
I got an idea while reading this nice blending trick: http://stackoverflow.com/questions/20681590/how-does-this-color-blending-tri...
We could do a similar thing when adding components in BitBlt partitionedAdd: word1 to: word2 nBits: nBits nPartitions: nParts
For a simple example, say I have 2 parts of 4 bits I will start reasonning with extended precision (thus on 16 bits here)
"The sum with carry is" sumWithCarry:=word1+word2. "But carry must not be propagated past each component." "So we must care of what happens at" carryOverflowMask := 2r100010000. "The sum without any carry is" sumWithoutCarry:=word1 bitXor: word2. "If the sum without carry differ from sum with carry then an overflow occured." "We can thus detect presence of a carry overflow:" carryOverflow := (sumWithCarry bitXor: sumWithoutCarry) bitAnd: carryOverflowMask. "If an undue carry occured, we just removet it:" sumWithoutUndueCarry := sumWithCarry - carryOverflow. "But in this case, previous component did overflow, we must saturate it at 2r1111, that is:" componentMask:=1<<nBits-1. "we just have to multiply each carryOverflow bit with this componentMask:" result := sumWithoutUndueCarry bitOr: carryOverflow >> nBit * componentMask.
-----------
"Generalization: note that 2r00010001 * componentMask = 2r11111111" "Correlatively, for arbitrary nBits and nParts parameters:" carryOverflowMask := 1<<(nParts*nBits)-1//componentMask<<nBits.
-----------
In BitBlt, we want to operate on 32bits words. We can use #usqLong (64 bits at least) all the way, and obtain branch free replacement for above method
<var: #word1 type: 'unsigned int'> <var: #word2 type: 'unsigned int'> <var: #one type: #usqLong> <var: #componentMask type: #usqLong> <var: #carryOverflowMask type: #usqLong> <var: #carryOverflow type: #usqLong> <var: #sum type: #usqLong> one := 1. componentMask := one<<nBits-1. carryOverflowMask := one<<(nBits*nParts)-1//componentMask<<nBits. sum := word1. sum := sum + word2. carryOverflow := ((word1 bitXor: word2) bitXor: sum) bitAnd: carryOverflowMask. ^sum-carryOverflow bitOr: carryOverflow>>nBits * componentMask
-----------
But maybe we can do better and express all with native unsigned int operations. We must then look if bits at 2r10001000 could produce a carry. We have a carry in next bit if at least 2 out of the 3 are true among word1 word2 carry... That is (word1 bitAnd: word2) bitOr: ((word1 bitOr: word2) bitAnd: carry).
<var: #word1 type: 'unsigned int'> <var: #word2 type: 'unsigned int'> <var: #one type: #usqLong> "because we cannot shift <<32 a usqInt in C..." <var: #componentMask type: 'unsigned int'> <var: #carryOverflowMask type: 'unsigned int'> <var: #carryOverflow type: 'unsigned int'> <var: #carry type: 'unsigned int'> <var: #sum type: 'unsigned int'> one := 1. componentMask := one<<nBits-1. carryOverflowMask := one<<(nBits*nParts)-1. carryOverflowMask := carryOverflowMask//componentMask<<(nBits-1). sum := word1. sum := sum + word2. carry := (word1 bitXor: word2) bitXor: sum. carryOverflow := ((word1 bitAnd: word2) bitOr: ((word1 bitOr: word2) bitAnd: carry)) bitAnd: carryOverflowMask. ^sum-(carryOverflow<<1) bitOr: carryOverflow>>(nBits-1) * componentMask
Maybe some good soul may help reducing # ops further, but we already have a branch free sum. I did no performance test. Does one have good BitBlt benchmark?
2013/12/24 Nicolas Cellier nicolas.cellier.aka.nice@gmail.com
I got an idea while reading this nice blending trick:
http://stackoverflow.com/questions/20681590/how-does-this-color-blending-tri...
We could do a similar thing when adding components in BitBlt partitionedAdd: word1 to: word2 nBits: nBits nPartitions: nParts
For a simple example, say I have 2 parts of 4 bits I will start reasonning with extended precision (thus on 16 bits here)
"The sum with carry is" sumWithCarry:=word1+word2. "But carry must not be propagated past each component." "So we must care of what happens at" carryOverflowMask := 2r100010000. "The sum without any carry is" sumWithoutCarry:=word1 bitXor: word2. "If the sum without carry differ from sum with carry then an overflow occured." "We can thus detect presence of a carry overflow:" carryOverflow := (sumWithCarry bitXor: sumWithoutCarry) bitAnd: carryOverflowMask. "If an undue carry occured, we just removet it:" sumWithoutUndueCarry := sumWithCarry - carryOverflow. "But in this case, previous component did overflow, we must saturate it at 2r1111, that is:" componentMask:=1<<nBits-1. "we just have to multiply each carryOverflow bit with this componentMask:" result := sumWithoutUndueCarry bitOr: carryOverflow >> nBit * componentMask.
"Generalization: note that 2r00010001 * componentMask = 2r11111111" "Correlatively, for arbitrary nBits and nParts parameters:" carryOverflowMask := 1<<(nParts*nBits)-1//componentMask<<nBits.
In BitBlt, we want to operate on 32bits words. We can use #usqLong (64 bits at least) all the way, and obtain branch free replacement for above method
<var: #word1 type: 'unsigned int'> <var: #word2 type: 'unsigned int'> <var: #one type: #usqLong> <var: #componentMask type: #usqLong> <var: #carryOverflowMask type: #usqLong> <var: #carryOverflow type: #usqLong> <var: #sum type: #usqLong> one := 1. componentMask := one<<nBits-1. carryOverflowMask := one<<(nBits*nParts)-1//componentMask<<nBits. sum := word1. sum := sum + word2. carryOverflow := ((word1 bitXor: word2) bitXor: sum) bitAnd:carryOverflowMask. ^sum-carryOverflow bitOr: carryOverflow>>nBits * componentMask
But maybe we can do better and express all with native unsigned int operations. We must then look if bits at 2r10001000 could produce a carry. We have a carry in next bit if at least 2 out of the 3 are true among word1 word2 carry... That is (word1 bitAnd: word2) bitOr: ((word1 bitOr: word2) bitAnd: carry).
<var: #word1 type: 'unsigned int'> <var: #word2 type: 'unsigned int'> <var: #one type: #usqLong> "because we cannot shift <<32 a usqInt inC..." <var: #componentMask type: 'unsigned int'> <var: #carryOverflowMask type: 'unsigned int'> <var: #carryOverflow type: 'unsigned int'> <var: #carry type: 'unsigned int'> <var: #sum type: 'unsigned int'> one := 1. componentMask := one<<nBits-1. carryOverflowMask := one<<(nBits*nParts)-1. carryOverflowMask := carryOverflowMask//componentMask<<(nBits-1). sum := word1. sum := sum + word2. carry := (word1 bitXor: word2) bitXor: sum. carryOverflow := ((word1 bitAnd: word2) bitOr: ((word1 bitOr: word2) bitAnd: carry)) bitAnd: carryOverflowMask. ^sum-(carryOverflow<<1) bitOr: carryOverflow>>(nBits-1) * componentMask
Maybe some good soul may help reducing # ops further, but we already have a branch free sum. I did no performance test. Does one have good BitBlt benchmark?
Attached is what I could come with minimal ops... The carry overflow can be written with this table
0 0 0 0 1 1 1 1 word1 0 0 1 1 0 0 1 1 word2 0 1 0 1 0 1 0 1 carry ------------------- 0 0 0 1 0 1 0 1 next carry if at least 2 out of 3 0 1 1 0 1 0 0 1 sum=word1+word2 (with carry) 0 0 0 1 0 1 x x (word1 bitOr: word2) bitAnd: sum bitInvert 0 0 0 0 0 0 1 1 (word1 bitAnd: word2)
The bit masks are not computed when depths are known constants
2013/12/24 Nicolas Cellier nicolas.cellier.aka.nice@gmail.com
2013/12/24 Nicolas Cellier nicolas.cellier.aka.nice@gmail.com
I got an idea while reading this nice blending trick:
http://stackoverflow.com/questions/20681590/how-does-this-color-blending-tri...
We could do a similar thing when adding components in BitBlt partitionedAdd: word1 to: word2 nBits: nBits nPartitions: nParts
For a simple example, say I have 2 parts of 4 bits I will start reasonning with extended precision (thus on 16 bits here)
"The sum with carry is" sumWithCarry:=word1+word2. "But carry must not be propagated past each component." "So we must care of what happens at" carryOverflowMask := 2r100010000. "The sum without any carry is" sumWithoutCarry:=word1 bitXor: word2. "If the sum without carry differ from sum with carry then an overflow occured." "We can thus detect presence of a carry overflow:" carryOverflow := (sumWithCarry bitXor: sumWithoutCarry) bitAnd: carryOverflowMask. "If an undue carry occured, we just removet it:" sumWithoutUndueCarry := sumWithCarry - carryOverflow. "But in this case, previous component did overflow, we must saturate it at 2r1111, that is:" componentMask:=1<<nBits-1. "we just have to multiply each carryOverflow bit with this componentMask:" result := sumWithoutUndueCarry bitOr: carryOverflow >> nBit * componentMask.
