
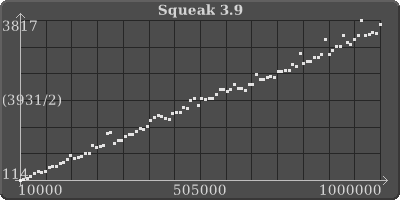
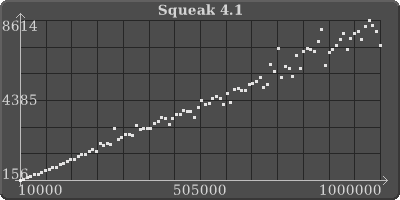
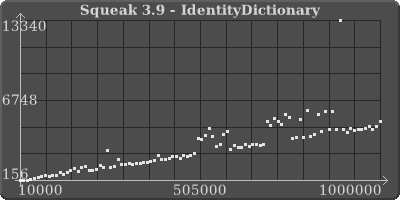
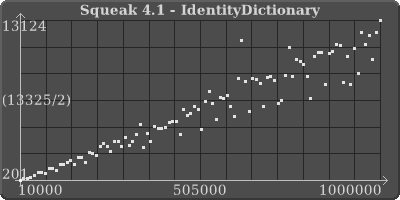
4.1 hashed collections, across the board, small to large, are slower by a factor of 2?! I just don't think we can keep doing this; getting slower and slower and slower, like molasses.. I'm sorry, but I really care about this and I know you do too because speed was the whole premise of putting these changes in.
What went wrong? More importantly, how can we fix this?
{kind=link}
{kind=link}
{kind=link}
{kind=link}

On 22.03.2010, at 22:40, Chris Muller wrote:
4.1 hashed collections, across the board, small to large, are slower by a factor of 2?! I just don't think we can keep doing this; getting slower and slower and slower, like molasses.. I'm sorry, but I really care about this and I know you do too because speed was the whole premise of putting these changes in.
What went wrong? More importantly, how can we fix this? <IdentitySet.3.9.png><IdentitySet.4.1.png><IdentityDictionary.3.9.png><IdentityDictionary.4.1.png>
Neat graphs. But what exactly are you measuring?
- Bert -
The output of the test script from the other day.
| test ord | test := IdentitySet new. [ test size >= 1000000 ] whileFalse: [ ord := OrderedCollection new: 100. 10000 timesRepeat: [ test add: ( ord add: Object new ) ]. Transcript show: test size asString; tab. Transcript show: [ 10 timesRepeat: [ ord do: [ :each | test includes: each ] ] ] timeToRun asString. Transcript cr ]
On Mon, Mar 22, 2010 at 4:46 PM, Bert Freudenberg bert@freudenbergs.de wrote:
On 22.03.2010, at 22:40, Chris Muller wrote:
4.1 hashed collections, across the board, small to large, are slower by a factor of 2?! I just don't think we can keep doing this; getting slower and slower and slower, like molasses.. I'm sorry, but I really care about this and I know you do too because speed was the whole premise of putting these changes in.
What went wrong? More importantly, how can we fix this? <IdentitySet.3.9.png><IdentitySet.4.1.png><IdentityDictionary.3.9.png><IdentityDictionary.4.1.png>
Neat graphs. But what exactly are you measuring?
- Bert -

On Mon, 22 Mar 2010, Chris Muller wrote:
4.1 hashed collections, across the board, small to large, are slower by a factor of 2?! I just don't think we can keep doing this; getting slower and slower and slower, like molasses.. I'm sorry, but I really care about this and I know you do too because speed was the whole premise of putting these changes in.
What went wrong? More importantly, how can we fix this?
What went wrong?
I think nothing. :) IdentitySet and IdentityDictionary wasn't ment to support really large collections. The main reason is that there are only 4096 different hash values. So practically these collections are growing 4096 lists in a single array. In 3.9 and 3.10 these collections used a hash expansion technique which distributed the elements uniformly. This was changed when we integrated Andrés' hash changes. As you noticed some of the primes didn't work well with #scaledIdentityHash, it's far better now, though there may be even better primes. Finding such primes is a computationally intensive task and the current ones (up to 10000000) are pretty close to optimal. Other than that there are two things that cause slowdown: +1 extra message send/scanning: #scaledIdentityHash (the new hash expansion scheme, but we save one by not using #findElementOrNil:) +k (worst case) extra message send/scanning: #enclosedSetElement (OO nil support, this only applies for IdentitySet) Where k is the length of the list. Since there are only 4096 different identity hash values for n = 250000 k will be ~61 (if the identity hashes have a uniform distribution). For n = 1000000 it will be ~244. Note that your benchmark exploits the worst case. The long lists are bad, because HashedCollection is optimized for O(1) list length. In this case the length of the list is not O(1), but O(n) (with a very small constant).
How can we fix this?
I see two possible solutions for the problem: 1) use #largeHash instead of #identityHash, which is the identity hash of the object mixed with the identity hash of its class. This helps if there are objects from different classes in the set, but it doesn't help with your benchmark. SystemTracer uses this method. 2) use differently implemented collections which are optimized for your use case. For example I wrote LargeIdentitySet which probably has the best performance you can have: http://leves.web.elte.hu/squeak/LargeIdentitySet.st (note that it's hardly tested, probably contains bugs)
Levente

Has it ever been considered to make the identity hash larger than 12 bits? Of course this is a trade off against space, but one that can be justified?!
Just an idea: we could get rid of compact classes, which would give us additional 6 bits (5 bits from the compact class index plus 1 bit from the header type because there would only be 2 header types left). This would increase the identity hash values from 4096 to 262144. In a PharoCore1.0 image there are 148589 instances of compact classes, hence this would cost 580k. Or, we could just add an additional word and use the spare bits from the old identity hash for other stuff, e.g., immutability ;)
Cheers, Adrian
On Mar 23, 2010, at 11:36 , Levente Uzonyi wrote:
How can we fix this?
I see two possible solutions for the problem:
- use #largeHash instead of #identityHash, which is the identity hash of the object mixed with the identity hash of its class. This helps if there are objects from different classes in the set, but it doesn't help with your benchmark. SystemTracer uses this method.
- use differently implemented collections which are optimized for your use case. For example I wrote LargeIdentitySet which probably has the best performance you can have: http://leves.web.elte.hu/squeak/LargeIdentitySet.st
(note that it's hardly tested, probably contains bugs)
Levente
On Tue, 23 Mar 2010, Adrian Lienhard wrote:
Has it ever been considered to make the identity hash larger than 12 bits? Of course this is a trade off against space, but one that can be justified?!
Probably yes.
Just an idea: we could get rid of compact classes, which would give us additional 6 bits (5 bits from the compact class index plus 1 bit from the header type because there would only be 2 header types left). This would increase the identity hash values from 4096 to 262144. In a PharoCore1.0 image there are 148589 instances of compact classes, hence this would cost 580k. Or, we could just add an additional word and use the spare bits from the old identity hash for other stuff, e.g., immutability ;)
I like the first idea, we could even have the 17 continuous bits for identity hash the 1 separate bit for immutability.
Levente
Cheers, Adrian
On Mar 23, 2010, at 11:36 , Levente Uzonyi wrote:
How can we fix this?
I see two possible solutions for the problem:
- use #largeHash instead of #identityHash, which is the identity hash of the object mixed with the identity hash of its class. This helps if there are objects from different classes in the set, but it doesn't help with your benchmark. SystemTracer uses this method.
- use differently implemented collections which are optimized for your use case. For example I wrote LargeIdentitySet which probably has the best performance you can have: http://leves.web.elte.hu/squeak/LargeIdentitySet.st
(note that it's hardly tested, probably contains bugs)
Levente

Just an idea: we could get rid of compact classes, which would give us additional 6 bits (5 bits from the compact class index plus 1 bit from the header type because there would only be 2 header types left). This would increase the identity hash values from 4096 to 262144. In a PharoCore1.0 image there are 148589 instances of compact classes, hence this would cost 580k. Or, we could just add an additional word and use the spare bits from the old identity hash for other stuff, e.g., immutability ;)
I like the first idea, we could even have the 17 continuous bits for identity hash the 1 separate bit for immutability.
Yes please, I love it :-)
Lukas
On 23.03.2010, at 16:01, Lukas Renggli wrote:
Just an idea: we could get rid of compact classes, which would give us additional 6 bits (5 bits from the compact class index plus 1 bit from the header type because there would only be 2 header types left). This would increase the identity hash values from 4096 to 262144. In a PharoCore1.0 image there are 148589 instances of compact classes, hence this would cost 580k. Or, we could just add an additional word and use the spare bits from the old identity hash for other stuff, e.g., immutability ;)
I like the first idea, we could even have the 17 continuous bits for identity hash the 1 separate bit for immutability.
Yes please, I love it :-)
Lukas
Well, someone should code it up, and then lets's see macro benchmarks :)
- Bert -
On Tue, 23 Mar 2010, Bert Freudenberg wrote:
On 23.03.2010, at 16:01, Lukas Renggli wrote:
Just an idea: we could get rid of compact classes, which would give us additional 6 bits (5 bits from the compact class index plus 1 bit from the header type because there would only be 2 header types left). This would increase the identity hash values from 4096 to 262144. In a PharoCore1.0 image there are 148589 instances of compact classes, hence this would cost 580k. Or, we could just add an additional word and use the spare bits from the old identity hash for other stuff, e.g., immutability ;)
I like the first idea, we could even have the 17 continuous bits for identity hash the 1 separate bit for immutability.
Yes please, I love it :-)
Lukas
Well, someone should code it up, and then lets's see macro benchmarks :)
That's a great idea, but I'm sure it'll take a while until that happens. Fortunately identityhash related benchmarks can be done without changing the vm. I rewrote a bit the benchmark from Chris, created three classes which have 17, 18 and 30 bits for #scaledIdentityHash. Ran the benchmark with these three classes + Object, collected the data and created some diagrams. I'm sure most people don't care about the code/data[1], so here are the diagrams: http://leves.web.elte.hu/identityHashBits/identityHashBits.png http://leves.web.elte.hu/identityHashBits/identityHashBits2.png http://leves.web.elte.hu/identityHashBits/identityHashBits3.png
The first one contains the four graphs. It clearly shows that 12 bits (Object) are insufficient for #identityHash. Even 5 more bits gives 8-9x speedup and a dramatic change in behavior.
The second is the same as the first, but it shows only the 17, 18 and 30 bits case. Note that the primes (hashtable sizes) are now optimized for 12 bits. If they are optimized for 17/18 bits then the results can be better for larger set sizes (130+/260+) where they show worse behavior compared to the 18/30 bits case.
The third graph shows how an optimized data structure (LargeIdentitySet) compares to the 17, 18 and 30 bits case using only 12 bits.
[1] All the code/data that were used to generate these graphs can be found here http://leves.web.elte.hu/identityHashBits
Levente
P.S. I also created a 12 bit version of the 17-18-30 bit classes and found that it's 1.2-2.0x slower than Object, so the values after the vm changes are expected to be even better than what these graphs show.
- Bert -
On 23.03.2010, at 23:57, Levente Uzonyi wrote:
On Tue, 23 Mar 2010, Bert Freudenberg wrote:
On 23.03.2010, at 16:01, Lukas Renggli wrote:
Just an idea: we could get rid of compact classes, which would give us additional 6 bits (5 bits from the compact class index plus 1 bit from the header type because there would only be 2 header types left). This would increase the identity hash values from 4096 to 262144. In a PharoCore1.0 image there are 148589 instances of compact classes, hence this would cost 580k. Or, we could just add an additional word and use the spare bits from the old identity hash for other stuff, e.g., immutability ;)
I like the first idea, we could even have the 17 continuous bits for identity hash the 1 separate bit for immutability.
Yes please, I love it :-)
Lukas
Well, someone should code it up, and then lets's see macro benchmarks :)
That's a great idea, but I'm sure it'll take a while until that happens. Fortunately identityhash related benchmarks can be done without changing the vm. I rewrote a bit the benchmark from Chris, created three classes which have 17, 18 and 30 bits for #scaledIdentityHash. Ran the benchmark with these three classes + Object, collected the data and created some diagrams. I'm sure most people don't care about the code/data[1], so here are the diagrams: http://leves.web.elte.hu/identityHashBits/identityHashBits.png http://leves.web.elte.hu/identityHashBits/identityHashBits2.png http://leves.web.elte.hu/identityHashBits/identityHashBits3.png
The first one contains the four graphs. It clearly shows that 12 bits (Object) are insufficient for #identityHash. Even 5 more bits gives 8-9x speedup and a dramatic change in behavior.
The second is the same as the first, but it shows only the 17, 18 and 30 bits case. Note that the primes (hashtable sizes) are now optimized for 12 bits. If they are optimized for 17/18 bits then the results can be better for larger set sizes (130+/260+) where they show worse behavior compared to the 18/30 bits case.
The third graph shows how an optimized data structure (LargeIdentitySet) compares to the 17, 18 and 30 bits case using only 12 bits.
[1] All the code/data that were used to generate these graphs can be found here http://leves.web.elte.hu/identityHashBits
Levente
P.S. I also created a 12 bit version of the 17-18-30 bit classes and found that it's 1.2-2.0x slower than Object, so the values after the vm changes are expected to be even better than what these graphs show.
So this seems to indicate your specialized data structure beats all VM hash bits extension?
Also, we don't know yet how getting rid of compact classes would affect performance.
- Bert -

On 24 March 2010 01:22, Bert Freudenberg bert@freudenbergs.de wrote:
On 23.03.2010, at 23:57, Levente Uzonyi wrote:
On Tue, 23 Mar 2010, Bert Freudenberg wrote:
On 23.03.2010, at 16:01, Lukas Renggli wrote:
Just an idea: we could get rid of compact classes, which would give us additional 6 bits (5 bits from the compact class index plus 1 bit from the header type because there would only be 2 header types left). This would increase the identity hash values from 4096 to 262144. In a PharoCore1.0 image there are 148589 instances of compact classes, hence this would cost 580k. Or, we could just add an additional word and use the spare bits from the old identity hash for other stuff, e.g., immutability ;)
I like the first idea, we could even have the 17 continuous bits for identity hash the 1 separate bit for immutability.
Yes please, I love it :-)
Lukas
Well, someone should code it up, and then lets's see macro benchmarks :)
That's a great idea, but I'm sure it'll take a while until that happens. Fortunately identityhash related benchmarks can be done without changing the vm. I rewrote a bit the benchmark from Chris, created three classes which have 17, 18 and 30 bits for #scaledIdentityHash. Ran the benchmark with these three classes + Object, collected the data and created some diagrams. I'm sure most people don't care about the code/data[1], so here are the diagrams: http://leves.web.elte.hu/identityHashBits/identityHashBits.png http://leves.web.elte.hu/identityHashBits/identityHashBits2.png http://leves.web.elte.hu/identityHashBits/identityHashBits3.png
The first one contains the four graphs. It clearly shows that 12 bits (Object) are insufficient for #identityHash. Even 5 more bits gives 8-9x speedup and a dramatic change in behavior.
The second is the same as the first, but it shows only the 17, 18 and 30 bits case. Note that the primes (hashtable sizes) are now optimized for 12 bits. If they are optimized for 17/18 bits then the results can be better for larger set sizes (130+/260+) where they show worse behavior compared to the 18/30 bits case.
