
Dear vm developers,
I’ve encountered multiple times an issue when my images cannot be opened after saving (only on spur). I think that this happens when image is large, and the following script results in a corrupt image almost 100%:
curl get.pharo.org/50+vm | bash
./pharo Pharo.image --no-default-preferences eval --save \ "Smalltalk globals at: #ReallyBigArray put: (ByteArray new: 1024*1024*1000). 'Done'"
./pharo Pharo.image printVersion
The last line is there just to make image do something and for me it fails all the times. I hope that this can help to troubleshoot the issue with the vm.
Also here are my system & hardware specs:
System Version: OS X 10.11.3 (15D21) Model Identifier: MacBookPro11,5 Processor Name: Intel Core i7 Processor Speed: 2.8 GHz Total Number of Cores: 4 Memory: 16 GB
Cheers! Uko

Hi Yuriy,
what's the version info in that VM? I expect this is the same bug I fixed in
CogVM binaries as per VMMaker.oscog-eem.1679/r3602 ... Fix start up of images containing >= 16 segments. The old code assumed numSegments < 16 and failed to grow the segment records, resulting in objects in segments greater than 15 to not be swizzled, and a resulting crash.
_,,,^..^,,,_ (phone)
On Mar 7, 2016, at 1:32 PM, Yuriy Tymchuk yuriy.tymchuk@me.com wrote:
Dear vm developers,
I’ve encountered multiple times an issue when my images cannot be opened after saving (only on spur). I think that this happens when image is large, and the following script results in a corrupt image almost 100%:
curl get.pharo.org/50+vm | bash
./pharo Pharo.image --no-default-preferences eval --save \ "Smalltalk globals at: #ReallyBigArray put: (ByteArray new: 1024*1024*1000). 'Done'"
./pharo Pharo.image printVersion
The last line is there just to make image do something and for me it fails all the times. I hope that this can help to troubleshoot the issue with the vm.
Also here are my system & hardware specs:
System Version: OS X 10.11.3 (15D21) Model Identifier: MacBookPro11,5 Processor Name: Intel Core i7 Processor Speed: 2.8 GHz Total Number of Cores: 4 Memory: 16 GB
Cheers! Uko
Yes, I’m using VMMaker.oscog-EstebanLorenzano.1676
Thank you
On 08 Mar 2016, at 06:08, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Yuriy,
what's the version info in that VM? I expect this is the same bug I fixed inCogVM binaries as per VMMaker.oscog-eem.1679/r3602 ... Fix start up of images containing >= 16 segments. The old code assumed numSegments < 16 and failed to grow the segment records, resulting in objects in segments greater than 15 to not be swizzled, and a resulting crash.
_,,,^..^,,,_ (phone)
On Mar 7, 2016, at 1:32 PM, Yuriy Tymchuk <yuriy.tymchuk@me.com mailto:yuriy.tymchuk@me.com> wrote:
Dear vm developers,
I’ve encountered multiple times an issue when my images cannot be opened after saving (only on spur). I think that this happens when image is large, and the following script results in a corrupt image almost 100%:
curl get.pharo.org/50+vm http://get.pharo.org/50+vm | bash
./pharo Pharo.image --no-default-preferences eval --save \ "Smalltalk globals at: #ReallyBigArray put: (ByteArray new: 1024*1024*1000). 'Done'"
./pharo Pharo.image printVersion
The last line is there just to make image do something and for me it fails all the times. I hope that this can help to troubleshoot the issue with the vm.
Also here are my system & hardware specs:
System Version: OS X 10.11.3 (15D21) Model Identifier: MacBookPro11,5 Processor Name: Intel Core i7 Processor Speed: 2.8 GHz Total Number of Cores: 4 Memory: 16 GB
Cheers! Uko

can you try with vmLatest, to check if Eliot change fix it?
Esteban
On 08 Mar 2016, at 11:43, Yuriy Tymchuk yuriy.tymchuk@me.com wrote:
Yes, I’m using VMMaker.oscog-EstebanLorenzano.1676
Thank you
On 08 Mar 2016, at 06:08, Eliot Miranda <eliot.miranda@gmail.com mailto:eliot.miranda@gmail.com> wrote:
Hi Yuriy,
what's the version info in that VM? I expect this is the same bug I fixed inCogVM binaries as per VMMaker.oscog-eem.1679/r3602 ... Fix start up of images containing >= 16 segments. The old code assumed numSegments < 16 and failed to grow the segment records, resulting in objects in segments greater than 15 to not be swizzled, and a resulting crash.
_,,,^..^,,,_ (phone)
On Mar 7, 2016, at 1:32 PM, Yuriy Tymchuk <yuriy.tymchuk@me.com mailto:yuriy.tymchuk@me.com> wrote:
Dear vm developers,
I’ve encountered multiple times an issue when my images cannot be opened after saving (only on spur). I think that this happens when image is large, and the following script results in a corrupt image almost 100%:
curl get.pharo.org/50+vm http://get.pharo.org/50+vm | bash
./pharo Pharo.image --no-default-preferences eval --save \ "Smalltalk globals at: #ReallyBigArray put: (ByteArray new: 1024*1024*1000). 'Done'"
./pharo Pharo.image printVersion
The last line is there just to make image do something and for me it fails all the times. I hope that this can help to troubleshoot the issue with the vm.