"Generalization: note that 2r00010001 * componentMask = 2r11111111" "Correlatively, for arbitrary nBits and nParts parameters:" carryOverflowMask := 1<<(nParts*nBits)-1//componentMask<<nBits.
In BitBlt, we want to operate on 32bits words. We can use #usqLong (64 bits at least) all the way, and obtain branch free replacement for above method
<var: #word1 type: 'unsigned int'> <var: #word2 type: 'unsigned int'> <var: #one type: #usqLong> <var: #componentMask type: #usqLong> <var: #carryOverflowMask type: #usqLong> <var: #carryOverflow type: #usqLong> <var: #sum type: #usqLong> one := 1. componentMask := one<<nBits-1. carryOverflowMask := one<<(nBits*nParts)-1//componentMask<<nBits. sum := word1. sum := sum + word2. carryOverflow := ((word1 bitXor: word2) bitXor: sum) bitAnd:carryOverflowMask. ^sum-carryOverflow bitOr: carryOverflow>>nBits * componentMask
But maybe we can do better and express all with native unsigned int operations. We must then look if bits at 2r10001000 could produce a carry. We have a carry in next bit if at least 2 out of the 3 are true among word1 word2 carry... That is (word1 bitAnd: word2) bitOr: ((word1 bitOr: word2) bitAnd: carry).
<var: #word1 type: 'unsigned int'> <var: #word2 type: 'unsigned int'> <var: #one type: #usqLong> "because we cannot shift <<32 a usqInt inC..." <var: #componentMask type: 'unsigned int'> <var: #carryOverflowMask type: 'unsigned int'> <var: #carryOverflow type: 'unsigned int'> <var: #carry type: 'unsigned int'> <var: #sum type: 'unsigned int'> one := 1. componentMask := one<<nBits-1. carryOverflowMask := one<<(nBits*nParts)-1. carryOverflowMask := carryOverflowMask//componentMask<<(nBits-1). sum := word1. sum := sum + word2. carry := (word1 bitXor: word2) bitXor: sum. carryOverflow := ((word1 bitAnd: word2) bitOr: ((word1 bitOr: word2) bitAnd: carry)) bitAnd: carryOverflowMask. ^sum-(carryOverflow<<1) bitOr: carryOverflow>>(nBits-1) * componentMask
Maybe some good soul may help reducing # ops further, but we already have a branch free sum. I did no performance test. Does one have good BitBlt benchmark?
Attached is what I could come with minimal ops... The carry overflow can be written with this table
0 0 0 0 1 1 1 1 word1 0 0 1 1 0 0 1 1 word2 0 1 0 1 0 1 0 1 carry
0 0 0 1 0 1 0 1 next carry if at least 2 out of 3 0 1 1 0 1 0 0 1 sum=word1+word2 (with carry) 0 0 0 1 0 1 x x (word1 bitOr: word2) bitAnd: sum bitInvert 0 0 0 0 0 0 1 1 (word1 bitAnd: word2)
The bit masks are not computed when depths are known constants
Arghh, I posted too fast, it was bitInvert32 because that's the only thing that the CCodeGenerator understand by now. Hmm this is wrong, ~x works for other int types than int32/uint32, but well...
I have yet another version published at http://smalltalkhub.com/mc/nice/NiceVMExperiments/main to handle a 2x16bits word in a single pass Of course, speed up is spectacular on low depth (around x5 at depth 1, x2 at depth 4, only 40% at depth 16 and 30% at depth 32).
2013/12/24 Nicolas Cellier nicolas.cellier.aka.nice@gmail.com
2013/12/24 Nicolas Cellier nicolas.cellier.aka.nice@gmail.com
2013/12/24 Nicolas Cellier nicolas.cellier.aka.nice@gmail.com
I got an idea while reading this nice blending trick:
http://stackoverflow.com/questions/20681590/how-does-this-color-blending-tri...
We could do a similar thing when adding components in BitBlt partitionedAdd: word1 to: word2 nBits: nBits nPartitions: nParts
For a simple example, say I have 2 parts of 4 bits I will start reasonning with extended precision (thus on 16 bits here)
"The sum with carry is" sumWithCarry:=word1+word2. "But carry must not be propagated past each component." "So we must care of what happens at" carryOverflowMask := 2r100010000. "The sum without any carry is" sumWithoutCarry:=word1 bitXor: word2. "If the sum without carry differ from sum with carry then an overflow occured." "We can thus detect presence of a carry overflow:" carryOverflow := (sumWithCarry bitXor: sumWithoutCarry) bitAnd: carryOverflowMask. "If an undue carry occured, we just removet it:" sumWithoutUndueCarry := sumWithCarry - carryOverflow. "But in this case, previous component did overflow, we must saturate it at 2r1111, that is:" componentMask:=1<<nBits-1. "we just have to multiply each carryOverflow bit with this componentMask:" result := sumWithoutUndueCarry bitOr: carryOverflow >> nBit * componentMask.
"Generalization: note that 2r00010001 * componentMask = 2r11111111" "Correlatively, for arbitrary nBits and nParts parameters:" carryOverflowMask := 1<<(nParts*nBits)-1//componentMask<<nBits.
In BitBlt, we want to operate on 32bits words. We can use #usqLong (64 bits at least) all the way, and obtain branch free replacement for above method
<var: #word1 type: 'unsigned int'> <var: #word2 type: 'unsigned int'> <var: #one type: #usqLong> <var: #componentMask type: #usqLong> <var: #carryOverflowMask type: #usqLong> <var: #carryOverflow type: #usqLong> <var: #sum type: #usqLong> one := 1. componentMask := one<<nBits-1. carryOverflowMask := one<<(nBits*nParts)-1//componentMask<<nBits. sum := word1. sum := sum + word2. carryOverflow := ((word1 bitXor: word2) bitXor: sum) bitAnd:carryOverflowMask. ^sum-carryOverflow bitOr: carryOverflow>>nBits * componentMask
But maybe we can do better and express all with native unsigned int operations. We must then look if bits at 2r10001000 could produce a carry. We have a carry in next bit if at least 2 out of the 3 are true among word1 word2 carry... That is (word1 bitAnd: word2) bitOr: ((word1 bitOr: word2) bitAnd: carry).
<var: #word1 type: 'unsigned int'> <var: #word2 type: 'unsigned int'> <var: #one type: #usqLong> "because we cannot shift <<32 a usqInt inC..." <var: #componentMask type: 'unsigned int'> <var: #carryOverflowMask type: 'unsigned int'> <var: #carryOverflow type: 'unsigned int'> <var: #carry type: 'unsigned int'> <var: #sum type: 'unsigned int'> one := 1. componentMask := one<<nBits-1. carryOverflowMask := one<<(nBits*nParts)-1. carryOverflowMask := carryOverflowMask//componentMask<<(nBits-1). sum := word1. sum := sum + word2. carry := (word1 bitXor: word2) bitXor: sum. carryOverflow := ((word1 bitAnd: word2) bitOr: ((word1 bitOr: word2) bitAnd: carry)) bitAnd: carryOverflowMask. ^sum-(carryOverflow<<1) bitOr: carryOverflow>>(nBits-1) * componentMask
Maybe some good soul may help reducing # ops further, but we already have a branch free sum. I did no performance test. Does one have good BitBlt benchmark?
Attached is what I could come with minimal ops... The carry overflow can be written with this table
0 0 0 0 1 1 1 1 word1 0 0 1 1 0 0 1 1 word2 0 1 0 1 0 1 0 1 carry
0 0 0 1 0 1 0 1 next carry if at least 2 out of 3 0 1 1 0 1 0 0 1 sum=word1+word2 (with carry) 0 0 0 1 0 1 x x (word1 bitOr: word2) bitAnd: sum bitInvert 0 0 0 0 0 0 1 1 (word1 bitAnd: word2)
The bit masks are not computed when depths are known constants
Arghh, I posted too fast, it was bitInvert32 because that's the only thing that the CCodeGenerator understand by now. Hmm this is wrong, ~x works for other int types than int32/uint32, but well...

If you (or anyone else, of course) are interested in really speeding up bitblt, it would likely be worth looking at the ARM specific speedups Ben Avison did for the PI. (Look in platforms/Cross/plugins/BitBltPlugin) and seeing if similar tricks could be done with the assorted media instructions in current i7 etc cpus.
tim -- tim Rowledge; tim@rowledge.org; http://www.rowledge.org/tim Experience is something you don't get until just after you need it.