The third graph shows how an optimized data structure (LargeIdentitySet) compares to the 17, 18 and 30 bits case using only 12 bits.
[1] All the code/data that were used to generate these graphs can be found here http://leves.web.elte.hu/identityHashBits
Levente
P.S. I also created a 12 bit version of the 17-18-30 bit classes and found that it's 1.2-2.0x slower than Object, so the values after the vm changes are expected to be even better than what these graphs show.
So this seems to indicate your specialized data structure beats all VM hash bits extension?
Also, we don't know yet how getting rid of compact classes would affect performance.
i expect a slight speed increase, because of more uniform header handling :)
Concerning LargeIdentitySet - this is good argument to the point that for large collections we should use different data structures.
- Bert -

Igor, keep in mind that the image will become larger... you may get a counterbalancing performance hit because the CPU will have to do more memory reads...
On 3/23/10 16:29 , Igor Stasenko wrote:
On 24 March 2010 01:22, Bert Freudenbergbert@freudenbergs.de wrote:
On 23.03.2010, at 23:57, Levente Uzonyi wrote:
On Tue, 23 Mar 2010, Bert Freudenberg wrote:
On 23.03.2010, at 16:01, Lukas Renggli wrote:
> Just an idea: we could get rid of compact classes, which would give us > additional 6 bits (5 bits from the compact class index plus 1 bit from the > header type because there would only be 2 header types left). This would > increase the identity hash values from 4096 to 262144. In a PharoCore1.0 > image there are 148589 instances of compact classes, hence this would cost > 580k. Or, we could just add an additional word and use the spare bits from > the old identity hash for other stuff, e.g., immutability ;) > I like the first idea, we could even have the 17 continuous bits for identity hash the 1 separate bit for immutability.
Yes please, I love it :-)
Lukas
Well, someone should code it up, and then lets's see macro benchmarks :)
That's a great idea, but I'm sure it'll take a while until that happens. Fortunately identityhash related benchmarks can be done without changing the vm. I rewrote a bit the benchmark from Chris, created three classes which have 17, 18 and 30 bits for #scaledIdentityHash. Ran the benchmark with these three classes + Object, collected the data and created some diagrams. I'm sure most people don't care about the code/data[1], so here are the diagrams: http://leves.web.elte.hu/identityHashBits/identityHashBits.png http://leves.web.elte.hu/identityHashBits/identityHashBits2.png http://leves.web.elte.hu/identityHashBits/identityHashBits3.png
The first one contains the four graphs. It clearly shows that 12 bits (Object) are insufficient for #identityHash. Even 5 more bits gives 8-9x speedup and a dramatic change in behavior.
The second is the same as the first, but it shows only the 17, 18 and 30 bits case. Note that the primes (hashtable sizes) are now optimized for 12 bits. If they are optimized for 17/18 bits then the results can be better for larger set sizes (130+/260+) where they show worse behavior compared to the 18/30 bits case.
The third graph shows how an optimized data structure (LargeIdentitySet) compares to the 17, 18 and 30 bits case using only 12 bits.
[1] All the code/data that were used to generate these graphs can be found here http://leves.web.elte.hu/identityHashBits
Levente
P.S. I also created a 12 bit version of the 17-18-30 bit classes and found that it's 1.2-2.0x slower than Object, so the values after the vm changes are expected to be even better than what these graphs show.
So this seems to indicate your specialized data structure beats all VM hash bits extension?
Also, we don't know yet how getting rid of compact classes would affect performance.
i expect a slight speed increase, because of more uniform header handling :)
Concerning LargeIdentitySet - this is good argument to the point that for large collections we should use different data structures.
- Bert -
On Wed, 24 Mar 2010, Bert Freudenberg wrote:
On 23.03.2010, at 23:57, Levente Uzonyi wrote:
On Tue, 23 Mar 2010, Bert Freudenberg wrote:
On 23.03.2010, at 16:01, Lukas Renggli wrote:
Just an idea: we could get rid of compact classes, which would give us additional 6 bits (5 bits from the compact class index plus 1 bit from the header type because there would only be 2 header types left). This would increase the identity hash values from 4096 to 262144. In a PharoCore1.0 image there are 148589 instances of compact classes, hence this would cost 580k. Or, we could just add an additional word and use the spare bits from the old identity hash for other stuff, e.g., immutability ;)
I like the first idea, we could even have the 17 continuous bits for identity hash the 1 separate bit for immutability.
Yes please, I love it :-)
Lukas
Well, someone should code it up, and then lets's see macro benchmarks :)
That's a great idea, but I'm sure it'll take a while until that happens. Fortunately identityhash related benchmarks can be done without changing the vm. I rewrote a bit the benchmark from Chris, created three classes which have 17, 18 and 30 bits for #scaledIdentityHash. Ran the benchmark with these three classes + Object, collected the data and created some diagrams. I'm sure most people don't care about the code/data[1], so here are the diagrams: http://leves.web.elte.hu/identityHashBits/identityHashBits.png http://leves.web.elte.hu/identityHashBits/identityHashBits2.png http://leves.web.elte.hu/identityHashBits/identityHashBits3.png
The first one contains the four graphs. It clearly shows that 12 bits (Object) are insufficient for #identityHash. Even 5 more bits gives 8-9x speedup and a dramatic change in behavior.
The second is the same as the first, but it shows only the 17, 18 and 30 bits case. Note that the primes (hashtable sizes) are now optimized for 12 bits. If they are optimized for 17/18 bits then the results can be better for larger set sizes (130+/260+) where they show worse behavior compared to the 18/30 bits case.
The third graph shows how an optimized data structure (LargeIdentitySet) compares to the 17, 18 and 30 bits case using only 12 bits.
[1] All the code/data that were used to generate these graphs can be found here http://leves.web.elte.hu/identityHashBits
Levente
P.S. I also created a 12 bit version of the 17-18-30 bit classes and found that it's 1.2-2.0x slower than Object, so the values after the vm changes are expected to be even better than what these graphs show.
So this seems to indicate your specialized data structure beats all VM hash bits extension?
For IdentitySet - probably yes, up to a few million elements, but I expect the difference to be smaller with the vm support and optimal table sizes. (note that a "normal" image contains less than 500000 objects). For IdentityDictionary - probably not, because we don't have a fast primitive that can be used for the lookups.
Levente
Also, we don't know yet how getting rid of compact classes would affect performance.
- Bert -
As soon as you get a JIT VM, you will be surprised at how expensive primitives that require calling a C function can be. You might be better off without the primitive and with a more streamlined hashed collection instead. Also, the presence of the primitive will allow little to no flexibility...
On 3/23/10 16:47 , Levente Uzonyi wrote:
On Wed, 24 Mar 2010, Bert Freudenberg wrote:
On 23.03.2010, at 23:57, Levente Uzonyi wrote:
On Tue, 23 Mar 2010, Bert Freudenberg wrote:
On 23.03.2010, at 16:01, Lukas Renggli wrote:
> Just an idea: we could get rid of compact classes, which would give us > additional 6 bits (5 bits from the compact class index plus 1 bit from the > header type because there would only be 2 header types left). This would > increase the identity hash values from 4096 to 262144. In a PharoCore1.0 > image there are 148589 instances of compact classes, hence this would cost > 580k. Or, we could just add an additional word and use the spare bits from > the old identity hash for other stuff, e.g., immutability ;) > I like the first idea, we could even have the 17 continuous bits for identity hash the 1 separate bit for immutability.
Yes please, I love it :-)
Lukas
Well, someone should code it up, and then lets's see macro benchmarks :)
That's a great idea, but I'm sure it'll take a while until that happens. Fortunately identityhash related benchmarks can be done without changing the vm. I rewrote a bit the benchmark from Chris, created three classes which have 17, 18 and 30 bits for #scaledIdentityHash. Ran the benchmark with these three classes + Object, collected the data and created some diagrams. I'm sure most people don't care about the code/data[1], so here are the diagrams: http://leves.web.elte.hu/identityHashBits/identityHashBits.png http://leves.web.elte.hu/identityHashBits/identityHashBits2.png http://leves.web.elte.hu/identityHashBits/identityHashBits3.png
The first one contains the four graphs. It clearly shows that 12 bits (Object) are insufficient for #identityHash. Even 5 more bits gives 8-9x speedup and a dramatic change in behavior.
The second is the same as the first, but it shows only the 17, 18 and 30 bits case. Note that the primes (hashtable sizes) are now optimized for 12 bits. If they are optimized for 17/18 bits then the results can be better for larger set sizes (130+/260+) where they show worse behavior compared to the 18/30 bits case.
The third graph shows how an optimized data structure (LargeIdentitySet) compares to the 17, 18 and 30 bits case using only 12 bits.
[1] All the code/data that were used to generate these graphs can be found here http://leves.web.elte.hu/identityHashBits
Levente
P.S. I also created a 12 bit version of the 17-18-30 bit classes and found that it's 1.2-2.0x slower than Object, so the values after the vm changes are expected to be even better than what these graphs show.
So this seems to indicate your specialized data structure beats all VM hash bits extension?
For IdentitySet - probably yes, up to a few million elements, but I expect the difference to be smaller with the vm support and optimal table sizes. (note that a "normal" image contains less than 500000 objects). For IdentityDictionary - probably not, because we don't have a fast primitive that can be used for the lookups.
Levente
Also, we don't know yet how getting rid of compact classes would affect performance.
- Bert -
.
(with a good hash function, the primitive will almost always find the required object in the first try, negating the benefits of the primitive)
On 3/23/10 18:20 , Andres Valloud wrote:
As soon as you get a JIT VM, you will be surprised at how expensive primitives that require calling a C function can be. You might be better off without the primitive and with a more streamlined hashed collection instead. Also, the presence of the primitive will allow little to no flexibility...
On 3/23/10 16:47 , Levente Uzonyi wrote:
On Wed, 24 Mar 2010, Bert Freudenberg wrote:
On 23.03.2010, at 23:57, Levente Uzonyi wrote:
On Tue, 23 Mar 2010, Bert Freudenberg wrote:
On 23.03.2010, at 16:01, Lukas Renggli wrote:
>> Just an idea: we could get rid of compact classes, which would give us >> additional 6 bits (5 bits from the compact class index plus 1 bit from the >> header type because there would only be 2 header types left). This would >> increase the identity hash values from 4096 to 262144. In a PharoCore1.0 >> image there are 148589 instances of compact classes, hence this would cost >> 580k. Or, we could just add an additional word and use the spare bits from >> the old identity hash for other stuff, e.g., immutability ;) >> >> > I like the first idea, we could even have the 17 continuous bits for > identity hash the 1 separate bit for immutability. > > Yes please, I love it :-)
Lukas
Well, someone should code it up, and then lets's see macro benchmarks :)
That's a great idea, but I'm sure it'll take a while until that happens. Fortunately identityhash related benchmarks can be done without changing the vm. I rewrote a bit the benchmark from Chris, created three classes which have 17, 18 and 30 bits for #scaledIdentityHash. Ran the benchmark with these three classes + Object, collected the data and created some diagrams. I'm sure most people don't care about the code/data[1], so here are the diagrams: http://leves.web.elte.hu/identityHashBits/identityHashBits.png http://leves.web.elte.hu/identityHashBits/identityHashBits2.png http://leves.web.elte.hu/identityHashBits/identityHashBits3.png
The first one contains the four graphs. It clearly shows that 12 bits (Object) are insufficient for #identityHash. Even 5 more bits gives 8-9x speedup and a dramatic change in behavior.
The second is the same as the first, but it shows only the 17, 18 and 30 bits case. Note that the primes (hashtable sizes) are now optimized for 12 bits. If they are optimized for 17/18 bits then the results can be better for larger set sizes (130+/260+) where they show worse behavior compared to the 18/30 bits case.
The third graph shows how an optimized data structure (LargeIdentitySet) compares to the 17, 18 and 30 bits case using only 12 bits.
[1] All the code/data that were used to generate these graphs can be found here http://leves.web.elte.hu/identityHashBits
Levente
P.S. I also created a 12 bit version of the 17-18-30 bit classes and found that it's 1.2-2.0x slower than Object, so the values after the vm changes are expected to be even better than what these graphs show.
So this seems to indicate your specialized data structure beats all VM hash bits extension?
For IdentitySet - probably yes, up to a few million elements, but I expect the difference to be smaller with the vm support and optimal table sizes. (note that a "normal" image contains less than 500000 objects). For IdentityDictionary - probably not, because we don't have a fast primitive that can be used for the lookups.
Levente
Also, we don't know yet how getting rid of compact classes would affect performance.
- Bert -
.
.
On Tue, 23 Mar 2010, Andres Valloud wrote:
(with a good hash function, the primitive will almost always find the required object in the first try, negating the benefits of the primitive)
With 4096 different hash values and 1000000 objects that won't happen.
Levente
On 3/23/10 18:20 , Andres Valloud wrote:
As soon as you get a JIT VM, you will be surprised at how expensive primitives that require calling a C function can be. You might be better off without the primitive and with a more streamlined hashed collection instead. Also, the presence of the primitive will allow little to no flexibility...
On 3/23/10 16:47 , Levente Uzonyi wrote:
On Wed, 24 Mar 2010, Bert Freudenberg wrote:
On 23.03.2010, at 23:57, Levente Uzonyi wrote:
On Tue, 23 Mar 2010, Bert Freudenberg wrote:
On 23.03.2010, at 16:01, Lukas Renggli wrote:
> > >>> Just an idea: we could get rid of compact classes, which would give >>> us >>> additional 6 bits (5 bits from the compact class index plus 1 bit >>> from the >>> header type because there would only be 2 header types left). This >>> would >>> increase the identity hash values from 4096 to 262144. In a >>> PharoCore1.0 >>> image there are 148589 instances of compact classes, hence this >>> would cost >>> 580k. Or, we could just add an additional word and use the spare >>> bits from >>> the old identity hash for other stuff, e.g., immutability ;) >>> >>> >> I like the first idea, we could even have the 17 continuous bits for >> identity hash the 1 separate bit for immutability. >> >> > Yes please, I love it :-) > > Lukas > > Well, someone should code it up, and then lets's see macro benchmarks :)
That's a great idea, but I'm sure it'll take a while until that happens. Fortunately identityhash related benchmarks can be done without changing the vm. I rewrote a bit the benchmark from Chris, created three classes which have 17, 18 and 30 bits for #scaledIdentityHash. Ran the benchmark with these three classes + Object, collected the data and created some diagrams. I'm sure most people don't care about the code/data[1], so here are the diagrams: http://leves.web.elte.hu/identityHashBits/identityHashBits.png http://leves.web.elte.hu/identityHashBits/identityHashBits2.png http://leves.web.elte.hu/identityHashBits/identityHashBits3.png
The first one contains the four graphs. It clearly shows that 12 bits (Object) are insufficient for #identityHash. Even 5 more bits gives 8-9x speedup and a dramatic change in behavior.
The second is the same as the first, but it shows only the 17, 18 and 30 bits case. Note that the primes (hashtable sizes) are now optimized for 12 bits. If they are optimized for 17/18 bits then the results can be better for larger set sizes (130+/260+) where they show worse behavior compared to the 18/30 bits case.