Also here are my system & hardware specs:
System Version: OS X 10.11.3 (15D21) Model Identifier: MacBookPro11,5 Processor Name: Intel Core i7 Processor Speed: 2.8 GHz Total Number of Cores: 4 Memory: 16 GB
Cheers! Uko
Same issue happens with:
VMMaker.oscog-nice.1713
Does the script that I provided crash only for me?
Cheers. Uko
On 08 Mar 2016, at 13:48, Esteban Lorenzano estebanlm@gmail.com wrote:
can you try with vmLatest, to check if Eliot change fix it?
Esteban
On 08 Mar 2016, at 11:43, Yuriy Tymchuk <yuriy.tymchuk@me.com mailto:yuriy.tymchuk@me.com> wrote:
Yes, I’m using VMMaker.oscog-EstebanLorenzano.1676
Thank you
On 08 Mar 2016, at 06:08, Eliot Miranda <eliot.miranda@gmail.com mailto:eliot.miranda@gmail.com> wrote:
Hi Yuriy,
what's the version info in that VM? I expect this is the same bug I fixed inCogVM binaries as per VMMaker.oscog-eem.1679/r3602 ... Fix start up of images containing >= 16 segments. The old code assumed numSegments < 16 and failed to grow the segment records, resulting in objects in segments greater than 15 to not be swizzled, and a resulting crash.
_,,,^..^,,,_ (phone)
On Mar 7, 2016, at 1:32 PM, Yuriy Tymchuk <yuriy.tymchuk@me.com mailto:yuriy.tymchuk@me.com> wrote:
Dear vm developers,
I’ve encountered multiple times an issue when my images cannot be opened after saving (only on spur). I think that this happens when image is large, and the following script results in a corrupt image almost 100%:
curl get.pharo.org/50+vm http://get.pharo.org/50+vm | bash
./pharo Pharo.image --no-default-preferences eval --save \ "Smalltalk globals at: #ReallyBigArray put: (ByteArray new: 1024*1024*1000). 'Done'"
./pharo Pharo.image printVersion
The last line is there just to make image do something and for me it fails all the times. I hope that this can help to troubleshoot the issue with the vm.
Also here are my system & hardware specs:
System Version: OS X 10.11.3 (15D21) Model Identifier: MacBookPro11,5 Processor Name: Intel Core i7 Processor Speed: 2.8 GHz Total Number of Cores: 4 Memory: 16 GB
Cheers! Uko
Hi Yuriy,
_,,,^..^,,,_ (phone)
On Mar 8, 2016, at 2:43 AM, Yuriy Tymchuk yuriy.tymchuk@me.com wrote:
Yes, I’m using VMMaker.oscog-EstebanLorenzano.1676
and how about the VMs in http://www.mirandabanda.org/files/Cog/VM/latest/? If you're on Mac you would use http://www.mirandabanda.org/files/Cog/VM/latest/CogPharoSpur.app-16.08.3632..... Just check if it starts up. The VM is missing some plugins and support libraries. But it definitely has the problem fixed.
Also Yuriy, could you purine of the images that won't start up somewhere where I can download it to take a look?
Thank you
On 08 Mar 2016, at 06:08, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Yuriy,
what's the version info in that VM? I expect this is the same bug I fixed inCogVM binaries as per VMMaker.oscog-eem.1679/r3602 ... Fix start up of images containing >= 16 segments. The old code assumed numSegments < 16 and failed to grow the segment records, resulting in objects in segments greater than 15 to not be swizzled, and a resulting crash.
_,,,^..^,,,_ (phone)
On Mar 7, 2016, at 1:32 PM, Yuriy Tymchuk yuriy.tymchuk@me.com wrote:
Dear vm developers,
I’ve encountered multiple times an issue when my images cannot be opened after saving (only on spur). I think that this happens when image is large, and the following script results in a corrupt image almost 100%:
curl get.pharo.org/50+vm | bash
./pharo Pharo.image --no-default-preferences eval --save \ "Smalltalk globals at: #ReallyBigArray put: (ByteArray new: 1024*1024*1000). 'Done'"
./pharo Pharo.image printVersion
The last line is there just to make image do something and for me it fails all the times. I hope that this can help to troubleshoot the issue with the vm.
Also here are my system & hardware specs:
System Version: OS X 10.11.3 (15D21) Model Identifier: MacBookPro11,5 Processor Name: Intel Core i7 Processor Speed: 2.8 GHz Total Number of Cores: 4 Memory: 16 GB
Cheers! Uko
Yuriy, Steph,
On Mar 8, 2016, at 2:43 AM, Yuriy Tymchuk yuriy.tymchuk@me.com wrote:
Yes, I’m using VMMaker.oscog-EstebanLorenzano.1676
ignore my earlier response. You need to use a newer VM. The problem was fixed in VMMaker.oscog-eem.1679 so move to a newer VM.
_,,,^..^,,,_ (phone)
Thank you
On 08 Mar 2016, at 06:08, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Yuriy,
what's the version info in that VM? I expect this is the same bug I fixed inCogVM binaries as per VMMaker.oscog-eem.1679/r3602 ... Fix start up of images containing >= 16 segments. The old code assumed numSegments < 16 and failed to grow the segment records, resulting in objects in segments greater than 15 to not be swizzled, and a resulting crash.