Sure, I agree but this would require platform specific code... As I developped in the other thread, an alternative is to use native libraries where possible - that is when they perform an equivalent job (It would be Quartz or something like that for me). Such platform specific support will be harder to obtain, because it requires knowledge of VM plugin+external library or low level assembler... Plus the pain of diving into historical VM architecture (specifically in BitBlt, it's not that easy to get the full picture when you did not participate to the development - like me). I note that there is plenty of work required in this area, sort of technical debt. For example my MacOSX VMs do not support the little endian image formats yes (those with negative depth) which could be surprising if we didn't knew historical roots... ^Display supportedDisplayDepths
So, in a word, such platform specific support can certainly provide great rewards, but with significative investments. On the other hand, these little tricks are like harvesting low hanging fruits. They are made of pure C^H slang, thus valid on every platform which does not yet provide specific accelerated support. I'm lazy and just musing, so the fastest ROI is appealing.
Remember my little text composition/display benchs?
| text canvas m1 | canvas := FormCanvas extent: 569@399 depth: 32. text := Compiler evaluate: (FileStream fileNamed: 'text.st') contentsOfEntireFile. m1 := TextMorph new. m1 text: text textStyle: TextStyle default. m1 wrapFlag: true. m1 extent: 569@9999999. MessageTally spyOn: [ Time millisecondsToRun: [100 timesRepeat: [ m1 drawOn: canvas]]] Interpreter VM 4.10.10 Before bit hacks: 1425 1411 1403 Interpreter VM After bit hacks: 1152 1173
15 to 20% less, it's not really impressive, but the hurdle is low, just two bit-hacks applied to rules 20 24 30 & 31
2013/12/24 tim Rowledge tim@rowledge.org
If you (or anyone else, of course) are interested in really speeding up bitblt, it would likely be worth looking at the ARM specific speedups Ben Avison did for the PI. (Look in platforms/Cross/plugins/BitBltPlugin) and seeing if similar tricks could be done with the assorted media instructions in current i7 etc cpus.
tim
tim Rowledge; tim@rowledge.org; http://www.rowledge.org/tim Experience is something you don't get until just after you need it.

On Tue, Dec 24, 2013 at 1:35 PM, Nicolas Cellier < nicolas.cellier.aka.nice@gmail.com> wrote:
Sure, I agree but this would require platform specific code... As I developped in the other thread, an alternative is to use native libraries where possible - that is when they perform an equivalent job (It would be Quartz or something like that for me). Such platform specific support will be harder to obtain, because it requires knowledge of VM plugin+external library or low level assembler... Plus the pain of diving into historical VM architecture (specifically in BitBlt, it's not that easy to get the full picture when you did not participate to the development - like me). I note that there is plenty of work required in this area, sort of technical debt. For example my MacOSX VMs do not support the little endian image formats yes (those with negative depth) which could be surprising if we didn't knew historical roots... ^Display supportedDisplayDepths
So, in a word, such platform specific support can certainly provide great rewards, but with significative investments. On the other hand, these little tricks are like harvesting low hanging fruits. They are made of pure C^H slang, thus valid on every platform which does not yet provide specific accelerated support. I'm lazy and just musing, so the fastest ROI is appealing.
Remember my little text composition/display benchs?
| text canvas m1 | canvas := FormCanvas extent: 569@399 depth: 32.text := Compiler evaluate: (FileStream fileNamed: 'text.st') contentsOfEntireFile. m1 := TextMorph new. m1 text: text textStyle: TextStyle default. m1 wrapFlag: true. m1 extent: 569@9999999. MessageTally spyOn: [ Time millisecondsToRun: [100 timesRepeat: [ m1 drawOn: canvas]]] Interpreter VM 4.10.10 Before bit hacks: 1425 1411 1403 Interpreter VM After bit hacks: 1152 1173
15 to 20% less, it's not really impressive, but the hurdle is low, just two bit-hacks applied to rules 20 24 30 & 31
On the contrary. That kind of speed-up in a mature tuned numerical algorithm is impressive. Thanks!
2013/12/24 tim Rowledge tim@rowledge.org
If you (or anyone else, of course) are interested in really speeding up bitblt, it would likely be worth looking at the ARM specific speedups Ben Avison did for the PI. (Look in platforms/Cross/plugins/BitBltPlugin) and seeing if similar tricks could be done with the assorted media instructions in current i7 etc cpus.
tim
tim Rowledge; tim@rowledge.org; http://www.rowledge.org/tim Experience is something you don't get until just after you need it.
2013/12/25 Eliot Miranda eliot.miranda@gmail.com
On Tue, Dec 24, 2013 at 1:35 PM, Nicolas Cellier < nicolas.cellier.aka.nice@gmail.com> wrote:
Sure, I agree but this would require platform specific code... As I developped in the other thread, an alternative is to use native libraries where possible - that is when they perform an equivalent job (It would be Quartz or something like that for me). Such platform specific support will be harder to obtain, because it requires knowledge of VM plugin+external library or low level assembler... Plus the pain of diving into historical VM architecture (specifically in BitBlt, it's not that easy to get the full picture when you did not participate to the development - like me). I note that there is plenty of work required in this area, sort of technical debt. For example my MacOSX VMs do not support the little endian image formats yes (those with negative depth) which could be surprising if we didn't knew historical roots... ^Display supportedDisplayDepths
So, in a word, such platform specific support can certainly provide great rewards, but with significative investments. On the other hand, these little tricks are like harvesting low hanging fruits. They are made of pure C^H slang, thus valid on every platform which does not yet provide specific accelerated support. I'm lazy and just musing, so the fastest ROI is appealing.
Remember my little text composition/display benchs?
| text canvas m1 | canvas := FormCanvas extent: 569@399 depth: 32.text := Compiler evaluate: (FileStream fileNamed: 'text.st') contentsOfEntireFile. m1 := TextMorph new. m1 text: text textStyle: TextStyle default. m1 wrapFlag: true. m1 extent: 569@9999999. MessageTally spyOn: [ Time millisecondsToRun: [100 timesRepeat: [ m1 drawOn: canvas]]] Interpreter VM 4.10.10 Before bit hacks: 1425 1411 1403 Interpreter VM After bit hacks: 1152 1173
15 to 20% less, it's not really impressive, but the hurdle is low, just two bit-hacks applied to rules 20 24 30 & 31
On the contrary. That kind of speed-up in a mature tuned numerical algorithm is impressive. Thanks!
Hem, except I messed up a bit the partittionAdd: ... Here is a correct version:
w1 := word1 bitAnd: carryOverflowMask. "mask to remove high bit of each component" w2 := word2 bitAnd: carryOverflowMask. sum := (word1 bitXor: w1)+(word2 bitXor: w2). "sum without high bit to avoid overflowing over next component" carryOverflow := (w1 bitAnd: w2) bitOr: ((w1 bitOr: w2) bitAnd: sum). "detect overflow condition for saturating" ^((sum bitXor: w1)bitXor:w2) "sum high bit without overflow" bitOr: carryOverflow>>(nBits-1) * componentMask "saturate in case of overflow"
And here is a simple test:
pb := OrderedCollection new. carryOverflowMask := 2r10101010. componentMask := 2r11. nBits := 2. (0 to: 16rFF) do: [:word1 | (0 to: 16rFF) do: [:word2 | w1 := (word1 bitAnd: carryOverflowMask). w2 := (word2 bitAnd: carryOverflowMask). sum := (word1 bitXor: w1)+(word2 bitXor: w2). carryOverflow := w1 + w2 + (sum bitAnd: carryOverflowMask). res1 := (((sum bitXor:w1)bitXor:w2) bitOr: (carryOverflow bitAnd: carryOverflowMask)>>(nBits-1) * componentMask). res2 := ((word1 bitAnd: 2r11)+(word2 bitAnd: 2r11) min: 2r11)+ ((word1 bitAnd: 2r1100)+(word2 bitAnd: 2r1100) min: 2r1100)+ ((word1 bitAnd: 2r110000)+(word2 bitAnd: 2r110000) min: 2r110000)+ ((word1 bitAnd: 2r11000000)+(word2 bitAnd: 2r11000000) min: 2r11000000). (res1 = res2) ifFalse: [pb add: {word1 printStringBase: 2. word2 printStringBase: 2. res1 printStringBase: 2. res2 printStringBase: 2.}]]]. ^pb
Fortunately, performance gain is preserved :)
2013/12/24 tim Rowledge tim@rowledge.org
If you (or anyone else, of course) are interested in really speeding up bitblt, it would likely be worth looking at the ARM specific speedups Ben Avison did for the PI. (Look in platforms/Cross/plugins/BitBltPlugin) and seeing if similar tricks could be done with the assorted media instructions in current i7 etc cpus.
tim
tim Rowledge; tim@rowledge.org; http://www.rowledge.org/tim Experience is something you don't get until just after you need it.