The third graph shows how an optimized data structure (LargeIdentitySet) compares to the 17, 18 and 30 bits case using only 12 bits.
[1] All the code/data that were used to generate these graphs can be found here http://leves.web.elte.hu/identityHashBits
Levente
P.S. I also created a 12 bit version of the 17-18-30 bit classes and found that it's 1.2-2.0x slower than Object, so the values after the vm changes are expected to be even better than what these graphs show.
So this seems to indicate your specialized data structure beats all VM hash bits extension?
For IdentitySet - probably yes, up to a few million elements, but I expect the difference to be smaller with the vm support and optimal table sizes. (note that a "normal" image contains less than 500000 objects). For IdentityDictionary - probably not, because we don't have a fast primitive that can be used for the lookups.
Levente
Also, we don't know yet how getting rid of compact classes would affect performance.
- Bert -
.
.
On a board's meeting, Chris mentioned my implementation, and he says that it outperforms the LargeIdentitySet. I'm not sure how Chris compared it, because i implemented this scheme only for dictionaries , not sets.
If you interested in details, you can check it in Magma. Brief description: i using a linked list for storing associations which keys having same hash value so, in addition to key/value pair there is next ivar. And dictionary's array entries look like this: ... ... ... e1 -> e2 -> e3 ... ...
where e1,e2,e3 is associations , which having same hash value, but different keys. So, when it doing lookup for a key, say e3, initially by doing hash lookup it finds e1, and then since #= for e1 answers false, it looks for the next linked association, until e3 is found.
If i remember, the last time i benched this implementation, it almost same in speed as an original implementation for small sizes, and outperforms on a large sizes, especially, when you got more than 4096 elements.
So, Chris, can you give us details how you compared the speed between LargeIdentitySet and my dictionaries? I don't think its correct to compare them, because dictionaries need to handle more data than sets, and we should expect some slowdown because of it. But sure, you can imitate the Set behavior with dicts, by simply ignoring the value field of association (set it to nil), and use only keys, i.e. set add: object is like: dict at: object put: nil.
On Wed, 24 Mar 2010, Igor Stasenko wrote:
On a board's meeting, Chris mentioned my implementation, and he says that it outperforms the LargeIdentitySet. I'm not sure how Chris compared it, because i implemented this scheme only for dictionaries , not sets.
It's really hard to believe that a dictionary can be faster than LargeIdentitySet (I even doubt that a set could be faster), so I'm waiting for the numbers.
As you pointed out it's unfair to compare sets to dictionaries, so I wrote LargeIdentityDictionary (http://leves.web.elte.hu/LargeIdentityDictionary/LargeIdentityDictionary.st ) which works just like LargeIdentitySet, but it also stores the values besides the keys. I modified Chris' benchmark just like you suggested: store nil as the value (http://leves.web.elte.hu/LargeIdentityDictionary/LargeIdentityDictionaryBenc... ). The benchmark compares LargeIdentityDictionary to IdentityDictionary. It uses two diffent lookup methods (#at: and #includesKey:). I ran the benchmarks and copied the results to a single file (http://leves.web.elte.hu/LargeIdentityDictionary/LargeIdentityDictionaryBenc... ), but I'm sure the nice charts are more interesting, so here they are: http://leves.web.elte.hu/LargeIdentityDictionary/LargeIdentityDictionary.png http://leves.web.elte.hu/LargeIdentityDictionary/LargeIdentityDictionary2.pn...
The first chart shows that IdentityDictionary has a big spike at 970000, probably because of clustering (we need even better primes). So the second chart is the same as the first, but it only shows the 0-5000ms range. What we can see is #at: and #includesKey: have similar performance for IdentityDictionary (both use #scanFor:). LargeIdentityDictionary >> #at: is ~3.5-5x faster than IdentityDictionary >> #at:. And what's more interresing is that #includesKey: is so fast that it seems to be totally flat (though it's not). That's because #includesKey: can use the #pointsTo: primitive, but #at: can't, because it has to return the value for the key. So if a dictionary is faster than LargeIdentitySet, than it's graph has to be even flatter than #includesKey:'s graph (it's really hard to believe that such dictionary exists).
I wonder how LargeIdentityDictionary compares to your dictionaries'.
Levente
P.S. LargeIdentityDictionary is hardly tested and doesn't implement every "public" method that IdentityDictionary does.
If you interested in details, you can check it in Magma. Brief description: i using a linked list for storing associations which keys having same hash value so, in addition to key/value pair there is next ivar. And dictionary's array entries look like this: ... ... ... e1 -> e2 -> e3 ... ...
where e1,e2,e3 is associations , which having same hash value, but different keys. So, when it doing lookup for a key, say e3, initially by doing hash lookup it finds e1, and then since #= for e1 answers false, it looks for the next linked association, until e3 is found.
If i remember, the last time i benched this implementation, it almost same in speed as an original implementation for small sizes, and outperforms on a large sizes, especially, when you got more than 4096 elements.
So, Chris, can you give us details how you compared the speed between LargeIdentitySet and my dictionaries? I don't think its correct to compare them, because dictionaries need to handle more data than sets, and we should expect some slowdown because of it. But sure, you can imitate the Set behavior with dicts, by simply ignoring the value field of association (set it to nil), and use only keys, i.e. set add: object is like: dict at: object put: nil.
-- Best regards, Igor Stasenko AKA sig.
On 25 March 2010 00:26, Levente Uzonyi leves@elte.hu wrote:
On Wed, 24 Mar 2010, Igor Stasenko wrote:
On a board's meeting, Chris mentioned my implementation, and he says that it outperforms the LargeIdentitySet. I'm not sure how Chris compared it, because i implemented this scheme only for dictionaries , not sets.
It's really hard to believe that a dictionary can be faster than LargeIdentitySet (I even doubt that a set could be faster), so I'm waiting for the numbers.
As you pointed out it's unfair to compare sets to dictionaries, so I wrote LargeIdentityDictionary (http://leves.web.elte.hu/LargeIdentityDictionary/LargeIdentityDictionary.st ) which works just like LargeIdentitySet, but it also stores the values besides the keys. I modified Chris' benchmark just like you suggested: store nil as the value (http://leves.web.elte.hu/LargeIdentityDictionary/LargeIdentityDictionaryBenc... ). The benchmark compares LargeIdentityDictionary to IdentityDictionary. It uses two diffent lookup methods (#at: and #includesKey:). I ran the benchmarks and copied the results to a single file (http://leves.web.elte.hu/LargeIdentityDictionary/LargeIdentityDictionaryBenc... ), but I'm sure the nice charts are more interesting, so here they are: http://leves.web.elte.hu/LargeIdentityDictionary/LargeIdentityDictionary.png http://leves.web.elte.hu/LargeIdentityDictionary/LargeIdentityDictionary2.pn...
The first chart shows that IdentityDictionary has a big spike at 970000, probably because of clustering (we need even better primes). So the second chart is the same as the first, but it only shows the 0-5000ms range. What we can see is #at: and #includesKey: have similar performance for IdentityDictionary (both use #scanFor:). LargeIdentityDictionary >> #at: is ~3.5-5x faster than IdentityDictionary >> #at:. And what's more interresing is that #includesKey: is so fast that it seems to be totally flat (though it's not). That's because #includesKey: can use the #pointsTo: primitive, but #at: can't, because it has to return the value for the key. So if a dictionary is faster than LargeIdentitySet, than it's graph has to be even flatter than #includesKey:'s graph (it's really hard to believe that such dictionary exists).
i think that #pointsTo: is a cheat :), which you can use in Sets but not dictionaries, because it contains associations. Also, it works only for identity-based collections.
I wonder how LargeIdentityDictionary compares to your dictionaries'.
me too.
Levente
P.S. LargeIdentityDictionary is hardly tested and doesn't implement every "public" method that IdentityDictionary does.
If you interested in details, you can check it in Magma. Brief description: i using a linked list for storing associations which keys having same hash value so, in addition to key/value pair there is next ivar. And dictionary's array entries look like this: ... ... ... e1 -> e2 -> e3 ... ...
where e1,e2,e3 is associations , which having same hash value, but different keys. So, when it doing lookup for a key, say e3, initially by doing hash lookup it finds e1, and then since #= for e1 answers false, it looks for the next linked association, until e3 is found.
If i remember, the last time i benched this implementation, it almost same in speed as an original implementation for small sizes, and outperforms on a large sizes, especially, when you got more than 4096 elements.
So, Chris, can you give us details how you compared the speed between LargeIdentitySet and my dictionaries? I don't think its correct to compare them, because dictionaries need to handle more data than sets, and we should expect some slowdown because of it. But sure, you can imitate the Set behavior with dicts, by simply ignoring the value field of association (set it to nil), and use only keys, i.e. set add: object is like: dict at: object put: nil.
-- Best regards, Igor Stasenko AKA sig.
On Thu, 25 Mar 2010, Igor Stasenko wrote:
i think that #pointsTo: is a cheat :), which you can use in Sets but not dictionaries, because it contains associations. Also, it works only for identity-based collections.
Dictionaries don't have to use associations (for example MethodDictionary doesn't use them), that's why #pointsTo: works (MethodDictionary also uses it).
I wonder how LargeIdentityDictionary compares to your dictionaries'.
me too.
If you give me a pointer to the source code, I can run the benchmarks.
Levente
From the Magma or Magma Tester projects of squeaksource, load latest
versions of these packages (in this order):
Ma exception handling Ma base additions Ma special collections
sig's Dictionary's are under the "MaDictionary" hierarchy. Good luck, I think they're fantastic.. :)
- Chris
On Thu, Mar 25, 2010 at 3:27 AM, Levente Uzonyi leves@elte.hu wrote:
On Thu, 25 Mar 2010, Igor Stasenko wrote:
i think that #pointsTo: is a cheat :), which you can use in Sets but not dictionaries, because it contains associations. Also, it works only for identity-based collections.
Dictionaries don't have to use associations (for example MethodDictionary doesn't use them), that's why #pointsTo: works (MethodDictionary also uses it).
I wonder how LargeIdentityDictionary compares to your dictionaries'.
me too.
If you give me a pointer to the source code, I can run the benchmarks.
Levente
If lookups find the sought object in mostly one attempt, the primitive is overkill... most of the time, the real issue is the quality of the hash function.
On 3/25/10 1:27 , Levente Uzonyi wrote:
On Thu, 25 Mar 2010, Igor Stasenko wrote:
i think that #pointsTo: is a cheat :), which you can use in Sets but not dictionaries, because it contains associations. Also, it works only for identity-based collections.
Dictionaries don't have to use associations (for example MethodDictionary doesn't use them), that's why #pointsTo: works (MethodDictionary also uses it).
I wonder how LargeIdentityDictionary compares to your dictionaries'.
me too.
If you give me a pointer to the source code, I can run the benchmarks.
Levente
On Thu, 25 Mar 2010, Andres Valloud wrote:
If lookups find the sought object in mostly one attempt, the primitive is overkill... most of the time, the real issue is the quality of the hash function.
That's true, but this is not the case with the 4096 hash values.
Levente
On 3/25/10 1:27 , Levente Uzonyi wrote:
On Thu, 25 Mar 2010, Igor Stasenko wrote:
i think that #pointsTo: is a cheat :), which you can use in Sets but not dictionaries, because it contains associations. Also, it works only for identity-based collections.
Dictionaries don't have to use associations (for example MethodDictionary doesn't use them), that's why #pointsTo: works (MethodDictionary also uses it).
I wonder how LargeIdentityDictionary compares to your dictionaries'.
me too.
If you give me a pointer to the source code, I can run the benchmarks.
Levente
Right, so provide a better identityHash implementation in the image (e.g.: implement hash and then have identityHash call hash instead), and problem solved...
On 3/26/10 3:37 , Levente Uzonyi wrote:
On Thu, 25 Mar 2010, Andres Valloud wrote:
If lookups find the sought object in mostly one attempt, the primitive is overkill... most of the time, the real issue is the quality of the hash function.
That's true, but this is not the case with the 4096 hash values.
Levente
On 3/25/10 1:27 , Levente Uzonyi wrote:
On Thu, 25 Mar 2010, Igor Stasenko wrote:
i think that #pointsTo: is a cheat :), which you can use in Sets but not dictionaries, because it contains associations. Also, it works only for identity-based collections.
Dictionaries don't have to use associations (for example MethodDictionary doesn't use them), that's why #pointsTo: works (MethodDictionary also uses it).
I wonder how LargeIdentityDictionary compares to your dictionaries'.
me too.
If you give me a pointer to the source code, I can run the benchmarks.
Levente

On 3/30/2010 1:09 AM, Andres Valloud wrote:
Right, so provide a better identityHash implementation in the image (e.g.: implement hash and then have identityHash call hash instead), and problem solved...
Except that #hash is not constant over the lifetime of most objects but #identityHash is. So if you have a property associated with an object in a IDDict and the #hash depends on a value of a variable it may change over the lifetime of the object and your key gets invalid.
Cheers, - Andreas
On 3/26/10 3:37 , Levente Uzonyi wrote:
On Thu, 25 Mar 2010, Andres Valloud wrote:
If lookups find the sought object in mostly one attempt, the primitive is overkill... most of the time, the real issue is the quality of the hash function.
That's true, but this is not the case with the 4096 hash values.
Levente
On 3/25/10 1:27 , Levente Uzonyi wrote:
On Thu, 25 Mar 2010, Igor Stasenko wrote:
i think that #pointsTo: is a cheat :), which you can use in Sets but not dictionaries, because it contains associations. Also, it works only for identity-based collections.
Dictionaries don't have to use associations (for example MethodDictionary doesn't use them), that's why #pointsTo: works (MethodDictionary also uses it).
I wonder how LargeIdentityDictionary compares to your dictionaries'.
me too.
If you give me a pointer to the source code, I can run the benchmarks.
Levente
I mentioned implementing identityHash as hash as an example given. I also think I mentioned the rule x == y => x identityHash = y identityHash, so I hope it's clear that one shouldn't just blindly move ahead in these matters. The point is that nothing prevents anybody from adding an instance variable called identityHash to their objects, storing arbitrary (but well chosen!) small integers in said instance variable, and then having the identityHash message just answer said values. If you do this for the cases in which you have significantly more than 4096 objects, then you only pay the price to hold better identityHash values for the objects that need them (as opposed to every single object in the image when the header is expanded instead). Or perhaps you don't really need identity for the cases being discussed in practice, and just using hash as identityHash is fine. It's hard to tell without concrete examples. One way or the other, I do not think the size of the identityHash field *must* result in poor hashed collection performance. Such an implication does not follow.
On 3/30/10 1:48 , Andreas Raab wrote:
On 3/30/2010 1:09 AM, Andres Valloud wrote:
Right, so provide a better identityHash implementation in the image (e.g.: implement hash and then have identityHash call hash instead), and problem solved...
Except that #hash is not constant over the lifetime of most objects but #identityHash is. So if you have a property associated with an object in a IDDict and the #hash depends on a value of a variable it may change over the lifetime of the object and your key gets invalid.
Cheers, - Andreas
On 3/26/10 3:37 , Levente Uzonyi wrote:
On Thu, 25 Mar 2010, Andres Valloud wrote:
If lookups find the sought object in mostly one attempt, the primitive is overkill... most of the time, the real issue is the quality of the hash function.