_,,,^..^,,,_ (phone)
On Mar 7, 2016, at 1:32 PM, Yuriy Tymchuk yuriy.tymchuk@me.com wrote:
Dear vm developers,
I’ve encountered multiple times an issue when my images cannot be opened after saving (only on spur). I think that this happens when image is large, and the following script results in a corrupt image almost 100%:
curl get.pharo.org/50+vm | bash
./pharo Pharo.image --no-default-preferences eval --save \ "Smalltalk globals at: #ReallyBigArray put: (ByteArray new: 1024*1024*1000). 'Done'"
./pharo Pharo.image printVersion
The last line is there just to make image do something and for me it fails all the times. I hope that this can help to troubleshoot the issue with the vm.
Also here are my system & hardware specs:
System Version: OS X 10.11.3 (15D21) Model Identifier: MacBookPro11,5 Processor Name: Intel Core i7 Processor Speed: 2.8 GHz Total Number of Cores: 4 Memory: 16 GB
Cheers! Uko
On 08 Mar 2016, at 16:30, Eliot Miranda eliot.miranda@gmail.com wrote:
Yuriy, Steph,
On Mar 8, 2016, at 2:43 AM, Yuriy Tymchuk <yuriy.tymchuk@me.com mailto:yuriy.tymchuk@me.com> wrote:
Yes, I’m using VMMaker.oscog-EstebanLorenzano.1676
ignore my earlier response. You need to use a newer VM. The problem was fixed in VMMaker.oscog-eem.1679 so move to a newer VM.
he also tested on VMMaker.oscog-nice.1713 :)
_,,,^..^,,,_ (phone)
Thank you
On 08 Mar 2016, at 06:08, Eliot Miranda <eliot.miranda@gmail.com mailto:eliot.miranda@gmail.com> wrote:
Hi Yuriy,
what's the version info in that VM? I expect this is the same bug I fixed inCogVM binaries as per VMMaker.oscog-eem.1679/r3602 ... Fix start up of images containing >= 16 segments. The old code assumed numSegments < 16 and failed to grow the segment records, resulting in objects in segments greater than 15 to not be swizzled, and a resulting crash.
_,,,^..^,,,_ (phone)
On Mar 7, 2016, at 1:32 PM, Yuriy Tymchuk <yuriy.tymchuk@me.com mailto:yuriy.tymchuk@me.com> wrote:
Dear vm developers,
I’ve encountered multiple times an issue when my images cannot be opened after saving (only on spur). I think that this happens when image is large, and the following script results in a corrupt image almost 100%:
curl get.pharo.org/50+vm http://get.pharo.org/50+vm | bash
./pharo Pharo.image --no-default-preferences eval --save \ "Smalltalk globals at: #ReallyBigArray put: (ByteArray new: 1024*1024*1000). 'Done'"
./pharo Pharo.image printVersion
The last line is there just to make image do something and for me it fails all the times. I hope that this can help to troubleshoot the issue with the vm.
Also here are my system & hardware specs:
System Version: OS X 10.11.3 (15D21) Model Identifier: MacBookPro11,5 Processor Name: Intel Core i7 Processor Speed: 2.8 GHz Total Number of Cores: 4 Memory: 16 GB
Cheers! Uko

Thanks I will check (now I have a huge deadline for this evening) Mooc videos.
Stef
On 08 Mar 2016, at 16:30, Eliot Miranda <eliot.miranda@gmail.com mailto:eliot.miranda@gmail.com> wrote:
Yuriy, Steph,
On Mar 8, 2016, at 2:43 AM, Yuriy Tymchuk <yuriy.tymchuk@me.com mailto:yuriy.tymchuk@me.com> wrote:
Yes, I’m using VMMaker.oscog-EstebanLorenzano.1676
ignore my earlier response. You need to use a newer VM. The problem was fixed in VMMaker.oscog-eem.1679 so move to a newer VM.
_,,,^..^,,,_ (phone)
Thank you
On 08 Mar 2016, at 06:08, Eliot Miranda <eliot.miranda@gmail.com mailto:eliot.miranda@gmail.com> wrote:
Hi Yuriy,
what's the version info in that VM? I expect this is the same bug I fixed inCogVM binaries as per VMMaker.oscog-eem.1679/r3602 ... Fix start up of images containing >= 16 segments. The old code assumed numSegments < 16 and failed to grow the segment records, resulting in objects in segments greater than 15 to not be swizzled, and a resulting crash.
_,,,^..^,,,_ (phone)
On Mar 7, 2016, at 1:32 PM, Yuriy Tymchuk <yuriy.tymchuk@me.com mailto:yuriy.tymchuk@me.com> wrote:
Dear vm developers,
I’ve encountered multiple times an issue when my images cannot be opened after saving (only on spur). I think that this happens when image is large, and the following script results in a corrupt image almost 100%:
curl get.pharo.org/50+vm http://get.pharo.org/50+vm | bash
./pharo Pharo.image --no-default-preferences eval --save \ "Smalltalk globals at: #ReallyBigArray put: (ByteArray new: 1024*1024*1000). 'Done'"
./pharo Pharo.image printVersion
The last line is there just to make image do something and for me it fails all the times. I hope that this can help to troubleshoot the issue with the vm.
