. > >>>> > >>>> > >>>> > >>>> > >>>> > >>>>On 21-Nov-23 6:40:32 PM, "Eliot Miranda" <eliot.miranda(a)gmail.com> > >>>>wrote: > >>>> > >>>>>Hi Jaromir, > >>>>> > >>>>>>On Nov 20, 2023, at 11:51 PM, Jaromir Matas <mail(a)jaromir.net> > >>>>>>wrote: > >>>>>> > >>>>>> > >>>>>>Hi Eliot, > >>>>>>Very elegant! Now I finally got what you meant exactly
:)
Thanks. > >>>>>> > >>>>>>Two questions: > >>>>>>1. in order for the enclosed test to work I'd need an
Error
> >>>>>>instead of Processor debugWithTitle:full: call in #cannotReturn:. > >>>>>>Otherwise I don't know how to catch a plain invocation
of
the
> >>>>>>Debugger: > >>>>>> > >>>>>>cannotReturn: result > >>>>>> > >>>>>> closureOrNil ifNotNil: [^ self cannotReturn: result
to:
self
> >>>>>>home sender]. > >>>>>> self error: 'Computation has been terminated!' > >>>>> > >>>>>Much nicer. > >>>>> > >>>>>>2. We are capturing a pc of self which is completely
different
> >>>>>>context from homeContext indeed. > >>>>> > >>>>>Right. The return is attempted from a specific return
bytecode
in a > >>>>>specific block. This is the coordinate of the return
that
cannot
be > >>>>>made. This is the relevant point of origin of the
cannot
return
> >>>>>exception. > >>>>> > >>>>>Why the return fails is another matter: > >>>>>- the home context’s sender is a dead context (cannot
be
resumed) > >>>>>- the home context’s sender is nil (home already
returned
from)
> >>>>>- the block activation’s home is nil rather than a
context
(should > >>>>>not happen) > >>>>> > >>>>>But in all these cases the pc of the home context is
immaterial.
> >>>>>The hike is being returned through/from, rather than
from;
the
> >>>>>home’s pc is not relevant. > >>>>> > >>>>>>Maybe we could capture self in the exception too to
make it
more > >>>>>>clear/explicit what is going on: what context the
captured
pc
is > >>>>>>actually associated with. Just a thought... > >>>>> > >>>>>Yes, I like that. I also like the idea of somehow
passing
the
> >>>>>block activation’s pc to the debugger so that the
relevant
return > >>>>>expression is highlighted in the debugger. > >>>>> > >>>>>> > >>>>>>Thanks again, > >>>>>>Jaromir > >>>>> > >>>>>You’re welcome. I love working in this part of the
system.
Thanks > >>>>>for dragging me there. I’m in a slump right now and
appreciate
the > >>>>>fellowship. > >>>>> > >>>>>>------ Original Message ------ > >>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> > >>>>>>To "Jaromir Matas" <mail(a)jaromir.net> > >>>>>>Cc squeak-dev(a)lists.squeakfoundation.org > >>>>>>Date 11/21/2023 2:17:21 AM > >>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn > >>>>>>exception > >>>>>> > >>>>>>>Hi Jaromir, > >>>>>>> > >>>>>>> see Kernel-eem.1535 for what I was suggesting. This
example
> >>>>>>>now has an exception with the right pc value in it: > >>>>>>> > >>>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect.
ex
resume]] > >>>>>>>fork > >>>>>>> > >>>>>>>The fix is simply > >>>>>>> > >>>>>>>Context>>cannotReturn: result to: homeContext > >>>>>>> "The receiver tried to return result to homeContext
that
> >>>>>>>cannot be returned from. > >>>>>>> Capture the return pc in a BlockCannotReturn. Nil
the pc
to
> >>>>>>>prevent repeat > >>>>>>> attempts and/or invalid continuation. Answer the
result
of
> >>>>>>>raising the exception." > >>>>>>> > >>>>>>> | exception | > >>>>>>> exception := BlockCannotReturn new. > >>>>>>> exception > >>>>>>> result: result; > >>>>>>> deadHome: homeContext; > >>>>>>> pc: self previousPc. > >>>>>>> pc := nil. > >>>>>>> ^exception signal > >>>>>>> > >>>>>>> > >>>>>>>The VM crash is now avoided. The debugger displays
the
method,
> >>>>>>>but does not highlight the offending pc, which is no
big
deal.
A > >>>>>>>suitable defaultHandler for B lockCannotReturn may be
able
to
get > >>>>>>>the debugger to highlight correctly on opening. Try
the
> >>>>>>>following examples: > >>>>>>> > >>>>>>>[[^1] on: BlockCannotReturn do: #resume] fork. > >>>>>>> > >>>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect.
ex
resume]] > >>>>>>>fork > >>>>>>> > >>>>>>>[[^1] value] fork. > >>>>>>> > >>>>>>>They al; seem to behave perfectly acceptably to me.
Does
this
> >>>>>>>fix work for you? > >>>>>>> > >>>>>>>On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas <mail(a)jaromir.net> > >>>>>>>wrote: > >>>>>>>>Hi Eliot, > >>>>>>>> > >>>>>>>>How about to nil the pc just before making the
return:
> >>>>>>>>``` > >>>>>>>>Context >> #cannotReturn: result > >>>>>>>> > >>>>>>>> self push: self pc. "backup the pc for the sake of > >>>>>>>>debugging" > >>>>>>>> closureOrNil ifNotNil: [^self cannotReturn: result
to:
self
> >>>>>>>>home sender; pc: nil]. > >>>>>>>> Processor debugWithTitle: 'Computation has been
terminated!'
> >>>>>>>>translated full: false > >>>>>>>>``` > >>>>>>>>The nilled pc should not even potentially interfere
with
the
> >>>>>>>>#isDead now. > >>>>>>>> > >>>>>>>>I hope this is at least a step in the right
direction :)
> >>>>>>>> > >>>>>>>>However, there's still a problem when debugging the resumption > >>>>>>>>of #cannotReturn because the encoders expect a
reasonable
index. > >>>>>>>>I haven't figured out yet where to place a nil check
#step,
> >>>>>>>>#stepToSendOrReturn... ? > >>>>>>>> > >>>>>>>>Thanks again, > >>>>>>>>Jaromir > >>>>>>>> > >>>>>>>> > >>>>>>>>------ Original Message ------ > >>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> > >>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> > >>>>>>>>Date 11/17/2023 8:36:50 PM > >>>>>>>>Subject Re: [squeak-dev] Re: Resuming on
BlockCannotReturn
> >>>>>>>>exception > >>>>>>>> > >>>>>>>>>Hi Jaromir, > >>>>>>>>> > >>>>>>>>>>On Nov 17, 2023, at 7:05 AM, Jaromir Matas <mail(a)jaromir.net> > >>>>>>>>>>wrote: > >>>>>>>>>> > >>>>>>>>>> > >>>>>>>>>>Eliot, hi again, > >>>>>>>>>> > >>>>>>>>>>Please disregard my previous comment about nilling
the
> >>>>>>>>>>contexts that have returned. We are indeed talking
about
the > >>>>>>>>>>context directly under the #cannotReturn context
which
is
> >>>>>>>>>>totally different from the home context in another
thread
> >>>>>>>>>>that's gone. > >>>>>>>>>> > >>>>>>>>>>I may still be confused but would nilling the pc
of the
> >>>>>>>>>>context directly under the cannotReturn context
help?
Here's > >>>>>>>>>>what I mean: > >>>>>>>>>>``` > >>>>>>>>>>Context >> #cannotReturn: result > >>>>>>>>>> > >>>>>>>>>> closureOrNil ifNotNil: [^self pc: nil;
cannotReturn:
> >>>>>>>>>>result to: self home sender]. > >>>>>>>>>> Processor debugWithTitle: 'Computation has been > >>>>>>>>>>terminated!' translated full: false. > >>>>>>>>>>``` > >>>>>>>>>>Instead of crashing the VM invokes the debugger
with
the
> >>>>>>>>>>'Computation has been terminated!' message. > >>>>>>>>>> > >>>>>>>>>>Does this make sense? > >>>>>>>>> > >>>>>>>>>Nearly. But it loses the information on what the pc
actually
> >>>>>>>>>is, and that’s potentially vital information. So
IMO the
ox
> >>>>>>>>>should only be nilled between the BlockCannotReturn exception > >>>>>>>>>being created and raised. > >>>>>>>>> > >>>>>>>>>[But if you try this don’t be surprised if it
causes a
few
> >>>>>>>>>temporary problems. It looks to me that without a
little
> >>>>>>>>>refactoring this could easily cause an infinite
recursion
> >>>>>>>>>around the sending of isDead. I’m sure you’ll be
able to
fix
> >>>>>>>>>the code to work correctly] > >>>>>>>>> > >>>>>>>>>>Thanks, > >>>>>>>>>>Jaromir > >>>>>>>>>> > >>>>>>>>>> > >>>>>>>>>>------ Original Message ------ > >>>>>>>>>>From "Jaromir Matas" <mail(a)jaromir.net> > >>>>>>>>>>To "Eliot Miranda" <eliot.miranda(a)gmail.com>;
"The
> >>>>>>>>>>general-purpose Squeak developers list" > >>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > >>>>>>>>>>Date 11/17/2023 10:15:17 AM > >>>>>>>>>>Subject [squeak-dev] Re: Resuming on
BlockCannotReturn
> >>>>>>>>>>exception > >>>>>>>>>> > >>>>>>>>>>>Hi Eliot, > >>>>>>>>>>> > >>>>>>>>>>> > >>>>>>>>>>> > >>>>>>>>>>>------ Original Message ------ > >>>>>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> > >>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> > >>>>>>>>>>>Cc "The general-purpose Squeak developers list" > >>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > >>>>>>>>>>>Date 11/16/2023 11:52:45 PM > >>>>>>>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on > >>>>>>>>>>>BlockCannotReturn exception > >>>>>>>>>>> > >>>>>>>>>>>>Hi Jaromir, > >>>>>>>>>>>> > >>>>>>>>>>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas > >>>>>>>>>>>><mail(a)jaromir.net> wrote: > >>>>>>>>>>>>>Hi Nicolas, Eliot, > >>>>>>>>>>>>> > >>>>>>>>>>>>>here's what I understand is happening (see the
enclosed
> >>>>>>>>>>>>>screenshot): > >>>>>>>>>>>>> > >>>>>>>>>>>>>1) we fork a new process to evaluate [^1] > >>>>>>>>>>>>>2) the new process evaluates [^1] which means instruction > >>>>>>>>>>>>>18 is being evaluated, hence pc points to
instruction 19
> >>>>>>>>>>>>>now > >>>>>>>>>>>>>3) however, the home context where ^1 should
return
to
is > >>>>>>>>>>>>>gone by this time (the process that executed
the
fork
has > >>>>>>>>>>>>>already returned - notice the two up arrows in
the
debugger > >>>>>>>>>>>>>screenshot) > >>>>>>>>>>>>>4) the VM can't finish the instruction and
returns
control > >>>>>>>>>>>>>to the image via placing the #cannotReturn:
context
on
top > >>>>>>>>>>>>>of the [^1] context > >>>>>>>>>>>>>5) #cannotReturn: evaluation results in
signalling
the
BCR > >>>>>>>>>>>>>exception which is then handled by the #resume
handler
> >>>>>>>>>>>>> (in our debugged case the [:ex | self halt. ex
resume]
> >>>>>>>>>>>>>handler) > >>>>>>>>>>>>>6) ex resume is evaluated, however, this means requesting > >>>>>>>>>>>>>the VM to evaluate instruction 19 of the [^1]
context -
> >>>>>>>>>>>>>which is past the last instruction of the
context
and
the > >>>>>>>>>>>>>crash ensues > >>>>>>>>>>>>> > >>>>>>>>>>>>>I wonder whether such situations could/should
be
prevented > >>>>>>>>>>>>>inside the VM or whether such an expectation is
wrong
for > >>>>>>>>>>>>>some reason. > >>>>>>>>>>>> > >>>>>>>>>>>>As Nicolas says, IMO this is best done at the
image
level. > >>>>>>>>>>>> > >>>>>>>>>>>>It could be prevented in the VM, but at great
cost,
and
only > >>>>>>>>>>>>partially. The performance issue is that the
last
bytecode > >>>>>>>>>>>>in a method is not marked in any way, and that
to
determine > >>>>>>>>>>>>the last bytecode the bytecodes must be
symbolically
> >>>>>>>>>>>>evaluated from the start of the method. See
implementors
of > >>>>>>>>>>>>endPC at the image level (which defer to the
method
trailer) > >>>>>>>>>>>>and implementors of endPCOf: in the VMMaker
code.
Doing
this > >>>>>>>>>>>>every time execution commences is prohibitively expensive. > >>>>>>>>>>>>The "only partially" issue is that following the
return
> >>>>>>>>>>>>instruction may be other valid bytecodes, but
these
are
not > >>>>>>>>>>>>a continuation. > >>>>>>>>>>>> > >>>>>>>>>>>> > >>>>>>>>>>>>Consider the following code in some block: > >>>>>>>>>>>> [self expression ifTrue: > >>>>>>>>>>>> [^1]. > >>>>>>>>>>>> ^2 > >>>>>>>>>>>> > >>>>>>>>>>>>The bytecodes for this are > >>>>>>>>>>>> pushReceiver > >>>>>>>>>>>> send #expression > >>>>>>>>>>>> jumpFalse L1 > >>>>>>>>>>>> push 1 > >>>>>>>>>>>> methodReturnTop > >>>>>>>>>>>>L1 > >>>>>>>>>>>> push 2 > >>>>>>>>>>>> methodReturnTop > >>>>>>>>>>>> > >>>>>>>>>>>>Clearly if expression is true these should be
*no*
> >>>>>>>>>>>>continuation in which ^2 is executed. > >>>>>>>>>>> > >>>>>>>>>>>Well, in that case there's a bug because the
computation
in > >>>>>>>>>>>the following example shouldn't continue past the
[^1]
block > >>>>>>>>>>>but it silently does: > >>>>>>>>>>>`[[true ifTrue: [^ 1]] on: BlockCannotReturn do:
#resume ]
> >>>>>>>>>>>fork` > >>>>>>>>>>> > >>>>>>>>>>>The bytecodes are > >>>>>>>>>>> push true > >>>>>>>>>>> jumpFalse L1 > >>>>>>>>>>> push 1 > >>>>>>>>>>> returnTop > >>>>>>>>>>>L1 > >>>>>>>>>>> push nil > >>>>>>>>>>> blockReturn > >>>>>>>>>>> > >>>>>>>>>>> > >>>>>>>>>>> > >>>>>>>>>>>> > >>>>>>>>>>>>So even if the VM did try and detect whether the
return
was > >>>>>>>>>>>>at the last block method, it would only work for
special
> >>>>>>>>>>>>cases. > >>>>>>>>>>>> > >>>>>>>>>>>> > >>>>>>>>>>>>It seems to me the issue is simply that the
context
that
> >>>>>>>>>>>>cannot be returned from should be marked as dead
(see
> >>>>>>>>>>>>Context>>isDead) by setting its pc to nil at
some
point,
> >>>>>>>>>>>>presumably after copying the actual return pc
into
the
> >>>>>>>>>>>>BlockCannotReturn exception, to avoid ever
trying to
resume > >>>>>>>>>>>>the context. > >>>>>>>>>>> > >>>>>>>>>>>Does this mean, in other words, that every
context
that
> >>>>>>>>>>>returns should nil its pc to avoid being
"wrongly"
> >>>>>>>>>>>reused/executed in the future, which concerns
primarily
those > >>>>>>>>>>>being referenced somewhere hence potentially
executable in
> >>>>>>>>>>>the future, is that right? > >>>>>>>>>>>Hypothetical question: would nilling the pc
during
returns
> >>>>>>>>>>>"fix" the example? > >>>>>>>>>>>Thanks a lot for helping me understand this. > >>>>>>>>>>>Best, > >>>>>>>>>>>Jaromir > >>>>>>>>>>> > >>>>>>>>>>> > >>>>>>>>>>> > >>>>>>>>>>>> > >>>>>>>>>>>> > >>>>>>>>>>>>> > >>>>>>>>>>>>>Thanks, > >>>>>>>>>>>>>Jaromir > >>>>>>>>>>>>> > >>>>>>>>>>>>><bdxuqalu.png> > >>>>>>>>>>>>> > >>>>>>>>>>>>>------ Original Message ------ > >>>>>>>>>>>>>From "Eliot Miranda"
<eliot.miranda(a)gmail.com>
> >>>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The general-purpose > >>>>>>>>>>>>>Squeak developers list" > >>>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > >>>>>>>>>>>>>Date 11/16/2023 6:48:43 PM > >>>>>>>>>>>>>Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn > >>>>>>>>>>>>>exception > >>>>>>>>>>>>> > >>>>>>>>>>>>>>Hi Jaromir, > >>>>>>>>>>>>>> > >>>>>>>>>>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas > >>>>>>>>>>>>>>><mail(a)jaromir.net> wrote: > >>>>>>>>>>>>>>> > >>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>Hi Nicloas, > >>>>>>>>>>>>>>>No no, I don't have any practical scenario in
mind,
I'm > >>>>>>>>>>>>>>>just trying to understand why the VM is
implemented
like > >>>>>>>>>>>>>>>this, whether there were a reason to leave
this
> >>>>>>>>>>>>>>>possibility of a crash, e.g. it would slow
down
the VM
to > >>>>>>>>>>>>>>>try to prevent such a dumb situation (who
would
resume
> >>>>>>>>>>>>>>>from BCR in his right mind? :) ) - or perhaps
I
have
> >>>>>>>>>>>>>>>overlooked some good reason to even keep this
behavior
in > >>>>>>>>>>>>>>>the VM. That's all. > >>>>>>>>>>>>>> > >>>>>>>>>>>>>>Let’s first understand what’s really
happening.
Presumably > >>>>>>>>>>>>>>at tone point a context is resumed those pc is
already
at > >>>>>>>>>>>>>>the block return bytecode (effectively,
because it
crashes > >>>>>>>>>>>>>>in JITted code, but I bet the stack vm will
crash
also,
> >>>>>>>>>>>>>>but not as cleanly - it will try and execute
the
bytes
in > >>>>>>>>>>>>>>the encoded method trailer). So which method
actually
> >>>>>>>>>>>>>>sends resume, and to what, and what state is
resume’s
> >>>>>>>>>>>>>>receiver when resume is sent? > >>>>>>>>>>>>>> > >>>>>>>>>>>>>> > >>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>Thanks for your reply. > >>>>>>>>>>>>>>>Regards, > >>>>>>>>>>>>>>>Jaromir > >>>>>>>>>>>>>>> > >>>>>>>>>>>>>>> > >>>>>>>>>>>>>>> > >>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>------ Original Message ------ > >>>>>>>>>>>>>>>From "Nicolas Cellier" > >>>>>>>>>>>>>>><nicolas.cellier.aka.nice(a)gmail.com> > >>>>>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The > >>>>>>>>>>>>>>>general-purpose Squeak developers list" > >>>>>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > >>>>>>>>>>>>>>>Date 11/16/2023 7:20:20 AM > >>>>>>>>>>>>>>>Subject Re: [squeak-dev] Resuming on
BlockCannotReturn
> >>>>>>>>>>>>>>>exception > >>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>Hi Jaromir, > >>>>>>>>>>>>>>>>Is there a scenario where it would make
sense to
resume > >>>>>>>>>>>>>>>>a BlockCannotReturn? > >>>>>>>>>>>>>>>>If not, I would suggest to protect at image
side
and
> >>>>>>>>>>>>>>>>override #resume. > >>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas > >>>>>>>>>>>>>>>><mail(a)jaromir.net> a écrit : > >>>>>>>>>>>>>>>>>Hi Eliot, Christoph, All, > >>>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>>It's known the following example crashes
the VM.
Is
> >>>>>>>>>>>>>>>>>this an intended behavior or a "tolerated
bug"?
> >>>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume]
fork`
> >>>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>>I understand why it crashes: the non-local
return
has > >>>>>>>>>>>>>>>>>nowhere to return to and so resuming the
computation
> >>>>>>>>>>>>>>>>>leads to a crash. But why not raise another
BCR
> >>>>>>>>>>>>>>>>>exception to prevent the crash? Potential
infinite
> >>>>>>>>>>>>>>>>>loop? Perhaps I'm just missing the purpose
of
this
> >>>>>>>>>>>>>>>>>behavior... > >>>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>>Thanks for an explanation. > >>>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>>Best, > >>>>>>>>>>>>>>>>>Jaromir > >>>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>>-- > >>>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>>Jaromir Matas > >>>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>> > >>>>>>>>>>>> > >>>>>>>>>>>> > >>>>>>>>>>>>-- > >>>>>>>>>>>>_,,,^..^,,,_ > >>>>>>>>>>>>best, Eliot > >>>>>>>>>><Context-cannotReturn.st> > >>>>>>> > >>>>>>> > >>>>>>>-- > >>>>>>>_,,,^..^,,,_ > >>>>>>>best, Eliot > >>>>>><ProcessTest-testResumeAfterBCR.st>
Hi Jaromir,
thanks for the clarification. If you don't mind I would still wait for a couple of days to see whether Eliot or Marcel or someone else who are longer aboard find anything against your change, but I have been convinced by you. :-) After that, we can merge your open test and eliminate the ifNil checks in the TraceDebugger and also in the penultimate line of Context>>#return:from:.
In general, some methods are "pure simulation" methods intended to mimic the VM behavior (#step etc) but nothing prevents one from using them for other purposes - like what #runUntilErrorOrReturnFrom: did: to just get rid of some contexts). Is it ok to do that? I tend to think it's not; it's confusing. That's why I made #stepToCalleeOrNil a private method because it's not a "true" simulation method but a sort of hybrid.
Yes, I think I understand your point here, the assumptions and use cases for #stepToCalleeOrNil are too special to expose it to everyone. Clients should mainly use #step, #stepToCallee, or maybe - with care - #runUntilErrorOrReturnFrom: to advance a context I think.
This is also why I checked Jakob's Git Browser and all tests seem fine.
Wait, Squot is using code simulation?
Best, Christoph
--- Sent from Squeak Inbox Talk
On 2024-01-02T11:25:57+00:00, mail@jaromir.net wrote:
Hi Christoph,
correct me if I'm wrong: with the corrected #step semantics (the #return:from: fix) one should no longer need to do things like:
self step ifNil: [^ self]
because #step should always return a context, even if attempting to step to a nil context:
[] asContext step
In this case it correctly returns the #cannotReturn: context.
I've noticed these nil checks in Trace debugger's #doStepOver or #stepToHome.
I hope I haven't overlooked anything :)
Thanks for your thoughts, Jaromir
On 31-Dec-23 10:42:54 AM, "Jaromir Matas" <mail(a)jaromir.net> wrote:
Hi Christoph,
Yes, that's exactly what I was talking about - the #return:from: fix changes slightly (perhaps it's better to say corrects) the semantics of some stepping methods - #step and #stepToCallee, which allowed illegally stepping into a dead or nil context. They can no longer be used in the manner you showed. Another example was #runUntilErrorOrReturnFrom: - it used #stepToCallee this way so as a workaround I created the #stepToCalleeOrNil method and used in #runUntilErrorOrReturnFrom:
[ctxt isDead or: [topContext isNil]] whileFalse: [topContext := topContext stepToCalleeOrNil].
Theoretically there might be some external code (mis)using the incorrect stepping semantics. In Pharo's trunk they were mainly tests and #stepToHome but I haven't checked any external code. But all their tests are green with this change and I guess it's not widespread.
This is also why I checked Jakob's Git Browser and all tests seem fine.
My opinion is to keep the correct simulation semantics and deal with potential consequences as/if they come. However I don't expect a huge impact as the change only affects border situations.
In general, some methods are "pure simulation" methods intended to mimic the VM behavior (#step etc) but nothing prevents one from using them for other purposes - like what #runUntilErrorOrReturnFrom: did: to just get rid of some contexts). Is it ok to do that? I tend to think it's not; it's confusing. That's why I made #stepToCalleeOrNil a private method because it's not a "true" simulation method but a sort of hybrid.
What do you think?
Thanks for reviewing the fix! Best, Jaromir
On 30-Dec-23 11:07:54 PM, christoph.thiede(a)student.hpi.uni-potsdam.de wrote:
Hi Jaromir,
I found a breaking change in the new behavior of Context>>#return:from: while using the TraceDebugger:
In the past we could say:
c:=[2+3]asContext. [c]whileNotNil:[c:=cstep].
With your change, the script runs forever because the last step does not answer nil as before but activates a new #cannotReturn:.
This behavior seems not be expected anywhere in the trunk (if my first search was complete), and you are right that the new behavior aligns closer to the VM behavior. Still, the old code seemed to explicitly intend this - see the "newTop ifNotNil:" at the bottom of the method.
I wonder whether we should keep this. For me it is not a big deal; I can just change my script like this:
c:=[2+3]asContext. [csenderisNiland:[cwillReturn]]whileNotNil:[c:=cstep].
I just wonder whether this could a breaking or unintended change for anything else. For [^2] ensure: [] it would not be a big deal, we could just change the check in question to (aSenderisDeador:[newTopnotNiland:[newTopisDead]])ifTrue:. I am tending against restoring the old behavior, but I am unsure. What is your opinion on this?
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-12-30T21:13:37+00:00, mail(a)jaromir.net wrote:
nit: You mixed up the order of arguments for #assert:equals:
oops, sorry :) It happens to me all the time; I've never actually understood why the strange, almost Yodaesque, order... as if you
asked
in English:
"Make sure 18 is his age."
Thanks, Jaromir
On 30-Dec-23 9:13:56 PM,
christoph.thiede(a)student.hpi.uni-potsdam.de
wrote:
nit: You mixed up the order of arguments for #assert:equals: (it is assert: expected equals: actual) and could have used it in the
final
assert again, but that's clearly no reason to hold back a useful
test.
;-) Merged, thanks! :-)
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-12-30T17:33:08+00:00, mail(a)jaromir.net wrote:
Hi Christoph,
Thanks for merging the fixes; I've just sent another test in KernelTests-jar.448 to complement them.
Please take a look and if ok I'd appreciate it if you could
merge it
as
well.
Best regards and Happy New Year to you too! Jaromir
On 30-Dec-23 6:15:25 PM,
christoph.thiede(a)student.hpi.uni-potsdam.de
wrote:
>Hi Jaromir, hi all, > >finally I have found the time to review these suggestions. >Kernel-jar.1537, Kernel-jar.1538, and Kernel-jar.1539 look
excellent
to
>me as well. Clear, straightforward, useful. :-) I have merged
them
into
>the trunk via Kernel-ct.1545. > >Regarding DebuggerTests>>test16HandleSimulationError, I have
patched
it
>via ToolsTests-ct.125. Nothing to rack your brains over:
"thisContext
>pc: nil" just mimicks any kind of unhandled error inside the
simulator
>- since we now gently handle this via #cannotReturn:, I just
replaced
>it with "thisContext pc: false". :-) Sorry for not clarifying
that
>earlier and letting you speculate. > >Thanks for your work, and I already wish you a happy new year! > >Best, >Christoph > >--- >Sent from Squeak Inbox Talk >https://github.com/hpi-swa-lab/squeak-inbox-talk > >On 2023-11-29T13:31:09+00:00, mail(a)jaromir.net wrote: > > > Hi Marcel, > > > > > [myself] whether the patch would have been necessary
should the
> > #return:from: had been fixed then > > > > Nonsense, I just mixed it up with another issue :) > > > > > > On 29-Nov-23 1:51:21 PM, "Jaromir Matas"
<mail(a)jaromir.net>
wrote:
> > > > >Thanks Marcel! This test somehow slipped my attention :) > > > > > >The test can no longer work as is. It takes advantage of
the
>erroneous > > >behavior of #return:from: in the sense that if you simulate > > > > > > thisContext pc: nil > > > > > >it'll happily return to a dead context (i.e. to thisContext
from
>#pc: > > >nil context) - which is not what the VM does during
runtime. It
>should > > >immediately raise an illegal return exception not only
during
>runtime > > >but also during simulation. > > > > > >The test mentions a patch for an infinite debugger chain > >
(http://forum.world.st/I-broke-the-debugger-td5110752.html). I
>wonder > > >whether the problem could have something to do with this
simulation
>bug > > >in return:from:; and a terrible idea occurred to me whether
the
>patch > > >would have been necessary should the #return:from: had been
fixed
>then > > >;O > > > > > >We may potentially come up with more examples like this,
even in
the
> > >trunk, where the bug from #return:from: propagated and was
taken
> > >advantage of. I've found and fixed
#runUntilErrorOrReturnFrom:
but
>more > > >can still be surviving undetected... > > > > > >I'd place the test into #expectedFailures for now but maybe
it's
>time > > >to remove it; Christoph should decide :) > > > > > >Thanks again, > > >Jaromir > > > > > > > > >On 29-Nov-23 10:28:38 AM, "Taeumel, Marcel via Squeak-dev" > > ><squeak-dev(a)lists.squeakfoundation.org> wrote: > > > > > >>Hi Jaromir -- > > >> > > >>Looks good. Still, what about that
#test16HandleSimulationError
>now? > > >>:-) It is failing with your changes ... how would you
adapt it?
> > >> > > >> > > >> > > >>Best, > > >>Marcel > > >>>Am 28.11.2023 01:29:39 schrieb Jaromir Matas
<mail(a)jaromir.net>:
> > >>> > > >>>Hi Eliot, Marcel, all, > > >>> > > >>>I've sent a fix Kernel-jar.1539 to the Inbox that solves
the
> > >>>remaining bit of the chain of bugs described in the
previous
post.
> > >>>All tests are green now and I think the root cause has
been
found
>and > > >>>fixed. > > >>> > > >>>In this last bit I've created a version of stepToCallee
that
would
> > >>>identify a potential illegal return to a nil sender and
avoid
it.
> > >>> > > >>>Now this example can be debugged without any problems: > > >>> > > >>>[[self halt. ^ 1] on: BlockCannotReturn do: #resume ]
fork
> > >>> > > >>>If you're happy with the solution in Kernel-jar.1539, > > >>>Kernel-jar.1538, Kernel-jar.1537 and the test in >KernelTests-jar.447, > > >>>could you please double-check and merge, please? (And
remove
> > >>>Kernel-mt.1534 and Tools-jar.1240 from the Inbox) > > >>> > > >>>Best, > > >>>Jaromir > > >>> > > >>> > > >>> > > >>>On 27-Nov-23 12:09:37 AM, "Jaromir Matas"
<mail(a)jaromir.net>
>wrote: > > >>> > > >>>>Hi Eliot, Christoph, all > > >>>> > > >>>>It looks like there are some more skeletons in the
closet :/
> > >>>> > > >>>>If you run this example > > >>>> > > >>>>[[self halt. ^ 1] on: BlockCannotReturn do: [:ex | ex
resume]
]
>fork > > >>>> > > >>>>and step over halt and then step over ^1 you get a
nonsensical
>error > > >>>>as a result of decoding nil as an instruction. > > >>>> > > >>>>It turns out that the root cause is in the #return:from:
method:
>it > > >>>>only checks whether aSender is dead but ignores the
possibility
>that > > >>>>aSender sender may be nil or dead in which cases the VM
also
> > >>>>responds with sending #cannotReturn, hence I assume the
simulator
> > >>>>should do the same. In addition, the VM nills the pc in
such
> > >>>>scenario, so I added the same functionality here too: > > >>>> > > >>>>Context >> return: value from: aSender > > >>>> "For simulation. Roll back self to aSender and return
value
> > >>>>from it. Execute any unwind blocks on the way. ASSUMES
aSender is
> > >>>>a sender of self" > > >>>> > > >>>> | newTop | > > >>>> newTop := aSender sender. > > >>>> (aSender isDead or: [newTop isNil or: [newTop isDead]])
ifTrue:
> > >>>> "<--------- this is extended ------" > > >>>> [^self pc: nil; send: #cannotReturn: to: self with: > > >>>>{value}]. "<------ pc: nil is added ----" > > >>>> (self findNextUnwindContextUpTo: newTop) ifNotNil: > > >>>> "Send #aboutToReturn:through: with nil as the second > > >>>>argument to avoid this bug: > > >>>> Cannot #stepOver '^2' in example '[^2] ensure: []'. > > >>>> See > > >
>http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html > > >
>http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html" > > >>>> [^self send: #aboutToReturn:through: to: self with:
{value.
> > >>>>nil}]. > > >>>> self releaseTo: newTop. > > >>>> newTop ifNotNil: [newTop push: value]. > > >>>> ^newTop > > >>>> > > >>>>In order for this to work #cannotReturn: has to be
modified
as in
> > >>>>Kernel-jar.1537: > > >>>> > > >>>>Context >> cannotReturn: result > > >>>> > > >>>> closureOrNil ifNotNil: [^ self cannotReturn: result to:
self
> > >>>>home sender]. > > >>>> self error: 'Computation has been terminated!' > > >>>>"<----------- this has to be an Error -----" > > >>>> > > >>>>Then it almost works except when you keep stepping over
in
the
> > >>>>example above, you get an MNU error on `self previousPc`
in
> > >>>>#cannotReturn:to:` with your solution of the VM crash.
If you
>don't > > >>>>mind I've amended your solution and added the final
context
where
> > >>>>the computation couldn't return along with the pc: > > >>>> > > >>>>Context >> cannotReturn: result to: homeContext > > >>>> "The receiver tried to return result to homeContext
that
cannot
> > >>>>be returned from. > > >>>> Capture the return context/pc in a BlockCannotReturn.
Nil
the pc
> > >>>>to prevent repeat > > >>>> attempts and/or invalid continuation. Answer the result
of
> > >>>>raising the exception." > > >>>> > > >>>> | exception previousPc | > > >>>> exception := BlockCannotReturn new. > > >>>> previousPc := pc ifNotNil: [self previousPc]. "<-----
here's
a
> > >>>>fix ----" > > >>>> exception > > >>>> result: result; > > >>>> deadHome: homeContext; > > >>>> finalContext: self; "<----- here's the new state, if > > >>>>that's fine ----" > > >>>> pc: previousPc. > > >>>> pc := nil. > > >>>> ^exception signal > > >>>> > > >>>>Unfortunately, this is still not the end of the story:
there
are
> > >>>>situations where #runUntilErrorOrReturnFrom: places the
two
guard
> > >>>>contexts below the bottom context. And that is a problem
because
> > >>>>when the method tries to remove the two guard contexts
before
> > >>>>returning at the end it uses #stepToCalee to do the job
but
this
> > >>>>unforotunately was (ab)using the above bug in
#return:from: -
>I'll > > >>>>explain: #return:from: didn't check whether aSender
sender
was
>nil > > >>>>and as a result it allowed to simulate a return to a
"nil
>context" > > >>>>which was then (ab)used in the clean-up via #stepToCalee
in
the
> > >>>>#runUntilErrorOrReturnFrom:. > > >>>> > > >>>>When I fixed the #return:from: bug, the >#runUntilErrorOrReturnFrom: > > >>>>cleanup of the guard contexts no longer works in that
very
>special > > >>>>case where the guard contexts are below the bottom
context.
>There's > > >>>>one case where this is being used: #terminateAggresively
by
> > >>>>Christoph. > > >>>> > > >>>>If I'm right with this analysis, the
#runUntilErrorOrReturnFrom:
> > >>>>should get fixed too but I'll be away now for a few days
and
I
>won't > > >>>>be able to respond. If you or Christoph had a chance to
take
a
>look > > >>>>at Kernel-jar.1538 and Kernel-jar.1537 I'd be very
grateful.
I
>hope > > >>>>this super long message at least makes some sense :) > > >>>>Best, > > >>>>Jaromir > > >>>> > > >>>>[1] Kernel-jar.1538, Kernel-jar.1537 > > >>>>[2] KernelTests-jar.447 > > >>>> > > >>>> > > >>>>PS: Christoph, > > >>>> > > >>>>With Kernel-jar.1538 + Kernel-jar.1537 your example > > >>>> > > >>>>process := > > >>>> [(c := thisContext) pc: nil. > > >>>> 2+3] newProcess. > > >>>>process runUntil: [:ctx | ctx selector =
#cannotReturn:].
> > >>>>self assert: process suspendedContext sender sender = c. > > >>>>self assert: process suspendedContext arguments = {c}. > > >>>> > > >>>>works fine, I've just corrected your first assert. > > >>>> > > >>>> > > >>>> > > >>>> > > >>>> > > >>>>On 21-Nov-23 6:40:32 PM, "Eliot Miranda" ><eliot.miranda(a)gmail.com> > > >>>>wrote: > > >>>> > > >>>>>Hi Jaromir, > > >>>>> > > >>>>>>On Nov 20, 2023, at 11:51 PM, Jaromir Matas ><mail(a)jaromir.net> > > >>>>>>wrote: > > >>>>>> > > >>>>>> > > >>>>>>Hi Eliot, > > >>>>>>Very elegant! Now I finally got what you meant exactly
:)
>Thanks. > > >>>>>> > > >>>>>>Two questions: > > >>>>>>1. in order for the enclosed test to work I'd need an
Error
> > >>>>>>instead of Processor debugWithTitle:full: call in >#cannotReturn:. > > >>>>>>Otherwise I don't know how to catch a plain invocation
of
the
> > >>>>>>Debugger: > > >>>>>> > > >>>>>>cannotReturn: result > > >>>>>> > > >>>>>> closureOrNil ifNotNil: [^ self cannotReturn: result
to:
self
> > >>>>>>home sender]. > > >>>>>> self error: 'Computation has been terminated!' > > >>>>> > > >>>>>Much nicer. > > >>>>> > > >>>>>>2. We are capturing a pc of self which is completely
different
> > >>>>>>context from homeContext indeed. > > >>>>> > > >>>>>Right. The return is attempted from a specific return
bytecode
>in a > > >>>>>specific block. This is the coordinate of the return
that
cannot
>be > > >>>>>made. This is the relevant point of origin of the
cannot
return
> > >>>>>exception. > > >>>>> > > >>>>>Why the return fails is another matter: > > >>>>>- the home context’s sender is a dead context (cannot
be
>resumed) > > >>>>>- the home context’s sender is nil (home already
returned
from)
> > >>>>>- the block activation’s home is nil rather than a
context
>(should > > >>>>>not happen) > > >>>>> > > >>>>>But in all these cases the pc of the home context is
immaterial.
> > >>>>>The hike is being returned through/from, rather than
from;
the
> > >>>>>home’s pc is not relevant. > > >>>>> > > >>>>>>Maybe we could capture self in the exception too to
make it
>more > > >>>>>>clear/explicit what is going on: what context the
captured
pc
>is > > >>>>>>actually associated with. Just a thought... > > >>>>> > > >>>>>Yes, I like that. I also like the idea of somehow
passing
the
> > >>>>>block activation’s pc to the debugger so that the
relevant
>return > > >>>>>expression is highlighted in the debugger. > > >>>>> > > >>>>>> > > >>>>>>Thanks again, > > >>>>>>Jaromir > > >>>>> > > >>>>>You’re welcome. I love working in this part of the
system.
>Thanks > > >>>>>for dragging me there. I’m in a slump right now and
appreciate
>the > > >>>>>fellowship. > > >>>>> > > >>>>>>------ Original Message ------ > > >>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> > > >>>>>>To "Jaromir Matas" <mail(a)jaromir.net> > > >>>>>>Cc squeak-dev(a)lists.squeakfoundation.org > > >>>>>>Date 11/21/2023 2:17:21 AM > > >>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on >BlockCannotReturn > > >>>>>>exception > > >>>>>> > > >>>>>>>Hi Jaromir, > > >>>>>>> > > >>>>>>> see Kernel-eem.1535 for what I was suggesting. This
example
> > >>>>>>>now has an exception with the right pc value in it: > > >>>>>>> > > >>>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect.
ex
>resume]] > > >>>>>>>fork > > >>>>>>> > > >>>>>>>The fix is simply > > >>>>>>> > > >>>>>>>Context>>cannotReturn: result to: homeContext > > >>>>>>> "The receiver tried to return result to homeContext
that
> > >>>>>>>cannot be returned from. > > >>>>>>> Capture the return pc in a BlockCannotReturn. Nil
the pc
to
> > >>>>>>>prevent repeat > > >>>>>>> attempts and/or invalid continuation. Answer the
result
of
> > >>>>>>>raising the exception." > > >>>>>>> > > >>>>>>> | exception | > > >>>>>>> exception := BlockCannotReturn new. > > >>>>>>> exception > > >>>>>>> result: result; > > >>>>>>> deadHome: homeContext; > > >>>>>>> pc: self previousPc. > > >>>>>>> pc := nil. > > >>>>>>> ^exception signal > > >>>>>>> > > >>>>>>> > > >>>>>>>The VM crash is now avoided. The debugger displays
the
method,
> > >>>>>>>but does not highlight the offending pc, which is no
big
deal.
>A > > >>>>>>>suitable defaultHandler for B lockCannotReturn may be
able
to
>get > > >>>>>>>the debugger to highlight correctly on opening. Try
the
> > >>>>>>>following examples: > > >>>>>>> > > >>>>>>>[[^1] on: BlockCannotReturn do: #resume] fork. > > >>>>>>> > > >>>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect.
ex
>resume]] > > >>>>>>>fork > > >>>>>>> > > >>>>>>>[[^1] value] fork. > > >>>>>>> > > >>>>>>>They al; seem to behave perfectly acceptably to me.
Does
this
> > >>>>>>>fix work for you? > > >>>>>>> > > >>>>>>>On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas ><mail(a)jaromir.net> > > >>>>>>>wrote: > > >>>>>>>>Hi Eliot, > > >>>>>>>> > > >>>>>>>>How about to nil the pc just before making the
return:
> > >>>>>>>>``` > > >>>>>>>>Context >> #cannotReturn: result > > >>>>>>>> > > >>>>>>>> self push: self pc. "backup the pc for the sake of > > >>>>>>>>debugging" > > >>>>>>>> closureOrNil ifNotNil: [^self cannotReturn: result
to:
self
> > >>>>>>>>home sender; pc: nil]. > > >>>>>>>> Processor debugWithTitle: 'Computation has been
terminated!'
> > >>>>>>>>translated full: false > > >>>>>>>>``` > > >>>>>>>>The nilled pc should not even potentially interfere
with
the
> > >>>>>>>>#isDead now. > > >>>>>>>> > > >>>>>>>>I hope this is at least a step in the right
direction :)
> > >>>>>>>> > > >>>>>>>>However, there's still a problem when debugging the >resumption > > >>>>>>>>of #cannotReturn because the encoders expect a
reasonable
>index. > > >>>>>>>>I haven't figured out yet where to place a nil check
#step,
> > >>>>>>>>#stepToSendOrReturn... ? > > >>>>>>>> > > >>>>>>>>Thanks again, > > >>>>>>>>Jaromir > > >>>>>>>> > > >>>>>>>> > > >>>>>>>>------ Original Message ------ > > >>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> > > >>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> > > >>>>>>>>Date 11/17/2023 8:36:50 PM > > >>>>>>>>Subject Re: [squeak-dev] Re: Resuming on
BlockCannotReturn
> > >>>>>>>>exception > > >>>>>>>> > > >>>>>>>>>Hi Jaromir, > > >>>>>>>>> > > >>>>>>>>>>On Nov 17, 2023, at 7:05 AM, Jaromir Matas ><mail(a)jaromir.net> > > >>>>>>>>>>wrote: > > >>>>>>>>>> > > >>>>>>>>>> > > >>>>>>>>>>Eliot, hi again, > > >>>>>>>>>> > > >>>>>>>>>>Please disregard my previous comment about nilling
the
> > >>>>>>>>>>contexts that have returned. We are indeed talking
about
>the > > >>>>>>>>>>context directly under the #cannotReturn context
which
is
> > >>>>>>>>>>totally different from the home context in another
thread
> > >>>>>>>>>>that's gone. > > >>>>>>>>>> > > >>>>>>>>>>I may still be confused but would nilling the pc
of the
> > >>>>>>>>>>context directly under the cannotReturn context
help?
>Here's > > >>>>>>>>>>what I mean: > > >>>>>>>>>>``` > > >>>>>>>>>>Context >> #cannotReturn: result > > >>>>>>>>>> > > >>>>>>>>>> closureOrNil ifNotNil: [^self pc: nil;
cannotReturn:
> > >>>>>>>>>>result to: self home sender]. > > >>>>>>>>>> Processor debugWithTitle: 'Computation has been > > >>>>>>>>>>terminated!' translated full: false. > > >>>>>>>>>>``` > > >>>>>>>>>>Instead of crashing the VM invokes the debugger
with
the
> > >>>>>>>>>>'Computation has been terminated!' message. > > >>>>>>>>>> > > >>>>>>>>>>Does this make sense? > > >>>>>>>>> > > >>>>>>>>>Nearly. But it loses the information on what the pc
actually
> > >>>>>>>>>is, and that’s potentially vital information. So
IMO the
ox
> > >>>>>>>>>should only be nilled between the BlockCannotReturn >exception > > >>>>>>>>>being created and raised. > > >>>>>>>>> > > >>>>>>>>>[But if you try this don’t be surprised if it
causes a
few
> > >>>>>>>>>temporary problems. It looks to me that without a
little
> > >>>>>>>>>refactoring this could easily cause an infinite
recursion
> > >>>>>>>>>around the sending of isDead. I’m sure you’ll be
able to
fix
> > >>>>>>>>>the code to work correctly] > > >>>>>>>>> > > >>>>>>>>>>Thanks, > > >>>>>>>>>>Jaromir > > >>>>>>>>>> > > >>>>>>>>>> > > >>>>>>>>>>------ Original Message ------ > > >>>>>>>>>>From "Jaromir Matas" <mail(a)jaromir.net> > > >>>>>>>>>>To "Eliot Miranda" <eliot.miranda(a)gmail.com>;
"The
> > >>>>>>>>>>general-purpose Squeak developers list" > > >>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > > >>>>>>>>>>Date 11/17/2023 10:15:17 AM > > >>>>>>>>>>Subject [squeak-dev] Re: Resuming on
BlockCannotReturn
> > >>>>>>>>>>exception > > >>>>>>>>>> > > >>>>>>>>>>>Hi Eliot, > > >>>>>>>>>>> > > >>>>>>>>>>> > > >>>>>>>>>>> > > >>>>>>>>>>>------ Original Message ------ > > >>>>>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> > > >>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> > > >>>>>>>>>>>Cc "The general-purpose Squeak developers list" > > >>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > > >>>>>>>>>>>Date 11/16/2023 11:52:45 PM > > >>>>>>>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on > > >>>>>>>>>>>BlockCannotReturn exception > > >>>>>>>>>>> > > >>>>>>>>>>>>Hi Jaromir, > > >>>>>>>>>>>> > > >>>>>>>>>>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas > > >>>>>>>>>>>><mail(a)jaromir.net> wrote: > > >>>>>>>>>>>>>Hi Nicolas, Eliot, > > >>>>>>>>>>>>> > > >>>>>>>>>>>>>here's what I understand is happening (see the
enclosed
> > >>>>>>>>>>>>>screenshot): > > >>>>>>>>>>>>> > > >>>>>>>>>>>>>1) we fork a new process to evaluate [^1] > > >>>>>>>>>>>>>2) the new process evaluates [^1] which means >instruction > > >>>>>>>>>>>>>18 is being evaluated, hence pc points to
instruction 19
> > >>>>>>>>>>>>>now > > >>>>>>>>>>>>>3) however, the home context where ^1 should
return
to
>is > > >>>>>>>>>>>>>gone by this time (the process that executed
the
fork
>has > > >>>>>>>>>>>>>already returned - notice the two up arrows in
the
>debugger > > >>>>>>>>>>>>>screenshot) > > >>>>>>>>>>>>>4) the VM can't finish the instruction and
returns
>control > > >>>>>>>>>>>>>to the image via placing the #cannotReturn:
context
on
>top > > >>>>>>>>>>>>>of the [^1] context > > >>>>>>>>>>>>>5) #cannotReturn: evaluation results in
signalling
the
>BCR > > >>>>>>>>>>>>>exception which is then handled by the #resume
handler
> > >>>>>>>>>>>>> (in our debugged case the [:ex | self halt. ex
resume]
> > >>>>>>>>>>>>>handler) > > >>>>>>>>>>>>>6) ex resume is evaluated, however, this means >requesting > > >>>>>>>>>>>>>the VM to evaluate instruction 19 of the [^1]
context -
> > >>>>>>>>>>>>>which is past the last instruction of the
context
and
>the > > >>>>>>>>>>>>>crash ensues > > >>>>>>>>>>>>> > > >>>>>>>>>>>>>I wonder whether such situations could/should
be
>prevented > > >>>>>>>>>>>>>inside the VM or whether such an expectation is
wrong
>for > > >>>>>>>>>>>>>some reason. > > >>>>>>>>>>>> > > >>>>>>>>>>>>As Nicolas says, IMO this is best done at the
image
>level. > > >>>>>>>>>>>> > > >>>>>>>>>>>>It could be prevented in the VM, but at great
cost,
and
>only > > >>>>>>>>>>>>partially. The performance issue is that the
last
>bytecode > > >>>>>>>>>>>>in a method is not marked in any way, and that
to
>determine > > >>>>>>>>>>>>the last bytecode the bytecodes must be
symbolically
> > >>>>>>>>>>>>evaluated from the start of the method. See
implementors
>of > > >>>>>>>>>>>>endPC at the image level (which defer to the
method
>trailer) > > >>>>>>>>>>>>and implementors of endPCOf: in the VMMaker
code.
Doing
>this > > >>>>>>>>>>>>every time execution commences is prohibitively >expensive. > > >>>>>>>>>>>>The "only partially" issue is that following the
return
> > >>>>>>>>>>>>instruction may be other valid bytecodes, but
these
are
>not > > >>>>>>>>>>>>a continuation. > > >>>>>>>>>>>> > > >>>>>>>>>>>> > > >>>>>>>>>>>>Consider the following code in some block: > > >>>>>>>>>>>> [self expression ifTrue: > > >>>>>>>>>>>> [^1]. > > >>>>>>>>>>>> ^2 > > >>>>>>>>>>>> > > >>>>>>>>>>>>The bytecodes for this are > > >>>>>>>>>>>> pushReceiver > > >>>>>>>>>>>> send #expression > > >>>>>>>>>>>> jumpFalse L1 > > >>>>>>>>>>>> push 1 > > >>>>>>>>>>>> methodReturnTop > > >>>>>>>>>>>>L1 > > >>>>>>>>>>>> push 2 > > >>>>>>>>>>>> methodReturnTop > > >>>>>>>>>>>> > > >>>>>>>>>>>>Clearly if expression is true these should be
*no*
> > >>>>>>>>>>>>continuation in which ^2 is executed. > > >>>>>>>>>>> > > >>>>>>>>>>>Well, in that case there's a bug because the
computation
>in > > >>>>>>>>>>>the following example shouldn't continue past the
[^1]
>block > > >>>>>>>>>>>but it silently does: > > >>>>>>>>>>>`[[true ifTrue: [^ 1]] on: BlockCannotReturn do:
#resume ]
> > >>>>>>>>>>>fork` > > >>>>>>>>>>> > > >>>>>>>>>>>The bytecodes are > > >>>>>>>>>>> push true > > >>>>>>>>>>> jumpFalse L1 > > >>>>>>>>>>> push 1 > > >>>>>>>>>>> returnTop > > >>>>>>>>>>>L1 > > >>>>>>>>>>> push nil > > >>>>>>>>>>> blockReturn > > >>>>>>>>>>> > > >>>>>>>>>>> > > >>>>>>>>>>> > > >>>>>>>>>>>> > > >>>>>>>>>>>>So even if the VM did try and detect whether the
return
>was > > >>>>>>>>>>>>at the last block method, it would only work for
special
> > >>>>>>>>>>>>cases. > > >>>>>>>>>>>> > > >>>>>>>>>>>> > > >>>>>>>>>>>>It seems to me the issue is simply that the
context
that
> > >>>>>>>>>>>>cannot be returned from should be marked as dead
(see
> > >>>>>>>>>>>>Context>>isDead) by setting its pc to nil at
some
point,
> > >>>>>>>>>>>>presumably after copying the actual return pc
into
the
> > >>>>>>>>>>>>BlockCannotReturn exception, to avoid ever
trying to
>resume > > >>>>>>>>>>>>the context. > > >>>>>>>>>>> > > >>>>>>>>>>>Does this mean, in other words, that every
context
that
> > >>>>>>>>>>>returns should nil its pc to avoid being
"wrongly"
> > >>>>>>>>>>>reused/executed in the future, which concerns
primarily
>those > > >>>>>>>>>>>being referenced somewhere hence potentially
executable in
> > >>>>>>>>>>>the future, is that right? > > >>>>>>>>>>>Hypothetical question: would nilling the pc
during
returns
> > >>>>>>>>>>>"fix" the example? > > >>>>>>>>>>>Thanks a lot for helping me understand this. > > >>>>>>>>>>>Best, > > >>>>>>>>>>>Jaromir > > >>>>>>>>>>> > > >>>>>>>>>>> > > >>>>>>>>>>> > > >>>>>>>>>>>> > > >>>>>>>>>>>> > > >>>>>>>>>>>>> > > >>>>>>>>>>>>>Thanks, > > >>>>>>>>>>>>>Jaromir > > >>>>>>>>>>>>> > > >>>>>>>>>>>>><bdxuqalu.png> > > >>>>>>>>>>>>> > > >>>>>>>>>>>>>------ Original Message ------ > > >>>>>>>>>>>>>From "Eliot Miranda"
<eliot.miranda(a)gmail.com>
> > >>>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The >general-purpose > > >>>>>>>>>>>>>Squeak developers list" > > >>>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > > >>>>>>>>>>>>>Date 11/16/2023 6:48:43 PM > > >>>>>>>>>>>>>Subject Re: [squeak-dev] Re: Resuming on >BlockCannotReturn > > >>>>>>>>>>>>>exception > > >>>>>>>>>>>>> > > >>>>>>>>>>>>>>Hi Jaromir, > > >>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas > > >>>>>>>>>>>>>>><mail(a)jaromir.net> wrote: > > >>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>Hi Nicloas, > > >>>>>>>>>>>>>>>No no, I don't have any practical scenario in
mind,
>I'm > > >>>>>>>>>>>>>>>just trying to understand why the VM is
implemented
>like > > >>>>>>>>>>>>>>>this, whether there were a reason to leave
this
> > >>>>>>>>>>>>>>>possibility of a crash, e.g. it would slow
down
the VM
>to > > >>>>>>>>>>>>>>>try to prevent such a dumb situation (who
would
resume
> > >>>>>>>>>>>>>>>from BCR in his right mind? :) ) - or perhaps
I
have
> > >>>>>>>>>>>>>>>overlooked some good reason to even keep this
behavior
>in > > >>>>>>>>>>>>>>>the VM. That's all. > > >>>>>>>>>>>>>> > > >>>>>>>>>>>>>>Let’s first understand what’s really
happening.
>Presumably > > >>>>>>>>>>>>>>at tone point a context is resumed those pc is
already
>at > > >>>>>>>>>>>>>>the block return bytecode (effectively,
because it
>crashes > > >>>>>>>>>>>>>>in JITted code, but I bet the stack vm will
crash
also,
> > >>>>>>>>>>>>>>but not as cleanly - it will try and execute
the
bytes
>in > > >>>>>>>>>>>>>>the encoded method trailer). So which method
actually
> > >>>>>>>>>>>>>>sends resume, and to what, and what state is
resume’s
> > >>>>>>>>>>>>>>receiver when resume is sent? > > >>>>>>>>>>>>>> > > >>>>>>>>>>>>>> > > >>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>Thanks for your reply. > > >>>>>>>>>>>>>>>Regards, > > >>>>>>>>>>>>>>>Jaromir > > >>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>------ Original Message ------ > > >>>>>>>>>>>>>>>From "Nicolas Cellier" > > >>>>>>>>>>>>>>><nicolas.cellier.aka.nice(a)gmail.com> > > >>>>>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The > > >>>>>>>>>>>>>>>general-purpose Squeak developers list" > > >>>>>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > > >>>>>>>>>>>>>>>Date 11/16/2023 7:20:20 AM > > >>>>>>>>>>>>>>>Subject Re: [squeak-dev] Resuming on
BlockCannotReturn
> > >>>>>>>>>>>>>>>exception > > >>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>>Hi Jaromir, > > >>>>>>>>>>>>>>>>Is there a scenario where it would make
sense to
>resume > > >>>>>>>>>>>>>>>>a BlockCannotReturn? > > >>>>>>>>>>>>>>>>If not, I would suggest to protect at image
side
and
> > >>>>>>>>>>>>>>>>override #resume. > > >>>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas > > >>>>>>>>>>>>>>>><mail(a)jaromir.net> a écrit : > > >>>>>>>>>>>>>>>>>Hi Eliot, Christoph, All, > > >>>>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>>>It's known the following example crashes
the VM.
Is
> > >>>>>>>>>>>>>>>>>this an intended behavior or a "tolerated
bug"?
> > >>>>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume]
fork`
> > >>>>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>>>I understand why it crashes: the non-local
return
>has > > >>>>>>>>>>>>>>>>>nowhere to return to and so resuming the
computation
> > >>>>>>>>>>>>>>>>>leads to a crash. But why not raise another
BCR
> > >>>>>>>>>>>>>>>>>exception to prevent the crash? Potential
infinite
> > >>>>>>>>>>>>>>>>>loop? Perhaps I'm just missing the purpose
of
this
> > >>>>>>>>>>>>>>>>>behavior... > > >>>>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>>>Thanks for an explanation. > > >>>>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>>>Best, > > >>>>>>>>>>>>>>>>>Jaromir > > >>>>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>>>-- > > >>>>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>>>Jaromir Matas > > >>>>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>> > > >>>>>>>>>>>> > > >>>>>>>>>>>> > > >>>>>>>>>>>>-- > > >>>>>>>>>>>>_,,,^..^,,,_ > > >>>>>>>>>>>>best, Eliot > > >>>>>>>>>><Context-cannotReturn.st> > > >>>>>>> > > >>>>>>> > > >>>>>>>-- > > >>>>>>>_,,,^..^,,,_ > > >>>>>>>best, Eliot > > >>>>>><ProcessTest-testResumeAfterBCR.st>
Hi Christoph,
On 02-Jan-24 8:05:31 PM, christoph.thiede@student.hpi.uni-potsdam.de wrote:
Hi Jaromir,
thanks for the clarification. If you don't mind I would still wait for a couple of days to see whether Eliot or Marcel or someone else who are longer aboard find anything against your change, but I have been convinced by you. :-) After that, we can merge your open test and eliminate the ifNil checks in the TraceDebugger and also in the penultimate line of Context>>#return:from:.
In general, some methods are "pure simulation" methods intended to
mimic the VM behavior (#step etc) but nothing prevents one from using them for other purposes - like what #runUntilErrorOrReturnFrom: did: to just get rid of some contexts). Is it ok to do that? I tend to think it's not; it's confusing. That's why I made #stepToCalleeOrNil a private method because it's not a "true" simulation method but a sort of hybrid.
Yes, I think I understand your point here, the assumptions and use cases for #stepToCalleeOrNil are too special to expose it to everyone. Clients should mainly use #step, #stepToCallee, or maybe - with care - #runUntilErrorOrReturnFrom: to advance a context I think.
This is also why I checked Jakob's Git Browser and all tests seem
fine.
Wait, Squot is using code simulation?
I guess not, but as I noted, nothing prevents you from using simulation methods in the non-simulation code :) Plus, one might use simulation methods to prepare test scenarios... So I just ran the changes through Squot tests for good measure ;)
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2024-01-02T11:25:57+00:00, mail@jaromir.net wrote:
Hi Christoph,
correct me if I'm wrong: with the corrected #step semantics (the #return:from: fix) one should no longer need to do things like:
self step ifNil: [^ self]
because #step should always return a context, even if attempting to
step
to a nil context:
[] asContext step
In this case it correctly returns the #cannotReturn: context.
I've noticed these nil checks in Trace debugger's #doStepOver or #stepToHome.
I hope I haven't overlooked anything :)
Thanks for your thoughts, Jaromir
On 31-Dec-23 10:42:54 AM, "Jaromir Matas" <mail(a)jaromir.net> wrote:
Hi Christoph,
Yes, that's exactly what I was talking about - the #return:from: fix changes slightly (perhaps it's better to say corrects) the semantics
of
some stepping methods - #step and #stepToCallee, which allowed illegally stepping into a dead or nil context. They can no longer be used in the manner you showed. Another example was #runUntilErrorOrReturnFrom: - it used #stepToCallee this way so as a workaround I created the #stepToCalleeOrNil method and used in #runUntilErrorOrReturnFrom:
[ctxt isDead or: [topContext isNil]] whileFalse: [topContext := topContext stepToCalleeOrNil].
Theoretically there might be some external code (mis)using the incorrect stepping semantics. In Pharo's trunk they were mainly
tests
and #stepToHome but I haven't checked any external code. But all
their
tests are green with this change and I guess it's not widespread.
This is also why I checked Jakob's Git Browser and all tests seem
fine.
My opinion is to keep the correct simulation semantics and deal with potential consequences as/if they come. However I don't expect a
huge
impact as the change only affects border situations.
In general, some methods are "pure simulation" methods intended to mimic the VM behavior (#step etc) but nothing prevents one from
using
them for other purposes - like what #runUntilErrorOrReturnFrom: did:
to
just get rid of some contexts). Is it ok to do that? I tend to think it's not; it's confusing. That's why I made #stepToCalleeOrNil a private method because it's not a "true" simulation method but a
sort
of hybrid.
What do you think?
Thanks for reviewing the fix! Best, Jaromir
On 30-Dec-23 11:07:54 PM,
christoph.thiede(a)student.hpi.uni-potsdam.de
wrote:
Hi Jaromir,
I found a breaking change in the new behavior of Context>>#return:from: while using the TraceDebugger:
In the past we could say:
c:=[2+3]asContext. [c]whileNotNil:[c:=cstep].
With your change, the script runs forever because the last step
does
not answer nil as before but activates a new #cannotReturn:.
This behavior seems not be expected anywhere in the trunk (if my
first
search was complete), and you are right that the new behavior
aligns
closer to the VM behavior. Still, the old code seemed to explicitly intend this - see the "newTop ifNotNil:" at the bottom of the
method.
I wonder whether we should keep this. For me it is not a big deal;
I
can just change my script like this:
c:=[2+3]asContext. [csenderisNiland:[cwillReturn]]whileNotNil:[c:=cstep].
I just wonder whether this could a breaking or unintended change
for
anything else. For [^2] ensure: [] it would not be a big deal, we could just change the check in question to (aSenderisDeador:[newTopnotNiland:[newTopisDead]])ifTrue:. I am tending against restoring the old behavior, but I am unsure. What
is
your opinion on this?
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-12-30T21:13:37+00:00, mail(a)jaromir.net wrote:
nit: You mixed up the order of arguments for #assert:equals:
oops, sorry :) It happens to me all the time; I've never
actually
understood why the strange, almost Yodaesque, order... as if you
asked
in English:
"Make sure 18 is his age."
Thanks, Jaromir
On 30-Dec-23 9:13:56 PM,
christoph.thiede(a)student.hpi.uni-potsdam.de
wrote:
nit: You mixed up the order of arguments for #assert:equals:
(it is
assert: expected equals: actual) and could have used it in the
final
assert again, but that's clearly no reason to hold back a
useful
test.
;-) Merged, thanks! :-)
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-12-30T17:33:08+00:00, mail(a)jaromir.net wrote:
> Hi Christoph, > > Thanks for merging the fixes; I've just sent another test in > KernelTests-jar.448 to complement them. > > Please take a look and if ok I'd appreciate it if you could
merge it
as > well. > > Best regards and Happy New Year to you too! > Jaromir > > > On 30-Dec-23 6:15:25 PM, christoph.thiede(a)student.hpi.uni-potsdam.de > wrote: > > >Hi Jaromir, hi all, > > > >finally I have found the time to review these suggestions. > >Kernel-jar.1537, Kernel-jar.1538, and Kernel-jar.1539 look
excellent
to > >me as well. Clear, straightforward, useful. :-) I have
merged
them
into > >the trunk via Kernel-ct.1545. > > > >Regarding DebuggerTests>>test16HandleSimulationError, I
have
patched
it > >via ToolsTests-ct.125. Nothing to rack your brains over: "thisContext > >pc: nil" just mimicks any kind of unhandled error inside
the
simulator > >- since we now gently handle this via #cannotReturn:, I
just
replaced > >it with "thisContext pc: false". :-) Sorry for not
clarifying
that
> >earlier and letting you speculate. > > > >Thanks for your work, and I already wish you a happy new
year!
> > > >Best, > >Christoph > > > >--- > >Sent from Squeak Inbox Talk > >https://github.com/hpi-swa-lab/squeak-inbox-talk > > > >On 2023-11-29T13:31:09+00:00, mail(a)jaromir.net wrote: > > > > > Hi Marcel, > > > > > > > [myself] whether the patch would have been necessary
should the
> > > #return:from: had been fixed then > > > > > > Nonsense, I just mixed it up with another issue :) > > > > > > > > > On 29-Nov-23 1:51:21 PM, "Jaromir Matas"
<mail(a)jaromir.net>
wrote: > > > > > > >Thanks Marcel! This test somehow slipped my attention
:)
> > > > > > > >The test can no longer work as is. It takes advantage
of
the
> >erroneous > > > >behavior of #return:from: in the sense that if you
simulate
> > > > > > > > thisContext pc: nil > > > > > > > >it'll happily return to a dead context (i.e. to
thisContext
from
> >#pc: > > > >nil context) - which is not what the VM does during
runtime. It
> >should > > > >immediately raise an illegal return exception not only
during
> >runtime > > > >but also during simulation. > > > > > > > >The test mentions a patch for an infinite debugger
chain
> > >
(http://forum.world.st/I-broke-the-debugger-td5110752.html). I
> >wonder > > > >whether the problem could have something to do with
this
simulation > >bug > > > >in return:from:; and a terrible idea occurred to me
whether
the
> >patch > > > >would have been necessary should the #return:from: had
been
fixed > >then > > > >;O > > > > > > > >We may potentially come up with more examples like
this,
even in
the > > > >trunk, where the bug from #return:from: propagated and
was
taken
> > > >advantage of. I've found and fixed
#runUntilErrorOrReturnFrom:
but > >more > > > >can still be surviving undetected... > > > > > > > >I'd place the test into #expectedFailures for now but
maybe
it's
> >time > > > >to remove it; Christoph should decide :) > > > > > > > >Thanks again, > > > >Jaromir > > > > > > > > > > > >On 29-Nov-23 10:28:38 AM, "Taeumel, Marcel via
Squeak-dev"
> > > ><squeak-dev(a)lists.squeakfoundation.org> wrote: > > > > > > > >>Hi Jaromir -- > > > >> > > > >>Looks good. Still, what about that
#test16HandleSimulationError
> >now? > > > >>:-) It is failing with your changes ... how would you
adapt it?