-- best, Eliot
This has been capitalized at http://bugs.squeak.org/view.php?id=7802 I use the old squeak mantis right now rather than cog issue tracker (abandonned?) or newest pharo fogbugz (restricted?) What do VM maintainers prefer? I don't really like the balkanisation in progress, and hope we can converge on some better communalisation again.
2013/12/26 Nicolas Cellier nicolas.cellier.aka.nice@gmail.com
2013/12/25 Eliot Miranda eliot.miranda@gmail.com
On Tue, Dec 24, 2013 at 1:35 PM, Nicolas Cellier < nicolas.cellier.aka.nice@gmail.com> wrote:
Sure, I agree but this would require platform specific code... As I developped in the other thread, an alternative is to use native libraries where possible - that is when they perform an equivalent job (It would be Quartz or something like that for me). Such platform specific support will be harder to obtain, because it requires knowledge of VM plugin+external library or low level assembler... Plus the pain of diving into historical VM architecture (specifically in BitBlt, it's not that easy to get the full picture when you did not participate to the development - like me). I note that there is plenty of work required in this area, sort of technical debt. For example my MacOSX VMs do not support the little endian image formats yes (those with negative depth) which could be surprising if we didn't knew historical roots... ^Display supportedDisplayDepths
So, in a word, such platform specific support can certainly provide great rewards, but with significative investments. On the other hand, these little tricks are like harvesting low hanging fruits. They are made of pure C^H slang, thus valid on every platform which does not yet provide specific accelerated support. I'm lazy and just musing, so the fastest ROI is appealing.
Remember my little text composition/display benchs?
| text canvas m1 | canvas := FormCanvas extent: 569@399 depth: 32.text := Compiler evaluate: (FileStream fileNamed: 'text.st') contentsOfEntireFile. m1 := TextMorph new. m1 text: text textStyle: TextStyle default. m1 wrapFlag: true. m1 extent: 569@9999999. MessageTally spyOn: [ Time millisecondsToRun: [100 timesRepeat: [ m1 drawOn: canvas]]] Interpreter VM 4.10.10 Before bit hacks: 1425 1411 1403 Interpreter VM After bit hacks: 1152 1173
15 to 20% less, it's not really impressive, but the hurdle is low, just two bit-hacks applied to rules 20 24 30 & 31
On the contrary. That kind of speed-up in a mature tuned numerical algorithm is impressive. Thanks!
Hem, except I messed up a bit the partittionAdd: ... Here is a correct version:
w1 := word1 bitAnd: carryOverflowMask. "mask to remove high bit ofeach component" w2 := word2 bitAnd: carryOverflowMask. sum := (word1 bitXor: w1)+(word2 bitXor: w2). "sum without high bit to avoid overflowing over next component" carryOverflow := (w1 bitAnd: w2) bitOr: ((w1 bitOr: w2) bitAnd: sum). "detect overflow condition for saturating" ^((sum bitXor: w1)bitXor:w2) "sum high bit without overflow" bitOr: carryOverflow>>(nBits-1) * componentMask "saturate in case of overflow"
And here is a simple test:
pb := OrderedCollection new. carryOverflowMask := 2r10101010. componentMask := 2r11. nBits := 2. (0 to: 16rFF) do: [:word1 | (0 to: 16rFF) do: [:word2 | w1 := (word1 bitAnd: carryOverflowMask). w2 := (word2 bitAnd: carryOverflowMask). sum := (word1 bitXor: w1)+(word2 bitXor: w2). carryOverflow := w1 + w2 + (sum bitAnd: carryOverflowMask). res1 := (((sum bitXor:w1)bitXor:w2) bitOr: (carryOverflow bitAnd: carryOverflowMask)>>(nBits-1) * componentMask). res2 := ((word1 bitAnd: 2r11)+(word2 bitAnd: 2r11) min: 2r11)+ ((word1 bitAnd: 2r1100)+(word2 bitAnd: 2r1100) min: 2r1100)+ ((word1 bitAnd: 2r110000)+(word2 bitAnd: 2r110000) min: 2r110000)+ ((word1 bitAnd: 2r11000000)+(word2 bitAnd: 2r11000000) min: 2r11000000). (res1 = res2) ifFalse: [pb add: {word1 printStringBase: 2. word2 printStringBase: 2. res1 printStringBase: 2. res2 printStringBase: 2.}]]]. ^pb
Fortunately, performance gain is preserved :)
2013/12/24 tim Rowledge tim@rowledge.org
If you (or anyone else, of course) are interested in really speeding up bitblt, it would likely be worth looking at the ARM specific speedups Ben Avison did for the PI. (Look in platforms/Cross/plugins/BitBltPlugin) and seeing if similar tricks could be done with the assorted media instructions in current i7 etc cpus.
tim
tim Rowledge; tim@rowledge.org; http://www.rowledge.org/tim Experience is something you don't get until just after you need it.
-- best, Eliot

On Fri, Dec 27, 2013 at 06:06:02PM +0100, Nicolas Cellier wrote:
This has been capitalized at http://bugs.squeak.org/view.php?id=7802 I use the old squeak mantis right now rather than cog issue tracker (abandonned?) or newest pharo fogbugz (restricted?) What do VM maintainers prefer?
Thanks for opening this issue on the mantis tracker. That happens to be the one that I use to try to keep track of issues that may take some time to resolve, and/or that require coordiation between multiple people.
I have been watching #7802 with interest (though I am not a bitblt expert) and I will make sure that your updates get into the trunk VMM, and will coordinate with Eliot and/or add it to oscog directory. The trunk and oscog branches are pretty much identical in this area, so it's just a matter of keeping both updated, with is not a problem.
From my point of view, the bugs.squeak.org issue tracker is the one that
I watch. I don't have an account on fogbugz, although I do read the pharo mailing list and try to keep up to date with issues that get mentioned there.
The cog issue tracker was a good idea, although I think it probably got abandoned when people moved to fogbugz, so I do not try to keep track of it now.
I don't really like the balkanisation in progress, and hope we can converge on some better communalisation again.
<curmudgeon alert>
Inventing a new process is easy. To actually use an existing process that someone else invented is hard. Or so it would seem.
I see the same problem in my corporate IT environments. Everybody wants to invent ways for the other guy to be more productive and nobody wants to use the other guy's ideas to actually *be* productive. I think we are raising a whole new generation of consultants who will all be experts on how the other guy should be working if only he was as smart as me :-(
I should not complain because I make my living as a consultant. But still I dream of a world where people like me are not needed. Then I can retire and be happy.
</curmudgeon alert>
Dave
Here is an update about performances: I compared two images that were too much distant (bitblt was not the only change, but there are other (Large)Integer hacks...)
If I take two interpreter VM with only differences in BitBltPlugin rgbAdd/alphaBlend/alphaBlendScaled, then the micro benchmark are unchanged (-25% of run time in 32bit depth) but the text display macro benchmark is less spectacular, only -6% of runtime.
The good news is that the macro -15% are somehow achievable by other means.
It remain to be measured in COG. My results are not reliable so far. Here again, I have too many differences between the VM used for bench, including recent changes from Eliot, and C compiler (LLVM 1.7 vs GCC 4.2, from old Xcode 3.2). I also experiment some lack of repeatability for which I did not identify the root cause.
2013/12/30 David T. Lewis lewis@mail.msen.com
On Fri, Dec 27, 2013 at 06:06:02PM +0100, Nicolas Cellier wrote:
This has been capitalized at http://bugs.squeak.org/view.php?id=7802 I use the old squeak mantis right now rather than cog issue tracker (abandonned?) or newest pharo fogbugz (restricted?) What do VM maintainers prefer?
Thanks for opening this issue on the mantis tracker. That happens to be the one that I use to try to keep track of issues that may take some time to resolve, and/or that require coordiation between multiple people.
I have been watching #7802 with interest (though I am not a bitblt expert) and I will make sure that your updates get into the trunk VMM, and will coordinate with Eliot and/or add it to oscog directory. The trunk and oscog branches are pretty much identical in this area, so it's just a matter of keeping both updated, with is not a problem.
From my point of view, the bugs.squeak.org issue tracker is the one that
I watch. I don't have an account on fogbugz, although I do read the pharo mailing list and try to keep up to date with issues that get mentioned there.
The cog issue tracker was a good idea, although I think it probably got abandoned when people moved to fogbugz, so I do not try to keep track of it now.
I don't really like the balkanisation in progress, and hope we can
converge
on some better communalisation again.
<curmudgeon alert>
Inventing a new process is easy. To actually use an existing process that someone else invented is hard. Or so it would seem.
I see the same problem in my corporate IT environments. Everybody wants to invent ways for the other guy to be more productive and nobody wants to use the other guy's ideas to actually *be* productive. I think we are raising a whole new generation of consultants who will all be experts on how the other guy should be working if only he was as smart as me :-(
I should not complain because I make my living as a consultant. But still I dream of a world where people like me are not needed. Then I can retire and be happy.