Also here are my system & hardware specs:
System Version: OS X 10.11.3 (15D21) Model Identifier: MacBookPro11,5 Processor Name: Intel Core i7 Processor Speed: 2.8 GHz Total Number of Cores: 4 Memory: 16 GB
Cheers! Uko
Yes I got the same last week. I loaded SciSmalltalk and just program one hour and my image went to 1.4 Gb I could not load it.
Stef
On 07 Mar 2016, at 22:32, Yuriy Tymchuk yuriy.tymchuk@me.com wrote:
Dear vm developers,
I’ve encountered multiple times an issue when my images cannot be opened after saving (only on spur). I think that this happens when image is large, and the following script results in a corrupt image almost 100%:
curl get.pharo.org/50+vm http://get.pharo.org/50+vm | bash
./pharo Pharo.image --no-default-preferences eval --save \ "Smalltalk globals at: #ReallyBigArray put: (ByteArray new: 1024*1024*1000). 'Done'"
./pharo Pharo.image printVersion
The last line is there just to make image do something and for me it fails all the times. I hope that this can help to troubleshoot the issue with the vm.
Also here are my system & hardware specs:
System Version: OS X 10.11.3 (15D21) Model Identifier: MacBookPro11,5 Processor Name: Intel Core i7 Processor Speed: 2.8 GHz Total Number of Cores: 4 Memory: 16 GB
Cheers! Uko
The script can be still used to reproduce the issue with the latest vm
On 07 Mar 2016, at 22:32, Yuriy Tymchuk yuriy.tymchuk@me.com wrote:
Dear vm developers,
I’ve encountered multiple times an issue when my images cannot be opened after saving (only on spur). I think that this happens when image is large, and the following script results in a corrupt image almost 100%:
curl get.pharo.org/50+vmLatest http://get.pharo.org/50+vm | bash
./pharo Pharo.image --no-default-preferences eval --save \ "Smalltalk globals at: #ReallyBigArray put: (ByteArray new: 1024*1024*1000). 'Done'"
./pharo Pharo.image printVersion
The last line is there just to make image do something and for me it fails all the times. I hope that this can help to troubleshoot the issue with the vm.
Also here are my system & hardware specs:
System Version: OS X 10.11.3 (15D21) Model Identifier: MacBookPro11,5 Processor Name: Intel Core i7 Processor Speed: 2.8 GHz Total Number of Cores: 4 Memory: 16 GB
Cheers! Uko

Thanks for reporting. Indeed, I just encountered a similar situation with a 900Mb image.
Cheers, Doru
On Apr 22, 2016, at 9:17 AM, Yuriy Tymchuk yuriy.tymchuk@me.com wrote:
The script can be still used to reproduce the issue with the latest vm
On 07 Mar 2016, at 22:32, Yuriy Tymchuk yuriy.tymchuk@me.com wrote:
Dear vm developers,
I’ve encountered multiple times an issue when my images cannot be opened after saving (only on spur). I think that this happens when image is large, and the following script results in a corrupt image almost 100%:
curl get.pharo.org/50+vmLatest | bash
./pharo Pharo.image --no-default-preferences eval --save \ "Smalltalk globals at: #ReallyBigArray put: (ByteArray new: 1024*1024*1000). 'Done'"
./pharo Pharo.image printVersion
The last line is there just to make image do something and for me it fails all the times. I hope that this can help to troubleshoot the issue with the vm.
Also here are my system & hardware specs:
System Version: OS X 10.11.3 (15D21) Model Identifier: MacBookPro11,5 Processor Name: Intel Core i7 Processor Speed: 2.8 GHz Total Number of Cores: 4 Memory: 16 GB
Cheers! Uko
-- www.tudorgirba.com www.feenk.com
"We are all great at making mistakes."
Hi Yuriy, Hi Esteban,
On Fri, Apr 22, 2016 at 12:17 AM, Yuriy Tymchuk yuriy.tymchuk@me.com wrote:
The script can be still used to reproduce the issue with the latest vm
On 07 Mar 2016, at 22:32, Yuriy Tymchuk yuriy.tymchuk@me.com wrote:
Dear vm developers,
I’ve encountered multiple times an issue when my images cannot be opened after saving (only on spur). I think that this happens when image is large, and the following script results in a corrupt image almost 100%:
curl get.pharo.org/50+vmLatest http://get.pharo.org/50+vm | bash
./pharo Pharo.image --no-default-preferences eval --save \ "Smalltalk globals at: #ReallyBigArray put: (ByteArray new: 1024*1024*1000). 'Done'"
./pharo Pharo.image printVersion
The last line is there just to make image do something and for me it fails all the times. I hope that this can help to troubleshoot the issue with the vm.
Also here are my system & hardware specs:
System Version: OS X 10.11.3 (15D21) Model Identifier: MacBookPro11,5 Processor Name: Intel Core i7 Processor Speed: 2.8 GHz Total Number of Cores: 4 Memory: 16 GB
Cheers! Uko
I've reproduced this with the pharo vm. I see an issue not with the image but with the platform subsystem. Here's the error message I see after the image is successfully saved with the ~ 1Gb byte array:
McStalker.Pharo$ ls -lh Pharo.image -rw-r--r--@ 1 eliot staff 1.0G Apr 22 15:52 Pharo.image McStalker.Pharo$ ./pharo-vm/Pharo.app/Contents/MacOS/Pharo Pharo.image objc[44476]: autorelease pool page 0x21ce000 corrupted magic 0x0100040b 0x03000000 0x214a9d00 0x00000003 pthread 0x9f75b00
Illegal instruction: 4
but if I start the image with a "Pharo" VM compiled from the Cog source tree (Pharo in quotes because the VM is missing a number of plugins) the system starts up and is usable.