> > > >> > > > >> > > > >> > > > >>Best, > > > >>Marcel > > > >>>Am 28.11.2023 01:29:39 schrieb Jaromir Matas <mail(a)jaromir.net>: > > > >>> > > > >>>Hi Eliot, Marcel, all, > > > >>> > > > >>>I've sent a fix Kernel-jar.1539 to the Inbox that
solves
the
> > > >>>remaining bit of the chain of bugs described in the
previous
post. > > > >>>All tests are green now and I think the root cause
has
been
found > >and > > > >>>fixed. > > > >>> > > > >>>In this last bit I've created a version of
stepToCallee
that
would > > > >>>identify a potential illegal return to a nil sender
and
avoid
it. > > > >>> > > > >>>Now this example can be debugged without any
problems:
> > > >>> > > > >>>[[self halt. ^ 1] on: BlockCannotReturn do: #resume ]
fork
> > > >>> > > > >>>If you're happy with the solution in Kernel-jar.1539, > > > >>>Kernel-jar.1538, Kernel-jar.1537 and the test in > >KernelTests-jar.447, > > > >>>could you please double-check and merge, please? (And
remove
> > > >>>Kernel-mt.1534 and Tools-jar.1240 from the Inbox) > > > >>> > > > >>>Best, > > > >>>Jaromir > > > >>> > > > >>> > > > >>> > > > >>>On 27-Nov-23 12:09:37 AM, "Jaromir Matas"
<mail(a)jaromir.net>
> >wrote: > > > >>> > > > >>>>Hi Eliot, Christoph, all > > > >>>> > > > >>>>It looks like there are some more skeletons in the
closet :/
> > > >>>> > > > >>>>If you run this example > > > >>>> > > > >>>>[[self halt. ^ 1] on: BlockCannotReturn do: [:ex |
ex
resume]
] > >fork > > > >>>> > > > >>>>and step over halt and then step over ^1 you get a nonsensical > >error > > > >>>>as a result of decoding nil as an instruction. > > > >>>> > > > >>>>It turns out that the root cause is in the
#return:from:
method: > >it > > > >>>>only checks whether aSender is dead but ignores the possibility > >that > > > >>>>aSender sender may be nil or dead in which cases the
VM
also
> > > >>>>responds with sending #cannotReturn, hence I assume
the
simulator > > > >>>>should do the same. In addition, the VM nills the pc
in
such
> > > >>>>scenario, so I added the same functionality here
too:
> > > >>>> > > > >>>>Context >> return: value from: aSender > > > >>>> "For simulation. Roll back self to aSender and
return
value
> > > >>>>from it. Execute any unwind blocks on the way.
ASSUMES
aSender is > > > >>>>a sender of self" > > > >>>> > > > >>>> | newTop | > > > >>>> newTop := aSender sender. > > > >>>> (aSender isDead or: [newTop isNil or: [newTop
isDead]])
ifTrue: > > > >>>> "<--------- this is extended ------" > > > >>>> [^self pc: nil; send: #cannotReturn: to: self with: > > > >>>>{value}]. "<------ pc: nil is added ----" > > > >>>> (self findNextUnwindContextUpTo: newTop) ifNotNil: > > > >>>> "Send #aboutToReturn:through: with nil as the
second
> > > >>>>argument to avoid this bug: > > > >>>> Cannot #stepOver '^2' in example '[^2] ensure: []'. > > > >>>> See > > > > >
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html
> > > > >
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html"
> > > >>>> [^self send: #aboutToReturn:through: to: self with:
{value.
> > > >>>>nil}]. > > > >>>> self releaseTo: newTop. > > > >>>> newTop ifNotNil: [newTop push: value]. > > > >>>> ^newTop > > > >>>> > > > >>>>In order for this to work #cannotReturn: has to be
modified
as in > > > >>>>Kernel-jar.1537: > > > >>>> > > > >>>>Context >> cannotReturn: result > > > >>>> > > > >>>> closureOrNil ifNotNil: [^ self cannotReturn: result
to:
self
> > > >>>>home sender]. > > > >>>> self error: 'Computation has been terminated!' > > > >>>>"<----------- this has to be an Error -----" > > > >>>> > > > >>>>Then it almost works except when you keep stepping
over
in
the > > > >>>>example above, you get an MNU error on `self
previousPc`
in
> > > >>>>#cannotReturn:to:` with your solution of the VM
crash.
If you
> >don't > > > >>>>mind I've amended your solution and added the final
context
where > > > >>>>the computation couldn't return along with the pc: > > > >>>> > > > >>>>Context >> cannotReturn: result to: homeContext > > > >>>> "The receiver tried to return result to homeContext
that
cannot > > > >>>>be returned from. > > > >>>> Capture the return context/pc in a
BlockCannotReturn.
Nil
the pc > > > >>>>to prevent repeat > > > >>>> attempts and/or invalid continuation. Answer the
result
of
> > > >>>>raising the exception." > > > >>>> > > > >>>> | exception previousPc | > > > >>>> exception := BlockCannotReturn new. > > > >>>> previousPc := pc ifNotNil: [self previousPc].
"<-----
here's
a > > > >>>>fix ----" > > > >>>> exception > > > >>>> result: result; > > > >>>> deadHome: homeContext; > > > >>>> finalContext: self; "<----- here's the new state,
if
> > > >>>>that's fine ----" > > > >>>> pc: previousPc. > > > >>>> pc := nil. > > > >>>> ^exception signal > > > >>>> > > > >>>>Unfortunately, this is still not the end of the
story:
there
are > > > >>>>situations where #runUntilErrorOrReturnFrom: places
the
two
guard > > > >>>>contexts below the bottom context. And that is a
problem
because > > > >>>>when the method tries to remove the two guard
contexts
before
> > > >>>>returning at the end it uses #stepToCalee to do the
job
but
this > > > >>>>unforotunately was (ab)using the above bug in
#return:from: -
> >I'll > > > >>>>explain: #return:from: didn't check whether aSender
sender
was > >nil > > > >>>>and as a result it allowed to simulate a return to a
"nil
> >context" > > > >>>>which was then (ab)used in the clean-up via
#stepToCalee
in
the > > > >>>>#runUntilErrorOrReturnFrom:. > > > >>>> > > > >>>>When I fixed the #return:from: bug, the > >#runUntilErrorOrReturnFrom: > > > >>>>cleanup of the guard contexts no longer works in
that
very
> >special > > > >>>>case where the guard contexts are below the bottom
context.
> >There's > > > >>>>one case where this is being used:
#terminateAggresively
by
> > > >>>>Christoph. > > > >>>> > > > >>>>If I'm right with this analysis, the #runUntilErrorOrReturnFrom: > > > >>>>should get fixed too but I'll be away now for a few
days
and
I > >won't > > > >>>>be able to respond. If you or Christoph had a chance
to
take
a > >look > > > >>>>at Kernel-jar.1538 and Kernel-jar.1537 I'd be very
grateful.
I > >hope > > > >>>>this super long message at least makes some sense :) > > > >>>>Best, > > > >>>>Jaromir > > > >>>> > > > >>>>[1] Kernel-jar.1538, Kernel-jar.1537 > > > >>>>[2] KernelTests-jar.447 > > > >>>> > > > >>>> > > > >>>>PS: Christoph, > > > >>>> > > > >>>>With Kernel-jar.1538 + Kernel-jar.1537 your example > > > >>>> > > > >>>>process := > > > >>>> [(c := thisContext) pc: nil. > > > >>>> 2+3] newProcess. > > > >>>>process runUntil: [:ctx | ctx selector =
#cannotReturn:].
> > > >>>>self assert: process suspendedContext sender sender
= c.
> > > >>>>self assert: process suspendedContext arguments =
{c}.
> > > >>>> > > > >>>>works fine, I've just corrected your first assert. > > > >>>> > > > >>>> > > > >>>> > > > >>>> > > > >>>> > > > >>>>On 21-Nov-23 6:40:32 PM, "Eliot Miranda" > ><eliot.miranda(a)gmail.com> > > > >>>>wrote: > > > >>>> > > > >>>>>Hi Jaromir, > > > >>>>> > > > >>>>>>On Nov 20, 2023, at 11:51 PM, Jaromir Matas > ><mail(a)jaromir.net> > > > >>>>>>wrote: > > > >>>>>> > > > >>>>>> > > > >>>>>>Hi Eliot, > > > >>>>>>Very elegant! Now I finally got what you meant
exactly
:)
> >Thanks. > > > >>>>>> > > > >>>>>>Two questions: > > > >>>>>>1. in order for the enclosed test to work I'd need
an
Error
> > > >>>>>>instead of Processor debugWithTitle:full: call in > >#cannotReturn:. > > > >>>>>>Otherwise I don't know how to catch a plain
invocation
of
the > > > >>>>>>Debugger: > > > >>>>>> > > > >>>>>>cannotReturn: result > > > >>>>>> > > > >>>>>> closureOrNil ifNotNil: [^ self cannotReturn:
result
to:
self > > > >>>>>>home sender]. > > > >>>>>> self error: 'Computation has been terminated!' > > > >>>>> > > > >>>>>Much nicer. > > > >>>>> > > > >>>>>>2. We are capturing a pc of self which is
completely
different > > > >>>>>>context from homeContext indeed. > > > >>>>> > > > >>>>>Right. The return is attempted from a specific
return
bytecode > >in a > > > >>>>>specific block. This is the coordinate of the
return
that
cannot > >be > > > >>>>>made. This is the relevant point of origin of the
cannot
return > > > >>>>>exception. > > > >>>>> > > > >>>>>Why the return fails is another matter: > > > >>>>>- the home context’s sender is a dead context
(cannot
be
> >resumed) > > > >>>>>- the home context’s sender is nil (home already
returned
from) > > > >>>>>- the block activation’s home is nil rather than a
context
> >(should > > > >>>>>not happen) > > > >>>>> > > > >>>>>But in all these cases the pc of the home context
is
immaterial. > > > >>>>>The hike is being returned through/from, rather
than
from;
the > > > >>>>>home’s pc is not relevant. > > > >>>>> > > > >>>>>>Maybe we could capture self in the exception too
to
make it
> >more > > > >>>>>>clear/explicit what is going on: what context the
captured
pc > >is > > > >>>>>>actually associated with. Just a thought... > > > >>>>> > > > >>>>>Yes, I like that. I also like the idea of somehow
passing
the > > > >>>>>block activation’s pc to the debugger so that the
relevant
> >return > > > >>>>>expression is highlighted in the debugger. > > > >>>>> > > > >>>>>> > > > >>>>>>Thanks again, > > > >>>>>>Jaromir > > > >>>>> > > > >>>>>You’re welcome. I love working in this part of the
system.
> >Thanks > > > >>>>>for dragging me there. I’m in a slump right now and appreciate > >the > > > >>>>>fellowship. > > > >>>>> > > > >>>>>>------ Original Message ------ > > > >>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> > > > >>>>>>To "Jaromir Matas" <mail(a)jaromir.net> > > > >>>>>>Cc squeak-dev(a)lists.squeakfoundation.org > > > >>>>>>Date 11/21/2023 2:17:21 AM > > > >>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on > >BlockCannotReturn > > > >>>>>>exception > > > >>>>>> > > > >>>>>>>Hi Jaromir, > > > >>>>>>> > > > >>>>>>> see Kernel-eem.1535 for what I was suggesting.
This
example > > > >>>>>>>now has an exception with the right pc value in
it:
> > > >>>>>>> > > > >>>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc
inspect.
ex
> >resume]] > > > >>>>>>>fork > > > >>>>>>> > > > >>>>>>>The fix is simply > > > >>>>>>> > > > >>>>>>>Context>>cannotReturn: result to: homeContext > > > >>>>>>> "The receiver tried to return result to
homeContext
that
> > > >>>>>>>cannot be returned from. > > > >>>>>>> Capture the return pc in a BlockCannotReturn.
Nil
the pc
to > > > >>>>>>>prevent repeat > > > >>>>>>> attempts and/or invalid continuation. Answer the
result
of > > > >>>>>>>raising the exception." > > > >>>>>>> > > > >>>>>>> | exception | > > > >>>>>>> exception := BlockCannotReturn new. > > > >>>>>>> exception > > > >>>>>>> result: result; > > > >>>>>>> deadHome: homeContext; > > > >>>>>>> pc: self previousPc. > > > >>>>>>> pc := nil. > > > >>>>>>> ^exception signal > > > >>>>>>> > > > >>>>>>> > > > >>>>>>>The VM crash is now avoided. The debugger
displays
the
method, > > > >>>>>>>but does not highlight the offending pc, which is
no
big
deal. > >A > > > >>>>>>>suitable defaultHandler for B lockCannotReturn
may be
able
to > >get > > > >>>>>>>the debugger to highlight correctly on opening.
Try
the
> > > >>>>>>>following examples: > > > >>>>>>> > > > >>>>>>>[[^1] on: BlockCannotReturn do: #resume] fork. > > > >>>>>>> > > > >>>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc
inspect.
ex
> >resume]] > > > >>>>>>>fork > > > >>>>>>> > > > >>>>>>>[[^1] value] fork. > > > >>>>>>> > > > >>>>>>>They al; seem to behave perfectly acceptably to
me.
Does
this > > > >>>>>>>fix work for you? > > > >>>>>>> > > > >>>>>>>On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas > ><mail(a)jaromir.net> > > > >>>>>>>wrote: > > > >>>>>>>>Hi Eliot, > > > >>>>>>>> > > > >>>>>>>>How about to nil the pc just before making the
return:
> > > >>>>>>>>``` > > > >>>>>>>>Context >> #cannotReturn: result > > > >>>>>>>> > > > >>>>>>>> self push: self pc. "backup the pc for the sake
of
> > > >>>>>>>>debugging" > > > >>>>>>>> closureOrNil ifNotNil: [^self cannotReturn:
result
to:
self > > > >>>>>>>>home sender; pc: nil]. > > > >>>>>>>> Processor debugWithTitle: 'Computation has been terminated!' > > > >>>>>>>>translated full: false > > > >>>>>>>>``` > > > >>>>>>>>The nilled pc should not even potentially
interfere
with
the > > > >>>>>>>>#isDead now. > > > >>>>>>>> > > > >>>>>>>>I hope this is at least a step in the right
direction :)
> > > >>>>>>>> > > > >>>>>>>>However, there's still a problem when debugging
the
> >resumption > > > >>>>>>>>of #cannotReturn because the encoders expect a
reasonable
> >index. > > > >>>>>>>>I haven't figured out yet where to place a nil
check
#step, > > > >>>>>>>>#stepToSendOrReturn... ? > > > >>>>>>>> > > > >>>>>>>>Thanks again, > > > >>>>>>>>Jaromir > > > >>>>>>>> > > > >>>>>>>> > > > >>>>>>>>------ Original Message ------ > > > >>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> > > > >>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> > > > >>>>>>>>Date 11/17/2023 8:36:50 PM > > > >>>>>>>>Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn > > > >>>>>>>>exception > > > >>>>>>>> > > > >>>>>>>>>Hi Jaromir, > > > >>>>>>>>> > > > >>>>>>>>>>On Nov 17, 2023, at 7:05 AM, Jaromir Matas > ><mail(a)jaromir.net> > > > >>>>>>>>>>wrote: > > > >>>>>>>>>> > > > >>>>>>>>>> > > > >>>>>>>>>>Eliot, hi again, > > > >>>>>>>>>> > > > >>>>>>>>>>Please disregard my previous comment about
nilling
the
> > > >>>>>>>>>>contexts that have returned. We are indeed
talking
about > >the > > > >>>>>>>>>>context directly under the #cannotReturn
context
which
is > > > >>>>>>>>>>totally different from the home context in
another
thread > > > >>>>>>>>>>that's gone. > > > >>>>>>>>>> > > > >>>>>>>>>>I may still be confused but would nilling the
pc
of the
> > > >>>>>>>>>>context directly under the cannotReturn
context
help?
> >Here's > > > >>>>>>>>>>what I mean: > > > >>>>>>>>>>``` > > > >>>>>>>>>>Context >> #cannotReturn: result > > > >>>>>>>>>> > > > >>>>>>>>>> closureOrNil ifNotNil: [^self pc: nil;
cannotReturn:
> > > >>>>>>>>>>result to: self home sender]. > > > >>>>>>>>>> Processor debugWithTitle: 'Computation has
been
> > > >>>>>>>>>>terminated!' translated full: false. > > > >>>>>>>>>>``` > > > >>>>>>>>>>Instead of crashing the VM invokes the
debugger
with
the > > > >>>>>>>>>>'Computation has been terminated!' message. > > > >>>>>>>>>> > > > >>>>>>>>>>Does this make sense? > > > >>>>>>>>> > > > >>>>>>>>>Nearly. But it loses the information on what
the pc
actually > > > >>>>>>>>>is, and that’s potentially vital information.
So
IMO the
ox > > > >>>>>>>>>should only be nilled between the
BlockCannotReturn
> >exception > > > >>>>>>>>>being created and raised. > > > >>>>>>>>> > > > >>>>>>>>>[But if you try this don’t be surprised if it
causes a
few > > > >>>>>>>>>temporary problems. It looks to me that without
a
little
> > > >>>>>>>>>refactoring this could easily cause an infinite recursion > > > >>>>>>>>>around the sending of isDead. I’m sure you’ll
be
able to
fix > > > >>>>>>>>>the code to work correctly] > > > >>>>>>>>> > > > >>>>>>>>>>Thanks, > > > >>>>>>>>>>Jaromir > > > >>>>>>>>>> > > > >>>>>>>>>> > > > >>>>>>>>>>------ Original Message ------ > > > >>>>>>>>>>From "Jaromir Matas" <mail(a)jaromir.net> > > > >>>>>>>>>>To "Eliot Miranda"
<eliot.miranda(a)gmail.com>;
"The
> > > >>>>>>>>>>general-purpose Squeak developers list" > > > >>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > > > >>>>>>>>>>Date 11/17/2023 10:15:17 AM > > > >>>>>>>>>>Subject [squeak-dev] Re: Resuming on
BlockCannotReturn
> > > >>>>>>>>>>exception > > > >>>>>>>>>> > > > >>>>>>>>>>>Hi Eliot, > > > >>>>>>>>>>> > > > >>>>>>>>>>> > > > >>>>>>>>>>> > > > >>>>>>>>>>>------ Original Message ------ > > > >>>>>>>>>>>From "Eliot Miranda"
<eliot.miranda(a)gmail.com>
> > > >>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> > > > >>>>>>>>>>>Cc "The general-purpose Squeak developers
list"
> > > >>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > > > >>>>>>>>>>>Date 11/16/2023 11:52:45 PM > > > >>>>>>>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming
on
> > > >>>>>>>>>>>BlockCannotReturn exception > > > >>>>>>>>>>> > > > >>>>>>>>>>>>Hi Jaromir, > > > >>>>>>>>>>>> > > > >>>>>>>>>>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir
Matas
> > > >>>>>>>>>>>><mail(a)jaromir.net> wrote: > > > >>>>>>>>>>>>>Hi Nicolas, Eliot, > > > >>>>>>>>>>>>> > > > >>>>>>>>>>>>>here's what I understand is happening (see
the
enclosed > > > >>>>>>>>>>>>>screenshot): > > > >>>>>>>>>>>>> > > > >>>>>>>>>>>>>1) we fork a new process to evaluate [^1] > > > >>>>>>>>>>>>>2) the new process evaluates [^1] which
means
> >instruction > > > >>>>>>>>>>>>>18 is being evaluated, hence pc points to instruction 19 > > > >>>>>>>>>>>>>now > > > >>>>>>>>>>>>>3) however, the home context where ^1
should
return
to > >is > > > >>>>>>>>>>>>>gone by this time (the process that
executed
the
fork > >has > > > >>>>>>>>>>>>>already returned - notice the two up arrows
in
the
> >debugger > > > >>>>>>>>>>>>>screenshot) > > > >>>>>>>>>>>>>4) the VM can't finish the instruction and
returns
> >control > > > >>>>>>>>>>>>>to the image via placing the #cannotReturn:
context
on > >top > > > >>>>>>>>>>>>>of the [^1] context > > > >>>>>>>>>>>>>5) #cannotReturn: evaluation results in
signalling
the > >BCR > > > >>>>>>>>>>>>>exception which is then handled by the
#resume
handler > > > >>>>>>>>>>>>> (in our debugged case the [:ex | self
halt. ex
resume] > > > >>>>>>>>>>>>>handler) > > > >>>>>>>>>>>>>6) ex resume is evaluated, however, this
means
> >requesting > > > >>>>>>>>>>>>>the VM to evaluate instruction 19 of the
[^1]
context - > > > >>>>>>>>>>>>>which is past the last instruction of the
context
and > >the > > > >>>>>>>>>>>>>crash ensues > > > >>>>>>>>>>>>> > > > >>>>>>>>>>>>>I wonder whether such situations
could/should
be
> >prevented > > > >>>>>>>>>>>>>inside the VM or whether such an
expectation is
wrong > >for > > > >>>>>>>>>>>>>some reason. > > > >>>>>>>>>>>> > > > >>>>>>>>>>>>As Nicolas says, IMO this is best done at
the
image
> >level. > > > >>>>>>>>>>>> > > > >>>>>>>>>>>>It could be prevented in the VM, but at
great
cost,
and > >only > > > >>>>>>>>>>>>partially. The performance issue is that the
last
> >bytecode > > > >>>>>>>>>>>>in a method is not marked in any way, and
that
to
> >determine > > > >>>>>>>>>>>>the last bytecode the bytecodes must be
symbolically
> > > >>>>>>>>>>>>evaluated from the start of the method. See implementors > >of > > > >>>>>>>>>>>>endPC at the image level (which defer to the
method
> >trailer) > > > >>>>>>>>>>>>and implementors of endPCOf: in the VMMaker
code.
Doing > >this > > > >>>>>>>>>>>>every time execution commences is
prohibitively
> >expensive. > > > >>>>>>>>>>>>The "only partially" issue is that following
the
return > > > >>>>>>>>>>>>instruction may be other valid bytecodes,
but
these
are > >not > > > >>>>>>>>>>>>a continuation. > > > >>>>>>>>>>>> > > > >>>>>>>>>>>> > > > >>>>>>>>>>>>Consider the following code in some block: > > > >>>>>>>>>>>> [self expression ifTrue: > > > >>>>>>>>>>>> [^1]. > > > >>>>>>>>>>>> ^2 > > > >>>>>>>>>>>> > > > >>>>>>>>>>>>The bytecodes for this are > > > >>>>>>>>>>>> pushReceiver > > > >>>>>>>>>>>> send #expression > > > >>>>>>>>>>>> jumpFalse L1 > > > >>>>>>>>>>>> push 1 > > > >>>>>>>>>>>> methodReturnTop > > > >>>>>>>>>>>>L1 > > > >>>>>>>>>>>> push 2 > > > >>>>>>>>>>>> methodReturnTop > > > >>>>>>>>>>>> > > > >>>>>>>>>>>>Clearly if expression is true these should
be
*no*
> > > >>>>>>>>>>>>continuation in which ^2 is executed. > > > >>>>>>>>>>> > > > >>>>>>>>>>>Well, in that case there's a bug because the computation > >in > > > >>>>>>>>>>>the following example shouldn't continue past
the
[^1]
> >block > > > >>>>>>>>>>>but it silently does: > > > >>>>>>>>>>>`[[true ifTrue: [^ 1]] on: BlockCannotReturn
do:
#resume ] > > > >>>>>>>>>>>fork` > > > >>>>>>>>>>> > > > >>>>>>>>>>>The bytecodes are > > > >>>>>>>>>>> push true > > > >>>>>>>>>>> jumpFalse L1 > > > >>>>>>>>>>> push 1 > > > >>>>>>>>>>> returnTop > > > >>>>>>>>>>>L1 > > > >>>>>>>>>>> push nil > > > >>>>>>>>>>> blockReturn > > > >>>>>>>>>>> > > > >>>>>>>>>>> > > > >>>>>>>>>>> > > > >>>>>>>>>>>> > > > >>>>>>>>>>>>So even if the VM did try and detect whether
the
return > >was > > > >>>>>>>>>>>>at the last block method, it would only work
for
special > > > >>>>>>>>>>>>cases. > > > >>>>>>>>>>>> > > > >>>>>>>>>>>> > > > >>>>>>>>>>>>It seems to me the issue is simply that the
context
that > > > >>>>>>>>>>>>cannot be returned from should be marked as
dead
(see
> > > >>>>>>>>>>>>Context>>isDead) by setting its pc to nil at
some
point, > > > >>>>>>>>>>>>presumably after copying the actual return
pc
into
the > > > >>>>>>>>>>>>BlockCannotReturn exception, to avoid ever
trying to
> >resume > > > >>>>>>>>>>>>the context. > > > >>>>>>>>>>> > > > >>>>>>>>>>>Does this mean, in other words, that every
context
that > > > >>>>>>>>>>>returns should nil its pc to avoid being
"wrongly"
> > > >>>>>>>>>>>reused/executed in the future, which concerns primarily > >those > > > >>>>>>>>>>>being referenced somewhere hence potentially executable in > > > >>>>>>>>>>>the future, is that right? > > > >>>>>>>>>>>Hypothetical question: would nilling the pc
during
returns > > > >>>>>>>>>>>"fix" the example? > > > >>>>>>>>>>>Thanks a lot for helping me understand this. > > > >>>>>>>>>>>Best, > > > >>>>>>>>>>>Jaromir > > > >>>>>>>>>>> > > > >>>>>>>>>>> > > > >>>>>>>>>>> > > > >>>>>>>>>>>> > > > >>>>>>>>>>>> > > > >>>>>>>>>>>>> > > > >>>>>>>>>>>>>Thanks, > > > >>>>>>>>>>>>>Jaromir > > > >>>>>>>>>>>>> > > > >>>>>>>>>>>>><bdxuqalu.png> > > > >>>>>>>>>>>>> > > > >>>>>>>>>>>>>------ Original Message ------ > > > >>>>>>>>>>>>>From "Eliot Miranda"
<eliot.miranda(a)gmail.com>
> > > >>>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>;
"The
> >general-purpose > > > >>>>>>>>>>>>>Squeak developers list" > > > >>>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > > > >>>>>>>>>>>>>Date 11/16/2023 6:48:43 PM > > > >>>>>>>>>>>>>Subject Re: [squeak-dev] Re: Resuming on > >BlockCannotReturn > > > >>>>>>>>>>>>>exception > > > >>>>>>>>>>>>> > > > >>>>>>>>>>>>>>Hi Jaromir, > > > >>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir
Matas
> > > >>>>>>>>>>>>>>><mail(a)jaromir.net> wrote: > > > >>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>>Hi Nicloas, > > > >>>>>>>>>>>>>>>No no, I don't have any practical
scenario in
mind, > >I'm > > > >>>>>>>>>>>>>>>just trying to understand why the VM is implemented > >like > > > >>>>>>>>>>>>>>>this, whether there were a reason to
leave
this
> > > >>>>>>>>>>>>>>>possibility of a crash, e.g. it would
slow
down
the VM > >to > > > >>>>>>>>>>>>>>>try to prevent such a dumb situation (who
would
resume > > > >>>>>>>>>>>>>>>from BCR in his right mind? :) ) - or
perhaps
I
have > > > >>>>>>>>>>>>>>>overlooked some good reason to even keep
this
behavior > >in > > > >>>>>>>>>>>>>>>the VM. That's all. > > > >>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>Let’s first understand what’s really
happening.
> >Presumably > > > >>>>>>>>>>>>>>at tone point a context is resumed those
pc is
already > >at > > > >>>>>>>>>>>>>>the block return bytecode (effectively,
because it
> >crashes > > > >>>>>>>>>>>>>>in JITted code, but I bet the stack vm
will
crash
also, > > > >>>>>>>>>>>>>>but not as cleanly - it will try and
execute
the
bytes > >in > > > >>>>>>>>>>>>>>the encoded method trailer). So which
method
actually > > > >>>>>>>>>>>>>>sends resume, and to what, and what state
is
resume’s > > > >>>>>>>>>>>>>>receiver when resume is sent? > > > >>>>>>>>>>>>>> > > > >>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>>Thanks for your reply. > > > >>>>>>>>>>>>>>>Regards, > > > >>>>>>>>>>>>>>>Jaromir > > > >>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>>------ Original Message ------ > > > >>>>>>>>>>>>>>>From "Nicolas Cellier" > > > >>>>>>>>>>>>>>><nicolas.cellier.aka.nice(a)gmail.com> > > > >>>>>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>;
"The
> > > >>>>>>>>>>>>>>>general-purpose Squeak developers list" > > > >>>>>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > > > >>>>>>>>>>>>>>>Date 11/16/2023 7:20:20 AM > > > >>>>>>>>>>>>>>>Subject Re: [squeak-dev] Resuming on BlockCannotReturn > > > >>>>>>>>>>>>>>>exception > > > >>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>>>Hi Jaromir, > > > >>>>>>>>>>>>>>>>Is there a scenario where it would make
sense to
> >resume > > > >>>>>>>>>>>>>>>>a BlockCannotReturn? > > > >>>>>>>>>>>>>>>>If not, I would suggest to protect at
image
side
and > > > >>>>>>>>>>>>>>>>override #resume. > > > >>>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir
Matas
> > > >>>>>>>>>>>>>>>><mail(a)jaromir.net> a écrit : > > > >>>>>>>>>>>>>>>>>Hi Eliot, Christoph, All, > > > >>>>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>>>>It's known the following example
crashes
the VM.
Is > > > >>>>>>>>>>>>>>>>>this an intended behavior or a
"tolerated
bug"?
> > > >>>>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>>>>`[[^ 1] on: BlockCannotReturn do:
#resume]
fork`
> > > >>>>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>>>>I understand why it crashes: the
non-local
return > >has > > > >>>>>>>>>>>>>>>>>nowhere to return to and so resuming
the
computation > > > >>>>>>>>>>>>>>>>>leads to a crash. But why not raise
another
BCR
> > > >>>>>>>>>>>>>>>>>exception to prevent the crash?
Potential
infinite > > > >>>>>>>>>>>>>>>>>loop? Perhaps I'm just missing the
purpose
of
this > > > >>>>>>>>>>>>>>>>>behavior... > > > >>>>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>>>>Thanks for an explanation. > > > >>>>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>>>>Best, > > > >>>>>>>>>>>>>>>>>Jaromir > > > >>>>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>>>>-- > > > >>>>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>>>>Jaromir Matas > > > >>>>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>> > > > >>>>>>>>>>>> > > > >>>>>>>>>>>> > > > >>>>>>>>>>>>-- > > > >>>>>>>>>>>>_,,,^..^,,,_ > > > >>>>>>>>>>>>best, Eliot > > > >>>>>>>>>><Context-cannotReturn.st> > > > >>>>>>> > > > >>>>>>> > > > >>>>>>>-- > > > >>>>>>>_,,,^..^,,,_ > > > >>>>>>>best, Eliot > > > >>>>>><ProcessTest-testResumeAfterBCR.st>
Hi Jaromir,
On 2024-01-03T22:36:17+00:00, mail@jaromir.net wrote:
Hi Christoph,
On 02-Jan-24 8:05:31 PM, christoph.thiede(a)student.hpi.uni-potsdam.de wrote:
Hi Jaromir,
thanks for the clarification. If you don't mind I would still wait for a couple of days to see whether Eliot or Marcel or someone else who are longer aboard find anything against your change, but I have been convinced by you. :-) After that, we can merge your open test and eliminate the ifNil checks in the TraceDebugger and also in the penultimate line of Context>>#return:from:.
In general, some methods are "pure simulation" methods intended to
mimic the VM behavior (#step etc) but nothing prevents one from using them for other purposes - like what #runUntilErrorOrReturnFrom: did: to just get rid of some contexts). Is it ok to do that? I tend to think it's not; it's confusing. That's why I made #stepToCalleeOrNil a private method because it's not a "true" simulation method but a sort of hybrid.
Yes, I think I understand your point here, the assumptions and use cases for #stepToCalleeOrNil are too special to expose it to everyone. Clients should mainly use #step, #stepToCallee, or maybe - with care - #runUntilErrorOrReturnFrom: to advance a context I think.
This is also why I checked Jakob's Git Browser and all tests seem
fine.
Wait, Squot is using code simulation?
I guess not, but as I noted, nothing prevents you from using simulation methods in the non-simulation code :) Plus, one might use simulation methods to prepare test scenarios... So I just ran the changes through Squot tests for good measure ;)
I still don't understand. :-) You ran the Squot test on the off chance that something in Squot or the Squot test uses code simulation? Or did you run the Squot tests inside the simulator? :D
Best, Christoph
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2024-01-02T11:25:57+00:00, mail(a)jaromir.net wrote:
Hi Christoph,
correct me if I'm wrong: with the corrected #step semantics (the #return:from: fix) one should no longer need to do things like:
self step ifNil: [^ self]
because #step should always return a context, even if attempting to
step
to a nil context:
[] asContext step
In this case it correctly returns the #cannotReturn: context.
I've noticed these nil checks in Trace debugger's #doStepOver or #stepToHome.
I hope I haven't overlooked anything :)
Thanks for your thoughts, Jaromir
On 31-Dec-23 10:42:54 AM, "Jaromir Matas" <mail(a)jaromir.net> wrote:
Hi Christoph,
Yes, that's exactly what I was talking about - the #return:from: fix changes slightly (perhaps it's better to say corrects) the semantics
of
some stepping methods - #step and #stepToCallee, which allowed illegally stepping into a dead or nil context. They can no longer be used in the manner you showed. Another example was #runUntilErrorOrReturnFrom: - it used #stepToCallee this way so as a workaround I created the #stepToCalleeOrNil method and used in #runUntilErrorOrReturnFrom:
[ctxt isDead or: [topContext isNil]] whileFalse: [topContext := topContext stepToCalleeOrNil].
Theoretically there might be some external code (mis)using the incorrect stepping semantics. In Pharo's trunk they were mainly
tests
and #stepToHome but I haven't checked any external code. But all
their
tests are green with this change and I guess it's not widespread.
This is also why I checked Jakob's Git Browser and all tests seem
fine.
My opinion is to keep the correct simulation semantics and deal with potential consequences as/if they come. However I don't expect a
huge
impact as the change only affects border situations.
In general, some methods are "pure simulation" methods intended to mimic the VM behavior (#step etc) but nothing prevents one from
using
them for other purposes - like what #runUntilErrorOrReturnFrom: did:
to
just get rid of some contexts). Is it ok to do that? I tend to think it's not; it's confusing. That's why I made #stepToCalleeOrNil a private method because it's not a "true" simulation method but a
sort
of hybrid.
What do you think?
Thanks for reviewing the fix! Best, Jaromir
On 30-Dec-23 11:07:54 PM,
christoph.thiede(a)student.hpi.uni-potsdam.de
wrote:
Hi Jaromir,
I found a breaking change in the new behavior of Context>>#return:from: while using the TraceDebugger:
In the past we could say:
c:=[2+3]asContext. [c]whileNotNil:[c:=cstep].
With your change, the script runs forever because the last step
does
not answer nil as before but activates a new #cannotReturn:.
This behavior seems not be expected anywhere in the trunk (if my
first
search was complete), and you are right that the new behavior
aligns
closer to the VM behavior. Still, the old code seemed to explicitly intend this - see the "newTop ifNotNil:" at the bottom of the
method.
I wonder whether we should keep this. For me it is not a big deal;
I
can just change my script like this:
c:=[2+3]asContext. [csenderisNiland:[cwillReturn]]whileNotNil:[c:=cstep].
I just wonder whether this could a breaking or unintended change
for
anything else. For [^2] ensure: [] it would not be a big deal, we could just change the check in question to (aSenderisDeador:[newTopnotNiland:[newTopisDead]])ifTrue:. I am tending against restoring the old behavior, but I am unsure. What
is
your opinion on this?
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-12-30T21:13:37+00:00, mail(a)jaromir.net wrote:
> nit: You mixed up the order of arguments for #assert:equals:
oops, sorry :) It happens to me all the time; I've never
actually
understood why the strange, almost Yodaesque, order... as if you
asked
in English:
"Make sure 18 is his age."
Thanks, Jaromir
On 30-Dec-23 9:13:56 PM,
christoph.thiede(a)student.hpi.uni-potsdam.de
wrote:
>nit: You mixed up the order of arguments for #assert:equals:
(it is
>assert: expected equals: actual) and could have used it in the
final
>assert again, but that's clearly no reason to hold back a
useful
test.
>;-) Merged, thanks! :-) > >Best, >Christoph > >--- >Sent from Squeak Inbox Talk >https://github.com/hpi-swa-lab/squeak-inbox-talk > >On 2023-12-30T17:33:08+00:00, mail(a)jaromir.net wrote: > > > Hi Christoph, > > > > Thanks for merging the fixes; I've just sent another test in > > KernelTests-jar.448 to complement them. > > > > Please take a look and if ok I'd appreciate it if you could
merge it
>as > > well. > > > > Best regards and Happy New Year to you too! > > Jaromir > > > > > > On 30-Dec-23 6:15:25 PM, >christoph.thiede(a)student.hpi.uni-potsdam.de > > wrote: > > > > >Hi Jaromir, hi all, > > > > > >finally I have found the time to review these suggestions. > > >Kernel-jar.1537, Kernel-jar.1538, and Kernel-jar.1539 look
excellent
>to > > >me as well. Clear, straightforward, useful. :-) I have
merged
them
>into > > >the trunk via Kernel-ct.1545. > > > > > >Regarding DebuggerTests>>test16HandleSimulationError, I
have
patched
>it > > >via ToolsTests-ct.125. Nothing to rack your brains over: >"thisContext > > >pc: nil" just mimicks any kind of unhandled error inside
the
>simulator > > >- since we now gently handle this via #cannotReturn:, I
just
>replaced > > >it with "thisContext pc: false". :-) Sorry for not
clarifying
that
> > >earlier and letting you speculate. > > > > > >Thanks for your work, and I already wish you a happy new
year!
> > > > > >Best, > > >Christoph > > > > > >--- > > >Sent from Squeak Inbox Talk > > >https://github.com/hpi-swa-lab/squeak-inbox-talk > > > > > >On 2023-11-29T13:31:09+00:00, mail(a)jaromir.net wrote: > > > > > > > Hi Marcel, > > > > > > > > > [myself] whether the patch would have been necessary
should the
> > > > #return:from: had been fixed then > > > > > > > > Nonsense, I just mixed it up with another issue :) > > > > > > > > > > > > On 29-Nov-23 1:51:21 PM, "Jaromir Matas"
<mail(a)jaromir.net>
>wrote: > > > > > > > > >Thanks Marcel! This test somehow slipped my attention
:)
> > > > > > > > > >The test can no longer work as is. It takes advantage
of
the
> > >erroneous > > > > >behavior of #return:from: in the sense that if you
simulate
> > > > > > > > > > thisContext pc: nil > > > > > > > > > >it'll happily return to a dead context (i.e. to
thisContext
from
> > >#pc: > > > > >nil context) - which is not what the VM does during
runtime. It
> > >should > > > > >immediately raise an illegal return exception not only
during
> > >runtime > > > > >but also during simulation. > > > > > > > > > >The test mentions a patch for an infinite debugger
chain
> > > > (http://forum.world.st/I-broke-the-debugger-td5110752.html). I > > >wonder > > > > >whether the problem could have something to do with
this
>simulation > > >bug > > > > >in return:from:; and a terrible idea occurred to me
whether
the
> > >patch > > > > >would have been necessary should the #return:from: had
been
>fixed > > >then > > > > >;O > > > > > > > > > >We may potentially come up with more examples like
this,
even in
>the > > > > >trunk, where the bug from #return:from: propagated and
was
taken
> > > > >advantage of. I've found and fixed
#runUntilErrorOrReturnFrom:
>but > > >more > > > > >can still be surviving undetected... > > > > > > > > > >I'd place the test into #expectedFailures for now but
maybe
it's
> > >time > > > > >to remove it; Christoph should decide :) > > > > > > > > > >Thanks again, > > > > >Jaromir > > > > > > > > > > > > > > >On 29-Nov-23 10:28:38 AM, "Taeumel, Marcel via
Squeak-dev"
> > > > ><squeak-dev(a)lists.squeakfoundation.org> wrote: > > > > > > > > > >>Hi Jaromir -- > > > > >> > > > > >>Looks good. Still, what about that
#test16HandleSimulationError
> > >now? > > > > >>:-) It is failing with your changes ... how would you
adapt it?
> > > > >> > > > > >> > > > > >> > > > > >>Best, > > > > >>Marcel > > > > >>>Am 28.11.2023 01:29:39 schrieb Jaromir Matas ><mail(a)jaromir.net>: > > > > >>> > > > > >>>Hi Eliot, Marcel, all, > > > > >>> > > > > >>>I've sent a fix Kernel-jar.1539 to the Inbox that
solves
the
> > > > >>>remaining bit of the chain of bugs described in the
previous
>post. > > > > >>>All tests are green now and I think the root cause
has
been
>found > > >and > > > > >>>fixed. > > > > >>> > > > > >>>In this last bit I've created a version of
stepToCallee
that
>would > > > > >>>identify a potential illegal return to a nil sender
and
avoid
>it. > > > > >>> > > > > >>>Now this example can be debugged without any
problems:
> > > > >>> > > > > >>>[[self halt. ^ 1] on: BlockCannotReturn do: #resume ]
fork
> > > > >>> > > > > >>>If you're happy with the solution in Kernel-jar.1539, > > > > >>>Kernel-jar.1538, Kernel-jar.1537 and the test in > > >KernelTests-jar.447, > > > > >>>could you please double-check and merge, please? (And
remove
> > > > >>>Kernel-mt.1534 and Tools-jar.1240 from the Inbox) > > > > >>> > > > > >>>Best, > > > > >>>Jaromir > > > > >>> > > > > >>> > > > > >>> > > > > >>>On 27-Nov-23 12:09:37 AM, "Jaromir Matas"
<mail(a)jaromir.net>
> > >wrote: > > > > >>> > > > > >>>>Hi Eliot, Christoph, all > > > > >>>> > > > > >>>>It looks like there are some more skeletons in the
closet :/
> > > > >>>> > > > > >>>>If you run this example > > > > >>>> > > > > >>>>[[self halt. ^ 1] on: BlockCannotReturn do: [:ex |
ex
resume]
>] > > >fork > > > > >>>> > > > > >>>>and step over halt and then step over ^1 you get a >nonsensical > > >error > > > > >>>>as a result of decoding nil as an instruction. > > > > >>>> > > > > >>>>It turns out that the root cause is in the
#return:from:
>method: > > >it > > > > >>>>only checks whether aSender is dead but ignores the >possibility > > >that > > > > >>>>aSender sender may be nil or dead in which cases the
VM
also
> > > > >>>>responds with sending #cannotReturn, hence I assume
the
>simulator > > > > >>>>should do the same. In addition, the VM nills the pc
in
such
> > > > >>>>scenario, so I added the same functionality here
too:
> > > > >>>> > > > > >>>>Context >> return: value from: aSender > > > > >>>> "For simulation. Roll back self to aSender and
return
value
> > > > >>>>from it. Execute any unwind blocks on the way.
ASSUMES
>aSender is > > > > >>>>a sender of self" > > > > >>>> > > > > >>>> | newTop | > > > > >>>> newTop := aSender sender. > > > > >>>> (aSender isDead or: [newTop isNil or: [newTop
isDead]])
>ifTrue: > > > > >>>> "<--------- this is extended ------" > > > > >>>> [^self pc: nil; send: #cannotReturn: to: self with: > > > > >>>>{value}]. "<------ pc: nil is added ----" > > > > >>>> (self findNextUnwindContextUpTo: newTop) ifNotNil: > > > > >>>> "Send #aboutToReturn:through: with nil as the
second
> > > > >>>>argument to avoid this bug: > > > > >>>> Cannot #stepOver '^2' in example '[^2] ensure: []'. > > > > >>>> See > > > > > > > >
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html > > > > > > > >
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html" > > > > >>>> [^self send: #aboutToReturn:through: to: self with:
{value.
> > > > >>>>nil}]. > > > > >>>> self releaseTo: newTop. > > > > >>>> newTop ifNotNil: [newTop push: value]. > > > > >>>> ^newTop > > > > >>>> > > > > >>>>In order for this to work #cannotReturn: has to be
modified
>as in > > > > >>>>Kernel-jar.1537: > > > > >>>> > > > > >>>>Context >> cannotReturn: result > > > > >>>> > > > > >>>> closureOrNil ifNotNil: [^ self cannotReturn: result
to:
self
> > > > >>>>home sender]. > > > > >>>> self error: 'Computation has been terminated!' > > > > >>>>"<----------- this has to be an Error -----" > > > > >>>> > > > > >>>>Then it almost works except when you keep stepping
over
in
>the > > > > >>>>example above, you get an MNU error on `self
previousPc`
in
> > > > >>>>#cannotReturn:to:` with your solution of the VM
crash.
If you
> > >don't > > > > >>>>mind I've amended your solution and added the final
context
>where > > > > >>>>the computation couldn't return along with the pc: > > > > >>>> > > > > >>>>Context >> cannotReturn: result to: homeContext > > > > >>>> "The receiver tried to return result to homeContext
that
>cannot > > > > >>>>be returned from. > > > > >>>> Capture the return context/pc in a
BlockCannotReturn.
Nil
>the pc > > > > >>>>to prevent repeat > > > > >>>> attempts and/or invalid continuation. Answer the
result
of
> > > > >>>>raising the exception." > > > > >>>> > > > > >>>> | exception previousPc | > > > > >>>> exception := BlockCannotReturn new. > > > > >>>> previousPc := pc ifNotNil: [self previousPc].
"<-----
here's
>a > > > > >>>>fix ----" > > > > >>>> exception > > > > >>>> result: result; > > > > >>>> deadHome: homeContext; > > > > >>>> finalContext: self; "<----- here's the new state,
if
> > > > >>>>that's fine ----" > > > > >>>> pc: previousPc. > > > > >>>> pc := nil. > > > > >>>> ^exception signal > > > > >>>> > > > > >>>>Unfortunately, this is still not the end of the
story:
there
>are > > > > >>>>situations where #runUntilErrorOrReturnFrom: places
the
two
>guard > > > > >>>>contexts below the bottom context. And that is a
problem
>because > > > > >>>>when the method tries to remove the two guard
contexts
before
> > > > >>>>returning at the end it uses #stepToCalee to do the
job
but
>this > > > > >>>>unforotunately was (ab)using the above bug in
#return:from: -
> > >I'll > > > > >>>>explain: #return:from: didn't check whether aSender
sender
>was > > >nil > > > > >>>>and as a result it allowed to simulate a return to a
"nil
> > >context" > > > > >>>>which was then (ab)used in the clean-up via
#stepToCalee
in
>the > > > > >>>>#runUntilErrorOrReturnFrom:. > > > > >>>> > > > > >>>>When I fixed the #return:from: bug, the > > >#runUntilErrorOrReturnFrom: > > > > >>>>cleanup of the guard contexts no longer works in
that
very
> > >special > > > > >>>>case where the guard contexts are below the bottom
context.
> > >There's > > > > >>>>one case where this is being used:
#terminateAggresively
by
> > > > >>>>Christoph. > > > > >>>> > > > > >>>>If I'm right with this analysis, the >#runUntilErrorOrReturnFrom: > > > > >>>>should get fixed too but I'll be away now for a few
days
and
>I > > >won't > > > > >>>>be able to respond. If you or Christoph had a chance
to
take
>a > > >look > > > > >>>>at Kernel-jar.1538 and Kernel-jar.1537 I'd be very
grateful.
>I > > >hope > > > > >>>>this super long message at least makes some sense :) > > > > >>>>Best, > > > > >>>>Jaromir > > > > >>>> > > > > >>>>[1] Kernel-jar.1538, Kernel-jar.1537 > > > > >>>>[2] KernelTests-jar.447 > > > > >>>> > > > > >>>> > > > > >>>>PS: Christoph, > > > > >>>> > > > > >>>>With Kernel-jar.1538 + Kernel-jar.1537 your example > > > > >>>> > > > > >>>>process := > > > > >>>> [(c := thisContext) pc: nil. > > > > >>>> 2+3] newProcess. > > > > >>>>process runUntil: [:ctx | ctx selector =
#cannotReturn:].
> > > > >>>>self assert: process suspendedContext sender sender
= c.
> > > > >>>>self assert: process suspendedContext arguments =
{c}.
> > > > >>>> > > > > >>>>works fine, I've just corrected your first assert. > > > > >>>> > > > > >>>> > > > > >>>> > > > > >>>> > > > > >>>> > > > > >>>>On 21-Nov-23 6:40:32 PM, "Eliot Miranda" > > ><eliot.miranda(a)gmail.com> > > > > >>>>wrote: > > > > >>>> > > > > >>>>>Hi Jaromir, > > > > >>>>> > > > > >>>>>>On Nov 20, 2023, at 11:51 PM, Jaromir Matas > > ><mail(a)jaromir.net> > > > > >>>>>>wrote: > > > > >>>>>> > > > > >>>>>> > > > > >>>>>>Hi Eliot, > > > > >>>>>>Very elegant! Now I finally got what you meant
exactly
:)
> > >Thanks. > > > > >>>>>> > > > > >>>>>>Two questions: > > > > >>>>>>1. in order for the enclosed test to work I'd need
an
Error
> > > > >>>>>>instead of Processor debugWithTitle:full: call in > > >#cannotReturn:. > > > > >>>>>>Otherwise I don't know how to catch a plain
invocation
of
>the > > > > >>>>>>Debugger: > > > > >>>>>> > > > > >>>>>>cannotReturn: result > > > > >>>>>> > > > > >>>>>> closureOrNil ifNotNil: [^ self cannotReturn:
result
to:
>self > > > > >>>>>>home sender]. > > > > >>>>>> self error: 'Computation has been terminated!' > > > > >>>>> > > > > >>>>>Much nicer. > > > > >>>>> > > > > >>>>>>2. We are capturing a pc of self which is
completely
>different > > > > >>>>>>context from homeContext indeed. > > > > >>>>> > > > > >>>>>Right. The return is attempted from a specific
return
>bytecode > > >in a > > > > >>>>>specific block. This is the coordinate of the
return
that
>cannot > > >be > > > > >>>>>made. This is the relevant point of origin of the
cannot
>return > > > > >>>>>exception. > > > > >>>>> > > > > >>>>>Why the return fails is another matter: > > > > >>>>>- the home context’s sender is a dead context
(cannot
be
> > >resumed) > > > > >>>>>- the home context’s sender is nil (home already
returned
>from) > > > > >>>>>- the block activation’s home is nil rather than a
context
> > >(should > > > > >>>>>not happen) > > > > >>>>> > > > > >>>>>But in all these cases the pc of the home context
is
>immaterial. > > > > >>>>>The hike is being returned through/from, rather
than
from;
>the > > > > >>>>>home’s pc is not relevant. > > > > >>>>> > > > > >>>>>>Maybe we could capture self in the exception too
to
make it
> > >more > > > > >>>>>>clear/explicit what is going on: what context the
captured
>pc > > >is > > > > >>>>>>actually associated with. Just a thought... > > > > >>>>> > > > > >>>>>Yes, I like that. I also like the idea of somehow
passing
>the > > > > >>>>>block activation’s pc to the debugger so that the
relevant
> > >return > > > > >>>>>expression is highlighted in the debugger. > > > > >>>>> > > > > >>>>>> > > > > >>>>>>Thanks again, > > > > >>>>>>Jaromir > > > > >>>>> > > > > >>>>>You’re welcome. I love working in this part of the
system.
> > >Thanks > > > > >>>>>for dragging me there. I’m in a slump right now and >appreciate > > >the > > > > >>>>>fellowship. > > > > >>>>> > > > > >>>>>>------ Original Message ------ > > > > >>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> > > > > >>>>>>To "Jaromir Matas" <mail(a)jaromir.net> > > > > >>>>>>Cc squeak-dev(a)lists.squeakfoundation.org > > > > >>>>>>Date 11/21/2023 2:17:21 AM > > > > >>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on > > >BlockCannotReturn > > > > >>>>>>exception > > > > >>>>>> > > > > >>>>>>>Hi Jaromir, > > > > >>>>>>> > > > > >>>>>>> see Kernel-eem.1535 for what I was suggesting.
This
>example > > > > >>>>>>>now has an exception with the right pc value in
it:
> > > > >>>>>>> > > > > >>>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc
inspect.
ex
> > >resume]] > > > > >>>>>>>fork > > > > >>>>>>> > > > > >>>>>>>The fix is simply > > > > >>>>>>> > > > > >>>>>>>Context>>cannotReturn: result to: homeContext > > > > >>>>>>> "The receiver tried to return result to
homeContext
that
> > > > >>>>>>>cannot be returned from. > > > > >>>>>>> Capture the return pc in a BlockCannotReturn.
Nil
the pc
>to > > > > >>>>>>>prevent repeat > > > > >>>>>>> attempts and/or invalid continuation. Answer the
result
>of > > > > >>>>>>>raising the exception." > > > > >>>>>>> > > > > >>>>>>> | exception | > > > > >>>>>>> exception := BlockCannotReturn new. > > > > >>>>>>> exception > > > > >>>>>>> result: result; > > > > >>>>>>> deadHome: homeContext; > > > > >>>>>>> pc: self previousPc. > > > > >>>>>>> pc := nil. > > > > >>>>>>> ^exception signal > > > > >>>>>>> > > > > >>>>>>> > > > > >>>>>>>The VM crash is now avoided. The debugger
displays
the
>method, > > > > >>>>>>>but does not highlight the offending pc, which is
no
big
>deal. > > >A > > > > >>>>>>>suitable defaultHandler for B lockCannotReturn
may be
able
>to > > >get > > > > >>>>>>>the debugger to highlight correctly on opening.
Try
the
> > > > >>>>>>>following examples: > > > > >>>>>>> > > > > >>>>>>>[[^1] on: BlockCannotReturn do: #resume] fork. > > > > >>>>>>> > > > > >>>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc
inspect.
ex
> > >resume]] > > > > >>>>>>>fork > > > > >>>>>>> > > > > >>>>>>>[[^1] value] fork. > > > > >>>>>>> > > > > >>>>>>>They al; seem to behave perfectly acceptably to
me.
Does
>this > > > > >>>>>>>fix work for you? > > > > >>>>>>> > > > > >>>>>>>On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas > > ><mail(a)jaromir.net> > > > > >>>>>>>wrote: > > > > >>>>>>>>Hi Eliot, > > > > >>>>>>>> > > > > >>>>>>>>How about to nil the pc just before making the
return:
> > > > >>>>>>>>``` > > > > >>>>>>>>Context >> #cannotReturn: result > > > > >>>>>>>> > > > > >>>>>>>> self push: self pc. "backup the pc for the sake
of
> > > > >>>>>>>>debugging" > > > > >>>>>>>> closureOrNil ifNotNil: [^self cannotReturn:
result
to:
>self > > > > >>>>>>>>home sender; pc: nil]. > > > > >>>>>>>> Processor debugWithTitle: 'Computation has been >terminated!' > > > > >>>>>>>>translated full: false > > > > >>>>>>>>``` > > > > >>>>>>>>The nilled pc should not even potentially
interfere
with
>the > > > > >>>>>>>>#isDead now. > > > > >>>>>>>> > > > > >>>>>>>>I hope this is at least a step in the right
direction :)
> > > > >>>>>>>> > > > > >>>>>>>>However, there's still a problem when debugging
the
> > >resumption > > > > >>>>>>>>of #cannotReturn because the encoders expect a
reasonable
> > >index. > > > > >>>>>>>>I haven't figured out yet where to place a nil
check
>#step, > > > > >>>>>>>>#stepToSendOrReturn... ? > > > > >>>>>>>> > > > > >>>>>>>>Thanks again, > > > > >>>>>>>>Jaromir > > > > >>>>>>>> > > > > >>>>>>>> > > > > >>>>>>>>------ Original Message ------ > > > > >>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> > > > > >>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> > > > > >>>>>>>>Date 11/17/2023 8:36:50 PM > > > > >>>>>>>>Subject Re: [squeak-dev] Re: Resuming on >BlockCannotReturn > > > > >>>>>>>>exception > > > > >>>>>>>> > > > > >>>>>>>>>Hi Jaromir, > > > > >>>>>>>>> > > > > >>>>>>>>>>On Nov 17, 2023, at 7:05 AM, Jaromir Matas > > ><mail(a)jaromir.net> > > > > >>>>>>>>>>wrote: > > > > >>>>>>>>>> > > > > >>>>>>>>>> > > > > >>>>>>>>>>Eliot, hi again, > > > > >>>>>>>>>> > > > > >>>>>>>>>>Please disregard my previous comment about
nilling
the
> > > > >>>>>>>>>>contexts that have returned. We are indeed
talking
>about > > >the > > > > >>>>>>>>>>context directly under the #cannotReturn
context
which
>is > > > > >>>>>>>>>>totally different from the home context in
another
>thread > > > > >>>>>>>>>>that's gone. > > > > >>>>>>>>>> > > > > >>>>>>>>>>I may still be confused but would nilling the
pc
of the
> > > > >>>>>>>>>>context directly under the cannotReturn
context
help?
> > >Here's > > > > >>>>>>>>>>what I mean: > > > > >>>>>>>>>>``` > > > > >>>>>>>>>>Context >> #cannotReturn: result > > > > >>>>>>>>>> > > > > >>>>>>>>>> closureOrNil ifNotNil: [^self pc: nil;
cannotReturn:
> > > > >>>>>>>>>>result to: self home sender]. > > > > >>>>>>>>>> Processor debugWithTitle: 'Computation has
been
> > > > >>>>>>>>>>terminated!' translated full: false. > > > > >>>>>>>>>>``` > > > > >>>>>>>>>>Instead of crashing the VM invokes the
debugger
with
>the > > > > >>>>>>>>>>'Computation has been terminated!' message. > > > > >>>>>>>>>> > > > > >>>>>>>>>>Does this make sense? > > > > >>>>>>>>> > > > > >>>>>>>>>Nearly. But it loses the information on what
the pc
>actually > > > > >>>>>>>>>is, and that’s potentially vital information.
So
IMO the
>ox > > > > >>>>>>>>>should only be nilled between the
BlockCannotReturn
> > >exception > > > > >>>>>>>>>being created and raised. > > > > >>>>>>>>> > > > > >>>>>>>>>[But if you try this don’t be surprised if it
causes a
>few > > > > >>>>>>>>>temporary problems. It looks to me that without
a
little
> > > > >>>>>>>>>refactoring this could easily cause an infinite >recursion > > > > >>>>>>>>>around the sending of isDead. I’m sure you’ll
be
able to
>fix > > > > >>>>>>>>>the code to work correctly] > > > > >>>>>>>>> > > > > >>>>>>>>>>Thanks, > > > > >>>>>>>>>>Jaromir > > > > >>>>>>>>>> > > > > >>>>>>>>>> > > > > >>>>>>>>>>------ Original Message ------ > > > > >>>>>>>>>>From "Jaromir Matas" <mail(a)jaromir.net> > > > > >>>>>>>>>>To "Eliot Miranda"
<eliot.miranda(a)gmail.com>;
"The
> > > > >>>>>>>>>>general-purpose Squeak developers list" > > > > >>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > > > > >>>>>>>>>>Date 11/17/2023 10:15:17 AM > > > > >>>>>>>>>>Subject [squeak-dev] Re: Resuming on
BlockCannotReturn
> > > > >>>>>>>>>>exception > > > > >>>>>>>>>> > > > > >>>>>>>>>>>Hi Eliot, > > > > >>>>>>>>>>> > > > > >>>>>>>>>>> > > > > >>>>>>>>>>> > > > > >>>>>>>>>>>------ Original Message ------ > > > > >>>>>>>>>>>From "Eliot Miranda"
<eliot.miranda(a)gmail.com>
> > > > >>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> > > > > >>>>>>>>>>>Cc "The general-purpose Squeak developers
list"
> > > > >>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > > > > >>>>>>>>>>>Date 11/16/2023 11:52:45 PM > > > > >>>>>>>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming
on
> > > > >>>>>>>>>>>BlockCannotReturn exception > > > > >>>>>>>>>>> > > > > >>>>>>>>>>>>Hi Jaromir, > > > > >>>>>>>>>>>> > > > > >>>>>>>>>>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir
Matas
> > > > >>>>>>>>>>>><mail(a)jaromir.net> wrote: > > > > >>>>>>>>>>>>>Hi Nicolas, Eliot, > > > > >>>>>>>>>>>>> > > > > >>>>>>>>>>>>>here's what I understand is happening (see
the
>enclosed > > > > >>>>>>>>>>>>>screenshot): > > > > >>>>>>>>>>>>> > > > > >>>>>>>>>>>>>1) we fork a new process to evaluate [^1] > > > > >>>>>>>>>>>>>2) the new process evaluates [^1] which
means
> > >instruction > > > > >>>>>>>>>>>>>18 is being evaluated, hence pc points to >instruction 19 > > > > >>>>>>>>>>>>>now > > > > >>>>>>>>>>>>>3) however, the home context where ^1
should
return
>to > > >is > > > > >>>>>>>>>>>>>gone by this time (the process that
executed
the
>fork > > >has > > > > >>>>>>>>>>>>>already returned - notice the two up arrows
in
the
> > >debugger > > > > >>>>>>>>>>>>>screenshot) > > > > >>>>>>>>>>>>>4) the VM can't finish the instruction and
returns
> > >control > > > > >>>>>>>>>>>>>to the image via placing the #cannotReturn:
context
>on > > >top > > > > >>>>>>>>>>>>>of the [^1] context > > > > >>>>>>>>>>>>>5) #cannotReturn: evaluation results in
signalling
>the > > >BCR > > > > >>>>>>>>>>>>>exception which is then handled by the
#resume
>handler > > > > >>>>>>>>>>>>> (in our debugged case the [:ex | self
halt. ex
>resume] > > > > >>>>>>>>>>>>>handler) > > > > >>>>>>>>>>>>>6) ex resume is evaluated, however, this
means
> > >requesting > > > > >>>>>>>>>>>>>the VM to evaluate instruction 19 of the
[^1]
>context - > > > > >>>>>>>>>>>>>which is past the last instruction of the
context
>and > > >the > > > > >>>>>>>>>>>>>crash ensues > > > > >>>>>>>>>>>>> > > > > >>>>>>>>>>>>>I wonder whether such situations
could/should
be
> > >prevented > > > > >>>>>>>>>>>>>inside the VM or whether such an
expectation is
>wrong > > >for > > > > >>>>>>>>>>>>>some reason. > > > > >>>>>>>>>>>> > > > > >>>>>>>>>>>>As Nicolas says, IMO this is best done at
the
image
> > >level. > > > > >>>>>>>>>>>> > > > > >>>>>>>>>>>>It could be prevented in the VM, but at
great
cost,
>and > > >only > > > > >>>>>>>>>>>>partially. The performance issue is that the
last
> > >bytecode > > > > >>>>>>>>>>>>in a method is not marked in any way, and
that
to
> > >determine > > > > >>>>>>>>>>>>the last bytecode the bytecodes must be
symbolically
> > > > >>>>>>>>>>>>evaluated from the start of the method. See >implementors > > >of > > > > >>>>>>>>>>>>endPC at the image level (which defer to the
method
> > >trailer) > > > > >>>>>>>>>>>>and implementors of endPCOf: in the VMMaker
code.
>Doing > > >this > > > > >>>>>>>>>>>>every time execution commences is
prohibitively
> > >expensive. > > > > >>>>>>>>>>>>The "only partially" issue is that following
the
>return > > > > >>>>>>>>>>>>instruction may be other valid bytecodes,
but
these
>are > > >not > > > > >>>>>>>>>>>>a continuation. > > > > >>>>>>>>>>>> > > > > >>>>>>>>>>>> > > > > >>>>>>>>>>>>Consider the following code in some block: > > > > >>>>>>>>>>>> [self expression ifTrue: > > > > >>>>>>>>>>>> [^1]. > > > > >>>>>>>>>>>> ^2 > > > > >>>>>>>>>>>> > > > > >>>>>>>>>>>>The bytecodes for this are > > > > >>>>>>>>>>>> pushReceiver > > > > >>>>>>>>>>>> send #expression > > > > >>>>>>>>>>>> jumpFalse L1 > > > > >>>>>>>>>>>> push 1 > > > > >>>>>>>>>>>> methodReturnTop > > > > >>>>>>>>>>>>L1 > > > > >>>>>>>>>>>> push 2 > > > > >>>>>>>>>>>> methodReturnTop > > > > >>>>>>>>>>>> > > > > >>>>>>>>>>>>Clearly if expression is true these should
be
*no*
> > > > >>>>>>>>>>>>continuation in which ^2 is executed. > > > > >>>>>>>>>>> > > > > >>>>>>>>>>>Well, in that case there's a bug because the >computation > > >in > > > > >>>>>>>>>>>the following example shouldn't continue past
the
[^1]
> > >block > > > > >>>>>>>>>>>but it silently does: > > > > >>>>>>>>>>>`[[true ifTrue: [^ 1]] on: BlockCannotReturn
do:
>#resume ] > > > > >>>>>>>>>>>fork` > > > > >>>>>>>>>>> > > > > >>>>>>>>>>>The bytecodes are > > > > >>>>>>>>>>> push true > > > > >>>>>>>>>>> jumpFalse L1 > > > > >>>>>>>>>>> push 1 > > > > >>>>>>>>>>> returnTop > > > > >>>>>>>>>>>L1 > > > > >>>>>>>>>>> push nil > > > > >>>>>>>>>>> blockReturn > > > > >>>>>>>>>>> > > > > >>>>>>>>>>> > > > > >>>>>>>>>>> > > > > >>>>>>>>>>>> > > > > >>>>>>>>>>>>So even if the VM did try and detect whether
the
>return > > >was > > > > >>>>>>>>>>>>at the last block method, it would only work
for
>special > > > > >>>>>>>>>>>>cases. > > > > >>>>>>>>>>>> > > > > >>>>>>>>>>>> > > > > >>>>>>>>>>>>It seems to me the issue is simply that the
context
>that > > > > >>>>>>>>>>>>cannot be returned from should be marked as
dead
(see
> > > > >>>>>>>>>>>>Context>>isDead) by setting its pc to nil at
some
>point, > > > > >>>>>>>>>>>>presumably after copying the actual return
pc
into
>the > > > > >>>>>>>>>>>>BlockCannotReturn exception, to avoid ever
trying to
> > >resume > > > > >>>>>>>>>>>>the context. > > > > >>>>>>>>>>> > > > > >>>>>>>>>>>Does this mean, in other words, that every
context
>that > > > > >>>>>>>>>>>returns should nil its pc to avoid being
"wrongly"
> > > > >>>>>>>>>>>reused/executed in the future, which concerns >primarily > > >those > > > > >>>>>>>>>>>being referenced somewhere hence potentially >executable in > > > > >>>>>>>>>>>the future, is that right? > > > > >>>>>>>>>>>Hypothetical question: would nilling the pc
during
>returns > > > > >>>>>>>>>>>"fix" the example? > > > > >>>>>>>>>>>Thanks a lot for helping me understand this. > > > > >>>>>>>>>>>Best, > > > > >>>>>>>>>>>Jaromir > > > > >>>>>>>>>>> > > > > >>>>>>>>>>> > > > > >>>>>>>>>>> > > > > >>>>>>>>>>>> > > > > >>>>>>>>>>>> > > > > >>>>>>>>>>>>> > > > > >>>>>>>>>>>>>Thanks, > > > > >>>>>>>>>>>>>Jaromir > > > > >>>>>>>>>>>>> > > > > >>>>>>>>>>>>><bdxuqalu.png> > > > > >>>>>>>>>>>>> > > > > >>>>>>>>>>>>>------ Original Message ------ > > > > >>>>>>>>>>>>>From "Eliot Miranda"
<eliot.miranda(a)gmail.com>
> > > > >>>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>;
"The
> > >general-purpose > > > > >>>>>>>>>>>>>Squeak developers list" > > > > >>>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > > > > >>>>>>>>>>>>>Date 11/16/2023 6:48:43 PM > > > > >>>>>>>>>>>>>Subject Re: [squeak-dev] Re: Resuming on > > >BlockCannotReturn > > > > >>>>>>>>>>>>>exception > > > > >>>>>>>>>>>>> > > > > >>>>>>>>>>>>>>Hi Jaromir, > > > > >>>>>>>>>>>>>> > > > > >>>>>>>>>>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir
Matas
> > > > >>>>>>>>>>>>>>><mail(a)jaromir.net> wrote: > > > > >>>>>>>>>>>>>>> > > > > >>>>>>>>>>>>>>> > > > > >>>>>>>>>>>>>>>Hi Nicloas, > > > > >>>>>>>>>>>>>>>No no, I don't have any practical
scenario in
>mind, > > >I'm > > > > >>>>>>>>>>>>>>>just trying to understand why the VM is >implemented > > >like > > > > >>>>>>>>>>>>>>>this, whether there were a reason to
leave
this
> > > > >>>>>>>>>>>>>>>possibility of a crash, e.g. it would
slow
down
>the VM > > >to > > > > >>>>>>>>>>>>>>>try to prevent such a dumb situation (who
would
>resume > > > > >>>>>>>>>>>>>>>from BCR in his right mind? :) ) - or
perhaps
I
>have > > > > >>>>>>>>>>>>>>>overlooked some good reason to even keep
this
>behavior > > >in > > > > >>>>>>>>>>>>>>>the VM. That's all. > > > > >>>>>>>>>>>>>> > > > > >>>>>>>>>>>>>>Let’s first understand what’s really
happening.