</curmudgeon alert>
Dave
I added your enhancements for the rgbAdd rule and the alpha blending rules in VMMaker for both the interpreter and Cog VM.
I did not try to measure performance, but my expectation would be that the relative performance improvement will be even greater for Cog than what you measured with the interpreter VM, because your improvements affect the compiled primitives.
Great stuff, thanks!
Dave
On Mon, Dec 30, 2013 at 02:03:29AM +0100, Nicolas Cellier wrote:
Here is an update about performances: I compared two images that were too much distant (bitblt was not the only change, but there are other (Large)Integer hacks...)
If I take two interpreter VM with only differences in BitBltPlugin rgbAdd/alphaBlend/alphaBlendScaled, then the micro benchmark are unchanged (-25% of run time in 32bit depth) but the text display macro benchmark is less spectacular, only -6% of runtime.
The good news is that the macro -15% are somehow achievable by other means.
It remain to be measured in COG. My results are not reliable so far. Here again, I have too many differences between the VM used for bench, including recent changes from Eliot, and C compiler (LLVM 1.7 vs GCC 4.2, from old Xcode 3.2). I also experiment some lack of repeatability for which I did not identify the root cause.
2013/12/30 David T. Lewis lewis@mail.msen.com
On Fri, Dec 27, 2013 at 06:06:02PM +0100, Nicolas Cellier wrote:
This has been capitalized at http://bugs.squeak.org/view.php?id=7802 I use the old squeak mantis right now rather than cog issue tracker (abandonned?) or newest pharo fogbugz (restricted?) What do VM maintainers prefer?
Thanks for opening this issue on the mantis tracker. That happens to be the one that I use to try to keep track of issues that may take some time to resolve, and/or that require coordiation between multiple people.
I have been watching #7802 with interest (though I am not a bitblt expert) and I will make sure that your updates get into the trunk VMM, and will coordinate with Eliot and/or add it to oscog directory. The trunk and oscog branches are pretty much identical in this area, so it's just a matter of keeping both updated, with is not a problem.
From my point of view, the bugs.squeak.org issue tracker is the one that
I watch. I don't have an account on fogbugz, although I do read the pharo mailing list and try to keep up to date with issues that get mentioned there.
The cog issue tracker was a good idea, although I think it probably got abandoned when people moved to fogbugz, so I do not try to keep track of it now.
I don't really like the balkanisation in progress, and hope we can
converge
on some better communalisation again.
<curmudgeon alert>
Inventing a new process is easy. To actually use an existing process that someone else invented is hard. Or so it would seem.
I see the same problem in my corporate IT environments. Everybody wants to invent ways for the other guy to be more productive and nobody wants to use the other guy's ideas to actually *be* productive. I think we are raising a whole new generation of consultants who will all be experts on how the other guy should be working if only he was as smart as me :-(
I should not complain because I make my living as a consultant. But still I dream of a world where people like me are not needed. Then I can retire and be happy.
</curmudgeon alert>
Dave

In Eliot's first example on fixing the reentrancy problem that uses "factorial copy" for the recursion.
I modifed his code:
| factorial | factorial := [:n| n = 1 ifTrue: [1] ifFalse: [(factorial copy value: n - 1) * n]]. (1 to: 10) collect: factorial copy
into something I could trace out a bit easier.
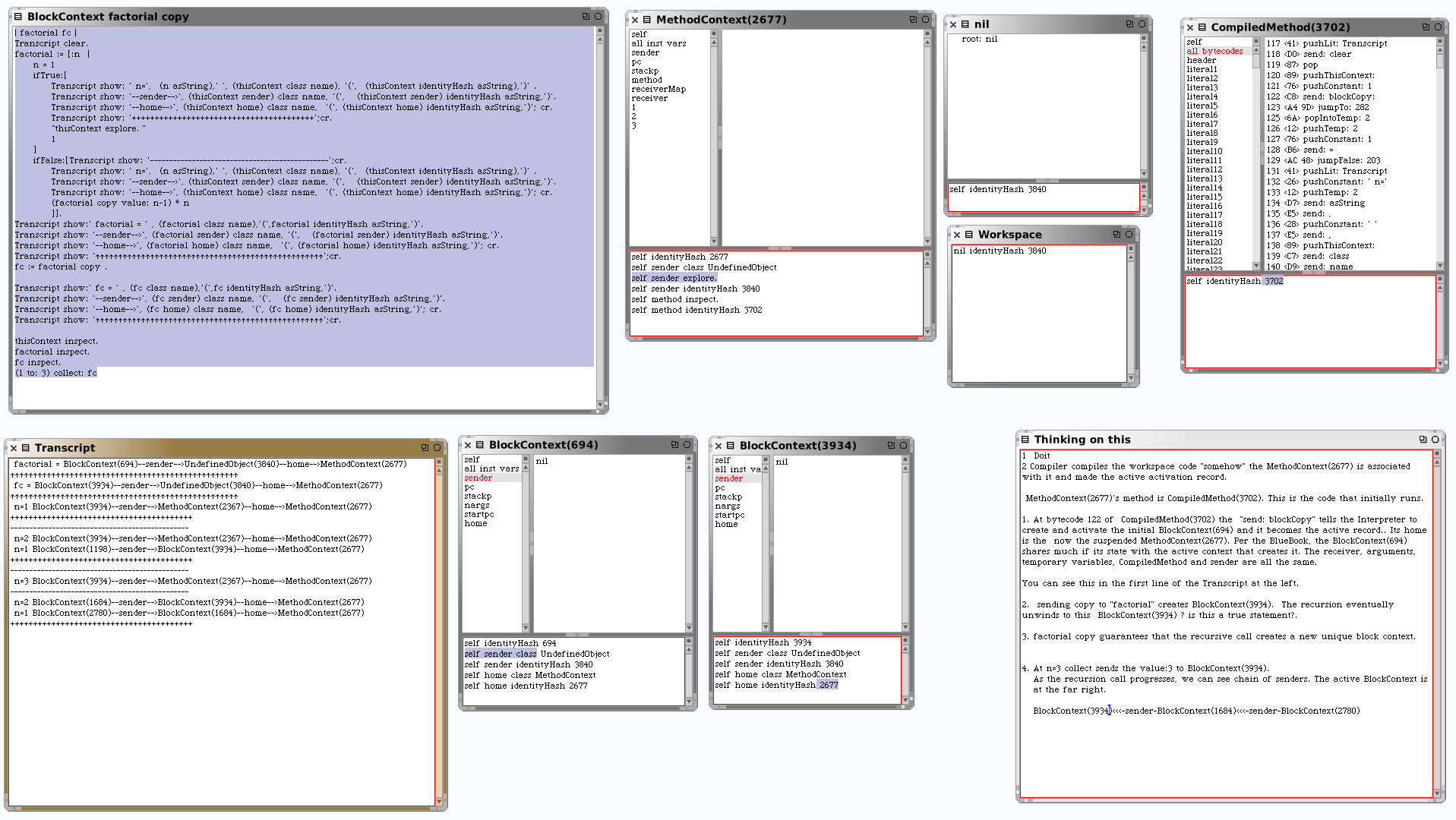
| factorial fc | Transcript clear. factorial := [:n | n = 1 ifTrue:[ Transcript show: ' n=', (n asString),' ', (thisContext class name), '(', (thisContext identityHash asString),')' . Transcript show: '--sender-->', (thisContext sender) class name, '(', (thisContext sender) identityHash asString,')'. Transcript show: '--home-->', (thisContext home) class name, '(', (thisContext home) identityHash asString,')'; cr. Transcript show: '++++++++++++++++++++++++++++++++++++++++';cr. "thisContext explore. " 1 ] ifFalse:[ Transcript show: '-----------------------------------------------';cr. Transcript show: ' n=', (n asString),' ', (thisContext class name), '(', (thisContext identityHash asString),')' . Transcript show: '--sender-->', (thisContext sender) class name, '(', (thisContext sender) identityHash asString,')'. Transcript show: '--home-->', (thisContext home) class name, '(', (thisContext home) identityHash asString,')'; cr. (factorial copy value: n-1) * n ]]. Transcript show:' factorial = ' , (factorial class name),'(',factorial identityHash asString,')'. Transcript show: '--sender-->', (factorial sender) class name, '(', (factorial sender) identityHash asString,')'. Transcript show: '--home-->', (factorial home) class name, '(', (factorial home) identityHash asString,')'; cr. Transcript show: '^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^';cr. fc := factorial copy .