McStalker.Pharo$ pharocfvm -version /Users/eliot/oscogvm/build.macos32x86/pharo.cog.spur/CocoaFast.app/Contents/MacOS/Pharo 5.0 5.0.3678 Mac OS X built on Apr 22 2016 11:40:09 PDT Compiler: 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.57) [Production Spur VM] CoInterpreter VMMaker.oscog-eem.1832 uuid: 3e4d6e88-f60d-4a01-930d-7c5895b8a86a Apr 22 2016 StackToRegisterMappingCogit VMMaker.oscog-eem.1832 uuid: 3e4d6e88-f60d-4a01-930d-7c5895b8a86a Apr 22 2016 VM: r3678 http://www.squeakvm.org/svn/squeak/branches/Cog Date: 2016-04-22 11:26:57 -0700 Plugins: r3639 http://squeakvm.org/svn/squeak/trunk/platforms/Cross/plugins
I can confirm that the problem is with the Pharo platforms/iOS subsystem, and not for example,e, plugins. If I include the plains from the official pharo-vm in the Pharo VM built from the Cog branch sources, the image loads.
Somehow we need to merge the two subsystems. i.e. we need to merge http://www.squeakvm.org/svn/squeak/branches/Cog/platforms/iOS with the pharo equivalent. For example, Pharo's tree supports -headless but the Cog branch does not, the Cog branch supports 64-bits and -version, Pharo's does not. Volunteers?
_,,,^..^,,,_ best, Eliot
Hi,
On 23 Apr 2016, at 01:10, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Yuriy, Hi Esteban,
On Fri, Apr 22, 2016 at 12:17 AM, Yuriy Tymchuk <yuriy.tymchuk@me.com mailto:yuriy.tymchuk@me.com> wrote:
The script can be still used to reproduce the issue with the latest vm
On 07 Mar 2016, at 22:32, Yuriy Tymchuk <yuriy.tymchuk@me.com mailto:yuriy.tymchuk@me.com> wrote:
Dear vm developers,
I’ve encountered multiple times an issue when my images cannot be opened after saving (only on spur). I think that this happens when image is large, and the following script results in a corrupt image almost 100%:
curl get.pharo.org/50+vmLatest http://get.pharo.org/50+vm | bash
./pharo Pharo.image --no-default-preferences eval --save \ "Smalltalk globals at: #ReallyBigArray put: (ByteArray new: 1024*1024*1000). 'Done'"
./pharo Pharo.image printVersion
The last line is there just to make image do something and for me it fails all the times. I hope that this can help to troubleshoot the issue with the vm.
Also here are my system & hardware specs:
System Version: OS X 10.11.3 (15D21) Model Identifier: MacBookPro11,5 Processor Name: Intel Core i7 Processor Speed: 2.8 GHz Total Number of Cores: 4 Memory: 16 GB
Cheers! Uko
I've reproduced this with the pharo vm. I see an issue not with the image but with the platform subsystem. Here's the error message I see after the image is successfully saved with the ~ 1Gb byte array:
McStalker.Pharo$ ls -lh Pharo.image -rw-r--r--@ 1 eliot staff 1.0G Apr 22 15:52 Pharo.image McStalker.Pharo$ ./pharo-vm/Pharo.app/Contents/MacOS/Pharo Pharo.image objc[44476]: autorelease pool page 0x21ce000 corrupted magic 0x0100040b 0x03000000 0x214a9d00 0x00000003 pthread 0x9f75b00
Illegal instruction: 4
but if I start the image with a "Pharo" VM compiled from the Cog source tree (Pharo in quotes because the VM is missing a number of plugins) the system starts up and is usable.
McStalker.Pharo$ pharocfvm -version /Users/eliot/oscogvm/build.macos32x86/pharo.cog.spur/CocoaFast.app/Contents/MacOS/Pharo 5.0 5.0.3678 Mac OS X built on Apr 22 2016 11:40:09 PDT Compiler: 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.57) [Production Spur VM] CoInterpreter VMMaker.oscog-eem.1832 uuid: 3e4d6e88-f60d-4a01-930d-7c5895b8a86a Apr 22 2016 StackToRegisterMappingCogit VMMaker.oscog-eem.1832 uuid: 3e4d6e88-f60d-4a01-930d-7c5895b8a86a Apr 22 2016 VM: r3678 http://www.squeakvm.org/svn/squeak/branches/Cog http://www.squeakvm.org/svn/squeak/branches/Cog Date: 2016-04-22 11:26:57 -0700 Plugins: r3639 http://squeakvm.org/svn/squeak/trunk/platforms/Cross/plugins http://squeakvm.org/svn/squeak/trunk/platforms/Cross/plugins
I can confirm that the problem is with the Pharo platforms/iOS subsystem, and not for example,e, plugins. If I include the plains from the official pharo-vm in the Pharo VM built from the Cog branch sources, the image loads.