> > >Presumably > > > > >>>>>>>>>>>>>>at tone point a context is resumed those
pc is
>already > > >at > > > > >>>>>>>>>>>>>>the block return bytecode (effectively,
because it
> > >crashes > > > > >>>>>>>>>>>>>>in JITted code, but I bet the stack vm
will
crash
>also, > > > > >>>>>>>>>>>>>>but not as cleanly - it will try and
execute
the
>bytes > > >in > > > > >>>>>>>>>>>>>>the encoded method trailer). So which
method
>actually > > > > >>>>>>>>>>>>>>sends resume, and to what, and what state
is
>resume’s > > > > >>>>>>>>>>>>>>receiver when resume is sent? > > > > >>>>>>>>>>>>>> > > > > >>>>>>>>>>>>>> > > > > >>>>>>>>>>>>>>> > > > > >>>>>>>>>>>>>>>Thanks for your reply. > > > > >>>>>>>>>>>>>>>Regards, > > > > >>>>>>>>>>>>>>>Jaromir > > > > >>>>>>>>>>>>>>> > > > > >>>>>>>>>>>>>>> > > > > >>>>>>>>>>>>>>> > > > > >>>>>>>>>>>>>>> > > > > >>>>>>>>>>>>>>>------ Original Message ------ > > > > >>>>>>>>>>>>>>>From "Nicolas Cellier" > > > > >>>>>>>>>>>>>>><nicolas.cellier.aka.nice(a)gmail.com> > > > > >>>>>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>;
"The
> > > > >>>>>>>>>>>>>>>general-purpose Squeak developers list" > > > > >>>>>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > > > > >>>>>>>>>>>>>>>Date 11/16/2023 7:20:20 AM > > > > >>>>>>>>>>>>>>>Subject Re: [squeak-dev] Resuming on >BlockCannotReturn > > > > >>>>>>>>>>>>>>>exception > > > > >>>>>>>>>>>>>>> > > > > >>>>>>>>>>>>>>>>Hi Jaromir, > > > > >>>>>>>>>>>>>>>>Is there a scenario where it would make
sense to
> > >resume > > > > >>>>>>>>>>>>>>>>a BlockCannotReturn? > > > > >>>>>>>>>>>>>>>>If not, I would suggest to protect at
image
side
>and > > > > >>>>>>>>>>>>>>>>override #resume. > > > > >>>>>>>>>>>>>>>> > > > > >>>>>>>>>>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir
Matas
> > > > >>>>>>>>>>>>>>>><mail(a)jaromir.net> a écrit : > > > > >>>>>>>>>>>>>>>>>Hi Eliot, Christoph, All, > > > > >>>>>>>>>>>>>>>>> > > > > >>>>>>>>>>>>>>>>>It's known the following example
crashes
the VM.
>Is > > > > >>>>>>>>>>>>>>>>>this an intended behavior or a
"tolerated
bug"?
> > > > >>>>>>>>>>>>>>>>> > > > > >>>>>>>>>>>>>>>>>`[[^ 1] on: BlockCannotReturn do:
#resume]
fork`
> > > > >>>>>>>>>>>>>>>>> > > > > >>>>>>>>>>>>>>>>>I understand why it crashes: the
non-local
>return > > >has > > > > >>>>>>>>>>>>>>>>>nowhere to return to and so resuming
the
>computation > > > > >>>>>>>>>>>>>>>>>leads to a crash. But why not raise
another
BCR
> > > > >>>>>>>>>>>>>>>>>exception to prevent the crash?
Potential
>infinite > > > > >>>>>>>>>>>>>>>>>loop? Perhaps I'm just missing the
purpose
of
>this > > > > >>>>>>>>>>>>>>>>>behavior... > > > > >>>>>>>>>>>>>>>>> > > > > >>>>>>>>>>>>>>>>>Thanks for an explanation. > > > > >>>>>>>>>>>>>>>>> > > > > >>>>>>>>>>>>>>>>>Best, > > > > >>>>>>>>>>>>>>>>>Jaromir > > > > >>>>>>>>>>>>>>>>> > > > > >>>>>>>>>>>>>>>>>-- > > > > >>>>>>>>>>>>>>>>> > > > > >>>>>>>>>>>>>>>>>Jaromir Matas > > > > >>>>>>>>>>>>>>>>> > > > > >>>>>>>>>>>>>>>>> > > > > >>>>>>>>>>>>>>> > > > > >>>>>>>>>>>> > > > > >>>>>>>>>>>> > > > > >>>>>>>>>>>>-- > > > > >>>>>>>>>>>>_,,,^..^,,,_ > > > > >>>>>>>>>>>>best, Eliot > > > > >>>>>>>>>><Context-cannotReturn.st> > > > > >>>>>>> > > > > >>>>>>> > > > > >>>>>>>-- > > > > >>>>>>>_,,,^..^,,,_ > > > > >>>>>>>best, Eliot > > > > >>>>>><ProcessTest-testResumeAfterBCR.st>
--- Sent from Squeak Inbox Talk
Hi Christoph, sorry for confusing you :)
On 04-Jan-24 12:34:04 AM, christoph.thiede@student.hpi.uni-potsdam.de wrote:
Hi Jaromir,
On 2024-01-03T22:36:17+00:00, mail@jaromir.net wrote:
Hi Christoph,
On 02-Jan-24 8:05:31 PM,
christoph.thiede(a)student.hpi.uni-potsdam.de
wrote:
Hi Jaromir,
thanks for the clarification. If you don't mind I would still wait
for
a couple of days to see whether Eliot or Marcel or someone else who
are
longer aboard find anything against your change, but I have been convinced by you. :-) After that, we can merge your open test and eliminate the ifNil checks in the TraceDebugger and also in the penultimate line of Context>>#return:from:.
In general, some methods are "pure simulation" methods intended
to
mimic the VM behavior (#step etc) but nothing prevents one from
using
them for other purposes - like what #runUntilErrorOrReturnFrom: did:
to
just get rid of some contexts). Is it ok to do that? I tend to think it's not; it's confusing. That's why I made #stepToCalleeOrNil a private method because it's not a "true" simulation method but a
sort
of hybrid.
Yes, I think I understand your point here, the assumptions and use cases for #stepToCalleeOrNil are too special to expose it to
everyone.
Clients should mainly use #step, #stepToCallee, or maybe - with care
#runUntilErrorOrReturnFrom: to advance a context I think.
This is also why I checked Jakob's Git Browser and all tests seem
fine.
Wait, Squot is using code simulation?
I guess not, but as I noted, nothing prevents you from using
simulation
methods in the non-simulation code :) Plus, one might use simulation methods to prepare test scenarios... So I just ran the changes
through
Squot tests for good measure ;)
I still don't understand. :-) You ran the Squot test on the off chance that something in Squot or the Squot test uses code simulation?
Well, you can put it that way :) The more tests the better chance you catch something :D It happened a few times Pharo tests caught things Squeak didn't.
Or did you run the Squot tests inside the simulator? :D
Best, Christoph
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2024-01-02T11:25:57+00:00, mail(a)jaromir.net wrote:
Hi Christoph,
correct me if I'm wrong: with the corrected #step semantics (the #return:from: fix) one should no longer need to do things like:
self step ifNil: [^ self]
because #step should always return a context, even if attempting
to
step
to a nil context:
[] asContext step
In this case it correctly returns the #cannotReturn: context.
I've noticed these nil checks in Trace debugger's #doStepOver or #stepToHome.
I hope I haven't overlooked anything :)
Thanks for your thoughts, Jaromir
On 31-Dec-23 10:42:54 AM, "Jaromir Matas" <mail(a)jaromir.net>
wrote:
Hi Christoph,
Yes, that's exactly what I was talking about - the #return:from:
fix
changes slightly (perhaps it's better to say corrects) the
semantics
of
some stepping methods - #step and #stepToCallee, which allowed illegally stepping into a dead or nil context. They can no
longer be
used in the manner you showed. Another example was #runUntilErrorOrReturnFrom: - it used #stepToCallee this way so
as a
workaround I created the #stepToCalleeOrNil method and used in #runUntilErrorOrReturnFrom:
[ctxt isDead or: [topContext isNil]] whileFalse: [topContext := topContext stepToCalleeOrNil].
Theoretically there might be some external code (mis)using the incorrect stepping semantics. In Pharo's trunk they were mainly
tests
and #stepToHome but I haven't checked any external code. But all
their
tests are green with this change and I guess it's not
widespread.
This is also why I checked Jakob's Git Browser and all tests
seem
fine.
My opinion is to keep the correct simulation semantics and deal
with
potential consequences as/if they come. However I don't expect a
huge
impact as the change only affects border situations.
In general, some methods are "pure simulation" methods intended
to
mimic the VM behavior (#step etc) but nothing prevents one from
using
them for other purposes - like what #runUntilErrorOrReturnFrom:
did:
to
just get rid of some contexts). Is it ok to do that? I tend to
think
it's not; it's confusing. That's why I made #stepToCalleeOrNil a private method because it's not a "true" simulation method but a
sort
of hybrid.
What do you think?
Thanks for reviewing the fix! Best, Jaromir
On 30-Dec-23 11:07:54 PM,
christoph.thiede(a)student.hpi.uni-potsdam.de
wrote:
Hi Jaromir,
I found a breaking change in the new behavior of Context>>#return:from: while using the TraceDebugger:
In the past we could say:
c:=[2+3]asContext. [c]whileNotNil:[c:=cstep].
With your change, the script runs forever because the last step
does
not answer nil as before but activates a new #cannotReturn:.
This behavior seems not be expected anywhere in the trunk (if
my
first
search was complete), and you are right that the new behavior
aligns
closer to the VM behavior. Still, the old code seemed to
explicitly
intend this - see the "newTop ifNotNil:" at the bottom of the
method.
I wonder whether we should keep this. For me it is not a big
deal;
I
can just change my script like this:
c:=[2+3]asContext. [csenderisNiland:[cwillReturn]]whileNotNil:[c:=cstep].
I just wonder whether this could a breaking or unintended
change
for
anything else. For [^2] ensure: [] it would not be a big deal,
we
could just change the check in question to (aSenderisDeador:[newTopnotNiland:[newTopisDead]])ifTrue:. I am tending against restoring the old behavior, but I am unsure.
What
is
your opinion on this?
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-12-30T21:13:37+00:00, mail(a)jaromir.net wrote:
> > nit: You mixed up the order of arguments for
#assert:equals:
> > oops, sorry :) It happens to me all the time; I've never
actually
> understood why the strange, almost Yodaesque, order... as if
you
asked > in English: > > "Make sure 18 is his age." > > Thanks, > Jaromir > > > On 30-Dec-23 9:13:56 PM, christoph.thiede(a)student.hpi.uni-potsdam.de > wrote: > > >nit: You mixed up the order of arguments for
#assert:equals:
(it is
> >assert: expected equals: actual) and could have used it in
the
final > >assert again, but that's clearly no reason to hold back a
useful
test. > >;-) Merged, thanks! :-) > > > >Best, > >Christoph > > > >--- > >Sent from Squeak Inbox Talk > >https://github.com/hpi-swa-lab/squeak-inbox-talk > > > >On 2023-12-30T17:33:08+00:00, mail(a)jaromir.net wrote: > > > > > Hi Christoph, > > > > > > Thanks for merging the fixes; I've just sent another
test in
> > > KernelTests-jar.448 to complement them. > > > > > > Please take a look and if ok I'd appreciate it if you
could
merge it > >as > > > well. > > > > > > Best regards and Happy New Year to you too! > > > Jaromir > > > > > > > > > On 30-Dec-23 6:15:25 PM, > >christoph.thiede(a)student.hpi.uni-potsdam.de > > > wrote: > > > > > > >Hi Jaromir, hi all, > > > > > > > >finally I have found the time to review these
suggestions.
> > > >Kernel-jar.1537, Kernel-jar.1538, and Kernel-jar.1539
look
excellent > >to > > > >me as well. Clear, straightforward, useful. :-) I have
merged
them > >into > > > >the trunk via Kernel-ct.1545. > > > > > > > >Regarding DebuggerTests>>test16HandleSimulationError, I
have
patched > >it > > > >via ToolsTests-ct.125. Nothing to rack your brains
over:
> >"thisContext > > > >pc: nil" just mimicks any kind of unhandled error
inside
the
> >simulator > > > >- since we now gently handle this via #cannotReturn:, I
just
> >replaced > > > >it with "thisContext pc: false". :-) Sorry for not
clarifying
that > > > >earlier and letting you speculate. > > > > > > > >Thanks for your work, and I already wish you a happy
new
year!
> > > > > > > >Best, > > > >Christoph > > > > > > > >--- > > > >Sent from Squeak Inbox Talk > > > >https://github.com/hpi-swa-lab/squeak-inbox-talk > > > > > > > >On 2023-11-29T13:31:09+00:00, mail(a)jaromir.net wrote: > > > > > > > > > Hi Marcel, > > > > > > > > > > > [myself] whether the patch would have been
necessary
should the > > > > > #return:from: had been fixed then > > > > > > > > > > Nonsense, I just mixed it up with another issue :) > > > > > > > > > > > > > > > On 29-Nov-23 1:51:21 PM, "Jaromir Matas" <mail(a)jaromir.net> > >wrote: > > > > > > > > > > >Thanks Marcel! This test somehow slipped my
attention
:)
> > > > > > > > > > > >The test can no longer work as is. It takes
advantage
of
the > > > >erroneous > > > > > >behavior of #return:from: in the sense that if you
simulate
> > > > > > > > > > > > thisContext pc: nil > > > > > > > > > > > >it'll happily return to a dead context (i.e. to
thisContext
from > > > >#pc: > > > > > >nil context) - which is not what the VM does during runtime. It > > > >should > > > > > >immediately raise an illegal return exception not
only
during > > > >runtime > > > > > >but also during simulation. > > > > > > > > > > > >The test mentions a patch for an infinite debugger
chain
> > > > > >(http://forum.world.st/I-broke-the-debugger-td5110752.html).
I
> > > >wonder > > > > > >whether the problem could have something to do with
this
> >simulation > > > >bug > > > > > >in return:from:; and a terrible idea occurred to me
whether
the > > > >patch > > > > > >would have been necessary should the #return:from:
had
been
> >fixed > > > >then > > > > > >;O > > > > > > > > > > > >We may potentially come up with more examples like
this,
even in > >the > > > > > >trunk, where the bug from #return:from: propagated
and
was
taken > > > > > >advantage of. I've found and fixed #runUntilErrorOrReturnFrom: > >but > > > >more > > > > > >can still be surviving undetected... > > > > > > > > > > > >I'd place the test into #expectedFailures for now
but
maybe
it's > > > >time > > > > > >to remove it; Christoph should decide :) > > > > > > > > > > > >Thanks again, > > > > > >Jaromir > > > > > > > > > > > > > > > > > >On 29-Nov-23 10:28:38 AM, "Taeumel, Marcel via
Squeak-dev"
> > > > > ><squeak-dev(a)lists.squeakfoundation.org> wrote: > > > > > > > > > > > >>Hi Jaromir -- > > > > > >> > > > > > >>Looks good. Still, what about that #test16HandleSimulationError > > > >now? > > > > > >>:-) It is failing with your changes ... how would
you
adapt it? > > > > > >> > > > > > >> > > > > > >> > > > > > >>Best, > > > > > >>Marcel > > > > > >>>Am 28.11.2023 01:29:39 schrieb Jaromir Matas > ><mail(a)jaromir.net>: > > > > > >>> > > > > > >>>Hi Eliot, Marcel, all, > > > > > >>> > > > > > >>>I've sent a fix Kernel-jar.1539 to the Inbox that
solves
the > > > > > >>>remaining bit of the chain of bugs described in
the
previous > >post. > > > > > >>>All tests are green now and I think the root
cause
has
been > >found > > > >and > > > > > >>>fixed. > > > > > >>> > > > > > >>>In this last bit I've created a version of
stepToCallee
that > >would > > > > > >>>identify a potential illegal return to a nil
sender
and
avoid > >it. > > > > > >>> > > > > > >>>Now this example can be debugged without any
problems:
> > > > > >>> > > > > > >>>[[self halt. ^ 1] on: BlockCannotReturn do:
#resume ]
fork > > > > > >>> > > > > > >>>If you're happy with the solution in
Kernel-jar.1539,
> > > > > >>>Kernel-jar.1538, Kernel-jar.1537 and the test in > > > >KernelTests-jar.447, > > > > > >>>could you please double-check and merge, please?
(And
remove > > > > > >>>Kernel-mt.1534 and Tools-jar.1240 from the Inbox) > > > > > >>> > > > > > >>>Best, > > > > > >>>Jaromir > > > > > >>> > > > > > >>> > > > > > >>> > > > > > >>>On 27-Nov-23 12:09:37 AM, "Jaromir Matas" <mail(a)jaromir.net> > > > >wrote: > > > > > >>> > > > > > >>>>Hi Eliot, Christoph, all > > > > > >>>> > > > > > >>>>It looks like there are some more skeletons in
the
closet :/ > > > > > >>>> > > > > > >>>>If you run this example > > > > > >>>> > > > > > >>>>[[self halt. ^ 1] on: BlockCannotReturn do: [:ex
|
ex
resume] > >] > > > >fork > > > > > >>>> > > > > > >>>>and step over halt and then step over ^1 you get
a
> >nonsensical > > > >error > > > > > >>>>as a result of decoding nil as an instruction. > > > > > >>>> > > > > > >>>>It turns out that the root cause is in the
#return:from:
> >method: > > > >it > > > > > >>>>only checks whether aSender is dead but ignores
the
> >possibility > > > >that > > > > > >>>>aSender sender may be nil or dead in which cases
the
VM
also > > > > > >>>>responds with sending #cannotReturn, hence I
assume
the
> >simulator > > > > > >>>>should do the same. In addition, the VM nills
the pc
in
such > > > > > >>>>scenario, so I added the same functionality here
too:
> > > > > >>>> > > > > > >>>>Context >> return: value from: aSender > > > > > >>>> "For simulation. Roll back self to aSender and
return
value > > > > > >>>>from it. Execute any unwind blocks on the way.
ASSUMES
> >aSender is > > > > > >>>>a sender of self" > > > > > >>>> > > > > > >>>> | newTop | > > > > > >>>> newTop := aSender sender. > > > > > >>>> (aSender isDead or: [newTop isNil or: [newTop
isDead]])
> >ifTrue: > > > > > >>>> "<--------- this is extended ------" > > > > > >>>> [^self pc: nil; send: #cannotReturn: to: self
with:
> > > > > >>>>{value}]. "<------ pc: nil is added ----" > > > > > >>>> (self findNextUnwindContextUpTo: newTop)
ifNotNil:
> > > > > >>>> "Send #aboutToReturn:through: with nil as the
second
> > > > > >>>>argument to avoid this bug: > > > > > >>>> Cannot #stepOver '^2' in example '[^2] ensure:
[]'.
> > > > > >>>> See > > > > > > > > > > >
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html
> > > > > > > > > > >
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html"
> > > > > >>>> [^self send: #aboutToReturn:through: to: self
with:
{value. > > > > > >>>>nil}]. > > > > > >>>> self releaseTo: newTop. > > > > > >>>> newTop ifNotNil: [newTop push: value]. > > > > > >>>> ^newTop > > > > > >>>> > > > > > >>>>In order for this to work #cannotReturn: has to
be
modified > >as in > > > > > >>>>Kernel-jar.1537: > > > > > >>>> > > > > > >>>>Context >> cannotReturn: result > > > > > >>>> > > > > > >>>> closureOrNil ifNotNil: [^ self cannotReturn:
result
to:
self > > > > > >>>>home sender]. > > > > > >>>> self error: 'Computation has been terminated!' > > > > > >>>>"<----------- this has to be an Error -----" > > > > > >>>> > > > > > >>>>Then it almost works except when you keep
stepping
over
in > >the > > > > > >>>>example above, you get an MNU error on `self
previousPc`
in > > > > > >>>>#cannotReturn:to:` with your solution of the VM
crash.
If you > > > >don't > > > > > >>>>mind I've amended your solution and added the
final
context > >where > > > > > >>>>the computation couldn't return along with the
pc:
> > > > > >>>> > > > > > >>>>Context >> cannotReturn: result to: homeContext > > > > > >>>> "The receiver tried to return result to
homeContext
that > >cannot > > > > > >>>>be returned from. > > > > > >>>> Capture the return context/pc in a
BlockCannotReturn.
Nil > >the pc > > > > > >>>>to prevent repeat > > > > > >>>> attempts and/or invalid continuation. Answer
the
result
of > > > > > >>>>raising the exception." > > > > > >>>> > > > > > >>>> | exception previousPc | > > > > > >>>> exception := BlockCannotReturn new. > > > > > >>>> previousPc := pc ifNotNil: [self previousPc].
"<-----
here's > >a > > > > > >>>>fix ----" > > > > > >>>> exception > > > > > >>>> result: result; > > > > > >>>> deadHome: homeContext; > > > > > >>>> finalContext: self; "<----- here's the new
state,
if
> > > > > >>>>that's fine ----" > > > > > >>>> pc: previousPc. > > > > > >>>> pc := nil. > > > > > >>>> ^exception signal > > > > > >>>> > > > > > >>>>Unfortunately, this is still not the end of the
story:
there > >are > > > > > >>>>situations where #runUntilErrorOrReturnFrom:
places
the
two > >guard > > > > > >>>>contexts below the bottom context. And that is a
problem
> >because > > > > > >>>>when the method tries to remove the two guard
contexts
before > > > > > >>>>returning at the end it uses #stepToCalee to do
the
job
but > >this > > > > > >>>>unforotunately was (ab)using the above bug in #return:from: - > > > >I'll > > > > > >>>>explain: #return:from: didn't check whether
aSender
sender > >was > > > >nil > > > > > >>>>and as a result it allowed to simulate a return
to a
"nil > > > >context" > > > > > >>>>which was then (ab)used in the clean-up via
#stepToCalee
in > >the > > > > > >>>>#runUntilErrorOrReturnFrom:. > > > > > >>>> > > > > > >>>>When I fixed the #return:from: bug, the > > > >#runUntilErrorOrReturnFrom: > > > > > >>>>cleanup of the guard contexts no longer works in
that
very > > > >special > > > > > >>>>case where the guard contexts are below the
bottom
context. > > > >There's > > > > > >>>>one case where this is being used:
#terminateAggresively
by > > > > > >>>>Christoph. > > > > > >>>> > > > > > >>>>If I'm right with this analysis, the > >#runUntilErrorOrReturnFrom: > > > > > >>>>should get fixed too but I'll be away now for a
few
days
and > >I > > > >won't > > > > > >>>>be able to respond. If you or Christoph had a
chance
to
take > >a > > > >look > > > > > >>>>at Kernel-jar.1538 and Kernel-jar.1537 I'd be
very
grateful. > >I > > > >hope > > > > > >>>>this super long message at least makes some
sense :)
> > > > > >>>>Best, > > > > > >>>>Jaromir > > > > > >>>> > > > > > >>>>[1] Kernel-jar.1538, Kernel-jar.1537 > > > > > >>>>[2] KernelTests-jar.447 > > > > > >>>> > > > > > >>>> > > > > > >>>>PS: Christoph, > > > > > >>>> > > > > > >>>>With Kernel-jar.1538 + Kernel-jar.1537 your
example
> > > > > >>>> > > > > > >>>>process := > > > > > >>>> [(c := thisContext) pc: nil. > > > > > >>>> 2+3] newProcess. > > > > > >>>>process runUntil: [:ctx | ctx selector = #cannotReturn:]. > > > > > >>>>self assert: process suspendedContext sender
sender
= c.
> > > > > >>>>self assert: process suspendedContext arguments
=
{c}.
> > > > > >>>> > > > > > >>>>works fine, I've just corrected your first
assert.
> > > > > >>>> > > > > > >>>> > > > > > >>>> > > > > > >>>> > > > > > >>>> > > > > > >>>>On 21-Nov-23 6:40:32 PM, "Eliot Miranda" > > > ><eliot.miranda(a)gmail.com> > > > > > >>>>wrote: > > > > > >>>> > > > > > >>>>>Hi Jaromir, > > > > > >>>>> > > > > > >>>>>>On Nov 20, 2023, at 11:51 PM, Jaromir Matas > > > ><mail(a)jaromir.net> > > > > > >>>>>>wrote: > > > > > >>>>>> > > > > > >>>>>> > > > > > >>>>>>Hi Eliot, > > > > > >>>>>>Very elegant! Now I finally got what you meant
exactly
:) > > > >Thanks. > > > > > >>>>>> > > > > > >>>>>>Two questions: > > > > > >>>>>>1. in order for the enclosed test to work I'd
need
an
Error > > > > > >>>>>>instead of Processor debugWithTitle:full: call
in
> > > >#cannotReturn:. > > > > > >>>>>>Otherwise I don't know how to catch a plain
invocation
of > >the > > > > > >>>>>>Debugger: > > > > > >>>>>> > > > > > >>>>>>cannotReturn: result > > > > > >>>>>> > > > > > >>>>>> closureOrNil ifNotNil: [^ self cannotReturn:
result
to: > >self > > > > > >>>>>>home sender]. > > > > > >>>>>> self error: 'Computation has been
terminated!'
> > > > > >>>>> > > > > > >>>>>Much nicer. > > > > > >>>>> > > > > > >>>>>>2. We are capturing a pc of self which is
completely
> >different > > > > > >>>>>>context from homeContext indeed. > > > > > >>>>> > > > > > >>>>>Right. The return is attempted from a specific
return
> >bytecode > > > >in a > > > > > >>>>>specific block. This is the coordinate of the
return
that > >cannot > > > >be > > > > > >>>>>made. This is the relevant point of origin of
the
cannot > >return > > > > > >>>>>exception. > > > > > >>>>> > > > > > >>>>>Why the return fails is another matter: > > > > > >>>>>- the home context’s sender is a dead context
(cannot
be > > > >resumed) > > > > > >>>>>- the home context’s sender is nil (home
already
returned > >from) > > > > > >>>>>- the block activation’s home is nil rather
than a
context > > > >(should > > > > > >>>>>not happen) > > > > > >>>>> > > > > > >>>>>But in all these cases the pc of the home
context
is
> >immaterial. > > > > > >>>>>The hike is being returned through/from, rather
than
from; > >the > > > > > >>>>>home’s pc is not relevant. > > > > > >>>>> > > > > > >>>>>>Maybe we could capture self in the exception
too
to
make it > > > >more > > > > > >>>>>>clear/explicit what is going on: what context
the
captured > >pc > > > >is > > > > > >>>>>>actually associated with. Just a thought... > > > > > >>>>> > > > > > >>>>>Yes, I like that. I also like the idea of
somehow
passing > >the > > > > > >>>>>block activation’s pc to the debugger so that
the
relevant > > > >return > > > > > >>>>>expression is highlighted in the debugger. > > > > > >>>>> > > > > > >>>>>> > > > > > >>>>>>Thanks again, > > > > > >>>>>>Jaromir > > > > > >>>>> > > > > > >>>>>You’re welcome. I love working in this part of
the
system. > > > >Thanks > > > > > >>>>>for dragging me there. I’m in a slump right now
and
> >appreciate > > > >the > > > > > >>>>>fellowship. > > > > > >>>>> > > > > > >>>>>>------ Original Message ------ > > > > > >>>>>>From "Eliot Miranda"
<eliot.miranda(a)gmail.com>
> > > > > >>>>>>To "Jaromir Matas" <mail(a)jaromir.net> > > > > > >>>>>>Cc squeak-dev(a)lists.squeakfoundation.org > > > > > >>>>>>Date 11/21/2023 2:17:21 AM > > > > > >>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming
on
> > > >BlockCannotReturn > > > > > >>>>>>exception > > > > > >>>>>> > > > > > >>>>>>>Hi Jaromir, > > > > > >>>>>>> > > > > > >>>>>>> see Kernel-eem.1535 for what I was
suggesting.
This
> >example > > > > > >>>>>>>now has an exception with the right pc value
in
it:
> > > > > >>>>>>> > > > > > >>>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc
inspect.
ex > > > >resume]] > > > > > >>>>>>>fork > > > > > >>>>>>> > > > > > >>>>>>>The fix is simply > > > > > >>>>>>> > > > > > >>>>>>>Context>>cannotReturn: result to: homeContext > > > > > >>>>>>> "The receiver tried to return result to
homeContext
that > > > > > >>>>>>>cannot be returned from. > > > > > >>>>>>> Capture the return pc in a
BlockCannotReturn.
Nil
the pc > >to > > > > > >>>>>>>prevent repeat > > > > > >>>>>>> attempts and/or invalid continuation. Answer
the
result > >of > > > > > >>>>>>>raising the exception." > > > > > >>>>>>> > > > > > >>>>>>> | exception | > > > > > >>>>>>> exception := BlockCannotReturn new. > > > > > >>>>>>> exception > > > > > >>>>>>> result: result; > > > > > >>>>>>> deadHome: homeContext; > > > > > >>>>>>> pc: self previousPc. > > > > > >>>>>>> pc := nil. > > > > > >>>>>>> ^exception signal > > > > > >>>>>>> > > > > > >>>>>>> > > > > > >>>>>>>The VM crash is now avoided. The debugger
displays
the > >method, > > > > > >>>>>>>but does not highlight the offending pc,
which is
no
big > >deal. > > > >A > > > > > >>>>>>>suitable defaultHandler for B
lockCannotReturn
may be
able > >to > > > >get > > > > > >>>>>>>the debugger to highlight correctly on
opening.
Try
the > > > > > >>>>>>>following examples: > > > > > >>>>>>> > > > > > >>>>>>>[[^1] on: BlockCannotReturn do: #resume]
fork.
> > > > > >>>>>>> > > > > > >>>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc
inspect.
ex > > > >resume]] > > > > > >>>>>>>fork > > > > > >>>>>>> > > > > > >>>>>>>[[^1] value] fork. > > > > > >>>>>>> > > > > > >>>>>>>They al; seem to behave perfectly acceptably
to
me.
Does > >this > > > > > >>>>>>>fix work for you? > > > > > >>>>>>> > > > > > >>>>>>>On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas > > > ><mail(a)jaromir.net> > > > > > >>>>>>>wrote: > > > > > >>>>>>>>Hi Eliot, > > > > > >>>>>>>> > > > > > >>>>>>>>How about to nil the pc just before making
the
return: > > > > > >>>>>>>>``` > > > > > >>>>>>>>Context >> #cannotReturn: result > > > > > >>>>>>>> > > > > > >>>>>>>> self push: self pc. "backup the pc for the
sake
of
> > > > > >>>>>>>>debugging" > > > > > >>>>>>>> closureOrNil ifNotNil: [^self cannotReturn:
result
to: > >self > > > > > >>>>>>>>home sender; pc: nil]. > > > > > >>>>>>>> Processor debugWithTitle: 'Computation has
been
> >terminated!' > > > > > >>>>>>>>translated full: false > > > > > >>>>>>>>``` > > > > > >>>>>>>>The nilled pc should not even potentially
interfere
with > >the > > > > > >>>>>>>>#isDead now. > > > > > >>>>>>>> > > > > > >>>>>>>>I hope this is at least a step in the right direction :) > > > > > >>>>>>>> > > > > > >>>>>>>>However, there's still a problem when
debugging
the
> > > >resumption > > > > > >>>>>>>>of #cannotReturn because the encoders expect
a
reasonable > > > >index. > > > > > >>>>>>>>I haven't figured out yet where to place a
nil
check
> >#step, > > > > > >>>>>>>>#stepToSendOrReturn... ? > > > > > >>>>>>>> > > > > > >>>>>>>>Thanks again, > > > > > >>>>>>>>Jaromir > > > > > >>>>>>>> > > > > > >>>>>>>> > > > > > >>>>>>>>------ Original Message ------ > > > > > >>>>>>>>From "Eliot Miranda"
<eliot.miranda(a)gmail.com>
> > > > > >>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> > > > > > >>>>>>>>Date 11/17/2023 8:36:50 PM > > > > > >>>>>>>>Subject Re: [squeak-dev] Re: Resuming on > >BlockCannotReturn > > > > > >>>>>>>>exception > > > > > >>>>>>>> > > > > > >>>>>>>>>Hi Jaromir, > > > > > >>>>>>>>> > > > > > >>>>>>>>>>On Nov 17, 2023, at 7:05 AM, Jaromir Matas > > > ><mail(a)jaromir.net> > > > > > >>>>>>>>>>wrote: > > > > > >>>>>>>>>> > > > > > >>>>>>>>>> > > > > > >>>>>>>>>>Eliot, hi again, > > > > > >>>>>>>>>> > > > > > >>>>>>>>>>Please disregard my previous comment about
nilling
the > > > > > >>>>>>>>>>contexts that have returned. We are indeed
talking
> >about > > > >the > > > > > >>>>>>>>>>context directly under the #cannotReturn
context
which > >is > > > > > >>>>>>>>>>totally different from the home context in
another
> >thread > > > > > >>>>>>>>>>that's gone. > > > > > >>>>>>>>>> > > > > > >>>>>>>>>>I may still be confused but would nilling
the
pc
of the > > > > > >>>>>>>>>>context directly under the cannotReturn
context
help? > > > >Here's > > > > > >>>>>>>>>>what I mean: > > > > > >>>>>>>>>>``` > > > > > >>>>>>>>>>Context >> #cannotReturn: result > > > > > >>>>>>>>>> > > > > > >>>>>>>>>> closureOrNil ifNotNil: [^self pc: nil; cannotReturn: > > > > > >>>>>>>>>>result to: self home sender]. > > > > > >>>>>>>>>> Processor debugWithTitle: 'Computation
has
been
> > > > > >>>>>>>>>>terminated!' translated full: false. > > > > > >>>>>>>>>>``` > > > > > >>>>>>>>>>Instead of crashing the VM invokes the
debugger
with > >the > > > > > >>>>>>>>>>'Computation has been terminated!'
message.
> > > > > >>>>>>>>>> > > > > > >>>>>>>>>>Does this make sense? > > > > > >>>>>>>>> > > > > > >>>>>>>>>Nearly. But it loses the information on
what
the pc
> >actually > > > > > >>>>>>>>>is, and that’s potentially vital
information.
So
IMO the > >ox > > > > > >>>>>>>>>should only be nilled between the
BlockCannotReturn
> > > >exception > > > > > >>>>>>>>>being created and raised. > > > > > >>>>>>>>> > > > > > >>>>>>>>>[But if you try this don’t be surprised if
it
causes a > >few > > > > > >>>>>>>>>temporary problems. It looks to me that
without
a
little > > > > > >>>>>>>>>refactoring this could easily cause an
infinite
> >recursion > > > > > >>>>>>>>>around the sending of isDead. I’m sure
you’ll
be
able to > >fix > > > > > >>>>>>>>>the code to work correctly] > > > > > >>>>>>>>> > > > > > >>>>>>>>>>Thanks, > > > > > >>>>>>>>>>Jaromir > > > > > >>>>>>>>>> > > > > > >>>>>>>>>> > > > > > >>>>>>>>>>------ Original Message ------ > > > > > >>>>>>>>>>From "Jaromir Matas" <mail(a)jaromir.net> > > > > > >>>>>>>>>>To "Eliot Miranda"
<eliot.miranda(a)gmail.com>;
"The > > > > > >>>>>>>>>>general-purpose Squeak developers list" > > > > > >>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > > > > > >>>>>>>>>>Date 11/17/2023 10:15:17 AM > > > > > >>>>>>>>>>Subject [squeak-dev] Re: Resuming on BlockCannotReturn > > > > > >>>>>>>>>>exception > > > > > >>>>>>>>>> > > > > > >>>>>>>>>>>Hi Eliot, > > > > > >>>>>>>>>>> > > > > > >>>>>>>>>>> > > > > > >>>>>>>>>>> > > > > > >>>>>>>>>>>------ Original Message ------ > > > > > >>>>>>>>>>>From "Eliot Miranda"
<eliot.miranda(a)gmail.com>
> > > > > >>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> > > > > > >>>>>>>>>>>Cc "The general-purpose Squeak developers
list"
> > > > > >>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > > > > > >>>>>>>>>>>Date 11/16/2023 11:52:45 PM > > > > > >>>>>>>>>>>Subject Re: Re[2]: [squeak-dev] Re:
Resuming
on
> > > > > >>>>>>>>>>>BlockCannotReturn exception > > > > > >>>>>>>>>>> > > > > > >>>>>>>>>>>>Hi Jaromir, > > > > > >>>>>>>>>>>> > > > > > >>>>>>>>>>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir
Matas
> > > > > >>>>>>>>>>>><mail(a)jaromir.net> wrote: > > > > > >>>>>>>>>>>>>Hi Nicolas, Eliot, > > > > > >>>>>>>>>>>>> > > > > > >>>>>>>>>>>>>here's what I understand is happening
(see
the
> >enclosed > > > > > >>>>>>>>>>>>>screenshot): > > > > > >>>>>>>>>>>>> > > > > > >>>>>>>>>>>>>1) we fork a new process to evaluate
[^1]
> > > > > >>>>>>>>>>>>>2) the new process evaluates [^1] which
means
> > > >instruction > > > > > >>>>>>>>>>>>>18 is being evaluated, hence pc points
to
> >instruction 19 > > > > > >>>>>>>>>>>>>now > > > > > >>>>>>>>>>>>>3) however, the home context where ^1
should
return > >to > > > >is > > > > > >>>>>>>>>>>>>gone by this time (the process that
executed
the > >fork > > > >has > > > > > >>>>>>>>>>>>>already returned - notice the two up
arrows
in
the > > > >debugger > > > > > >>>>>>>>>>>>>screenshot) > > > > > >>>>>>>>>>>>>4) the VM can't finish the instruction
and
returns > > > >control > > > > > >>>>>>>>>>>>>to the image via placing the
#cannotReturn:
context > >on > > > >top > > > > > >>>>>>>>>>>>>of the [^1] context > > > > > >>>>>>>>>>>>>5) #cannotReturn: evaluation results in signalling > >the > > > >BCR > > > > > >>>>>>>>>>>>>exception which is then handled by the
#resume
> >handler > > > > > >>>>>>>>>>>>> (in our debugged case the [:ex | self
halt. ex
> >resume] > > > > > >>>>>>>>>>>>>handler) > > > > > >>>>>>>>>>>>>6) ex resume is evaluated, however,
this
means
> > > >requesting > > > > > >>>>>>>>>>>>>the VM to evaluate instruction 19 of
the
[^1]
> >context - > > > > > >>>>>>>>>>>>>which is past the last instruction of
the
context > >and > > > >the > > > > > >>>>>>>>>>>>>crash ensues > > > > > >>>>>>>>>>>>> > > > > > >>>>>>>>>>>>>I wonder whether such situations
could/should
be > > > >prevented > > > > > >>>>>>>>>>>>>inside the VM or whether such an
expectation is
> >wrong > > > >for > > > > > >>>>>>>>>>>>>some reason. > > > > > >>>>>>>>>>>> > > > > > >>>>>>>>>>>>As Nicolas says, IMO this is best done
at
the
image > > > >level. > > > > > >>>>>>>>>>>> > > > > > >>>>>>>>>>>>It could be prevented in the VM, but at
great
cost, > >and > > > >only > > > > > >>>>>>>>>>>>partially. The performance issue is that
the
last > > > >bytecode > > > > > >>>>>>>>>>>>in a method is not marked in any way,
and
that
to > > > >determine > > > > > >>>>>>>>>>>>the last bytecode the bytecodes must be symbolically > > > > > >>>>>>>>>>>>evaluated from the start of the method.
See
> >implementors > > > >of > > > > > >>>>>>>>>>>>endPC at the image level (which defer to
the
method > > > >trailer) > > > > > >>>>>>>>>>>>and implementors of endPCOf: in the
VMMaker
code. > >Doing > > > >this > > > > > >>>>>>>>>>>>every time execution commences is
prohibitively
> > > >expensive. > > > > > >>>>>>>>>>>>The "only partially" issue is that
following
the
> >return > > > > > >>>>>>>>>>>>instruction may be other valid
bytecodes,
but
these > >are > > > >not > > > > > >>>>>>>>>>>>a continuation. > > > > > >>>>>>>>>>>> > > > > > >>>>>>>>>>>> > > > > > >>>>>>>>>>>>Consider the following code in some
block:
> > > > > >>>>>>>>>>>> [self expression ifTrue: > > > > > >>>>>>>>>>>> [^1]. > > > > > >>>>>>>>>>>> ^2 > > > > > >>>>>>>>>>>> > > > > > >>>>>>>>>>>>The bytecodes for this are > > > > > >>>>>>>>>>>> pushReceiver > > > > > >>>>>>>>>>>> send #expression > > > > > >>>>>>>>>>>> jumpFalse L1 > > > > > >>>>>>>>>>>> push 1 > > > > > >>>>>>>>>>>> methodReturnTop > > > > > >>>>>>>>>>>>L1 > > > > > >>>>>>>>>>>> push 2 > > > > > >>>>>>>>>>>> methodReturnTop > > > > > >>>>>>>>>>>> > > > > > >>>>>>>>>>>>Clearly if expression is true these
should
be
*no* > > > > > >>>>>>>>>>>>continuation in which ^2 is executed. > > > > > >>>>>>>>>>> > > > > > >>>>>>>>>>>Well, in that case there's a bug because
the
> >computation > > > >in > > > > > >>>>>>>>>>>the following example shouldn't continue
past
the
[^1] > > > >block > > > > > >>>>>>>>>>>but it silently does: > > > > > >>>>>>>>>>>`[[true ifTrue: [^ 1]] on:
BlockCannotReturn
do:
> >#resume ] > > > > > >>>>>>>>>>>fork` > > > > > >>>>>>>>>>> > > > > > >>>>>>>>>>>The bytecodes are > > > > > >>>>>>>>>>> push true > > > > > >>>>>>>>>>> jumpFalse L1 > > > > > >>>>>>>>>>> push 1 > > > > > >>>>>>>>>>> returnTop > > > > > >>>>>>>>>>>L1 > > > > > >>>>>>>>>>> push nil > > > > > >>>>>>>>>>> blockReturn > > > > > >>>>>>>>>>> > > > > > >>>>>>>>>>> > > > > > >>>>>>>>>>> > > > > > >>>>>>>>>>>> > > > > > >>>>>>>>>>>>So even if the VM did try and detect
whether
the
> >return > > > >was > > > > > >>>>>>>>>>>>at the last block method, it would only
work
for
> >special > > > > > >>>>>>>>>>>>cases. > > > > > >>>>>>>>>>>> > > > > > >>>>>>>>>>>> > > > > > >>>>>>>>>>>>It seems to me the issue is simply that
the
context > >that > > > > > >>>>>>>>>>>>cannot be returned from should be marked
as
dead
(see > > > > > >>>>>>>>>>>>Context>>isDead) by setting its pc to
nil at
some > >point, > > > > > >>>>>>>>>>>>presumably after copying the actual
return
pc
into > >the > > > > > >>>>>>>>>>>>BlockCannotReturn exception, to avoid
ever
trying to > > > >resume > > > > > >>>>>>>>>>>>the context. > > > > > >>>>>>>>>>> > > > > > >>>>>>>>>>>Does this mean, in other words, that
every
context > >that > > > > > >>>>>>>>>>>returns should nil its pc to avoid being "wrongly" > > > > > >>>>>>>>>>>reused/executed in the future, which
concerns
> >primarily > > > >those > > > > > >>>>>>>>>>>being referenced somewhere hence
potentially
> >executable in > > > > > >>>>>>>>>>>the future, is that right? > > > > > >>>>>>>>>>>Hypothetical question: would nilling the
pc
during > >returns > > > > > >>>>>>>>>>>"fix" the example? > > > > > >>>>>>>>>>>Thanks a lot for helping me understand
this.
> > > > > >>>>>>>>>>>Best, > > > > > >>>>>>>>>>>Jaromir > > > > > >>>>>>>>>>> > > > > > >>>>>>>>>>> > > > > > >>>>>>>>>>> > > > > > >>>>>>>>>>>> > > > > > >>>>>>>>>>>> > > > > > >>>>>>>>>>>>> > > > > > >>>>>>>>>>>>>Thanks, > > > > > >>>>>>>>>>>>>Jaromir > > > > > >>>>>>>>>>>>> > > > > > >>>>>>>>>>>>><bdxuqalu.png> > > > > > >>>>>>>>>>>>> > > > > > >>>>>>>>>>>>>------ Original Message ------ > > > > > >>>>>>>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> > > > > > >>>>>>>>>>>>>To "Jaromir Matas"
<mail(a)jaromir.net>;
"The
> > > >general-purpose > > > > > >>>>>>>>>>>>>Squeak developers list" > > > > > >>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > > > > > >>>>>>>>>>>>>Date 11/16/2023 6:48:43 PM > > > > > >>>>>>>>>>>>>Subject Re: [squeak-dev] Re: Resuming
on
> > > >BlockCannotReturn > > > > > >>>>>>>>>>>>>exception > > > > > >>>>>>>>>>>>> > > > > > >>>>>>>>>>>>>>Hi Jaromir, > > > > > >>>>>>>>>>>>>> > > > > > >>>>>>>>>>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir
Matas
> > > > > >>>>>>>>>>>>>>><mail(a)jaromir.net> wrote: > > > > > >>>>>>>>>>>>>>> > > > > > >>>>>>>>>>>>>>> > > > > > >>>>>>>>>>>>>>>Hi Nicloas, > > > > > >>>>>>>>>>>>>>>No no, I don't have any practical
scenario in
> >mind, > > > >I'm > > > > > >>>>>>>>>>>>>>>just trying to understand why the VM
is
> >implemented > > > >like > > > > > >>>>>>>>>>>>>>>this, whether there were a reason to
leave
this > > > > > >>>>>>>>>>>>>>>possibility of a crash, e.g. it would
slow
down > >the VM > > > >to > > > > > >>>>>>>>>>>>>>>try to prevent such a dumb situation
(who
would > >resume > > > > > >>>>>>>>>>>>>>>from BCR in his right mind? :) ) - or
perhaps
I > >have > > > > > >>>>>>>>>>>>>>>overlooked some good reason to even
keep
this
> >behavior > > > >in > > > > > >>>>>>>>>>>>>>>the VM. That's all. > > > > > >>>>>>>>>>>>>> > > > > > >>>>>>>>>>>>>>Let’s first understand what’s really happening. > > > >Presumably > > > > > >>>>>>>>>>>>>>at tone point a context is resumed
those
pc is
> >already > > > >at > > > > > >>>>>>>>>>>>>>the block return bytecode
(effectively,
because it > > > >crashes > > > > > >>>>>>>>>>>>>>in JITted code, but I bet the stack vm
will
crash > >also, > > > > > >>>>>>>>>>>>>>but not as cleanly - it will try and
execute
the > >bytes > > > >in > > > > > >>>>>>>>>>>>>>the encoded method trailer). So which
method
> >actually > > > > > >>>>>>>>>>>>>>sends resume, and to what, and what
state
is
> >resume’s > > > > > >>>>>>>>>>>>>>receiver when resume is sent? > > > > > >>>>>>>>>>>>>> > > > > > >>>>>>>>>>>>>> > > > > > >>>>>>>>>>>>>>> > > > > > >>>>>>>>>>>>>>>Thanks for your reply. > > > > > >>>>>>>>>>>>>>>Regards, > > > > > >>>>>>>>>>>>>>>Jaromir > > > > > >>>>>>>>>>>>>>> > > > > > >>>>>>>>>>>>>>> > > > > > >>>>>>>>>>>>>>> > > > > > >>>>>>>>>>>>>>> > > > > > >>>>>>>>>>>>>>>------ Original Message ------ > > > > > >>>>>>>>>>>>>>>From "Nicolas Cellier" > > > > > >>>>>>>>>><nicolas.cellier.aka.nice(a)gmail.com> > > > > > >>>>>>>>>>>>>>>To "Jaromir Matas"
<mail(a)jaromir.net>;
"The
> > > > > >>>>>>>>>>>>>>>general-purpose Squeak developers
list"
> > > > > >>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > > > > > >>>>>>>>>>>>>>>Date 11/16/2023 7:20:20 AM > > > > > >>>>>>>>>>>>>>>Subject Re: [squeak-dev] Resuming on > >BlockCannotReturn > > > > > >>>>>>>>>>>>>>>exception > > > > > >>>>>>>>>>>>>>> > > > > > >>>>>>>>>>>>>>>>Hi Jaromir, > > > > > >>>>>>>>>>>>>>>>Is there a scenario where it would
make
sense to > > > >resume > > > > > >>>>>>>>>>>>>>>>a BlockCannotReturn? > > > > > >>>>>>>>>>>>>>>>If not, I would suggest to protect
at
image
side > >and > > > > > >>>>>>>>>>>>>>>>override #resume. > > > > > >>>>>>>>>>>>>>>> > > > > > >>>>>>>>>>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir
Matas
> > > > > >>>>>>>>>>>>>>>><mail(a)jaromir.net> a écrit : > > > > > >>>>>>>>>>>>>>>>>Hi Eliot, Christoph, All, > > > > > >>>>>>>>>>>>>>>>> > > > > > >>>>>>>>>>>>>>>>>It's known the following example
crashes
the VM. > >Is > > > > > >>>>>>>>>>>>>>>>>this an intended behavior or a
"tolerated
bug"? > > > > > >>>>>>>>>>>>>>>>> > > > > > >>>>>>>>>>>>>>>>>`[[^ 1] on: BlockCannotReturn do:
#resume]
fork` > > > > > >>>>>>>>>>>>>>>>> > > > > > >>>>>>>>>>>>>>>>>I understand why it crashes: the
non-local
> >return > > > >has > > > > > >>>>>>>>>>>>>>>>>nowhere to return to and so
resuming
the
> >computation > > > > > >>>>>>>>>>>>>>>>>leads to a crash. But why not raise
another
BCR > > > > > >>>>>>>>>>>>>>>>>exception to prevent the crash?
Potential
> >infinite > > > > > >>>>>>>>>>>>>>>>>loop? Perhaps I'm just missing the
purpose
of > >this > > > > > >>>>>>>>>>>>>>>>>behavior... > > > > > >>>>>>>>>>>>>>>>> > > > > > >>>>>>>>>>>>>>>>>Thanks for an explanation. > > > > > >>>>>>>>>>>>>>>>> > > > > > >>>>>>>>>>>>>>>>>Best, > > > > > >>>>>>>>>>>>>>>>>Jaromir > > > > > >>>>>>>>>>>>>>>>> > > > > > >>>>>>>>>>>>>>>>>-- > > > > > >>>>>>>>>>>>>>>>> > > > > > >>>>>>>>>>>>>>>>>Jaromir Matas > > > > > >>>>>>>>>>>>>>>>> > > > > > >>>>>>>>>>>>>>>>> > > > > > >>>>>>>>>>>>>>> > > > > > >>>>>>>>>>>> > > > > > >>>>>>>>>>>> > > > > > >>>>>>>>>>>>-- > > > > > >>>>>>>>>>>>_,,,^..^,,,_ > > > > > >>>>>>>>>>>>best, Eliot > > > > > >>>>>>>>>><Context-cannotReturn.st> > > > > > >>>>>>> > > > > > >>>>>>> > > > > > >>>>>>>-- > > > > > >>>>>>>_,,,^..^,,,_ > > > > > >>>>>>>best, Eliot > > > > > >>>>>><ProcessTest-testResumeAfterBCR.st>
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2024-01-03T23:44:30+00:00, mail@jaromir.net wrote:
Hi Christoph, sorry for confusing you :)
On 04-Jan-24 12:34:04 AM, christoph.thiede(a)student.hpi.uni-potsdam.de wrote:
Hi Jaromir,
On 2024-01-03T22:36:17+00:00, mail(a)jaromir.net wrote:
Hi Christoph,
On 02-Jan-24 8:05:31 PM,
christoph.thiede(a)student.hpi.uni-potsdam.de
wrote:
Hi Jaromir,
thanks for the clarification. If you don't mind I would still wait
for
a couple of days to see whether Eliot or Marcel or someone else who
are
longer aboard find anything against your change, but I have been convinced by you. :-) After that, we can merge your open test and eliminate the ifNil checks in the TraceDebugger and also in the penultimate line of Context>>#return:from:.
In general, some methods are "pure simulation" methods intended
to
mimic the VM behavior (#step etc) but nothing prevents one from
using
them for other purposes - like what #runUntilErrorOrReturnFrom: did:
to
just get rid of some contexts). Is it ok to do that? I tend to think it's not; it's confusing. That's why I made #stepToCalleeOrNil a private method because it's not a "true" simulation method but a
sort
of hybrid.
Yes, I think I understand your point here, the assumptions and use cases for #stepToCalleeOrNil are too special to expose it to
everyone.
Clients should mainly use #step, #stepToCallee, or maybe - with care
#runUntilErrorOrReturnFrom: to advance a context I think.
This is also why I checked Jakob's Git Browser and all tests seem
fine.
Wait, Squot is using code simulation?
I guess not, but as I noted, nothing prevents you from using
simulation
methods in the non-simulation code :) Plus, one might use simulation methods to prepare test scenarios... So I just ran the changes
through
Squot tests for good measure ;)
I still don't understand. :-) You ran the Squot test on the off chance that something in Squot or the Squot test uses code simulation?
Well, you can put it that way :) The more tests the better chance you catch something :D It happened a few times Pharo tests caught things Squeak didn't.
Got it! But chances might be very low in many situations ... There is even a distinct research topic on test prioritization. :D I guess I'm doing something roughly similar in the kernel tests for SimulationStudio and TraceDebugger, where I run a couple of selected test suites from trunk packages inside my simulators to catch any edge cases in their execution semantics ...
Or did you run the Squot tests inside the simulator? :D
Best, Christoph
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2024-01-02T11:25:57+00:00, mail(a)jaromir.net wrote:
Hi Christoph,
correct me if I'm wrong: with the corrected #step semantics (the #return:from: fix) one should no longer need to do things like:
self step ifNil: [^ self]
because #step should always return a context, even if attempting
to
step
to a nil context:
[] asContext step
In this case it correctly returns the #cannotReturn: context.
I've noticed these nil checks in Trace debugger's #doStepOver or #stepToHome.
I hope I haven't overlooked anything :)
Thanks for your thoughts, Jaromir
On 31-Dec-23 10:42:54 AM, "Jaromir Matas" <mail(a)jaromir.net>
wrote:
Hi Christoph,
Yes, that's exactly what I was talking about - the #return:from:
fix
changes slightly (perhaps it's better to say corrects) the
semantics
of
some stepping methods - #step and #stepToCallee, which allowed illegally stepping into a dead or nil context. They can no
longer be
used in the manner you showed. Another example was #runUntilErrorOrReturnFrom: - it used #stepToCallee this way so
as a
workaround I created the #stepToCalleeOrNil method and used in #runUntilErrorOrReturnFrom:
[ctxt isDead or: [topContext isNil]] whileFalse: [topContext := topContext stepToCalleeOrNil].
Theoretically there might be some external code (mis)using the incorrect stepping semantics. In Pharo's trunk they were mainly
tests
and #stepToHome but I haven't checked any external code. But all
their
tests are green with this change and I guess it's not
widespread.
This is also why I checked Jakob's Git Browser and all tests
seem
fine.
My opinion is to keep the correct simulation semantics and deal
with
potential consequences as/if they come. However I don't expect a
huge
impact as the change only affects border situations.
In general, some methods are "pure simulation" methods intended
to
mimic the VM behavior (#step etc) but nothing prevents one from
using
them for other purposes - like what #runUntilErrorOrReturnFrom:
did:
to
just get rid of some contexts). Is it ok to do that? I tend to
think
it's not; it's confusing. That's why I made #stepToCalleeOrNil a private method because it's not a "true" simulation method but a
sort
of hybrid.
What do you think?
Thanks for reviewing the fix! Best, Jaromir
On 30-Dec-23 11:07:54 PM,
christoph.thiede(a)student.hpi.uni-potsdam.de
wrote:
>Hi Jaromir, > >I found a breaking change in the new behavior of >Context>>#return:from: while using the TraceDebugger: > >In the past we could say: > >c:=[2+3]asContext. >[c]whileNotNil:[c:=cstep]. > >With your change, the script runs forever because the last step
does
>not answer nil as before but activates a new #cannotReturn:. > >This behavior seems not be expected anywhere in the trunk (if
my
first
>search was complete), and you are right that the new behavior
aligns
>closer to the VM behavior. Still, the old code seemed to
explicitly
>intend this - see the "newTop ifNotNil:" at the bottom of the
method.
> >I wonder whether we should keep this. For me it is not a big
deal;
I
>can just change my script like this: > >c:=[2+3]asContext. >[csenderisNiland:[cwillReturn]]whileNotNil:[c:=cstep]. > >I just wonder whether this could a breaking or unintended
change
for
>anything else. For [^2] ensure: [] it would not be a big deal,
we
>could just change the check in question to >(aSenderisDeador:[newTopnotNiland:[newTopisDead]])ifTrue:. I am >tending against restoring the old behavior, but I am unsure.
What
is
>your opinion on this? > >Best, >Christoph > >--- >Sent from Squeak Inbox Talk >https://github.com/hpi-swa-lab/squeak-inbox-talk > >On 2023-12-30T21:13:37+00:00, mail(a)jaromir.net wrote: > > > > nit: You mixed up the order of arguments for
#assert:equals:
> > > > oops, sorry :) It happens to me all the time; I've never
actually
> > understood why the strange, almost Yodaesque, order... as if
you
>asked > > in English: > > > > "Make sure 18 is his age." > > > > Thanks, > > Jaromir > > > > > > On 30-Dec-23 9:13:56 PM, >christoph.thiede(a)student.hpi.uni-potsdam.de > > wrote: > > > > >nit: You mixed up the order of arguments for
#assert:equals:
(it is
> > >assert: expected equals: actual) and could have used it in
the
>final > > >assert again, but that's clearly no reason to hold back a
useful
>test. > > >;-) Merged, thanks! :-) > > > > > >Best, > > >Christoph > > > > > >--- > > >Sent from Squeak Inbox Talk > > >https://github.com/hpi-swa-lab/squeak-inbox-talk > > > > > >On 2023-12-30T17:33:08+00:00, mail(a)jaromir.net wrote: > > > > > > > Hi Christoph, > > > > > > > > Thanks for merging the fixes; I've just sent another
test in
> > > > KernelTests-jar.448 to complement them. > > > > > > > > Please take a look and if ok I'd appreciate it if you
could
>merge it > > >as > > > > well. > > > > > > > > Best regards and Happy New Year to you too! > > > > Jaromir > > > > > > > > > > > > On 30-Dec-23 6:15:25 PM, > > >christoph.thiede(a)student.hpi.uni-potsdam.de > > > > wrote: > > > > > > > > >Hi Jaromir, hi all, > > > > > > > > > >finally I have found the time to review these
suggestions.
> > > > >Kernel-jar.1537, Kernel-jar.1538, and Kernel-jar.1539
look
>excellent > > >to > > > > >me as well. Clear, straightforward, useful. :-) I have
merged
>them > > >into > > > > >the trunk via Kernel-ct.1545. > > > > > > > > > >Regarding DebuggerTests>>test16HandleSimulationError, I
have
>patched > > >it > > > > >via ToolsTests-ct.125. Nothing to rack your brains
over:
> > >"thisContext > > > > >pc: nil" just mimicks any kind of unhandled error
inside
the
> > >simulator > > > > >- since we now gently handle this via #cannotReturn:, I
just
> > >replaced > > > > >it with "thisContext pc: false". :-) Sorry for not
clarifying
>that > > > > >earlier and letting you speculate. > > > > > > > > > >Thanks for your work, and I already wish you a happy
new
year!
> > > > > > > > > >Best, > > > > >Christoph > > > > > > > > > >--- > > > > >Sent from Squeak Inbox Talk > > > > >https://github.com/hpi-swa-lab/squeak-inbox-talk > > > > > > > > > >On 2023-11-29T13:31:09+00:00, mail(a)jaromir.net wrote: > > > > > > > > > > > Hi Marcel, > > > > > > > > > > > > > [myself] whether the patch would have been
necessary
>should the > > > > > > #return:from: had been fixed then > > > > > > > > > > > > Nonsense, I just mixed it up with another issue :) > > > > > > > > > > > > > > > > > > On 29-Nov-23 1:51:21 PM, "Jaromir Matas" ><mail(a)jaromir.net> > > >wrote: > > > > > > > > > > > > >Thanks Marcel! This test somehow slipped my
attention
:)
> > > > > > > > > > > > > >The test can no longer work as is. It takes
advantage
of
>the > > > > >erroneous > > > > > > >behavior of #return:from: in the sense that if you
simulate
> > > > > > > > > > > > > > thisContext pc: nil > > > > > > > > > > > > > >it'll happily return to a dead context (i.e. to
thisContext
>from > > > > >#pc: > > > > > > >nil context) - which is not what the VM does during >runtime. It > > > > >should > > > > > > >immediately raise an illegal return exception not
only
>during > > > > >runtime > > > > > > >but also during simulation. > > > > > > > > > > > > > >The test mentions a patch for an infinite debugger
chain
> > > > > > > >(http://forum.world.st/I-broke-the-debugger-td5110752.html).
I
> > > > >wonder > > > > > > >whether the problem could have something to do with
this
> > >simulation > > > > >bug > > > > > > >in return:from:; and a terrible idea occurred to me
whether
>the > > > > >patch > > > > > > >would have been necessary should the #return:from:
had
been
> > >fixed > > > > >then > > > > > > >;O > > > > > > > > > > > > > >We may potentially come up with more examples like
this,
>even in > > >the > > > > > > >trunk, where the bug from #return:from: propagated
and
was
>taken > > > > > > >advantage of. I've found and fixed >#runUntilErrorOrReturnFrom: > > >but > > > > >more > > > > > > >can still be surviving undetected... > > > > > > > > > > > > > >I'd place the test into #expectedFailures for now
but
maybe
>it's > > > > >time > > > > > > >to remove it; Christoph should decide :) > > > > > > > > > > > > > >Thanks again, > > > > > > >Jaromir > > > > > > > > > > > > > > > > > > > > >On 29-Nov-23 10:28:38 AM, "Taeumel, Marcel via
Squeak-dev"
> > > > > > ><squeak-dev(a)lists.squeakfoundation.org> wrote: > > > > > > > > > > > > > >>Hi Jaromir -- > > > > > > >> > > > > > > >>Looks good. Still, what about that >#test16HandleSimulationError > > > > >now? > > > > > > >>:-) It is failing with your changes ... how would
you
>adapt it? > > > > > > >> > > > > > > >> > > > > > > >> > > > > > > >>Best, > > > > > > >>Marcel > > > > > > >>>Am 28.11.2023 01:29:39 schrieb Jaromir Matas > > ><mail(a)jaromir.net>: > > > > > > >>> > > > > > > >>>Hi Eliot, Marcel, all, > > > > > > >>> > > > > > > >>>I've sent a fix Kernel-jar.1539 to the Inbox that
solves
>the > > > > > > >>>remaining bit of the chain of bugs described in
the
>previous > > >post. > > > > > > >>>All tests are green now and I think the root
cause
has
>been > > >found > > > > >and > > > > > > >>>fixed. > > > > > > >>> > > > > > > >>>In this last bit I've created a version of
stepToCallee
>that > > >would > > > > > > >>>identify a potential illegal return to a nil
sender
and
>avoid > > >it. > > > > > > >>> > > > > > > >>>Now this example can be debugged without any
problems:
> > > > > > >>> > > > > > > >>>[[self halt. ^ 1] on: BlockCannotReturn do:
#resume ]
>fork > > > > > > >>> > > > > > > >>>If you're happy with the solution in
Kernel-jar.1539,
> > > > > > >>>Kernel-jar.1538, Kernel-jar.1537 and the test in > > > > >KernelTests-jar.447, > > > > > > >>>could you please double-check and merge, please?
(And
>remove > > > > > > >>>Kernel-mt.1534 and Tools-jar.1240 from the Inbox) > > > > > > >>> > > > > > > >>>Best, > > > > > > >>>Jaromir > > > > > > >>> > > > > > > >>> > > > > > > >>> > > > > > > >>>On 27-Nov-23 12:09:37 AM, "Jaromir Matas" ><mail(a)jaromir.net> > > > > >wrote: > > > > > > >>> > > > > > > >>>>Hi Eliot, Christoph, all > > > > > > >>>> > > > > > > >>>>It looks like there are some more skeletons in
the
>closet :/ > > > > > > >>>> > > > > > > >>>>If you run this example > > > > > > >>>> > > > > > > >>>>[[self halt. ^ 1] on: BlockCannotReturn do: [:ex
|
ex
>resume] > > >] > > > > >fork > > > > > > >>>> > > > > > > >>>>and step over halt and then step over ^1 you get
a
> > >nonsensical > > > > >error > > > > > > >>>>as a result of decoding nil as an instruction. > > > > > > >>>> > > > > > > >>>>It turns out that the root cause is in the
#return:from:
> > >method: > > > > >it > > > > > > >>>>only checks whether aSender is dead but ignores
the
> > >possibility > > > > >that > > > > > > >>>>aSender sender may be nil or dead in which cases
the
VM
>also > > > > > > >>>>responds with sending #cannotReturn, hence I
assume
the
> > >simulator > > > > > > >>>>should do the same. In addition, the VM nills
the pc
in
>such > > > > > > >>>>scenario, so I added the same functionality here
too:
> > > > > > >>>> > > > > > > >>>>Context >> return: value from: aSender > > > > > > >>>> "For simulation. Roll back self to aSender and
return
>value > > > > > > >>>>from it. Execute any unwind blocks on the way.
ASSUMES
> > >aSender is > > > > > > >>>>a sender of self" > > > > > > >>>> > > > > > > >>>> | newTop | > > > > > > >>>> newTop := aSender sender. > > > > > > >>>> (aSender isDead or: [newTop isNil or: [newTop
isDead]])
> > >ifTrue: > > > > > > >>>> "<--------- this is extended ------" > > > > > > >>>> [^self pc: nil; send: #cannotReturn: to: self
with:
> > > > > > >>>>{value}]. "<------ pc: nil is added ----" > > > > > > >>>> (self findNextUnwindContextUpTo: newTop)
ifNotNil:
> > > > > > >>>> "Send #aboutToReturn:through: with nil as the
second
> > > > > > >>>>argument to avoid this bug: > > > > > > >>>> Cannot #stepOver '^2' in example '[^2] ensure:
[]'.
> > > > > > >>>> See > > > > > > > > > > > > > > >
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html > > > > > > > > > > > > > > >
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html" > > > > > > >>>> [^self send: #aboutToReturn:through: to: self
with:
>{value. > > > > > > >>>>nil}]. > > > > > > >>>> self releaseTo: newTop. > > > > > > >>>> newTop ifNotNil: [newTop push: value]. > > > > > > >>>> ^newTop > > > > > > >>>> > > > > > > >>>>In order for this to work #cannotReturn: has to
be
>modified > > >as in > > > > > > >>>>Kernel-jar.1537: > > > > > > >>>> > > > > > > >>>>Context >> cannotReturn: result > > > > > > >>>> > > > > > > >>>> closureOrNil ifNotNil: [^ self cannotReturn:
result
to:
>self > > > > > > >>>>home sender]. > > > > > > >>>> self error: 'Computation has been terminated!' > > > > > > >>>>"<----------- this has to be an Error -----" > > > > > > >>>> > > > > > > >>>>Then it almost works except when you keep
stepping
over
>in > > >the > > > > > > >>>>example above, you get an MNU error on `self
previousPc`
>in > > > > > > >>>>#cannotReturn:to:` with your solution of the VM
crash.
>If you > > > > >don't > > > > > > >>>>mind I've amended your solution and added the
final
>context > > >where > > > > > > >>>>the computation couldn't return along with the
pc:
> > > > > > >>>> > > > > > > >>>>Context >> cannotReturn: result to: homeContext > > > > > > >>>> "The receiver tried to return result to
homeContext
>that > > >cannot > > > > > > >>>>be returned from. > > > > > > >>>> Capture the return context/pc in a
BlockCannotReturn.