Transcript show:' fc = ' , (fc class name),'(',fc identityHash asString,')'. Transcript show: '--sender-->', (fc sender) class name, '(', (fc sender) identityHash asString,')'. Transcript show: '--home-->', (fc home) class name, '(', (fc home) identityHash asString,')'; cr. Transcript show: '^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^';cr.
thisContext inspect. factorial inspect. fc inspect. (1 to: 3) collect: fc
The Transcript output is as follows:
factorial = BlockContext(694)--sender-->UndefinedObject(3840)--home-->MethodContext(2677) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ fc = BlockContext(3934)--sender-->UndefinedObject(3840)--home-->MethodContext(2677) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ n=1 BlockContext(3934)--sender-->MethodContext(2367)--home-->MethodContext(2677) ++++++++++++++++++++++++++++++++++++++++ ----------------------------------------------- n=2 BlockContext(3934)--sender-->MethodContext(2367)--home-->MethodContext(2677) n=1 BlockContext(1198)--sender-->BlockContext(3934)--home-->MethodContext(2677) ++++++++++++++++++++++++++++++++++++++++ ----------------------------------------------- n=3 BlockContext(3934)--sender-->MethodContext(2367)--home-->MethodContext(2677) ----------------------------------------------- n=2 BlockContext(1684)--sender-->BlockContext(3934)--home-->MethodContext(2677) n=1 BlockContext(2780)--sender-->BlockContext(1684)--home-->MethodContext(2677) ++++++++++++++++++++++++++++++++++++++++
Look at the 3'rd line, where n=1. Why is the sender-->MethodContext(2367) instead of sender-->MethodContext(2677) What created that new MethodContext?
A screenshot of my Squeak 4.0 session is attached if the above gets mangled in posting this.
Thank you for your time.
tty
{kind=link}

On Wed, Jan 1, 2014 at 2:55 PM, gettimothy gettimothy@zoho.com wrote:
In Eliot's first example on fixing the reentrancy problemhttp://www.mirandabanda.org/cogblog/category/cog/page/14/that uses "factorial copy" for the recursion.
I modifed his code:
| factorial | factorial := [:n| n = 1 ifTrue: [1] ifFalse: [(factorial copy value: n - 1) * n]]. (1 to: 10) collect: factorial copy
into something I could trace out a bit easier.
| factorial fc | Transcript clear. factorial := [:n | n = 1 ifTrue:[ Transcript show: ' n=', (n asString),' ', (thisContext class name), '(', (thisContext identityHash asString),')' . Transcript show: '--sender-->', (thisContext sender) class name, '(', (thisContext sender) identityHash asString,')'. Transcript show: '--home-->', (thisContext home) class name, '(', (thisContext home) identityHash asString,')'; cr.
Transcript show: '++++++++++++++++++++++++++++++++++++++++';cr. "thisContext explore. " 1 ] ifFalse:[ Transcript show:'-----------------------------------------------';cr. Transcript show: ' n=', (n asString),' ', (thisContext class name), '(', (thisContext identityHash asString),')' . Transcript show: '--sender-->', (thisContext sender) class name, '(', (thisContext sender) identityHash asString,')'. Transcript show: '--home-->', (thisContext home) class name, '(', (thisContext home) identityHash asString,')'; cr.
(factorial copy value: n-1) * n ]].Transcript show:' factorial = ' , (factorial class name),'(',factorial identityHash asString,')'. Transcript show: '--sender-->', (factorial sender) class name, '(', (factorial sender) identityHash asString,')'. Transcript show: '--home-->', (factorial home) class name, '(', (factorial home) identityHash asString,')'; cr. Transcript show: '^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^';cr.
fc := factorial copy .
Transcript show:' fc = ' , (fc class name),'(',fc identityHash asString,')'. Transcript show: '--sender-->', (fc sender) class name, '(', (fc sender) identityHash asString,')'. Transcript show: '--home-->', (fc home) class name, '(', (fc home) identityHash asString,')'; cr. Transcript show: '^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^';cr.
thisContext inspect. factorial inspect. fc inspect. (1 to: 3) collect: fc
The Transcript output is as follows:
factorial = BlockContext(694)--sender-->UndefinedObject(3840)--home-->MethodContext(2677) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ fc = BlockContext(3934)--sender-->UndefinedObject(3840)--home-->MethodContext(2677) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ n=1 BlockContext(3934)--sender-->MethodContext(2367)--home-->MethodContext(2677)
++++++++++++++++++++++++++++++++++++++++
n=2 BlockContext(3934)--sender-->MethodContext(2367)--home-->MethodContext(2677) n=1 BlockContext(1198)--sender-->BlockContext(3934)--home-->MethodContext(2677)
++++++++++++++++++++++++++++++++++++++++
n=3 BlockContext(3934)--sender-->MethodContext(2367)--home-->MethodContext(2677)
n=2 BlockContext(1684)--sender-->BlockContext(3934)--home-->MethodContext(2677) n=1 BlockContext(2780)--sender-->BlockContext(1684)--home-->MethodContext(2677) ++++++++++++++++++++++++++++++++++++++++
http://www.mirandabanda.org/cogblog/category/cog/page/14/ Look at the 3'rd line, where n=1. Why is the sender-->MethodContext(2367) instead of sender-->MethodContext(2677) What created that new MethodContext?
That would be the activation of Interval>>collect:, which performs the first call of the copied factorial block for each 1 through 3.
collect: aBlock | nextValue result | result := self species new: self size. nextValue := start. 1 to: result size do: [:i | result at: i put: (*aBlock value: nextValue*). nextValue := nextValue + step]. ^ result
Thank you.
I had the mis-conception of 1 MethodContext representing the code in that Doit.
From the BlueBook
A MethodContext ... Represents the execution of a CompiledMethod in response to a message.
Funny how you can read a thing a dozen times and until you try to do something with it, you don't really understand it.
Thanks again for your help.
---- On Wed, 01 Jan 2014 14:15:01 -0800 Ryan Macnak<rmacnak@gmail.com> wrote ----
On Wed, Jan 1, 2014 at 2:55 PM, gettimothy <gettimothy@zoho.com> wrote:
In Eliot's first example on fixing the reentrancy problem that uses "factorial copy" for the recursion.
I modifed his code:
| factorial | factorial := [:n| n = 1 ifTrue: [1] ifFalse: [(factorial copy value: n - 1) * n]]. (1 to: 10) collect: factorial copy
into something I could trace out a bit easier.
| factorial fc | Transcript clear. factorial := [:n | n = 1 ifTrue:[ Transcript show: ' n=', (n asString),' ', (thisContext class name), '(', (thisContext identityHash asString),')' . Transcript show: '--sender-->', (thisContext sender) class name, '(', (thisContext sender) identityHash asString,')'. Transcript show: '--home-->', (thisContext home) class name, '(', (thisContext home) identityHash asString,')'; cr. Transcript show: '++++++++++++++++++++++++++++++++++++++++';cr. "thisContext explore. " 1 ] ifFalse:[ Transcript show: '-----------------------------------------------';cr. Transcript show: ' n=', (n asString),' ', (thisContext class name), '(', (thisContext identityHash asString),')' . Transcript show: '--sender-->', (thisContext sender) class name, '(', (thisContext sender) identityHash asString,')'. Transcript show: '--home-->', (thisContext home) class name, '(', (thisContext home) identityHash asString,')'; cr. (factorial copy value: n-1) * n ]]. Transcript show:' factorial = ' , (factorial class name),'(',factorial identityHash asString,')'. Transcript show: '--sender-->', (factorial sender) class name, '(', (factorial sender) identityHash asString,')'. Transcript show: '--home-->', (factorial home) class name, '(', (factorial home) identityHash asString,')'; cr. Transcript show: '^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^';cr. fc := factorial copy .
Transcript show:' fc = ' , (fc class name),'(',fc identityHash asString,')'. Transcript show: '--sender-->', (fc sender) class name, '(', (fc sender) identityHash asString,')'. Transcript show: '--home-->', (fc home) class name, '(', (fc home) identityHash asString,')'; cr. Transcript show: '^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^';cr.
thisContext inspect. factorial inspect. fc inspect. (1 to: 3) collect: fc
The Transcript output is as follows:
factorial = BlockContext(694)--sender-->UndefinedObject(3840)--home-->MethodContext(2677) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ fc = BlockContext(3934)--sender-->UndefinedObject(3840)--home-->MethodContext(2677) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ n=1 BlockContext(3934)--sender-->MethodContext(2367)--home-->MethodContext(2677) ++++++++++++++++++++++++++++++++++++++++ ----------------------------------------------- n=2 BlockContext(3934)--sender-->MethodContext(2367)--home-->MethodContext(2677) n=1 BlockContext(1198)--sender-->BlockContext(3934)--home-->MethodContext(2677) ++++++++++++++++++++++++++++++++++++++++ ----------------------------------------------- n=3 BlockContext(3934)--sender-->MethodContext(2367)--home-->MethodContext(2677) ----------------------------------------------- n=2 BlockContext(1684)--sender-->BlockContext(3934)--home-->MethodContext(2677) n=1 BlockContext(2780)--sender-->BlockContext(1684)--home-->MethodContext(2677) ++++++++++++++++++++++++++++++++++++++++
Look at the 3'rd line, where n=1. Why is the sender-->MethodContext(2367) instead of sender-->MethodContext(2677) What created that new MethodContext?