Somehow we need to merge the two subsystems. i.e. we need to merge http://www.squeakvm.org/svn/squeak/branches/Cog/platforms/iOS http://www.squeakvm.org/svn/squeak/branches/Cog/platforms/iOS with the pharo equivalent. For example, Pharo's tree supports -headless but the Cog branch does not, the Cog branch supports 64-bits and -version, Pharo's does not. Volunteers?
I agree that we need to converge (too many waist of efforts), and I’m slowly working on that (you’d be surprised how few our changes are now compared to last year(s))… iOS is a bit more difficult because we changed some important things, but it will be done anyway… Anyway, anyone willing to help is very welcome :)
… as I told before, it would help me HUGE if the announced migration to git/github happens soon :) I’m willing to help in that migration if you want, it should be an easy task (I saw Fabio is doing some tests already…)
cheers! Esteban
_,,,^..^,,,_ best, Eliot

On 23.04.2016, at 09:17, Esteban Lorenzano estebanlm@gmail.com wrote:
… as I told before, it would help me HUGE if the announced migration to git/github happens soon :) I’m willing to help in that migration if you want, it should be an easy task (I saw Fabio is doing some tests already…)
Actually, Fabio did a complete migration while squeakvm.org http://squeakvm.org/ was out. This had a full history of all SVN commits.
“Unfortunately” Ian fixed the server too soon so development continued on SVN, so now the git repo is again out-of-date.
We would need to freeze the SVN, do the migration again, and use git from that point on. It would involve a day of downtime, but doing this sooner than later would be a good thing.
Any opinions on what date may be good?
- Bert -

On Sat, Apr 23, 2016 at 12:54 PM, Bert Freudenberg bert@freudenbergs.de wrote:
On 23.04.2016, at 09:17, Esteban Lorenzano estebanlm@gmail.com wrote:
… as I told before, it would help me HUGE if the announced migration to git/github happens soon :) I’m willing to help in that migration if you want, it should be an easy task (I saw Fabio is doing some tests already…)
Actually, Fabio did a complete migration while squeakvm.org was out. This had a full history of all SVN commits.
“Unfortunately” Ian fixed the server too soon so development continued on SVN, so now the git repo is again out-of-date.
We would need to freeze the SVN, do the migration again, and use git from that point on. It would involve a day of downtime, but doing this sooner than later would be a good thing.
Any opinions on what date may be good?
I'd love to see that happening next week.
I would like to see the merge of the iOS branches ASAP. I am *really really really* pissed at this drag'n'drop bug in the current state of Eliot's branch because I drag'n'drop things all the time and it creates me a lot of crashes.
But Eliot and Nicolas have to decide, they're the ones committing the most on the svn currently.
- Bert -

2016-04-23 13:56 GMT+02:00 Clément Bera bera.clement@gmail.com:
On Sat, Apr 23, 2016 at 12:54 PM, Bert Freudenberg bert@freudenbergs.de wrote:
On 23.04.2016, at 09:17, Esteban Lorenzano estebanlm@gmail.com wrote:
… as I told before, it would help me HUGE if the announced migration to git/github happens soon :) I’m willing to help in that migration if you want, it should be an easy task (I saw Fabio is doing some tests already…)
Actually, Fabio did a complete migration while squeakvm.org was out. This had a full history of all SVN commits.
“Unfortunately” Ian fixed the server too soon so development continued on SVN, so now the git repo is again out-of-date.
We would need to freeze the SVN, do the migration again, and use git from that point on. It would involve a day of downtime, but doing this sooner than later would be a good thing.
doesn't gitsvn help?
Any opinions on what date may be good?
I'd love to see that happening next week.
I would like to see the merge of the iOS branches ASAP. I am *really really really* pissed at this drag'n'drop bug in the current state of Eliot's branch because I drag'n'drop things all the time and it creates me a lot of crashes.
But Eliot and Nicolas have to decide, they're the ones committing the most on the svn currently.
for myself I'm fine with github. Nicolas
- Bert -
2016-04-23 14:22 GMT+02:00 Nicolas Cellier < nicolas.cellier.aka.nice@gmail.com>:
2016-04-23 13:56 GMT+02:00 Clément Bera bera.clement@gmail.com:
On Sat, Apr 23, 2016 at 12:54 PM, Bert Freudenberg bert@freudenbergs.de wrote:
On 23.04.2016, at 09:17, Esteban Lorenzano estebanlm@gmail.com wrote:
… as I told before, it would help me HUGE if the announced migration to git/github happens soon :) I’m willing to help in that migration if you want, it should be an easy task (I saw Fabio is doing some tests already…)
Actually, Fabio did a complete migration while squeakvm.org was out. This had a full history of all SVN commits.
“Unfortunately” Ian fixed the server too soon so development continued on SVN, so now the git repo is again out-of-date.
We would need to freeze the SVN, do the migration again, and use git from that point on. It would involve a day of downtime, but doing this sooner than later would be a good thing.
doesn't gitsvn help?
Any opinions on what date may be good?
I'd love to see that happening next week.
I would like to see the merge of the iOS branches ASAP. I am *really really really* pissed at this drag'n'drop bug in the current state of Eliot's branch because I drag'n'drop things all the time and it creates me a lot of crashes.
But Eliot and Nicolas have to decide, they're the ones committing the most on the svn currently.
for myself I'm fine with github. Nicolas
I should have said more than fine, enthusiasm!