>Nil > > >the pc > > > > > > >>>>to prevent repeat > > > > > > >>>> attempts and/or invalid continuation. Answer
the
result
>of > > > > > > >>>>raising the exception." > > > > > > >>>> > > > > > > >>>> | exception previousPc | > > > > > > >>>> exception := BlockCannotReturn new. > > > > > > >>>> previousPc := pc ifNotNil: [self previousPc].
"<-----
>here's > > >a > > > > > > >>>>fix ----" > > > > > > >>>> exception > > > > > > >>>> result: result; > > > > > > >>>> deadHome: homeContext; > > > > > > >>>> finalContext: self; "<----- here's the new
state,
if
> > > > > > >>>>that's fine ----" > > > > > > >>>> pc: previousPc. > > > > > > >>>> pc := nil. > > > > > > >>>> ^exception signal > > > > > > >>>> > > > > > > >>>>Unfortunately, this is still not the end of the
story:
>there > > >are > > > > > > >>>>situations where #runUntilErrorOrReturnFrom:
places
the
>two > > >guard > > > > > > >>>>contexts below the bottom context. And that is a
problem
> > >because > > > > > > >>>>when the method tries to remove the two guard
contexts
>before > > > > > > >>>>returning at the end it uses #stepToCalee to do
the
job
>but > > >this > > > > > > >>>>unforotunately was (ab)using the above bug in >#return:from: - > > > > >I'll > > > > > > >>>>explain: #return:from: didn't check whether
aSender
>sender > > >was > > > > >nil > > > > > > >>>>and as a result it allowed to simulate a return
to a
>"nil > > > > >context" > > > > > > >>>>which was then (ab)used in the clean-up via
#stepToCalee
>in > > >the > > > > > > >>>>#runUntilErrorOrReturnFrom:. > > > > > > >>>> > > > > > > >>>>When I fixed the #return:from: bug, the > > > > >#runUntilErrorOrReturnFrom: > > > > > > >>>>cleanup of the guard contexts no longer works in
that
>very > > > > >special > > > > > > >>>>case where the guard contexts are below the
bottom
>context. > > > > >There's > > > > > > >>>>one case where this is being used:
#terminateAggresively
>by > > > > > > >>>>Christoph. > > > > > > >>>> > > > > > > >>>>If I'm right with this analysis, the > > >#runUntilErrorOrReturnFrom: > > > > > > >>>>should get fixed too but I'll be away now for a
few
days
>and > > >I > > > > >won't > > > > > > >>>>be able to respond. If you or Christoph had a
chance
to
>take > > >a > > > > >look > > > > > > >>>>at Kernel-jar.1538 and Kernel-jar.1537 I'd be
very
>grateful. > > >I > > > > >hope > > > > > > >>>>this super long message at least makes some
sense :)
> > > > > > >>>>Best, > > > > > > >>>>Jaromir > > > > > > >>>> > > > > > > >>>>[1] Kernel-jar.1538, Kernel-jar.1537 > > > > > > >>>>[2] KernelTests-jar.447 > > > > > > >>>> > > > > > > >>>> > > > > > > >>>>PS: Christoph, > > > > > > >>>> > > > > > > >>>>With Kernel-jar.1538 + Kernel-jar.1537 your
example
> > > > > > >>>> > > > > > > >>>>process := > > > > > > >>>> [(c := thisContext) pc: nil. > > > > > > >>>> 2+3] newProcess. > > > > > > >>>>process runUntil: [:ctx | ctx selector = >#cannotReturn:]. > > > > > > >>>>self assert: process suspendedContext sender
sender
= c.
> > > > > > >>>>self assert: process suspendedContext arguments
=
{c}.
> > > > > > >>>> > > > > > > >>>>works fine, I've just corrected your first
assert.
> > > > > > >>>> > > > > > > >>>> > > > > > > >>>> > > > > > > >>>> > > > > > > >>>> > > > > > > >>>>On 21-Nov-23 6:40:32 PM, "Eliot Miranda" > > > > ><eliot.miranda(a)gmail.com> > > > > > > >>>>wrote: > > > > > > >>>> > > > > > > >>>>>Hi Jaromir, > > > > > > >>>>> > > > > > > >>>>>>On Nov 20, 2023, at 11:51 PM, Jaromir Matas > > > > ><mail(a)jaromir.net> > > > > > > >>>>>>wrote: > > > > > > >>>>>> > > > > > > >>>>>> > > > > > > >>>>>>Hi Eliot, > > > > > > >>>>>>Very elegant! Now I finally got what you meant
exactly
>:) > > > > >Thanks. > > > > > > >>>>>> > > > > > > >>>>>>Two questions: > > > > > > >>>>>>1. in order for the enclosed test to work I'd
need
an
>Error > > > > > > >>>>>>instead of Processor debugWithTitle:full: call
in
> > > > >#cannotReturn:. > > > > > > >>>>>>Otherwise I don't know how to catch a plain
invocation
>of > > >the > > > > > > >>>>>>Debugger: > > > > > > >>>>>> > > > > > > >>>>>>cannotReturn: result > > > > > > >>>>>> > > > > > > >>>>>> closureOrNil ifNotNil: [^ self cannotReturn:
result
>to: > > >self > > > > > > >>>>>>home sender]. > > > > > > >>>>>> self error: 'Computation has been
terminated!'
> > > > > > >>>>> > > > > > > >>>>>Much nicer. > > > > > > >>>>> > > > > > > >>>>>>2. We are capturing a pc of self which is
completely
> > >different > > > > > > >>>>>>context from homeContext indeed. > > > > > > >>>>> > > > > > > >>>>>Right. The return is attempted from a specific
return
> > >bytecode > > > > >in a > > > > > > >>>>>specific block. This is the coordinate of the
return
>that > > >cannot > > > > >be > > > > > > >>>>>made. This is the relevant point of origin of
the
>cannot > > >return > > > > > > >>>>>exception. > > > > > > >>>>> > > > > > > >>>>>Why the return fails is another matter: > > > > > > >>>>>- the home context’s sender is a dead context
(cannot
>be > > > > >resumed) > > > > > > >>>>>- the home context’s sender is nil (home
already
>returned > > >from) > > > > > > >>>>>- the block activation’s home is nil rather
than a
>context > > > > >(should > > > > > > >>>>>not happen) > > > > > > >>>>> > > > > > > >>>>>But in all these cases the pc of the home
context
is
> > >immaterial. > > > > > > >>>>>The hike is being returned through/from, rather
than
>from; > > >the > > > > > > >>>>>home’s pc is not relevant. > > > > > > >>>>> > > > > > > >>>>>>Maybe we could capture self in the exception
too
to
>make it > > > > >more > > > > > > >>>>>>clear/explicit what is going on: what context
the
>captured > > >pc > > > > >is > > > > > > >>>>>>actually associated with. Just a thought... > > > > > > >>>>> > > > > > > >>>>>Yes, I like that. I also like the idea of
somehow
>passing > > >the > > > > > > >>>>>block activation’s pc to the debugger so that
the
>relevant > > > > >return > > > > > > >>>>>expression is highlighted in the debugger. > > > > > > >>>>> > > > > > > >>>>>> > > > > > > >>>>>>Thanks again, > > > > > > >>>>>>Jaromir > > > > > > >>>>> > > > > > > >>>>>You’re welcome. I love working in this part of
the
>system. > > > > >Thanks > > > > > > >>>>>for dragging me there. I’m in a slump right now
and
> > >appreciate > > > > >the > > > > > > >>>>>fellowship. > > > > > > >>>>> > > > > > > >>>>>>------ Original Message ------ > > > > > > >>>>>>From "Eliot Miranda"
<eliot.miranda(a)gmail.com>
> > > > > > >>>>>>To "Jaromir Matas" <mail(a)jaromir.net> > > > > > > >>>>>>Cc squeak-dev(a)lists.squeakfoundation.org > > > > > > >>>>>>Date 11/21/2023 2:17:21 AM > > > > > > >>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming
on
> > > > >BlockCannotReturn > > > > > > >>>>>>exception > > > > > > >>>>>> > > > > > > >>>>>>>Hi Jaromir, > > > > > > >>>>>>> > > > > > > >>>>>>> see Kernel-eem.1535 for what I was
suggesting.
This
> > >example > > > > > > >>>>>>>now has an exception with the right pc value
in
it:
> > > > > > >>>>>>> > > > > > > >>>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc
inspect.
>ex > > > > >resume]] > > > > > > >>>>>>>fork > > > > > > >>>>>>> > > > > > > >>>>>>>The fix is simply > > > > > > >>>>>>> > > > > > > >>>>>>>Context>>cannotReturn: result to: homeContext > > > > > > >>>>>>> "The receiver tried to return result to
homeContext
>that > > > > > > >>>>>>>cannot be returned from. > > > > > > >>>>>>> Capture the return pc in a
BlockCannotReturn.
Nil
>the pc > > >to > > > > > > >>>>>>>prevent repeat > > > > > > >>>>>>> attempts and/or invalid continuation. Answer
the
>result > > >of > > > > > > >>>>>>>raising the exception." > > > > > > >>>>>>> > > > > > > >>>>>>> | exception | > > > > > > >>>>>>> exception := BlockCannotReturn new. > > > > > > >>>>>>> exception > > > > > > >>>>>>> result: result; > > > > > > >>>>>>> deadHome: homeContext; > > > > > > >>>>>>> pc: self previousPc. > > > > > > >>>>>>> pc := nil. > > > > > > >>>>>>> ^exception signal > > > > > > >>>>>>> > > > > > > >>>>>>> > > > > > > >>>>>>>The VM crash is now avoided. The debugger
displays
>the > > >method, > > > > > > >>>>>>>but does not highlight the offending pc,
which is
no
>big > > >deal. > > > > >A > > > > > > >>>>>>>suitable defaultHandler for B
lockCannotReturn
may be
>able > > >to > > > > >get > > > > > > >>>>>>>the debugger to highlight correctly on
opening.
Try
>the > > > > > > >>>>>>>following examples: > > > > > > >>>>>>> > > > > > > >>>>>>>[[^1] on: BlockCannotReturn do: #resume]
fork.
> > > > > > >>>>>>> > > > > > > >>>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc
inspect.
>ex > > > > >resume]] > > > > > > >>>>>>>fork > > > > > > >>>>>>> > > > > > > >>>>>>>[[^1] value] fork. > > > > > > >>>>>>> > > > > > > >>>>>>>They al; seem to behave perfectly acceptably
to
me.
>Does > > >this > > > > > > >>>>>>>fix work for you? > > > > > > >>>>>>> > > > > > > >>>>>>>On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas > > > > ><mail(a)jaromir.net> > > > > > > >>>>>>>wrote: > > > > > > >>>>>>>>Hi Eliot, > > > > > > >>>>>>>> > > > > > > >>>>>>>>How about to nil the pc just before making
the
>return: > > > > > > >>>>>>>>``` > > > > > > >>>>>>>>Context >> #cannotReturn: result > > > > > > >>>>>>>> > > > > > > >>>>>>>> self push: self pc. "backup the pc for the
sake
of
> > > > > > >>>>>>>>debugging" > > > > > > >>>>>>>> closureOrNil ifNotNil: [^self cannotReturn:
result
>to: > > >self > > > > > > >>>>>>>>home sender; pc: nil]. > > > > > > >>>>>>>> Processor debugWithTitle: 'Computation has
been
> > >terminated!' > > > > > > >>>>>>>>translated full: false > > > > > > >>>>>>>>``` > > > > > > >>>>>>>>The nilled pc should not even potentially
interfere
>with > > >the > > > > > > >>>>>>>>#isDead now. > > > > > > >>>>>>>> > > > > > > >>>>>>>>I hope this is at least a step in the right >direction :) > > > > > > >>>>>>>> > > > > > > >>>>>>>>However, there's still a problem when
debugging
the
> > > > >resumption > > > > > > >>>>>>>>of #cannotReturn because the encoders expect
a
>reasonable > > > > >index. > > > > > > >>>>>>>>I haven't figured out yet where to place a
nil
check
>- > > >#step, > > > > > > >>>>>>>>#stepToSendOrReturn... ? > > > > > > >>>>>>>> > > > > > > >>>>>>>>Thanks again, > > > > > > >>>>>>>>Jaromir > > > > > > >>>>>>>> > > > > > > >>>>>>>> > > > > > > >>>>>>>>------ Original Message ------ > > > > > > >>>>>>>>From "Eliot Miranda"
<eliot.miranda(a)gmail.com>
> > > > > > >>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> > > > > > > >>>>>>>>Date 11/17/2023 8:36:50 PM > > > > > > >>>>>>>>Subject Re: [squeak-dev] Re: Resuming on > > >BlockCannotReturn > > > > > > >>>>>>>>exception > > > > > > >>>>>>>> > > > > > > >>>>>>>>>Hi Jaromir, > > > > > > >>>>>>>>> > > > > > > >>>>>>>>>>On Nov 17, 2023, at 7:05 AM, Jaromir Matas > > > > ><mail(a)jaromir.net> > > > > > > >>>>>>>>>>wrote: > > > > > > >>>>>>>>>> > > > > > > >>>>>>>>>> > > > > > > >>>>>>>>>>Eliot, hi again, > > > > > > >>>>>>>>>> > > > > > > >>>>>>>>>>Please disregard my previous comment about
nilling
>the > > > > > > >>>>>>>>>>contexts that have returned. We are indeed
talking
> > >about > > > > >the > > > > > > >>>>>>>>>>context directly under the #cannotReturn
context
>which > > >is > > > > > > >>>>>>>>>>totally different from the home context in
another
> > >thread > > > > > > >>>>>>>>>>that's gone. > > > > > > >>>>>>>>>> > > > > > > >>>>>>>>>>I may still be confused but would nilling
the
pc
>of the > > > > > > >>>>>>>>>>context directly under the cannotReturn
context
>help? > > > > >Here's > > > > > > >>>>>>>>>>what I mean: > > > > > > >>>>>>>>>>``` > > > > > > >>>>>>>>>>Context >> #cannotReturn: result > > > > > > >>>>>>>>>> > > > > > > >>>>>>>>>> closureOrNil ifNotNil: [^self pc: nil; >cannotReturn: > > > > > > >>>>>>>>>>result to: self home sender]. > > > > > > >>>>>>>>>> Processor debugWithTitle: 'Computation
has
been
> > > > > > >>>>>>>>>>terminated!' translated full: false. > > > > > > >>>>>>>>>>``` > > > > > > >>>>>>>>>>Instead of crashing the VM invokes the
debugger
>with > > >the > > > > > > >>>>>>>>>>'Computation has been terminated!'
message.
> > > > > > >>>>>>>>>> > > > > > > >>>>>>>>>>Does this make sense? > > > > > > >>>>>>>>> > > > > > > >>>>>>>>>Nearly. But it loses the information on
what
the pc
> > >actually > > > > > > >>>>>>>>>is, and that’s potentially vital
information.
So
>IMO the > > >ox > > > > > > >>>>>>>>>should only be nilled between the
BlockCannotReturn
> > > > >exception > > > > > > >>>>>>>>>being created and raised. > > > > > > >>>>>>>>> > > > > > > >>>>>>>>>[But if you try this don’t be surprised if
it
>causes a > > >few > > > > > > >>>>>>>>>temporary problems. It looks to me that
without
a
>little > > > > > > >>>>>>>>>refactoring this could easily cause an
infinite
> > >recursion > > > > > > >>>>>>>>>around the sending of isDead. I’m sure
you’ll
be
>able to > > >fix > > > > > > >>>>>>>>>the code to work correctly] > > > > > > >>>>>>>>> > > > > > > >>>>>>>>>>Thanks, > > > > > > >>>>>>>>>>Jaromir > > > > > > >>>>>>>>>> > > > > > > >>>>>>>>>> > > > > > > >>>>>>>>>>------ Original Message ------ > > > > > > >>>>>>>>>>From "Jaromir Matas" <mail(a)jaromir.net> > > > > > > >>>>>>>>>>To "Eliot Miranda"
<eliot.miranda(a)gmail.com>;
>"The > > > > > > >>>>>>>>>>general-purpose Squeak developers list" > > > > > > >>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > > > > > > >>>>>>>>>>Date 11/17/2023 10:15:17 AM > > > > > > >>>>>>>>>>Subject [squeak-dev] Re: Resuming on >BlockCannotReturn > > > > > > >>>>>>>>>>exception > > > > > > >>>>>>>>>> > > > > > > >>>>>>>>>>>Hi Eliot, > > > > > > >>>>>>>>>>> > > > > > > >>>>>>>>>>> > > > > > > >>>>>>>>>>> > > > > > > >>>>>>>>>>>------ Original Message ------ > > > > > > >>>>>>>>>>>From "Eliot Miranda"
<eliot.miranda(a)gmail.com>
> > > > > > >>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> > > > > > > >>>>>>>>>>>Cc "The general-purpose Squeak developers
list"
> > > > > > >>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > > > > > > >>>>>>>>>>>Date 11/16/2023 11:52:45 PM > > > > > > >>>>>>>>>>>Subject Re: Re[2]: [squeak-dev] Re:
Resuming
on
> > > > > > >>>>>>>>>>>BlockCannotReturn exception > > > > > > >>>>>>>>>>> > > > > > > >>>>>>>>>>>>Hi Jaromir, > > > > > > >>>>>>>>>>>> > > > > > > >>>>>>>>>>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir
Matas
> > > > > > >>>>>>>>>>>><mail(a)jaromir.net> wrote: > > > > > > >>>>>>>>>>>>>Hi Nicolas, Eliot, > > > > > > >>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>>here's what I understand is happening
(see
the
> > >enclosed > > > > > > >>>>>>>>>>>>>screenshot): > > > > > > >>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>>1) we fork a new process to evaluate
[^1]
> > > > > > >>>>>>>>>>>>>2) the new process evaluates [^1] which
means
> > > > >instruction > > > > > > >>>>>>>>>>>>>18 is being evaluated, hence pc points
to
> > >instruction 19 > > > > > > >>>>>>>>>>>>>now > > > > > > >>>>>>>>>>>>>3) however, the home context where ^1
should
>return > > >to > > > > >is > > > > > > >>>>>>>>>>>>>gone by this time (the process that
executed
>the > > >fork > > > > >has > > > > > > >>>>>>>>>>>>>already returned - notice the two up
arrows
in
>the > > > > >debugger > > > > > > >>>>>>>>>>>>>screenshot) > > > > > > >>>>>>>>>>>>>4) the VM can't finish the instruction
and
>returns > > > > >control > > > > > > >>>>>>>>>>>>>to the image via placing the
#cannotReturn:
>context > > >on > > > > >top > > > > > > >>>>>>>>>>>>>of the [^1] context > > > > > > >>>>>>>>>>>>>5) #cannotReturn: evaluation results in >signalling > > >the > > > > >BCR > > > > > > >>>>>>>>>>>>>exception which is then handled by the
#resume
> > >handler > > > > > > >>>>>>>>>>>>> (in our debugged case the [:ex | self
halt. ex
> > >resume] > > > > > > >>>>>>>>>>>>>handler) > > > > > > >>>>>>>>>>>>>6) ex resume is evaluated, however,
this
means
> > > > >requesting > > > > > > >>>>>>>>>>>>>the VM to evaluate instruction 19 of
the
[^1]
> > >context - > > > > > > >>>>>>>>>>>>>which is past the last instruction of
the
>context > > >and > > > > >the > > > > > > >>>>>>>>>>>>>crash ensues > > > > > > >>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>>I wonder whether such situations
could/should
>be > > > > >prevented > > > > > > >>>>>>>>>>>>>inside the VM or whether such an
expectation is
> > >wrong > > > > >for > > > > > > >>>>>>>>>>>>>some reason. > > > > > > >>>>>>>>>>>> > > > > > > >>>>>>>>>>>>As Nicolas says, IMO this is best done
at
the
>image > > > > >level. > > > > > > >>>>>>>>>>>> > > > > > > >>>>>>>>>>>>It could be prevented in the VM, but at
great
>cost, > > >and > > > > >only > > > > > > >>>>>>>>>>>>partially. The performance issue is that
the
>last > > > > >bytecode > > > > > > >>>>>>>>>>>>in a method is not marked in any way,
and
that
>to > > > > >determine > > > > > > >>>>>>>>>>>>the last bytecode the bytecodes must be >symbolically > > > > > > >>>>>>>>>>>>evaluated from the start of the method.
See
> > >implementors > > > > >of > > > > > > >>>>>>>>>>>>endPC at the image level (which defer to
the
>method > > > > >trailer) > > > > > > >>>>>>>>>>>>and implementors of endPCOf: in the
VMMaker
>code. > > >Doing > > > > >this > > > > > > >>>>>>>>>>>>every time execution commences is
prohibitively
> > > > >expensive. > > > > > > >>>>>>>>>>>>The "only partially" issue is that
following
the
> > >return > > > > > > >>>>>>>>>>>>instruction may be other valid
bytecodes,
but
>these > > >are > > > > >not > > > > > > >>>>>>>>>>>>a continuation. > > > > > > >>>>>>>>>>>> > > > > > > >>>>>>>>>>>> > > > > > > >>>>>>>>>>>>Consider the following code in some
block:
> > > > > > >>>>>>>>>>>> [self expression ifTrue: > > > > > > >>>>>>>>>>>> [^1]. > > > > > > >>>>>>>>>>>> ^2 > > > > > > >>>>>>>>>>>> > > > > > > >>>>>>>>>>>>The bytecodes for this are > > > > > > >>>>>>>>>>>> pushReceiver > > > > > > >>>>>>>>>>>> send #expression > > > > > > >>>>>>>>>>>> jumpFalse L1 > > > > > > >>>>>>>>>>>> push 1 > > > > > > >>>>>>>>>>>> methodReturnTop > > > > > > >>>>>>>>>>>>L1 > > > > > > >>>>>>>>>>>> push 2 > > > > > > >>>>>>>>>>>> methodReturnTop > > > > > > >>>>>>>>>>>> > > > > > > >>>>>>>>>>>>Clearly if expression is true these
should
be
>*no* > > > > > > >>>>>>>>>>>>continuation in which ^2 is executed. > > > > > > >>>>>>>>>>> > > > > > > >>>>>>>>>>>Well, in that case there's a bug because
the
> > >computation > > > > >in > > > > > > >>>>>>>>>>>the following example shouldn't continue
past
the
>[^1] > > > > >block > > > > > > >>>>>>>>>>>but it silently does: > > > > > > >>>>>>>>>>>`[[true ifTrue: [^ 1]] on:
BlockCannotReturn
do:
> > >#resume ] > > > > > > >>>>>>>>>>>fork` > > > > > > >>>>>>>>>>> > > > > > > >>>>>>>>>>>The bytecodes are > > > > > > >>>>>>>>>>> push true > > > > > > >>>>>>>>>>> jumpFalse L1 > > > > > > >>>>>>>>>>> push 1 > > > > > > >>>>>>>>>>> returnTop > > > > > > >>>>>>>>>>>L1 > > > > > > >>>>>>>>>>> push nil > > > > > > >>>>>>>>>>> blockReturn > > > > > > >>>>>>>>>>> > > > > > > >>>>>>>>>>> > > > > > > >>>>>>>>>>> > > > > > > >>>>>>>>>>>> > > > > > > >>>>>>>>>>>>So even if the VM did try and detect
whether
the
> > >return > > > > >was > > > > > > >>>>>>>>>>>>at the last block method, it would only
work
for
> > >special > > > > > > >>>>>>>>>>>>cases. > > > > > > >>>>>>>>>>>> > > > > > > >>>>>>>>>>>> > > > > > > >>>>>>>>>>>>It seems to me the issue is simply that
the
>context > > >that > > > > > > >>>>>>>>>>>>cannot be returned from should be marked
as
dead
>(see > > > > > > >>>>>>>>>>>>Context>>isDead) by setting its pc to
nil at
>some > > >point, > > > > > > >>>>>>>>>>>>presumably after copying the actual
return
pc
>into > > >the > > > > > > >>>>>>>>>>>>BlockCannotReturn exception, to avoid
ever
>trying to > > > > >resume > > > > > > >>>>>>>>>>>>the context. > > > > > > >>>>>>>>>>> > > > > > > >>>>>>>>>>>Does this mean, in other words, that
every
>context > > >that > > > > > > >>>>>>>>>>>returns should nil its pc to avoid being >"wrongly" > > > > > > >>>>>>>>>>>reused/executed in the future, which
concerns
> > >primarily > > > > >those > > > > > > >>>>>>>>>>>being referenced somewhere hence
potentially
> > >executable in > > > > > > >>>>>>>>>>>the future, is that right? > > > > > > >>>>>>>>>>>Hypothetical question: would nilling the
pc
>during > > >returns > > > > > > >>>>>>>>>>>"fix" the example? > > > > > > >>>>>>>>>>>Thanks a lot for helping me understand
this.
> > > > > > >>>>>>>>>>>Best, > > > > > > >>>>>>>>>>>Jaromir > > > > > > >>>>>>>>>>> > > > > > > >>>>>>>>>>> > > > > > > >>>>>>>>>>> > > > > > > >>>>>>>>>>>> > > > > > > >>>>>>>>>>>> > > > > > > >>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>>Thanks, > > > > > > >>>>>>>>>>>>>Jaromir > > > > > > >>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>><bdxuqalu.png> > > > > > > >>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>>------ Original Message ------ > > > > > > >>>>>>>>>>>>>From "Eliot Miranda" ><eliot.miranda(a)gmail.com> > > > > > > >>>>>>>>>>>>>To "Jaromir Matas"
<mail(a)jaromir.net>;
"The
> > > > >general-purpose > > > > > > >>>>>>>>>>>>>Squeak developers list" > > > > > > >>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > > > > > > >>>>>>>>>>>>>Date 11/16/2023 6:48:43 PM > > > > > > >>>>>>>>>>>>>Subject Re: [squeak-dev] Re: Resuming
on
> > > > >BlockCannotReturn > > > > > > >>>>>>>>>>>>>exception > > > > > > >>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>>>Hi Jaromir, > > > > > > >>>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir
Matas
> > > > > > >>>>>>>>>>>>>>><mail(a)jaromir.net> wrote: > > > > > > >>>>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>>>>Hi Nicloas, > > > > > > >>>>>>>>>>>>>>>No no, I don't have any practical
scenario in
> > >mind, > > > > >I'm > > > > > > >>>>>>>>>>>>>>>just trying to understand why the VM
is
> > >implemented > > > > >like > > > > > > >>>>>>>>>>>>>>>this, whether there were a reason to
leave
>this > > > > > > >>>>>>>>>>>>>>>possibility of a crash, e.g. it would
slow
>down > > >the VM > > > > >to > > > > > > >>>>>>>>>>>>>>>try to prevent such a dumb situation
(who
>would > > >resume > > > > > > >>>>>>>>>>>>>>>from BCR in his right mind? :) ) - or
perhaps
>I > > >have > > > > > > >>>>>>>>>>>>>>>overlooked some good reason to even
keep
this
> > >behavior > > > > >in > > > > > > >>>>>>>>>>>>>>>the VM. That's all. > > > > > > >>>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>>>Let’s first understand what’s really >happening. > > > > >Presumably > > > > > > >>>>>>>>>>>>>>at tone point a context is resumed
those
pc is
> > >already > > > > >at > > > > > > >>>>>>>>>>>>>>the block return bytecode
(effectively,
>because it > > > > >crashes > > > > > > >>>>>>>>>>>>>>in JITted code, but I bet the stack vm
will
>crash > > >also, > > > > > > >>>>>>>>>>>>>>but not as cleanly - it will try and
execute
>the > > >bytes > > > > >in > > > > > > >>>>>>>>>>>>>>the encoded method trailer). So which
method
> > >actually > > > > > > >>>>>>>>>>>>>>sends resume, and to what, and what
state
is
> > >resume’s > > > > > > >>>>>>>>>>>>>>receiver when resume is sent? > > > > > > >>>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>>>>Thanks for your reply. > > > > > > >>>>>>>>>>>>>>>Regards, > > > > > > >>>>>>>>>>>>>>>Jaromir > > > > > > >>>>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>>>>------ Original Message ------ > > > > > > >>>>>>>>>>>>>>>From "Nicolas Cellier" > > > > > > >>>>>>>>>>><nicolas.cellier.aka.nice(a)gmail.com> > > > > > > >>>>>>>>>>>>>>>To "Jaromir Matas"
<mail(a)jaromir.net>;
"The
> > > > > > >>>>>>>>>>>>>>>general-purpose Squeak developers
list"
> > > > > > >>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > > > > > > >>>>>>>>>>>>>>>Date 11/16/2023 7:20:20 AM > > > > > > >>>>>>>>>>>>>>>Subject Re: [squeak-dev] Resuming on > > >BlockCannotReturn > > > > > > >>>>>>>>>>>>>>>exception > > > > > > >>>>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>>>>>Hi Jaromir, > > > > > > >>>>>>>>>>>>>>>>Is there a scenario where it would
make
>sense to > > > > >resume > > > > > > >>>>>>>>>>>>>>>>a BlockCannotReturn? > > > > > > >>>>>>>>>>>>>>>>If not, I would suggest to protect
at
image
>side > > >and > > > > > > >>>>>>>>>>>>>>>>override #resume. > > > > > > >>>>>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir
Matas
> > > > > > >>>>>>>>>>>>>>>><mail(a)jaromir.net> a écrit : > > > > > > >>>>>>>>>>>>>>>>>Hi Eliot, Christoph, All, > > > > > > >>>>>>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>>>>>>It's known the following example
crashes
>the VM. > > >Is > > > > > > >>>>>>>>>>>>>>>>>this an intended behavior or a
"tolerated
>bug"? > > > > > > >>>>>>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>>>>>>`[[^ 1] on: BlockCannotReturn do:
#resume]
>fork` > > > > > > >>>>>>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>>>>>>I understand why it crashes: the
non-local
> > >return > > > > >has > > > > > > >>>>>>>>>>>>>>>>>nowhere to return to and so
resuming
the
> > >computation > > > > > > >>>>>>>>>>>>>>>>>leads to a crash. But why not raise
another
>BCR > > > > > > >>>>>>>>>>>>>>>>>exception to prevent the crash?
Potential
> > >infinite > > > > > > >>>>>>>>>>>>>>>>>loop? Perhaps I'm just missing the
purpose
>of > > >this > > > > > > >>>>>>>>>>>>>>>>>behavior... > > > > > > >>>>>>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>>>>>>Thanks for an explanation. > > > > > > >>>>>>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>>>>>>Best, > > > > > > >>>>>>>>>>>>>>>>>Jaromir > > > > > > >>>>>>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>>>>>>-- > > > > > > >>>>>>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>>>>>>Jaromir Matas > > > > > > >>>>>>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>>>>>> > > > > > > >>>>>>>>>>>>>>> > > > > > > >>>>>>>>>>>> > > > > > > >>>>>>>>>>>> > > > > > > >>>>>>>>>>>>-- > > > > > > >>>>>>>>>>>>_,,,^..^,,,_ > > > > > > >>>>>>>>>>>>best, Eliot > > > > > > >>>>>>>>>><Context-cannotReturn.st> > > > > > > >>>>>>> > > > > > > >>>>>>> > > > > > > >>>>>>>-- > > > > > > >>>>>>>_,,,^..^,,,_ > > > > > > >>>>>>>best, Eliot > > > > > > >>>>>><ProcessTest-testResumeAfterBCR.st>
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
Best, Christoph
--- Sent from Squeak Inbox Talk
Hi Jaromir,
I have merged KernelTests-jar.449 into the trunk and also removed the redundant nil checks in the TraceDebugger. :-)
Best, Christoph
--- Sent from Squeak Inbox Talk
On 2024-01-02T20:05:31+01:00, christoph.thiede@student.hpi.uni-potsdam.de wrote:
Hi Jaromir,
thanks for the clarification. If you don't mind I would still wait for a couple of days to see whether Eliot or Marcel or someone else who are longer aboard find anything against your change, but I have been convinced by you. :-) After that, we can merge your open test and eliminate the ifNil checks in the TraceDebugger and also in the penultimate line of Context>>#return:from:.
In general, some methods are "pure simulation" methods intended to mimic the VM behavior (#step etc) but nothing prevents one from using them for other purposes - like what #runUntilErrorOrReturnFrom: did: to just get rid of some contexts). Is it ok to do that? I tend to think it's not; it's confusing. That's why I made #stepToCalleeOrNil a private method because it's not a "true" simulation method but a sort of hybrid.
Yes, I think I understand your point here, the assumptions and use cases for #stepToCalleeOrNil are too special to expose it to everyone. Clients should mainly use #step, #stepToCallee, or maybe - with care - #runUntilErrorOrReturnFrom: to advance a context I think.
This is also why I checked Jakob's Git Browser and all tests seem fine.
Wait, Squot is using code simulation?
Best, Christoph
Sent from Squeak Inbox Talk
On 2024-01-02T11:25:57+00:00, mail(a)jaromir.net wrote:
Hi Christoph,
correct me if I'm wrong: with the corrected #step semantics (the #return:from: fix) one should no longer need to do things like:
self step ifNil: [^ self]
because #step should always return a context, even if attempting to step to a nil context:
[] asContext step
In this case it correctly returns the #cannotReturn: context.
I've noticed these nil checks in Trace debugger's #doStepOver or #stepToHome.
I hope I haven't overlooked anything :)
Thanks for your thoughts, Jaromir
On 31-Dec-23 10:42:54 AM, "Jaromir Matas" <mail(a)jaromir.net> wrote:
Hi Christoph,
Yes, that's exactly what I was talking about - the #return:from: fix changes slightly (perhaps it's better to say corrects) the semantics of some stepping methods - #step and #stepToCallee, which allowed illegally stepping into a dead or nil context. They can no longer be used in the manner you showed. Another example was #runUntilErrorOrReturnFrom: - it used #stepToCallee this way so as a workaround I created the #stepToCalleeOrNil method and used in #runUntilErrorOrReturnFrom:
[ctxt isDead or: [topContext isNil]] whileFalse: [topContext := topContext stepToCalleeOrNil].
Theoretically there might be some external code (mis)using the incorrect stepping semantics. In Pharo's trunk they were mainly tests and #stepToHome but I haven't checked any external code. But all their tests are green with this change and I guess it's not widespread.
This is also why I checked Jakob's Git Browser and all tests seem fine.
My opinion is to keep the correct simulation semantics and deal with potential consequences as/if they come. However I don't expect a huge impact as the change only affects border situations.
In general, some methods are "pure simulation" methods intended to mimic the VM behavior (#step etc) but nothing prevents one from using them for other purposes - like what #runUntilErrorOrReturnFrom: did: to just get rid of some contexts). Is it ok to do that? I tend to think it's not; it's confusing. That's why I made #stepToCalleeOrNil a private method because it's not a "true" simulation method but a sort of hybrid.
What do you think?
Thanks for reviewing the fix! Best, Jaromir
On 30-Dec-23 11:07:54 PM, christoph.thiede(a)student.hpi.uni-potsdam.de wrote:
Hi Jaromir,
I found a breaking change in the new behavior of Context>>#return:from: while using the TraceDebugger:
In the past we could say:
c:=[2+3]asContext. [c]whileNotNil:[c:=cstep].
With your change, the script runs forever because the last step does not answer nil as before but activates a new #cannotReturn:.
This behavior seems not be expected anywhere in the trunk (if my first search was complete), and you are right that the new behavior aligns closer to the VM behavior. Still, the old code seemed to explicitly intend this - see the "newTop ifNotNil:" at the bottom of the method.
I wonder whether we should keep this. For me it is not a big deal; I can just change my script like this:
c:=[2+3]asContext. [csenderisNiland:[cwillReturn]]whileNotNil:[c:=cstep].
I just wonder whether this could a breaking or unintended change for anything else. For [^2] ensure: [] it would not be a big deal, we could just change the check in question to (aSenderisDeador:[newTopnotNiland:[newTopisDead]])ifTrue:. I am tending against restoring the old behavior, but I am unsure. What is your opinion on this?
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-12-30T21:13:37+00:00, mail(a)jaromir.net wrote:
nit: You mixed up the order of arguments for #assert:equals:
oops, sorry :) It happens to me all the time; I've never actually understood why the strange, almost Yodaesque, order... as if you
asked
in English:
"Make sure 18 is his age."
Thanks, Jaromir
On 30-Dec-23 9:13:56 PM,
christoph.thiede(a)student.hpi.uni-potsdam.de
wrote:
nit: You mixed up the order of arguments for #assert:equals: (it is assert: expected equals: actual) and could have used it in the
final
assert again, but that's clearly no reason to hold back a useful
test.
;-) Merged, thanks! :-)
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-12-30T17:33:08+00:00, mail(a)jaromir.net wrote:
> Hi Christoph, > > Thanks for merging the fixes; I've just sent another test in > KernelTests-jar.448 to complement them. > > Please take a look and if ok I'd appreciate it if you could
merge it
as > well. > > Best regards and Happy New Year to you too! > Jaromir > > > On 30-Dec-23 6:15:25 PM, christoph.thiede(a)student.hpi.uni-potsdam.de > wrote: > > >Hi Jaromir, hi all, > > > >finally I have found the time to review these suggestions. > >Kernel-jar.1537, Kernel-jar.1538, and Kernel-jar.1539 look
excellent
to > >me as well. Clear, straightforward, useful. :-) I have merged
them
into > >the trunk via Kernel-ct.1545. > > > >Regarding DebuggerTests>>test16HandleSimulationError, I have
patched
it > >via ToolsTests-ct.125. Nothing to rack your brains over: "thisContext > >pc: nil" just mimicks any kind of unhandled error inside the simulator > >- since we now gently handle this via #cannotReturn:, I just replaced > >it with "thisContext pc: false". :-) Sorry for not clarifying
that
> >earlier and letting you speculate. > > > >Thanks for your work, and I already wish you a happy new year! > > > >Best, > >Christoph > > > >--- > >Sent from Squeak Inbox Talk > >https://github.com/hpi-swa-lab/squeak-inbox-talk > > > >On 2023-11-29T13:31:09+00:00, mail(a)jaromir.net wrote: > > > > > Hi Marcel, > > > > > > > [myself] whether the patch would have been necessary
should the
> > > #return:from: had been fixed then > > > > > > Nonsense, I just mixed it up with another issue :) > > > > > > > > > On 29-Nov-23 1:51:21 PM, "Jaromir Matas"
<mail(a)jaromir.net>
wrote: > > > > > > >Thanks Marcel! This test somehow slipped my attention :) > > > > > > > >The test can no longer work as is. It takes advantage of
the
> >erroneous > > > >behavior of #return:from: in the sense that if you simulate > > > > > > > > thisContext pc: nil > > > > > > > >it'll happily return to a dead context (i.e. to thisContext
from
> >#pc: > > > >nil context) - which is not what the VM does during
runtime. It
> >should > > > >immediately raise an illegal return exception not only
during
> >runtime > > > >but also during simulation. > > > > > > > >The test mentions a patch for an infinite debugger chain > > >
(http://forum.world.st/I-broke-the-debugger-td5110752.html). I
> >wonder > > > >whether the problem could have something to do with this simulation > >bug > > > >in return:from:; and a terrible idea occurred to me whether
the
> >patch > > > >would have been necessary should the #return:from: had been fixed > >then > > > >;O > > > > > > > >We may potentially come up with more examples like this,
even in
the > > > >trunk, where the bug from #return:from: propagated and was
taken
> > > >advantage of. I've found and fixed
#runUntilErrorOrReturnFrom:
but > >more > > > >can still be surviving undetected... > > > > > > > >I'd place the test into #expectedFailures for now but maybe
it's
> >time > > > >to remove it; Christoph should decide :) > > > > > > > >Thanks again, > > > >Jaromir > > > > > > > > > > > >On 29-Nov-23 10:28:38 AM, "Taeumel, Marcel via Squeak-dev" > > > ><squeak-dev(a)lists.squeakfoundation.org> wrote: > > > > > > > >>Hi Jaromir -- > > > >> > > > >>Looks good. Still, what about that
#test16HandleSimulationError
> >now? > > > >>:-) It is failing with your changes ... how would you
adapt it?
> > > >> > > > >> > > > >> > > > >>Best, > > > >>Marcel > > > >>>Am 28.11.2023 01:29:39 schrieb Jaromir Matas <mail(a)jaromir.net>: > > > >>> > > > >>>Hi Eliot, Marcel, all, > > > >>> > > > >>>I've sent a fix Kernel-jar.1539 to the Inbox that solves
the
> > > >>>remaining bit of the chain of bugs described in the
previous
post. > > > >>>All tests are green now and I think the root cause has
been
found > >and > > > >>>fixed. > > > >>> > > > >>>In this last bit I've created a version of stepToCallee
that
would > > > >>>identify a potential illegal return to a nil sender and
avoid
it. > > > >>> > > > >>>Now this example can be debugged without any problems: > > > >>> > > > >>>[[self halt. ^ 1] on: BlockCannotReturn do: #resume ]
fork
> > > >>> > > > >>>If you're happy with the solution in Kernel-jar.1539, > > > >>>Kernel-jar.1538, Kernel-jar.1537 and the test in > >KernelTests-jar.447, > > > >>>could you please double-check and merge, please? (And
remove
> > > >>>Kernel-mt.1534 and Tools-jar.1240 from the Inbox) > > > >>> > > > >>>Best, > > > >>>Jaromir > > > >>> > > > >>> > > > >>> > > > >>>On 27-Nov-23 12:09:37 AM, "Jaromir Matas"
<mail(a)jaromir.net>
> >wrote: > > > >>> > > > >>>>Hi Eliot, Christoph, all > > > >>>> > > > >>>>It looks like there are some more skeletons in the
closet :/
> > > >>>> > > > >>>>If you run this example > > > >>>> > > > >>>>[[self halt. ^ 1] on: BlockCannotReturn do: [:ex | ex
resume]
] > >fork > > > >>>> > > > >>>>and step over halt and then step over ^1 you get a nonsensical > >error > > > >>>>as a result of decoding nil as an instruction. > > > >>>> > > > >>>>It turns out that the root cause is in the #return:from: method: > >it > > > >>>>only checks whether aSender is dead but ignores the possibility > >that > > > >>>>aSender sender may be nil or dead in which cases the VM
also
> > > >>>>responds with sending #cannotReturn, hence I assume the simulator > > > >>>>should do the same. In addition, the VM nills the pc in
such
> > > >>>>scenario, so I added the same functionality here too: > > > >>>> > > > >>>>Context >> return: value from: aSender > > > >>>> "For simulation. Roll back self to aSender and return
value
> > > >>>>from it. Execute any unwind blocks on the way. ASSUMES aSender is > > > >>>>a sender of self" > > > >>>> > > > >>>> | newTop | > > > >>>> newTop := aSender sender. > > > >>>> (aSender isDead or: [newTop isNil or: [newTop isDead]]) ifTrue: > > > >>>> "<--------- this is extended ------" > > > >>>> [^self pc: nil; send: #cannotReturn: to: self with: > > > >>>>{value}]. "<------ pc: nil is added ----" > > > >>>> (self findNextUnwindContextUpTo: newTop) ifNotNil: > > > >>>> "Send #aboutToReturn:through: with nil as the second > > > >>>>argument to avoid this bug: > > > >>>> Cannot #stepOver '^2' in example '[^2] ensure: []'. > > > >>>> See > > > > >
>>http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html > > > > >
>>http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html" > > > >>>> [^self send: #aboutToReturn:through: to: self with:
{value.
> > > >>>>nil}]. > > > >>>> self releaseTo: newTop. > > > >>>> newTop ifNotNil: [newTop push: value]. > > > >>>> ^newTop > > > >>>> > > > >>>>In order for this to work #cannotReturn: has to be
modified
as in > > > >>>>Kernel-jar.1537: > > > >>>> > > > >>>>Context >> cannotReturn: result > > > >>>> > > > >>>> closureOrNil ifNotNil: [^ self cannotReturn: result to:
self
> > > >>>>home sender]. > > > >>>> self error: 'Computation has been terminated!' > > > >>>>"<----------- this has to be an Error -----" > > > >>>> > > > >>>>Then it almost works except when you keep stepping over
in
the > > > >>>>example above, you get an MNU error on `self previousPc`
in
> > > >>>>#cannotReturn:to:` with your solution of the VM crash.
If you
> >don't > > > >>>>mind I've amended your solution and added the final
context
where > > > >>>>the computation couldn't return along with the pc: > > > >>>> > > > >>>>Context >> cannotReturn: result to: homeContext > > > >>>> "The receiver tried to return result to homeContext
that
cannot > > > >>>>be returned from. > > > >>>> Capture the return context/pc in a BlockCannotReturn.
Nil
the pc > > > >>>>to prevent repeat > > > >>>> attempts and/or invalid continuation. Answer the result
of
> > > >>>>raising the exception." > > > >>>> > > > >>>> | exception previousPc | > > > >>>> exception := BlockCannotReturn new. > > > >>>> previousPc := pc ifNotNil: [self previousPc]. "<-----
here's
a > > > >>>>fix ----" > > > >>>> exception > > > >>>> result: result; > > > >>>> deadHome: homeContext; > > > >>>> finalContext: self; "<----- here's the new state, if > > > >>>>that's fine ----" > > > >>>> pc: previousPc. > > > >>>> pc := nil. > > > >>>> ^exception signal > > > >>>> > > > >>>>Unfortunately, this is still not the end of the story:
there
are > > > >>>>situations where #runUntilErrorOrReturnFrom: places the
two
guard > > > >>>>contexts below the bottom context. And that is a problem because > > > >>>>when the method tries to remove the two guard contexts
before
> > > >>>>returning at the end it uses #stepToCalee to do the job
but
this > > > >>>>unforotunately was (ab)using the above bug in
#return:from: -
> >I'll > > > >>>>explain: #return:from: didn't check whether aSender
sender
was > >nil > > > >>>>and as a result it allowed to simulate a return to a
"nil
> >context" > > > >>>>which was then (ab)used in the clean-up via #stepToCalee
in
the > > > >>>>#runUntilErrorOrReturnFrom:. > > > >>>> > > > >>>>When I fixed the #return:from: bug, the > >#runUntilErrorOrReturnFrom: > > > >>>>cleanup of the guard contexts no longer works in that
very
> >special > > > >>>>case where the guard contexts are below the bottom
context.
> >There's > > > >>>>one case where this is being used: #terminateAggresively
by
> > > >>>>Christoph. > > > >>>> > > > >>>>If I'm right with this analysis, the #runUntilErrorOrReturnFrom: > > > >>>>should get fixed too but I'll be away now for a few days
and
I > >won't > > > >>>>be able to respond. If you or Christoph had a chance to
take
a > >look > > > >>>>at Kernel-jar.1538 and Kernel-jar.1537 I'd be very
grateful.
I > >hope > > > >>>>this super long message at least makes some sense :) > > > >>>>Best, > > > >>>>Jaromir > > > >>>> > > > >>>>[1] Kernel-jar.1538, Kernel-jar.1537 > > > >>>>[2] KernelTests-jar.447 > > > >>>> > > > >>>> > > > >>>>PS: Christoph, > > > >>>> > > > >>>>With Kernel-jar.1538 + Kernel-jar.1537 your example > > > >>>> > > > >>>>process := > > > >>>> [(c := thisContext) pc: nil. > > > >>>> 2+3] newProcess. > > > >>>>process runUntil: [:ctx | ctx selector =
#cannotReturn:].
> > > >>>>self assert: process suspendedContext sender sender = c. > > > >>>>self assert: process suspendedContext arguments = {c}. > > > >>>> > > > >>>>works fine, I've just corrected your first assert. > > > >>>> > > > >>>> > > > >>>> > > > >>>> > > > >>>> > > > >>>>On 21-Nov-23 6:40:32 PM, "Eliot Miranda" > ><eliot.miranda(a)gmail.com> > > > >>>>wrote: > > > >>>> > > > >>>>>Hi Jaromir, > > > >>>>> > > > >>>>>>On Nov 20, 2023, at 11:51 PM, Jaromir Matas > ><mail(a)jaromir.net> > > > >>>>>>wrote: > > > >>>>>> > > > >>>>>> > > > >>>>>>Hi Eliot, > > > >>>>>>Very elegant! Now I finally got what you meant exactly
:)
> >Thanks. > > > >>>>>> > > > >>>>>>Two questions: > > > >>>>>>1. in order for the enclosed test to work I'd need an
Error
> > > >>>>>>instead of Processor debugWithTitle:full: call in > >#cannotReturn:. > > > >>>>>>Otherwise I don't know how to catch a plain invocation
of
the > > > >>>>>>Debugger: > > > >>>>>> > > > >>>>>>cannotReturn: result > > > >>>>>> > > > >>>>>> closureOrNil ifNotNil: [^ self cannotReturn: result
to:
self > > > >>>>>>home sender]. > > > >>>>>> self error: 'Computation has been terminated!' > > > >>>>> > > > >>>>>Much nicer. > > > >>>>> > > > >>>>>>2. We are capturing a pc of self which is completely different > > > >>>>>>context from homeContext indeed. > > > >>>>> > > > >>>>>Right. The return is attempted from a specific return bytecode > >in a > > > >>>>>specific block. This is the coordinate of the return
that
cannot > >be > > > >>>>>made. This is the relevant point of origin of the
cannot
return > > > >>>>>exception. > > > >>>>> > > > >>>>>Why the return fails is another matter: > > > >>>>>- the home context’s sender is a dead context (cannot
be
> >resumed) > > > >>>>>- the home context’s sender is nil (home already
returned
from) > > > >>>>>- the block activation’s home is nil rather than a
context
> >(should > > > >>>>>not happen) > > > >>>>> > > > >>>>>But in all these cases the pc of the home context is immaterial. > > > >>>>>The hike is being returned through/from, rather than
from;
the > > > >>>>>home’s pc is not relevant. > > > >>>>> > > > >>>>>>Maybe we could capture self in the exception too to
make it
> >more > > > >>>>>>clear/explicit what is going on: what context the
captured
pc > >is > > > >>>>>>actually associated with. Just a thought... > > > >>>>> > > > >>>>>Yes, I like that. I also like the idea of somehow
passing
the > > > >>>>>block activation’s pc to the debugger so that the
relevant
> >return > > > >>>>>expression is highlighted in the debugger. > > > >>>>> > > > >>>>>> > > > >>>>>>Thanks again, > > > >>>>>>Jaromir > > > >>>>> > > > >>>>>You’re welcome. I love working in this part of the
system.
> >Thanks > > > >>>>>for dragging me there. I’m in a slump right now and appreciate > >the > > > >>>>>fellowship. > > > >>>>> > > > >>>>>>------ Original Message ------ > > > >>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> > > > >>>>>>To "Jaromir Matas" <mail(a)jaromir.net> > > > >>>>>>Cc squeak-dev(a)lists.squeakfoundation.org > > > >>>>>>Date 11/21/2023 2:17:21 AM > > > >>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on > >BlockCannotReturn > > > >>>>>>exception > > > >>>>>> > > > >>>>>>>Hi Jaromir, > > > >>>>>>> > > > >>>>>>> see Kernel-eem.1535 for what I was suggesting. This example > > > >>>>>>>now has an exception with the right pc value in it: > > > >>>>>>> > > > >>>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect.
ex
> >resume]] > > > >>>>>>>fork > > > >>>>>>> > > > >>>>>>>The fix is simply > > > >>>>>>> > > > >>>>>>>Context>>cannotReturn: result to: homeContext > > > >>>>>>> "The receiver tried to return result to homeContext
that
> > > >>>>>>>cannot be returned from. > > > >>>>>>> Capture the return pc in a BlockCannotReturn. Nil
the pc
to > > > >>>>>>>prevent repeat > > > >>>>>>> attempts and/or invalid continuation. Answer the
result
of > > > >>>>>>>raising the exception." > > > >>>>>>> > > > >>>>>>> | exception | > > > >>>>>>> exception := BlockCannotReturn new. > > > >>>>>>> exception > > > >>>>>>> result: result; > > > >>>>>>> deadHome: homeContext; > > > >>>>>>> pc: self previousPc. > > > >>>>>>> pc := nil. > > > >>>>>>> ^exception signal > > > >>>>>>> > > > >>>>>>> > > > >>>>>>>The VM crash is now avoided. The debugger displays
the
method, > > > >>>>>>>but does not highlight the offending pc, which is no
big
deal. > >A > > > >>>>>>>suitable defaultHandler for B lockCannotReturn may be
able
to > >get > > > >>>>>>>the debugger to highlight correctly on opening. Try
the
> > > >>>>>>>following examples: > > > >>>>>>> > > > >>>>>>>[[^1] on: BlockCannotReturn do: #resume] fork. > > > >>>>>>> > > > >>>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect.
ex
> >resume]] > > > >>>>>>>fork > > > >>>>>>> > > > >>>>>>>[[^1] value] fork. > > > >>>>>>> > > > >>>>>>>They al; seem to behave perfectly acceptably to me.
Does
this > > > >>>>>>>fix work for you? > > > >>>>>>> > > > >>>>>>>On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas > ><mail(a)jaromir.net> > > > >>>>>>>wrote: > > > >>>>>>>>Hi Eliot, > > > >>>>>>>> > > > >>>>>>>>How about to nil the pc just before making the
return:
> > > >>>>>>>>``` > > > >>>>>>>>Context >> #cannotReturn: result > > > >>>>>>>> > > > >>>>>>>> self push: self pc. "backup the pc for the sake of > > > >>>>>>>>debugging" > > > >>>>>>>> closureOrNil ifNotNil: [^self cannotReturn: result
to:
self > > > >>>>>>>>home sender; pc: nil]. > > > >>>>>>>> Processor debugWithTitle: 'Computation has been terminated!' > > > >>>>>>>>translated full: false > > > >>>>>>>>``` > > > >>>>>>>>The nilled pc should not even potentially interfere
with
the > > > >>>>>>>>#isDead now. > > > >>>>>>>> > > > >>>>>>>>I hope this is at least a step in the right
direction :)
> > > >>>>>>>> > > > >>>>>>>>However, there's still a problem when debugging the > >resumption > > > >>>>>>>>of #cannotReturn because the encoders expect a
reasonable
> >index. > > > >>>>>>>>I haven't figured out yet where to place a nil check
#step, > > > >>>>>>>>#stepToSendOrReturn... ? > > > >>>>>>>> > > > >>>>>>>>Thanks again, > > > >>>>>>>>Jaromir > > > >>>>>>>> > > > >>>>>>>> > > > >>>>>>>>------ Original Message ------ > > > >>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> > > > >>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> > > > >>>>>>>>Date 11/17/2023 8:36:50 PM > > > >>>>>>>>Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn > > > >>>>>>>>exception > > > >>>>>>>> > > > >>>>>>>>>Hi Jaromir, > > > >>>>>>>>> > > > >>>>>>>>>>On Nov 17, 2023, at 7:05 AM, Jaromir Matas > ><mail(a)jaromir.net> > > > >>>>>>>>>>wrote: > > > >>>>>>>>>> > > > >>>>>>>>>> > > > >>>>>>>>>>Eliot, hi again, > > > >>>>>>>>>> > > > >>>>>>>>>>Please disregard my previous comment about nilling
the
> > > >>>>>>>>>>contexts that have returned. We are indeed talking about > >the > > > >>>>>>>>>>context directly under the #cannotReturn context
which
is > > > >>>>>>>>>>totally different from the home context in another thread > > > >>>>>>>>>>that's gone. > > > >>>>>>>>>> > > > >>>>>>>>>>I may still be confused but would nilling the pc
of the
> > > >>>>>>>>>>context directly under the cannotReturn context
help?
> >Here's > > > >>>>>>>>>>what I mean: > > > >>>>>>>>>>``` > > > >>>>>>>>>>Context >> #cannotReturn: result > > > >>>>>>>>>> > > > >>>>>>>>>> closureOrNil ifNotNil: [^self pc: nil;
cannotReturn:
> > > >>>>>>>>>>result to: self home sender]. > > > >>>>>>>>>> Processor debugWithTitle: 'Computation has been > > > >>>>>>>>>>terminated!' translated full: false. > > > >>>>>>>>>>``` > > > >>>>>>>>>>Instead of crashing the VM invokes the debugger
with
the > > > >>>>>>>>>>'Computation has been terminated!' message. > > > >>>>>>>>>> > > > >>>>>>>>>>Does this make sense? > > > >>>>>>>>> > > > >>>>>>>>>Nearly. But it loses the information on what the pc actually > > > >>>>>>>>>is, and that’s potentially vital information. So
IMO the
ox > > > >>>>>>>>>should only be nilled between the BlockCannotReturn > >exception > > > >>>>>>>>>being created and raised. > > > >>>>>>>>> > > > >>>>>>>>>[But if you try this don’t be surprised if it
causes a
few > > > >>>>>>>>>temporary problems. It looks to me that without a
little
> > > >>>>>>>>>refactoring this could easily cause an infinite recursion > > > >>>>>>>>>around the sending of isDead. I’m sure you’ll be
able to
fix > > > >>>>>>>>>the code to work correctly] > > > >>>>>>>>> > > > >>>>>>>>>>Thanks, > > > >>>>>>>>>>Jaromir > > > >>>>>>>>>> > > > >>>>>>>>>> > > > >>>>>>>>>>------ Original Message ------ > > > >>>>>>>>>>From "Jaromir Matas" <mail(a)jaromir.net> > > > >>>>>>>>>>To "Eliot Miranda" <eliot.miranda(a)gmail.com>;
"The
> > > >>>>>>>>>>general-purpose Squeak developers list" > > > >>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > > > >>>>>>>>>>Date 11/17/2023 10:15:17 AM > > > >>>>>>>>>>Subject [squeak-dev] Re: Resuming on
BlockCannotReturn
> > > >>>>>>>>>>exception > > > >>>>>>>>>> > > > >>>>>>>>>>>Hi Eliot, > > > >>>>>>>>>>> > > > >>>>>>>>>>> > > > >>>>>>>>>>> > > > >>>>>>>>>>>------ Original Message ------ > > > >>>>>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> > > > >>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> > > > >>>>>>>>>>>Cc "The general-purpose Squeak developers list" > > > >>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > > > >>>>>>>>>>>Date 11/16/2023 11:52:45 PM > > > >>>>>>>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on > > > >>>>>>>>>>>BlockCannotReturn exception > > > >>>>>>>>>>> > > > >>>>>>>>>>>>Hi Jaromir, > > > >>>>>>>>>>>> > > > >>>>>>>>>>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas > > > >>>>>>>>>>>><mail(a)jaromir.net> wrote: > > > >>>>>>>>>>>>>Hi Nicolas, Eliot, > > > >>>>>>>>>>>>> > > > >>>>>>>>>>>>>here's what I understand is happening (see the enclosed > > > >>>>>>>>>>>>>screenshot): > > > >>>>>>>>>>>>> > > > >>>>>>>>>>>>>1) we fork a new process to evaluate [^1] > > > >>>>>>>>>>>>>2) the new process evaluates [^1] which means > >instruction > > > >>>>>>>>>>>>>18 is being evaluated, hence pc points to instruction 19 > > > >>>>>>>>>>>>>now > > > >>>>>>>>>>>>>3) however, the home context where ^1 should
return
to > >is > > > >>>>>>>>>>>>>gone by this time (the process that executed
the
fork > >has > > > >>>>>>>>>>>>>already returned - notice the two up arrows in
the
> >debugger > > > >>>>>>>>>>>>>screenshot) > > > >>>>>>>>>>>>>4) the VM can't finish the instruction and
returns
> >control > > > >>>>>>>>>>>>>to the image via placing the #cannotReturn:
context
on > >top > > > >>>>>>>>>>>>>of the [^1] context > > > >>>>>>>>>>>>>5) #cannotReturn: evaluation results in
signalling
the > >BCR > > > >>>>>>>>>>>>>exception which is then handled by the #resume handler > > > >>>>>>>>>>>>> (in our debugged case the [:ex | self halt. ex resume] > > > >>>>>>>>>>>>>handler) > > > >>>>>>>>>>>>>6) ex resume is evaluated, however, this means > >requesting > > > >>>>>>>>>>>>>the VM to evaluate instruction 19 of the [^1] context - > > > >>>>>>>>>>>>>which is past the last instruction of the
context
and > >the > > > >>>>>>>>>>>>>crash ensues > > > >>>>>>>>>>>>> > > > >>>>>>>>>>>>>I wonder whether such situations could/should
be
> >prevented > > > >>>>>>>>>>>>>inside the VM or whether such an expectation is wrong > >for > > > >>>>>>>>>>>>>some reason. > > > >>>>>>>>>>>> > > > >>>>>>>>>>>>As Nicolas says, IMO this is best done at the
image
> >level. > > > >>>>>>>>>>>> > > > >>>>>>>>>>>>It could be prevented in the VM, but at great
cost,
and > >only > > > >>>>>>>>>>>>partially. The performance issue is that the
last
> >bytecode > > > >>>>>>>>>>>>in a method is not marked in any way, and that
to
> >determine > > > >>>>>>>>>>>>the last bytecode the bytecodes must be
symbolically
> > > >>>>>>>>>>>>evaluated from the start of the method. See implementors > >of > > > >>>>>>>>>>>>endPC at the image level (which defer to the
method
> >trailer) > > > >>>>>>>>>>>>and implementors of endPCOf: in the VMMaker
code.
Doing > >this > > > >>>>>>>>>>>>every time execution commences is prohibitively > >expensive. > > > >>>>>>>>>>>>The "only partially" issue is that following the return > > > >>>>>>>>>>>>instruction may be other valid bytecodes, but
these
are > >not > > > >>>>>>>>>>>>a continuation. > > > >>>>>>>>>>>> > > > >>>>>>>>>>>> > > > >>>>>>>>>>>>Consider the following code in some block: > > > >>>>>>>>>>>> [self expression ifTrue: > > > >>>>>>>>>>>> [^1]. > > > >>>>>>>>>>>> ^2 > > > >>>>>>>>>>>> > > > >>>>>>>>>>>>The bytecodes for this are > > > >>>>>>>>>>>> pushReceiver > > > >>>>>>>>>>>> send #expression > > > >>>>>>>>>>>> jumpFalse L1 > > > >>>>>>>>>>>> push 1 > > > >>>>>>>>>>>> methodReturnTop > > > >>>>>>>>>>>>L1 > > > >>>>>>>>>>>> push 2 > > > >>>>>>>>>>>> methodReturnTop > > > >>>>>>>>>>>> > > > >>>>>>>>>>>>Clearly if expression is true these should be
*no*
> > > >>>>>>>>>>>>continuation in which ^2 is executed. > > > >>>>>>>>>>> > > > >>>>>>>>>>>Well, in that case there's a bug because the computation > >in > > > >>>>>>>>>>>the following example shouldn't continue past the
[^1]
> >block > > > >>>>>>>>>>>but it silently does: > > > >>>>>>>>>>>`[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] > > > >>>>>>>>>>>fork` > > > >>>>>>>>>>> > > > >>>>>>>>>>>The bytecodes are > > > >>>>>>>>>>> push true > > > >>>>>>>>>>> jumpFalse L1 > > > >>>>>>>>>>> push 1 > > > >>>>>>>>>>> returnTop > > > >>>>>>>>>>>L1 > > > >>>>>>>>>>> push nil > > > >>>>>>>>>>> blockReturn > > > >>>>>>>>>>> > > > >>>>>>>>>>> > > > >>>>>>>>>>> > > > >>>>>>>>>>>> > > > >>>>>>>>>>>>So even if the VM did try and detect whether the return > >was > > > >>>>>>>>>>>>at the last block method, it would only work for special > > > >>>>>>>>>>>>cases. > > > >>>>>>>>>>>> > > > >>>>>>>>>>>> > > > >>>>>>>>>>>>It seems to me the issue is simply that the
context
that > > > >>>>>>>>>>>>cannot be returned from should be marked as dead
(see
> > > >>>>>>>>>>>>Context>>isDead) by setting its pc to nil at
some
point, > > > >>>>>>>>>>>>presumably after copying the actual return pc
into
the > > > >>>>>>>>>>>>BlockCannotReturn exception, to avoid ever
trying to
> >resume > > > >>>>>>>>>>>>the context. > > > >>>>>>>>>>> > > > >>>>>>>>>>>Does this mean, in other words, that every
context
that > > > >>>>>>>>>>>returns should nil its pc to avoid being
"wrongly"
> > > >>>>>>>>>>>reused/executed in the future, which concerns primarily > >those > > > >>>>>>>>>>>being referenced somewhere hence potentially executable in > > > >>>>>>>>>>>the future, is that right? > > > >>>>>>>>>>>Hypothetical question: would nilling the pc
during
returns > > > >>>>>>>>>>>"fix" the example? > > > >>>>>>>>>>>Thanks a lot for helping me understand this. > > > >>>>>>>>>>>Best, > > > >>>>>>>>>>>Jaromir > > > >>>>>>>>>>> > > > >>>>>>>>>>> > > > >>>>>>>>>>> > > > >>>>>>>>>>>> > > > >>>>>>>>>>>> > > > >>>>>>>>>>>>> > > > >>>>>>>>>>>>>Thanks, > > > >>>>>>>>>>>>>Jaromir > > > >>>>>>>>>>>>> > > > >>>>>>>>>>>>><bdxuqalu.png> > > > >>>>>>>>>>>>> > > > >>>>>>>>>>>>>------ Original Message ------ > > > >>>>>>>>>>>>>From "Eliot Miranda"
<eliot.miranda(a)gmail.com>
> > > >>>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The > >general-purpose > > > >>>>>>>>>>>>>Squeak developers list" > > > >>>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > > > >>>>>>>>>>>>>Date 11/16/2023 6:48:43 PM > > > >>>>>>>>>>>>>Subject Re: [squeak-dev] Re: Resuming on > >BlockCannotReturn > > > >>>>>>>>>>>>>exception > > > >>>>>>>>>>>>> > > > >>>>>>>>>>>>>>Hi Jaromir, > > > >>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas > > > >>>>>>>>>>>>>>><mail(a)jaromir.net> wrote: > > > >>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>>Hi Nicloas, > > > >>>>>>>>>>>>>>>No no, I don't have any practical scenario in mind, > >I'm > > > >>>>>>>>>>>>>>>just trying to understand why the VM is implemented > >like > > > >>>>>>>>>>>>>>>this, whether there were a reason to leave
this
> > > >>>>>>>>>>>>>>>possibility of a crash, e.g. it would slow
down
the VM > >to > > > >>>>>>>>>>>>>>>try to prevent such a dumb situation (who
would
resume > > > >>>>>>>>>>>>>>>from BCR in his right mind? :) ) - or perhaps
I
have > > > >>>>>>>>>>>>>>>overlooked some good reason to even keep this behavior > >in > > > >>>>>>>>>>>>>>>the VM. That's all. > > > >>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>Let’s first understand what’s really
happening.
> >Presumably > > > >>>>>>>>>>>>>>at tone point a context is resumed those pc is already > >at > > > >>>>>>>>>>>>>>the block return bytecode (effectively,
because it
> >crashes > > > >>>>>>>>>>>>>>in JITted code, but I bet the stack vm will
crash
also, > > > >>>>>>>>>>>>>>but not as cleanly - it will try and execute
the
bytes > >in > > > >>>>>>>>>>>>>>the encoded method trailer). So which method actually > > > >>>>>>>>>>>>>>sends resume, and to what, and what state is resume’s > > > >>>>>>>>>>>>>>receiver when resume is sent? > > > >>>>>>>>>>>>>> > > > >>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>>Thanks for your reply. > > > >>>>>>>>>>>>>>>Regards, > > > >>>>>>>>>>>>>>>Jaromir > > > >>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>>------ Original Message ------ > > > >>>>>>>>>>>>>>>From "Nicolas Cellier" > > > >>>>>>>>>>>>>>><nicolas.cellier.aka.nice(a)gmail.com> > > > >>>>>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The > > > >>>>>>>>>>>>>>>general-purpose Squeak developers list" > > > >>>>>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > > > >>>>>>>>>>>>>>>Date 11/16/2023 7:20:20 AM > > > >>>>>>>>>>>>>>>Subject Re: [squeak-dev] Resuming on BlockCannotReturn > > > >>>>>>>>>>>>>>>exception > > > >>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>>>Hi Jaromir, > > > >>>>>>>>>>>>>>>>Is there a scenario where it would make
sense to
> >resume > > > >>>>>>>>>>>>>>>>a BlockCannotReturn? > > > >>>>>>>>>>>>>>>>If not, I would suggest to protect at image
side
and > > > >>>>>>>>>>>>>>>>override #resume. > > > >>>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas > > > >>>>>>>>>>>>>>>><mail(a)jaromir.net> a écrit : > > > >>>>>>>>>>>>>>>>>Hi Eliot, Christoph, All, > > > >>>>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>>>>It's known the following example crashes
the VM.