That would be the activation of Interval>>collect:, which performs the first call of the copied factorial block for each 1 through 3.
collect: aBlock | nextValue result | result := self species new: self size. nextValue := start. 1 to: result size do: [:i | result at: i put: (aBlock value: nextValue). nextValue := nextValue + step]. ^ result
I figured that as I studied the VM stuff, it would be helpful to start compiling a book that others can use down the road. The goal is to make it easier for people like me who know zero about this, to be able to ramp up using a good pedagogical method.
I have successfully downloaded and compiled the Squeak By Example LaTeX source and I am using that source tree as my template and I will be recording what I learn into it.
If anybody is interested with suggestions on what chapters should be in there and what order they should be in, then please chime and I can start building a skeleton.
If the community wants an open book, I am happy to build that skeleton and turn it over to whoever wants to put it up on github.
As for content, I would like it to include historical progressions so the sense of how and why things progress over time is captured. An obvious example is this BlockContext to BlockClosure progression I am currently getting my head around.
My only caveat is that it not infringe on Eliot's wallet. He has stated on his blog that his notes are the starting point for a book and it would not be fair to deprive him of the $$ he has earned for his knowledge. If Eliot objects to this effort, I will not step on his toes and my offer is retracted.
thx
tty
On Thu, Jan 2, 2014 at 9:58 AM, gettimothy gettimothy@zoho.com wrote:
I figured that as I studied the VM stuff, it would be helpful to start compiling a book that others can use down the road. The goal is to make it easier for people like me who know zero about this, to be able to ramp up using a good pedagogical method.
I have successfully downloaded and compiled the Squeak By Example LaTeX source and I am using that source tree as my template and I will be recording what I learn into it.
If anybody is interested with suggestions on what chapters should be in there and what order they should be in, then please chime and I can start building a skeleton.
If the community wants an open book, I am happy to build that skeleton and turn it over to whoever wants to put it up on github.
As for content, I would like it to include historical progressions so the sense of how and why things progress over time is captured. An obvious example is this BlockContext to BlockClosure progression I am currently getting my head around.
My only caveat is that it not infringe on Eliot's wallet. He has stated on his blog that his notes are the starting point for a book and it would not be fair to deprive him of the $$ he has earned for his knowledge. If Eliot objects to this effort, I will not step on his toes and my offer is retracted.
No objection. My blog's proving to fitful and perhaps too specific to turn into a book any time soon. BTW, I'd love to see the last section of the blue book rewritten around a modern VM.
thx
tty
That is wonderful news.
Thank you Eliot.
I have added "recreate the last section of the blue book rewritten around a modern VM. " to my notes.
cordially
tty
---- On Sun, 05 Jan 2014 22:50:47 -0800 Eliot Miranda <eliot.miranda@gmail.com> wrote ----
On Thu, Jan 2, 2014 at 9:58 AM, gettimothy <gettimothy@zoho.com> wrote:
I figured that as I studied the VM stuff, it would be helpful to start compiling a book that others can use down the road. The goal is to make it easier for people like me who know zero about this, to be able to ramp up using a good pedagogical method.
I have successfully downloaded and compiled the Squeak By Example LaTeX source and I am using that source tree as my template and I will be recording what I learn into it.
If anybody is interested with suggestions on what chapters should be in there and what order they should be in, then please chime and I can start building a skeleton.
If the community wants an open book, I am happy to build that skeleton and turn it over to whoever wants to put it up on github.
As for content, I would like it to include historical progressions so the sense of how and why things progress over time is captured. An obvious example is this BlockContext to BlockClosure progression I am currently getting my head around.
My only caveat is that it not infringe on Eliot's wallet. He has stated on his blog that his notes are the starting point for a book and it would not be fair to deprive him of the $$ he has earned for his knowledge. If Eliot objects to this effort, I will not step on his toes and my offer is retracted.
No objection. My blog's proving to fitful and perhaps too specific to turn into a book any time soon. BTW, I'd love to see the last section of the blue book rewritten around a modern VM.
thx
tty
Referring to my earlier post on the trace of the Block/Method Contexts, at n=1, n=2, n=3 We see, per Ryan pointing it out, that MethodContext(2367) is activated 3 times.
To me this is obviously caching in action. If its not, please give me a heads up.
thank you for your time.
tty
factorial = BlockContext(694)--sender-->UndefinedObject(3840)--home-->MethodContext(2677) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ fc = BlockContext(3934)--sender-->UndefinedObject(3840)--home-->MethodContext(2677) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ n=1 BlockContext(3934)--sender-->MethodContext(2367)--home-->MethodContext(2677) ++++++++++++++++++++++++++++++++++++++++ ----------------------------------------------- n=2 BlockContext(3934)--sender-->MethodContext(2367)--home-->MethodContext(2677) n=1 BlockContext(1198)--sender-->BlockContext(3934)--home-->MethodContext(2677) ++++++++++++++++++++++++++++++++++++++++ ----------------------------------------------- n=3 BlockContext(3934)--sender-->MethodContext(2367)--home-->MethodContext(2677) ----------------------------------------------- n=2 BlockContext(1684)--sender-->BlockContext(3934)--home-->MethodContext(2677) n=1 BlockContext(2780)--sender-->BlockContext(1684)--home-->MethodContext(2677) ++++++++++++++++++++++++++++++++++++++++ ---- On Wed, 01 Jan 2014 14:15:01 -0800 Ryan Macnak <rmacnak@gmail.com> wrote ----
On 02-01-2014, at 9:33 AM, gettimothy gettimothy@zoho.com wrote:
Referring to my earlier post on the trace of the Block/Method Contexts, at n=1, n=2, n=3 We see, per Ryan pointing it out, that MethodContext(2367) is activated 3 times.
To me this is obviously caching in action. If its not, please give me a heads up.
Without having looked in any detail at the code I’d say it is more likely to be the simple context recycling in action. It’s a very, very, long time since I did anything in that area but I have this vague memory of used contexts getting stuck on a list (so yes, a very simplistic cache of sorts) and being available for use the next time a new context is needed. Ah, here we are - look for allocateOrRecycleContext
tim -- tim Rowledge; tim@rowledge.org; http://www.rowledge.org/tim egret - apology by email
Awesome Tim.
Thank you.
I am adding your insight to the book notes.
tty.
---- On Thu, 02 Jan 2014 10:06:45 -0800 tim Rowledge<tim@rowledge.org> wrote ----
On 02-01-2014, at 9:33 AM, gettimothy <gettimothy@zoho.com> wrote:
> Referring to my earlier post on the trace of the Block/Method Contexts, at n=1, n=2, n=3 We see, per Ryan pointing it out, that MethodContext(2367) is activated 3 times. > > To me this is obviously caching in action. If its not, please give me a heads up.
Without having looked in any detail at the code I’d say it is more likely to be the simple context recycling in action. It’s a very, very, long time since I did anything in that area but I have this vague memory of used contexts getting stuck on a list (so yes, a very simplistic cache of sorts) and being available for use the next time a new context is needed. Ah, here we are - look for allocateOrRecycleContext
tim
Is there a term for all the Method/Block Contexts that are invoked prior to a DoIt getting to
Compiler>>evaluate: textOrStream in: aContext to: receiver notifying: aRequestor ifFail: failBlock logged: logFlag
?
I know this is just semantics, but before there is a lot of "Context" going on before the first MethodContext of
| factorial |
factorial := [:n | n = 1 ifTrue:[ 1 ] ifFalse:[ (factorial copy value: n-1) * n]]. (1 to: 3) collect: factorial copy .
is activated.
Just curious if there is a term for that that people use.
thx.
ttty

On 03.01.2014, at 00:33, gettimothy gettimothy@zoho.com wrote:
Is there a term for all the Method/Block Contexts that are invoked prior to a DoIt getting to
Compiler>>evaluate: textOrStream in: aContext to: receiver notifying: aRequestor ifFail: failBlock logged: logFlag
?
I know this is just semantics, but before there is a lot of "Context" going on before the first MethodContext of
| factorial |
factorial := [:n | n = 1 ifTrue:[ 1 ] ifFalse:[ (factorial copy value: n-1) * n]]. (1 to: 3) collect: factorial copy .
is activated.
Just curious if there is a term for that that people use.
thx.
ttty
I'd call it "user interface code". If you refer to the stack dump below, you see that the TextEditor pretty much directly invokes the Compiler, triggered by a keystroke event that is handled by the hierarchy of morphs and generated by the Morphic main loop (with a slight diversion via the ToolSet layer).