BTW could someone point me to Fabio repository, I failed to find it.
- Bert -

On Sat, Apr 23, 2016 at 02:22:29PM +0200, Nicolas Cellier wrote:
2016-04-23 13:56 GMT+02:00 Cl??ment Bera bera.clement@gmail.com:
On Sat, Apr 23, 2016 at 12:54 PM, Bert Freudenberg bert@freudenbergs.de wrote:
Actually, Fabio did a complete migration while squeakvm.org was out. This had a full history of all SVN commits.
???Unfortunately??? Ian fixed the server too soon so development continued on SVN, so now the git repo is again out-of-date.
We would need to freeze the SVN, do the migration again, and use git from that point on. It would involve a day of downtime, but doing this sooner than later would be a good thing.
doesn't gitsvn help?
I have to admit that I did not even know that an active git svn bridge was possible. It sounds like this it might be very helpful.
It would be great to have the advantages of git for development, and it could also be helpful to be able to have the squeakvm.org repo updated periodically from git. There are portions of the platforms tree that Eliot has been able to make identical for oscog and trunk, and this seems like a worthwhile effort to continue.
Another possible advantage is that Ian's cmake build process takes advantage of the SVN revision numbering, and it would be good to make sure this stays healthy as development proceeds (it's a lot nicer than autotools).
Eliot, do you have a view on this?
Dave

Hi all,
Bert already mentioned that I've been working on migrating the repository from SVN to Git. I believe there are three problems that need to be solved here:
*1. Migrating SVN externals for sharing code between branches* This is currently used to share a few directories (e.g. platforms/Cross/plugins) across different branches. But Git does no support this kind of code sharing. Instead, it supports submodules [1] and subtrees [2]. I would suggest to move code that we want to share into separate Git repositories and include them as submodules. I think submodules are easier to understand (GitHub integrates them nicely in their UI). The only drawback: if someone updates code in a shared repository, one needs to update all references to this repository as well. But I'd say this is also a good thing: if someone changes e.g. a plugin and the change is compatible to Cog, but incompatible to the interpreter vm, then the interpreter branch is not automatically broken as soon as one pushes the plugin change. If the above is unclear, I'm happy to explain submodules in more detail.
*2. Versioning and new releases* If we migrate to Git, I'd recommend to deprecate the way we do versioning in SVN. Instead, we should use Git commit hashes and Git tags. Let's say we want to release a new version, we tag the commit of interest with e.g. v1.0.0. When building the Cog VM on this tag, the version will be v1.0.0. If we use GitHub, we might as well use a CI service such as Travis CI [3] to automate the build process. That means, each time someone pushes changes to GitHub, Travis CI will build a new Cog VM (we can call this "bleeding edge"). Let's say I push changes right after the release of v1.0.0, the version for the next build will be something like v1.0.0-37553a9 with "37553a9" being the short SHA1 identifying my latest commit. If we want to release e.g. v1.1.0, we just tag a newer commit and GitHub/Travis CI does the rest for us. I already have this working, you can find a Travis build at [4] and the result at [5]. Obviously, we can push the binaries to a different server.
*3. Keeping a copy of the code* We of course want to keep a copy of our code at all times in case something happens with GitHub. There are already tools that we can use to automate this. However, I wouldn't try to keep the old SVN repository in sync. I believe this might be quite difficult and I don't see a reason to maintain something we want to deprecate in the first place. Anyway, it should be fairly easy to set up a tool that creates a backup on one of our servers whenever we change code on GitHub.
Doing a migration from SVN to Git(Hub) takes a few hours and I'd recommend we stop pushing code to the SVN as soon as we start to migrate. This obviously requires everyone working with the code base to switch to Git. So please let me know if everyone is comfortable with the migration. If we want to do this next week, I'd recommend to do it on a Thursday or a Friday, because I would be able to do it with Bert sitting two rooms next to me :)
I hope I have thought about the important things and I'm happy to answer any questions you might have.
Best, Fabio
[1] https://git-scm.com/book/en/v2/Git-Tools-Submodules [2] http://blogs.atlassian.com/2013/05/alternatives-to-git-submodule-git-subtree... [3] http://travis-ci.org [4] https://travis-ci.org/fniephaus/squeak/builds/119507180 [5] https://www.hpi.uni-potsdam.de/hirschfeld/artefacts/cog/v0.1.0/
Hi Fabio,
On Apr 23, 2016, at 9:40 AM, Fabio Niephaus lists@fniephaus.com wrote:
Hi all,
Bert already mentioned that I've been working on migrating the repository from SVN to Git. I believe there are three problems that need to be solved here:
- Migrating SVN externals for sharing code between branches
This is currently used to share a few directories (e.g. platforms/Cross/plugins) across different branches. But Git does no support this kind of code sharing. Instead, it supports submodules [1] and subtrees [2]. I would suggest to move code that we want to share into separate Git repositories and include them as submodules. I think submodules are easier to understand (GitHub integrates them nicely in their UI). The only drawback: if someone updates code in a shared repository, one needs to update all references to this repository as well. But I'd say this is also a good thing: if someone changes e.g. a plugin and the change is compatible to Cog, but incompatible to the interpreter vm, then the interpreter branch is not automatically broken as soon as one pushes the plugin change. If the above is unclear, I'm happy to explain submodules in more detail.