That's true, but this is not the case with the 4096 hash values.
Levente
On 3/25/10 1:27 , Levente Uzonyi wrote:
On Thu, 25 Mar 2010, Igor Stasenko wrote:
i think that #pointsTo: is a cheat :), which you can use in Sets but not dictionaries, because it contains associations. Also, it works only for identity-based collections.
Dictionaries don't have to use associations (for example MethodDictionary doesn't use them), that's why #pointsTo: works (MethodDictionary also uses it).
> I wonder how LargeIdentityDictionary compares to your dictionaries'. > > > me too.
If you give me a pointer to the source code, I can run the benchmarks.
Levente
On Tue, 30 Mar 2010, Andres Valloud wrote:
I mentioned implementing identityHash as hash as an example given. I also think I mentioned the rule x == y => x identityHash = y identityHash, so I hope it's clear that one shouldn't just blindly move ahead in these matters. The point is that nothing prevents anybody from adding an instance variable called identityHash to their objects, storing arbitrary (but well chosen!) small integers in said instance variable, and then having the identityHash message just answer said values. If you do this for the cases in which you have significantly more than 4096 objects, then you only pay the price to hold better identityHash values for the objects that need them (as opposed to every single object in the image when the header is expanded instead). Or perhaps you don't really need identity for the cases being discussed in practice, and just using hash as identityHash is fine. It's hard to tell without concrete examples. One way or the other, I do not think the size of the identityHash field *must* result in poor hashed collection performance. Such an implication does not follow.
The original problem is: pick 1000000 or more objects and associate an id to them. - Using #hash and #== doesn't work help, because the objects state may change. - Adding a slot to every object can't be done, because the class of the objects can be anything. Adding a slot to Object would break lots of code. - Using #largeHash (12 bits from the object + 12 bits from the object's class) doesn't help, because there may be only a few different classes.
Levente
On 3/30/10 1:48 , Andreas Raab wrote:
On 3/30/2010 1:09 AM, Andres Valloud wrote:
Right, so provide a better identityHash implementation in the image (e.g.: implement hash and then have identityHash call hash instead), and problem solved...
Except that #hash is not constant over the lifetime of most objects but #identityHash is. So if you have a property associated with an object in a IDDict and the #hash depends on a value of a variable it may change over the lifetime of the object and your key gets invalid.
Cheers, - Andreas
On 3/26/10 3:37 , Levente Uzonyi wrote:
On Thu, 25 Mar 2010, Andres Valloud wrote:
If lookups find the sought object in mostly one attempt, the primitive is overkill... most of the time, the real issue is the quality of the hash function.
That's true, but this is not the case with the 4096 hash values.
Levente
On 3/25/10 1:27 , Levente Uzonyi wrote:
On Thu, 25 Mar 2010, Igor Stasenko wrote:
> i think that #pointsTo: is a cheat :), which you can use in Sets but > not dictionaries, because > it contains associations. Also, it works only for identity-based > collections. > > Dictionaries don't have to use associations (for example MethodDictionary doesn't use them), that's why #pointsTo: works (MethodDictionary also uses it).
>> I wonder how LargeIdentityDictionary compares to your dictionaries'. >> >> >> > me too. > > If you give me a pointer to the source code, I can run the benchmarks.
Levente
What is the purpose of adding an id to so many objects? Is this a real application problem? Can you be more specific as to the context?
On 3/30/10 9:21 , Levente Uzonyi wrote:
On Tue, 30 Mar 2010, Andres Valloud wrote:
I mentioned implementing identityHash as hash as an example given. I also think I mentioned the rule x == y => x identityHash = y identityHash, so I hope it's clear that one shouldn't just blindly move ahead in these matters. The point is that nothing prevents anybody from adding an instance variable called identityHash to their objects, storing arbitrary (but well chosen!) small integers in said instance variable, and then having the identityHash message just answer said values. If you do this for the cases in which you have significantly more than 4096 objects, then you only pay the price to hold better identityHash values for the objects that need them (as opposed to every single object in the image when the header is expanded instead). Or perhaps you don't really need identity for the cases being discussed in practice, and just using hash as identityHash is fine. It's hard to tell without concrete examples. One way or the other, I do not think the size of the identityHash field *must* result in poor hashed collection performance. Such an implication does not follow.
The original problem is: pick 1000000 or more objects and associate an id to them.
- Using #hash and #== doesn't work help, because the objects state may
change.
- Adding a slot to every object can't be done, because the class of the
objects can be anything. Adding a slot to Object would break lots of code.
- Using #largeHash (12 bits from the object + 12 bits from the object's
class) doesn't help, because there may be only a few different classes.
Levente
On 3/30/10 1:48 , Andreas Raab wrote:
On 3/30/2010 1:09 AM, Andres Valloud wrote:
Right, so provide a better identityHash implementation in the image (e.g.: implement hash and then have identityHash call hash instead), and problem solved...
Except that #hash is not constant over the lifetime of most objects but #identityHash is. So if you have a property associated with an object in a IDDict and the #hash depends on a value of a variable it may change over the lifetime of the object and your key gets invalid.
Cheers, - Andreas
On 3/26/10 3:37 , Levente Uzonyi wrote:
On Thu, 25 Mar 2010, Andres Valloud wrote:
If lookups find the sought object in mostly one attempt, the primitive is overkill... most of the time, the real issue is the quality of the hash function.
That's true, but this is not the case with the 4096 hash values.
Levente
On 3/25/10 1:27 , Levente Uzonyi wrote:
> On Thu, 25 Mar 2010, Igor Stasenko wrote: > > > > >> i think that #pointsTo: is a cheat :), which you can use in Sets but >> not dictionaries, because >> it contains associations. Also, it works only for identity-based >> collections. >> >> >> > Dictionaries don't have to use associations (for example > MethodDictionary > doesn't use them), that's why #pointsTo: works (MethodDictionary also > uses it). > > > > >>> I wonder how LargeIdentityDictionary compares to your dictionaries'. >>> >>> >>> >>> >> me too. >> >> >> > If you give me a pointer to the source code, I can run the benchmarks. > > > Levente > > > > >
.
On Tue, 30 Mar 2010, Andres Valloud wrote:
What is the purpose of adding an id to so many objects? Is this a real application problem? Can you be more specific as to the context?
AFAIK Magma uses it to assign unique ids to objects.
Levente
On 3/30/10 9:21 , Levente Uzonyi wrote:
On Tue, 30 Mar 2010, Andres Valloud wrote:
I mentioned implementing identityHash as hash as an example given. I also think I mentioned the rule x == y => x identityHash = y identityHash, so I hope it's clear that one shouldn't just blindly move ahead in these matters. The point is that nothing prevents anybody from adding an instance variable called identityHash to their objects, storing arbitrary (but well chosen!) small integers in said instance variable, and then having the identityHash message just answer said values. If you do this for the cases in which you have significantly more than 4096 objects, then you only pay the price to hold better identityHash values for the objects that need them (as opposed to every single object in the image when the header is expanded instead). Or perhaps you don't really need identity for the cases being discussed in practice, and just using hash as identityHash is fine. It's hard to tell without concrete examples. One way or the other, I do not think the size of the identityHash field *must* result in poor hashed collection performance. Such an implication does not follow.
The original problem is: pick 1000000 or more objects and associate an id to them.
- Using #hash and #== doesn't work help, because the objects state may
change.
- Adding a slot to every object can't be done, because the class of the
objects can be anything. Adding a slot to Object would break lots of code.
- Using #largeHash (12 bits from the object + 12 bits from the object's
class) doesn't help, because there may be only a few different classes.
Levente
On 3/30/10 1:48 , Andreas Raab wrote:
On 3/30/2010 1:09 AM, Andres Valloud wrote:
Right, so provide a better identityHash implementation in the image (e.g.: implement hash and then have identityHash call hash instead), and problem solved...
Except that #hash is not constant over the lifetime of most objects but #identityHash is. So if you have a property associated with an object in a IDDict and the #hash depends on a value of a variable it may change over the lifetime of the object and your key gets invalid.
Cheers, - Andreas
On 3/26/10 3:37 , Levente Uzonyi wrote:
On Thu, 25 Mar 2010, Andres Valloud wrote:
> If lookups find the sought object in mostly one attempt, the > primitive is > overkill... most of the time, the real issue is the quality of the > hash > function. > > That's true, but this is not the case with the 4096 hash values.
Levente
> On 3/25/10 1:27 , Levente Uzonyi wrote: > > >> On Thu, 25 Mar 2010, Igor Stasenko wrote: >> >> >> >> >>> i think that #pointsTo: is a cheat :), which you can use in Sets but >>> not dictionaries, because >>> it contains associations. Also, it works only for identity-based >>> collections. >>> >>> >>> >> Dictionaries don't have to use associations (for example >> MethodDictionary >> doesn't use them), that's why #pointsTo: works (MethodDictionary also >> uses it). >> >> >> >> >>>> I wonder how LargeIdentityDictionary compares to your >>>> dictionaries'. >>>> >>>> >>>> >>>> >>> me too. >>> >>> >>> >> If you give me a pointer to the source code, I can run the >> benchmarks. >> >> >> Levente >> >> >> >> >> >
.
IME, relational database mappings typically restrict the classes of mapped objects to some hierarchy of classes. The top of the hierarchy adds an instance variable such as id, which typically holds values from the primary key of the table in question. Please excuse my ignorance, but is this how Magma works? If not, how does it do things?
On 3/30/10 17:55 , Levente Uzonyi wrote:
On Tue, 30 Mar 2010, Andres Valloud wrote:
What is the purpose of adding an id to so many objects? Is this a real application problem? Can you be more specific as to the context?
AFAIK Magma uses it to assign unique ids to objects.
Levente
On 3/30/10 9:21 , Levente Uzonyi wrote:
On Tue, 30 Mar 2010, Andres Valloud wrote:
I mentioned implementing identityHash as hash as an example given. I also think I mentioned the rule x == y => x identityHash = y identityHash, so I hope it's clear that one shouldn't just blindly move ahead in these matters. The point is that nothing prevents anybody from adding an instance variable called identityHash to their objects, storing arbitrary (but well chosen!) small integers in said instance variable, and then having the identityHash message just answer said values. If you do this for the cases in which you have significantly more than 4096 objects, then you only pay the price to hold better identityHash values for the objects that need them (as opposed to every single object in the image when the header is expanded instead). Or perhaps you don't really need identity for the cases being discussed in practice, and just using hash as identityHash is fine. It's hard to tell without concrete examples. One way or the other, I do not think the size of the identityHash field *must* result in poor hashed collection performance. Such an implication does not follow.
The original problem is: pick 1000000 or more objects and associate an id to them.
- Using #hash and #== doesn't work help, because the objects state may
change.
- Adding a slot to every object can't be done, because the class of the
objects can be anything. Adding a slot to Object would break lots of code.
- Using #largeHash (12 bits from the object + 12 bits from the object's
class) doesn't help, because there may be only a few different classes.
Levente
On 3/30/10 1:48 , Andreas Raab wrote:
On 3/30/2010 1:09 AM, Andres Valloud wrote:
Right, so provide a better identityHash implementation in the image (e.g.: implement hash and then have identityHash call hash instead), and problem solved...
Except that #hash is not constant over the lifetime of most objects but #identityHash is. So if you have a property associated with an object in a IDDict and the #hash depends on a value of a variable it may change over the lifetime of the object and your key gets invalid.
Cheers, - Andreas
On 3/26/10 3:37 , Levente Uzonyi wrote:
> On Thu, 25 Mar 2010, Andres Valloud wrote: > > > > >> If lookups find the sought object in mostly one attempt, the >> primitive is >> overkill... most of the time, the real issue is the quality of the >> hash >> function. >> >> >> > That's true, but this is not the case with the 4096 hash values. > > > Levente > > > > >> On 3/25/10 1:27 , Levente Uzonyi wrote: >> >> >> >>> On Thu, 25 Mar 2010, Igor Stasenko wrote: >>> >>> >>> >>> >>> >>>> i think that #pointsTo: is a cheat :), which you can use in Sets but >>>> not dictionaries, because >>>> it contains associations. Also, it works only for identity-based >>>> collections. >>>> >>>> >>>> >>>> >>> Dictionaries don't have to use associations (for example >>> MethodDictionary >>> doesn't use them), that's why #pointsTo: works (MethodDictionary also >>> uses it). >>> >>> >>> >>> >>> >>>>> I wonder how LargeIdentityDictionary compares to your >>>>> dictionaries'. >>>>> >>>>> >>>>> >>>>> >>>>> >>>> me too. >>>> >>>> >>>> >>>> >>> If you give me a pointer to the source code, I can run the >>> benchmarks. >>> >>> >>> Levente >>> >>> >>> >>> >>> >>> >> >
.
.
On Tue, 30 Mar 2010, Andres Valloud wrote:
IME, relational database mappings typically restrict the classes of mapped objects to some hierarchy of classes. The top of the hierarchy adds an instance variable such as id, which typically holds values from the primary key of the table in question. Please excuse my ignorance, but is this how Magma works? If not, how does it do things?
No, Magma is an OODB, not an ORM and you can store any object in the database (including instances of Object).
Levente
On 3/30/10 17:55 , Levente Uzonyi wrote:
On Tue, 30 Mar 2010, Andres Valloud wrote:
What is the purpose of adding an id to so many objects? Is this a real application problem? Can you be more specific as to the context?
AFAIK Magma uses it to assign unique ids to objects.
Levente
On 3/30/10 9:21 , Levente Uzonyi wrote:
On Tue, 30 Mar 2010, Andres Valloud wrote:
I mentioned implementing identityHash as hash as an example given. I also think I mentioned the rule x == y => x identityHash = y identityHash, so I hope it's clear that one shouldn't just blindly move ahead in these matters. The point is that nothing prevents anybody from adding an instance variable called identityHash to their objects, storing arbitrary (but well chosen!) small integers in said instance variable, and then having the identityHash message just answer said values. If you do this for the cases in which you have significantly more than 4096 objects, then you only pay the price to hold better identityHash values for the objects that need them (as opposed to every single object in the image when the header is expanded instead). Or perhaps you don't really need identity for the cases being discussed in practice, and just using hash as identityHash is fine. It's hard to tell without concrete examples. One way or the other, I do not think the size of the identityHash field *must* result in poor hashed collection performance. Such an implication does not follow.
The original problem is: pick 1000000 or more objects and associate an id to them.
- Using #hash and #== doesn't work help, because the objects state may
change.
- Adding a slot to every object can't be done, because the class of the
objects can be anything. Adding a slot to Object would break lots of code.
- Using #largeHash (12 bits from the object + 12 bits from the object's
class) doesn't help, because there may be only a few different classes.
Levente
On 3/30/10 1:48 , Andreas Raab wrote:
On 3/30/2010 1:09 AM, Andres Valloud wrote:
> Right, so provide a better identityHash implementation in the image > (e.g.: implement hash and then have identityHash call hash instead), > and > problem solved... > > > Except that #hash is not constant over the lifetime of most objects but #identityHash is. So if you have a property associated with an object in a IDDict and the #hash depends on a value of a variable it may change over the lifetime of the object and your key gets invalid.