Is > > > >>>>>>>>>>>>>>>>>this an intended behavior or a "tolerated
bug"?
> > > >>>>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume]
fork`
> > > >>>>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>>>>I understand why it crashes: the non-local return > >has > > > >>>>>>>>>>>>>>>>>nowhere to return to and so resuming the computation > > > >>>>>>>>>>>>>>>>>leads to a crash. But why not raise another
BCR
> > > >>>>>>>>>>>>>>>>>exception to prevent the crash? Potential infinite > > > >>>>>>>>>>>>>>>>>loop? Perhaps I'm just missing the purpose
of
this > > > >>>>>>>>>>>>>>>>>behavior... > > > >>>>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>>>>Thanks for an explanation. > > > >>>>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>>>>Best, > > > >>>>>>>>>>>>>>>>>Jaromir > > > >>>>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>>>>-- > > > >>>>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>>>>Jaromir Matas > > > >>>>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>>>> > > > >>>>>>>>>>>>>>> > > > >>>>>>>>>>>> > > > >>>>>>>>>>>> > > > >>>>>>>>>>>>-- > > > >>>>>>>>>>>>_,,,^..^,,,_ > > > >>>>>>>>>>>>best, Eliot > > > >>>>>>>>>><Context-cannotReturn.st> > > > >>>>>>> > > > >>>>>>> > > > >>>>>>>-- > > > >>>>>>>_,,,^..^,,,_ > > > >>>>>>>best, Eliot > > > >>>>>><ProcessTest-testResumeAfterBCR.st>

Understand it no one does.
On 2023-12-30 21:13, Jaromir Matas wrote:
nit: You mixed up the order of arguments for #assert:equals:
oops, sorry :) It happens to me all the time; I've never actually understood why the strange, almost Yodaesque, order... as if you asked in English:
"Make sure 18 is his age."
Thanks, Jaromir
On 30-Dec-23 9:13:56 PM, christoph.thiede@student.hpi.uni-potsdam.de wrote:
nit: You mixed up the order of arguments for #assert:equals: (it is assert: expected equals: actual) and could have used it in the final assert again, but that's clearly no reason to hold back a useful test. ;-) Merged, thanks! :-)
Best, Christoph
_Sent from __Squeak Inbox Talk [1]_
On 2023-12-30T17:33:08+00:00, mail@jaromir.net wrote:
Hi Christoph,
Thanks for merging the fixes; I've just sent another test in KernelTests-jar.448 to complement them.
Please take a look and if ok I'd appreciate it if you could merge it as well.
Best regards and Happy New Year to you too! Jaromir
On 30-Dec-23 6:15:25 PM, christoph.thiede(a)student.hpi.uni-potsdam.de wrote:
Hi Jaromir, hi all,
finally I have found the time to review these suggestions. Kernel-jar.1537, Kernel-jar.1538, and Kernel-jar.1539 look excellent to me as well. Clear, straightforward, useful. :-) I have merged them into the trunk via Kernel-ct.1545.
Regarding DebuggerTests>>test16HandleSimulationError, I have patched it via ToolsTests-ct.125. Nothing to rack your brains over: "thisContext pc: nil" just mimicks any kind of unhandled error inside the simulator
- since we now gently handle this via #cannotReturn:, I just
replaced it with "thisContext pc: false". :-) Sorry for not clarifying that earlier and letting you speculate.
Thanks for your work, and I already wish you a happy new year!
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-11-29T13:31:09+00:00, mail(a)jaromir.net wrote:
Hi Marcel,
[myself] whether the patch would have been necessary should the
#return:from: had been fixed then
Nonsense, I just mixed it up with another issue :)
On 29-Nov-23 1:51:21 PM, "Jaromir Matas" <mail(a)jaromir.net> wrote:
Thanks Marcel! This test somehow slipped my attention :)
The test can no longer work as is. It takes advantage of the
erroneous
behavior of #return:from: in the sense that if you simulate
thisContext pc: nil
it'll happily return to a dead context (i.e. to thisContext from
#pc:
nil context) - which is not what the VM does during runtime. It
should
immediately raise an illegal return exception not only during
runtime
but also during simulation.
The test mentions a patch for an infinite debugger chain (http://forum.world.st/I-broke-the-debugger-td5110752.html). I
wonder
whether the problem could have something to do with this simulation
bug
in return:from:; and a terrible idea occurred to me whether the
patch
would have been necessary should the #return:from: had been fixed
then
;O
We may potentially come up with more examples like this, even in the trunk, where the bug from #return:from: propagated and was taken advantage of. I've found and fixed #runUntilErrorOrReturnFrom: but
more
can still be surviving undetected...
I'd place the test into #expectedFailures for now but maybe it's
time
to remove it; Christoph should decide :)
Thanks again, Jaromir
On 29-Nov-23 10:28:38 AM, "Taeumel, Marcel via Squeak-dev" <squeak-dev(a)lists.squeakfoundation.org> wrote:
>Hi Jaromir -- > >Looks good. Still, what about that #test16HandleSimulationError
now?
>:-) It is failing with your changes ... how would you adapt it? > > > >Best, >Marcel >>Am 28.11.2023 01:29:39 schrieb Jaromir Matas <mail(a)jaromir.net>: >> >>Hi Eliot, Marcel, all, >> >>I've sent a fix Kernel-jar.1539 to the Inbox that solves the >>remaining bit of the chain of bugs described in the previous post. >>All tests are green now and I think the root cause has been found
and
>>fixed. >> >>In this last bit I've created a version of stepToCallee that would >>identify a potential illegal return to a nil sender and avoid it. >> >>Now this example can be debugged without any problems: >> >>[[self halt. ^ 1] on: BlockCannotReturn do: #resume ] fork >> >>If you're happy with the solution in Kernel-jar.1539, >>Kernel-jar.1538, Kernel-jar.1537 and the test in
KernelTests-jar.447,
>>could you please double-check and merge, please? (And remove >>Kernel-mt.1534 and Tools-jar.1240 from the Inbox) >> >>Best, >>Jaromir >> >> >> >>On 27-Nov-23 12:09:37 AM, "Jaromir Matas" <mail(a)jaromir.net>
wrote:
>> >>>Hi Eliot, Christoph, all >>> >>>It looks like there are some more skeletons in the closet :/ >>> >>>If you run this example >>> >>>[[self halt. ^ 1] on: BlockCannotReturn do: [:ex | ex resume] ]
fork
>>> >>>and step over halt and then step over ^1 you get a nonsensical
error
>>>as a result of decoding nil as an instruction. >>> >>>It turns out that the root cause is in the #return:from: method:
it
>>>only checks whether aSender is dead but ignores the possibility
that
>>>aSender sender may be nil or dead in which cases the VM also >>>responds with sending #cannotReturn, hence I assume the simulator >>>should do the same. In addition, the VM nills the pc in such >>>scenario, so I added the same functionality here too: >>> >>>Context >> return: value from: aSender >>> "For simulation. Roll back self to aSender and return value >>>from it. Execute any unwind blocks on the way. ASSUMES aSender is >>>a sender of self" >>> >>> | newTop | >>> newTop := aSender sender. >>> (aSender isDead or: [newTop isNil or: [newTop isDead]]) ifTrue: >>> "<--------- this is extended ------" >>> [^self pc: nil; send: #cannotReturn: to: self with: >>>{value}]. "<------ pc: nil is added ----" >>> (self findNextUnwindContextUpTo: newTop) ifNotNil: >>> "Send #aboutToReturn:through: with nil as the second >>>argument to avoid this bug: >>> Cannot #stepOver '^2' in example '[^2] ensure: []'. >>> See
>> http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html
>> http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html" >>> [^self send: #aboutToReturn:through: to: self with: {value. >>>nil}]. >>> self releaseTo: newTop. >>> newTop ifNotNil: [newTop push: value]. >>> ^newTop >>> >>>In order for this to work #cannotReturn: has to be modified as in >>>Kernel-jar.1537: >>> >>>Context >> cannotReturn: result >>> >>> closureOrNil ifNotNil: [^ self cannotReturn: result to: self >>>home sender]. >>> self error: 'Computation has been terminated!' >>>"<----------- this has to be an Error -----" >>> >>>Then it almost works except when you keep stepping over in the >>>example above, you get an MNU error on `self previousPc` in >>>#cannotReturn:to:` with your solution of the VM crash. If you
don't
>>>mind I've amended your solution and added the final context where >>>the computation couldn't return along with the pc: >>> >>>Context >> cannotReturn: result to: homeContext >>> "The receiver tried to return result to homeContext that cannot >>>be returned from. >>> Capture the return context/pc in a BlockCannotReturn. Nil the pc >>>to prevent repeat >>> attempts and/or invalid continuation. Answer the result of >>>raising the exception." >>> >>> | exception previousPc | >>> exception := BlockCannotReturn new. >>> previousPc := pc ifNotNil: [self previousPc]. "<----- here's a >>>fix ----" >>> exception >>> result: result; >>> deadHome: homeContext; >>> finalContext: self; "<----- here's the new state, if >>>that's fine ----" >>> pc: previousPc. >>> pc := nil. >>> ^exception signal >>> >>>Unfortunately, this is still not the end of the story: there are >>>situations where #runUntilErrorOrReturnFrom: places the two guard >>>contexts below the bottom context. And that is a problem because >>>when the method tries to remove the two guard contexts before >>>returning at the end it uses #stepToCalee to do the job but this >>>unforotunately was (ab)using the above bug in #return:from: -
I'll
>>>explain: #return:from: didn't check whether aSender sender was
nil
>>>and as a result it allowed to simulate a return to a "nil
context"
>>>which was then (ab)used in the clean-up via #stepToCalee in the >>>#runUntilErrorOrReturnFrom:. >>> >>>When I fixed the #return:from: bug, the
#runUntilErrorOrReturnFrom:
>>>cleanup of the guard contexts no longer works in that very
special
>>>case where the guard contexts are below the bottom context.
There's
>>>one case where this is being used: #terminateAggresively by >>>Christoph. >>> >>>If I'm right with this analysis, the #runUntilErrorOrReturnFrom: >>>should get fixed too but I'll be away now for a few days and I
won't
>>>be able to respond. If you or Christoph had a chance to take a
look
>>>at Kernel-jar.1538 and Kernel-jar.1537 I'd be very grateful. I
hope
>>>this super long message at least makes some sense :) >>>Best, >>>Jaromir >>> >>>[1] Kernel-jar.1538, Kernel-jar.1537 >>>[2] KernelTests-jar.447 >>> >>> >>>PS: Christoph, >>> >>>With Kernel-jar.1538 + Kernel-jar.1537 your example >>> >>>process := >>> [(c := thisContext) pc: nil. >>> 2+3] newProcess. >>>process runUntil: [:ctx | ctx selector = #cannotReturn:]. >>>self assert: process suspendedContext sender sender = c. >>>self assert: process suspendedContext arguments = {c}. >>> >>>works fine, I've just corrected your first assert. >>> >>> >>> >>> >>> >>>On 21-Nov-23 6:40:32 PM, "Eliot Miranda"
<eliot.miranda(a)gmail.com>
>>>wrote: >>> >>>>Hi Jaromir, >>>> >>>>>On Nov 20, 2023, at 11:51 PM, Jaromir Matas
<mail(a)jaromir.net>
>>>>>wrote: >>>>> >>>>> >>>>>Hi Eliot, >>>>>Very elegant! Now I finally got what you meant exactly :)
Thanks.
>>>>> >>>>>Two questions: >>>>>1. in order for the enclosed test to work I'd need an Error >>>>>instead of Processor debugWithTitle:full: call in
#cannotReturn:.
>>>>>Otherwise I don't know how to catch a plain invocation of the >>>>>Debugger: >>>>> >>>>>cannotReturn: result >>>>> >>>>> closureOrNil ifNotNil: [^ self cannotReturn: result to: self >>>>>home sender]. >>>>> self error: 'Computation has been terminated!' >>>> >>>>Much nicer. >>>> >>>>>2. We are capturing a pc of self which is completely different >>>>>context from homeContext indeed. >>>> >>>>Right. The return is attempted from a specific return bytecode
in a
>>>>specific block. This is the coordinate of the return that cannot
be
>>>>made. This is the relevant point of origin of the cannot return >>>>exception. >>>> >>>>Why the return fails is another matter: >>>>- the home context's sender is a dead context (cannot be
resumed)
>>>>- the home context's sender is nil (home already returned from) >>>>- the block activation's home is nil rather than a context
(should
>>>>not happen) >>>> >>>>But in all these cases the pc of the home context is immaterial. >>>>The hike is being returned through/from, rather than from; the >>>>home's pc is not relevant. >>>> >>>>>Maybe we could capture self in the exception too to make it
more
>>>>>clear/explicit what is going on: what context the captured pc
is
>>>>>actually associated with. Just a thought... >>>> >>>>Yes, I like that. I also like the idea of somehow passing the >>>>block activation's pc to the debugger so that the relevant
return
>>>>expression is highlighted in the debugger. >>>> >>>>> >>>>>Thanks again, >>>>>Jaromir >>>> >>>>You're welcome. I love working in this part of the system.
Thanks
>>>>for dragging me there. I'm in a slump right now and appreciate
the
>>>>fellowship. >>>> >>>>>------ Original Message ------ >>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>Cc squeak-dev(a)lists.squeakfoundation.org >>>>>Date 11/21/2023 2:17:21 AM >>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>exception >>>>> >>>>>>Hi Jaromir, >>>>>> >>>>>> see Kernel-eem.1535 for what I was suggesting. This example >>>>>>now has an exception with the right pc value in it: >>>>>> >>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex
resume]]
>>>>>>fork >>>>>> >>>>>>The fix is simply >>>>>> >>>>>>Context>>cannotReturn: result to: homeContext >>>>>> "The receiver tried to return result to homeContext that >>>>>>cannot be returned from. >>>>>> Capture the return pc in a BlockCannotReturn. Nil the pc to >>>>>>prevent repeat >>>>>> attempts and/or invalid continuation. Answer the result of >>>>>>raising the exception." >>>>>> >>>>>> | exception | >>>>>> exception := BlockCannotReturn new. >>>>>> exception >>>>>> result: result; >>>>>> deadHome: homeContext; >>>>>> pc: self previousPc. >>>>>> pc := nil. >>>>>> ^exception signal >>>>>> >>>>>> >>>>>>The VM crash is now avoided. The debugger displays the method, >>>>>>but does not highlight the offending pc, which is no big deal.
A
>>>>>>suitable defaultHandler for B lockCannotReturn may be able to
get
>>>>>>the debugger to highlight correctly on opening. Try the >>>>>>following examples: >>>>>> >>>>>>[[^1] on: BlockCannotReturn do: #resume] fork. >>>>>> >>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex
resume]]
>>>>>>fork >>>>>> >>>>>>[[^1] value] fork. >>>>>> >>>>>>They al; seem to behave perfectly acceptably to me. Does this >>>>>>fix work for you? >>>>>> >>>>>>On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas
<mail(a)jaromir.net>
>>>>>>wrote: >>>>>>>Hi Eliot, >>>>>>> >>>>>>>How about to nil the pc just before making the return: >>>>>>>``` >>>>>>>Context >> #cannotReturn: result >>>>>>> >>>>>>> self push: self pc. "backup the pc for the sake of >>>>>>>debugging" >>>>>>> closureOrNil ifNotNil: [^self cannotReturn: result to: self >>>>>>>home sender; pc: nil]. >>>>>>> Processor debugWithTitle: 'Computation has been terminated!' >>>>>>>translated full: false >>>>>>>``` >>>>>>>The nilled pc should not even potentially interfere with the >>>>>>>#isDead now. >>>>>>> >>>>>>>I hope this is at least a step in the right direction :) >>>>>>> >>>>>>>However, there's still a problem when debugging the
resumption
>>>>>>>of #cannotReturn because the encoders expect a reasonable
index.
>>>>>>>I haven't figured out yet where to place a nil check - #step, >>>>>>>#stepToSendOrReturn... ? >>>>>>> >>>>>>>Thanks again, >>>>>>>Jaromir >>>>>>> >>>>>>> >>>>>>>------ Original Message ------ >>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>Date 11/17/2023 8:36:50 PM >>>>>>>Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn >>>>>>>exception >>>>>>> >>>>>>>>Hi Jaromir, >>>>>>>> >>>>>>>>>On Nov 17, 2023, at 7:05 AM, Jaromir Matas
<mail(a)jaromir.net>
>>>>>>>>>wrote: >>>>>>>>> >>>>>>>>> >>>>>>>>>Eliot, hi again, >>>>>>>>> >>>>>>>>>Please disregard my previous comment about nilling the >>>>>>>>>contexts that have returned. We are indeed talking about
the
>>>>>>>>>context directly under the #cannotReturn context which is >>>>>>>>>totally different from the home context in another thread >>>>>>>>>that's gone. >>>>>>>>> >>>>>>>>>I may still be confused but would nilling the pc of the >>>>>>>>>context directly under the cannotReturn context help?
Here's
>>>>>>>>>what I mean: >>>>>>>>>``` >>>>>>>>>Context >> #cannotReturn: result >>>>>>>>> >>>>>>>>> closureOrNil ifNotNil: [^self pc: nil; cannotReturn: >>>>>>>>>result to: self home sender]. >>>>>>>>> Processor debugWithTitle: 'Computation has been >>>>>>>>>terminated!' translated full: false. >>>>>>>>>``` >>>>>>>>>Instead of crashing the VM invokes the debugger with the >>>>>>>>>'Computation has been terminated!' message. >>>>>>>>> >>>>>>>>>Does this make sense? >>>>>>>> >>>>>>>>Nearly. But it loses the information on what the pc actually >>>>>>>>is, and that's potentially vital information. So IMO the ox >>>>>>>>should only be nilled between the BlockCannotReturn
exception
>>>>>>>>being created and raised. >>>>>>>> >>>>>>>>[But if you try this don't be surprised if it causes a few >>>>>>>>temporary problems. It looks to me that without a little >>>>>>>>refactoring this could easily cause an infinite recursion >>>>>>>>around the sending of isDead. I'm sure you'll be able to fix >>>>>>>>the code to work correctly] >>>>>>>> >>>>>>>>>Thanks, >>>>>>>>>Jaromir >>>>>>>>> >>>>>>>>> >>>>>>>>>------ Original Message ------ >>>>>>>>>From "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>>>To "Eliot Miranda" <eliot.miranda(a)gmail.com>; "The >>>>>>>>>general-purpose Squeak developers list" >>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>Date 11/17/2023 10:15:17 AM >>>>>>>>>Subject [squeak-dev] Re: Resuming on BlockCannotReturn >>>>>>>>>exception >>>>>>>>> >>>>>>>>>>Hi Eliot, >>>>>>>>>> >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>------ Original Message ------ >>>>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>>>>Cc "The general-purpose Squeak developers list" >>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>Date 11/16/2023 11:52:45 PM >>>>>>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on >>>>>>>>>>BlockCannotReturn exception >>>>>>>>>> >>>>>>>>>>>Hi Jaromir, >>>>>>>>>>> >>>>>>>>>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas >>>>>>>>>>><mail(a)jaromir.net> wrote: >>>>>>>>>>>>Hi Nicolas, Eliot, >>>>>>>>>>>> >>>>>>>>>>>>here's what I understand is happening (see the enclosed >>>>>>>>>>>>screenshot): >>>>>>>>>>>> >>>>>>>>>>>>1) we fork a new process to evaluate [^1] >>>>>>>>>>>>2) the new process evaluates [^1] which means
instruction
>>>>>>>>>>>>18 is being evaluated, hence pc points to instruction 19 >>>>>>>>>>>>now >>>>>>>>>>>>3) however, the home context where ^1 should return to
is
>>>>>>>>>>>>gone by this time (the process that executed the fork
has
>>>>>>>>>>>>already returned - notice the two up arrows in the
debugger
>>>>>>>>>>>>screenshot) >>>>>>>>>>>>4) the VM can't finish the instruction and returns
control
>>>>>>>>>>>>to the image via placing the #cannotReturn: context on
top
>>>>>>>>>>>>of the [^1] context >>>>>>>>>>>>5) #cannotReturn: evaluation results in signalling the
BCR
>>>>>>>>>>>>exception which is then handled by the #resume handler >>>>>>>>>>>> (in our debugged case the [:ex | self halt. ex resume] >>>>>>>>>>>>handler) >>>>>>>>>>>>6) ex resume is evaluated, however, this means
requesting
>>>>>>>>>>>>the VM to evaluate instruction 19 of the [^1] context - >>>>>>>>>>>>which is past the last instruction of the context and
the
>>>>>>>>>>>>crash ensues >>>>>>>>>>>> >>>>>>>>>>>>I wonder whether such situations could/should be
prevented
>>>>>>>>>>>>inside the VM or whether such an expectation is wrong
for
>>>>>>>>>>>>some reason. >>>>>>>>>>> >>>>>>>>>>>As Nicolas says, IMO this is best done at the image
level.
>>>>>>>>>>> >>>>>>>>>>>It could be prevented in the VM, but at great cost, and
only
>>>>>>>>>>>partially. The performance issue is that the last
bytecode
>>>>>>>>>>>in a method is not marked in any way, and that to
determine
>>>>>>>>>>>the last bytecode the bytecodes must be symbolically >>>>>>>>>>>evaluated from the start of the method. See implementors
of
>>>>>>>>>>>endPC at the image level (which defer to the method
trailer)
>>>>>>>>>>>and implementors of endPCOf: in the VMMaker code. Doing
this
>>>>>>>>>>>every time execution commences is prohibitively
expensive.
>>>>>>>>>>>The "only partially" issue is that following the return >>>>>>>>>>>instruction may be other valid bytecodes, but these are
not
>>>>>>>>>>>a continuation. >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>Consider the following code in some block: >>>>>>>>>>> [self expression ifTrue: >>>>>>>>>>> [^1]. >>>>>>>>>>> ^2 >>>>>>>>>>> >>>>>>>>>>>The bytecodes for this are >>>>>>>>>>> pushReceiver >>>>>>>>>>> send #expression >>>>>>>>>>> jumpFalse L1 >>>>>>>>>>> push 1 >>>>>>>>>>> methodReturnTop >>>>>>>>>>>L1 >>>>>>>>>>> push 2 >>>>>>>>>>> methodReturnTop >>>>>>>>>>> >>>>>>>>>>>Clearly if expression is true these should be *no* >>>>>>>>>>>continuation in which ^2 is executed. >>>>>>>>>> >>>>>>>>>>Well, in that case there's a bug because the computation
in
>>>>>>>>>>the following example shouldn't continue past the [^1]
block
>>>>>>>>>>but it silently does: >>>>>>>>>>`[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] >>>>>>>>>>fork` >>>>>>>>>> >>>>>>>>>>The bytecodes are >>>>>>>>>> push true >>>>>>>>>> jumpFalse L1 >>>>>>>>>> push 1 >>>>>>>>>> returnTop >>>>>>>>>>L1 >>>>>>>>>> push nil >>>>>>>>>> blockReturn >>>>>>>>>> >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>So even if the VM did try and detect whether the return
was
>>>>>>>>>>>at the last block method, it would only work for special >>>>>>>>>>>cases. >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>It seems to me the issue is simply that the context that >>>>>>>>>>>cannot be returned from should be marked as dead (see >>>>>>>>>>>Context>>isDead) by setting its pc to nil at some point, >>>>>>>>>>>presumably after copying the actual return pc into the >>>>>>>>>>>BlockCannotReturn exception, to avoid ever trying to
resume
>>>>>>>>>>>the context. >>>>>>>>>> >>>>>>>>>>Does this mean, in other words, that every context that >>>>>>>>>>returns should nil its pc to avoid being "wrongly" >>>>>>>>>>reused/executed in the future, which concerns primarily
those
>>>>>>>>>>being referenced somewhere hence potentially executable in >>>>>>>>>>the future, is that right? >>>>>>>>>>Hypothetical question: would nilling the pc during returns >>>>>>>>>>"fix" the example? >>>>>>>>>>Thanks a lot for helping me understand this. >>>>>>>>>>Best, >>>>>>>>>>Jaromir >>>>>>>>>> >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>Thanks, >>>>>>>>>>>>Jaromir >>>>>>>>>>>> >>>>>>>>>>>><bdxuqalu.png> >>>>>>>>>>>> >>>>>>>>>>>>------ Original Message ------ >>>>>>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The
general-purpose
>>>>>>>>>>>>Squeak developers list" >>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>>>Date 11/16/2023 6:48:43 PM >>>>>>>>>>>>Subject Re: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>>>>>>>>exception >>>>>>>>>>>> >>>>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>>> >>>>>>>>>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas >>>>>>>>>>>>>><mail(a)jaromir.net> wrote: >>>>>>>>>>>>>> >>>>>>>>>>>>>> >>>>>>>>>>>>>>Hi Nicloas, >>>>>>>>>>>>>>No no, I don't have any practical scenario in mind,
I'm
>>>>>>>>>>>>>>just trying to understand why the VM is implemented
like
>>>>>>>>>>>>>>this, whether there were a reason to leave this >>>>>>>>>>>>>>possibility of a crash, e.g. it would slow down the VM
to
>>>>>>>>>>>>>>try to prevent such a dumb situation (who would resume >>>>>>>>>>>>>>from BCR in his right mind? :) ) - or perhaps I have >>>>>>>>>>>>>>overlooked some good reason to even keep this behavior
in
>>>>>>>>>>>>>>the VM. That's all. >>>>>>>>>>>>> >>>>>>>>>>>>>Let's first understand what's really happening.
Presumably
>>>>>>>>>>>>>at tone point a context is resumed those pc is already
at
>>>>>>>>>>>>>the block return bytecode (effectively, because it
crashes
>>>>>>>>>>>>>in JITted code, but I bet the stack vm will crash also, >>>>>>>>>>>>>but not as cleanly - it will try and execute the bytes
in
>>>>>>>>>>>>>the encoded method trailer). So which method actually >>>>>>>>>>>>>sends resume, and to what, and what state is resume's >>>>>>>>>>>>>receiver when resume is sent? >>>>>>>>>>>>> >>>>>>>>>>>>> >>>>>>>>>>>>>> >>>>>>>>>>>>>>Thanks for your reply. >>>>>>>>>>>>>>Regards, >>>>>>>>>>>>>>Jaromir >>>>>>>>>>>>>> >>>>>>>>>>>>>> >>>>>>>>>>>>>> >>>>>>>>>>>>>> >>>>>>>>>>>>>>------ Original Message ------ >>>>>>>>>>>>>>>From "Nicolas Cellier" >>>>>>>>>>>>>><nicolas.cellier.aka.nice(a)gmail.com> >>>>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The >>>>>>>>>>>>>>general-purpose Squeak developers list" >>>>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>>>>>Date 11/16/2023 7:20:20 AM >>>>>>>>>>>>>>Subject Re: [squeak-dev] Resuming on BlockCannotReturn >>>>>>>>>>>>>>exception >>>>>>>>>>>>>> >>>>>>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>>>>>Is there a scenario where it would make sense to
resume
>>>>>>>>>>>>>>>a BlockCannotReturn? >>>>>>>>>>>>>>>If not, I would suggest to protect at image side and >>>>>>>>>>>>>>>override #resume. >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas >>>>>>>>>>>>>>><mail(a)jaromir.net> a écrit : >>>>>>>>>>>>>>>>Hi Eliot, Christoph, All, >>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>It's known the following example crashes the VM. Is >>>>>>>>>>>>>>>>this an intended behavior or a "tolerated bug"? >>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>I understand why it crashes: the non-local return
has
>>>>>>>>>>>>>>>>nowhere to return to and so resuming the computation >>>>>>>>>>>>>>>>leads to a crash. But why not raise another BCR >>>>>>>>>>>>>>>>exception to prevent the crash? Potential infinite >>>>>>>>>>>>>>>>loop? Perhaps I'm just missing the purpose of this >>>>>>>>>>>>>>>>behavior... >>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>Thanks for an explanation. >>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>Best, >>>>>>>>>>>>>>>>Jaromir >>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>-- >>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>Jaromir Matas >>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>> >>>>>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>-- >>>>>>>>>>>_,,,^..^,,,_ >>>>>>>>>>>best, Eliot >>>>>>>>><Context-cannotReturn.st> >>>>>> >>>>>> >>>>>>-- >>>>>>_,,,^..^,,,_ >>>>>>best, Eliot >>>>><ProcessTest-testResumeAfterBCR.st>
Links: ------ [1] https://github.com/hpi-swa-lab/squeak-inbox-talk
Much to learn, I still have.
On 30-Dec-23 11:29:53 PM, lewis@mail.msen.com wrote:
Understand it no one does.
On 2023-12-30 21:13, Jaromir Matas wrote:
nit: You mixed up the order of arguments for #assert:equals:
oops, sorry :) It happens to me all the time; I've never actually understood why the strange, almost Yodaesque, order... as if you asked in English:
"Make sure 18 is his age."
Thanks, Jaromir
On 30-Dec-23 9:13:56 PM, christoph.thiede@student.hpi.uni-potsdam.de wrote:
nit: You mixed up the order of arguments for #assert:equals: (it is assert: expected equals: actual) and could have used it in the final assert again, but that's clearly no reason to hold back a useful test. ;-) Merged, thanks! :-)
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-12-30T17:33:08+00:00, mail@jaromir.net wrote:
Hi Christoph,
Thanks for merging the fixes; I've just sent another test in KernelTests-jar.448 to complement them.
Please take a look and if ok I'd appreciate it if you could merge
it as
well.
Best regards and Happy New Year to you too! Jaromir
On 30-Dec-23 6:15:25 PM,
christoph.thiede(a)student.hpi.uni-potsdam.de
wrote:
Hi Jaromir, hi all,
finally I have found the time to review these suggestions. Kernel-jar.1537, Kernel-jar.1538, and Kernel-jar.1539 look
excellent to
me as well. Clear, straightforward, useful. :-) I have merged them
into
the trunk via Kernel-ct.1545.
Regarding DebuggerTests>>test16HandleSimulationError, I have
patched it
via ToolsTests-ct.125. Nothing to rack your brains over:
"thisContext
pc: nil" just mimicks any kind of unhandled error inside the
simulator
- since we now gently handle this via #cannotReturn:, I just
replaced
it with "thisContext pc: false". :-) Sorry for not clarifying that earlier and letting you speculate.
Thanks for your work, and I already wish you a happy new year!
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-11-29T13:31:09+00:00, mail(a)jaromir.net wrote:
Hi Marcel,
> [myself] whether the patch would have been necessary should
the
#return:from: had been fixed then
Nonsense, I just mixed it up with another issue :)
On 29-Nov-23 1:51:21 PM, "Jaromir Matas" <mail(a)jaromir.net>
wrote:
>Thanks Marcel! This test somehow slipped my attention :) > >The test can no longer work as is. It takes advantage of the
erroneous
>behavior of #return:from: in the sense that if you simulate > > thisContext pc: nil > >it'll happily return to a dead context (i.e. to thisContext
from
#pc:
>nil context) - which is not what the VM does during runtime.
It
should
>immediately raise an illegal return exception not only during
runtime
>but also during simulation. > >The test mentions a patch for an infinite debugger chain >(http://forum.world.st/I-broke-the-debugger-td5110752.html). I
wonder
>whether the problem could have something to do with this
simulation
bug
>in return:from:; and a terrible idea occurred to me whether
the
patch
>would have been necessary should the #return:from: had been
fixed
then
>;O > >We may potentially come up with more examples like this, even
in the
>trunk, where the bug from #return:from: propagated and was
taken
>advantage of. I've found and fixed #runUntilErrorOrReturnFrom:
but
more
>can still be surviving undetected... > >I'd place the test into #expectedFailures for now but maybe
it's
time
>to remove it; Christoph should decide :) > >Thanks again, >Jaromir > > >On 29-Nov-23 10:28:38 AM, "Taeumel, Marcel via Squeak-dev" ><squeak-dev(a)lists.squeakfoundation.org> wrote: > >>Hi Jaromir -- >> >>Looks good. Still, what about that
#test16HandleSimulationError
now?
>>:-) It is failing with your changes ... how would you adapt
it?
>> >> >> >>Best, >>Marcel >>>Am 28.11.2023 01:29:39 schrieb Jaromir Matas
<mail(a)jaromir.net>:
>>> >>>Hi Eliot, Marcel, all, >>> >>>I've sent a fix Kernel-jar.1539 to the Inbox that solves the >>>remaining bit of the chain of bugs described in the previous
post.
>>>All tests are green now and I think the root cause has been
found
and
>>>fixed. >>> >>>In this last bit I've created a version of stepToCallee that
would
>>>identify a potential illegal return to a nil sender and
avoid it.
>>> >>>Now this example can be debugged without any problems: >>> >>>[[self halt. ^ 1] on: BlockCannotReturn do: #resume ] fork >>> >>>If you're happy with the solution in Kernel-jar.1539, >>>Kernel-jar.1538, Kernel-jar.1537 and the test in
KernelTests-jar.447,
>>>could you please double-check and merge, please? (And remove >>>Kernel-mt.1534 and Tools-jar.1240 from the Inbox) >>> >>>Best, >>>Jaromir >>> >>> >>> >>>On 27-Nov-23 12:09:37 AM, "Jaromir Matas"
<mail(a)jaromir.net>
wrote:
>>> >>>>Hi Eliot, Christoph, all >>>> >>>>It looks like there are some more skeletons in the closet
:/
>>>> >>>>If you run this example >>>> >>>>[[self halt. ^ 1] on: BlockCannotReturn do: [:ex | ex
resume] ]
fork
>>>> >>>>and step over halt and then step over ^1 you get a
nonsensical
error
>>>>as a result of decoding nil as an instruction. >>>> >>>>It turns out that the root cause is in the #return:from:
method:
it
>>>>only checks whether aSender is dead but ignores the
possibility
that
>>>>aSender sender may be nil or dead in which cases the VM
also
>>>>responds with sending #cannotReturn, hence I assume the
simulator
>>>>should do the same. In addition, the VM nills the pc in
such
>>>>scenario, so I added the same functionality here too: >>>> >>>>Context >> return: value from: aSender >>>> "For simulation. Roll back self to aSender and return
value
>>>>from it. Execute any unwind blocks on the way. ASSUMES
aSender is
>>>>a sender of self" >>>> >>>> | newTop | >>>> newTop := aSender sender. >>>> (aSender isDead or: [newTop isNil or: [newTop isDead]])
ifTrue:
>>>> "<--------- this is extended ------" >>>> [^self pc: nil; send: #cannotReturn: to: self with: >>>>{value}]. "<------ pc: nil is added ----" >>>> (self findNextUnwindContextUpTo: newTop) ifNotNil: >>>> "Send #aboutToReturn:through: with nil as the second >>>>argument to avoid this bug: >>>> Cannot #stepOver '^2' in example '[^2] ensure: []'. >>>> See
>http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html
>http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html" >>>> [^self send: #aboutToReturn:through: to: self with:
{value.
>>>>nil}]. >>>> self releaseTo: newTop. >>>> newTop ifNotNil: [newTop push: value]. >>>> ^newTop >>>> >>>>In order for this to work #cannotReturn: has to be modified
as in
>>>>Kernel-jar.1537: >>>> >>>>Context >> cannotReturn: result >>>> >>>> closureOrNil ifNotNil: [^ self cannotReturn: result to:
self
>>>>home sender]. >>>> self error: 'Computation has been terminated!' >>>>"<----------- this has to be an Error -----" >>>> >>>>Then it almost works except when you keep stepping over in
the
>>>>example above, you get an MNU error on `self previousPc` in >>>>#cannotReturn:to:` with your solution of the VM crash. If
you
don't
>>>>mind I've amended your solution and added the final context
where
>>>>the computation couldn't return along with the pc: >>>> >>>>Context >> cannotReturn: result to: homeContext >>>> "The receiver tried to return result to homeContext that
cannot
>>>>be returned from. >>>> Capture the return context/pc in a BlockCannotReturn. Nil
the pc
>>>>to prevent repeat >>>> attempts and/or invalid continuation. Answer the result of >>>>raising the exception." >>>> >>>> | exception previousPc | >>>> exception := BlockCannotReturn new. >>>> previousPc := pc ifNotNil: [self previousPc]. "<-----
here's a
>>>>fix ----" >>>> exception >>>> result: result; >>>> deadHome: homeContext; >>>> finalContext: self; "<----- here's the new state, if >>>>that's fine ----" >>>> pc: previousPc. >>>> pc := nil. >>>> ^exception signal >>>> >>>>Unfortunately, this is still not the end of the story:
there are
>>>>situations where #runUntilErrorOrReturnFrom: places the two
guard
>>>>contexts below the bottom context. And that is a problem
because
>>>>when the method tries to remove the two guard contexts
before
>>>>returning at the end it uses #stepToCalee to do the job but
this
>>>>unforotunately was (ab)using the above bug in #return:from:
I'll
>>>>explain: #return:from: didn't check whether aSender sender
was
nil
>>>>and as a result it allowed to simulate a return to a "nil
context"
>>>>which was then (ab)used in the clean-up via #stepToCalee in
the
>>>>#runUntilErrorOrReturnFrom:. >>>> >>>>When I fixed the #return:from: bug, the
#runUntilErrorOrReturnFrom:
>>>>cleanup of the guard contexts no longer works in that very
special
>>>>case where the guard contexts are below the bottom context.
There's
>>>>one case where this is being used: #terminateAggresively by >>>>Christoph. >>>> >>>>If I'm right with this analysis, the
#runUntilErrorOrReturnFrom:
>>>>should get fixed too but I'll be away now for a few days
and I
won't
>>>>be able to respond. If you or Christoph had a chance to
take a
look
>>>>at Kernel-jar.1538 and Kernel-jar.1537 I'd be very
grateful. I
hope
>>>>this super long message at least makes some sense :) >>>>Best, >>>>Jaromir >>>> >>>>[1] Kernel-jar.1538, Kernel-jar.1537 >>>>[2] KernelTests-jar.447 >>>> >>>> >>>>PS: Christoph, >>>> >>>>With Kernel-jar.1538 + Kernel-jar.1537 your example >>>> >>>>process := >>>> [(c := thisContext) pc: nil. >>>> 2+3] newProcess. >>>>process runUntil: [:ctx | ctx selector = #cannotReturn:]. >>>>self assert: process suspendedContext sender sender = c. >>>>self assert: process suspendedContext arguments = {c}. >>>> >>>>works fine, I've just corrected your first assert. >>>> >>>> >>>> >>>> >>>> >>>>On 21-Nov-23 6:40:32 PM, "Eliot Miranda"
<eliot.miranda(a)gmail.com>
>>>>wrote: >>>> >>>>>Hi Jaromir, >>>>> >>>>>>On Nov 20, 2023, at 11:51 PM, Jaromir Matas
<mail(a)jaromir.net>
>>>>>>wrote: >>>>>> >>>>>> >>>>>>Hi Eliot, >>>>>>Very elegant! Now I finally got what you meant exactly :)
Thanks.
>>>>>> >>>>>>Two questions: >>>>>>1. in order for the enclosed test to work I'd need an
Error
>>>>>>instead of Processor debugWithTitle:full: call in
#cannotReturn:.
>>>>>>Otherwise I don't know how to catch a plain invocation of
the
>>>>>>Debugger: >>>>>> >>>>>>cannotReturn: result >>>>>> >>>>>> closureOrNil ifNotNil: [^ self cannotReturn: result to:
self
>>>>>>home sender]. >>>>>> self error: 'Computation has been terminated!' >>>>> >>>>>Much nicer. >>>>> >>>>>>2. We are capturing a pc of self which is completely
different
>>>>>>context from homeContext indeed. >>>>> >>>>>Right. The return is attempted from a specific return
bytecode
in a
>>>>>specific block. This is the coordinate of the return that
cannot
be
>>>>>made. This is the relevant point of origin of the cannot
return
>>>>>exception. >>>>> >>>>>Why the return fails is another matter: >>>>>- the home context's sender is a dead context (cannot be
resumed)
>>>>>- the home context's sender is nil (home already returned
from)
>>>>>- the block activation's home is nil rather than a context
(should
>>>>>not happen) >>>>> >>>>>But in all these cases the pc of the home context is
immaterial.
>>>>>The hike is being returned through/from, rather than from;
the
>>>>>home's pc is not relevant. >>>>> >>>>>>Maybe we could capture self in the exception too to make
it
more
>>>>>>clear/explicit what is going on: what context the
captured pc
is
>>>>>>actually associated with. Just a thought... >>>>> >>>>>Yes, I like that. I also like the idea of somehow passing
the
>>>>>block activation's pc to the debugger so that the relevant
return
>>>>>expression is highlighted in the debugger. >>>>> >>>>>> >>>>>>Thanks again, >>>>>>Jaromir >>>>> >>>>>You're welcome. I love working in this part of the system.
Thanks
>>>>>for dragging me there. I'm in a slump right now and
appreciate
the
>>>>>fellowship. >>>>> >>>>>>------ Original Message ------ >>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>>Cc squeak-dev(a)lists.squeakfoundation.org >>>>>>Date 11/21/2023 2:17:21 AM >>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>>exception >>>>>> >>>>>>>Hi Jaromir, >>>>>>> >>>>>>> see Kernel-eem.1535 for what I was suggesting. This
example
>>>>>>>now has an exception with the right pc value in it: >>>>>>> >>>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex
resume]]
>>>>>>>fork >>>>>>> >>>>>>>The fix is simply >>>>>>> >>>>>>>Context>>cannotReturn: result to: homeContext >>>>>>> "The receiver tried to return result to homeContext
that
>>>>>>>cannot be returned from. >>>>>>> Capture the return pc in a BlockCannotReturn. Nil the
pc to
>>>>>>>prevent repeat >>>>>>> attempts and/or invalid continuation. Answer the result
of
>>>>>>>raising the exception." >>>>>>> >>>>>>> | exception | >>>>>>> exception := BlockCannotReturn new. >>>>>>> exception >>>>>>> result: result; >>>>>>> deadHome: homeContext; >>>>>>> pc: self previousPc. >>>>>>> pc := nil. >>>>>>> ^exception signal >>>>>>> >>>>>>> >>>>>>>The VM crash is now avoided. The debugger displays the
method,
>>>>>>>but does not highlight the offending pc, which is no big
deal.
A
>>>>>>>suitable defaultHandler for B lockCannotReturn may be
able to
get
>>>>>>>the debugger to highlight correctly on opening. Try the >>>>>>>following examples: >>>>>>> >>>>>>>[[^1] on: BlockCannotReturn do: #resume] fork. >>>>>>> >>>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex
resume]]
>>>>>>>fork >>>>>>> >>>>>>>[[^1] value] fork. >>>>>>> >>>>>>>They al; seem to behave perfectly acceptably to me. Does
this
>>>>>>>fix work for you? >>>>>>> >>>>>>>On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas
<mail(a)jaromir.net>
>>>>>>>wrote: >>>>>>>>Hi Eliot, >>>>>>>> >>>>>>>>How about to nil the pc just before making the return: >>>>>>>>``` >>>>>>>>Context >> #cannotReturn: result >>>>>>>> >>>>>>>> self push: self pc. "backup the pc for the sake of >>>>>>>>debugging" >>>>>>>> closureOrNil ifNotNil: [^self cannotReturn: result to:
self
>>>>>>>>home sender; pc: nil]. >>>>>>>> Processor debugWithTitle: 'Computation has been
terminated!'
>>>>>>>>translated full: false >>>>>>>>``` >>>>>>>>The nilled pc should not even potentially interfere
with the
>>>>>>>>#isDead now. >>>>>>>> >>>>>>>>I hope this is at least a step in the right direction
:)
>>>>>>>> >>>>>>>>However, there's still a problem when debugging the
resumption
>>>>>>>>of #cannotReturn because the encoders expect a
reasonable
index.
>>>>>>>>I haven't figured out yet where to place a nil check -
#step,
>>>>>>>>#stepToSendOrReturn... ? >>>>>>>> >>>>>>>>Thanks again, >>>>>>>>Jaromir >>>>>>>> >>>>>>>> >>>>>>>>------ Original Message ------ >>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>>Date 11/17/2023 8:36:50 PM >>>>>>>>Subject Re: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>>>>exception >>>>>>>> >>>>>>>>>Hi Jaromir, >>>>>>>>> >>>>>>>>>>On Nov 17, 2023, at 7:05 AM, Jaromir Matas
<mail(a)jaromir.net>
>>>>>>>>>>wrote: >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>Eliot, hi again, >>>>>>>>>> >>>>>>>>>>Please disregard my previous comment about nilling
the
>>>>>>>>>>contexts that have returned. We are indeed talking
about
the
>>>>>>>>>>context directly under the #cannotReturn context
which is
>>>>>>>>>>totally different from the home context in another
thread
>>>>>>>>>>that's gone. >>>>>>>>>> >>>>>>>>>>I may still be confused but would nilling the pc of
the
>>>>>>>>>>context directly under the cannotReturn context help?
Here's
>>>>>>>>>>what I mean: >>>>>>>>>>``` >>>>>>>>>>Context >> #cannotReturn: result >>>>>>>>>> >>>>>>>>>> closureOrNil ifNotNil: [^self pc: nil; cannotReturn: >>>>>>>>>>result to: self home sender]. >>>>>>>>>> Processor debugWithTitle: 'Computation has been >>>>>>>>>>terminated!' translated full: false. >>>>>>>>>>``` >>>>>>>>>>Instead of crashing the VM invokes the debugger with
the
>>>>>>>>>>'Computation has been terminated!' message. >>>>>>>>>> >>>>>>>>>>Does this make sense? >>>>>>>>> >>>>>>>>>Nearly. But it loses the information on what the pc
actually
>>>>>>>>>is, and that's potentially vital information. So IMO
the ox
>>>>>>>>>should only be nilled between the BlockCannotReturn
exception
>>>>>>>>>being created and raised. >>>>>>>>> >>>>>>>>>[But if you try this don't be surprised if it causes a
few
>>>>>>>>>temporary problems. It looks to me that without a
little
>>>>>>>>>refactoring this could easily cause an infinite
recursion
>>>>>>>>>around the sending of isDead. I'm sure you'll be able
to fix
>>>>>>>>>the code to work correctly] >>>>>>>>> >>>>>>>>>>Thanks, >>>>>>>>>>Jaromir >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>------ Original Message ------ >>>>>>>>>>From "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>>>>To "Eliot Miranda" <eliot.miranda(a)gmail.com>; "The >>>>>>>>>>general-purpose Squeak developers list" >>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>Date 11/17/2023 10:15:17 AM >>>>>>>>>>Subject [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>>>>>>exception >>>>>>>>>> >>>>>>>>>>>Hi Eliot, >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>------ Original Message ------ >>>>>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>>>>>Cc "The general-purpose Squeak developers list" >>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>>Date 11/16/2023 11:52:45 PM >>>>>>>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on >>>>>>>>>>>BlockCannotReturn exception >>>>>>>>>>> >>>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>> >>>>>>>>>>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas >>>>>>>>>>>><mail(a)jaromir.net> wrote: >>>>>>>>>>>>>Hi Nicolas, Eliot, >>>>>>>>>>>>> >>>>>>>>>>>>>here's what I understand is happening (see the
enclosed
>>>>>>>>>>>>>screenshot): >>>>>>>>>>>>> >>>>>>>>>>>>>1) we fork a new process to evaluate [^1] >>>>>>>>>>>>>2) the new process evaluates [^1] which means
instruction
>>>>>>>>>>>>>18 is being evaluated, hence pc points to
instruction 19
>>>>>>>>>>>>>now >>>>>>>>>>>>>3) however, the home context where ^1 should
return to
is
>>>>>>>>>>>>>gone by this time (the process that executed the
fork
has
>>>>>>>>>>>>>already returned - notice the two up arrows in the
debugger
>>>>>>>>>>>>>screenshot) >>>>>>>>>>>>>4) the VM can't finish the instruction and returns
control
>>>>>>>>>>>>>to the image via placing the #cannotReturn:
context on
top
>>>>>>>>>>>>>of the [^1] context >>>>>>>>>>>>>5) #cannotReturn: evaluation results in signalling
the
BCR
>>>>>>>>>>>>>exception which is then handled by the #resume
handler
>>>>>>>>>>>>> (in our debugged case the [:ex | self halt. ex
resume]
>>>>>>>>>>>>>handler) >>>>>>>>>>>>>6) ex resume is evaluated, however, this means
requesting
>>>>>>>>>>>>>the VM to evaluate instruction 19 of the [^1]
context -
>>>>>>>>>>>>>which is past the last instruction of the context
and
the
>>>>>>>>>>>>>crash ensues >>>>>>>>>>>>> >>>>>>>>>>>>>I wonder whether such situations could/should be
prevented
>>>>>>>>>>>>>inside the VM or whether such an expectation is
wrong
for
>>>>>>>>>>>>>some reason. >>>>>>>>>>>> >>>>>>>>>>>>As Nicolas says, IMO this is best done at the image
level.
>>>>>>>>>>>> >>>>>>>>>>>>It could be prevented in the VM, but at great cost,
and
only
>>>>>>>>>>>>partially. The performance issue is that the last
bytecode
>>>>>>>>>>>>in a method is not marked in any way, and that to
determine
>>>>>>>>>>>>the last bytecode the bytecodes must be
symbolically
>>>>>>>>>>>>evaluated from the start of the method. See
implementors
of
>>>>>>>>>>>>endPC at the image level (which defer to the method
trailer)
>>>>>>>>>>>>and implementors of endPCOf: in the VMMaker code.
Doing
this
>>>>>>>>>>>>every time execution commences is prohibitively
expensive.
>>>>>>>>>>>>The "only partially" issue is that following the
return
>>>>>>>>>>>>instruction may be other valid bytecodes, but these
are
not
>>>>>>>>>>>>a continuation. >>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>Consider the following code in some block: >>>>>>>>>>>> [self expression ifTrue: >>>>>>>>>>>> [^1]. >>>>>>>>>>>> ^2 >>>>>>>>>>>> >>>>>>>>>>>>The bytecodes for this are >>>>>>>>>>>> pushReceiver >>>>>>>>>>>> send #expression >>>>>>>>>>>> jumpFalse L1 >>>>>>>>>>>> push 1 >>>>>>>>>>>> methodReturnTop >>>>>>>>>>>>L1 >>>>>>>>>>>> push 2 >>>>>>>>>>>> methodReturnTop >>>>>>>>>>>> >>>>>>>>>>>>Clearly if expression is true these should be *no* >>>>>>>>>>>>continuation in which ^2 is executed. >>>>>>>>>>> >>>>>>>>>>>Well, in that case there's a bug because the
computation
in
>>>>>>>>>>>the following example shouldn't continue past the
[^1]
block
>>>>>>>>>>>but it silently does: >>>>>>>>>>>`[[true ifTrue: [^ 1]] on: BlockCannotReturn do:
#resume ]
>>>>>>>>>>>fork` >>>>>>>>>>> >>>>>>>>>>>The bytecodes are >>>>>>>>>>> push true >>>>>>>>>>> jumpFalse L1 >>>>>>>>>>> push 1 >>>>>>>>>>> returnTop >>>>>>>>>>>L1 >>>>>>>>>>> push nil >>>>>>>>>>> blockReturn >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>So even if the VM did try and detect whether the
return
was
>>>>>>>>>>>>at the last block method, it would only work for
special
>>>>>>>>>>>>cases. >>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>It seems to me the issue is simply that the context
that
>>>>>>>>>>>>cannot be returned from should be marked as dead
(see
>>>>>>>>>>>>Context>>isDead) by setting its pc to nil at some
point,
>>>>>>>>>>>>presumably after copying the actual return pc into
the
>>>>>>>>>>>>BlockCannotReturn exception, to avoid ever trying
to
resume
>>>>>>>>>>>>the context. >>>>>>>>>>> >>>>>>>>>>>Does this mean, in other words, that every context
that
>>>>>>>>>>>returns should nil its pc to avoid being "wrongly" >>>>>>>>>>>reused/executed in the future, which concerns
primarily
those
>>>>>>>>>>>being referenced somewhere hence potentially
executable in
>>>>>>>>>>>the future, is that right? >>>>>>>>>>>Hypothetical question: would nilling the pc during
returns
>>>>>>>>>>>"fix" the example? >>>>>>>>>>>Thanks a lot for helping me understand this. >>>>>>>>>>>Best, >>>>>>>>>>>Jaromir >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>> >>>>>>>>>>>>>Thanks, >>>>>>>>>>>>>Jaromir >>>>>>>>>>>>> >>>>>>>>>>>>><bdxuqalu.png> >>>>>>>>>>>>> >>>>>>>>>>>>>------ Original Message ------ >>>>>>>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The
general-purpose
>>>>>>>>>>>>>Squeak developers list" >>>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>>>>Date 11/16/2023 6:48:43 PM >>>>>>>>>>>>>Subject Re: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>>>>>>>>>exception >>>>>>>>>>>>> >>>>>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>>>> >>>>>>>>>>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas >>>>>>>>>>>>>>><mail(a)jaromir.net> wrote: >>>>>>>>>>>>>>> >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>Hi Nicloas, >>>>>>>>>>>>>>>No no, I don't have any practical scenario in
mind,
I'm
>>>>>>>>>>>>>>>just trying to understand why the VM is
implemented
like
>>>>>>>>>>>>>>>this, whether there were a reason to leave this >>>>>>>>>>>>>>>possibility of a crash, e.g. it would slow down
the VM
to
>>>>>>>>>>>>>>>try to prevent such a dumb situation (who would
resume
>>>>>>>>>>>>>>>from BCR in his right mind? :) ) - or perhaps I
have
>>>>>>>>>>>>>>>overlooked some good reason to even keep this
behavior
in
>>>>>>>>>>>>>>>the VM. That's all. >>>>>>>>>>>>>> >>>>>>>>>>>>>>Let's first understand what's really happening.
Presumably
>>>>>>>>>>>>>>at tone point a context is resumed those pc is
already
at
>>>>>>>>>>>>>>the block return bytecode (effectively, because
it
crashes
>>>>>>>>>>>>>>in JITted code, but I bet the stack vm will crash
also,
>>>>>>>>>>>>>>but not as cleanly - it will try and execute the
bytes
in
>>>>>>>>>>>>>>the encoded method trailer). So which method
actually
>>>>>>>>>>>>>>sends resume, and to what, and what state is
resume's
>>>>>>>>>>>>>>receiver when resume is sent? >>>>>>>>>>>>>> >>>>>>>>>>>>>> >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>Thanks for your reply. >>>>>>>>>>>>>>>Regards, >>>>>>>>>>>>>>>Jaromir >>>>>>>>>>>>>>> >>>>>>>>>>>>>>> >>>>>>>>>>>>>>> >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>------ Original Message ------ >>>>>>>>>>>>>>>>From "Nicolas Cellier" >>>>>>>>>>>>>>><nicolas.cellier.aka.nice(a)gmail.com> >>>>>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The >>>>>>>>>>>>>>>general-purpose Squeak developers list" >>>>>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>>>>>>Date 11/16/2023 7:20:20 AM >>>>>>>>>>>>>>>Subject Re: [squeak-dev] Resuming on
BlockCannotReturn
>>>>>>>>>>>>>>>exception >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>>>>>>Is there a scenario where it would make sense
to
resume
>>>>>>>>>>>>>>>>a BlockCannotReturn? >>>>>>>>>>>>>>>>If not, I would suggest to protect at image
side and
>>>>>>>>>>>>>>>>override #resume. >>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas >>>>>>>>>>>>>>>><mail(a)jaromir.net> a écrit : >>>>>>>>>>>>>>>>>Hi Eliot, Christoph, All, >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>It's known the following example crashes the
VM. Is
>>>>>>>>>>>>>>>>>this an intended behavior or a "tolerated
bug"?
>>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume]
fork`
>>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>I understand why it crashes: the non-local
return
has
>>>>>>>>>>>>>>>>>nowhere to return to and so resuming the
computation
>>>>>>>>>>>>>>>>>leads to a crash. But why not raise another
BCR
>>>>>>>>>>>>>>>>>exception to prevent the crash? Potential
infinite
>>>>>>>>>>>>>>>>>loop? Perhaps I'm just missing the purpose of
this
>>>>>>>>>>>>>>>>>behavior... >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>Thanks for an explanation. >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>Best, >>>>>>>>>>>>>>>>>Jaromir >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>-- >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>Jaromir Matas >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>-- >>>>>>>>>>>>_,,,^..^,,,_ >>>>>>>>>>>>best, Eliot >>>>>>>>>><Context-cannotReturn.st> >>>>>>> >>>>>>> >>>>>>>-- >>>>>>>_,,,^..^,,,_ >>>>>>>best, Eliot >>>>>><ProcessTest-testResumeAfterBCR.st>

Maybe just renaming it to assertThatResultOf: equals: would help?
On 2024-02-01, at 10:16 AM, Eliot Miranda eliot.miranda@gmail.com wrote:
I *hate* assert:equals: for this very reason. I wonder if TestCase could use a specialized compiler that would add compile-time check and warn the programmer if they get things the wrong way round. Of course it’s non-trivial to detect constant expressions in general, but one might be able to catch 95% of goofs cheaply.
tim -- tim Rowledge; tim@rowledge.org; http://www.rowledge.org/tim Semolina - a system of signalling with pudding.
On Feb 1, 2024, at 11:13 AM, Tim Rowledge tim@rowledge.org wrote:
Maybe just renaming it to assertThatResultOf: equals: would help?
+1/2,
assertResultOf: is:
They may have to be typed and have to fit on the page. Brevity is a virtue if it doesn’t hurt readability.
On 2024-02-01, at 10:16 AM, Eliot Miranda eliot.miranda@gmail.com wrote:
I *hate* assert:equals: for this very reason. I wonder if TestCase could use a specialized compiler that would add compile-time check and warn the programmer if they get things the wrong way round. Of course it’s non-trivial to detect constant expressions in general, but one might be able to catch 95% of goofs cheaply.
tim
tim Rowledge; tim@rowledge.org; http://www.rowledge.org/tim Semolina - a system of signalling with pudding.
On 2024-02-25, at 5:35 PM, Eliot Miranda eliot.miranda@gmail.com wrote:
On Feb 1, 2024, at 11:13 AM, Tim Rowledge tim@rowledge.org wrote:
Maybe just renaming it to assertThatResultOf: equals: would help?
+1/2,
assertResultOf: is:
They may have to be typed and have to fit on the page. Brevity is a virtue if it doesn’t hurt readability.
Ya. :-)
tim -- tim Rowledge; tim@rowledge.org; http://www.rowledge.org/tim Useful Latin Phrases:- Magister Mundi sum! = I am the Master of the Universe!

Renaming unfortunately doesn't help with keeping compatible with existing code out there. So it doesn't free up #assert:equals: to the more common order of arguments.
Would be nice if one knew to which version of the SUnit package a sender was "linked". Of course there is no such thing, unless somebody creates an appropriate config map that nobody wants to load.
Tim Rowledge tim@rowledge.org schrieb am Mo., 26. Feb. 2024, 03:05:
On 2024-02-25, at 5:35 PM, Eliot Miranda eliot.miranda@gmail.com
wrote:
On Feb 1, 2024, at 11:13 AM, Tim Rowledge tim@rowledge.org wrote:
Maybe just renaming it to assertThatResultOf: equals: would help?
+1/2,
assertResultOf: is:
They may have to be typed and have to fit on the page. Brevity is a
virtue if it doesn’t hurt readability.
Ya. :-)
tim
tim Rowledge; tim@rowledge.org; http://www.rowledge.org/tim Useful Latin Phrases:- Magister Mundi sum! = I am the Master of the Universe!
On 2024-02-26, at 8:37 AM, Jakob Reschke jakres+squeak@gmail.com wrote:
Renaming unfortunately doesn't help with keeping compatible with existing code out there. So it doesn't free up #assert:equals: to the more common order of arguments.
OK, so a monotonically improving possibility would be to add @assertResultOf:is: and comment that it is a readability-improved version of assert:equals:. Combined with changing all the plausibly reachable code to use that, it should make things a little clearer.
tim -- tim Rowledge; tim@rowledge.org; http://www.rowledge.org/tim Never test for an error condition you don't know how to handle.
On 2/26/24 11:53, Tim Rowledge wrote:
On 2024-02-26, at 8:37 AM, Jakob Reschkejakres+squeak@gmail.com wrote:
Renaming unfortunately doesn't help with keeping compatible with existing code out there. So it doesn't free up #assert:equals: to the more common order of arguments.
OK, so a monotonically improving possibility would be to add @assertResultOf:is: and comment that it is a readability-improved version ofassert:equals:. Combined with changing all the plausibly reachable code to use that, it should make things a little clearer.
It might be simpler to fix the existing tests so that the assertions are written correctly. Presumably you would want to do that anyway, and I suspect that if the existing test suites were all written correctly in a consistent style then the perceived readability problem would go away.
I'll confess that my perspective is twisted by exposure to a vast swamp of unit test enhancements in various Java frameworks. There are as many variations on the JUnit frameworks as there are developer opinions, which turns out to be quite a lot. To my eyes, the result is a big mess.
Dave
On Feb 26, 2024, at 9:54 AM, Tim Rowledge tim@rowledge.org wrote:
On 2024-02-26, at 8:37 AM, Jakob Reschke jakres+squeak@gmail.com wrote:
Renaming unfortunately doesn't help with keeping compatible with existing code out there. So it doesn't free up #assert:equals: to the more common order of arguments.
OK, so a monotonically improving possibility would be to add @assertResultOf:is: and comment that it is a readability-improved version of assert:equals:. Combined with changing all the plausibly reachable code to use that, it should make things a little clearer.
+1000
tim
tim Rowledge; tim@rowledge.org; http://www.rowledge.org/tim Never test for an error condition you don't know how to handle.
Hi Christoph, all
I've just sent a minor fix to the Inbox I missed previously - Kernel-jar.1550.
if you debug and do step through to ^2 and then step over in [^2] ensure: [] the debugger incorrectly stops at #resume:through:.
This is an old issue predating any of my changes. I'm sending the fix as part of this thread because it's closely related (but independent).
I think it can be safely merged.
Thanks, Jaromir
On 30-Dec-23 6:15:25 PM, christoph.thiede@student.hpi.uni-potsdam.de wrote:
Hi Jaromir, hi all,
finally I have found the time to review these suggestions. Kernel-jar.1537, Kernel-jar.1538, and Kernel-jar.1539 look excellent to me as well. Clear, straightforward, useful. :-) I have merged them into the trunk via Kernel-ct.1545.
Regarding DebuggerTests>>test16HandleSimulationError, I have patched it via ToolsTests-ct.125. Nothing to rack your brains over: "thisContext pc: nil" just mimicks any kind of unhandled error inside the simulator
- since we now gently handle this via #cannotReturn:, I just replaced
it with "thisContext pc: false". :-) Sorry for not clarifying that earlier and letting you speculate.
Thanks for your work, and I already wish you a happy new year!
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-11-29T13:31:09+00:00, mail@jaromir.net wrote:
Hi Marcel,
[myself] whether the patch would have been necessary should the
#return:from: had been fixed then
Nonsense, I just mixed it up with another issue :)
On 29-Nov-23 1:51:21 PM, "Jaromir Matas" <mail(a)jaromir.net> wrote:
Thanks Marcel! This test somehow slipped my attention :)
The test can no longer work as is. It takes advantage of the
erroneous
behavior of #return:from: in the sense that if you simulate
thisContext pc: nil
it'll happily return to a dead context (i.e. to thisContext from
#pc:
nil context) - which is not what the VM does during runtime. It
should
immediately raise an illegal return exception not only during
runtime
but also during simulation.
The test mentions a patch for an infinite debugger chain (http://forum.world.st/I-broke-the-debugger-td5110752.html). I
wonder
whether the problem could have something to do with this simulation
bug
in return:from:; and a terrible idea occurred to me whether the
patch
would have been necessary should the #return:from: had been fixed
then
;O
We may potentially come up with more examples like this, even in the trunk, where the bug from #return:from: propagated and was taken advantage of. I've found and fixed #runUntilErrorOrReturnFrom: but
more
can still be surviving undetected...
I'd place the test into #expectedFailures for now but maybe it's
time
to remove it; Christoph should decide :)
Thanks again, Jaromir
On 29-Nov-23 10:28:38 AM, "Taeumel, Marcel via Squeak-dev" <squeak-dev(a)lists.squeakfoundation.org> wrote:
Hi Jaromir --
Looks good. Still, what about that #test16HandleSimulationError
now?
:-) It is failing with your changes ... how would you adapt it?
Best, Marcel
Am 28.11.2023 01:29:39 schrieb Jaromir Matas <mail(a)jaromir.net>:
Hi Eliot, Marcel, all,
I've sent a fix Kernel-jar.1539 to the Inbox that solves the remaining bit of the chain of bugs described in the previous post. All tests are green now and I think the root cause has been found
and
fixed.
In this last bit I've created a version of stepToCallee that would identify a potential illegal return to a nil sender and avoid it.
Now this example can be debugged without any problems:
[[self halt. ^ 1] on: BlockCannotReturn do: #resume ] fork
If you're happy with the solution in Kernel-jar.1539, Kernel-jar.1538, Kernel-jar.1537 and the test in
KernelTests-jar.447,
could you please double-check and merge, please? (And remove Kernel-mt.1534 and Tools-jar.1240 from the Inbox)
Best, Jaromir
On 27-Nov-23 12:09:37 AM, "Jaromir Matas" <mail(a)jaromir.net>
wrote:
Hi Eliot, Christoph, all
It looks like there are some more skeletons in the closet :/
If you run this example
[[self halt. ^ 1] on: BlockCannotReturn do: [:ex | ex resume] ]
fork
and step over halt and then step over ^1 you get a nonsensical
error
as a result of decoding nil as an instruction.
It turns out that the root cause is in the #return:from: method:
it
only checks whether aSender is dead but ignores the possibility
that
aSender sender may be nil or dead in which cases the VM also responds with sending #cannotReturn, hence I assume the simulator should do the same. In addition, the VM nills the pc in such scenario, so I added the same functionality here too:
Context >> return: value from: aSender "For simulation. Roll back self to aSender and return value from it. Execute any unwind blocks on the way. ASSUMES aSender is a sender of self"
| newTop | newTop := aSender sender. (aSender isDead or: [newTop isNil or: [newTop isDead]]) ifTrue: "<--------- this is extended ------" [^self pc: nil; send: #cannotReturn: to: self with: {value}]. "<------ pc: nil is added ----" (self findNextUnwindContextUpTo: newTop) ifNotNil: "Send #aboutToReturn:through: with nil as the second argument to avoid this bug: Cannot #stepOver '^2' in example '[^2] ensure: []'. See
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html"
[^self send: #aboutToReturn:through: to: self with: {value. nil}]. self releaseTo: newTop. newTop ifNotNil: [newTop push: value]. ^newTop
In order for this to work #cannotReturn: has to be modified as in Kernel-jar.1537:
Context >> cannotReturn: result
closureOrNil ifNotNil: [^ self cannotReturn: result to: self home sender]. self error: 'Computation has been terminated!' "<----------- this has to be an Error -----"
Then it almost works except when you keep stepping over in the example above, you get an MNU error on `self previousPc` in #cannotReturn:to:` with your solution of the VM crash. If you
don't
mind I've amended your solution and added the final context where the computation couldn't return along with the pc:
Context >> cannotReturn: result to: homeContext "The receiver tried to return result to homeContext that cannot be returned from. Capture the return context/pc in a BlockCannotReturn. Nil the pc to prevent repeat attempts and/or invalid continuation. Answer the result of raising the exception."
| exception previousPc | exception := BlockCannotReturn new. previousPc := pc ifNotNil: [self previousPc]. "<----- here's a fix ----" exception result: result; deadHome: homeContext; finalContext: self; "<----- here's the new state, if that's fine ----" pc: previousPc. pc := nil. ^exception signal
Unfortunately, this is still not the end of the story: there are situations where #runUntilErrorOrReturnFrom: places the two guard contexts below the bottom context. And that is a problem because when the method tries to remove the two guard contexts before returning at the end it uses #stepToCalee to do the job but this unforotunately was (ab)using the above bug in #return:from: -
I'll
explain: #return:from: didn't check whether aSender sender was
nil
and as a result it allowed to simulate a return to a "nil
context"
which was then (ab)used in the clean-up via #stepToCalee in the #runUntilErrorOrReturnFrom:.