- Bert -
UndefinedObject>>DoIt Compiler>>evaluateCue:ifFail: Compiler>>evaluateCue:ifFail:logged: Compiler>>evaluate:in:to:notifying:ifFail:logged: [] in SmalltalkEditor(TextEditor)>>evaluateSelectionAndDo: BlockClosure>>on:do: SmalltalkEditor(TextEditor)>>evaluateSelectionAndDo: SmalltalkEditor(TextEditor)>>printIt SmalltalkEditor(TextEditor)>>printIt: SmalltalkEditor(TextEditor)>>dispatchOnKeyboardEvent: SmalltalkEditor(TextEditor)>>keyStroke: [] in [] in TextMorphForEditView(TextMorph)>>keyStroke: TextMorphForEditView(TextMorph)>>handleInteraction:fromEvent: TextMorphForEditView>>handleInteraction:fromEvent: [] in TextMorphForEditView(TextMorph)>>keyStroke: StandardToolSet class>>codeCompletionAround:textMorph:keyStroke: ToolSet class>>codeCompletionAround:textMorph:keyStroke: TextMorphForEditView(TextMorph)>>keyStroke: TextMorphForEditView>>keyStroke: TextMorphForEditView(TextMorph)>>handleKeystroke: KeyboardEvent>>sentTo: TextMorphForEditView(Morph)>>handleEvent: TextMorphForEditView(Morph)>>handleFocusEvent: [] in HandMorph>>sendFocusEvent:to:clear: BlockClosure>>on:do: PasteUpMorph>>becomeActiveDuring: HandMorph>>sendFocusEvent:to:clear: HandMorph>>sendEvent:focus:clear: HandMorph>>sendKeyboardEvent: HandMorph>>handleEvent: HandMorph>>processEvents [] in WorldState>>doOneCycleNowFor: Array(SequenceableCollection)>>do: WorldState>>handsDo: WorldState>>doOneCycleNowFor: WorldState>>doOneCycleFor: PasteUpMorph>>doOneCycle [] in MorphicProject>>spawnNewProcess [] in BlockClosure>>newProcess
And no, "marshalling" has nothing to do with this. Neither is it a topic for the vm-dev list, really.
- Bert -
On 04.01.2014, at 14:37, Bert Freudenberg bert@freudenbergs.de wrote:
On 03.01.2014, at 00:33, gettimothy gettimothy@zoho.com wrote:
Is there a term for all the Method/Block Contexts that are invoked prior to a DoIt getting to
Compiler>>evaluate: textOrStream in: aContext to: receiver notifying: aRequestor ifFail: failBlock logged: logFlag
?
I know this is just semantics, but before there is a lot of "Context" going on before the first MethodContext of
| factorial |
factorial := [:n | n = 1 ifTrue:[ 1 ] ifFalse:[ (factorial copy value: n-1) * n]]. (1 to: 3) collect: factorial copy .
is activated.
Just curious if there is a term for that that people use.
thx.
ttty
I'd call it "user interface code". If you refer to the stack dump below, you see that the TextEditor pretty much directly invokes the Compiler, triggered by a keystroke event that is handled by the hierarchy of morphs and generated by the Morphic main loop (with a slight diversion via the ToolSet layer).
- Bert -
UndefinedObject>>DoIt Compiler>>evaluateCue:ifFail: Compiler>>evaluateCue:ifFail:logged: Compiler>>evaluate:in:to:notifying:ifFail:logged: [] in SmalltalkEditor(TextEditor)>>evaluateSelectionAndDo: BlockClosure>>on:do: SmalltalkEditor(TextEditor)>>evaluateSelectionAndDo: SmalltalkEditor(TextEditor)>>printIt SmalltalkEditor(TextEditor)>>printIt: SmalltalkEditor(TextEditor)>>dispatchOnKeyboardEvent: SmalltalkEditor(TextEditor)>>keyStroke: [] in [] in TextMorphForEditView(TextMorph)>>keyStroke: TextMorphForEditView(TextMorph)>>handleInteraction:fromEvent: TextMorphForEditView>>handleInteraction:fromEvent: [] in TextMorphForEditView(TextMorph)>>keyStroke: StandardToolSet class>>codeCompletionAround:textMorph:keyStroke: ToolSet class>>codeCompletionAround:textMorph:keyStroke: TextMorphForEditView(TextMorph)>>keyStroke: TextMorphForEditView>>keyStroke: TextMorphForEditView(TextMorph)>>handleKeystroke: KeyboardEvent>>sentTo: TextMorphForEditView(Morph)>>handleEvent: TextMorphForEditView(Morph)>>handleFocusEvent: [] in HandMorph>>sendFocusEvent:to:clear: BlockClosure>>on:do: PasteUpMorph>>becomeActiveDuring: HandMorph>>sendFocusEvent:to:clear: HandMorph>>sendEvent:focus:clear: HandMorph>>sendKeyboardEvent: HandMorph>>handleEvent: HandMorph>>processEvents [] in WorldState>>doOneCycleNowFor: Array(SequenceableCollection)>>do: WorldState>>handsDo: WorldState>>doOneCycleNowFor: WorldState>>doOneCycleFor: PasteUpMorph>>doOneCycle [] in MorphicProject>>spawnNewProcess [] in BlockClosure>>newProcess
Thanks.
I will post stuff like this to vm-beginners from now on.
fwiw, having observed, for the first time, "stuff that happens before my code runs" ->my code running in the active context-->"is there stuff that happens after my code runs?" I just wanted to use the correct terms for the pre and post processes, if they exist.
cordially,
tty
---- On Sat, 04 Jan 2014 05:42:39 -0800 Bert Freudenberg <bert@freudenbergs.de> wrote ----
And no, "marshalling" has nothing to do with this. Neither is it a topic for the vm-dev list, really.
- Bert -
On 04.01.2014, at 14:37, Bert Freudenberg <bert@freudenbergs.de> wrote:
On 03.01.2014, at 00:33, gettimothy <gettimothy@zoho.com> wrote:
Is there a term for all the Method/Block Contexts that are invoked prior to a DoIt getting to
Compiler>>evaluate: textOrStream in: aContext to: receiver notifying: aRequestor ifFail: failBlock logged: logFlag ?
I know this is just semantics, but before there is a lot of "Context" going on before the first MethodContext of
| factorial |
factorial := [:n | n = 1 ifTrue:[ 1 ] ifFalse:[ (factorial copy value: n-1) * n]]. (1 to: 3) collect: factorial copy . is activated.
Just curious if there is a term for that that people use.
thx.
ttty
I'd call it "user interface code". If you refer to the stack dump below, you see that the TextEditor pretty much directly invokes the Compiler, triggered by a keystroke event that is handled by the hierarchy of morphs and generated by the Morphic main loop (with a slight diversion via the ToolSet layer).
- Bert -
UndefinedObject>>DoIt Compiler>>evaluateCue:ifFail: Compiler>>evaluateCue:ifFail:logged: Compiler>>evaluate:in:to:notifying:ifFail:logged: [] in SmalltalkEditor(TextEditor)>>evaluateSelectionAndDo: BlockClosure>>on:do: SmalltalkEditor(TextEditor)>>evaluateSelectionAndDo: SmalltalkEditor(TextEditor)>>printIt SmalltalkEditor(TextEditor)>>printIt: SmalltalkEditor(TextEditor)>>dispatchOnKeyboardEvent: SmalltalkEditor(TextEditor)>>keyStroke: [] in [] in TextMorphForEditView(TextMorph)>>keyStroke: TextMorphForEditView(TextMorph)>>handleInteraction:fromEvent: TextMorphForEditView>>handleInteraction:fromEvent: [] in TextMorphForEditView(TextMorph)>>keyStroke: StandardToolSet class>>codeCompletionAround:textMorph:keyStroke: ToolSet class>>codeCompletionAround:textMorph:keyStroke: TextMorphForEditView(TextMorph)>>keyStroke: TextMorphForEditView>>keyStroke: TextMorphForEditView(TextMorph)>>handleKeystroke: KeyboardEvent>>sentTo: TextMorphForEditView(Morph)>>handleEvent: TextMorphForEditView(Morph)>>handleFocusEvent: [] in HandMorph>>sendFocusEvent:to:clear: BlockClosure>>on:do: PasteUpMorph>>becomeActiveDuring: HandMorph>>sendFocusEvent:to:clear: HandMorph>>sendEvent:focus:clear: HandMorph>>sendKeyboardEvent: HandMorph>>handleEvent: HandMorph>>processEvents [] in WorldState>>doOneCycleNowFor: Array(SequenceableCollection)>>do: WorldState>>handsDo: WorldState>>doOneCycleNowFor: WorldState>>doOneCycleFor: PasteUpMorph>>doOneCycle [] in MorphicProject>>spawnNewProcess [] in BlockClosure>>newProcess
vm-dev@lists.squeakfoundation.org
-
 Bert Freudenberg
Bert Freudenberg -
 David T. Lewis
David T. Lewis -
 Eliot Miranda
Eliot Miranda -
 gettimothy
gettimothy -
 Nicolas Cellier
Nicolas Cellier -
 Ryan Macnak
Ryan Macnak -
 tim Rowledge
tim Rowledge