Cheers, - Andreas
> On 3/26/10 3:37 , Levente Uzonyi wrote: > > > >> On Thu, 25 Mar 2010, Andres Valloud wrote: >> >> >> >> >>> If lookups find the sought object in mostly one attempt, the >>> primitive is >>> overkill... most of the time, the real issue is the quality of the >>> hash >>> function. >>> >>> >>> >> That's true, but this is not the case with the 4096 hash values. >> >> >> Levente >> >> >> >> >>> On 3/25/10 1:27 , Levente Uzonyi wrote: >>> >>> >>> >>>> On Thu, 25 Mar 2010, Igor Stasenko wrote: >>>> >>>> >>>> >>>> >>>> >>>>> i think that #pointsTo: is a cheat :), which you can use in Sets >>>>> but >>>>> not dictionaries, because >>>>> it contains associations. Also, it works only for identity-based >>>>> collections. >>>>> >>>>> >>>>> >>>>> >>>> Dictionaries don't have to use associations (for example >>>> MethodDictionary >>>> doesn't use them), that's why #pointsTo: works (MethodDictionary >>>> also >>>> uses it). >>>> >>>> >>>> >>>> >>>> >>>>>> I wonder how LargeIdentityDictionary compares to your >>>>>> dictionaries'. >>>>>> >>>>>> >>>>>> >>>>>> >>>>>> >>>>> me too. >>>>> >>>>> >>>>> >>>>> >>>> If you give me a pointer to the source code, I can run the >>>> benchmarks. >>>> >>>> >>>> Levente >>>> >>>> >>>> >>>> >>>> >>>> >>> >> > >
.
.
Ah, yes, 4096 identityHash values are not too many for that kind of use. GemStone runs into similar problems, and IIRC they use hash buckets keyed by identityHash value (VisualWorks, 32 bits, 16383 possible hash values, 16383 hash buckets). However, Martin noted that if the identityHash values are enlarged to 20 bits, then the hash buckets take too much space and the approach becomes counterproductive. I don't have all the details of what happened after that, and in any case it would be best for Martin to answer questions about alternative approaches in this particular case.
Regarding the identityHash for 32 bit Squeak, has the field been enlarged for 64 bits? If so, one should consider whether the trauma (and introduced image / VM incompatibility) for 32 bit Squeak is worth the potential benefits when compared to other benefits that may be obtained with a similar amount of effort. Also, I don't know what does the object header structure look like in Squeak, and it may or may not be a good idea to enlarge it merely to hold more identityHash values because larger headers will result in larger images and potentially slower execution. These unintended consequences should be accounted for.
On 3/30/10 18:44 , Levente Uzonyi wrote:
On Tue, 30 Mar 2010, Andres Valloud wrote:
IME, relational database mappings typically restrict the classes of mapped objects to some hierarchy of classes. The top of the hierarchy adds an instance variable such as id, which typically holds values from the primary key of the table in question. Please excuse my ignorance, but is this how Magma works? If not, how does it do things?
No, Magma is an OODB, not an ORM and you can store any object in the database (including instances of Object).
Levente
On 3/30/10 17:55 , Levente Uzonyi wrote:
On Tue, 30 Mar 2010, Andres Valloud wrote:
What is the purpose of adding an id to so many objects? Is this a real application problem? Can you be more specific as to the context?
AFAIK Magma uses it to assign unique ids to objects.
Levente
On 3/30/10 9:21 , Levente Uzonyi wrote:
On Tue, 30 Mar 2010, Andres Valloud wrote:
I mentioned implementing identityHash as hash as an example given. I also think I mentioned the rule x == y => x identityHash = y identityHash, so I hope it's clear that one shouldn't just blindly move ahead in these matters. The point is that nothing prevents anybody from adding an instance variable called identityHash to their objects, storing arbitrary (but well chosen!) small integers in said instance variable, and then having the identityHash message just answer said values. If you do this for the cases in which you have significantly more than 4096 objects, then you only pay the price to hold better identityHash values for the objects that need them (as opposed to every single object in the image when the header is expanded instead). Or perhaps you don't really need identity for the cases being discussed in practice, and just using hash as identityHash is fine. It's hard to tell without concrete examples. One way or the other, I do not think the size of the identityHash field *must* result in poor hashed collection performance. Such an implication does not follow.
The original problem is: pick 1000000 or more objects and associate an id to them.
- Using #hash and #== doesn't work help, because the objects state may
change.
- Adding a slot to every object can't be done, because the class of the
objects can be anything. Adding a slot to Object would break lots of code.
- Using #largeHash (12 bits from the object + 12 bits from the object's
class) doesn't help, because there may be only a few different classes.
Levente
On 3/30/10 1:48 , Andreas Raab wrote:
> On 3/30/2010 1:09 AM, Andres Valloud wrote: > > > > >> Right, so provide a better identityHash implementation in the image >> (e.g.: implement hash and then have identityHash call hash instead), >> and >> problem solved... >> >> >> >> > Except that #hash is not constant over the lifetime of most objects but > #identityHash is. So if you have a property associated with an object > in > a IDDict and the #hash depends on a value of a variable it may change > over the lifetime of the object and your key gets invalid. > > Cheers, > - Andreas > > > > > >> On 3/26/10 3:37 , Levente Uzonyi wrote: >> >> >> >> >>> On Thu, 25 Mar 2010, Andres Valloud wrote: >>> >>> >>> >>> >>> >>>> If lookups find the sought object in mostly one attempt, the >>>> primitive is >>>> overkill... most of the time, the real issue is the quality of the >>>> hash >>>> function. >>>> >>>> >>>> >>>> >>> That's true, but this is not the case with the 4096 hash values. >>> >>> >>> Levente >>> >>> >>> >>> >>> >>>> On 3/25/10 1:27 , Levente Uzonyi wrote: >>>> >>>> >>>> >>>> >>>>> On Thu, 25 Mar 2010, Igor Stasenko wrote: >>>>> >>>>> >>>>> >>>>> >>>>> >>>>> >>>>>> i think that #pointsTo: is a cheat :), which you can use in Sets >>>>>> but >>>>>> not dictionaries, because >>>>>> it contains associations. Also, it works only for identity-based >>>>>> collections. >>>>>> >>>>>> >>>>>> >>>>>> >>>>>> >>>>> Dictionaries don't have to use associations (for example >>>>> MethodDictionary >>>>> doesn't use them), that's why #pointsTo: works (MethodDictionary >>>>> also >>>>> uses it). >>>>> >>>>> >>>>> >>>>> >>>>> >>>>> >>>>>>> I wonder how LargeIdentityDictionary compares to your >>>>>>> dictionaries'. >>>>>>> >>>>>>> >>>>>>> >>>>>>> >>>>>>> >>>>>>> >>>>>> me too. >>>>>> >>>>>> >>>>>> >>>>>> >>>>>> >>>>> If you give me a pointer to the source code, I can run the >>>>> benchmarks. >>>>> >>>>> >>>>> Levente >>>>> >>>>> >>>>> >>>>> >>>>> >>>>> >>>>> >>>> >>> >> >> > > >
.
.
.
Magma oids are allocated by the server, they're consecutive integers. identityHash has nothing to do with that.
Andre wrote:
The point is that nothing prevents anybody from adding an instance variable called identityHash to their objects, storing arbitrary (but well chosen!) small integers in said instance variable, and then...
It has to be for any object; Morphs, Assocaitions, Sets, Strings, LargeIntegers, etc., not just my own application objects.
You make it sound easy; but the other thing to remember is the importance of doing it very *quickly*, because if #identityHash is long to initialize or calculate, then you lose speed that way.
So it seems we have a pretty good balanced solution; small object-header + relatively fast access..
On Tue, Mar 30, 2010 at 6:55 PM, Levente Uzonyi leves@elte.hu wrote:
On Tue, 30 Mar 2010, Andres Valloud wrote:
What is the purpose of adding an id to so many objects? Is this a real application problem? Can you be more specific as to the context?
AFAIK Magma uses it to assign unique ids to objects.
Levente
On 3/30/10 9:21 , Levente Uzonyi wrote:
On Tue, 30 Mar 2010, Andres Valloud wrote:
I mentioned implementing identityHash as hash as an example given. I also think I mentioned the rule x == y => x identityHash = y identityHash, so I hope it's clear that one shouldn't just blindly move ahead in these matters. The point is that nothing prevents anybody from adding an instance variable called identityHash to their objects, storing arbitrary (but well chosen!) small integers in said instance variable, and then having the identityHash message just answer said values. If you do this for the cases in which you have significantly more than 4096 objects, then you only pay the price to hold better identityHash values for the objects that need them (as opposed to every single object in the image when the header is expanded instead). Or perhaps you don't really need identity for the cases being discussed in practice, and just using hash as identityHash is fine. It's hard to tell without concrete examples. One way or the other, I do not think the size of the identityHash field *must* result in poor hashed collection performance. Such an implication does not follow.
The original problem is: pick 1000000 or more objects and associate an id to them.
- Using #hash and #== doesn't work help, because the objects state may
change.
- Adding a slot to every object can't be done, because the class of the
objects can be anything. Adding a slot to Object would break lots of code.
- Using #largeHash (12 bits from the object + 12 bits from the object's
class) doesn't help, because there may be only a few different classes.
Levente
On 3/30/10 1:48 , Andreas Raab wrote:
On 3/30/2010 1:09 AM, Andres Valloud wrote:
Right, so provide a better identityHash implementation in the image (e.g.: implement hash and then have identityHash call hash instead), and problem solved...
Except that #hash is not constant over the lifetime of most objects but #identityHash is. So if you have a property associated with an object in a IDDict and the #hash depends on a value of a variable it may change over the lifetime of the object and your key gets invalid.
Cheers, - Andreas
On 3/26/10 3:37 , Levente Uzonyi wrote:
> On Thu, 25 Mar 2010, Andres Valloud wrote: > > > >> If lookups find the sought object in mostly one attempt, the >> primitive is >> overkill... most of the time, the real issue is the quality of the >> hash >> function. >> >> > That's true, but this is not the case with the 4096 hash values. > > > Levente > > > >> On 3/25/10 1:27 , Levente Uzonyi wrote: >> >> >>> On Thu, 25 Mar 2010, Igor Stasenko wrote: >>> >>> >>> >>> >>>> i think that #pointsTo: is a cheat :), which you can use in Sets >>>> but >>>> not dictionaries, because >>>> it contains associations. Also, it works only for identity-based >>>> collections. >>>> >>>> >>>> >>> Dictionaries don't have to use associations (for example >>> MethodDictionary >>> doesn't use them), that's why #pointsTo: works (MethodDictionary >>> also >>> uses it). >>> >>> >>> >>> >>>>> I wonder how LargeIdentityDictionary compares to your >>>>> dictionaries'. >>>>> >>>>> >>>>> >>>>> >>>> me too. >>>> >>>> >>>> >>> If you give me a pointer to the source code, I can run the >>> benchmarks. >>> >>> >>> Levente >>> >>> >>> >>> >>> >> >
.
At the time I wrote that, I was assuming that Magma was a relational database mapper. Sigh :(. In any case, now you have the same "problem" GemStone has.
On 4/1/10 10:26 , Chris Muller wrote:
Magma oids are allocated by the server, they're consecutive integers. identityHash has nothing to do with that.
Andre wrote:
The point is that nothing prevents anybody from adding an instance variable called identityHash to their objects, storing arbitrary (but well chosen!) small integers in said instance variable, and then...
It has to be for any object; Morphs, Assocaitions, Sets, Strings, LargeIntegers, etc., not just my own application objects.
You make it sound easy; but the other thing to remember is the importance of doing it very *quickly*, because if #identityHash is long to initialize or calculate, then you lose speed that way.
So it seems we have a pretty good balanced solution; small object-header + relatively fast access..
On Tue, Mar 30, 2010 at 6:55 PM, Levente Uzonyileves@elte.hu wrote:
On Tue, 30 Mar 2010, Andres Valloud wrote:
What is the purpose of adding an id to so many objects? Is this a real application problem? Can you be more specific as to the context?
AFAIK Magma uses it to assign unique ids to objects.
Levente
On 3/30/10 9:21 , Levente Uzonyi wrote:
On Tue, 30 Mar 2010, Andres Valloud wrote:
I mentioned implementing identityHash as hash as an example given. I also think I mentioned the rule x == y => x identityHash = y identityHash, so I hope it's clear that one shouldn't just blindly move ahead in these matters. The point is that nothing prevents anybody from adding an instance variable called identityHash to their objects, storing arbitrary (but well chosen!) small integers in said instance variable, and then having the identityHash message just answer said values. If you do this for the cases in which you have significantly more than 4096 objects, then you only pay the price to hold better identityHash values for the objects that need them (as opposed to every single object in the image when the header is expanded instead). Or perhaps you don't really need identity for the cases being discussed in practice, and just using hash as identityHash is fine. It's hard to tell without concrete examples. One way or the other, I do not think the size of the identityHash field *must* result in poor hashed collection performance. Such an implication does not follow.
The original problem is: pick 1000000 or more objects and associate an id to them.
- Using #hash and #== doesn't work help, because the objects state may
change.
- Adding a slot to every object can't be done, because the class of the
objects can be anything. Adding a slot to Object would break lots of code.
- Using #largeHash (12 bits from the object + 12 bits from the object's
class) doesn't help, because there may be only a few different classes.
Levente
On 3/30/10 1:48 , Andreas Raab wrote:
On 3/30/2010 1:09 AM, Andres Valloud wrote:
> Right, so provide a better identityHash implementation in the image > (e.g.: implement hash and then have identityHash call hash instead), > and > problem solved... > > > Except that #hash is not constant over the lifetime of most objects but #identityHash is. So if you have a property associated with an object in a IDDict and the #hash depends on a value of a variable it may change over the lifetime of the object and your key gets invalid.
Cheers, - Andreas
> On 3/26/10 3:37 , Levente Uzonyi wrote: > > > >> On Thu, 25 Mar 2010, Andres Valloud wrote: >> >> >> >> >>> If lookups find the sought object in mostly one attempt, the >>> primitive is >>> overkill... most of the time, the real issue is the quality of the >>> hash >>> function. >>> >>> >>> >> That's true, but this is not the case with the 4096 hash values. >> >> >> Levente >> >> >> >> >>> On 3/25/10 1:27 , Levente Uzonyi wrote: >>> >>> >>> >>>> On Thu, 25 Mar 2010, Igor Stasenko wrote: >>>> >>>> >>>> >>>> >>>> >>>>> i think that #pointsTo: is a cheat :), which you can use in Sets >>>>> but >>>>> not dictionaries, because >>>>> it contains associations. Also, it works only for identity-based >>>>> collections. >>>>> >>>>> >>>>> >>>>> >>>> Dictionaries don't have to use associations (for example >>>> MethodDictionary >>>> doesn't use them), that's why #pointsTo: works (MethodDictionary >>>> also >>>> uses it). >>>> >>>> >>>> >>>> >>>> >>>>>> I wonder how LargeIdentityDictionary compares to your >>>>>> dictionaries'. >>>>>> >>>>>> >>>>>> >>>>>> >>>>>> >>>>> me too. >>>>> >>>>> >>>>> >>>>> >>>> If you give me a pointer to the source code, I can run the >>>> benchmarks. >>>> >>>> >>>> Levente >>>> >>>> >>>> >>>> >>>> >>>> >>> >> > >
.