When I fixed the #return:from: bug, the
#runUntilErrorOrReturnFrom:
cleanup of the guard contexts no longer works in that very
special
case where the guard contexts are below the bottom context.
There's
one case where this is being used: #terminateAggresively by Christoph.
If I'm right with this analysis, the #runUntilErrorOrReturnFrom: should get fixed too but I'll be away now for a few days and I
won't
be able to respond. If you or Christoph had a chance to take a
look
at Kernel-jar.1538 and Kernel-jar.1537 I'd be very grateful. I
hope
this super long message at least makes some sense :) Best, Jaromir
[1] Kernel-jar.1538, Kernel-jar.1537 [2] KernelTests-jar.447
PS: Christoph,
With Kernel-jar.1538 + Kernel-jar.1537 your example
process := [(c := thisContext) pc: nil. 2+3] newProcess. process runUntil: [:ctx | ctx selector = #cannotReturn:]. self assert: process suspendedContext sender sender = c. self assert: process suspendedContext arguments = {c}.
works fine, I've just corrected your first assert.
On 21-Nov-23 6:40:32 PM, "Eliot Miranda"
<eliot.miranda(a)gmail.com>
wrote:
>Hi Jaromir, > >>On Nov 20, 2023, at 11:51 PM, Jaromir Matas
<mail(a)jaromir.net>
>>wrote: >> >> >>Hi Eliot, >>Very elegant! Now I finally got what you meant exactly :)
Thanks.
>> >>Two questions: >>1. in order for the enclosed test to work I'd need an Error >>instead of Processor debugWithTitle:full: call in
#cannotReturn:.
>>Otherwise I don't know how to catch a plain invocation of the >>Debugger: >> >>cannotReturn: result >> >> closureOrNil ifNotNil: [^ self cannotReturn: result to: self >>home sender]. >> self error: 'Computation has been terminated!' > >Much nicer. > >>2. We are capturing a pc of self which is completely different >>context from homeContext indeed. > >Right. The return is attempted from a specific return bytecode
in a
>specific block. This is the coordinate of the return that cannot
be
>made. This is the relevant point of origin of the cannot return >exception. > >Why the return fails is another matter: >- the home context’s sender is a dead context (cannot be
resumed)
>- the home context’s sender is nil (home already returned from) >- the block activation’s home is nil rather than a context
(should
>not happen) > >But in all these cases the pc of the home context is immaterial. >The hike is being returned through/from, rather than from; the >home’s pc is not relevant. > >>Maybe we could capture self in the exception too to make it
more
>>clear/explicit what is going on: what context the captured pc
is
>>actually associated with. Just a thought... > >Yes, I like that. I also like the idea of somehow passing the >block activation’s pc to the debugger so that the relevant
return
>expression is highlighted in the debugger. > >> >>Thanks again, >>Jaromir > >You’re welcome. I love working in this part of the system.
Thanks
>for dragging me there. I’m in a slump right now and appreciate
the
>fellowship. > >>------ Original Message ------ >>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>To "Jaromir Matas" <mail(a)jaromir.net> >>Cc squeak-dev(a)lists.squeakfoundation.org >>Date 11/21/2023 2:17:21 AM >>Subject Re: Re[2]: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>exception >> >>>Hi Jaromir, >>> >>> see Kernel-eem.1535 for what I was suggesting. This example >>>now has an exception with the right pc value in it: >>> >>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex
resume]]
>>>fork >>> >>>The fix is simply >>> >>>Context>>cannotReturn: result to: homeContext >>> "The receiver tried to return result to homeContext that >>>cannot be returned from. >>> Capture the return pc in a BlockCannotReturn. Nil the pc to >>>prevent repeat >>> attempts and/or invalid continuation. Answer the result of >>>raising the exception." >>> >>> | exception | >>> exception := BlockCannotReturn new. >>> exception >>> result: result; >>> deadHome: homeContext; >>> pc: self previousPc. >>> pc := nil. >>> ^exception signal >>> >>> >>>The VM crash is now avoided. The debugger displays the method, >>>but does not highlight the offending pc, which is no big deal.
A
>>>suitable defaultHandler for B lockCannotReturn may be able to
get
>>>the debugger to highlight correctly on opening. Try the >>>following examples: >>> >>>[[^1] on: BlockCannotReturn do: #resume] fork. >>> >>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex
resume]]
>>>fork >>> >>>[[^1] value] fork. >>> >>>They al; seem to behave perfectly acceptably to me. Does this >>>fix work for you? >>> >>>On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas
<mail(a)jaromir.net>
>>>wrote: >>>>Hi Eliot, >>>> >>>>How about to nil the pc just before making the return: >>>>``` >>>>Context >> #cannotReturn: result >>>> >>>> self push: self pc. "backup the pc for the sake of >>>>debugging" >>>> closureOrNil ifNotNil: [^self cannotReturn: result to: self >>>>home sender; pc: nil]. >>>> Processor debugWithTitle: 'Computation has been terminated!' >>>>translated full: false >>>>``` >>>>The nilled pc should not even potentially interfere with the >>>>#isDead now. >>>> >>>>I hope this is at least a step in the right direction :) >>>> >>>>However, there's still a problem when debugging the
resumption
>>>>of #cannotReturn because the encoders expect a reasonable
index.
>>>>I haven't figured out yet where to place a nil check - #step, >>>>#stepToSendOrReturn... ? >>>> >>>>Thanks again, >>>>Jaromir >>>> >>>> >>>>------ Original Message ------ >>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>Date 11/17/2023 8:36:50 PM >>>>Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn >>>>exception >>>> >>>>>Hi Jaromir, >>>>> >>>>>>On Nov 17, 2023, at 7:05 AM, Jaromir Matas
<mail(a)jaromir.net>
>>>>>>wrote: >>>>>> >>>>>> >>>>>>Eliot, hi again, >>>>>> >>>>>>Please disregard my previous comment about nilling the >>>>>>contexts that have returned. We are indeed talking about
the
>>>>>>context directly under the #cannotReturn context which is >>>>>>totally different from the home context in another thread >>>>>>that's gone. >>>>>> >>>>>>I may still be confused but would nilling the pc of the >>>>>>context directly under the cannotReturn context help?
Here's
>>>>>>what I mean: >>>>>>``` >>>>>>Context >> #cannotReturn: result >>>>>> >>>>>> closureOrNil ifNotNil: [^self pc: nil; cannotReturn: >>>>>>result to: self home sender]. >>>>>> Processor debugWithTitle: 'Computation has been >>>>>>terminated!' translated full: false. >>>>>>``` >>>>>>Instead of crashing the VM invokes the debugger with the >>>>>>'Computation has been terminated!' message. >>>>>> >>>>>>Does this make sense? >>>>> >>>>>Nearly. But it loses the information on what the pc actually >>>>>is, and that’s potentially vital information. So IMO the ox >>>>>should only be nilled between the BlockCannotReturn
exception
>>>>>being created and raised. >>>>> >>>>>[But if you try this don’t be surprised if it causes a few >>>>>temporary problems. It looks to me that without a little >>>>>refactoring this could easily cause an infinite recursion >>>>>around the sending of isDead. I’m sure you’ll be able to fix >>>>>the code to work correctly] >>>>> >>>>>>Thanks, >>>>>>Jaromir >>>>>> >>>>>> >>>>>>------ Original Message ------ >>>>>>From "Jaromir Matas" <mail(a)jaromir.net> >>>>>>To "Eliot Miranda" <eliot.miranda(a)gmail.com>; "The >>>>>>general-purpose Squeak developers list" >>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>Date 11/17/2023 10:15:17 AM >>>>>>Subject [squeak-dev] Re: Resuming on BlockCannotReturn >>>>>>exception >>>>>> >>>>>>>Hi Eliot, >>>>>>> >>>>>>> >>>>>>> >>>>>>>------ Original Message ------ >>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>Cc "The general-purpose Squeak developers list" >>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>Date 11/16/2023 11:52:45 PM >>>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on >>>>>>>BlockCannotReturn exception >>>>>>> >>>>>>>>Hi Jaromir, >>>>>>>> >>>>>>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas >>>>>>>><mail(a)jaromir.net> wrote: >>>>>>>>>Hi Nicolas, Eliot, >>>>>>>>> >>>>>>>>>here's what I understand is happening (see the enclosed >>>>>>>>>screenshot): >>>>>>>>> >>>>>>>>>1) we fork a new process to evaluate [^1] >>>>>>>>>2) the new process evaluates [^1] which means
instruction
>>>>>>>>>18 is being evaluated, hence pc points to instruction 19 >>>>>>>>>now >>>>>>>>>3) however, the home context where ^1 should return to
is
>>>>>>>>>gone by this time (the process that executed the fork
has
>>>>>>>>>already returned - notice the two up arrows in the
debugger
>>>>>>>>>screenshot) >>>>>>>>>4) the VM can't finish the instruction and returns
control
>>>>>>>>>to the image via placing the #cannotReturn: context on
top
>>>>>>>>>of the [^1] context >>>>>>>>>5) #cannotReturn: evaluation results in signalling the
BCR
>>>>>>>>>exception which is then handled by the #resume handler >>>>>>>>> (in our debugged case the [:ex | self halt. ex resume] >>>>>>>>>handler) >>>>>>>>>6) ex resume is evaluated, however, this means
requesting
>>>>>>>>>the VM to evaluate instruction 19 of the [^1] context - >>>>>>>>>which is past the last instruction of the context and
the
>>>>>>>>>crash ensues >>>>>>>>> >>>>>>>>>I wonder whether such situations could/should be
prevented
>>>>>>>>>inside the VM or whether such an expectation is wrong
for
>>>>>>>>>some reason. >>>>>>>> >>>>>>>>As Nicolas says, IMO this is best done at the image
level.
>>>>>>>> >>>>>>>>It could be prevented in the VM, but at great cost, and
only
>>>>>>>>partially. The performance issue is that the last
bytecode
>>>>>>>>in a method is not marked in any way, and that to
determine
>>>>>>>>the last bytecode the bytecodes must be symbolically >>>>>>>>evaluated from the start of the method. See implementors
of
>>>>>>>>endPC at the image level (which defer to the method
trailer)
>>>>>>>>and implementors of endPCOf: in the VMMaker code. Doing
this
>>>>>>>>every time execution commences is prohibitively
expensive.
>>>>>>>>The "only partially" issue is that following the return >>>>>>>>instruction may be other valid bytecodes, but these are
not
>>>>>>>>a continuation. >>>>>>>> >>>>>>>> >>>>>>>>Consider the following code in some block: >>>>>>>> [self expression ifTrue: >>>>>>>> [^1]. >>>>>>>> ^2 >>>>>>>> >>>>>>>>The bytecodes for this are >>>>>>>> pushReceiver >>>>>>>> send #expression >>>>>>>> jumpFalse L1 >>>>>>>> push 1 >>>>>>>> methodReturnTop >>>>>>>>L1 >>>>>>>> push 2 >>>>>>>> methodReturnTop >>>>>>>> >>>>>>>>Clearly if expression is true these should be *no* >>>>>>>>continuation in which ^2 is executed. >>>>>>> >>>>>>>Well, in that case there's a bug because the computation
in
>>>>>>>the following example shouldn't continue past the [^1]
block
>>>>>>>but it silently does: >>>>>>>`[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] >>>>>>>fork` >>>>>>> >>>>>>>The bytecodes are >>>>>>> push true >>>>>>> jumpFalse L1 >>>>>>> push 1 >>>>>>> returnTop >>>>>>>L1 >>>>>>> push nil >>>>>>> blockReturn >>>>>>> >>>>>>> >>>>>>> >>>>>>>> >>>>>>>>So even if the VM did try and detect whether the return
was
>>>>>>>>at the last block method, it would only work for special >>>>>>>>cases. >>>>>>>> >>>>>>>> >>>>>>>>It seems to me the issue is simply that the context that >>>>>>>>cannot be returned from should be marked as dead (see >>>>>>>>Context>>isDead) by setting its pc to nil at some point, >>>>>>>>presumably after copying the actual return pc into the >>>>>>>>BlockCannotReturn exception, to avoid ever trying to
resume
>>>>>>>>the context. >>>>>>> >>>>>>>Does this mean, in other words, that every context that >>>>>>>returns should nil its pc to avoid being "wrongly" >>>>>>>reused/executed in the future, which concerns primarily
those
>>>>>>>being referenced somewhere hence potentially executable in >>>>>>>the future, is that right? >>>>>>>Hypothetical question: would nilling the pc during returns >>>>>>>"fix" the example? >>>>>>>Thanks a lot for helping me understand this. >>>>>>>Best, >>>>>>>Jaromir >>>>>>> >>>>>>> >>>>>>> >>>>>>>> >>>>>>>> >>>>>>>>> >>>>>>>>>Thanks, >>>>>>>>>Jaromir >>>>>>>>> >>>>>>>>><bdxuqalu.png> >>>>>>>>> >>>>>>>>>------ Original Message ------ >>>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The
general-purpose
>>>>>>>>>Squeak developers list" >>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>Date 11/16/2023 6:48:43 PM >>>>>>>>>Subject Re: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>>>>>exception >>>>>>>>> >>>>>>>>>>Hi Jaromir, >>>>>>>>>> >>>>>>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas >>>>>>>>>>><mail(a)jaromir.net> wrote: >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>Hi Nicloas, >>>>>>>>>>>No no, I don't have any practical scenario in mind,
I'm
>>>>>>>>>>>just trying to understand why the VM is implemented
like
>>>>>>>>>>>this, whether there were a reason to leave this >>>>>>>>>>>possibility of a crash, e.g. it would slow down the VM
to
>>>>>>>>>>>try to prevent such a dumb situation (who would resume >>>>>>>>>>>from BCR in his right mind? :) ) - or perhaps I have >>>>>>>>>>>overlooked some good reason to even keep this behavior
in
>>>>>>>>>>>the VM. That's all. >>>>>>>>>> >>>>>>>>>>Let’s first understand what’s really happening.
Presumably
>>>>>>>>>>at tone point a context is resumed those pc is already
at
>>>>>>>>>>the block return bytecode (effectively, because it
crashes
>>>>>>>>>>in JITted code, but I bet the stack vm will crash also, >>>>>>>>>>but not as cleanly - it will try and execute the bytes
in
>>>>>>>>>>the encoded method trailer). So which method actually >>>>>>>>>>sends resume, and to what, and what state is resume’s >>>>>>>>>>receiver when resume is sent? >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>Thanks for your reply. >>>>>>>>>>>Regards, >>>>>>>>>>>Jaromir >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>------ Original Message ------ >>>>>>>>>>>From "Nicolas Cellier" >>>>>>>>>>><nicolas.cellier.aka.nice(a)gmail.com> >>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The >>>>>>>>>>>general-purpose Squeak developers list" >>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>>Date 11/16/2023 7:20:20 AM >>>>>>>>>>>Subject Re: [squeak-dev] Resuming on BlockCannotReturn >>>>>>>>>>>exception >>>>>>>>>>> >>>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>>Is there a scenario where it would make sense to
resume
>>>>>>>>>>>>a BlockCannotReturn? >>>>>>>>>>>>If not, I would suggest to protect at image side and >>>>>>>>>>>>override #resume. >>>>>>>>>>>> >>>>>>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas >>>>>>>>>>>><mail(a)jaromir.net> a écrit : >>>>>>>>>>>>>Hi Eliot, Christoph, All, >>>>>>>>>>>>> >>>>>>>>>>>>>It's known the following example crashes the VM. Is >>>>>>>>>>>>>this an intended behavior or a "tolerated bug"? >>>>>>>>>>>>> >>>>>>>>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>>>>>>>>>>> >>>>>>>>>>>>>I understand why it crashes: the non-local return
has
>>>>>>>>>>>>>nowhere to return to and so resuming the computation >>>>>>>>>>>>>leads to a crash. But why not raise another BCR >>>>>>>>>>>>>exception to prevent the crash? Potential infinite >>>>>>>>>>>>>loop? Perhaps I'm just missing the purpose of this >>>>>>>>>>>>>behavior... >>>>>>>>>>>>> >>>>>>>>>>>>>Thanks for an explanation. >>>>>>>>>>>>> >>>>>>>>>>>>>Best, >>>>>>>>>>>>>Jaromir >>>>>>>>>>>>> >>>>>>>>>>>>>-- >>>>>>>>>>>>> >>>>>>>>>>>>>Jaromir Matas >>>>>>>>>>>>> >>>>>>>>>>>>> >>>>>>>>>>> >>>>>>>> >>>>>>>> >>>>>>>>-- >>>>>>>>_,,,^..^,,,_ >>>>>>>>best, Eliot >>>>>><Context-cannotReturn.st> >>> >>> >>>-- >>>_,,,^..^,,,_ >>>best, Eliot >><ProcessTest-testResumeAfterBCR.st>
Hi Jaromir,
do you have any idea why the former behavior would also stop when the context activates a new method?
Otherwise, I agree that seeing that #resume:through: context in the debugger is probably not required in this situation.
Best, Christoph
PS: Here's another bug if you haven't it on your radar already: In the same expression ([^2] ensure: []), step through, through, over so you end in FullBlockClosure(BlockClosure)>>ensure:. Step over, over, over, over to move beyond aBlock value. At the last step, you will get another BCR in a second debugger. :-)
--- Sent from Squeak Inbox Talk
On 2024-01-09T19:46:15+00:00, mail@jaromir.net wrote:
Hi Christoph, all
I've just sent a minor fix to the Inbox I missed previously - Kernel-jar.1550.
if you debug and do step through to ^2 and then step over in [^2] ensure: [] the debugger incorrectly stops at #resume:through:.
This is an old issue predating any of my changes. I'm sending the fix as part of this thread because it's closely related (but independent).
I think it can be safely merged.
Thanks, Jaromir
On 30-Dec-23 6:15:25 PM, christoph.thiede(a)student.hpi.uni-potsdam.de wrote:
Hi Jaromir, hi all,
finally I have found the time to review these suggestions. Kernel-jar.1537, Kernel-jar.1538, and Kernel-jar.1539 look excellent to me as well. Clear, straightforward, useful. :-) I have merged them into the trunk via Kernel-ct.1545.
Regarding DebuggerTests>>test16HandleSimulationError, I have patched it via ToolsTests-ct.125. Nothing to rack your brains over: "thisContext pc: nil" just mimicks any kind of unhandled error inside the simulator
- since we now gently handle this via #cannotReturn:, I just replaced
it with "thisContext pc: false". :-) Sorry for not clarifying that earlier and letting you speculate.
Thanks for your work, and I already wish you a happy new year!
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-11-29T13:31:09+00:00, mail(a)jaromir.net wrote:
Hi Marcel,
[myself] whether the patch would have been necessary should the
#return:from: had been fixed then
Nonsense, I just mixed it up with another issue :)
On 29-Nov-23 1:51:21 PM, "Jaromir Matas" <mail(a)jaromir.net> wrote:
Thanks Marcel! This test somehow slipped my attention :)
The test can no longer work as is. It takes advantage of the
erroneous
behavior of #return:from: in the sense that if you simulate
thisContext pc: nil
it'll happily return to a dead context (i.e. to thisContext from
#pc:
nil context) - which is not what the VM does during runtime. It
should
immediately raise an illegal return exception not only during
runtime
but also during simulation.
The test mentions a patch for an infinite debugger chain (http://forum.world.st/I-broke-the-debugger-td5110752.html). I
wonder
whether the problem could have something to do with this simulation
bug
in return:from:; and a terrible idea occurred to me whether the
patch
would have been necessary should the #return:from: had been fixed
then
;O
We may potentially come up with more examples like this, even in the trunk, where the bug from #return:from: propagated and was taken advantage of. I've found and fixed #runUntilErrorOrReturnFrom: but
more
can still be surviving undetected...
I'd place the test into #expectedFailures for now but maybe it's
time
to remove it; Christoph should decide :)
Thanks again, Jaromir
On 29-Nov-23 10:28:38 AM, "Taeumel, Marcel via Squeak-dev" <squeak-dev(a)lists.squeakfoundation.org> wrote:
Hi Jaromir --
Looks good. Still, what about that #test16HandleSimulationError
now?
:-) It is failing with your changes ... how would you adapt it?
Best, Marcel
Am 28.11.2023 01:29:39 schrieb Jaromir Matas <mail(a)jaromir.net>:
Hi Eliot, Marcel, all,
I've sent a fix Kernel-jar.1539 to the Inbox that solves the remaining bit of the chain of bugs described in the previous post. All tests are green now and I think the root cause has been found
and
fixed.
In this last bit I've created a version of stepToCallee that would identify a potential illegal return to a nil sender and avoid it.
Now this example can be debugged without any problems:
[[self halt. ^ 1] on: BlockCannotReturn do: #resume ] fork
If you're happy with the solution in Kernel-jar.1539, Kernel-jar.1538, Kernel-jar.1537 and the test in
KernelTests-jar.447,
could you please double-check and merge, please? (And remove Kernel-mt.1534 and Tools-jar.1240 from the Inbox)
Best, Jaromir
On 27-Nov-23 12:09:37 AM, "Jaromir Matas" <mail(a)jaromir.net>
wrote:
>Hi Eliot, Christoph, all > >It looks like there are some more skeletons in the closet :/ > >If you run this example > >[[self halt. ^ 1] on: BlockCannotReturn do: [:ex | ex resume] ]
fork
> >and step over halt and then step over ^1 you get a nonsensical
error
>as a result of decoding nil as an instruction. > >It turns out that the root cause is in the #return:from: method:
it
>only checks whether aSender is dead but ignores the possibility
that
>aSender sender may be nil or dead in which cases the VM also >responds with sending #cannotReturn, hence I assume the simulator >should do the same. In addition, the VM nills the pc in such >scenario, so I added the same functionality here too: > >Context >> return: value from: aSender > "For simulation. Roll back self to aSender and return value >from it. Execute any unwind blocks on the way. ASSUMES aSender is >a sender of self" > > | newTop | > newTop := aSender sender. > (aSender isDead or: [newTop isNil or: [newTop isDead]]) ifTrue: > "<--------- this is extended ------" > [^self pc: nil; send: #cannotReturn: to: self with: >{value}]. "<------ pc: nil is added ----" > (self findNextUnwindContextUpTo: newTop) ifNotNil: > "Send #aboutToReturn:through: with nil as the second >argument to avoid this bug: > Cannot #stepOver '^2' in example '[^2] ensure: []'. > See
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html" > [^self send: #aboutToReturn:through: to: self with: {value. >nil}]. > self releaseTo: newTop. > newTop ifNotNil: [newTop push: value]. > ^newTop > >In order for this to work #cannotReturn: has to be modified as in >Kernel-jar.1537: > >Context >> cannotReturn: result > > closureOrNil ifNotNil: [^ self cannotReturn: result to: self >home sender]. > self error: 'Computation has been terminated!' >"<----------- this has to be an Error -----" > >Then it almost works except when you keep stepping over in the >example above, you get an MNU error on `self previousPc` in >#cannotReturn:to:` with your solution of the VM crash. If you
don't
>mind I've amended your solution and added the final context where >the computation couldn't return along with the pc: > >Context >> cannotReturn: result to: homeContext > "The receiver tried to return result to homeContext that cannot >be returned from. > Capture the return context/pc in a BlockCannotReturn. Nil the pc >to prevent repeat > attempts and/or invalid continuation. Answer the result of >raising the exception." > > | exception previousPc | > exception := BlockCannotReturn new. > previousPc := pc ifNotNil: [self previousPc]. "<----- here's a >fix ----" > exception > result: result; > deadHome: homeContext; > finalContext: self; "<----- here's the new state, if >that's fine ----" > pc: previousPc. > pc := nil. > ^exception signal > >Unfortunately, this is still not the end of the story: there are >situations where #runUntilErrorOrReturnFrom: places the two guard >contexts below the bottom context. And that is a problem because >when the method tries to remove the two guard contexts before >returning at the end it uses #stepToCalee to do the job but this >unforotunately was (ab)using the above bug in #return:from: -
I'll
>explain: #return:from: didn't check whether aSender sender was
nil
>and as a result it allowed to simulate a return to a "nil
context"
>which was then (ab)used in the clean-up via #stepToCalee in the >#runUntilErrorOrReturnFrom:. > >When I fixed the #return:from: bug, the
#runUntilErrorOrReturnFrom:
>cleanup of the guard contexts no longer works in that very
special
>case where the guard contexts are below the bottom context.
There's
>one case where this is being used: #terminateAggresively by >Christoph. > >If I'm right with this analysis, the #runUntilErrorOrReturnFrom: >should get fixed too but I'll be away now for a few days and I
won't
>be able to respond. If you or Christoph had a chance to take a
look
>at Kernel-jar.1538 and Kernel-jar.1537 I'd be very grateful. I
hope
>this super long message at least makes some sense :) >Best, >Jaromir > >[1] Kernel-jar.1538, Kernel-jar.1537 >[2] KernelTests-jar.447 > > >PS: Christoph, > >With Kernel-jar.1538 + Kernel-jar.1537 your example > >process := > [(c := thisContext) pc: nil. > 2+3] newProcess. >process runUntil: [:ctx | ctx selector = #cannotReturn:]. >self assert: process suspendedContext sender sender = c. >self assert: process suspendedContext arguments = {c}. > >works fine, I've just corrected your first assert. > > > > > >On 21-Nov-23 6:40:32 PM, "Eliot Miranda"
<eliot.miranda(a)gmail.com>
>wrote: > >>Hi Jaromir, >> >>>On Nov 20, 2023, at 11:51 PM, Jaromir Matas
<mail(a)jaromir.net>
>>>wrote: >>> >>> >>>Hi Eliot, >>>Very elegant! Now I finally got what you meant exactly :)
Thanks.
>>> >>>Two questions: >>>1. in order for the enclosed test to work I'd need an Error >>>instead of Processor debugWithTitle:full: call in
#cannotReturn:.
>>>Otherwise I don't know how to catch a plain invocation of the >>>Debugger: >>> >>>cannotReturn: result >>> >>> closureOrNil ifNotNil: [^ self cannotReturn: result to: self >>>home sender]. >>> self error: 'Computation has been terminated!' >> >>Much nicer. >> >>>2. We are capturing a pc of self which is completely different >>>context from homeContext indeed. >> >>Right. The return is attempted from a specific return bytecode
in a
>>specific block. This is the coordinate of the return that cannot
be
>>made. This is the relevant point of origin of the cannot return >>exception. >> >>Why the return fails is another matter: >>- the home context’s sender is a dead context (cannot be
resumed)
>>- the home context’s sender is nil (home already returned from) >>- the block activation’s home is nil rather than a context
(should
>>not happen) >> >>But in all these cases the pc of the home context is immaterial. >>The hike is being returned through/from, rather than from; the >>home’s pc is not relevant. >> >>>Maybe we could capture self in the exception too to make it
more
>>>clear/explicit what is going on: what context the captured pc
is
>>>actually associated with. Just a thought... >> >>Yes, I like that. I also like the idea of somehow passing the >>block activation’s pc to the debugger so that the relevant
return
>>expression is highlighted in the debugger. >> >>> >>>Thanks again, >>>Jaromir >> >>You’re welcome. I love working in this part of the system.
Thanks
>>for dragging me there. I’m in a slump right now and appreciate
the
>>fellowship. >> >>>------ Original Message ------ >>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>To "Jaromir Matas" <mail(a)jaromir.net> >>>Cc squeak-dev(a)lists.squeakfoundation.org >>>Date 11/21/2023 2:17:21 AM >>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>exception >>> >>>>Hi Jaromir, >>>> >>>> see Kernel-eem.1535 for what I was suggesting. This example >>>>now has an exception with the right pc value in it: >>>> >>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex
resume]]
>>>>fork >>>> >>>>The fix is simply >>>> >>>>Context>>cannotReturn: result to: homeContext >>>> "The receiver tried to return result to homeContext that >>>>cannot be returned from. >>>> Capture the return pc in a BlockCannotReturn. Nil the pc to >>>>prevent repeat >>>> attempts and/or invalid continuation. Answer the result of >>>>raising the exception." >>>> >>>> | exception | >>>> exception := BlockCannotReturn new. >>>> exception >>>> result: result; >>>> deadHome: homeContext; >>>> pc: self previousPc. >>>> pc := nil. >>>> ^exception signal >>>> >>>> >>>>The VM crash is now avoided. The debugger displays the method, >>>>but does not highlight the offending pc, which is no big deal.
A
>>>>suitable defaultHandler for B lockCannotReturn may be able to
get
>>>>the debugger to highlight correctly on opening. Try the >>>>following examples: >>>> >>>>[[^1] on: BlockCannotReturn do: #resume] fork. >>>> >>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex
resume]]
>>>>fork >>>> >>>>[[^1] value] fork. >>>> >>>>They al; seem to behave perfectly acceptably to me. Does this >>>>fix work for you? >>>> >>>>On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas
<mail(a)jaromir.net>
>>>>wrote: >>>>>Hi Eliot, >>>>> >>>>>How about to nil the pc just before making the return: >>>>>``` >>>>>Context >> #cannotReturn: result >>>>> >>>>> self push: self pc. "backup the pc for the sake of >>>>>debugging" >>>>> closureOrNil ifNotNil: [^self cannotReturn: result to: self >>>>>home sender; pc: nil]. >>>>> Processor debugWithTitle: 'Computation has been terminated!' >>>>>translated full: false >>>>>``` >>>>>The nilled pc should not even potentially interfere with the >>>>>#isDead now. >>>>> >>>>>I hope this is at least a step in the right direction :) >>>>> >>>>>However, there's still a problem when debugging the
resumption
>>>>>of #cannotReturn because the encoders expect a reasonable
index.
>>>>>I haven't figured out yet where to place a nil check - #step, >>>>>#stepToSendOrReturn... ? >>>>> >>>>>Thanks again, >>>>>Jaromir >>>>> >>>>> >>>>>------ Original Message ------ >>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>Date 11/17/2023 8:36:50 PM >>>>>Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn >>>>>exception >>>>> >>>>>>Hi Jaromir, >>>>>> >>>>>>>On Nov 17, 2023, at 7:05 AM, Jaromir Matas
<mail(a)jaromir.net>
>>>>>>>wrote: >>>>>>> >>>>>>> >>>>>>>Eliot, hi again, >>>>>>> >>>>>>>Please disregard my previous comment about nilling the >>>>>>>contexts that have returned. We are indeed talking about
the
>>>>>>>context directly under the #cannotReturn context which is >>>>>>>totally different from the home context in another thread >>>>>>>that's gone. >>>>>>> >>>>>>>I may still be confused but would nilling the pc of the >>>>>>>context directly under the cannotReturn context help?
Here's
>>>>>>>what I mean: >>>>>>>``` >>>>>>>Context >> #cannotReturn: result >>>>>>> >>>>>>> closureOrNil ifNotNil: [^self pc: nil; cannotReturn: >>>>>>>result to: self home sender]. >>>>>>> Processor debugWithTitle: 'Computation has been >>>>>>>terminated!' translated full: false. >>>>>>>``` >>>>>>>Instead of crashing the VM invokes the debugger with the >>>>>>>'Computation has been terminated!' message. >>>>>>> >>>>>>>Does this make sense? >>>>>> >>>>>>Nearly. But it loses the information on what the pc actually >>>>>>is, and that’s potentially vital information. So IMO the ox >>>>>>should only be nilled between the BlockCannotReturn
exception
>>>>>>being created and raised. >>>>>> >>>>>>[But if you try this don’t be surprised if it causes a few >>>>>>temporary problems. It looks to me that without a little >>>>>>refactoring this could easily cause an infinite recursion >>>>>>around the sending of isDead. I’m sure you’ll be able to fix >>>>>>the code to work correctly] >>>>>> >>>>>>>Thanks, >>>>>>>Jaromir >>>>>>> >>>>>>> >>>>>>>------ Original Message ------ >>>>>>>From "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>To "Eliot Miranda" <eliot.miranda(a)gmail.com>; "The >>>>>>>general-purpose Squeak developers list" >>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>Date 11/17/2023 10:15:17 AM >>>>>>>Subject [squeak-dev] Re: Resuming on BlockCannotReturn >>>>>>>exception >>>>>>> >>>>>>>>Hi Eliot, >>>>>>>> >>>>>>>> >>>>>>>> >>>>>>>>------ Original Message ------ >>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>>Cc "The general-purpose Squeak developers list" >>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>Date 11/16/2023 11:52:45 PM >>>>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on >>>>>>>>BlockCannotReturn exception >>>>>>>> >>>>>>>>>Hi Jaromir, >>>>>>>>> >>>>>>>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas >>>>>>>>><mail(a)jaromir.net> wrote: >>>>>>>>>>Hi Nicolas, Eliot, >>>>>>>>>> >>>>>>>>>>here's what I understand is happening (see the enclosed >>>>>>>>>>screenshot): >>>>>>>>>> >>>>>>>>>>1) we fork a new process to evaluate [^1] >>>>>>>>>>2) the new process evaluates [^1] which means
instruction
>>>>>>>>>>18 is being evaluated, hence pc points to instruction 19 >>>>>>>>>>now >>>>>>>>>>3) however, the home context where ^1 should return to
is
>>>>>>>>>>gone by this time (the process that executed the fork
has
>>>>>>>>>>already returned - notice the two up arrows in the
debugger
>>>>>>>>>>screenshot) >>>>>>>>>>4) the VM can't finish the instruction and returns
control
>>>>>>>>>>to the image via placing the #cannotReturn: context on
top
>>>>>>>>>>of the [^1] context >>>>>>>>>>5) #cannotReturn: evaluation results in signalling the
BCR
>>>>>>>>>>exception which is then handled by the #resume handler >>>>>>>>>> (in our debugged case the [:ex | self halt. ex resume] >>>>>>>>>>handler) >>>>>>>>>>6) ex resume is evaluated, however, this means
requesting
>>>>>>>>>>the VM to evaluate instruction 19 of the [^1] context - >>>>>>>>>>which is past the last instruction of the context and
the
>>>>>>>>>>crash ensues >>>>>>>>>> >>>>>>>>>>I wonder whether such situations could/should be
prevented
>>>>>>>>>>inside the VM or whether such an expectation is wrong
for
>>>>>>>>>>some reason. >>>>>>>>> >>>>>>>>>As Nicolas says, IMO this is best done at the image
level.
>>>>>>>>> >>>>>>>>>It could be prevented in the VM, but at great cost, and
only
>>>>>>>>>partially. The performance issue is that the last
bytecode
>>>>>>>>>in a method is not marked in any way, and that to
determine
>>>>>>>>>the last bytecode the bytecodes must be symbolically >>>>>>>>>evaluated from the start of the method. See implementors
of
>>>>>>>>>endPC at the image level (which defer to the method
trailer)
>>>>>>>>>and implementors of endPCOf: in the VMMaker code. Doing
this
>>>>>>>>>every time execution commences is prohibitively
expensive.
>>>>>>>>>The "only partially" issue is that following the return >>>>>>>>>instruction may be other valid bytecodes, but these are
not
>>>>>>>>>a continuation. >>>>>>>>> >>>>>>>>> >>>>>>>>>Consider the following code in some block: >>>>>>>>> [self expression ifTrue: >>>>>>>>> [^1]. >>>>>>>>> ^2 >>>>>>>>> >>>>>>>>>The bytecodes for this are >>>>>>>>> pushReceiver >>>>>>>>> send #expression >>>>>>>>> jumpFalse L1 >>>>>>>>> push 1 >>>>>>>>> methodReturnTop >>>>>>>>>L1 >>>>>>>>> push 2 >>>>>>>>> methodReturnTop >>>>>>>>> >>>>>>>>>Clearly if expression is true these should be *no* >>>>>>>>>continuation in which ^2 is executed. >>>>>>>> >>>>>>>>Well, in that case there's a bug because the computation
in
>>>>>>>>the following example shouldn't continue past the [^1]
block
>>>>>>>>but it silently does: >>>>>>>>`[[true ifTrue: [^ 1]] on: BlockCannotReturn do: #resume ] >>>>>>>>fork` >>>>>>>> >>>>>>>>The bytecodes are >>>>>>>> push true >>>>>>>> jumpFalse L1 >>>>>>>> push 1 >>>>>>>> returnTop >>>>>>>>L1 >>>>>>>> push nil >>>>>>>> blockReturn >>>>>>>> >>>>>>>> >>>>>>>> >>>>>>>>> >>>>>>>>>So even if the VM did try and detect whether the return
was
>>>>>>>>>at the last block method, it would only work for special >>>>>>>>>cases. >>>>>>>>> >>>>>>>>> >>>>>>>>>It seems to me the issue is simply that the context that >>>>>>>>>cannot be returned from should be marked as dead (see >>>>>>>>>Context>>isDead) by setting its pc to nil at some point, >>>>>>>>>presumably after copying the actual return pc into the >>>>>>>>>BlockCannotReturn exception, to avoid ever trying to
resume
>>>>>>>>>the context. >>>>>>>> >>>>>>>>Does this mean, in other words, that every context that >>>>>>>>returns should nil its pc to avoid being "wrongly" >>>>>>>>reused/executed in the future, which concerns primarily
those
>>>>>>>>being referenced somewhere hence potentially executable in >>>>>>>>the future, is that right? >>>>>>>>Hypothetical question: would nilling the pc during returns >>>>>>>>"fix" the example? >>>>>>>>Thanks a lot for helping me understand this. >>>>>>>>Best, >>>>>>>>Jaromir >>>>>>>> >>>>>>>> >>>>>>>> >>>>>>>>> >>>>>>>>> >>>>>>>>>> >>>>>>>>>>Thanks, >>>>>>>>>>Jaromir >>>>>>>>>> >>>>>>>>>><bdxuqalu.png> >>>>>>>>>> >>>>>>>>>>------ Original Message ------ >>>>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The
general-purpose
>>>>>>>>>>Squeak developers list" >>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>Date 11/16/2023 6:48:43 PM >>>>>>>>>>Subject Re: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>>>>>>exception >>>>>>>>>> >>>>>>>>>>>Hi Jaromir, >>>>>>>>>>> >>>>>>>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas >>>>>>>>>>>><mail(a)jaromir.net> wrote: >>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>Hi Nicloas, >>>>>>>>>>>>No no, I don't have any practical scenario in mind,
I'm
>>>>>>>>>>>>just trying to understand why the VM is implemented
like
>>>>>>>>>>>>this, whether there were a reason to leave this >>>>>>>>>>>>possibility of a crash, e.g. it would slow down the VM
to
>>>>>>>>>>>>try to prevent such a dumb situation (who would resume >>>>>>>>>>>>from BCR in his right mind? :) ) - or perhaps I have >>>>>>>>>>>>overlooked some good reason to even keep this behavior
in
>>>>>>>>>>>>the VM. That's all. >>>>>>>>>>> >>>>>>>>>>>Let’s first understand what’s really happening.
Presumably
>>>>>>>>>>>at tone point a context is resumed those pc is already
at
>>>>>>>>>>>the block return bytecode (effectively, because it
crashes
>>>>>>>>>>>in JITted code, but I bet the stack vm will crash also, >>>>>>>>>>>but not as cleanly - it will try and execute the bytes
in
>>>>>>>>>>>the encoded method trailer). So which method actually >>>>>>>>>>>sends resume, and to what, and what state is resume’s >>>>>>>>>>>receiver when resume is sent? >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>Thanks for your reply. >>>>>>>>>>>>Regards, >>>>>>>>>>>>Jaromir >>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>------ Original Message ------ >>>>>>>>>>>>From "Nicolas Cellier" >>>>>>>>>>>><nicolas.cellier.aka.nice(a)gmail.com> >>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The >>>>>>>>>>>>general-purpose Squeak developers list" >>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>>>Date 11/16/2023 7:20:20 AM >>>>>>>>>>>>Subject Re: [squeak-dev] Resuming on BlockCannotReturn >>>>>>>>>>>>exception >>>>>>>>>>>> >>>>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>>>Is there a scenario where it would make sense to
resume
>>>>>>>>>>>>>a BlockCannotReturn? >>>>>>>>>>>>>If not, I would suggest to protect at image side and >>>>>>>>>>>>>override #resume. >>>>>>>>>>>>> >>>>>>>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas >>>>>>>>>>>>><mail(a)jaromir.net> a écrit : >>>>>>>>>>>>>>Hi Eliot, Christoph, All, >>>>>>>>>>>>>> >>>>>>>>>>>>>>It's known the following example crashes the VM. Is >>>>>>>>>>>>>>this an intended behavior or a "tolerated bug"? >>>>>>>>>>>>>> >>>>>>>>>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>>>>>>>>>>>> >>>>>>>>>>>>>>I understand why it crashes: the non-local return
has
>>>>>>>>>>>>>>nowhere to return to and so resuming the computation >>>>>>>>>>>>>>leads to a crash. But why not raise another BCR >>>>>>>>>>>>>>exception to prevent the crash? Potential infinite >>>>>>>>>>>>>>loop? Perhaps I'm just missing the purpose of this >>>>>>>>>>>>>>behavior... >>>>>>>>>>>>>> >>>>>>>>>>>>>>Thanks for an explanation. >>>>>>>>>>>>>> >>>>>>>>>>>>>>Best, >>>>>>>>>>>>>>Jaromir >>>>>>>>>>>>>> >>>>>>>>>>>>>>-- >>>>>>>>>>>>>> >>>>>>>>>>>>>>Jaromir Matas >>>>>>>>>>>>>> >>>>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>> >>>>>>>>> >>>>>>>>>-- >>>>>>>>>_,,,^..^,,,_ >>>>>>>>>best, Eliot >>>>>>><Context-cannotReturn.st> >>>> >>>> >>>>-- >>>>_,,,^..^,,,_ >>>>best, Eliot >>><ProcessTest-testResumeAfterBCR.st>
Hi Christoph,
I still owe you an explanation of the mechanics of the bug (detailed description for future reference - especially for me):
On 13-Jan-24 9:52:19 PM, christoph.thiede@student.hpi.uni-potsdam.de wrote:
Hi Jaromir,
do you have any idea why the former behavior would also stop when the context activates a new method?
The key to understanding the issue with #runUntilErrorOrReturnFrom: in this particular example is that before returning, when stepping until the guard contexts inserted by #runUntilErrorOrReturnFrom: are gone, the stepping finalizes the execution of #resumeEvaluating:through: and it finally terminates all contexts including the guard context inserted by #runUntilErrorOrReturnFrom: which will satisfiy the condition `ctxt isDead` at the end of #runUntilErrorOrReturnFrom: BUT #resumeEvaluating:through: still has to execute `aBlock value` which will become the intermediate point where contexts switch (stack top context changes), hence #stepToCalleeOrNil returns and the above mentioned condition is checked - resulting in the observed premature return from #runUntilErrorOrReturnFrom:. If we replace #stepToCalleeOrNil with #stepToSenderOrNil the stepping in #runUntilErrorOrReturnFrom: will only stop when the stack goes down which is exactly was was intended. (i.e. the bug manifests in #stepOver but it's a general deficiency in #runUntilErrorOrReturnFrom:)
Otherwise, I agree that seeing that #resume:through: context in the debugger is probably not required in this situation.
Best, Christoph
PS: Here's another bug if you haven't it on your radar already: In the same expression ([^2] ensure: []), step through, through, over so you end in FullBlockClosure(BlockClosure)>>ensure:. Step over, over, over, over to move beyond aBlock value. At the last step, you will get another BCR in a second debugger. :-)
Yeah, a nice one. I've already wondered why... I'll investigate. Thanks for the push :)
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2024-01-09T19:46:15+00:00, mail@jaromir.net wrote:
Hi Christoph, all
I've just sent a minor fix to the Inbox I missed previously - Kernel-jar.1550.
if you debug and do step through to ^2 and then step over in [^2] ensure: [] the debugger incorrectly stops at #resume:through:.
This is an old issue predating any of my changes. I'm sending the fix
as
part of this thread because it's closely related (but independent).
I think it can be safely merged.
Thanks, Jaromir
On 30-Dec-23 6:15:25 PM,
christoph.thiede(a)student.hpi.uni-potsdam.de
wrote:
Hi Jaromir, hi all,
finally I have found the time to review these suggestions. Kernel-jar.1537, Kernel-jar.1538, and Kernel-jar.1539 look excellent
to
me as well. Clear, straightforward, useful. :-) I have merged them
into
the trunk via Kernel-ct.1545.
Regarding DebuggerTests>>test16HandleSimulationError, I have patched
it
via ToolsTests-ct.125. Nothing to rack your brains over:
"thisContext
pc: nil" just mimicks any kind of unhandled error inside the
simulator
- since we now gently handle this via #cannotReturn:, I just
replaced
it with "thisContext pc: false". :-) Sorry for not clarifying that earlier and letting you speculate.
Thanks for your work, and I already wish you a happy new year!
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-11-29T13:31:09+00:00, mail(a)jaromir.net wrote:
Hi Marcel,
[myself] whether the patch would have been necessary should the
#return:from: had been fixed then
Nonsense, I just mixed it up with another issue :)
On 29-Nov-23 1:51:21 PM, "Jaromir Matas" <mail(a)jaromir.net>
wrote:
Thanks Marcel! This test somehow slipped my attention :)
The test can no longer work as is. It takes advantage of the
erroneous
behavior of #return:from: in the sense that if you simulate
thisContext pc: nil
it'll happily return to a dead context (i.e. to thisContext from
#pc:
nil context) - which is not what the VM does during runtime. It
should
immediately raise an illegal return exception not only during
runtime
but also during simulation.
The test mentions a patch for an infinite debugger chain (http://forum.world.st/I-broke-the-debugger-td5110752.html). I
wonder
whether the problem could have something to do with this
simulation
bug
in return:from:; and a terrible idea occurred to me whether the
patch
would have been necessary should the #return:from: had been
fixed
then
;O
We may potentially come up with more examples like this, even in
the
trunk, where the bug from #return:from: propagated and was taken advantage of. I've found and fixed #runUntilErrorOrReturnFrom:
but
more
can still be surviving undetected...
I'd place the test into #expectedFailures for now but maybe it's
time
to remove it; Christoph should decide :)
Thanks again, Jaromir
On 29-Nov-23 10:28:38 AM, "Taeumel, Marcel via Squeak-dev" <squeak-dev(a)lists.squeakfoundation.org> wrote:
Hi Jaromir --
Looks good. Still, what about that #test16HandleSimulationError
now?
:-) It is failing with your changes ... how would you adapt it?
Best, Marcel >Am 28.11.2023 01:29:39 schrieb Jaromir Matas
<mail(a)jaromir.net>:
> >Hi Eliot, Marcel, all, > >I've sent a fix Kernel-jar.1539 to the Inbox that solves the >remaining bit of the chain of bugs described in the previous
post.
>All tests are green now and I think the root cause has been
found
and
>fixed. > >In this last bit I've created a version of stepToCallee that
would
>identify a potential illegal return to a nil sender and avoid
it.
> >Now this example can be debugged without any problems: > >[[self halt. ^ 1] on: BlockCannotReturn do: #resume ] fork > >If you're happy with the solution in Kernel-jar.1539, >Kernel-jar.1538, Kernel-jar.1537 and the test in
KernelTests-jar.447,
>could you please double-check and merge, please? (And remove >Kernel-mt.1534 and Tools-jar.1240 from the Inbox) > >Best, >Jaromir > > > >On 27-Nov-23 12:09:37 AM, "Jaromir Matas" <mail(a)jaromir.net>
wrote:
> >>Hi Eliot, Christoph, all >> >>It looks like there are some more skeletons in the closet :/ >> >>If you run this example >> >>[[self halt. ^ 1] on: BlockCannotReturn do: [:ex | ex resume]
]
fork
>> >>and step over halt and then step over ^1 you get a
nonsensical
error
>>as a result of decoding nil as an instruction. >> >>It turns out that the root cause is in the #return:from:
method:
it
>>only checks whether aSender is dead but ignores the
possibility
that
>>aSender sender may be nil or dead in which cases the VM also >>responds with sending #cannotReturn, hence I assume the
simulator
>>should do the same. In addition, the VM nills the pc in such >>scenario, so I added the same functionality here too: >> >>Context >> return: value from: aSender >> "For simulation. Roll back self to aSender and return value >>from it. Execute any unwind blocks on the way. ASSUMES
aSender is
>>a sender of self" >> >> | newTop | >> newTop := aSender sender. >> (aSender isDead or: [newTop isNil or: [newTop isDead]])
ifTrue:
>> "<--------- this is extended ------" >> [^self pc: nil; send: #cannotReturn: to: self with: >>{value}]. "<------ pc: nil is added ----" >> (self findNextUnwindContextUpTo: newTop) ifNotNil: >> "Send #aboutToReturn:through: with nil as the second >>argument to avoid this bug: >> Cannot #stepOver '^2' in example '[^2] ensure: []'. >> See
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html"
>> [^self send: #aboutToReturn:through: to: self with: {value. >>nil}]. >> self releaseTo: newTop. >> newTop ifNotNil: [newTop push: value]. >> ^newTop >> >>In order for this to work #cannotReturn: has to be modified
as in
>>Kernel-jar.1537: >> >>Context >> cannotReturn: result >> >> closureOrNil ifNotNil: [^ self cannotReturn: result to: self >>home sender]. >> self error: 'Computation has been terminated!' >>"<----------- this has to be an Error -----" >> >>Then it almost works except when you keep stepping over in
the
>>example above, you get an MNU error on `self previousPc` in >>#cannotReturn:to:` with your solution of the VM crash. If you
don't
>>mind I've amended your solution and added the final context
where
>>the computation couldn't return along with the pc: >> >>Context >> cannotReturn: result to: homeContext >> "The receiver tried to return result to homeContext that
cannot
>>be returned from. >> Capture the return context/pc in a BlockCannotReturn. Nil
the pc
>>to prevent repeat >> attempts and/or invalid continuation. Answer the result of >>raising the exception." >> >> | exception previousPc | >> exception := BlockCannotReturn new. >> previousPc := pc ifNotNil: [self previousPc]. "<----- here's
a
>>fix ----" >> exception >> result: result; >> deadHome: homeContext; >> finalContext: self; "<----- here's the new state, if >>that's fine ----" >> pc: previousPc. >> pc := nil. >> ^exception signal >> >>Unfortunately, this is still not the end of the story: there
are
>>situations where #runUntilErrorOrReturnFrom: places the two
guard
>>contexts below the bottom context. And that is a problem
because
>>when the method tries to remove the two guard contexts before >>returning at the end it uses #stepToCalee to do the job but
this
>>unforotunately was (ab)using the above bug in #return:from: -
I'll
>>explain: #return:from: didn't check whether aSender sender
was
nil
>>and as a result it allowed to simulate a return to a "nil
context"
>>which was then (ab)used in the clean-up via #stepToCalee in
the
>>#runUntilErrorOrReturnFrom:. >> >>When I fixed the #return:from: bug, the
#runUntilErrorOrReturnFrom:
>>cleanup of the guard contexts no longer works in that very
special
>>case where the guard contexts are below the bottom context.
There's
>>one case where this is being used: #terminateAggresively by >>Christoph. >> >>If I'm right with this analysis, the
#runUntilErrorOrReturnFrom:
>>should get fixed too but I'll be away now for a few days and
I
won't
>>be able to respond. If you or Christoph had a chance to take
a
look
>>at Kernel-jar.1538 and Kernel-jar.1537 I'd be very grateful.
I
hope
>>this super long message at least makes some sense :) >>Best, >>Jaromir >> >>[1] Kernel-jar.1538, Kernel-jar.1537 >>[2] KernelTests-jar.447 >> >> >>PS: Christoph, >> >>With Kernel-jar.1538 + Kernel-jar.1537 your example >> >>process := >> [(c := thisContext) pc: nil. >> 2+3] newProcess. >>process runUntil: [:ctx | ctx selector = #cannotReturn:]. >>self assert: process suspendedContext sender sender = c. >>self assert: process suspendedContext arguments = {c}. >> >>works fine, I've just corrected your first assert. >> >> >> >> >> >>On 21-Nov-23 6:40:32 PM, "Eliot Miranda"
<eliot.miranda(a)gmail.com>
>>wrote: >> >>>Hi Jaromir, >>> >>>>On Nov 20, 2023, at 11:51 PM, Jaromir Matas
<mail(a)jaromir.net>
>>>>wrote: >>>> >>>> >>>>Hi Eliot, >>>>Very elegant! Now I finally got what you meant exactly :)
Thanks.
>>>> >>>>Two questions: >>>>1. in order for the enclosed test to work I'd need an Error >>>>instead of Processor debugWithTitle:full: call in
#cannotReturn:.
>>>>Otherwise I don't know how to catch a plain invocation of
the
>>>>Debugger: >>>> >>>>cannotReturn: result >>>> >>>> closureOrNil ifNotNil: [^ self cannotReturn: result to:
self
>>>>home sender]. >>>> self error: 'Computation has been terminated!' >>> >>>Much nicer. >>> >>>>2. We are capturing a pc of self which is completely
different
>>>>context from homeContext indeed. >>> >>>Right. The return is attempted from a specific return
bytecode
in a
>>>specific block. This is the coordinate of the return that
cannot
be
>>>made. This is the relevant point of origin of the cannot
return
>>>exception. >>> >>>Why the return fails is another matter: >>>- the home context’s sender is a dead context (cannot be
resumed)
>>>- the home context’s sender is nil (home already returned
from)
>>>- the block activation’s home is nil rather than a context
(should
>>>not happen) >>> >>>But in all these cases the pc of the home context is
immaterial.
>>>The hike is being returned through/from, rather than from;
the
>>>home’s pc is not relevant. >>> >>>>Maybe we could capture self in the exception too to make it
more
>>>>clear/explicit what is going on: what context the captured
pc
is
>>>>actually associated with. Just a thought... >>> >>>Yes, I like that. I also like the idea of somehow passing
the
>>>block activation’s pc to the debugger so that the relevant
return
>>>expression is highlighted in the debugger. >>> >>>> >>>>Thanks again, >>>>Jaromir >>> >>>You’re welcome. I love working in this part of the system.
Thanks
>>>for dragging me there. I’m in a slump right now and
appreciate
the
>>>fellowship. >>> >>>>------ Original Message ------ >>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>Cc squeak-dev(a)lists.squeakfoundation.org >>>>Date 11/21/2023 2:17:21 AM >>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>exception >>>> >>>>>Hi Jaromir, >>>>> >>>>> see Kernel-eem.1535 for what I was suggesting. This
example
>>>>>now has an exception with the right pc value in it: >>>>> >>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex
resume]]
>>>>>fork >>>>> >>>>>The fix is simply >>>>> >>>>>Context>>cannotReturn: result to: homeContext >>>>> "The receiver tried to return result to homeContext that >>>>>cannot be returned from. >>>>> Capture the return pc in a BlockCannotReturn. Nil the pc
to
>>>>>prevent repeat >>>>> attempts and/or invalid continuation. Answer the result
of
>>>>>raising the exception." >>>>> >>>>> | exception | >>>>> exception := BlockCannotReturn new. >>>>> exception >>>>> result: result; >>>>> deadHome: homeContext; >>>>> pc: self previousPc. >>>>> pc := nil. >>>>> ^exception signal >>>>> >>>>> >>>>>The VM crash is now avoided. The debugger displays the
method,
>>>>>but does not highlight the offending pc, which is no big
deal.
A
>>>>>suitable defaultHandler for B lockCannotReturn may be able
to
get
>>>>>the debugger to highlight correctly on opening. Try the >>>>>following examples: >>>>> >>>>>[[^1] on: BlockCannotReturn do: #resume] fork. >>>>> >>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex
resume]]
>>>>>fork >>>>> >>>>>[[^1] value] fork. >>>>> >>>>>They al; seem to behave perfectly acceptably to me. Does
this
>>>>>fix work for you? >>>>> >>>>>On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas
<mail(a)jaromir.net>
>>>>>wrote: >>>>>>Hi Eliot, >>>>>> >>>>>>How about to nil the pc just before making the return: >>>>>>``` >>>>>>Context >> #cannotReturn: result >>>>>> >>>>>> self push: self pc. "backup the pc for the sake of >>>>>>debugging" >>>>>> closureOrNil ifNotNil: [^self cannotReturn: result to:
self
>>>>>>home sender; pc: nil]. >>>>>> Processor debugWithTitle: 'Computation has been
terminated!'
>>>>>>translated full: false >>>>>>``` >>>>>>The nilled pc should not even potentially interfere with
the
>>>>>>#isDead now. >>>>>> >>>>>>I hope this is at least a step in the right direction :) >>>>>> >>>>>>However, there's still a problem when debugging the
resumption
>>>>>>of #cannotReturn because the encoders expect a reasonable
index.
>>>>>>I haven't figured out yet where to place a nil check -
#step,
>>>>>>#stepToSendOrReturn... ? >>>>>> >>>>>>Thanks again, >>>>>>Jaromir >>>>>> >>>>>> >>>>>>------ Original Message ------ >>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>>Date 11/17/2023 8:36:50 PM >>>>>>Subject Re: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>>exception >>>>>> >>>>>>>Hi Jaromir, >>>>>>> >>>>>>>>On Nov 17, 2023, at 7:05 AM, Jaromir Matas
<mail(a)jaromir.net>
>>>>>>>>wrote: >>>>>>>> >>>>>>>> >>>>>>>>Eliot, hi again, >>>>>>>> >>>>>>>>Please disregard my previous comment about nilling the >>>>>>>>contexts that have returned. We are indeed talking
about
the
>>>>>>>>context directly under the #cannotReturn context which
is
>>>>>>>>totally different from the home context in another
thread
>>>>>>>>that's gone. >>>>>>>> >>>>>>>>I may still be confused but would nilling the pc of the >>>>>>>>context directly under the cannotReturn context help?
Here's
>>>>>>>>what I mean: >>>>>>>>``` >>>>>>>>Context >> #cannotReturn: result >>>>>>>> >>>>>>>> closureOrNil ifNotNil: [^self pc: nil; cannotReturn: >>>>>>>>result to: self home sender]. >>>>>>>> Processor debugWithTitle: 'Computation has been >>>>>>>>terminated!' translated full: false. >>>>>>>>``` >>>>>>>>Instead of crashing the VM invokes the debugger with
the
>>>>>>>>'Computation has been terminated!' message. >>>>>>>> >>>>>>>>Does this make sense? >>>>>>> >>>>>>>Nearly. But it loses the information on what the pc
actually
>>>>>>>is, and that’s potentially vital information. So IMO the
ox
>>>>>>>should only be nilled between the BlockCannotReturn
exception
>>>>>>>being created and raised. >>>>>>> >>>>>>>[But if you try this don’t be surprised if it causes a
few
>>>>>>>temporary problems. It looks to me that without a little >>>>>>>refactoring this could easily cause an infinite
recursion
>>>>>>>around the sending of isDead. I’m sure you’ll be able to
fix
>>>>>>>the code to work correctly] >>>>>>> >>>>>>>>Thanks, >>>>>>>>Jaromir >>>>>>>> >>>>>>>> >>>>>>>>------ Original Message ------ >>>>>>>>From "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>>To "Eliot Miranda" <eliot.miranda(a)gmail.com>; "The >>>>>>>>general-purpose Squeak developers list" >>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>Date 11/17/2023 10:15:17 AM >>>>>>>>Subject [squeak-dev] Re: Resuming on BlockCannotReturn >>>>>>>>exception >>>>>>>> >>>>>>>>>Hi Eliot, >>>>>>>>> >>>>>>>>> >>>>>>>>> >>>>>>>>>------ Original Message ------ >>>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>>>Cc "The general-purpose Squeak developers list" >>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>Date 11/16/2023 11:52:45 PM >>>>>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on >>>>>>>>>BlockCannotReturn exception >>>>>>>>> >>>>>>>>>>Hi Jaromir, >>>>>>>>>> >>>>>>>>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas >>>>>>>>>><mail(a)jaromir.net> wrote: >>>>>>>>>>>Hi Nicolas, Eliot, >>>>>>>>>>> >>>>>>>>>>>here's what I understand is happening (see the
enclosed
>>>>>>>>>>>screenshot): >>>>>>>>>>> >>>>>>>>>>>1) we fork a new process to evaluate [^1] >>>>>>>>>>>2) the new process evaluates [^1] which means
instruction
>>>>>>>>>>>18 is being evaluated, hence pc points to
instruction 19
>>>>>>>>>>>now >>>>>>>>>>>3) however, the home context where ^1 should return
to
is
>>>>>>>>>>>gone by this time (the process that executed the
fork
has
>>>>>>>>>>>already returned - notice the two up arrows in the
debugger
>>>>>>>>>>>screenshot) >>>>>>>>>>>4) the VM can't finish the instruction and returns
control
>>>>>>>>>>>to the image via placing the #cannotReturn: context
on
top
>>>>>>>>>>>of the [^1] context >>>>>>>>>>>5) #cannotReturn: evaluation results in signalling
the
BCR
>>>>>>>>>>>exception which is then handled by the #resume
handler
>>>>>>>>>>> (in our debugged case the [:ex | self halt. ex
resume]
>>>>>>>>>>>handler) >>>>>>>>>>>6) ex resume is evaluated, however, this means
requesting
>>>>>>>>>>>the VM to evaluate instruction 19 of the [^1]
context -
>>>>>>>>>>>which is past the last instruction of the context
and
the
>>>>>>>>>>>crash ensues >>>>>>>>>>> >>>>>>>>>>>I wonder whether such situations could/should be
prevented
>>>>>>>>>>>inside the VM or whether such an expectation is
wrong
for
>>>>>>>>>>>some reason. >>>>>>>>>> >>>>>>>>>>As Nicolas says, IMO this is best done at the image
level.
>>>>>>>>>> >>>>>>>>>>It could be prevented in the VM, but at great cost,
and
only
>>>>>>>>>>partially. The performance issue is that the last
bytecode
>>>>>>>>>>in a method is not marked in any way, and that to
determine
>>>>>>>>>>the last bytecode the bytecodes must be symbolically >>>>>>>>>>evaluated from the start of the method. See
implementors
of
>>>>>>>>>>endPC at the image level (which defer to the method
trailer)
>>>>>>>>>>and implementors of endPCOf: in the VMMaker code.
Doing
this
>>>>>>>>>>every time execution commences is prohibitively
expensive.
>>>>>>>>>>The "only partially" issue is that following the
return
>>>>>>>>>>instruction may be other valid bytecodes, but these
are
not
>>>>>>>>>>a continuation. >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>Consider the following code in some block: >>>>>>>>>> [self expression ifTrue: >>>>>>>>>> [^1]. >>>>>>>>>> ^2 >>>>>>>>>> >>>>>>>>>>The bytecodes for this are >>>>>>>>>> pushReceiver >>>>>>>>>> send #expression >>>>>>>>>> jumpFalse L1 >>>>>>>>>> push 1 >>>>>>>>>> methodReturnTop >>>>>>>>>>L1 >>>>>>>>>> push 2 >>>>>>>>>> methodReturnTop >>>>>>>>>> >>>>>>>>>>Clearly if expression is true these should be *no* >>>>>>>>>>continuation in which ^2 is executed. >>>>>>>>> >>>>>>>>>Well, in that case there's a bug because the
computation
in
>>>>>>>>>the following example shouldn't continue past the [^1]
block
>>>>>>>>>but it silently does: >>>>>>>>>`[[true ifTrue: [^ 1]] on: BlockCannotReturn do:
#resume ]
>>>>>>>>>fork` >>>>>>>>> >>>>>>>>>The bytecodes are >>>>>>>>> push true >>>>>>>>> jumpFalse L1 >>>>>>>>> push 1 >>>>>>>>> returnTop >>>>>>>>>L1 >>>>>>>>> push nil >>>>>>>>> blockReturn >>>>>>>>> >>>>>>>>> >>>>>>>>> >>>>>>>>>> >>>>>>>>>>So even if the VM did try and detect whether the
return
was
>>>>>>>>>>at the last block method, it would only work for
special
>>>>>>>>>>cases. >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>It seems to me the issue is simply that the context
that
>>>>>>>>>>cannot be returned from should be marked as dead (see >>>>>>>>>>Context>>isDead) by setting its pc to nil at some
point,
>>>>>>>>>>presumably after copying the actual return pc into
the
>>>>>>>>>>BlockCannotReturn exception, to avoid ever trying to
resume
>>>>>>>>>>the context. >>>>>>>>> >>>>>>>>>Does this mean, in other words, that every context
that
>>>>>>>>>returns should nil its pc to avoid being "wrongly" >>>>>>>>>reused/executed in the future, which concerns
primarily
those
>>>>>>>>>being referenced somewhere hence potentially
executable in
>>>>>>>>>the future, is that right? >>>>>>>>>Hypothetical question: would nilling the pc during
returns
>>>>>>>>>"fix" the example? >>>>>>>>>Thanks a lot for helping me understand this. >>>>>>>>>Best, >>>>>>>>>Jaromir >>>>>>>>> >>>>>>>>> >>>>>>>>> >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>Thanks, >>>>>>>>>>>Jaromir >>>>>>>>>>> >>>>>>>>>>><bdxuqalu.png> >>>>>>>>>>> >>>>>>>>>>>------ Original Message ------ >>>>>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The
general-purpose
>>>>>>>>>>>Squeak developers list" >>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>>Date 11/16/2023 6:48:43 PM >>>>>>>>>>>Subject Re: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>>>>>>>exception >>>>>>>>>>> >>>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>> >>>>>>>>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas >>>>>>>>>>>>><mail(a)jaromir.net> wrote: >>>>>>>>>>>>> >>>>>>>>>>>>> >>>>>>>>>>>>>Hi Nicloas, >>>>>>>>>>>>>No no, I don't have any practical scenario in
mind,
I'm
>>>>>>>>>>>>>just trying to understand why the VM is
implemented
like
>>>>>>>>>>>>>this, whether there were a reason to leave this >>>>>>>>>>>>>possibility of a crash, e.g. it would slow down
the VM
to
>>>>>>>>>>>>>try to prevent such a dumb situation (who would
resume
>>>>>>>>>>>>>from BCR in his right mind? :) ) - or perhaps I
have
>>>>>>>>>>>>>overlooked some good reason to even keep this
behavior
in
>>>>>>>>>>>>>the VM. That's all. >>>>>>>>>>>> >>>>>>>>>>>>Let’s first understand what’s really happening.
Presumably
>>>>>>>>>>>>at tone point a context is resumed those pc is
already
at
>>>>>>>>>>>>the block return bytecode (effectively, because it
crashes
>>>>>>>>>>>>in JITted code, but I bet the stack vm will crash
also,
>>>>>>>>>>>>but not as cleanly - it will try and execute the
bytes
in
>>>>>>>>>>>>the encoded method trailer). So which method
actually
>>>>>>>>>>>>sends resume, and to what, and what state is
resume’s
>>>>>>>>>>>>receiver when resume is sent? >>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>> >>>>>>>>>>>>>Thanks for your reply. >>>>>>>>>>>>>Regards, >>>>>>>>>>>>>Jaromir >>>>>>>>>>>>> >>>>>>>>>>>>> >>>>>>>>>>>>> >>>>>>>>>>>>> >>>>>>>>>>>>>------ Original Message ------ >>>>>>>>>>>>>From "Nicolas Cellier" >>>>>>>>>>>>><nicolas.cellier.aka.nice(a)gmail.com> >>>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The >>>>>>>>>>>>>general-purpose Squeak developers list" >>>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>>>>Date 11/16/2023 7:20:20 AM >>>>>>>>>>>>>Subject Re: [squeak-dev] Resuming on
BlockCannotReturn
>>>>>>>>>>>>>exception >>>>>>>>>>>>> >>>>>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>>>>Is there a scenario where it would make sense to
resume
>>>>>>>>>>>>>>a BlockCannotReturn? >>>>>>>>>>>>>>If not, I would suggest to protect at image side
and
>>>>>>>>>>>>>>override #resume. >>>>>>>>>>>>>> >>>>>>>>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas >>>>>>>>>>>>>><mail(a)jaromir.net> a écrit : >>>>>>>>>>>>>>>Hi Eliot, Christoph, All, >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>It's known the following example crashes the VM.