I don't know how to help with the choice of hash functions for different data domains, but assuming you can find a good function for your domain, there are much better ways to store the values than choosing a bucket based on the key modulo a prime. Take a look at Split-Order-List hash tables as an example. I'm a total Squeak noob, so this code probably has something to offend just about everyone's sensibilities :), but it does demonstrate the algorithm. It could be further improved by using Igor's approach to key collisions (equal keys get a sublist of their own, which keeps them out of the way of searches for other keys), but it is probably much better for the code to be "polished" by better Squeakers than myself :).
This doesn't do anything to solve the hash function problem, but it does let you stop looking for primes...
I also have no idea how to put this on SqueakMap or SqueakSource, or even which one to put it on, so I've attached it here. (I'd be happy for pointers on "best practice".)
I've used the Objective-C version of this with a load factor of 6 to store English text: 188743 input words, 167752 duplicates, 20991 retained, elapsed time 0.391754 seconds. bucket size histogram, 4050 buckets, 20991 elements: value: count 0: 15 1: 106 2: 311 3: 505 4: 684 5: 737 6: 638 7: 444 8: 297 9: 185 10: 77 11: 36 12: 12 13: 2 14: 1
-- Tom Rushworth
Hi All,
Just so that there is a record in the mail archive of where this went to, I've created a project for this code at:
http://www.squeaksource.com/SOLHashTable.html
and saved a version with one more round of refactoring/development.
The class comments in the code contain a reference to the paper which describes the algorithm.
I'm still interested in feedback if anyone cares to offer it, or wants commit access to the project.
On 2010-Apr-4, at 17:57, Tom Rushworth wrote:
I don't know how to help with the choice of hash functions....
[snip]
Regards,
-- Tom Rushworth
On 25 March 2010 10:27, Levente Uzonyi leves@elte.hu wrote:
On Thu, 25 Mar 2010, Igor Stasenko wrote:
i think that #pointsTo: is a cheat :), which you can use in Sets but not dictionaries, because it contains associations. Also, it works only for identity-based collections.
Dictionaries don't have to use associations (for example MethodDictionary doesn't use them), that's why #pointsTo: works (MethodDictionary also uses it).
But that means a linear scan of the whole collection, even if done primitively, this is not scalable.
I wonder how LargeIdentityDictionary compares to your dictionaries'.
me too.
If you give me a pointer to the source code, I can run the benchmarks.
Levente
On Fri, 26 Mar 2010, Igor Stasenko wrote:
On 25 March 2010 10:27, Levente Uzonyi leves@elte.hu wrote:
On Thu, 25 Mar 2010, Igor Stasenko wrote:
i think that #pointsTo: is a cheat :), which you can use in Sets but not dictionaries, because it contains associations. Also, it works only for identity-based collections.
Dictionaries don't have to use associations (for example MethodDictionary doesn't use them), that's why #pointsTo: works (MethodDictionary also uses it).
But that means a linear scan of the whole collection, even if done primitively, this is not scalable.
If you mean that MethodDictionaries implementation of #includesKey: doesn't scale, then you're right. But it doesn't have to scale at all. The average size of the MethodDictionaries in my image is ~11.1, the average capacity is ~17.2. For these dictionaries #includesKey: is >3x faster than the following (which is 30% faster than Dictionary >> #includesKey:):
^aSymbol ifNil: [ false ] ifNotNil: [ (array at: (self scanFor: aSymbol)) ~~ nil ]
The largest MethodDictionary contains 1176 keys in my image and the primitive is only 20% slower for that than the non-primitive method. The second largest has 610 entries and the primitive method is still 37% faster for that than the non-primitive version.
In LargeIdentityDictionary/LargeIdentitySet #pointsTo: does the same job as the list scanning loop in MaIdentityDictionary/MaIdentitySet, and #pointsTo: is faster than that.
Levente
I wonder how LargeIdentityDictionary compares to your dictionaries'.
me too.
If you give me a pointer to the source code, I can run the benchmarks.
Levente
-- Best regards, Igor Stasenko AKA sig.
Dictionaries don't have to use associations (for example MethodDictionary doesn't use them), that's why #pointsTo: works (MethodDictionary also uses it).
But that means a linear scan of the whole collection, even if done primitively, this is not scalable.
Not necessarily. VisualAge had a LookupTable class that was identical to Dictionary except it used two parallel Array's (keys / values) rather than Association objects instaniated by its Dictionary. LookupTable was faster..
On Sat, 27 Mar 2010, Chris Muller wrote:
Dictionaries don't have to use associations (for example MethodDictionary doesn't use them), that's why #pointsTo: works (MethodDictionary also uses it).
But that means a linear scan of the whole collection, even if done primitively, this is not scalable.
Not necessarily. VisualAge had a LookupTable class that was identical to Dictionary except it used two parallel Array's (keys / values) rather than Association objects instaniated by its Dictionary. LookupTable was faster..
Linear search is not scalable in the way MethodDictionary uses it, but that doesn't have to scale at all. MethodDictionaries rarely grow large and #pointsTo: is faster if the capacity of the dictinary is less than 1024 (that covers all but one MethodDictionary in my image).
LookupTable is totally unrelated to this issue. It's just an association-free dictionary implementation, but it still uses open addressing so it doesn't solve the issue with Squeak's identityHash.
It's easier to fight the issue of few keys and lots of objects with separate-chaining. Igor's sets/dictionaries use a linked list of associations for that, while my implementations uses arrays and no associations.
Using no associations and (separate key-value) arrays has several advantages over the list of associations: - smaller memory footprint because of less objects (this means that it's more cache-friendly) - better cache locality, because pointers to keys with the same hash use adjacent memory slots (this means that it's much more cache-friendly) - #pointsTo: can be used with IdentityDictionaries which is much faster than a linear search implemented with a fully optimized loop.
This all means that LargeIdentityDictionary is 3.7x faster than MaIdentityDictionary for #at:ifAbsent: and 40x faster for #includesKey: when reaching 1000000 elements in the benchmark below, while MaIdentityDictionary is only 30-40% faster than IdentityDictionary (if you don't run into a really bad clustering. With better primes the chance of that may be even lower, and with an extra check for clustering that may be totally avoided).
Of course the above numbers are only true if the #notNil send is replaced with == nil in MaIdentityDictionary >> #at:ifAbsent: otherwise it's a bit worse (MaIdentityDictionary is only 20% faster than IdentityDictionary).
The benchmark (requires the latest trunk image):
objects := Array new: 1000000 streamContents: [ :stream | 1 to: 1000000 do: [ :i | stream nextPut: Object new ] ]. objects shuffleBy: (Random seed: 36rSQUEAK). "Could be anything, since the hashes are random." results := { LargeIdentityDictionary. MaIdentityDictionary. IdentityDictionary } collect: [ :dictionaryClass | | objectSource | objectSource := objects readStream. dictionaryClass -> (Array streamContents: [ :results | | dictionary newObjects firstRun oldObjects | dictionary := dictionaryClass new. newObjects := Array new: 10000. oldObjects := nil. Smalltalk garbageCollect. [ dictionary size >= 1000000 ] whileFalse: [ 1 to: 10000 do: [ :index | dictionary at: (newObjects at: index put: objectSource next) put: nil ]. oldObjects ifNil: [ oldObjects := newObjects copy ]. results nextPut: { dictionary size. [ 1 to: 5 do: [ :run | 1 to: 10000 do: [ :index | dictionary includesKey: (oldObjects at: index) ] ]. 1 to: 5 do: [ :run | 1 to: 10000 do: [ :index | dictionary includesKey: (newObjects at: index) ] ] ] timeToRun. [ 1 to: 5 do: [ :run | 1 to: 10000 do: [ :index | dictionary at: (oldObjects at: index) ifAbsent: nil ] ]. 1 to: 5 do: [ :run | 1 to: 10000 do: [ :index | dictionary at: (newObjects at: index) ifAbsent: nil ] ] ] timeToRun } ] ]) ].
While reviewing MaDictionary and subclasses I found that #maxBuckets is wrong. It's okay for MaIdentityDictionary, but it won't allow an MaDictionary to have more than 4096 buckets.
Levente
On Sat, 27 Mar 2010, Chris Muller wrote:
While reviewing MaDictionary and subclasses I found that #maxBuckets is wrong. It's okay for MaIdentityDictionary, but it won't allow an MaDictionary to have more than 4096 buckets.
What would be a good maxBuckets for standard MaDictionary?
That shouldn't be limited, so SmallInteger maxVal.
Levente
On 28 March 2010 05:13, Chris Muller asqueaker@gmail.com wrote:
While reviewing MaDictionary and subclasses I found that #maxBuckets is wrong. It's okay for MaIdentityDictionary, but it won't allow an MaDictionary to have more than 4096 buckets.
What would be a good maxBuckets for standard MaDictionary?
yeah. that's probably would be fine. I focused mainly on an identity dicts implementation, and therefore took 4096 constant, because its using identity hash.
Igor, with high quality hash functions, full linear scans of the whole collection hardly ever happen, if at all...
On 3/26/10 6:14 , Igor Stasenko wrote:
On 25 March 2010 10:27, Levente Uzonyileves@elte.hu wrote:
On Thu, 25 Mar 2010, Igor Stasenko wrote:
i think that #pointsTo: is a cheat :), which you can use in Sets but not dictionaries, because it contains associations. Also, it works only for identity-based collections.
Dictionaries don't have to use associations (for example MethodDictionary doesn't use them), that's why #pointsTo: works (MethodDictionary also uses it).
But that means a linear scan of the whole collection, even if done primitively, this is not scalable.
I wonder how LargeIdentityDictionary compares to your dictionaries'.
me too.
If you give me a pointer to the source code, I can run the benchmarks.
Levente
I have not tested LargeIdentitySet. Igor, I may have used the wrong words, but I *meant* to say that your Dictionary and Sets are the fastest I've tested and I'm testing switching my software to use them everywhere, not just a few places in Magma.
I have not tested LargeIdentitySet because Levente said LargeIdentitySet may have bugs and I like the family of collections provided by your solution anyway, I need them.
- Chris
On Wed, Mar 24, 2010 at 2:36 PM, Igor Stasenko siguctua@gmail.com wrote:
On a board's meeting, Chris mentioned my implementation, and he says that it outperforms the LargeIdentitySet. I'm not sure how Chris compared it, because i implemented this scheme only for dictionaries , not sets.
If you interested in details, you can check it in Magma. Brief description: i using a linked list for storing associations which keys having same hash value so, in addition to key/value pair there is next ivar. And dictionary's array entries look like this: ... ... ... e1 -> e2 -> e3 ... ...
where e1,e2,e3 is associations , which having same hash value, but different keys. So, when it doing lookup for a key, say e3, initially by doing hash lookup it finds e1, and then since #= for e1 answers false, it looks for the next linked association, until e3 is found.
If i remember, the last time i benched this implementation, it almost same in speed as an original implementation for small sizes, and outperforms on a large sizes, especially, when you got more than 4096 elements.
So, Chris, can you give us details how you compared the speed between LargeIdentitySet and my dictionaries? I don't think its correct to compare them, because dictionaries need to handle more data than sets, and we should expect some slowdown because of it. But sure, you can imitate the Set behavior with dicts, by simply ignoring the value field of association (set it to nil), and use only keys, i.e. set add: object is like: dict at: object put: nil.
-- Best regards, Igor Stasenko AKA sig.
Typically, linked lists are better when the hash function is not of very high quality. However, when the hash function is good, open addressing linear probing will beat everything else.
On 3/24/10 12:36 , Igor Stasenko wrote:
On a board's meeting, Chris mentioned my implementation, and he says that it outperforms the LargeIdentitySet. I'm not sure how Chris compared it, because i implemented this scheme only for dictionaries , not sets.
If you interested in details, you can check it in Magma. Brief description: i using a linked list for storing associations which keys having same hash value so, in addition to key/value pair there is next ivar. And dictionary's array entries look like this: ... ... ... e1 -> e2 -> e3 ... ...
where e1,e2,e3 is associations , which having same hash value, but different keys. So, when it doing lookup for a key, say e3, initially by doing hash lookup it finds e1, and then since #= for e1 answers false, it looks for the next linked association, until e3 is found.
If i remember, the last time i benched this implementation, it almost same in speed as an original implementation for small sizes, and outperforms on a large sizes, especially, when you got more than 4096 elements.
So, Chris, can you give us details how you compared the speed between LargeIdentitySet and my dictionaries? I don't think its correct to compare them, because dictionaries need to handle more data than sets, and we should expect some slowdown because of it. But sure, you can imitate the Set behavior with dicts, by simply ignoring the value field of association (set it to nil), and use only keys, i.e. set add: object is like: dict at: object put: nil.
So the problem is that the objects are not implementing hash/identityHash properly...
On 3/24/10 1:47 , Levente Uzonyi wrote:
On Tue, 23 Mar 2010, Andres Valloud wrote:
(with a good hash function, the primitive will almost always find the required object in the first try, negating the benefits of the primitive)
With 4096 different hash values and 1000000 objects that won't happen.
Levente
On 3/23/10 18:20 , Andres Valloud wrote:
As soon as you get a JIT VM, you will be surprised at how expensive primitives that require calling a C function can be. You might be better off without the primitive and with a more streamlined hashed collection instead. Also, the presence of the primitive will allow little to no flexibility...
On 3/23/10 16:47 , Levente Uzonyi wrote:
On Wed, 24 Mar 2010, Bert Freudenberg wrote:
On 23.03.2010, at 23:57, Levente Uzonyi wrote:
On Tue, 23 Mar 2010, Bert Freudenberg wrote:
> On 23.03.2010, at 16:01, Lukas Renggli wrote: > > > >> >> >>>> Just an idea: we could get rid of compact classes, which would give >>>> us >>>> additional 6 bits (5 bits from the compact class index plus 1 bit >>>> from the >>>> header type because there would only be 2 header types left). This >>>> would >>>> increase the identity hash values from 4096 to 262144. In a >>>> PharoCore1.0 >>>> image there are 148589 instances of compact classes, hence this >>>> would cost >>>> 580k. Or, we could just add an additional word and use the spare >>>> bits from >>>> the old identity hash for other stuff, e.g., immutability ;) >>>> >>>> >>>> >>> I like the first idea, we could even have the 17 continuous bits for >>> identity hash the 1 separate bit for immutability. >>> >>> >>> >> Yes please, I love it :-) >> >> Lukas >> >> >> > Well, someone should code it up, and then lets's see macro benchmarks > :) > > > That's a great idea, but I'm sure it'll take a while until that happens. Fortunately identityhash related benchmarks can be done without changing the vm. I rewrote a bit the benchmark from Chris, created three classes which have 17, 18 and 30 bits for #scaledIdentityHash. Ran the benchmark with these three classes + Object, collected the data and created some diagrams. I'm sure most people don't care about the code/data[1], so here are the diagrams: http://leves.web.elte.hu/identityHashBits/identityHashBits.png http://leves.web.elte.hu/identityHashBits/identityHashBits2.png http://leves.web.elte.hu/identityHashBits/identityHashBits3.png
The first one contains the four graphs. It clearly shows that 12 bits (Object) are insufficient for #identityHash. Even 5 more bits gives 8-9x speedup and a dramatic change in behavior.