Is
>>>>>>>>>>>>>>>this an intended behavior or a "tolerated bug"? >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>I understand why it crashes: the non-local
return
has
>>>>>>>>>>>>>>>nowhere to return to and so resuming the
computation
>>>>>>>>>>>>>>>leads to a crash. But why not raise another BCR >>>>>>>>>>>>>>>exception to prevent the crash? Potential
infinite
>>>>>>>>>>>>>>>loop? Perhaps I'm just missing the purpose of
this
>>>>>>>>>>>>>>>behavior... >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>Thanks for an explanation. >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>Best, >>>>>>>>>>>>>>>Jaromir >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>-- >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>Jaromir Matas >>>>>>>>>>>>>>> >>>>>>>>>>>>>>> >>>>>>>>>>>>> >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>-- >>>>>>>>>>_,,,^..^,,,_ >>>>>>>>>>best, Eliot >>>>>>>><Context-cannotReturn.st> >>>>> >>>>> >>>>>-- >>>>>_,,,^..^,,,_ >>>>>best, Eliot >>>><ProcessTest-testResumeAfterBCR.st>
Hi Jaromir, all,
just found another oddity with debugging non-local returns:
Debug it in a workspace, then select the second method from the stack in the debugger (CompiledMethod>>valueWithReceiver:arguments:) and press Through:
[sender := thisContext swapSender: nil. ^ 1] value.
Expected: A BlockCannotReturn error Actual: The method has returned 1!
It seems that the VM "checks" the validity of the entire stack up to the sender-to-return-to while the simulator essentially just uses "self home sender". I wonder what's the best way to fix this. Insert something like this at the beginning of Context>>#return:from:?
newSender := self findContextSuchThat: [:ea | ea == aSender].
Or would this break sideways returns for any scenario I currently don't see? I have to confess I do not know whether and when we support them at all ...
Best, Christoph
--- Sent from Squeak Inbox Talk
On 2024-02-01T17:27:21+00:00, mail@jaromir.net wrote:
Hi Christoph,
I still owe you an explanation of the mechanics of the bug (detailed description for future reference - especially for me):
On 13-Jan-24 9:52:19 PM, christoph.thiede(a)student.hpi.uni-potsdam.de wrote:
Hi Jaromir,
do you have any idea why the former behavior would also stop when the context activates a new method?
The key to understanding the issue with #runUntilErrorOrReturnFrom: in this particular example is that before returning, when stepping until the guard contexts inserted by #runUntilErrorOrReturnFrom: are gone, the stepping finalizes the execution of #resumeEvaluating:through: and it finally terminates all contexts including the guard context inserted by #runUntilErrorOrReturnFrom: which will satisfiy the condition `ctxt isDead` at the end of #runUntilErrorOrReturnFrom: BUT #resumeEvaluating:through: still has to execute `aBlock value` which will become the intermediate point where contexts switch (stack top context changes), hence #stepToCalleeOrNil returns and the above mentioned condition is checked - resulting in the observed premature return from #runUntilErrorOrReturnFrom:. If we replace #stepToCalleeOrNil with #stepToSenderOrNil the stepping in #runUntilErrorOrReturnFrom: will only stop when the stack goes down which is exactly was was intended. (i.e. the bug manifests in #stepOver but it's a general deficiency in #runUntilErrorOrReturnFrom:)
Otherwise, I agree that seeing that #resume:through: context in the debugger is probably not required in this situation.
Best, Christoph
PS: Here's another bug if you haven't it on your radar already: In the same expression ([^2] ensure: []), step through, through, over so you end in FullBlockClosure(BlockClosure)>>ensure:. Step over, over, over, over to move beyond aBlock value. At the last step, you will get another BCR in a second debugger. :-)
Yeah, a nice one. I've already wondered why... I'll investigate. Thanks for the push :)
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2024-01-09T19:46:15+00:00, mail(a)jaromir.net wrote:
Hi Christoph, all
I've just sent a minor fix to the Inbox I missed previously - Kernel-jar.1550.
if you debug and do step through to ^2 and then step over in [^2] ensure: [] the debugger incorrectly stops at #resume:through:.
This is an old issue predating any of my changes. I'm sending the fix
as
part of this thread because it's closely related (but independent).
I think it can be safely merged.
Thanks, Jaromir
On 30-Dec-23 6:15:25 PM,
christoph.thiede(a)student.hpi.uni-potsdam.de
wrote:
Hi Jaromir, hi all,
finally I have found the time to review these suggestions. Kernel-jar.1537, Kernel-jar.1538, and Kernel-jar.1539 look excellent
to
me as well. Clear, straightforward, useful. :-) I have merged them
into
the trunk via Kernel-ct.1545.
Regarding DebuggerTests>>test16HandleSimulationError, I have patched
it
via ToolsTests-ct.125. Nothing to rack your brains over:
"thisContext
pc: nil" just mimicks any kind of unhandled error inside the
simulator
- since we now gently handle this via #cannotReturn:, I just
replaced
it with "thisContext pc: false". :-) Sorry for not clarifying that earlier and letting you speculate.
Thanks for your work, and I already wish you a happy new year!
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-11-29T13:31:09+00:00, mail(a)jaromir.net wrote:
Hi Marcel,
[myself] whether the patch would have been necessary should the
#return:from: had been fixed then
Nonsense, I just mixed it up with another issue :)
On 29-Nov-23 1:51:21 PM, "Jaromir Matas" <mail(a)jaromir.net>
wrote:
Thanks Marcel! This test somehow slipped my attention :)
The test can no longer work as is. It takes advantage of the
erroneous
behavior of #return:from: in the sense that if you simulate
thisContext pc: nil
it'll happily return to a dead context (i.e. to thisContext from
#pc:
nil context) - which is not what the VM does during runtime. It
should
immediately raise an illegal return exception not only during
runtime
but also during simulation.
The test mentions a patch for an infinite debugger chain (http://forum.world.st/I-broke-the-debugger-td5110752.html). I
wonder
whether the problem could have something to do with this
simulation
bug
in return:from:; and a terrible idea occurred to me whether the
patch
would have been necessary should the #return:from: had been
fixed
then
;O
We may potentially come up with more examples like this, even in
the
trunk, where the bug from #return:from: propagated and was taken advantage of. I've found and fixed #runUntilErrorOrReturnFrom:
but
more
can still be surviving undetected...
I'd place the test into #expectedFailures for now but maybe it's
time
to remove it; Christoph should decide :)
Thanks again, Jaromir
On 29-Nov-23 10:28:38 AM, "Taeumel, Marcel via Squeak-dev" <squeak-dev(a)lists.squeakfoundation.org> wrote:
>Hi Jaromir -- > >Looks good. Still, what about that #test16HandleSimulationError
now?
>:-) It is failing with your changes ... how would you adapt it? > > > >Best, >Marcel >>Am 28.11.2023 01:29:39 schrieb Jaromir Matas
<mail(a)jaromir.net>:
>> >>Hi Eliot, Marcel, all, >> >>I've sent a fix Kernel-jar.1539 to the Inbox that solves the >>remaining bit of the chain of bugs described in the previous
post.
>>All tests are green now and I think the root cause has been
found
and
>>fixed. >> >>In this last bit I've created a version of stepToCallee that
would
>>identify a potential illegal return to a nil sender and avoid
it.
>> >>Now this example can be debugged without any problems: >> >>[[self halt. ^ 1] on: BlockCannotReturn do: #resume ] fork >> >>If you're happy with the solution in Kernel-jar.1539, >>Kernel-jar.1538, Kernel-jar.1537 and the test in
KernelTests-jar.447,
>>could you please double-check and merge, please? (And remove >>Kernel-mt.1534 and Tools-jar.1240 from the Inbox) >> >>Best, >>Jaromir >> >> >> >>On 27-Nov-23 12:09:37 AM, "Jaromir Matas" <mail(a)jaromir.net>
wrote:
>> >>>Hi Eliot, Christoph, all >>> >>>It looks like there are some more skeletons in the closet :/ >>> >>>If you run this example >>> >>>[[self halt. ^ 1] on: BlockCannotReturn do: [:ex | ex resume]
]
fork
>>> >>>and step over halt and then step over ^1 you get a
nonsensical
error
>>>as a result of decoding nil as an instruction. >>> >>>It turns out that the root cause is in the #return:from:
method:
it
>>>only checks whether aSender is dead but ignores the
possibility
that
>>>aSender sender may be nil or dead in which cases the VM also >>>responds with sending #cannotReturn, hence I assume the
simulator
>>>should do the same. In addition, the VM nills the pc in such >>>scenario, so I added the same functionality here too: >>> >>>Context >> return: value from: aSender >>> "For simulation. Roll back self to aSender and return value >>>from it. Execute any unwind blocks on the way. ASSUMES
aSender is
>>>a sender of self" >>> >>> | newTop | >>> newTop := aSender sender. >>> (aSender isDead or: [newTop isNil or: [newTop isDead]])
ifTrue:
>>> "<--------- this is extended ------" >>> [^self pc: nil; send: #cannotReturn: to: self with: >>>{value}]. "<------ pc: nil is added ----" >>> (self findNextUnwindContextUpTo: newTop) ifNotNil: >>> "Send #aboutToReturn:through: with nil as the second >>>argument to avoid this bug: >>> Cannot #stepOver '^2' in example '[^2] ensure: []'. >>> See
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html" >>> [^self send: #aboutToReturn:through: to: self with: {value. >>>nil}]. >>> self releaseTo: newTop. >>> newTop ifNotNil: [newTop push: value]. >>> ^newTop >>> >>>In order for this to work #cannotReturn: has to be modified
as in
>>>Kernel-jar.1537: >>> >>>Context >> cannotReturn: result >>> >>> closureOrNil ifNotNil: [^ self cannotReturn: result to: self >>>home sender]. >>> self error: 'Computation has been terminated!' >>>"<----------- this has to be an Error -----" >>> >>>Then it almost works except when you keep stepping over in
the
>>>example above, you get an MNU error on `self previousPc` in >>>#cannotReturn:to:` with your solution of the VM crash. If you
don't
>>>mind I've amended your solution and added the final context
where
>>>the computation couldn't return along with the pc: >>> >>>Context >> cannotReturn: result to: homeContext >>> "The receiver tried to return result to homeContext that
cannot
>>>be returned from. >>> Capture the return context/pc in a BlockCannotReturn. Nil
the pc
>>>to prevent repeat >>> attempts and/or invalid continuation. Answer the result of >>>raising the exception." >>> >>> | exception previousPc | >>> exception := BlockCannotReturn new. >>> previousPc := pc ifNotNil: [self previousPc]. "<----- here's
a
>>>fix ----" >>> exception >>> result: result; >>> deadHome: homeContext; >>> finalContext: self; "<----- here's the new state, if >>>that's fine ----" >>> pc: previousPc. >>> pc := nil. >>> ^exception signal >>> >>>Unfortunately, this is still not the end of the story: there
are
>>>situations where #runUntilErrorOrReturnFrom: places the two
guard
>>>contexts below the bottom context. And that is a problem
because
>>>when the method tries to remove the two guard contexts before >>>returning at the end it uses #stepToCalee to do the job but
this
>>>unforotunately was (ab)using the above bug in #return:from: -
I'll
>>>explain: #return:from: didn't check whether aSender sender
was
nil
>>>and as a result it allowed to simulate a return to a "nil
context"
>>>which was then (ab)used in the clean-up via #stepToCalee in
the
>>>#runUntilErrorOrReturnFrom:. >>> >>>When I fixed the #return:from: bug, the
#runUntilErrorOrReturnFrom:
>>>cleanup of the guard contexts no longer works in that very
special
>>>case where the guard contexts are below the bottom context.
There's
>>>one case where this is being used: #terminateAggresively by >>>Christoph. >>> >>>If I'm right with this analysis, the
#runUntilErrorOrReturnFrom:
>>>should get fixed too but I'll be away now for a few days and
I
won't
>>>be able to respond. If you or Christoph had a chance to take
a
look
>>>at Kernel-jar.1538 and Kernel-jar.1537 I'd be very grateful.
I
hope
>>>this super long message at least makes some sense :) >>>Best, >>>Jaromir >>> >>>[1] Kernel-jar.1538, Kernel-jar.1537 >>>[2] KernelTests-jar.447 >>> >>> >>>PS: Christoph, >>> >>>With Kernel-jar.1538 + Kernel-jar.1537 your example >>> >>>process := >>> [(c := thisContext) pc: nil. >>> 2+3] newProcess. >>>process runUntil: [:ctx | ctx selector = #cannotReturn:]. >>>self assert: process suspendedContext sender sender = c. >>>self assert: process suspendedContext arguments = {c}. >>> >>>works fine, I've just corrected your first assert. >>> >>> >>> >>> >>> >>>On 21-Nov-23 6:40:32 PM, "Eliot Miranda"
<eliot.miranda(a)gmail.com>
>>>wrote: >>> >>>>Hi Jaromir, >>>> >>>>>On Nov 20, 2023, at 11:51 PM, Jaromir Matas
<mail(a)jaromir.net>
>>>>>wrote: >>>>> >>>>> >>>>>Hi Eliot, >>>>>Very elegant! Now I finally got what you meant exactly :)
Thanks.
>>>>> >>>>>Two questions: >>>>>1. in order for the enclosed test to work I'd need an Error >>>>>instead of Processor debugWithTitle:full: call in
#cannotReturn:.
>>>>>Otherwise I don't know how to catch a plain invocation of
the
>>>>>Debugger: >>>>> >>>>>cannotReturn: result >>>>> >>>>> closureOrNil ifNotNil: [^ self cannotReturn: result to:
self
>>>>>home sender]. >>>>> self error: 'Computation has been terminated!' >>>> >>>>Much nicer. >>>> >>>>>2. We are capturing a pc of self which is completely
different
>>>>>context from homeContext indeed. >>>> >>>>Right. The return is attempted from a specific return
bytecode
in a
>>>>specific block. This is the coordinate of the return that
cannot
be
>>>>made. This is the relevant point of origin of the cannot
return
>>>>exception. >>>> >>>>Why the return fails is another matter: >>>>- the home context’s sender is a dead context (cannot be
resumed)
>>>>- the home context’s sender is nil (home already returned
from)
>>>>- the block activation’s home is nil rather than a context
(should
>>>>not happen) >>>> >>>>But in all these cases the pc of the home context is
immaterial.
>>>>The hike is being returned through/from, rather than from;
the
>>>>home’s pc is not relevant. >>>> >>>>>Maybe we could capture self in the exception too to make it
more
>>>>>clear/explicit what is going on: what context the captured
pc
is
>>>>>actually associated with. Just a thought... >>>> >>>>Yes, I like that. I also like the idea of somehow passing
the
>>>>block activation’s pc to the debugger so that the relevant
return
>>>>expression is highlighted in the debugger. >>>> >>>>> >>>>>Thanks again, >>>>>Jaromir >>>> >>>>You’re welcome. I love working in this part of the system.
Thanks
>>>>for dragging me there. I’m in a slump right now and
appreciate
the
>>>>fellowship. >>>> >>>>>------ Original Message ------ >>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>Cc squeak-dev(a)lists.squeakfoundation.org >>>>>Date 11/21/2023 2:17:21 AM >>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>exception >>>>> >>>>>>Hi Jaromir, >>>>>> >>>>>> see Kernel-eem.1535 for what I was suggesting. This
example
>>>>>>now has an exception with the right pc value in it: >>>>>> >>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex
resume]]
>>>>>>fork >>>>>> >>>>>>The fix is simply >>>>>> >>>>>>Context>>cannotReturn: result to: homeContext >>>>>> "The receiver tried to return result to homeContext that >>>>>>cannot be returned from. >>>>>> Capture the return pc in a BlockCannotReturn. Nil the pc
to
>>>>>>prevent repeat >>>>>> attempts and/or invalid continuation. Answer the result
of
>>>>>>raising the exception." >>>>>> >>>>>> | exception | >>>>>> exception := BlockCannotReturn new. >>>>>> exception >>>>>> result: result; >>>>>> deadHome: homeContext; >>>>>> pc: self previousPc. >>>>>> pc := nil. >>>>>> ^exception signal >>>>>> >>>>>> >>>>>>The VM crash is now avoided. The debugger displays the
method,
>>>>>>but does not highlight the offending pc, which is no big
deal.
A
>>>>>>suitable defaultHandler for B lockCannotReturn may be able
to
get
>>>>>>the debugger to highlight correctly on opening. Try the >>>>>>following examples: >>>>>> >>>>>>[[^1] on: BlockCannotReturn do: #resume] fork. >>>>>> >>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect. ex
resume]]
>>>>>>fork >>>>>> >>>>>>[[^1] value] fork. >>>>>> >>>>>>They al; seem to behave perfectly acceptably to me. Does
this
>>>>>>fix work for you? >>>>>> >>>>>>On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas
<mail(a)jaromir.net>
>>>>>>wrote: >>>>>>>Hi Eliot, >>>>>>> >>>>>>>How about to nil the pc just before making the return: >>>>>>>``` >>>>>>>Context >> #cannotReturn: result >>>>>>> >>>>>>> self push: self pc. "backup the pc for the sake of >>>>>>>debugging" >>>>>>> closureOrNil ifNotNil: [^self cannotReturn: result to:
self
>>>>>>>home sender; pc: nil]. >>>>>>> Processor debugWithTitle: 'Computation has been
terminated!'
>>>>>>>translated full: false >>>>>>>``` >>>>>>>The nilled pc should not even potentially interfere with
the
>>>>>>>#isDead now. >>>>>>> >>>>>>>I hope this is at least a step in the right direction :) >>>>>>> >>>>>>>However, there's still a problem when debugging the
resumption
>>>>>>>of #cannotReturn because the encoders expect a reasonable
index.
>>>>>>>I haven't figured out yet where to place a nil check -
#step,
>>>>>>>#stepToSendOrReturn... ? >>>>>>> >>>>>>>Thanks again, >>>>>>>Jaromir >>>>>>> >>>>>>> >>>>>>>------ Original Message ------ >>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>Date 11/17/2023 8:36:50 PM >>>>>>>Subject Re: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>>>exception >>>>>>> >>>>>>>>Hi Jaromir, >>>>>>>> >>>>>>>>>On Nov 17, 2023, at 7:05 AM, Jaromir Matas
<mail(a)jaromir.net>
>>>>>>>>>wrote: >>>>>>>>> >>>>>>>>> >>>>>>>>>Eliot, hi again, >>>>>>>>> >>>>>>>>>Please disregard my previous comment about nilling the >>>>>>>>>contexts that have returned. We are indeed talking
about
the
>>>>>>>>>context directly under the #cannotReturn context which
is
>>>>>>>>>totally different from the home context in another
thread
>>>>>>>>>that's gone. >>>>>>>>> >>>>>>>>>I may still be confused but would nilling the pc of the >>>>>>>>>context directly under the cannotReturn context help?
Here's
>>>>>>>>>what I mean: >>>>>>>>>``` >>>>>>>>>Context >> #cannotReturn: result >>>>>>>>> >>>>>>>>> closureOrNil ifNotNil: [^self pc: nil; cannotReturn: >>>>>>>>>result to: self home sender]. >>>>>>>>> Processor debugWithTitle: 'Computation has been >>>>>>>>>terminated!' translated full: false. >>>>>>>>>``` >>>>>>>>>Instead of crashing the VM invokes the debugger with
the
>>>>>>>>>'Computation has been terminated!' message. >>>>>>>>> >>>>>>>>>Does this make sense? >>>>>>>> >>>>>>>>Nearly. But it loses the information on what the pc
actually
>>>>>>>>is, and that’s potentially vital information. So IMO the
ox
>>>>>>>>should only be nilled between the BlockCannotReturn
exception
>>>>>>>>being created and raised. >>>>>>>> >>>>>>>>[But if you try this don’t be surprised if it causes a
few
>>>>>>>>temporary problems. It looks to me that without a little >>>>>>>>refactoring this could easily cause an infinite
recursion
>>>>>>>>around the sending of isDead. I’m sure you’ll be able to
fix
>>>>>>>>the code to work correctly] >>>>>>>> >>>>>>>>>Thanks, >>>>>>>>>Jaromir >>>>>>>>> >>>>>>>>> >>>>>>>>>------ Original Message ------ >>>>>>>>>From "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>>>To "Eliot Miranda" <eliot.miranda(a)gmail.com>; "The >>>>>>>>>general-purpose Squeak developers list" >>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>Date 11/17/2023 10:15:17 AM >>>>>>>>>Subject [squeak-dev] Re: Resuming on BlockCannotReturn >>>>>>>>>exception >>>>>>>>> >>>>>>>>>>Hi Eliot, >>>>>>>>>> >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>------ Original Message ------ >>>>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>>>>Cc "The general-purpose Squeak developers list" >>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>Date 11/16/2023 11:52:45 PM >>>>>>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on >>>>>>>>>>BlockCannotReturn exception >>>>>>>>>> >>>>>>>>>>>Hi Jaromir, >>>>>>>>>>> >>>>>>>>>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas >>>>>>>>>>><mail(a)jaromir.net> wrote: >>>>>>>>>>>>Hi Nicolas, Eliot, >>>>>>>>>>>> >>>>>>>>>>>>here's what I understand is happening (see the
enclosed
>>>>>>>>>>>>screenshot): >>>>>>>>>>>> >>>>>>>>>>>>1) we fork a new process to evaluate [^1] >>>>>>>>>>>>2) the new process evaluates [^1] which means
instruction
>>>>>>>>>>>>18 is being evaluated, hence pc points to
instruction 19
>>>>>>>>>>>>now >>>>>>>>>>>>3) however, the home context where ^1 should return
to
is
>>>>>>>>>>>>gone by this time (the process that executed the
fork
has
>>>>>>>>>>>>already returned - notice the two up arrows in the
debugger
>>>>>>>>>>>>screenshot) >>>>>>>>>>>>4) the VM can't finish the instruction and returns
control
>>>>>>>>>>>>to the image via placing the #cannotReturn: context
on
top
>>>>>>>>>>>>of the [^1] context >>>>>>>>>>>>5) #cannotReturn: evaluation results in signalling
the
BCR
>>>>>>>>>>>>exception which is then handled by the #resume
handler
>>>>>>>>>>>> (in our debugged case the [:ex | self halt. ex
resume]
>>>>>>>>>>>>handler) >>>>>>>>>>>>6) ex resume is evaluated, however, this means
requesting
>>>>>>>>>>>>the VM to evaluate instruction 19 of the [^1]
context -
>>>>>>>>>>>>which is past the last instruction of the context
and
the
>>>>>>>>>>>>crash ensues >>>>>>>>>>>> >>>>>>>>>>>>I wonder whether such situations could/should be
prevented
>>>>>>>>>>>>inside the VM or whether such an expectation is
wrong
for
>>>>>>>>>>>>some reason. >>>>>>>>>>> >>>>>>>>>>>As Nicolas says, IMO this is best done at the image
level.
>>>>>>>>>>> >>>>>>>>>>>It could be prevented in the VM, but at great cost,
and
only
>>>>>>>>>>>partially. The performance issue is that the last
bytecode
>>>>>>>>>>>in a method is not marked in any way, and that to
determine
>>>>>>>>>>>the last bytecode the bytecodes must be symbolically >>>>>>>>>>>evaluated from the start of the method. See
implementors
of
>>>>>>>>>>>endPC at the image level (which defer to the method
trailer)
>>>>>>>>>>>and implementors of endPCOf: in the VMMaker code.
Doing
this
>>>>>>>>>>>every time execution commences is prohibitively
expensive.
>>>>>>>>>>>The "only partially" issue is that following the
return
>>>>>>>>>>>instruction may be other valid bytecodes, but these
are
not
>>>>>>>>>>>a continuation. >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>Consider the following code in some block: >>>>>>>>>>> [self expression ifTrue: >>>>>>>>>>> [^1]. >>>>>>>>>>> ^2 >>>>>>>>>>> >>>>>>>>>>>The bytecodes for this are >>>>>>>>>>> pushReceiver >>>>>>>>>>> send #expression >>>>>>>>>>> jumpFalse L1 >>>>>>>>>>> push 1 >>>>>>>>>>> methodReturnTop >>>>>>>>>>>L1 >>>>>>>>>>> push 2 >>>>>>>>>>> methodReturnTop >>>>>>>>>>> >>>>>>>>>>>Clearly if expression is true these should be *no* >>>>>>>>>>>continuation in which ^2 is executed. >>>>>>>>>> >>>>>>>>>>Well, in that case there's a bug because the
computation
in
>>>>>>>>>>the following example shouldn't continue past the [^1]
block
>>>>>>>>>>but it silently does: >>>>>>>>>>`[[true ifTrue: [^ 1]] on: BlockCannotReturn do:
#resume ]
>>>>>>>>>>fork` >>>>>>>>>> >>>>>>>>>>The bytecodes are >>>>>>>>>> push true >>>>>>>>>> jumpFalse L1 >>>>>>>>>> push 1 >>>>>>>>>> returnTop >>>>>>>>>>L1 >>>>>>>>>> push nil >>>>>>>>>> blockReturn >>>>>>>>>> >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>So even if the VM did try and detect whether the
return
was
>>>>>>>>>>>at the last block method, it would only work for
special
>>>>>>>>>>>cases. >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>It seems to me the issue is simply that the context
that
>>>>>>>>>>>cannot be returned from should be marked as dead (see >>>>>>>>>>>Context>>isDead) by setting its pc to nil at some
point,
>>>>>>>>>>>presumably after copying the actual return pc into
the
>>>>>>>>>>>BlockCannotReturn exception, to avoid ever trying to
resume
>>>>>>>>>>>the context. >>>>>>>>>> >>>>>>>>>>Does this mean, in other words, that every context
that
>>>>>>>>>>returns should nil its pc to avoid being "wrongly" >>>>>>>>>>reused/executed in the future, which concerns
primarily
those
>>>>>>>>>>being referenced somewhere hence potentially
executable in
>>>>>>>>>>the future, is that right? >>>>>>>>>>Hypothetical question: would nilling the pc during
returns
>>>>>>>>>>"fix" the example? >>>>>>>>>>Thanks a lot for helping me understand this. >>>>>>>>>>Best, >>>>>>>>>>Jaromir >>>>>>>>>> >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>Thanks, >>>>>>>>>>>>Jaromir >>>>>>>>>>>> >>>>>>>>>>>><bdxuqalu.png> >>>>>>>>>>>> >>>>>>>>>>>>------ Original Message ------ >>>>>>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The
general-purpose
>>>>>>>>>>>>Squeak developers list" >>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>>>Date 11/16/2023 6:48:43 PM >>>>>>>>>>>>Subject Re: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>>>>>>>>exception >>>>>>>>>>>> >>>>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>>> >>>>>>>>>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas >>>>>>>>>>>>>><mail(a)jaromir.net> wrote: >>>>>>>>>>>>>> >>>>>>>>>>>>>> >>>>>>>>>>>>>>Hi Nicloas, >>>>>>>>>>>>>>No no, I don't have any practical scenario in
mind,
I'm
>>>>>>>>>>>>>>just trying to understand why the VM is
implemented
like
>>>>>>>>>>>>>>this, whether there were a reason to leave this >>>>>>>>>>>>>>possibility of a crash, e.g. it would slow down
the VM
to
>>>>>>>>>>>>>>try to prevent such a dumb situation (who would
resume
>>>>>>>>>>>>>>from BCR in his right mind? :) ) - or perhaps I
have
>>>>>>>>>>>>>>overlooked some good reason to even keep this
behavior
in
>>>>>>>>>>>>>>the VM. That's all. >>>>>>>>>>>>> >>>>>>>>>>>>>Let’s first understand what’s really happening.
Presumably
>>>>>>>>>>>>>at tone point a context is resumed those pc is
already
at
>>>>>>>>>>>>>the block return bytecode (effectively, because it
crashes
>>>>>>>>>>>>>in JITted code, but I bet the stack vm will crash
also,
>>>>>>>>>>>>>but not as cleanly - it will try and execute the
bytes
in
>>>>>>>>>>>>>the encoded method trailer). So which method
actually
>>>>>>>>>>>>>sends resume, and to what, and what state is
resume’s
>>>>>>>>>>>>>receiver when resume is sent? >>>>>>>>>>>>> >>>>>>>>>>>>> >>>>>>>>>>>>>> >>>>>>>>>>>>>>Thanks for your reply. >>>>>>>>>>>>>>Regards, >>>>>>>>>>>>>>Jaromir >>>>>>>>>>>>>> >>>>>>>>>>>>>> >>>>>>>>>>>>>> >>>>>>>>>>>>>> >>>>>>>>>>>>>>------ Original Message ------ >>>>>>>>>>>>>>From "Nicolas Cellier" >>>>>>>>>>>>>><nicolas.cellier.aka.nice(a)gmail.com> >>>>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The >>>>>>>>>>>>>>general-purpose Squeak developers list" >>>>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>>>>>Date 11/16/2023 7:20:20 AM >>>>>>>>>>>>>>Subject Re: [squeak-dev] Resuming on
BlockCannotReturn
>>>>>>>>>>>>>>exception >>>>>>>>>>>>>> >>>>>>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>>>>>Is there a scenario where it would make sense to
resume
>>>>>>>>>>>>>>>a BlockCannotReturn? >>>>>>>>>>>>>>>If not, I would suggest to protect at image side
and
>>>>>>>>>>>>>>>override #resume. >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas >>>>>>>>>>>>>>><mail(a)jaromir.net> a écrit : >>>>>>>>>>>>>>>>Hi Eliot, Christoph, All, >>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>It's known the following example crashes the VM.
Is
>>>>>>>>>>>>>>>>this an intended behavior or a "tolerated bug"? >>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume] fork` >>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>I understand why it crashes: the non-local
return
has
>>>>>>>>>>>>>>>>nowhere to return to and so resuming the
computation
>>>>>>>>>>>>>>>>leads to a crash. But why not raise another BCR >>>>>>>>>>>>>>>>exception to prevent the crash? Potential
infinite
>>>>>>>>>>>>>>>>loop? Perhaps I'm just missing the purpose of
this
>>>>>>>>>>>>>>>>behavior... >>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>Thanks for an explanation. >>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>Best, >>>>>>>>>>>>>>>>Jaromir >>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>-- >>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>Jaromir Matas >>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>> >>>>>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>-- >>>>>>>>>>>_,,,^..^,,,_ >>>>>>>>>>>best, Eliot >>>>>>>>><Context-cannotReturn.st> >>>>>> >>>>>> >>>>>>-- >>>>>>_,,,^..^,,,_ >>>>>>best, Eliot >>>>><ProcessTest-testResumeAfterBCR.st>
Hi Christoph,
thanks again for these examples. I really look forward to trying to crack them :)
In the meantime, I wonder if you could help me cleanup my recent Inbox changesets:
If you're happy with Kernel-jar.1555, Kernel-jar.1554 and Kernel-jar.1553 they can be merged. These are related to the problems you observed in the Simulation Studio. All of them are IMO simple bugs that need fixing.
This one: Kernel-jar.1550 is a bugfix too - if you're ok with it, it's ready for merging.
Kernel-jar.1552, Kernel-jar.1545, and Tools-jar.1240 can be moved to Treated.
As for Kernel-jar.1551, I have a better version I'm looking forward to showing you :)
Sorry for throwing all this at you; many thanks for helping me to clean this up.
Best regards, Jaromir
On 24-Feb-24 10:38:37 PM, christoph.thiede@student.hpi.uni-potsdam.de wrote:
Hi Jaromir, all,
just found another oddity with debugging non-local returns:
Debug it in a workspace, then select the second method from the stack in the debugger (CompiledMethod>>valueWithReceiver:arguments:) and press Through:
[sender:=thisContextswapSender:nil. ^1]value.Expected: A BlockCannotReturn error Actual: The method has returned 1!
It seems that the VM "checks" the validity of the entire stack up to the sender-to-return-to while the simulator essentially just uses "self home sender". I wonder what's the best way to fix this. Insert something like this at the beginning of Context>>#return:from:?
newSender:=selffindContextSuchThat:[:ea|ea==aSender].Or would this break sideways returns for any scenario I currently don't see? I have to confess I do not know whether and when we support them at all ...
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2024-02-01T17:27:21+00:00, mail@jaromir.net wrote:
Hi Christoph,
I still owe you an explanation of the mechanics of the bug (detailed description for future reference - especially for me):
On 13-Jan-24 9:52:19 PM,
christoph.thiede(a)student.hpi.uni-potsdam.de
wrote:
Hi Jaromir,
do you have any idea why the former behavior would also stop when
the
context activates a new method?
The key to understanding the issue with #runUntilErrorOrReturnFrom:
in
this particular example is that before returning, when stepping until the guard contexts inserted by #runUntilErrorOrReturnFrom: are gone,
the
stepping finalizes the execution of #resumeEvaluating:through: and it finally terminates all contexts including the guard context inserted
by
#runUntilErrorOrReturnFrom: which will satisfiy the condition `ctxt isDead` at the end of #runUntilErrorOrReturnFrom: BUT #resumeEvaluating:through: still has to execute `aBlock value` which will become the intermediate point where contexts switch (stack top context changes), hence #stepToCalleeOrNil returns and the above mentioned condition is checked - resulting in the observed premature return from #runUntilErrorOrReturnFrom:. If we replace #stepToCalleeOrNil with #stepToSenderOrNil the stepping
in
#runUntilErrorOrReturnFrom: will only stop when the stack goes down which is exactly was was intended. (i.e. the bug manifests in
#stepOver
but it's a general deficiency in #runUntilErrorOrReturnFrom:)
Otherwise, I agree that seeing that #resume:through: context in the debugger is probably not required in this situation.
Best, Christoph
PS: Here's another bug if you haven't it on your radar already: In
the
same expression ([^2] ensure: []), step through, through, over so
you
end in FullBlockClosure(BlockClosure)>>ensure:. Step over, over,
over,
over to move beyond aBlock value. At the last step, you will get another BCR in a second debugger. :-)
Yeah, a nice one. I've already wondered why... I'll investigate.
Thanks
for the push :)
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2024-01-09T19:46:15+00:00, mail(a)jaromir.net wrote:
Hi Christoph, all
I've just sent a minor fix to the Inbox I missed previously - Kernel-jar.1550.
if you debug and do step through to ^2 and then step over in [^2] ensure: [] the debugger incorrectly stops at #resume:through:.
This is an old issue predating any of my changes. I'm sending the
fix
as
part of this thread because it's closely related (but
independent).
I think it can be safely merged.
Thanks, Jaromir
On 30-Dec-23 6:15:25 PM,
christoph.thiede(a)student.hpi.uni-potsdam.de
wrote:
Hi Jaromir, hi all,
finally I have found the time to review these suggestions. Kernel-jar.1537, Kernel-jar.1538, and Kernel-jar.1539 look
excellent
to
me as well. Clear, straightforward, useful. :-) I have merged
them
into
the trunk via Kernel-ct.1545.
Regarding DebuggerTests>>test16HandleSimulationError, I have
patched
it
via ToolsTests-ct.125. Nothing to rack your brains over:
"thisContext
pc: nil" just mimicks any kind of unhandled error inside the
simulator
- since we now gently handle this via #cannotReturn:, I just
replaced
it with "thisContext pc: false". :-) Sorry for not clarifying
that
earlier and letting you speculate.
Thanks for your work, and I already wish you a happy new year!
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-11-29T13:31:09+00:00, mail(a)jaromir.net wrote:
Hi Marcel,
> [myself] whether the patch would have been necessary should
the
#return:from: had been fixed then
Nonsense, I just mixed it up with another issue :)
On 29-Nov-23 1:51:21 PM, "Jaromir Matas" <mail(a)jaromir.net>
wrote:
>Thanks Marcel! This test somehow slipped my attention :) > >The test can no longer work as is. It takes advantage of the
erroneous
>behavior of #return:from: in the sense that if you simulate > > thisContext pc: nil > >it'll happily return to a dead context (i.e. to thisContext
from
#pc:
>nil context) - which is not what the VM does during runtime.
It
should
>immediately raise an illegal return exception not only
during
runtime
>but also during simulation. > >The test mentions a patch for an infinite debugger chain >(http://forum.world.st/I-broke-the-debugger-td5110752.html).
I
wonder
>whether the problem could have something to do with this
simulation
bug
>in return:from:; and a terrible idea occurred to me whether
the
patch
>would have been necessary should the #return:from: had been
fixed
then
>;O > >We may potentially come up with more examples like this,
even in
the
>trunk, where the bug from #return:from: propagated and was
taken
>advantage of. I've found and fixed
#runUntilErrorOrReturnFrom:
but
more
>can still be surviving undetected... > >I'd place the test into #expectedFailures for now but maybe
it's
time
>to remove it; Christoph should decide :) > >Thanks again, >Jaromir > > >On 29-Nov-23 10:28:38 AM, "Taeumel, Marcel via Squeak-dev" ><squeak-dev(a)lists.squeakfoundation.org> wrote: > >>Hi Jaromir -- >> >>Looks good. Still, what about that
#test16HandleSimulationError
now?
>>:-) It is failing with your changes ... how would you adapt
it?
>> >> >> >>Best, >>Marcel >>>Am 28.11.2023 01:29:39 schrieb Jaromir Matas
<mail(a)jaromir.net>:
>>> >>>Hi Eliot, Marcel, all, >>> >>>I've sent a fix Kernel-jar.1539 to the Inbox that solves
the
>>>remaining bit of the chain of bugs described in the
previous
post.
>>>All tests are green now and I think the root cause has
been
found
and
>>>fixed. >>> >>>In this last bit I've created a version of stepToCallee
that
would
>>>identify a potential illegal return to a nil sender and
avoid
it.
>>> >>>Now this example can be debugged without any problems: >>> >>>[[self halt. ^ 1] on: BlockCannotReturn do: #resume ] fork >>> >>>If you're happy with the solution in Kernel-jar.1539, >>>Kernel-jar.1538, Kernel-jar.1537 and the test in
KernelTests-jar.447,
>>>could you please double-check and merge, please? (And
remove
>>>Kernel-mt.1534 and Tools-jar.1240 from the Inbox) >>> >>>Best, >>>Jaromir >>> >>> >>> >>>On 27-Nov-23 12:09:37 AM, "Jaromir Matas"
<mail(a)jaromir.net>
wrote:
>>> >>>>Hi Eliot, Christoph, all >>>> >>>>It looks like there are some more skeletons in the closet
:/
>>>> >>>>If you run this example >>>> >>>>[[self halt. ^ 1] on: BlockCannotReturn do: [:ex | ex
resume]
]
fork
>>>> >>>>and step over halt and then step over ^1 you get a
nonsensical
error
>>>>as a result of decoding nil as an instruction. >>>> >>>>It turns out that the root cause is in the #return:from:
method:
it
>>>>only checks whether aSender is dead but ignores the
possibility
that
>>>>aSender sender may be nil or dead in which cases the VM
also
>>>>responds with sending #cannotReturn, hence I assume the
simulator
>>>>should do the same. In addition, the VM nills the pc in
such
>>>>scenario, so I added the same functionality here too: >>>> >>>>Context >> return: value from: aSender >>>> "For simulation. Roll back self to aSender and return
value
>>>>from it. Execute any unwind blocks on the way. ASSUMES
aSender is
>>>>a sender of self" >>>> >>>> | newTop | >>>> newTop := aSender sender. >>>> (aSender isDead or: [newTop isNil or: [newTop isDead]])
ifTrue:
>>>> "<--------- this is extended ------" >>>> [^self pc: nil; send: #cannotReturn: to: self with: >>>>{value}]. "<------ pc: nil is added ----" >>>> (self findNextUnwindContextUpTo: newTop) ifNotNil: >>>> "Send #aboutToReturn:through: with nil as the second >>>>argument to avoid this bug: >>>> Cannot #stepOver '^2' in example '[^2] ensure: []'. >>>> See
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html"
>>>> [^self send: #aboutToReturn:through: to: self with:
{value.
>>>>nil}]. >>>> self releaseTo: newTop. >>>> newTop ifNotNil: [newTop push: value]. >>>> ^newTop >>>> >>>>In order for this to work #cannotReturn: has to be
modified
as in
>>>>Kernel-jar.1537: >>>> >>>>Context >> cannotReturn: result >>>> >>>> closureOrNil ifNotNil: [^ self cannotReturn: result to:
self
>>>>home sender]. >>>> self error: 'Computation has been terminated!' >>>>"<----------- this has to be an Error -----" >>>> >>>>Then it almost works except when you keep stepping over
in
the
>>>>example above, you get an MNU error on `self previousPc`
in
>>>>#cannotReturn:to:` with your solution of the VM crash. If
you
don't
>>>>mind I've amended your solution and added the final
context
where
>>>>the computation couldn't return along with the pc: >>>> >>>>Context >> cannotReturn: result to: homeContext >>>> "The receiver tried to return result to homeContext that
cannot
>>>>be returned from. >>>> Capture the return context/pc in a BlockCannotReturn.
Nil
the pc
>>>>to prevent repeat >>>> attempts and/or invalid continuation. Answer the result
of
>>>>raising the exception." >>>> >>>> | exception previousPc | >>>> exception := BlockCannotReturn new. >>>> previousPc := pc ifNotNil: [self previousPc]. "<-----
here's
a
>>>>fix ----" >>>> exception >>>> result: result; >>>> deadHome: homeContext; >>>> finalContext: self; "<----- here's the new state, if >>>>that's fine ----" >>>> pc: previousPc. >>>> pc := nil. >>>> ^exception signal >>>> >>>>Unfortunately, this is still not the end of the story:
there
are
>>>>situations where #runUntilErrorOrReturnFrom: places the
two
guard
>>>>contexts below the bottom context. And that is a problem
because
>>>>when the method tries to remove the two guard contexts
before
>>>>returning at the end it uses #stepToCalee to do the job
but
this
>>>>unforotunately was (ab)using the above bug in
#return:from: -
I'll
>>>>explain: #return:from: didn't check whether aSender
sender
was
nil
>>>>and as a result it allowed to simulate a return to a "nil
context"
>>>>which was then (ab)used in the clean-up via #stepToCalee
in
the
>>>>#runUntilErrorOrReturnFrom:. >>>> >>>>When I fixed the #return:from: bug, the
#runUntilErrorOrReturnFrom:
>>>>cleanup of the guard contexts no longer works in that
very
special
>>>>case where the guard contexts are below the bottom
context.
There's
>>>>one case where this is being used: #terminateAggresively
by
>>>>Christoph. >>>> >>>>If I'm right with this analysis, the
#runUntilErrorOrReturnFrom:
>>>>should get fixed too but I'll be away now for a few days
and
I
won't
>>>>be able to respond. If you or Christoph had a chance to
take
a
look
>>>>at Kernel-jar.1538 and Kernel-jar.1537 I'd be very
grateful.
I
hope
>>>>this super long message at least makes some sense :) >>>>Best, >>>>Jaromir >>>> >>>>[1] Kernel-jar.1538, Kernel-jar.1537 >>>>[2] KernelTests-jar.447 >>>> >>>> >>>>PS: Christoph, >>>> >>>>With Kernel-jar.1538 + Kernel-jar.1537 your example >>>> >>>>process := >>>> [(c := thisContext) pc: nil. >>>> 2+3] newProcess. >>>>process runUntil: [:ctx | ctx selector = #cannotReturn:]. >>>>self assert: process suspendedContext sender sender = c. >>>>self assert: process suspendedContext arguments = {c}. >>>> >>>>works fine, I've just corrected your first assert. >>>> >>>> >>>> >>>> >>>> >>>>On 21-Nov-23 6:40:32 PM, "Eliot Miranda"
<eliot.miranda(a)gmail.com>
>>>>wrote: >>>> >>>>>Hi Jaromir, >>>>> >>>>>>On Nov 20, 2023, at 11:51 PM, Jaromir Matas
<mail(a)jaromir.net>
>>>>>>wrote: >>>>>> >>>>>> >>>>>>Hi Eliot, >>>>>>Very elegant! Now I finally got what you meant exactly
:)
Thanks.
>>>>>> >>>>>>Two questions: >>>>>>1. in order for the enclosed test to work I'd need an
Error
>>>>>>instead of Processor debugWithTitle:full: call in
#cannotReturn:.
>>>>>>Otherwise I don't know how to catch a plain invocation
of
the
>>>>>>Debugger: >>>>>> >>>>>>cannotReturn: result >>>>>> >>>>>> closureOrNil ifNotNil: [^ self cannotReturn: result
to:
self
>>>>>>home sender]. >>>>>> self error: 'Computation has been terminated!' >>>>> >>>>>Much nicer. >>>>> >>>>>>2. We are capturing a pc of self which is completely
different
>>>>>>context from homeContext indeed. >>>>> >>>>>Right. The return is attempted from a specific return
bytecode
in a
>>>>>specific block. This is the coordinate of the return
that
cannot
be
>>>>>made. This is the relevant point of origin of the cannot
return
>>>>>exception. >>>>> >>>>>Why the return fails is another matter: >>>>>- the home context’s sender is a dead context (cannot be
resumed)
>>>>>- the home context’s sender is nil (home already
returned
from)
>>>>>- the block activation’s home is nil rather than a
context
(should
>>>>>not happen) >>>>> >>>>>But in all these cases the pc of the home context is
immaterial.
>>>>>The hike is being returned through/from, rather than
from;
the
>>>>>home’s pc is not relevant. >>>>> >>>>>>Maybe we could capture self in the exception too to
make it
more
>>>>>>clear/explicit what is going on: what context the
captured
pc
is
>>>>>>actually associated with. Just a thought... >>>>> >>>>>Yes, I like that. I also like the idea of somehow
passing
the
>>>>>block activation’s pc to the debugger so that the
relevant
return
>>>>>expression is highlighted in the debugger. >>>>> >>>>>> >>>>>>Thanks again, >>>>>>Jaromir >>>>> >>>>>You’re welcome. I love working in this part of the
system.
Thanks
>>>>>for dragging me there. I’m in a slump right now and
appreciate
the
>>>>>fellowship. >>>>> >>>>>>------ Original Message ------ >>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>>Cc squeak-dev(a)lists.squeakfoundation.org >>>>>>Date 11/21/2023 2:17:21 AM >>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>>exception >>>>>> >>>>>>>Hi Jaromir, >>>>>>> >>>>>>> see Kernel-eem.1535 for what I was suggesting. This
example
>>>>>>>now has an exception with the right pc value in it: >>>>>>> >>>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect.
ex
resume]]
>>>>>>>fork >>>>>>> >>>>>>>The fix is simply >>>>>>> >>>>>>>Context>>cannotReturn: result to: homeContext >>>>>>> "The receiver tried to return result to homeContext
that
>>>>>>>cannot be returned from. >>>>>>> Capture the return pc in a BlockCannotReturn. Nil the
pc
to
>>>>>>>prevent repeat >>>>>>> attempts and/or invalid continuation. Answer the
result
of
>>>>>>>raising the exception." >>>>>>> >>>>>>> | exception | >>>>>>> exception := BlockCannotReturn new. >>>>>>> exception >>>>>>> result: result; >>>>>>> deadHome: homeContext; >>>>>>> pc: self previousPc. >>>>>>> pc := nil. >>>>>>> ^exception signal >>>>>>> >>>>>>> >>>>>>>The VM crash is now avoided. The debugger displays the
method,
>>>>>>>but does not highlight the offending pc, which is no
big
deal.
A
>>>>>>>suitable defaultHandler for B lockCannotReturn may be
able
to
get
>>>>>>>the debugger to highlight correctly on opening. Try
the
>>>>>>>following examples: >>>>>>> >>>>>>>[[^1] on: BlockCannotReturn do: #resume] fork. >>>>>>> >>>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect.
ex
resume]]
>>>>>>>fork >>>>>>> >>>>>>>[[^1] value] fork. >>>>>>> >>>>>>>They al; seem to behave perfectly acceptably to me.
Does
this
>>>>>>>fix work for you? >>>>>>> >>>>>>>On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas
<mail(a)jaromir.net>
>>>>>>>wrote: >>>>>>>>Hi Eliot, >>>>>>>> >>>>>>>>How about to nil the pc just before making the
return:
>>>>>>>>``` >>>>>>>>Context >> #cannotReturn: result >>>>>>>> >>>>>>>> self push: self pc. "backup the pc for the sake of >>>>>>>>debugging" >>>>>>>> closureOrNil ifNotNil: [^self cannotReturn: result
to:
self
>>>>>>>>home sender; pc: nil]. >>>>>>>> Processor debugWithTitle: 'Computation has been
terminated!'
>>>>>>>>translated full: false >>>>>>>>``` >>>>>>>>The nilled pc should not even potentially interfere
with
the
>>>>>>>>#isDead now. >>>>>>>> >>>>>>>>I hope this is at least a step in the right direction
:)
>>>>>>>> >>>>>>>>However, there's still a problem when debugging the
resumption
>>>>>>>>of #cannotReturn because the encoders expect a
reasonable
index.
>>>>>>>>I haven't figured out yet where to place a nil check
#step,
>>>>>>>>#stepToSendOrReturn... ? >>>>>>>> >>>>>>>>Thanks again, >>>>>>>>Jaromir >>>>>>>> >>>>>>>> >>>>>>>>------ Original Message ------ >>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>>Date 11/17/2023 8:36:50 PM >>>>>>>>Subject Re: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>>>>exception >>>>>>>> >>>>>>>>>Hi Jaromir, >>>>>>>>> >>>>>>>>>>On Nov 17, 2023, at 7:05 AM, Jaromir Matas
<mail(a)jaromir.net>
>>>>>>>>>>wrote: >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>Eliot, hi again, >>>>>>>>>> >>>>>>>>>>Please disregard my previous comment about nilling
the
>>>>>>>>>>contexts that have returned. We are indeed talking
about
the
>>>>>>>>>>context directly under the #cannotReturn context
which
is
>>>>>>>>>>totally different from the home context in another
thread
>>>>>>>>>>that's gone. >>>>>>>>>> >>>>>>>>>>I may still be confused but would nilling the pc of
the
>>>>>>>>>>context directly under the cannotReturn context
help?
Here's
>>>>>>>>>>what I mean: >>>>>>>>>>``` >>>>>>>>>>Context >> #cannotReturn: result >>>>>>>>>> >>>>>>>>>> closureOrNil ifNotNil: [^self pc: nil;
cannotReturn:
>>>>>>>>>>result to: self home sender]. >>>>>>>>>> Processor debugWithTitle: 'Computation has been >>>>>>>>>>terminated!' translated full: false. >>>>>>>>>>``` >>>>>>>>>>Instead of crashing the VM invokes the debugger
with
the
>>>>>>>>>>'Computation has been terminated!' message. >>>>>>>>>> >>>>>>>>>>Does this make sense? >>>>>>>>> >>>>>>>>>Nearly. But it loses the information on what the pc
actually
>>>>>>>>>is, and that’s potentially vital information. So IMO
the
ox
>>>>>>>>>should only be nilled between the BlockCannotReturn
exception
>>>>>>>>>being created and raised. >>>>>>>>> >>>>>>>>>[But if you try this don’t be surprised if it causes
a
few
>>>>>>>>>temporary problems. It looks to me that without a
little
>>>>>>>>>refactoring this could easily cause an infinite
recursion
>>>>>>>>>around the sending of isDead. I’m sure you’ll be
able to
fix
>>>>>>>>>the code to work correctly] >>>>>>>>> >>>>>>>>>>Thanks, >>>>>>>>>>Jaromir >>>>>>>>>> >>>>>>>>>> >>>>>>>>>>------ Original Message ------ >>>>>>>>>>From "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>>>>To "Eliot Miranda" <eliot.miranda(a)gmail.com>;
"The
>>>>>>>>>>general-purpose Squeak developers list" >>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>Date 11/17/2023 10:15:17 AM >>>>>>>>>>Subject [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>>>>>>exception >>>>>>>>>> >>>>>>>>>>>Hi Eliot, >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>------ Original Message ------ >>>>>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> >>>>>>>>>>>Cc "The general-purpose Squeak developers list" >>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>>Date 11/16/2023 11:52:45 PM >>>>>>>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on >>>>>>>>>>>BlockCannotReturn exception >>>>>>>>>>> >>>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>> >>>>>>>>>>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas >>>>>>>>>>>><mail(a)jaromir.net> wrote: >>>>>>>>>>>>>Hi Nicolas, Eliot, >>>>>>>>>>>>> >>>>>>>>>>>>>here's what I understand is happening (see the
enclosed
>>>>>>>>>>>>>screenshot): >>>>>>>>>>>>> >>>>>>>>>>>>>1) we fork a new process to evaluate [^1] >>>>>>>>>>>>>2) the new process evaluates [^1] which means
instruction
>>>>>>>>>>>>>18 is being evaluated, hence pc points to
instruction 19
>>>>>>>>>>>>>now >>>>>>>>>>>>>3) however, the home context where ^1 should
return
to
is
>>>>>>>>>>>>>gone by this time (the process that executed the
fork
has
>>>>>>>>>>>>>already returned - notice the two up arrows in
the
debugger
>>>>>>>>>>>>>screenshot) >>>>>>>>>>>>>4) the VM can't finish the instruction and
returns
control
>>>>>>>>>>>>>to the image via placing the #cannotReturn:
context
on
top
>>>>>>>>>>>>>of the [^1] context >>>>>>>>>>>>>5) #cannotReturn: evaluation results in
signalling
the
BCR
>>>>>>>>>>>>>exception which is then handled by the #resume
handler
>>>>>>>>>>>>> (in our debugged case the [:ex | self halt. ex
resume]
>>>>>>>>>>>>>handler) >>>>>>>>>>>>>6) ex resume is evaluated, however, this means
requesting
>>>>>>>>>>>>>the VM to evaluate instruction 19 of the [^1]
context -
>>>>>>>>>>>>>which is past the last instruction of the
context
and
the
>>>>>>>>>>>>>crash ensues >>>>>>>>>>>>> >>>>>>>>>>>>>I wonder whether such situations could/should be
prevented
>>>>>>>>>>>>>inside the VM or whether such an expectation is
wrong
for
>>>>>>>>>>>>>some reason. >>>>>>>>>>>> >>>>>>>>>>>>As Nicolas says, IMO this is best done at the
image
level.
>>>>>>>>>>>> >>>>>>>>>>>>It could be prevented in the VM, but at great
cost,
and
only
>>>>>>>>>>>>partially. The performance issue is that the last
bytecode
>>>>>>>>>>>>in a method is not marked in any way, and that to
determine
>>>>>>>>>>>>the last bytecode the bytecodes must be
symbolically
>>>>>>>>>>>>evaluated from the start of the method. See
implementors
of
>>>>>>>>>>>>endPC at the image level (which defer to the
method
trailer)
>>>>>>>>>>>>and implementors of endPCOf: in the VMMaker code.
Doing
this
>>>>>>>>>>>>every time execution commences is prohibitively
expensive.
>>>>>>>>>>>>The "only partially" issue is that following the
return
>>>>>>>>>>>>instruction may be other valid bytecodes, but
these
are
not
>>>>>>>>>>>>a continuation. >>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>Consider the following code in some block: >>>>>>>>>>>> [self expression ifTrue: >>>>>>>>>>>> [^1]. >>>>>>>>>>>> ^2 >>>>>>>>>>>> >>>>>>>>>>>>The bytecodes for this are >>>>>>>>>>>> pushReceiver >>>>>>>>>>>> send #expression >>>>>>>>>>>> jumpFalse L1 >>>>>>>>>>>> push 1 >>>>>>>>>>>> methodReturnTop >>>>>>>>>>>>L1 >>>>>>>>>>>> push 2 >>>>>>>>>>>> methodReturnTop >>>>>>>>>>>> >>>>>>>>>>>>Clearly if expression is true these should be
*no*
>>>>>>>>>>>>continuation in which ^2 is executed. >>>>>>>>>>> >>>>>>>>>>>Well, in that case there's a bug because the
computation
in
>>>>>>>>>>>the following example shouldn't continue past the
[^1]
block
>>>>>>>>>>>but it silently does: >>>>>>>>>>>`[[true ifTrue: [^ 1]] on: BlockCannotReturn do:
#resume ]
>>>>>>>>>>>fork` >>>>>>>>>>> >>>>>>>>>>>The bytecodes are >>>>>>>>>>> push true >>>>>>>>>>> jumpFalse L1 >>>>>>>>>>> push 1 >>>>>>>>>>> returnTop >>>>>>>>>>>L1 >>>>>>>>>>> push nil >>>>>>>>>>> blockReturn >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>So even if the VM did try and detect whether the
return
was
>>>>>>>>>>>>at the last block method, it would only work for
special
>>>>>>>>>>>>cases. >>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>It seems to me the issue is simply that the
context
that
>>>>>>>>>>>>cannot be returned from should be marked as dead
(see
>>>>>>>>>>>>Context>>isDead) by setting its pc to nil at some
point,
>>>>>>>>>>>>presumably after copying the actual return pc
into
the
>>>>>>>>>>>>BlockCannotReturn exception, to avoid ever trying
to
resume
>>>>>>>>>>>>the context. >>>>>>>>>>> >>>>>>>>>>>Does this mean, in other words, that every context
that
>>>>>>>>>>>returns should nil its pc to avoid being "wrongly" >>>>>>>>>>>reused/executed in the future, which concerns
primarily
those
>>>>>>>>>>>being referenced somewhere hence potentially
executable in
>>>>>>>>>>>the future, is that right? >>>>>>>>>>>Hypothetical question: would nilling the pc during
returns
>>>>>>>>>>>"fix" the example? >>>>>>>>>>>Thanks a lot for helping me understand this. >>>>>>>>>>>Best, >>>>>>>>>>>Jaromir >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>> >>>>>>>>>>>>>Thanks, >>>>>>>>>>>>>Jaromir >>>>>>>>>>>>> >>>>>>>>>>>>><bdxuqalu.png> >>>>>>>>>>>>> >>>>>>>>>>>>>------ Original Message ------ >>>>>>>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> >>>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The
general-purpose
>>>>>>>>>>>>>Squeak developers list" >>>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>>>>Date 11/16/2023 6:48:43 PM >>>>>>>>>>>>>Subject Re: [squeak-dev] Re: Resuming on
BlockCannotReturn
>>>>>>>>>>>>>exception >>>>>>>>>>>>> >>>>>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>>>> >>>>>>>>>>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas >>>>>>>>>>>>>>><mail(a)jaromir.net> wrote: >>>>>>>>>>>>>>> >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>Hi Nicloas, >>>>>>>>>>>>>>>No no, I don't have any practical scenario in
mind,
I'm
>>>>>>>>>>>>>>>just trying to understand why the VM is
implemented
like
>>>>>>>>>>>>>>>this, whether there were a reason to leave
this
>>>>>>>>>>>>>>>possibility of a crash, e.g. it would slow
down
the VM
to
>>>>>>>>>>>>>>>try to prevent such a dumb situation (who
would
resume
>>>>>>>>>>>>>>>from BCR in his right mind? :) ) - or perhaps
I
have
>>>>>>>>>>>>>>>overlooked some good reason to even keep this
behavior
in
>>>>>>>>>>>>>>>the VM. That's all. >>>>>>>>>>>>>> >>>>>>>>>>>>>>Let’s first understand what’s really happening.
Presumably
>>>>>>>>>>>>>>at tone point a context is resumed those pc is
already
at
>>>>>>>>>>>>>>the block return bytecode (effectively, because
it
crashes
>>>>>>>>>>>>>>in JITted code, but I bet the stack vm will
crash
also,
>>>>>>>>>>>>>>but not as cleanly - it will try and execute
the
bytes
in
>>>>>>>>>>>>>>the encoded method trailer). So which method
actually
>>>>>>>>>>>>>>sends resume, and to what, and what state is
resume’s
>>>>>>>>>>>>>>receiver when resume is sent? >>>>>>>>>>>>>> >>>>>>>>>>>>>> >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>Thanks for your reply. >>>>>>>>>>>>>>>Regards, >>>>>>>>>>>>>>>Jaromir >>>>>>>>>>>>>>> >>>>>>>>>>>>>>> >>>>>>>>>>>>>>> >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>------ Original Message ------ >>>>>>>>>>>>>>>From "Nicolas Cellier" >>>>>>>>>>>>>>><nicolas.cellier.aka.nice(a)gmail.com> >>>>>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The >>>>>>>>>>>>>>>general-purpose Squeak developers list" >>>>>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> >>>>>>>>>>>>>>>Date 11/16/2023 7:20:20 AM >>>>>>>>>>>>>>>Subject Re: [squeak-dev] Resuming on
BlockCannotReturn
>>>>>>>>>>>>>>>exception >>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>Hi Jaromir, >>>>>>>>>>>>>>>>Is there a scenario where it would make sense
to
resume
>>>>>>>>>>>>>>>>a BlockCannotReturn? >>>>>>>>>>>>>>>>If not, I would suggest to protect at image
side
and
>>>>>>>>>>>>>>>>override #resume. >>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas >>>>>>>>>>>>>>>><mail(a)jaromir.net> a écrit : >>>>>>>>>>>>>>>>>Hi Eliot, Christoph, All, >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>It's known the following example crashes the
VM.
Is
>>>>>>>>>>>>>>>>>this an intended behavior or a "tolerated
bug"?
>>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume]
fork`
>>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>I understand why it crashes: the non-local
return
has
>>>>>>>>>>>>>>>>>nowhere to return to and so resuming the
computation
>>>>>>>>>>>>>>>>>leads to a crash. But why not raise another
BCR
>>>>>>>>>>>>>>>>>exception to prevent the crash? Potential
infinite
>>>>>>>>>>>>>>>>>loop? Perhaps I'm just missing the purpose
of
this
>>>>>>>>>>>>>>>>>behavior... >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>Thanks for an explanation. >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>Best, >>>>>>>>>>>>>>>>>Jaromir >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>-- >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>Jaromir Matas >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>> >>>>>>>>>>>>-- >>>>>>>>>>>>_,,,^..^,,,_ >>>>>>>>>>>>best, Eliot >>>>>>>>>><Context-cannotReturn.st> >>>>>>> >>>>>>> >>>>>>>-- >>>>>>>_,,,^..^,,,_ >>>>>>>best, Eliot >>>>>><ProcessTest-testResumeAfterBCR.st>
Hi Jaromir,
On 2024-02-25T13:53:42+00:00, mail@jaromir.net wrote:
Hi Christoph,
thanks again for these examples. I really look forward to trying to crack them :)
In the meantime, I wonder if you could help me cleanup my recent Inbox changesets:
If you're happy with Kernel-jar.1555, Kernel-jar.1554 and Kernel-jar.1553 they can be merged. These are related to the problems you observed in the Simulation Studio. All of them are IMO simple bugs that need fixing.
I still wonder - yet I am no way convinced - whether we should fix this issue on a general level rather than avoiding temporarily incomplete context stacks. If it does not block you anywhere else, could we maybe continue that discussion in https://github.com/squeak-smalltalk/squeak-object-memory/issues/112 first? :-)
This one: Kernel-jar.1550 is a bugfix too - if you're ok with it, it's ready for merging.
Thanks, merged!
Kernel-jar.1552, Kernel-jar.1545, and Tools-jar.1240 can be moved to Treated.
Done.
As for Kernel-jar.1551, I have a better version I'm looking forward to showing you :)
Yay!
Sorry for throwing all this at you; many thanks for helping me to clean this up.
Best regards, Jaromir
Best, Christoph
On 24-Feb-24 10:38:37 PM, christoph.thiede(a)student.hpi.uni-potsdam.de wrote:
Hi Jaromir, all,
just found another oddity with debugging non-local returns:
Debug it in a workspace, then select the second method from the stack in the debugger (CompiledMethod>>valueWithReceiver:arguments:) and press Through:
[sender:=thisContextswapSender:nil. ^1]value.
Expected: A BlockCannotReturn error Actual: The method has returned 1!
It seems that the VM "checks" the validity of the entire stack up to the sender-to-return-to while the simulator essentially just uses "self home sender". I wonder what's the best way to fix this. Insert something like this at the beginning of Context>>#return:from:?
newSender:=selffindContextSuchThat:[:ea|ea==aSender].
Or would this break sideways returns for any scenario I currently don't see? I have to confess I do not know whether and when we support them at all ...
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2024-02-01T17:27:21+00:00, mail(a)jaromir.net wrote:
Hi Christoph,
I still owe you an explanation of the mechanics of the bug (detailed description for future reference - especially for me):
On 13-Jan-24 9:52:19 PM,
christoph.thiede(a)student.hpi.uni-potsdam.de
wrote:
Hi Jaromir,
do you have any idea why the former behavior would also stop when
the
context activates a new method?
The key to understanding the issue with #runUntilErrorOrReturnFrom:
in
this particular example is that before returning, when stepping until the guard contexts inserted by #runUntilErrorOrReturnFrom: are gone,
the
stepping finalizes the execution of #resumeEvaluating:through: and it finally terminates all contexts including the guard context inserted
by
#runUntilErrorOrReturnFrom: which will satisfiy the condition `ctxt isDead` at the end of #runUntilErrorOrReturnFrom: BUT #resumeEvaluating:through: still has to execute `aBlock value` which will become the intermediate point where contexts switch (stack top context changes), hence #stepToCalleeOrNil returns and the above mentioned condition is checked - resulting in the observed premature return from #runUntilErrorOrReturnFrom:. If we replace #stepToCalleeOrNil with #stepToSenderOrNil the stepping
in
#runUntilErrorOrReturnFrom: will only stop when the stack goes down which is exactly was was intended. (i.e. the bug manifests in
#stepOver
but it's a general deficiency in #runUntilErrorOrReturnFrom:)
Otherwise, I agree that seeing that #resume:through: context in the debugger is probably not required in this situation.
Best, Christoph
PS: Here's another bug if you haven't it on your radar already: In
the
same expression ([^2] ensure: []), step through, through, over so
you
end in FullBlockClosure(BlockClosure)>>ensure:. Step over, over,
over,
over to move beyond aBlock value. At the last step, you will get another BCR in a second debugger. :-)
Yeah, a nice one. I've already wondered why... I'll investigate.
Thanks
for the push :)
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2024-01-09T19:46:15+00:00, mail(a)jaromir.net wrote:
Hi Christoph, all
I've just sent a minor fix to the Inbox I missed previously - Kernel-jar.1550.
if you debug and do step through to ^2 and then step over in [^2] ensure: [] the debugger incorrectly stops at #resume:through:.
This is an old issue predating any of my changes. I'm sending the
fix
as
part of this thread because it's closely related (but
independent).
I think it can be safely merged.
Thanks, Jaromir
On 30-Dec-23 6:15:25 PM,
christoph.thiede(a)student.hpi.uni-potsdam.de
wrote:
Hi Jaromir, hi all,
finally I have found the time to review these suggestions. Kernel-jar.1537, Kernel-jar.1538, and Kernel-jar.1539 look
excellent
to
me as well. Clear, straightforward, useful. :-) I have merged
them
into
the trunk via Kernel-ct.1545.
Regarding DebuggerTests>>test16HandleSimulationError, I have
patched
it
via ToolsTests-ct.125. Nothing to rack your brains over:
"thisContext
pc: nil" just mimicks any kind of unhandled error inside the
simulator
- since we now gently handle this via #cannotReturn:, I just
replaced
it with "thisContext pc: false". :-) Sorry for not clarifying
that
earlier and letting you speculate.
Thanks for your work, and I already wish you a happy new year!
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2023-11-29T13:31:09+00:00, mail(a)jaromir.net wrote:
> Hi Marcel, > > > [myself] whether the patch would have been necessary should
the
> #return:from: had been fixed then > > Nonsense, I just mixed it up with another issue :) > > > On 29-Nov-23 1:51:21 PM, "Jaromir Matas" <mail(a)jaromir.net>
wrote:
> > >Thanks Marcel! This test somehow slipped my attention :) > > > >The test can no longer work as is. It takes advantage of the erroneous > >behavior of #return:from: in the sense that if you simulate > > > > thisContext pc: nil > > > >it'll happily return to a dead context (i.e. to thisContext
from
#pc: > >nil context) - which is not what the VM does during runtime.
It
should > >immediately raise an illegal return exception not only
during
runtime > >but also during simulation. > > > >The test mentions a patch for an infinite debugger chain > >(http://forum.world.st/I-broke-the-debugger-td5110752.html).
I
wonder > >whether the problem could have something to do with this
simulation
bug > >in return:from:; and a terrible idea occurred to me whether
the
patch > >would have been necessary should the #return:from: had been
fixed
then > >;O > > > >We may potentially come up with more examples like this,
even in
the
> >trunk, where the bug from #return:from: propagated and was
taken
> >advantage of. I've found and fixed
#runUntilErrorOrReturnFrom:
but
more > >can still be surviving undetected... > > > >I'd place the test into #expectedFailures for now but maybe
it's
time > >to remove it; Christoph should decide :) > > > >Thanks again, > >Jaromir > > > > > >On 29-Nov-23 10:28:38 AM, "Taeumel, Marcel via Squeak-dev" > ><squeak-dev(a)lists.squeakfoundation.org> wrote: > > > >>Hi Jaromir -- > >> > >>Looks good. Still, what about that
#test16HandleSimulationError
now? > >>:-) It is failing with your changes ... how would you adapt
it?
> >> > >> > >> > >>Best, > >>Marcel > >>>Am 28.11.2023 01:29:39 schrieb Jaromir Matas
<mail(a)jaromir.net>:
> >>> > >>>Hi Eliot, Marcel, all, > >>> > >>>I've sent a fix Kernel-jar.1539 to the Inbox that solves
the
> >>>remaining bit of the chain of bugs described in the
previous
post.
> >>>All tests are green now and I think the root cause has
been
found
and > >>>fixed. > >>> > >>>In this last bit I've created a version of stepToCallee
that
would
> >>>identify a potential illegal return to a nil sender and
avoid
it.
> >>> > >>>Now this example can be debugged without any problems: > >>> > >>>[[self halt. ^ 1] on: BlockCannotReturn do: #resume ] fork > >>> > >>>If you're happy with the solution in Kernel-jar.1539, > >>>Kernel-jar.1538, Kernel-jar.1537 and the test in KernelTests-jar.447, > >>>could you please double-check and merge, please? (And
remove
> >>>Kernel-mt.1534 and Tools-jar.1240 from the Inbox) > >>> > >>>Best, > >>>Jaromir > >>> > >>> > >>> > >>>On 27-Nov-23 12:09:37 AM, "Jaromir Matas"
<mail(a)jaromir.net>
wrote: > >>> > >>>>Hi Eliot, Christoph, all > >>>> > >>>>It looks like there are some more skeletons in the closet
:/
> >>>> > >>>>If you run this example > >>>> > >>>>[[self halt. ^ 1] on: BlockCannotReturn do: [:ex | ex
resume]
]
fork > >>>> > >>>>and step over halt and then step over ^1 you get a
nonsensical
error > >>>>as a result of decoding nil as an instruction. > >>>> > >>>>It turns out that the root cause is in the #return:from:
method:
it > >>>>only checks whether aSender is dead but ignores the
possibility
that > >>>>aSender sender may be nil or dead in which cases the VM
also
> >>>>responds with sending #cannotReturn, hence I assume the
simulator
> >>>>should do the same. In addition, the VM nills the pc in
such
> >>>>scenario, so I added the same functionality here too: > >>>> > >>>>Context >> return: value from: aSender > >>>> "For simulation. Roll back self to aSender and return
value
> >>>>from it. Execute any unwind blocks on the way. ASSUMES
aSender is
> >>>>a sender of self" > >>>> > >>>> | newTop | > >>>> newTop := aSender sender. > >>>> (aSender isDead or: [newTop isNil or: [newTop isDead]])
ifTrue:
> >>>> "<--------- this is extended ------" > >>>> [^self pc: nil; send: #cannotReturn: to: self with: > >>>>{value}]. "<------ pc: nil is added ----" > >>>> (self findNextUnwindContextUpTo: newTop) ifNotNil: > >>>> "Send #aboutToReturn:through: with nil as the second > >>>>argument to avoid this bug: > >>>> Cannot #stepOver '^2' in example '[^2] ensure: []'. > >>>> See >
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html >
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html" > >>>> [^self send: #aboutToReturn:through: to: self with:
{value.
> >>>>nil}]. > >>>> self releaseTo: newTop. > >>>> newTop ifNotNil: [newTop push: value]. > >>>> ^newTop > >>>> > >>>>In order for this to work #cannotReturn: has to be
modified
as in
> >>>>Kernel-jar.1537: > >>>> > >>>>Context >> cannotReturn: result > >>>> > >>>> closureOrNil ifNotNil: [^ self cannotReturn: result to:
self
> >>>>home sender]. > >>>> self error: 'Computation has been terminated!' > >>>>"<----------- this has to be an Error -----" > >>>> > >>>>Then it almost works except when you keep stepping over
in
the
> >>>>example above, you get an MNU error on `self previousPc`
in
> >>>>#cannotReturn:to:` with your solution of the VM crash. If
you
don't > >>>>mind I've amended your solution and added the final
context
where
> >>>>the computation couldn't return along with the pc: > >>>> > >>>>Context >> cannotReturn: result to: homeContext > >>>> "The receiver tried to return result to homeContext that
cannot
> >>>>be returned from. > >>>> Capture the return context/pc in a BlockCannotReturn.
Nil
the pc
> >>>>to prevent repeat > >>>> attempts and/or invalid continuation. Answer the result
of
> >>>>raising the exception." > >>>> > >>>> | exception previousPc | > >>>> exception := BlockCannotReturn new. > >>>> previousPc := pc ifNotNil: [self previousPc]. "<-----
here's
a
> >>>>fix ----" > >>>> exception > >>>> result: result; > >>>> deadHome: homeContext; > >>>> finalContext: self; "<----- here's the new state, if > >>>>that's fine ----" > >>>> pc: previousPc. > >>>> pc := nil. > >>>> ^exception signal > >>>> > >>>>Unfortunately, this is still not the end of the story:
there
are
> >>>>situations where #runUntilErrorOrReturnFrom: places the
two
guard
> >>>>contexts below the bottom context. And that is a problem
because
> >>>>when the method tries to remove the two guard contexts
before
> >>>>returning at the end it uses #stepToCalee to do the job
but
this
> >>>>unforotunately was (ab)using the above bug in
#return:from: -
I'll > >>>>explain: #return:from: didn't check whether aSender
sender
was
nil > >>>>and as a result it allowed to simulate a return to a "nil context" > >>>>which was then (ab)used in the clean-up via #stepToCalee
in
the
> >>>>#runUntilErrorOrReturnFrom:. > >>>> > >>>>When I fixed the #return:from: bug, the #runUntilErrorOrReturnFrom: > >>>>cleanup of the guard contexts no longer works in that
very
special > >>>>case where the guard contexts are below the bottom
context.
There's > >>>>one case where this is being used: #terminateAggresively
by
> >>>>Christoph. > >>>> > >>>>If I'm right with this analysis, the
#runUntilErrorOrReturnFrom:
> >>>>should get fixed too but I'll be away now for a few days
and
I
won't > >>>>be able to respond. If you or Christoph had a chance to
take
a
look > >>>>at Kernel-jar.1538 and Kernel-jar.1537 I'd be very
grateful.
I
hope > >>>>this super long message at least makes some sense :) > >>>>Best, > >>>>Jaromir > >>>> > >>>>[1] Kernel-jar.1538, Kernel-jar.1537 > >>>>[2] KernelTests-jar.447 > >>>> > >>>> > >>>>PS: Christoph, > >>>> > >>>>With Kernel-jar.1538 + Kernel-jar.1537 your example > >>>> > >>>>process := > >>>> [(c := thisContext) pc: nil. > >>>> 2+3] newProcess. > >>>>process runUntil: [:ctx | ctx selector = #cannotReturn:]. > >>>>self assert: process suspendedContext sender sender = c. > >>>>self assert: process suspendedContext arguments = {c}. > >>>> > >>>>works fine, I've just corrected your first assert. > >>>> > >>>> > >>>> > >>>> > >>>> > >>>>On 21-Nov-23 6:40:32 PM, "Eliot Miranda" <eliot.miranda(a)gmail.com> > >>>>wrote: > >>>> > >>>>>Hi Jaromir, > >>>>> > >>>>>>On Nov 20, 2023, at 11:51 PM, Jaromir Matas <mail(a)jaromir.net> > >>>>>>wrote: > >>>>>> > >>>>>> > >>>>>>Hi Eliot, > >>>>>>Very elegant! Now I finally got what you meant exactly
:)
Thanks. > >>>>>> > >>>>>>Two questions: > >>>>>>1. in order for the enclosed test to work I'd need an
Error
> >>>>>>instead of Processor debugWithTitle:full: call in #cannotReturn:. > >>>>>>Otherwise I don't know how to catch a plain invocation
of
the
> >>>>>>Debugger: > >>>>>> > >>>>>>cannotReturn: result > >>>>>> > >>>>>> closureOrNil ifNotNil: [^ self cannotReturn: result
to:
self
> >>>>>>home sender]. > >>>>>> self error: 'Computation has been terminated!' > >>>>> > >>>>>Much nicer. > >>>>> > >>>>>>2. We are capturing a pc of self which is completely
different
> >>>>>>context from homeContext indeed. > >>>>> > >>>>>Right. The return is attempted from a specific return
bytecode
in a > >>>>>specific block. This is the coordinate of the return
that
cannot
be > >>>>>made. This is the relevant point of origin of the cannot
return
> >>>>>exception. > >>>>> > >>>>>Why the return fails is another matter: > >>>>>- the home context’s sender is a dead context (cannot be resumed) > >>>>>- the home context’s sender is nil (home already
returned
from)
> >>>>>- the block activation’s home is nil rather than a
context
(should > >>>>>not happen) > >>>>> > >>>>>But in all these cases the pc of the home context is
immaterial.
> >>>>>The hike is being returned through/from, rather than
from;
the
> >>>>>home’s pc is not relevant. > >>>>> > >>>>>>Maybe we could capture self in the exception too to
make it
more > >>>>>>clear/explicit what is going on: what context the
captured
pc
is > >>>>>>actually associated with. Just a thought... > >>>>> > >>>>>Yes, I like that. I also like the idea of somehow
passing
the
> >>>>>block activation’s pc to the debugger so that the
relevant
return > >>>>>expression is highlighted in the debugger. > >>>>> > >>>>>> > >>>>>>Thanks again, > >>>>>>Jaromir > >>>>> > >>>>>You’re welcome. I love working in this part of the
system.
Thanks > >>>>>for dragging me there. I’m in a slump right now and
appreciate
the > >>>>>fellowship. > >>>>> > >>>>>>------ Original Message ------ > >>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> > >>>>>>To "Jaromir Matas" <mail(a)jaromir.net> > >>>>>>Cc squeak-dev(a)lists.squeakfoundation.org > >>>>>>Date 11/21/2023 2:17:21 AM > >>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on BlockCannotReturn > >>>>>>exception > >>>>>> > >>>>>>>Hi Jaromir, > >>>>>>> > >>>>>>> see Kernel-eem.1535 for what I was suggesting. This
example
> >>>>>>>now has an exception with the right pc value in it: > >>>>>>> > >>>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect.
ex
resume]] > >>>>>>>fork > >>>>>>> > >>>>>>>The fix is simply > >>>>>>> > >>>>>>>Context>>cannotReturn: result to: homeContext > >>>>>>> "The receiver tried to return result to homeContext
that
> >>>>>>>cannot be returned from. > >>>>>>> Capture the return pc in a BlockCannotReturn. Nil the
pc
to
> >>>>>>>prevent repeat > >>>>>>> attempts and/or invalid continuation. Answer the
result
of
> >>>>>>>raising the exception." > >>>>>>> > >>>>>>> | exception | > >>>>>>> exception := BlockCannotReturn new. > >>>>>>> exception > >>>>>>> result: result; > >>>>>>> deadHome: homeContext; > >>>>>>> pc: self previousPc. > >>>>>>> pc := nil. > >>>>>>> ^exception signal > >>>>>>> > >>>>>>> > >>>>>>>The VM crash is now avoided. The debugger displays the
method,
> >>>>>>>but does not highlight the offending pc, which is no
big
deal.
A > >>>>>>>suitable defaultHandler for B lockCannotReturn may be
able
to
get > >>>>>>>the debugger to highlight correctly on opening. Try
the
> >>>>>>>following examples: > >>>>>>> > >>>>>>>[[^1] on: BlockCannotReturn do: #resume] fork. > >>>>>>> > >>>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc inspect.
ex
resume]] > >>>>>>>fork > >>>>>>> > >>>>>>>[[^1] value] fork. > >>>>>>> > >>>>>>>They al; seem to behave perfectly acceptably to me.
Does
this
> >>>>>>>fix work for you? > >>>>>>> > >>>>>>>On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas <mail(a)jaromir.net> > >>>>>>>wrote: > >>>>>>>>Hi Eliot, > >>>>>>>> > >>>>>>>>How about to nil the pc just before making the
return:
> >>>>>>>>``` > >>>>>>>>Context >> #cannotReturn: result > >>>>>>>> > >>>>>>>> self push: self pc. "backup the pc for the sake of > >>>>>>>>debugging" > >>>>>>>> closureOrNil ifNotNil: [^self cannotReturn: result
to:
self
> >>>>>>>>home sender; pc: nil]. > >>>>>>>> Processor debugWithTitle: 'Computation has been
terminated!'
> >>>>>>>>translated full: false > >>>>>>>>``` > >>>>>>>>The nilled pc should not even potentially interfere
with
the
> >>>>>>>>#isDead now. > >>>>>>>> > >>>>>>>>I hope this is at least a step in the right direction
:)
> >>>>>>>> > >>>>>>>>However, there's still a problem when debugging the resumption > >>>>>>>>of #cannotReturn because the encoders expect a
reasonable
index. > >>>>>>>>I haven't figured out yet where to place a nil check
#step,
> >>>>>>>>#stepToSendOrReturn... ? > >>>>>>>> > >>>>>>>>Thanks again, > >>>>>>>>Jaromir > >>>>>>>> > >>>>>>>> > >>>>>>>>------ Original Message ------ > >>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> > >>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> > >>>>>>>>Date 11/17/2023 8:36:50 PM > >>>>>>>>Subject Re: [squeak-dev] Re: Resuming on
BlockCannotReturn
> >>>>>>>>exception > >>>>>>>> > >>>>>>>>>Hi Jaromir, > >>>>>>>>> > >>>>>>>>>>On Nov 17, 2023, at 7:05 AM, Jaromir Matas <mail(a)jaromir.net> > >>>>>>>>>>wrote: > >>>>>>>>>> > >>>>>>>>>> > >>>>>>>>>>Eliot, hi again, > >>>>>>>>>> > >>>>>>>>>>Please disregard my previous comment about nilling
the
> >>>>>>>>>>contexts that have returned. We are indeed talking
about
the > >>>>>>>>>>context directly under the #cannotReturn context
which
is
> >>>>>>>>>>totally different from the home context in another
thread
> >>>>>>>>>>that's gone. > >>>>>>>>>> > >>>>>>>>>>I may still be confused but would nilling the pc of
the
> >>>>>>>>>>context directly under the cannotReturn context
help?
Here's > >>>>>>>>>>what I mean: > >>>>>>>>>>``` > >>>>>>>>>>Context >> #cannotReturn: result > >>>>>>>>>> > >>>>>>>>>> closureOrNil ifNotNil: [^self pc: nil;
cannotReturn:
> >>>>>>>>>>result to: self home sender]. > >>>>>>>>>> Processor debugWithTitle: 'Computation has been > >>>>>>>>>>terminated!' translated full: false. > >>>>>>>>>>``` > >>>>>>>>>>Instead of crashing the VM invokes the debugger
with
the
> >>>>>>>>>>'Computation has been terminated!' message. > >>>>>>>>>> > >>>>>>>>>>Does this make sense? > >>>>>>>>> > >>>>>>>>>Nearly. But it loses the information on what the pc
actually
> >>>>>>>>>is, and that’s potentially vital information. So IMO
the
ox
> >>>>>>>>>should only be nilled between the BlockCannotReturn exception > >>>>>>>>>being created and raised. > >>>>>>>>> > >>>>>>>>>[But if you try this don’t be surprised if it causes
a
few
> >>>>>>>>>temporary problems. It looks to me that without a
little
> >>>>>>>>>refactoring this could easily cause an infinite
recursion
> >>>>>>>>>around the sending of isDead. I’m sure you’ll be
able to
fix
> >>>>>>>>>the code to work correctly] > >>>>>>>>> > >>>>>>>>>>Thanks, > >>>>>>>>>>Jaromir > >>>>>>>>>> > >>>>>>>>>> > >>>>>>>>>>------ Original Message ------ > >>>>>>>>>>From "Jaromir Matas" <mail(a)jaromir.net> > >>>>>>>>>>To "Eliot Miranda" <eliot.miranda(a)gmail.com>;
"The
> >>>>>>>>>>general-purpose Squeak developers list" > >>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > >>>>>>>>>>Date 11/17/2023 10:15:17 AM > >>>>>>>>>>Subject [squeak-dev] Re: Resuming on
BlockCannotReturn
> >>>>>>>>>>exception > >>>>>>>>>> > >>>>>>>>>>>Hi Eliot, > >>>>>>>>>>> > >>>>>>>>>>> > >>>>>>>>>>> > >>>>>>>>>>>------ Original Message ------ > >>>>>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> > >>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> > >>>>>>>>>>>Cc "The general-purpose Squeak developers list" > >>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > >>>>>>>>>>>Date 11/16/2023 11:52:45 PM > >>>>>>>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on > >>>>>>>>>>>BlockCannotReturn exception > >>>>>>>>>>> > >>>>>>>>>>>>Hi Jaromir, > >>>>>>>>>>>> > >>>>>>>>>>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas > >>>>>>>>>>>><mail(a)jaromir.net> wrote: > >>>>>>>>>>>>>Hi Nicolas, Eliot, > >>>>>>>>>>>>> > >>>>>>>>>>>>>here's what I understand is happening (see the
enclosed
> >>>>>>>>>>>>>screenshot): > >>>>>>>>>>>>> > >>>>>>>>>>>>>1) we fork a new process to evaluate [^1] > >>>>>>>>>>>>>2) the new process evaluates [^1] which means instruction > >>>>>>>>>>>>>18 is being evaluated, hence pc points to
instruction 19
> >>>>>>>>>>>>>now > >>>>>>>>>>>>>3) however, the home context where ^1 should
return
to
is > >>>>>>>>>>>>>gone by this time (the process that executed the
fork
has > >>>>>>>>>>>>>already returned - notice the two up arrows in
the
debugger > >>>>>>>>>>>>>screenshot) > >>>>>>>>>>>>>4) the VM can't finish the instruction and
returns
control > >>>>>>>>>>>>>to the image via placing the #cannotReturn:
context
on
top > >>>>>>>>>>>>>of the [^1] context > >>>>>>>>>>>>>5) #cannotReturn: evaluation results in
signalling
the
BCR > >>>>>>>>>>>>>exception which is then handled by the #resume
handler
> >>>>>>>>>>>>> (in our debugged case the [:ex | self halt. ex
resume]
> >>>>>>>>>>>>>handler) > >>>>>>>>>>>>>6) ex resume is evaluated, however, this means requesting > >>>>>>>>>>>>>the VM to evaluate instruction 19 of the [^1]
context -
> >>>>>>>>>>>>>which is past the last instruction of the
context
and
the > >>>>>>>>>>>>>crash ensues > >>>>>>>>>>>>> > >>>>>>>>>>>>>I wonder whether such situations could/should be prevented > >>>>>>>>>>>>>inside the VM or whether such an expectation is
wrong
for > >>>>>>>>>>>>>some reason. > >>>>>>>>>>>> > >>>>>>>>>>>>As Nicolas says, IMO this is best done at the
image
level. > >>>>>>>>>>>> > >>>>>>>>>>>>It could be prevented in the VM, but at great
cost,
and
only > >>>>>>>>>>>>partially. The performance issue is that the last bytecode > >>>>>>>>>>>>in a method is not marked in any way, and that to determine > >>>>>>>>>>>>the last bytecode the bytecodes must be
symbolically
> >>>>>>>>>>>>evaluated from the start of the method. See
implementors
of > >>>>>>>>>>>>endPC at the image level (which defer to the
method
trailer) > >>>>>>>>>>>>and implementors of endPCOf: in the VMMaker code.
Doing
this > >>>>>>>>>>>>every time execution commences is prohibitively expensive. > >>>>>>>>>>>>The "only partially" issue is that following the
return
> >>>>>>>>>>>>instruction may be other valid bytecodes, but
these
are
not > >>>>>>>>>>>>a continuation. > >>>>>>>>>>>> > >>>>>>>>>>>> > >>>>>>>>>>>>Consider the following code in some block: > >>>>>>>>>>>> [self expression ifTrue: > >>>>>>>>>>>> [^1]. > >>>>>>>>>>>> ^2 > >>>>>>>>>>>> > >>>>>>>>>>>>The bytecodes for this are > >>>>>>>>>>>> pushReceiver > >>>>>>>>>>>> send #expression > >>>>>>>>>>>> jumpFalse L1 > >>>>>>>>>>>> push 1 > >>>>>>>>>>>> methodReturnTop > >>>>>>>>>>>>L1 > >>>>>>>>>>>> push 2 > >>>>>>>>>>>> methodReturnTop > >>>>>>>>>>>> > >>>>>>>>>>>>Clearly if expression is true these should be
*no*
> >>>>>>>>>>>>continuation in which ^2 is executed. > >>>>>>>>>>> > >>>>>>>>>>>Well, in that case there's a bug because the
computation
in > >>>>>>>>>>>the following example shouldn't continue past the
[^1]
block > >>>>>>>>>>>but it silently does: > >>>>>>>>>>>`[[true ifTrue: [^ 1]] on: BlockCannotReturn do:
#resume ]
> >>>>>>>>>>>fork` > >>>>>>>>>>> > >>>>>>>>>>>The bytecodes are > >>>>>>>>>>> push true > >>>>>>>>>>> jumpFalse L1 > >>>>>>>>>>> push 1 > >>>>>>>>>>> returnTop > >>>>>>>>>>>L1 > >>>>>>>>>>> push nil > >>>>>>>>>>> blockReturn > >>>>>>>>>>> > >>>>>>>>>>> > >>>>>>>>>>> > >>>>>>>>>>>> > >>>>>>>>>>>>So even if the VM did try and detect whether the
return
was > >>>>>>>>>>>>at the last block method, it would only work for
special
> >>>>>>>>>>>>cases. > >>>>>>>>>>>> > >>>>>>>>>>>> > >>>>>>>>>>>>It seems to me the issue is simply that the
context
that
> >>>>>>>>>>>>cannot be returned from should be marked as dead
(see
> >>>>>>>>>>>>Context>>isDead) by setting its pc to nil at some
point,
> >>>>>>>>>>>>presumably after copying the actual return pc
into
the
> >>>>>>>>>>>>BlockCannotReturn exception, to avoid ever trying
to
resume > >>>>>>>>>>>>the context. > >>>>>>>>>>> > >>>>>>>>>>>Does this mean, in other words, that every context
that
> >>>>>>>>>>>returns should nil its pc to avoid being "wrongly" > >>>>>>>>>>>reused/executed in the future, which concerns
primarily
those > >>>>>>>>>>>being referenced somewhere hence potentially
executable in
> >>>>>>>>>>>the future, is that right? > >>>>>>>>>>>Hypothetical question: would nilling the pc during
returns
> >>>>>>>>>>>"fix" the example? > >>>>>>>>>>>Thanks a lot for helping me understand this. > >>>>>>>>>>>Best, > >>>>>>>>>>>Jaromir > >>>>>>>>>>> > >>>>>>>>>>> > >>>>>>>>>>> > >>>>>>>>>>>> > >>>>>>>>>>>> > >>>>>>>>>>>>> > >>>>>>>>>>>>>Thanks, > >>>>>>>>>>>>>Jaromir > >>>>>>>>>>>>> > >>>>>>>>>>>>><bdxuqalu.png> > >>>>>>>>>>>>> > >>>>>>>>>>>>>------ Original Message ------ > >>>>>>>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> > >>>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The general-purpose > >>>>>>>>>>>>>Squeak developers list" > >>>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > >>>>>>>>>>>>>Date 11/16/2023 6:48:43 PM > >>>>>>>>>>>>>Subject Re: [squeak-dev] Re: Resuming on BlockCannotReturn > >>>>>>>>>>>>>exception > >>>>>>>>>>>>> > >>>>>>>>>>>>>>Hi Jaromir, > >>>>>>>>>>>>>> > >>>>>>>>>>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas > >>>>>>>>>>>>>>><mail(a)jaromir.net> wrote: > >>>>>>>>>>>>>>> > >>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>Hi Nicloas, > >>>>>>>>>>>>>>>No no, I don't have any practical scenario in
mind,
I'm > >>>>>>>>>>>>>>>just trying to understand why the VM is
implemented
like > >>>>>>>>>>>>>>>this, whether there were a reason to leave
this
> >>>>>>>>>>>>>>>possibility of a crash, e.g. it would slow
down
the VM
to > >>>>>>>>>>>>>>>try to prevent such a dumb situation (who
would
resume
> >>>>>>>>>>>>>>>from BCR in his right mind? :) ) - or perhaps
I
have
> >>>>>>>>>>>>>>>overlooked some good reason to even keep this
behavior
in > >>>>>>>>>>>>>>>the VM. That's all. > >>>>>>>>>>>>>> > >>>>>>>>>>>>>>Let’s first understand what’s really happening. Presumably > >>>>>>>>>>>>>>at tone point a context is resumed those pc is
already
at > >>>>>>>>>>>>>>the block return bytecode (effectively, because
it
crashes > >>>>>>>>>>>>>>in JITted code, but I bet the stack vm will
crash
also,
> >>>>>>>>>>>>>>but not as cleanly - it will try and execute
the
bytes
in > >>>>>>>>>>>>>>the encoded method trailer). So which method
actually
> >>>>>>>>>>>>>>sends resume, and to what, and what state is
resume’s
> >>>>>>>>>>>>>>receiver when resume is sent? > >>>>>>>>>>>>>> > >>>>>>>>>>>>>> > >>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>Thanks for your reply. > >>>>>>>>>>>>>>>Regards, > >>>>>>>>>>>>>>>Jaromir > >>>>>>>>>>>>>>> > >>>>>>>>>>>>>>> > >>>>>>>>>>>>>>> > >>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>------ Original Message ------ > >>>>>>>>>>>>>>>From "Nicolas Cellier" > >>>>>>>>>>>>>>><nicolas.cellier.aka.nice(a)gmail.com> > >>>>>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>; "The > >>>>>>>>>>>>>>>general-purpose Squeak developers list" > >>>>>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > >>>>>>>>>>>>>>>Date 11/16/2023 7:20:20 AM > >>>>>>>>>>>>>>>Subject Re: [squeak-dev] Resuming on
BlockCannotReturn
> >>>>>>>>>>>>>>>exception > >>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>Hi Jaromir, > >>>>>>>>>>>>>>>>Is there a scenario where it would make sense
to
resume > >>>>>>>>>>>>>>>>a BlockCannotReturn? > >>>>>>>>>>>>>>>>If not, I would suggest to protect at image
side
and
> >>>>>>>>>>>>>>>>override #resume. > >>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir Matas > >>>>>>>>>>>>>>>><mail(a)jaromir.net> a écrit : > >>>>>>>>>>>>>>>>>Hi Eliot, Christoph, All, > >>>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>>It's known the following example crashes the
VM.
Is
> >>>>>>>>>>>>>>>>>this an intended behavior or a "tolerated
bug"?
> >>>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>>`[[^ 1] on: BlockCannotReturn do: #resume]
fork`
> >>>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>>I understand why it crashes: the non-local
return
has > >>>>>>>>>>>>>>>>>nowhere to return to and so resuming the
computation
> >>>>>>>>>>>>>>>>>leads to a crash. But why not raise another
BCR
> >>>>>>>>>>>>>>>>>exception to prevent the crash? Potential
infinite
> >>>>>>>>>>>>>>>>>loop? Perhaps I'm just missing the purpose
of
this
> >>>>>>>>>>>>>>>>>behavior... > >>>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>>Thanks for an explanation. > >>>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>>Best, > >>>>>>>>>>>>>>>>>Jaromir > >>>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>>-- > >>>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>>Jaromir Matas > >>>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>> > >>>>>>>>>>>> > >>>>>>>>>>>> > >>>>>>>>>>>>-- > >>>>>>>>>>>>_,,,^..^,,,_ > >>>>>>>>>>>>best, Eliot > >>>>>>>>>><Context-cannotReturn.st> > >>>>>>> > >>>>>>> > >>>>>>>-- > >>>>>>>_,,,^..^,,,_ > >>>>>>>best, Eliot > >>>>>><ProcessTest-testResumeAfterBCR.st>
--- Sent from Squeak Inbox Talk
Hi Christoph,
On 05-Mar-24 9:39:30 PM, christoph.thiede@student.hpi.uni-potsdam.de wrote:
Hi Jaromir,
On 2024-02-25T13:53:42+00:00, mail@jaromir.net wrote:
Hi Christoph,
thanks again for these examples. I really look forward to trying to crack them :)
In the meantime, I wonder if you could help me cleanup my recent
Inbox
changesets:
If you're happy with Kernel-jar.1555, Kernel-jar.1554 and Kernel-jar.1553 they can be merged. These are related to the problems you observed in the Simulation Studio. All of them are IMO simple
bugs
that need fixing.
I still wonder - yet I am no way convinced - whether we should fix this issue on a general level rather than avoiding temporarily incomplete context stacks. If it does not block you anywhere else, could we maybe continue that discussion in https://github.com/squeak-smalltalk/squeak-object-memory/issues/112 first? :-)
Of course; I have to finish some work now and then (alas, no sooner than April) I'd like to try to analyze your other examples and maybe a more genral pattern will emerge :)
Thanks a lot for the cleanup!
This one: Kernel-jar.1550 is a bugfix too - if you're ok with it,
it's
ready for merging.
Thanks, merged!
Kernel-jar.1552, Kernel-jar.1545, and Tools-jar.1240 can be moved to Treated.
Done.
As for Kernel-jar.1551, I have a better version I'm looking forward
to
showing you :)
Yay!
Sorry for throwing all this at you; many thanks for helping me to
clean
this up.
Best regards, Jaromir
Best, Christoph
On 24-Feb-24 10:38:37 PM,
christoph.thiede(a)student.hpi.uni-potsdam.de
wrote:
Hi Jaromir, all,
just found another oddity with debugging non-local returns:
Debug it in a workspace, then select the second method from the
stack
in the debugger (CompiledMethod>>valueWithReceiver:arguments:) and press Through:
[sender:=thisContextswapSender:nil. ^1]value.
Expected: A BlockCannotReturn error Actual: The method has returned 1!
It seems that the VM "checks" the validity of the entire stack up to the sender-to-return-to while the simulator essentially just uses
"self
home sender". I wonder what's the best way to fix this. Insert something like this at the beginning of Context>>#return:from:?
newSender:=selffindContextSuchThat:[:ea|ea==aSender].
Or would this break sideways returns for any scenario I currently
don't
see? I have to confess I do not know whether and when we support
them
at all ...
Best, Christoph
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2024-02-01T17:27:21+00:00, mail(a)jaromir.net wrote:
Hi Christoph,
I still owe you an explanation of the mechanics of the bug
(detailed
description for future reference - especially for me):
On 13-Jan-24 9:52:19 PM,
christoph.thiede(a)student.hpi.uni-potsdam.de
wrote:
Hi Jaromir,
do you have any idea why the former behavior would also stop
when
the
context activates a new method?
The key to understanding the issue with
#runUntilErrorOrReturnFrom:
in
this particular example is that before returning, when stepping
until
the guard contexts inserted by #runUntilErrorOrReturnFrom: are
gone,
the
stepping finalizes the execution of #resumeEvaluating:through:
and it
finally terminates all contexts including the guard context
inserted
by
#runUntilErrorOrReturnFrom: which will satisfiy the condition
`ctxt
isDead` at the end of #runUntilErrorOrReturnFrom: BUT #resumeEvaluating:through: still has to execute `aBlock value`
which
will become the intermediate point where contexts switch (stack
top
context changes), hence #stepToCalleeOrNil returns and the above mentioned condition is checked - resulting in the observed
premature
return from #runUntilErrorOrReturnFrom:. If we replace #stepToCalleeOrNil with #stepToSenderOrNil the
stepping
in
#runUntilErrorOrReturnFrom: will only stop when the stack goes
down
which is exactly was was intended. (i.e. the bug manifests in
#stepOver
but it's a general deficiency in #runUntilErrorOrReturnFrom:)
Otherwise, I agree that seeing that #resume:through: context in
the
debugger is probably not required in this situation.
Best, Christoph
PS: Here's another bug if you haven't it on your radar already:
In
the
same expression ([^2] ensure: []), step through, through, over
so
you
end in FullBlockClosure(BlockClosure)>>ensure:. Step over, over,
over,
over to move beyond aBlock value. At the last step, you will get another BCR in a second debugger. :-)
Yeah, a nice one. I've already wondered why... I'll investigate.
Thanks
for the push :)
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
On 2024-01-09T19:46:15+00:00, mail(a)jaromir.net wrote:
Hi Christoph, all
I've just sent a minor fix to the Inbox I missed previously - Kernel-jar.1550.
if you debug and do step through to ^2 and then step over in [^2] ensure: [] the debugger incorrectly stops at #resume:through:.
This is an old issue predating any of my changes. I'm sending
the
fix
as
part of this thread because it's closely related (but
independent).
I think it can be safely merged.
Thanks, Jaromir
On 30-Dec-23 6:15:25 PM,
christoph.thiede(a)student.hpi.uni-potsdam.de
wrote:
>Hi Jaromir, hi all, > >finally I have found the time to review these suggestions. >Kernel-jar.1537, Kernel-jar.1538, and Kernel-jar.1539 look
excellent
to
>me as well. Clear, straightforward, useful. :-) I have
merged
them
into
>the trunk via Kernel-ct.1545. > >Regarding DebuggerTests>>test16HandleSimulationError, I have
patched
it
>via ToolsTests-ct.125. Nothing to rack your brains over:
"thisContext
>pc: nil" just mimicks any kind of unhandled error inside the
simulator
>- since we now gently handle this via #cannotReturn:, I just
replaced
>it with "thisContext pc: false". :-) Sorry for not
clarifying
that
>earlier and letting you speculate. > >Thanks for your work, and I already wish you a happy new
year!
> >Best, >Christoph > >--- >Sent from Squeak Inbox Talk >https://github.com/hpi-swa-lab/squeak-inbox-talk > >On 2023-11-29T13:31:09+00:00, mail(a)jaromir.net wrote: > > > Hi Marcel, > > > > > [myself] whether the patch would have been necessary
should
the
> > #return:from: had been fixed then > > > > Nonsense, I just mixed it up with another issue :) > > > > > > On 29-Nov-23 1:51:21 PM, "Jaromir Matas"
<mail(a)jaromir.net>
wrote:
> > > > >Thanks Marcel! This test somehow slipped my attention :) > > > > > >The test can no longer work as is. It takes advantage of
the
>erroneous > > >behavior of #return:from: in the sense that if you
simulate
> > > > > > thisContext pc: nil > > > > > >it'll happily return to a dead context (i.e. to
thisContext
from
>#pc: > > >nil context) - which is not what the VM does during
runtime.
It
>should > > >immediately raise an illegal return exception not only
during
>runtime > > >but also during simulation. > > > > > >The test mentions a patch for an infinite debugger chain > >
(http://forum.world.st/I-broke-the-debugger-td5110752.html).
I
>wonder > > >whether the problem could have something to do with this
simulation
>bug > > >in return:from:; and a terrible idea occurred to me
whether
the
>patch > > >would have been necessary should the #return:from: had
been
fixed
>then > > >;O > > > > > >We may potentially come up with more examples like this,
even in
the
> > >trunk, where the bug from #return:from: propagated and
was
taken
> > >advantage of. I've found and fixed
#runUntilErrorOrReturnFrom:
but
>more > > >can still be surviving undetected... > > > > > >I'd place the test into #expectedFailures for now but
maybe
it's
>time > > >to remove it; Christoph should decide :) > > > > > >Thanks again, > > >Jaromir > > > > > > > > >On 29-Nov-23 10:28:38 AM, "Taeumel, Marcel via
Squeak-dev"
> > ><squeak-dev(a)lists.squeakfoundation.org> wrote: > > > > > >>Hi Jaromir -- > > >> > > >>Looks good. Still, what about that
#test16HandleSimulationError
>now? > > >>:-) It is failing with your changes ... how would you
adapt
it?
> > >> > > >> > > >> > > >>Best, > > >>Marcel > > >>>Am 28.11.2023 01:29:39 schrieb Jaromir Matas
<mail(a)jaromir.net>:
> > >>> > > >>>Hi Eliot, Marcel, all, > > >>> > > >>>I've sent a fix Kernel-jar.1539 to the Inbox that
solves
the
> > >>>remaining bit of the chain of bugs described in the
previous
post.
> > >>>All tests are green now and I think the root cause has
been
found
>and > > >>>fixed. > > >>> > > >>>In this last bit I've created a version of
stepToCallee
that
would
> > >>>identify a potential illegal return to a nil sender
and
avoid
it.
> > >>> > > >>>Now this example can be debugged without any problems: > > >>> > > >>>[[self halt. ^ 1] on: BlockCannotReturn do: #resume ]
fork
> > >>> > > >>>If you're happy with the solution in Kernel-jar.1539, > > >>>Kernel-jar.1538, Kernel-jar.1537 and the test in >KernelTests-jar.447, > > >>>could you please double-check and merge, please? (And
remove
> > >>>Kernel-mt.1534 and Tools-jar.1240 from the Inbox) > > >>> > > >>>Best, > > >>>Jaromir > > >>> > > >>> > > >>> > > >>>On 27-Nov-23 12:09:37 AM, "Jaromir Matas"
<mail(a)jaromir.net>
>wrote: > > >>> > > >>>>Hi Eliot, Christoph, all > > >>>> > > >>>>It looks like there are some more skeletons in the
closet
:/
> > >>>> > > >>>>If you run this example > > >>>> > > >>>>[[self halt. ^ 1] on: BlockCannotReturn do: [:ex | ex
resume]
]
>fork > > >>>> > > >>>>and step over halt and then step over ^1 you get a
nonsensical
>error > > >>>>as a result of decoding nil as an instruction. > > >>>> > > >>>>It turns out that the root cause is in the
#return:from:
method:
>it > > >>>>only checks whether aSender is dead but ignores the
possibility
>that > > >>>>aSender sender may be nil or dead in which cases the
VM
also
> > >>>>responds with sending #cannotReturn, hence I assume
the
simulator
> > >>>>should do the same. In addition, the VM nills the pc
in
such
> > >>>>scenario, so I added the same functionality here too: > > >>>> > > >>>>Context >> return: value from: aSender > > >>>> "For simulation. Roll back self to aSender and
return
value
> > >>>>from it. Execute any unwind blocks on the way.
ASSUMES
aSender is
> > >>>>a sender of self" > > >>>> > > >>>> | newTop | > > >>>> newTop := aSender sender. > > >>>> (aSender isDead or: [newTop isNil or: [newTop
isDead]])
ifTrue:
> > >>>> "<--------- this is extended ------" > > >>>> [^self pc: nil; send: #cannotReturn: to: self with: > > >>>>{value}]. "<------ pc: nil is added ----" > > >>>> (self findNextUnwindContextUpTo: newTop) ifNotNil: > > >>>> "Send #aboutToReturn:through: with nil as the second > > >>>>argument to avoid this bug: > > >>>> Cannot #stepOver '^2' in example '[^2] ensure: []'. > > >>>> See > > >
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html
> > >
http://lists.squeakfoundation.org/pipermail/squeak-dev/2022-June/220975.html"
> > >>>> [^self send: #aboutToReturn:through: to: self with:
{value.
> > >>>>nil}]. > > >>>> self releaseTo: newTop. > > >>>> newTop ifNotNil: [newTop push: value]. > > >>>> ^newTop > > >>>> > > >>>>In order for this to work #cannotReturn: has to be
modified
as in
> > >>>>Kernel-jar.1537: > > >>>> > > >>>>Context >> cannotReturn: result > > >>>> > > >>>> closureOrNil ifNotNil: [^ self cannotReturn: result
to:
self
> > >>>>home sender]. > > >>>> self error: 'Computation has been terminated!' > > >>>>"<----------- this has to be an Error -----" > > >>>> > > >>>>Then it almost works except when you keep stepping
over
in
the
> > >>>>example above, you get an MNU error on `self
previousPc`
in
> > >>>>#cannotReturn:to:` with your solution of the VM
crash. If
you
>don't > > >>>>mind I've amended your solution and added the final
context
where
> > >>>>the computation couldn't return along with the pc: > > >>>> > > >>>>Context >> cannotReturn: result to: homeContext > > >>>> "The receiver tried to return result to homeContext
that
cannot
> > >>>>be returned from. > > >>>> Capture the return context/pc in a
BlockCannotReturn.
Nil
the pc
> > >>>>to prevent repeat > > >>>> attempts and/or invalid continuation. Answer the
result
of
> > >>>>raising the exception." > > >>>> > > >>>> | exception previousPc | > > >>>> exception := BlockCannotReturn new. > > >>>> previousPc := pc ifNotNil: [self previousPc].
"<-----
here's
a
> > >>>>fix ----" > > >>>> exception > > >>>> result: result; > > >>>> deadHome: homeContext; > > >>>> finalContext: self; "<----- here's the new state, if > > >>>>that's fine ----" > > >>>> pc: previousPc. > > >>>> pc := nil. > > >>>> ^exception signal > > >>>> > > >>>>Unfortunately, this is still not the end of the
story:
there
are
> > >>>>situations where #runUntilErrorOrReturnFrom: places
the
two
guard
> > >>>>contexts below the bottom context. And that is a
problem
because
> > >>>>when the method tries to remove the two guard
contexts
before
> > >>>>returning at the end it uses #stepToCalee to do the
job
but
this
> > >>>>unforotunately was (ab)using the above bug in
#return:from: -
>I'll > > >>>>explain: #return:from: didn't check whether aSender
sender
was
>nil > > >>>>and as a result it allowed to simulate a return to a
"nil
>context" > > >>>>which was then (ab)used in the clean-up via
#stepToCalee
in
the
> > >>>>#runUntilErrorOrReturnFrom:. > > >>>> > > >>>>When I fixed the #return:from: bug, the >#runUntilErrorOrReturnFrom: > > >>>>cleanup of the guard contexts no longer works in that
very
>special > > >>>>case where the guard contexts are below the bottom
context.
>There's > > >>>>one case where this is being used:
#terminateAggresively
by
> > >>>>Christoph. > > >>>> > > >>>>If I'm right with this analysis, the
#runUntilErrorOrReturnFrom:
> > >>>>should get fixed too but I'll be away now for a few
days
and
I
>won't > > >>>>be able to respond. If you or Christoph had a chance
to
take
a
>look > > >>>>at Kernel-jar.1538 and Kernel-jar.1537 I'd be very
grateful.
I
>hope > > >>>>this super long message at least makes some sense :) > > >>>>Best, > > >>>>Jaromir > > >>>> > > >>>>[1] Kernel-jar.1538, Kernel-jar.1537 > > >>>>[2] KernelTests-jar.447 > > >>>> > > >>>> > > >>>>PS: Christoph, > > >>>> > > >>>>With Kernel-jar.1538 + Kernel-jar.1537 your example > > >>>> > > >>>>process := > > >>>> [(c := thisContext) pc: nil. > > >>>> 2+3] newProcess. > > >>>>process runUntil: [:ctx | ctx selector =
#cannotReturn:].
> > >>>>self assert: process suspendedContext sender sender =
c.
> > >>>>self assert: process suspendedContext arguments =
{c}.
> > >>>> > > >>>>works fine, I've just corrected your first assert. > > >>>> > > >>>> > > >>>> > > >>>> > > >>>> > > >>>>On 21-Nov-23 6:40:32 PM, "Eliot Miranda" ><eliot.miranda(a)gmail.com> > > >>>>wrote: > > >>>> > > >>>>>Hi Jaromir, > > >>>>> > > >>>>>>On Nov 20, 2023, at 11:51 PM, Jaromir Matas ><mail(a)jaromir.net> > > >>>>>>wrote: > > >>>>>> > > >>>>>> > > >>>>>>Hi Eliot, > > >>>>>>Very elegant! Now I finally got what you meant
exactly
:)
>Thanks. > > >>>>>> > > >>>>>>Two questions: > > >>>>>>1. in order for the enclosed test to work I'd need
an
Error
> > >>>>>>instead of Processor debugWithTitle:full: call in >#cannotReturn:. > > >>>>>>Otherwise I don't know how to catch a plain
invocation
of
the
> > >>>>>>Debugger: > > >>>>>> > > >>>>>>cannotReturn: result > > >>>>>> > > >>>>>> closureOrNil ifNotNil: [^ self cannotReturn:
result
to:
self
> > >>>>>>home sender]. > > >>>>>> self error: 'Computation has been terminated!' > > >>>>> > > >>>>>Much nicer. > > >>>>> > > >>>>>>2. We are capturing a pc of self which is
completely
different
> > >>>>>>context from homeContext indeed. > > >>>>> > > >>>>>Right. The return is attempted from a specific
return
bytecode
>in a > > >>>>>specific block. This is the coordinate of the return
that
cannot
>be > > >>>>>made. This is the relevant point of origin of the
cannot
return
> > >>>>>exception. > > >>>>> > > >>>>>Why the return fails is another matter: > > >>>>>- the home context’s sender is a dead context
(cannot be
>resumed) > > >>>>>- the home context’s sender is nil (home already
returned
from)
> > >>>>>- the block activation’s home is nil rather than a
context
>(should > > >>>>>not happen) > > >>>>> > > >>>>>But in all these cases the pc of the home context is
immaterial.
> > >>>>>The hike is being returned through/from, rather than
from;
the
> > >>>>>home’s pc is not relevant. > > >>>>> > > >>>>>>Maybe we could capture self in the exception too to
make it
>more > > >>>>>>clear/explicit what is going on: what context the
captured
pc
>is > > >>>>>>actually associated with. Just a thought... > > >>>>> > > >>>>>Yes, I like that. I also like the idea of somehow
passing
the
> > >>>>>block activation’s pc to the debugger so that the
relevant
>return > > >>>>>expression is highlighted in the debugger. > > >>>>> > > >>>>>> > > >>>>>>Thanks again, > > >>>>>>Jaromir > > >>>>> > > >>>>>You’re welcome. I love working in this part of the
system.
>Thanks > > >>>>>for dragging me there. I’m in a slump right now and
appreciate
>the > > >>>>>fellowship. > > >>>>> > > >>>>>>------ Original Message ------ > > >>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> > > >>>>>>To "Jaromir Matas" <mail(a)jaromir.net> > > >>>>>>Cc squeak-dev(a)lists.squeakfoundation.org > > >>>>>>Date 11/21/2023 2:17:21 AM > > >>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming on >BlockCannotReturn > > >>>>>>exception > > >>>>>> > > >>>>>>>Hi Jaromir, > > >>>>>>> > > >>>>>>> see Kernel-eem.1535 for what I was suggesting.
This
example
> > >>>>>>>now has an exception with the right pc value in
it:
> > >>>>>>> > > >>>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc
inspect.
ex
>resume]] > > >>>>>>>fork > > >>>>>>> > > >>>>>>>The fix is simply > > >>>>>>> > > >>>>>>>Context>>cannotReturn: result to: homeContext > > >>>>>>> "The receiver tried to return result to
homeContext
that
> > >>>>>>>cannot be returned from. > > >>>>>>> Capture the return pc in a BlockCannotReturn. Nil
the
pc
to
> > >>>>>>>prevent repeat > > >>>>>>> attempts and/or invalid continuation. Answer the
result
of
> > >>>>>>>raising the exception." > > >>>>>>> > > >>>>>>> | exception | > > >>>>>>> exception := BlockCannotReturn new. > > >>>>>>> exception > > >>>>>>> result: result; > > >>>>>>> deadHome: homeContext; > > >>>>>>> pc: self previousPc. > > >>>>>>> pc := nil. > > >>>>>>> ^exception signal > > >>>>>>> > > >>>>>>> > > >>>>>>>The VM crash is now avoided. The debugger displays
the
method,
> > >>>>>>>but does not highlight the offending pc, which is
no
big
deal.
>A > > >>>>>>>suitable defaultHandler for B lockCannotReturn may
be
able
to
>get > > >>>>>>>the debugger to highlight correctly on opening.
Try
the
> > >>>>>>>following examples: > > >>>>>>> > > >>>>>>>[[^1] on: BlockCannotReturn do: #resume] fork. > > >>>>>>> > > >>>>>>>[[^1] on: BlockCannotReturn do: [:ex| ex pc
inspect.
ex
>resume]] > > >>>>>>>fork > > >>>>>>> > > >>>>>>>[[^1] value] fork. > > >>>>>>> > > >>>>>>>They al; seem to behave perfectly acceptably to
me.
Does
this
> > >>>>>>>fix work for you? > > >>>>>>> > > >>>>>>>On Fri, Nov 17, 2023 at 3:14 PM Jaromir Matas ><mail(a)jaromir.net> > > >>>>>>>wrote: > > >>>>>>>>Hi Eliot, > > >>>>>>>> > > >>>>>>>>How about to nil the pc just before making the
return:
> > >>>>>>>>``` > > >>>>>>>>Context >> #cannotReturn: result > > >>>>>>>> > > >>>>>>>> self push: self pc. "backup the pc for the sake
of
> > >>>>>>>>debugging" > > >>>>>>>> closureOrNil ifNotNil: [^self cannotReturn:
result
to:
self
> > >>>>>>>>home sender; pc: nil]. > > >>>>>>>> Processor debugWithTitle: 'Computation has been
terminated!'
> > >>>>>>>>translated full: false > > >>>>>>>>``` > > >>>>>>>>The nilled pc should not even potentially
interfere
with
the
> > >>>>>>>>#isDead now. > > >>>>>>>> > > >>>>>>>>I hope this is at least a step in the right
direction
:)
> > >>>>>>>> > > >>>>>>>>However, there's still a problem when debugging
the
>resumption > > >>>>>>>>of #cannotReturn because the encoders expect a
reasonable
>index. > > >>>>>>>>I haven't figured out yet where to place a nil
check
#step,
> > >>>>>>>>#stepToSendOrReturn... ? > > >>>>>>>> > > >>>>>>>>Thanks again, > > >>>>>>>>Jaromir > > >>>>>>>> > > >>>>>>>> > > >>>>>>>>------ Original Message ------ > > >>>>>>>>From "Eliot Miranda" <eliot.miranda(a)gmail.com> > > >>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> > > >>>>>>>>Date 11/17/2023 8:36:50 PM > > >>>>>>>>Subject Re: [squeak-dev] Re: Resuming on
BlockCannotReturn
> > >>>>>>>>exception > > >>>>>>>> > > >>>>>>>>>Hi Jaromir, > > >>>>>>>>> > > >>>>>>>>>>On Nov 17, 2023, at 7:05 AM, Jaromir Matas ><mail(a)jaromir.net> > > >>>>>>>>>>wrote: > > >>>>>>>>>> > > >>>>>>>>>> > > >>>>>>>>>>Eliot, hi again, > > >>>>>>>>>> > > >>>>>>>>>>Please disregard my previous comment about
nilling
the
> > >>>>>>>>>>contexts that have returned. We are indeed
talking
about
>the > > >>>>>>>>>>context directly under the #cannotReturn
context
which
is
> > >>>>>>>>>>totally different from the home context in
another
thread
> > >>>>>>>>>>that's gone. > > >>>>>>>>>> > > >>>>>>>>>>I may still be confused but would nilling the
pc of
the
> > >>>>>>>>>>context directly under the cannotReturn context
help?
>Here's > > >>>>>>>>>>what I mean: > > >>>>>>>>>>``` > > >>>>>>>>>>Context >> #cannotReturn: result > > >>>>>>>>>> > > >>>>>>>>>> closureOrNil ifNotNil: [^self pc: nil;
cannotReturn:
> > >>>>>>>>>>result to: self home sender]. > > >>>>>>>>>> Processor debugWithTitle: 'Computation has
been
> > >>>>>>>>>>terminated!' translated full: false. > > >>>>>>>>>>``` > > >>>>>>>>>>Instead of crashing the VM invokes the debugger
with
the
> > >>>>>>>>>>'Computation has been terminated!' message. > > >>>>>>>>>> > > >>>>>>>>>>Does this make sense? > > >>>>>>>>> > > >>>>>>>>>Nearly. But it loses the information on what the
pc
actually
> > >>>>>>>>>is, and that’s potentially vital information. So
IMO
the
ox
> > >>>>>>>>>should only be nilled between the
BlockCannotReturn
>exception > > >>>>>>>>>being created and raised. > > >>>>>>>>> > > >>>>>>>>>[But if you try this don’t be surprised if it
causes
a
few
> > >>>>>>>>>temporary problems. It looks to me that without
a
little
> > >>>>>>>>>refactoring this could easily cause an infinite
recursion
> > >>>>>>>>>around the sending of isDead. I’m sure you’ll be
able to
fix
> > >>>>>>>>>the code to work correctly] > > >>>>>>>>> > > >>>>>>>>>>Thanks, > > >>>>>>>>>>Jaromir > > >>>>>>>>>> > > >>>>>>>>>> > > >>>>>>>>>>------ Original Message ------ > > >>>>>>>>>>From "Jaromir Matas" <mail(a)jaromir.net> > > >>>>>>>>>>To "Eliot Miranda" <eliot.miranda(a)gmail.com>;
"The
> > >>>>>>>>>>general-purpose Squeak developers list" > > >>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > > >>>>>>>>>>Date 11/17/2023 10:15:17 AM > > >>>>>>>>>>Subject [squeak-dev] Re: Resuming on
BlockCannotReturn
> > >>>>>>>>>>exception > > >>>>>>>>>> > > >>>>>>>>>>>Hi Eliot, > > >>>>>>>>>>> > > >>>>>>>>>>> > > >>>>>>>>>>> > > >>>>>>>>>>>------ Original Message ------ > > >>>>>>>>>>>From "Eliot Miranda"
<eliot.miranda(a)gmail.com>
> > >>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net> > > >>>>>>>>>>>Cc "The general-purpose Squeak developers
list"
> > >>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > > >>>>>>>>>>>Date 11/16/2023 11:52:45 PM > > >>>>>>>>>>>Subject Re: Re[2]: [squeak-dev] Re: Resuming
on
> > >>>>>>>>>>>BlockCannotReturn exception > > >>>>>>>>>>> > > >>>>>>>>>>>>Hi Jaromir, > > >>>>>>>>>>>> > > >>>>>>>>>>>>On Thu, Nov 16, 2023 at 2:22 PM Jaromir Matas > > >>>>>>>>>>>><mail(a)jaromir.net> wrote: > > >>>>>>>>>>>>>Hi Nicolas, Eliot, > > >>>>>>>>>>>>> > > >>>>>>>>>>>>>here's what I understand is happening (see
the
enclosed
> > >>>>>>>>>>>>>screenshot): > > >>>>>>>>>>>>> > > >>>>>>>>>>>>>1) we fork a new process to evaluate [^1] > > >>>>>>>>>>>>>2) the new process evaluates [^1] which
means
>instruction > > >>>>>>>>>>>>>18 is being evaluated, hence pc points to
instruction 19
> > >>>>>>>>>>>>>now > > >>>>>>>>>>>>>3) however, the home context where ^1 should
return
to
>is > > >>>>>>>>>>>>>gone by this time (the process that executed
the
fork
>has > > >>>>>>>>>>>>>already returned - notice the two up arrows
in
the
>debugger > > >>>>>>>>>>>>>screenshot) > > >>>>>>>>>>>>>4) the VM can't finish the instruction and
returns
>control > > >>>>>>>>>>>>>to the image via placing the #cannotReturn:
context
on
>top > > >>>>>>>>>>>>>of the [^1] context > > >>>>>>>>>>>>>5) #cannotReturn: evaluation results in
signalling
the
>BCR > > >>>>>>>>>>>>>exception which is then handled by the
#resume
handler
> > >>>>>>>>>>>>> (in our debugged case the [:ex | self halt.
ex
resume]
> > >>>>>>>>>>>>>handler) > > >>>>>>>>>>>>>6) ex resume is evaluated, however, this
means
>requesting > > >>>>>>>>>>>>>the VM to evaluate instruction 19 of the
[^1]
context -
> > >>>>>>>>>>>>>which is past the last instruction of the
context
and
>the > > >>>>>>>>>>>>>crash ensues > > >>>>>>>>>>>>> > > >>>>>>>>>>>>>I wonder whether such situations
could/should be
>prevented > > >>>>>>>>>>>>>inside the VM or whether such an expectation
is
wrong
>for > > >>>>>>>>>>>>>some reason. > > >>>>>>>>>>>> > > >>>>>>>>>>>>As Nicolas says, IMO this is best done at the
image
>level. > > >>>>>>>>>>>> > > >>>>>>>>>>>>It could be prevented in the VM, but at great
cost,
and
>only > > >>>>>>>>>>>>partially. The performance issue is that the
last
>bytecode > > >>>>>>>>>>>>in a method is not marked in any way, and
that to
>determine > > >>>>>>>>>>>>the last bytecode the bytecodes must be
symbolically
> > >>>>>>>>>>>>evaluated from the start of the method. See
implementors
>of > > >>>>>>>>>>>>endPC at the image level (which defer to the
method
>trailer) > > >>>>>>>>>>>>and implementors of endPCOf: in the VMMaker
code.
Doing
>this > > >>>>>>>>>>>>every time execution commences is
prohibitively
>expensive. > > >>>>>>>>>>>>The "only partially" issue is that following
the
return
> > >>>>>>>>>>>>instruction may be other valid bytecodes, but
these
are
>not > > >>>>>>>>>>>>a continuation. > > >>>>>>>>>>>> > > >>>>>>>>>>>> > > >>>>>>>>>>>>Consider the following code in some block: > > >>>>>>>>>>>> [self expression ifTrue: > > >>>>>>>>>>>> [^1]. > > >>>>>>>>>>>> ^2 > > >>>>>>>>>>>> > > >>>>>>>>>>>>The bytecodes for this are > > >>>>>>>>>>>> pushReceiver > > >>>>>>>>>>>> send #expression > > >>>>>>>>>>>> jumpFalse L1 > > >>>>>>>>>>>> push 1 > > >>>>>>>>>>>> methodReturnTop > > >>>>>>>>>>>>L1 > > >>>>>>>>>>>> push 2 > > >>>>>>>>>>>> methodReturnTop > > >>>>>>>>>>>> > > >>>>>>>>>>>>Clearly if expression is true these should be
*no*
> > >>>>>>>>>>>>continuation in which ^2 is executed. > > >>>>>>>>>>> > > >>>>>>>>>>>Well, in that case there's a bug because the
computation
>in > > >>>>>>>>>>>the following example shouldn't continue past
the
[^1]
>block > > >>>>>>>>>>>but it silently does: > > >>>>>>>>>>>`[[true ifTrue: [^ 1]] on: BlockCannotReturn
do:
#resume ]
> > >>>>>>>>>>>fork` > > >>>>>>>>>>> > > >>>>>>>>>>>The bytecodes are > > >>>>>>>>>>> push true > > >>>>>>>>>>> jumpFalse L1 > > >>>>>>>>>>> push 1 > > >>>>>>>>>>> returnTop > > >>>>>>>>>>>L1 > > >>>>>>>>>>> push nil > > >>>>>>>>>>> blockReturn > > >>>>>>>>>>> > > >>>>>>>>>>> > > >>>>>>>>>>> > > >>>>>>>>>>>> > > >>>>>>>>>>>>So even if the VM did try and detect whether
the
return
>was > > >>>>>>>>>>>>at the last block method, it would only work
for
special
> > >>>>>>>>>>>>cases. > > >>>>>>>>>>>> > > >>>>>>>>>>>> > > >>>>>>>>>>>>It seems to me the issue is simply that the
context
that
> > >>>>>>>>>>>>cannot be returned from should be marked as
dead
(see
> > >>>>>>>>>>>>Context>>isDead) by setting its pc to nil at
some
point,
> > >>>>>>>>>>>>presumably after copying the actual return pc
into
the
> > >>>>>>>>>>>>BlockCannotReturn exception, to avoid ever
trying
to
>resume > > >>>>>>>>>>>>the context. > > >>>>>>>>>>> > > >>>>>>>>>>>Does this mean, in other words, that every
context
that
> > >>>>>>>>>>>returns should nil its pc to avoid being
"wrongly"
> > >>>>>>>>>>>reused/executed in the future, which concerns
primarily
>those > > >>>>>>>>>>>being referenced somewhere hence potentially
executable in
> > >>>>>>>>>>>the future, is that right? > > >>>>>>>>>>>Hypothetical question: would nilling the pc
during
returns
> > >>>>>>>>>>>"fix" the example? > > >>>>>>>>>>>Thanks a lot for helping me understand this. > > >>>>>>>>>>>Best, > > >>>>>>>>>>>Jaromir > > >>>>>>>>>>> > > >>>>>>>>>>> > > >>>>>>>>>>> > > >>>>>>>>>>>> > > >>>>>>>>>>>> > > >>>>>>>>>>>>> > > >>>>>>>>>>>>>Thanks, > > >>>>>>>>>>>>>Jaromir > > >>>>>>>>>>>>> > > >>>>>>>>>>>>><bdxuqalu.png> > > >>>>>>>>>>>>> > > >>>>>>>>>>>>>------ Original Message ------ > > >>>>>>>>>>>>>From "Eliot Miranda"
<eliot.miranda(a)gmail.com>
> > >>>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>;
"The
>general-purpose > > >>>>>>>>>>>>>Squeak developers list" > > >>>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > > >>>>>>>>>>>>>Date 11/16/2023 6:48:43 PM > > >>>>>>>>>>>>>Subject Re: [squeak-dev] Re: Resuming on >BlockCannotReturn > > >>>>>>>>>>>>>exception > > >>>>>>>>>>>>> > > >>>>>>>>>>>>>>Hi Jaromir, > > >>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>On Nov 16, 2023, at 3:23 AM, Jaromir Matas > > >>>>>>>>>>>>>>><mail(a)jaromir.net> wrote: > > >>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>Hi Nicloas, > > >>>>>>>>>>>>>>>No no, I don't have any practical scenario
in
mind,
>I'm > > >>>>>>>>>>>>>>>just trying to understand why the VM is
implemented
>like > > >>>>>>>>>>>>>>>this, whether there were a reason to leave
this
> > >>>>>>>>>>>>>>>possibility of a crash, e.g. it would slow
down
the VM
>to > > >>>>>>>>>>>>>>>try to prevent such a dumb situation (who
would
resume
> > >>>>>>>>>>>>>>>from BCR in his right mind? :) ) - or
perhaps
I
have
> > >>>>>>>>>>>>>>>overlooked some good reason to even keep
this
behavior
>in > > >>>>>>>>>>>>>>>the VM. That's all. > > >>>>>>>>>>>>>> > > >>>>>>>>>>>>>>Let’s first understand what’s really
happening.
>Presumably > > >>>>>>>>>>>>>>at tone point a context is resumed those pc
is
already
>at > > >>>>>>>>>>>>>>the block return bytecode (effectively,
because
it
>crashes > > >>>>>>>>>>>>>>in JITted code, but I bet the stack vm will
crash
also,
> > >>>>>>>>>>>>>>but not as cleanly - it will try and
execute
the
bytes
>in > > >>>>>>>>>>>>>>the encoded method trailer). So which
method
actually
> > >>>>>>>>>>>>>>sends resume, and to what, and what state
is
resume’s
> > >>>>>>>>>>>>>>receiver when resume is sent? > > >>>>>>>>>>>>>> > > >>>>>>>>>>>>>> > > >>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>Thanks for your reply. > > >>>>>>>>>>>>>>>Regards, > > >>>>>>>>>>>>>>>Jaromir > > >>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>------ Original Message ------ > > >>>>>>>>>>>>>>>From "Nicolas Cellier" > > >>>>>>>>>>>>>>><nicolas.cellier.aka.nice(a)gmail.com> > > >>>>>>>>>>>>>>>To "Jaromir Matas" <mail(a)jaromir.net>;
"The
> > >>>>>>>>>>>>>>>general-purpose Squeak developers list" > > >>>>>>>>>>>>>>><squeak-dev(a)lists.squeakfoundation.org> > > >>>>>>>>>>>>>>>Date 11/16/2023 7:20:20 AM > > >>>>>>>>>>>>>>>Subject Re: [squeak-dev] Resuming on
BlockCannotReturn
> > >>>>>>>>>>>>>>>exception > > >>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>>Hi Jaromir, > > >>>>>>>>>>>>>>>>Is there a scenario where it would make
sense
to
>resume > > >>>>>>>>>>>>>>>>a BlockCannotReturn? > > >>>>>>>>>>>>>>>>If not, I would suggest to protect at
image
side
and
> > >>>>>>>>>>>>>>>>override #resume. > > >>>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>>Le mer. 15 nov. 2023, 23:42, Jaromir
Matas
> > >>>>>>>>>>>>>>>><mail(a)jaromir.net> a écrit : > > >>>>>>>>>>>>>>>>>Hi Eliot, Christoph, All, > > >>>>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>>>It's known the following example crashes
the
VM.
Is
> > >>>>>>>>>>>>>>>>>this an intended behavior or a
"tolerated
bug"?
> > >>>>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>>>`[[^ 1] on: BlockCannotReturn do:
#resume]
fork`
> > >>>>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>>>I understand why it crashes: the
non-local
return
>has > > >>>>>>>>>>>>>>>>>nowhere to return to and so resuming the
computation
> > >>>>>>>>>>>>>>>>>leads to a crash. But why not raise
another
BCR
> > >>>>>>>>>>>>>>>>>exception to prevent the crash?
Potential
infinite
> > >>>>>>>>>>>>>>>>>loop? Perhaps I'm just missing the
purpose
of
this
> > >>>>>>>>>>>>>>>>>behavior... > > >>>>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>>>Thanks for an explanation. > > >>>>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>>>Best, > > >>>>>>>>>>>>>>>>>Jaromir > > >>>>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>>>-- > > >>>>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>>>Jaromir Matas > > >>>>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>> > > >>>>>>>>>>>> > > >>>>>>>>>>>> > > >>>>>>>>>>>>-- > > >>>>>>>>>>>>_,,,^..^,,,_ > > >>>>>>>>>>>>best, Eliot > > >>>>>>>>>><Context-cannotReturn.st> > > >>>>>>> > > >>>>>>> > > >>>>>>>-- > > >>>>>>>_,,,^..^,,,_ > > >>>>>>>best, Eliot > > >>>>>><ProcessTest-testResumeAfterBCR.st>
Sent from Squeak Inbox Talk https://github.com/hpi-swa-lab/squeak-inbox-talk
squeak-dev@lists.squeakfoundation.org
-
 christoph.thiede@student.hpi.uni-potsdam.de
christoph.thiede@student.hpi.uni-potsdam.de -
 David T Lewis
David T Lewis -
 Eliot Miranda
Eliot Miranda -
 Jakob Reschke
Jakob Reschke -
 Jaromir Matas
Jaromir Matas -
lewis@mail.msen.com
-
 Taeumel, Marcel
Taeumel, Marcel -
 Tim Rowledge
Tim Rowledge