The second is the same as the first, but it shows only the 17, 18 and 30 bits case. Note that the primes (hashtable sizes) are now optimized for 12 bits. If they are optimized for 17/18 bits then the results can be better for larger set sizes (130+/260+) where they show worse behavior compared to the 18/30 bits case.
The third graph shows how an optimized data structure (LargeIdentitySet) compares to the 17, 18 and 30 bits case using only 12 bits.
[1] All the code/data that were used to generate these graphs can be found here http://leves.web.elte.hu/identityHashBits
Levente
P.S. I also created a 12 bit version of the 17-18-30 bit classes and found that it's 1.2-2.0x slower than Object, so the values after the vm changes are expected to be even better than what these graphs show.
So this seems to indicate your specialized data structure beats all VM hash bits extension?
For IdentitySet - probably yes, up to a few million elements, but I expect the difference to be smaller with the vm support and optimal table sizes. (note that a "normal" image contains less than 500000 objects). For IdentityDictionary - probably not, because we don't have a fast primitive that can be used for the lookups.
Levente
Also, we don't know yet how getting rid of compact classes would affect performance.
- Bert -
.
.
.
On Thu, 25 Mar 2010, Andres Valloud wrote:
So the problem is that the objects are not implementing hash/identityHash properly...
There are only 12 bits for identityHash in Squeak. The hash function used by the identity-based collections is from your hash changes.
Levente
On 3/24/10 1:47 , Levente Uzonyi wrote:
On Tue, 23 Mar 2010, Andres Valloud wrote:
(with a good hash function, the primitive will almost always find the required object in the first try, negating the benefits of the primitive)
With 4096 different hash values and 1000000 objects that won't happen.
Levente
On 3/23/10 18:20 , Andres Valloud wrote:
As soon as you get a JIT VM, you will be surprised at how expensive primitives that require calling a C function can be. You might be better off without the primitive and with a more streamlined hashed collection instead. Also, the presence of the primitive will allow little to no flexibility...
On 3/23/10 16:47 , Levente Uzonyi wrote:
On Wed, 24 Mar 2010, Bert Freudenberg wrote:
On 23.03.2010, at 23:57, Levente Uzonyi wrote:
> On Tue, 23 Mar 2010, Bert Freudenberg wrote: > > > > >> On 23.03.2010, at 16:01, Lukas Renggli wrote: >> >> >> >>> >>> >>>>> Just an idea: we could get rid of compact classes, which would >>>>> give >>>>> us >>>>> additional 6 bits (5 bits from the compact class index plus 1 bit >>>>> from the >>>>> header type because there would only be 2 header types left). This >>>>> would >>>>> increase the identity hash values from 4096 to 262144. In a >>>>> PharoCore1.0 >>>>> image there are 148589 instances of compact classes, hence this >>>>> would cost >>>>> 580k. Or, we could just add an additional word and use the spare >>>>> bits from >>>>> the old identity hash for other stuff, e.g., immutability ;) >>>>> >>>>> >>>>> >>>> I like the first idea, we could even have the 17 continuous bits >>>> for >>>> identity hash the 1 separate bit for immutability. >>>> >>>> >>>> >>> Yes please, I love it :-) >>> >>> Lukas >>> >>> >>> >> Well, someone should code it up, and then lets's see macro benchmarks >> :) >> >> >> > That's a great idea, but I'm sure it'll take a while until that > happens. > Fortunately identityhash related benchmarks can be done without > changing > the vm. I rewrote a bit the benchmark from Chris, created three > classes > which have 17, 18 and 30 bits for #scaledIdentityHash. Ran the > benchmark > with these three classes + Object, collected the data and created some > diagrams. I'm sure most people don't care about the code/data[1], so > here are the diagrams: > http://leves.web.elte.hu/identityHashBits/identityHashBits.png > http://leves.web.elte.hu/identityHashBits/identityHashBits2.png > http://leves.web.elte.hu/identityHashBits/identityHashBits3.png > > The first one contains the four graphs. It clearly shows that 12 bits > (Object) are insufficient for #identityHash. Even 5 more bits gives > 8-9x > speedup and a dramatic change in behavior. > > The second is the same as the first, but it shows only the 17, 18 and > 30 > bits case. Note that the primes (hashtable sizes) are now optimized > for > 12 bits. If they are optimized for 17/18 bits then the results can be > better for larger set sizes (130+/260+) where they show worse behavior > compared to the 18/30 bits case. > > The third graph shows how an optimized data structure > (LargeIdentitySet) > compares to the 17, 18 and 30 bits case using only 12 bits. > > [1] All the code/data that were used to generate these graphs can be > found here http://leves.web.elte.hu/identityHashBits > > > Levente > > P.S. I also created a 12 bit version of the 17-18-30 bit classes and > found that it's 1.2-2.0x slower than Object, so the values after the > vm > changes are expected to be even better than what these graphs show. > > > So this seems to indicate your specialized data structure beats all VM hash bits extension?
For IdentitySet - probably yes, up to a few million elements, but I expect the difference to be smaller with the vm support and optimal table sizes. (note that a "normal" image contains less than 500000 objects). For IdentityDictionary - probably not, because we don't have a fast primitive that can be used for the lookups.
Levente
Also, we don't know yet how getting rid of compact classes would affect performance.
- Bert -
.
.
.
The point is why insisting on using identityHash with == if identityHash is limited? Clearly you can refine identityHash to answer something more appropriate if needed, because the rule is x == y => x identityHash = y identityHash. Nothing requires identityHash to answer the 12 or whatever header bits. Also, if you take this route, then you don't make the object headers grow for every single object regardless of whether they are sent the message identityHash or not (which will make the VM run slower because the CPU will perform more memory reads). And note that a good optimization strategy for VMs is to leave the identityHash field uninitialized at allocation time betting that checking whether the field is set or not, and providing an identityHash value lazily, will be cheaper than providing identityHash values that will be left unused most of the time...
On 3/26/10 3:36 , Levente Uzonyi wrote:
On Thu, 25 Mar 2010, Andres Valloud wrote:
So the problem is that the objects are not implementing hash/identityHash properly...
There are only 12 bits for identityHash in Squeak. The hash function used by the identity-based collections is from your hash changes.
Levente
On 3/24/10 1:47 , Levente Uzonyi wrote:
On Tue, 23 Mar 2010, Andres Valloud wrote:
(with a good hash function, the primitive will almost always find the required object in the first try, negating the benefits of the primitive)
With 4096 different hash values and 1000000 objects that won't happen.
Levente
On 3/23/10 18:20 , Andres Valloud wrote:
As soon as you get a JIT VM, you will be surprised at how expensive primitives that require calling a C function can be. You might be better off without the primitive and with a more streamlined hashed collection instead. Also, the presence of the primitive will allow little to no flexibility...
On 3/23/10 16:47 , Levente Uzonyi wrote:
On Wed, 24 Mar 2010, Bert Freudenberg wrote:
> On 23.03.2010, at 23:57, Levente Uzonyi wrote: > > > > >> On Tue, 23 Mar 2010, Bert Freudenberg wrote: >> >> >> >> >> >>> On 23.03.2010, at 16:01, Lukas Renggli wrote: >>> >>> >>> >>> >>>> >>>> >>>>>> Just an idea: we could get rid of compact classes, which would >>>>>> give >>>>>> us >>>>>> additional 6 bits (5 bits from the compact class index plus 1 bit >>>>>> from the >>>>>> header type because there would only be 2 header types left). This >>>>>> would >>>>>> increase the identity hash values from 4096 to 262144. In a >>>>>> PharoCore1.0 >>>>>> image there are 148589 instances of compact classes, hence this >>>>>> would cost >>>>>> 580k. Or, we could just add an additional word and use the spare >>>>>> bits from >>>>>> the old identity hash for other stuff, e.g., immutability ;) >>>>>> >>>>>> >>>>>> >>>>>> >>>>> I like the first idea, we could even have the 17 continuous bits >>>>> for >>>>> identity hash the 1 separate bit for immutability. >>>>> >>>>> >>>>> >>>>> >>>> Yes please, I love it :-) >>>> >>>> Lukas >>>> >>>> >>>> >>>> >>> Well, someone should code it up, and then lets's see macro benchmarks >>> :) >>> >>> >>> >>> >> That's a great idea, but I'm sure it'll take a while until that >> happens. >> Fortunately identityhash related benchmarks can be done without >> changing >> the vm. I rewrote a bit the benchmark from Chris, created three >> classes >> which have 17, 18 and 30 bits for #scaledIdentityHash. Ran the >> benchmark >> with these three classes + Object, collected the data and created some >> diagrams. I'm sure most people don't care about the code/data[1], so >> here are the diagrams: >> http://leves.web.elte.hu/identityHashBits/identityHashBits.png >> http://leves.web.elte.hu/identityHashBits/identityHashBits2.png >> http://leves.web.elte.hu/identityHashBits/identityHashBits3.png >> >> The first one contains the four graphs. It clearly shows that 12 bits >> (Object) are insufficient for #identityHash. Even 5 more bits gives >> 8-9x >> speedup and a dramatic change in behavior. >> >> The second is the same as the first, but it shows only the 17, 18 and >> 30 >> bits case. Note that the primes (hashtable sizes) are now optimized >> for >> 12 bits. If they are optimized for 17/18 bits then the results can be >> better for larger set sizes (130+/260+) where they show worse behavior >> compared to the 18/30 bits case. >> >> The third graph shows how an optimized data structure >> (LargeIdentitySet) >> compares to the 17, 18 and 30 bits case using only 12 bits. >> >> [1] All the code/data that were used to generate these graphs can be >> found here http://leves.web.elte.hu/identityHashBits >> >> >> Levente >> >> P.S. I also created a 12 bit version of the 17-18-30 bit classes and >> found that it's 1.2-2.0x slower than Object, so the values after the >> vm >> changes are expected to be even better than what these graphs show. >> >> >> >> > So this seems to indicate your specialized data structure beats all VM > hash bits extension? > > > > For IdentitySet - probably yes, up to a few million elements, but I expect the difference to be smaller with the vm support and optimal table sizes. (note that a "normal" image contains less than 500000 objects). For IdentityDictionary - probably not, because we don't have a fast primitive that can be used for the lookups.
Levente
> Also, we don't know yet how getting rid of compact classes would affect > performance. > > - Bert - > > > > > > > > .
.
.
.
On Tue, 23 Mar 2010, Andres Valloud wrote:
As soon as you get a JIT VM, you will be surprised at how expensive primitives that require calling a C function can be. You might be better off without the primitive and with a more streamlined hashed collection instead. Also, the presence of the primitive will allow little to no flexibility...
We don't have a JIT and who knows if and when we will have one. Until then the following runtime rule applies most of the time: primitives < code mostly bytecodes < code with sends. And note that here I was talking abot #pointsTo: which when sent to an array tells if and object is in the array using ==. LargeIdentitySet uses this primitive to tell if the object is in the "list" of objects which have the same identity hash.
Levente
On 3/23/10 16:47 , Levente Uzonyi wrote:
On Wed, 24 Mar 2010, Bert Freudenberg wrote:
On 23.03.2010, at 23:57, Levente Uzonyi wrote:
On Tue, 23 Mar 2010, Bert Freudenberg wrote:
On 23.03.2010, at 16:01, Lukas Renggli wrote:
>> Just an idea: we could get rid of compact classes, which would give >> us >> additional 6 bits (5 bits from the compact class index plus 1 bit >> from the >> header type because there would only be 2 header types left). This >> would >> increase the identity hash values from 4096 to 262144. In a >> PharoCore1.0 >> image there are 148589 instances of compact classes, hence this would >> cost >> 580k. Or, we could just add an additional word and use the spare bits >> from >> the old identity hash for other stuff, e.g., immutability ;) >> > I like the first idea, we could even have the 17 continuous bits for > identity hash the 1 separate bit for immutability. > Yes please, I love it :-)
Lukas
Well, someone should code it up, and then lets's see macro benchmarks :)
That's a great idea, but I'm sure it'll take a while until that happens. Fortunately identityhash related benchmarks can be done without changing the vm. I rewrote a bit the benchmark from Chris, created three classes which have 17, 18 and 30 bits for #scaledIdentityHash. Ran the benchmark with these three classes + Object, collected the data and created some diagrams. I'm sure most people don't care about the code/data[1], so here are the diagrams: http://leves.web.elte.hu/identityHashBits/identityHashBits.png http://leves.web.elte.hu/identityHashBits/identityHashBits2.png http://leves.web.elte.hu/identityHashBits/identityHashBits3.png
The first one contains the four graphs. It clearly shows that 12 bits (Object) are insufficient for #identityHash. Even 5 more bits gives 8-9x speedup and a dramatic change in behavior.
The second is the same as the first, but it shows only the 17, 18 and 30 bits case. Note that the primes (hashtable sizes) are now optimized for 12 bits. If they are optimized for 17/18 bits then the results can be better for larger set sizes (130+/260+) where they show worse behavior compared to the 18/30 bits case.
The third graph shows how an optimized data structure (LargeIdentitySet) compares to the 17, 18 and 30 bits case using only 12 bits.
[1] All the code/data that were used to generate these graphs can be found here http://leves.web.elte.hu/identityHashBits
Levente
P.S. I also created a 12 bit version of the 17-18-30 bit classes and found that it's 1.2-2.0x slower than Object, so the values after the vm changes are expected to be even better than what these graphs show.
So this seems to indicate your specialized data structure beats all VM hash bits extension?
For IdentitySet - probably yes, up to a few million elements, but I expect the difference to be smaller with the vm support and optimal table sizes. (note that a "normal" image contains less than 500000 objects). For IdentityDictionary - probably not, because we don't have a fast primitive that can be used for the lookups.
Levente
Also, we don't know yet how getting rid of compact classes would affect performance.
- Bert -
.
IMO, it's not worth the hassle for hashed collections to store nil. Finding good primes is not that expensive either, usually it takes no more than a couple seconds. You can look at the bottom of the prime table in VisualWorks and see an expression that finds them from scratch (but note that isPrime *MUST BE DETERMINISTIC*).
In the case examined, just refine #hash or #identityHash as needed for your application, and everything should be just fine. For more information, get the hash book here: www.lulu.com/avSmalltalkBooks.
Andres.
On 3/23/10 3:36 , Levente Uzonyi wrote:
On Mon, 22 Mar 2010, Chris Muller wrote:
4.1 hashed collections, across the board, small to large, are slower by a factor of 2?! I just don't think we can keep doing this; getting slower and slower and slower, like molasses.. I'm sorry, but I really care about this and I know you do too because speed was the whole premise of putting these changes in.
What went wrong? More importantly, how can we fix this?
What went wrong?
I think nothing. :) IdentitySet and IdentityDictionary wasn't ment to support really large collections. The main reason is that there are only 4096 different hash values. So practically these collections are growing 4096 lists in a single array. In 3.9 and 3.10 these collections used a hash expansion technique which distributed the elements uniformly. This was changed when we integrated Andrés' hash changes. As you noticed some of the primes didn't work well with #scaledIdentityHash, it's far better now, though there may be even better primes. Finding such primes is a computationally intensive task and the current ones (up to 10000000) are pretty close to optimal. Other than that there are two things that cause slowdown: +1 extra message send/scanning: #scaledIdentityHash (the new hash expansion scheme, but we save one by not using #findElementOrNil:) +k (worst case) extra message send/scanning: #enclosedSetElement (OO nil support, this only applies for IdentitySet) Where k is the length of the list. Since there are only 4096 different identity hash values for n = 250000 k will be ~61 (if the identity hashes have a uniform distribution). For n = 1000000 it will be ~244. Note that your benchmark exploits the worst case. The long lists are bad, because HashedCollection is optimized for O(1) list length. In this case the length of the list is not O(1), but O(n) (with a very small constant).
How can we fix this?
I see two possible solutions for the problem:
- use #largeHash instead of #identityHash, which is the identity hash of
the object mixed with the identity hash of its class. This helps if there are objects from different classes in the set, but it doesn't help with your benchmark. SystemTracer uses this method. 2) use differently implemented collections which are optimized for your use case. For example I wrote LargeIdentitySet which probably has the best performance you can have: http://leves.web.elte.hu/squeak/LargeIdentitySet.st (note that it's hardly tested, probably contains bugs)
Levente

On Tue, Mar 23, 2010 at 06:18:23PM -0700, Andres Valloud wrote:
You can look at the bottom of the prime table in VisualWorks and see an expression that finds them from scratch (but note that isPrime *MUST BE DETERMINISTIC*).
Andres,
Is this a reference to the #isPrime in Squeak trunk, which calls #isProbablyPrime for LargePositiveInteger? If so, can you say if there is any difference in the actual results of computing a prime table with a Squeak trunk image compared to the VisualWorks results?
If there is an difference in the results in Squeak versus VisualWorks, this would be important to know.
Thanks, Dave
I don't have Squeak handy right now, I just meant to say that the code in the VisualWorks method will work correctly as long as isPrime is deterministic.
On 3/23/10 18:58 , David T. Lewis wrote:
On Tue, Mar 23, 2010 at 06:18:23PM -0700, Andres Valloud wrote:
You can look at the bottom of the prime table in VisualWorks and see an expression that finds them from scratch (but note that isPrime *MUST BE DETERMINISTIC*).
Andres,
Is this a reference to the #isPrime in Squeak trunk, which calls #isProbablyPrime for LargePositiveInteger? If so, can you say if there is any difference in the actual results of computing a prime table with a Squeak trunk image compared to the VisualWorks results?
If there is an difference in the results in Squeak versus VisualWorks, this would be important to know.
Thanks, Dave
The prime table is from the hash changes you made for Pharo.
From HashChangesI1.1.cs:
Set class methodsFor: 'sizing' stamp: 'SqR 10/25/2009 02:17'! goodPrimes "Answer a sorted array of prime numbers less than one billion that make good hash table sizes. Should be expanded as needed. See comments below code"
^#(5 11 17 23 31 43 59 79 107 149 199 269 359 479 641 857 1151 1549 2069 ...lines with primes... 1073741789)
"The above primes past 2096 were chosen carefully so that they do not interact badly with 1664525 (used by hashMultiply), and so that gcd(p, (256^k) +/- a) = 1, for 0<a<=32 and 0<k<=8. See Knuth's TAOCP for details. Use the following Integer method to check primality.
isDefinitelyPrime
| guess guessSquared delta selfSqrtFloor | self <= 1 ifTrue: [^self error: 'operation undefined']. self even ifTrue: [^self = 2]. guess := 1 bitShift: self highBit + 1 // 2. [ guessSquared := guess * guess. delta := guessSquared - self // (guess bitShift: 1). delta = 0 ] whileFalse: [guess := guess - delta]. guessSquared = self ifFalse: [guess := guess - 1]. selfSqrtFloor := guess. 3 to: selfSqrtFloor by: 2 do: [:each | self \ each = 0 ifTrue: [^false]]. ^true"! !
!
Levente
On Thu, 25 Mar 2010, Andres Valloud wrote:
I don't have Squeak handy right now, I just meant to say that the code in the VisualWorks method will work correctly as long as isPrime is deterministic.
On 3/23/10 18:58 , David T. Lewis wrote:
On Tue, Mar 23, 2010 at 06:18:23PM -0700, Andres Valloud wrote:
You can look at the bottom of the prime table in VisualWorks and see an expression that finds them from scratch (but note that isPrime *MUST BE DETERMINISTIC*).
Andres,
Is this a reference to the #isPrime in Squeak trunk, which calls #isProbablyPrime for LargePositiveInteger? If so, can you say if there is any difference in the actual results of computing a prime table with a Squeak trunk image compared to the VisualWorks results?
If there is an difference in the results in Squeak versus VisualWorks, this would be important to know.
Thanks, Dave
On Tue, 23 Mar 2010, Andres Valloud wrote:
IMO, it's not worth the hassle for hashed collections to store nil. Finding good primes is not that expensive either, usually it takes no more than a couple seconds. You can look at the bottom of the prime table in VisualWorks and see an expression that finds them from scratch (but note that isPrime *MUST BE DETERMINISTIC*).
I'm not a VW user, but if those primes are the same as the primes in HashedCollection class >> #goodPrimes (and the method is the same as the way #goodPrimes were generated), than those primes are not good enough for #scaledIdentityHash. Details here: http://lists.squeakfoundation.org/pipermail/squeak-dev/2010-March/147154.htm...
Levente
In the case examined, just refine #hash or #identityHash as needed for your application, and everything should be just fine. For more information, get the hash book here: www.lulu.com/avSmalltalkBooks.
Andres.
On 3/23/10 3:36 , Levente Uzonyi wrote:
On Mon, 22 Mar 2010, Chris Muller wrote:
4.1 hashed collections, across the board, small to large, are slower by a factor of 2?! I just don't think we can keep doing this; getting slower and slower and slower, like molasses.. I'm sorry, but I really care about this and I know you do too because speed was the whole premise of putting these changes in.
What went wrong? More importantly, how can we fix this?
What went wrong?
I think nothing. :) IdentitySet and IdentityDictionary wasn't ment to support really large collections. The main reason is that there are only 4096 different hash values. So practically these collections are growing 4096 lists in a single array. In 3.9 and 3.10 these collections used a hash expansion technique which distributed the elements uniformly. This was changed when we integrated Andrés' hash changes. As you noticed some of the primes didn't work well with #scaledIdentityHash, it's far better now, though there may be even better primes. Finding such primes is a computationally intensive task and the current ones (up to 10000000) are pretty close to optimal. Other than that there are two things that cause slowdown: +1 extra message send/scanning: #scaledIdentityHash (the new hash expansion scheme, but we save one by not using #findElementOrNil:) +k (worst case) extra message send/scanning: #enclosedSetElement (OO nil support, this only applies for IdentitySet) Where k is the length of the list. Since there are only 4096 different identity hash values for n = 250000 k will be ~61 (if the identity hashes have a uniform distribution). For n = 1000000 it will be ~244. Note that your benchmark exploits the worst case. The long lists are bad, because HashedCollection is optimized for O(1) list length. In this case the length of the list is not O(1), but O(n) (with a very small constant).
How can we fix this?
I see two possible solutions for the problem:
- use #largeHash instead of #identityHash, which is the identity hash of
the object mixed with the identity hash of its class. This helps if there are objects from different classes in the set, but it doesn't help with your benchmark. SystemTracer uses this method. 2) use differently implemented collections which are optimized for your use case. For example I wrote LargeIdentitySet which probably has the best performance you can have: http://leves.web.elte.hu/squeak/LargeIdentitySet.st (note that it's hardly tested, probably contains bugs)
Levente
Hi Levente, thanks a lot for all of your great help with the hashed collections. I would like to test your LargeIdentitySet and LargeIdentityDictionary with Magma and some of my proprietary applications. May I assume use of them under a MIT license?
- Chris
2010/3/23 Levente Uzonyi leves@elte.hu:
On Mon, 22 Mar 2010, Chris Muller wrote:
4.1 hashed collections, across the board, small to large, are slower by a factor of 2?! I just don't think we can keep doing this; getting slower and slower and slower, like molasses.. I'm sorry, but I really care about this and I know you do too because speed was the whole premise of putting these changes in.
What went wrong? More importantly, how can we fix this?
What went wrong?
I think nothing. :) IdentitySet and IdentityDictionary wasn't ment to support really large collections. The main reason is that there are only 4096 different hash values. So practically these collections are growing 4096 lists in a single array. In 3.9 and 3.10 these collections used a hash expansion technique which distributed the elements uniformly. This was changed when we integrated Andrés' hash changes. As you noticed some of the primes didn't work well with #scaledIdentityHash, it's far better now, though there may be even better primes. Finding such primes is a computationally intensive task and the current ones (up to 10000000) are pretty close to optimal. Other than that there are two things that cause slowdown: +1 extra message send/scanning: #scaledIdentityHash (the new hash expansion scheme, but we save one by not using #findElementOrNil:) +k (worst case) extra message send/scanning: #enclosedSetElement (OO nil support, this only applies for IdentitySet) Where k is the length of the list. Since there are only 4096 different identity hash values for n = 250000 k will be ~61 (if the identity hashes have a uniform distribution). For n = 1000000 it will be ~244. Note that your benchmark exploits the worst case. The long lists are bad, because HashedCollection is optimized for O(1) list length. In this case the length of the list is not O(1), but O(n) (with a very small constant).
How can we fix this?
I see two possible solutions for the problem:
- use #largeHash instead of #identityHash, which is the identity hash of
the object mixed with the identity hash of its class. This helps if there are objects from different classes in the set, but it doesn't help with your benchmark. SystemTracer uses this method. 2) use differently implemented collections which are optimized for your use case. For example I wrote LargeIdentitySet which probably has the best performance you can have: http://leves.web.elte.hu/squeak/LargeIdentitySet.st (note that it's hardly tested, probably contains bugs)
Levente
On Sun, 28 Mar 2010, Chris Muller wrote:
Hi Levente, thanks a lot for all of your great help with the hashed collections. I would like to test your LargeIdentitySet and LargeIdentityDictionary with Magma and some of my proprietary applications. May I assume use of them under a MIT license?
Sure. Note that LargeIdentityDictionary cannot have nil as key at the moment.
Levente
- Chris
2010/3/23 Levente Uzonyi leves@elte.hu:
On Mon, 22 Mar 2010, Chris Muller wrote:
4.1 hashed collections, across the board, small to large, are slower by a factor of 2?! I just don't think we can keep doing this; getting slower and slower and slower, like molasses.. I'm sorry, but I really care about this and I know you do too because speed was the whole premise of putting these changes in.
What went wrong? More importantly, how can we fix this?
What went wrong?
I think nothing. :) IdentitySet and IdentityDictionary wasn't ment to support really large collections. The main reason is that there are only 4096 different hash values. So practically these collections are growing 4096 lists in a single array. In 3.9 and 3.10 these collections used a hash expansion technique which distributed the elements uniformly. This was changed when we integrated Andrés' hash changes. As you noticed some of the primes didn't work well with #scaledIdentityHash, it's far better now, though there may be even better primes. Finding such primes is a computationally intensive task and the current ones (up to 10000000) are pretty close to optimal. Other than that there are two things that cause slowdown: +1 extra message send/scanning: #scaledIdentityHash (the new hash expansion scheme, but we save one by not using #findElementOrNil:) +k (worst case) extra message send/scanning: #enclosedSetElement (OO nil support, this only applies for IdentitySet) Where k is the length of the list. Since there are only 4096 different identity hash values for n = 250000 k will be ~61 (if the identity hashes have a uniform distribution). For n = 1000000 it will be ~244. Note that your benchmark exploits the worst case. The long lists are bad, because HashedCollection is optimized for O(1) list length. In this case the length of the list is not O(1), but O(n) (with a very small constant).
How can we fix this?
I see two possible solutions for the problem:
- use #largeHash instead of #identityHash, which is the identity hash of
the object mixed with the identity hash of its class. This helps if there are objects from different classes in the set, but it doesn't help with your benchmark. SystemTracer uses this method. 2) use differently implemented collections which are optimized for your use case. For example I wrote LargeIdentitySet which probably has the best performance you can have: http://leves.web.elte.hu/squeak/LargeIdentitySet.st (note that it's hardly tested, probably contains bugs)
Levente
On Sun, 28 Mar 2010, Levente Uzonyi wrote:
On Sun, 28 Mar 2010, Chris Muller wrote:
Hi Levente, thanks a lot for all of your great help with the hashed collections. I would like to test your LargeIdentitySet and LargeIdentityDictionary with Magma and some of my proprietary applications. May I assume use of them under a MIT license?
Sure. Note that LargeIdentityDictionary cannot have nil as key at the moment.
I was a bit too fast. It does support nil as key. :)
Levente
Levente
- Chris
2010/3/23 Levente Uzonyi leves@elte.hu:
On Mon, 22 Mar 2010, Chris Muller wrote:
4.1 hashed collections, across the board, small to large, are slower by a factor of 2?! I just don't think we can keep doing this; getting slower and slower and slower, like molasses.. I'm sorry, but I really care about this and I know you do too because speed was the whole premise of putting these changes in.
What went wrong? More importantly, how can we fix this?
What went wrong?
I think nothing. :) IdentitySet and IdentityDictionary wasn't ment to support really large collections. The main reason is that there are only 4096 different hash values. So practically these collections are growing 4096 lists in a single array. In 3.9 and 3.10 these collections used a hash expansion technique which distributed the elements uniformly. This was changed when we integrated Andrés' hash changes. As you noticed some of the primes didn't work well with #scaledIdentityHash, it's far better now, though there may be even better primes. Finding such primes is a computationally intensive task and the current ones (up to 10000000) are pretty close to optimal. Other than that there are two things that cause slowdown: +1 extra message send/scanning: #scaledIdentityHash (the new hash expansion scheme, but we save one by not using #findElementOrNil:) +k (worst case) extra message send/scanning: #enclosedSetElement (OO nil support, this only applies for IdentitySet) Where k is the length of the list. Since there are only 4096 different identity hash values for n = 250000 k will be ~61 (if the identity hashes have a uniform distribution). For n = 1000000 it will be ~244. Note that your benchmark exploits the worst case. The long lists are bad, because HashedCollection is optimized for O(1) list length. In this case the length of the list is not O(1), but O(n) (with a very small constant).
How can we fix this?
I see two possible solutions for the problem:
- use #largeHash instead of #identityHash, which is the identity hash of
the object mixed with the identity hash of its class. This helps if there are objects from different classes in the set, but it doesn't help with your benchmark. SystemTracer uses this method. 2) use differently implemented collections which are optimized for your use case. For example I wrote LargeIdentitySet which probably has the best performance you can have: http://leves.web.elte.hu/squeak/LargeIdentitySet.st (note that it's hardly tested, probably contains bugs)
Levente
squeak-dev@lists.squeakfoundation.org
-
 Adrian Lienhard
Adrian Lienhard -
 Andreas Raab
Andreas Raab -
 Andres Valloud
Andres Valloud -
 Bert Freudenberg
Bert Freudenberg -
 Chris Muller
Chris Muller -
 David T. Lewis
David T. Lewis -
 Igor Stasenko
Igor Stasenko -
 Levente Uzonyi
Levente Uzonyi -
 Lukas Renggli
Lukas Renggli -
 Tom Rushworth
Tom Rushworth