- Versioning and new releases
If we migrate to Git, I'd recommend to deprecate the way we do versioning in SVN. Instead, we should use Git commit hashes and Git tags.
But have you modified platforms/Cross/vm/sqSCCSVersion.h to capture this information? If so, can you please send me the code so I can integrate it? If not, why not?
Let's say we want to release a new version, we tag the commit of interest with e.g. v1.0.0. When building the Cog VM on this tag, the version will be v1.0.0. If we use GitHub, we might as well use a CI service such as Travis CI [3] to automate the build process. That means, each time someone pushes changes to GitHub, Travis CI will build a new Cog VM (we can call this "bleeding edge"). Let's say I push changes right after the release of v1.0.0, the version for the next build will be something like v1.0.0-37553a9 with "37553a9" being the short SHA1 identifying my latest commit. If we want to release e.g. v1.1.0, we just tag a newer commit and GitHub/Travis CI does the rest for us. I already have this working, you can find a Travis build at [4] and the result at [5]. Obviously, we can push the binaries to a different server.
- Keeping a copy of the code
We of course want to keep a copy of our code at all times in case something happens with GitHub. There are already tools that we can use to automate this. However, I wouldn't try to keep the old SVN repository in sync. I believe this might be quite difficult and I don't see a reason to maintain something we want to deprecate in the first place. Anyway, it should be fairly easy to set up a tool that creates a backup on one of our servers whenever we change code on GitHub.
Doing a migration from SVN to Git(Hub) takes a few hours and I'd recommend we stop pushing code to the SVN as soon as we start to migrate. This obviously requires everyone working with the code base to switch to Git. So please let me know if everyone is comfortable with the migration. If we want to do this next week, I'd recommend to do it on a Thursday or a Friday, because I would be able to do it with Bert sitting two rooms next to me :)
I'm not happy to migrate until there's a functional subversion bridge that works and doesn't break my builds. Cadence pays for my time (and hence pays for a lot of the VM development we enjoy) and its builds use Jenkins and subversion and I will not cooperate with any effort that sabotages this. "Next Thursday" doesn't appear to appreciate the constraints. This has to be done carefully or I will not cooperate.
I hope I have thought about the important things and I'm happy to answer any questions you might have.
Best, Fabio
[1] https://git-scm.com/book/en/v2/Git-Tools-Submodules [2] http://blogs.atlassian.com/2013/05/alternatives-to-git-submodule-git-subtree... [3] http://travis-ci.org [4] https://travis-ci.org/fniephaus/squeak/builds/119507180 [5] https://www.hpi.uni-potsdam.de/hirschfeld/artefacts/cog/v0.1.0/
--
On Sat, Apr 23, 2016 at 5:10 PM David T. Lewis lewis@mail.msen.com wrote:
On Sat, Apr 23, 2016 at 02:22:29PM +0200, Nicolas Cellier wrote:
2016-04-23 13:56 GMT+02:00 Cl??ment Bera bera.clement@gmail.com:
On Sat, Apr 23, 2016 at 12:54 PM, Bert Freudenberg bert@freudenbergs.de wrote:
Actually, Fabio did a complete migration while squeakvm.org was out. This had a full history of all SVN commits.
???Unfortunately??? Ian fixed the server too soon so development continued on SVN, so now the git repo is again out-of-date.
We would need to freeze the SVN, do the migration again, and use git from that point on. It would involve a day of downtime, but doing this sooner than later would be a good thing.
doesn't gitsvn help?
I have to admit that I did not even know that an active git svn bridge was possible. It sounds like this it might be very helpful.
It would be great to have the advantages of git for development, and it could also be helpful to be able to have the squeakvm.org repo updated periodically from git. There are portions of the platforms tree that Eliot has been able to make identical for oscog and trunk, and this seems like a worthwhile effort to continue.
Another possible advantage is that Ian's cmake build process takes advantage of the SVN revision numbering, and it would be good to make sure this stays healthy as development proceeds (it's a lot nicer than autotools).
Eliot, do you have a view on this?
Dave
_,,,^..^,,,_ (phone)
Hi,
I would like to have a list of constraints so we can sort it (otherwise this will never happen… :S) So far I have:
- sqSCCSVersion.h adapt to git. In Pharo we already have something but I do not think is enough… I will take a look to this. - do not break Cadence builds. AFAIK, nothing forbids jenkins to stop using SVN and start using GIT (we also use Jenkins for our builds and we didn’t found any problem)… someone has to do the change, but it should be fairly straightforward. Who is the person who can take this task? (I’d do it, but I suppose Cadence has access policy to that)
what more?
(please, take into account that this is very important for us, and that I personally will be in a better position to go back to the trunk, and then contribute back my changes, that’s why I’m pushing it)
Esteban
ps: As far as I understood, Fabio didn’t said “next thursday”, but “one thursday” :)
On 23 Apr 2016, at 18:54, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Fabio,
On Apr 23, 2016, at 9:40 AM, Fabio Niephaus <lists@fniephaus.com mailto:lists@fniephaus.com> wrote:
Hi all,
Bert already mentioned that I've been working on migrating the repository from SVN to Git. I believe there are three problems that need to be solved here:
- Migrating SVN externals for sharing code between branches
This is currently used to share a few directories (e.g. platforms/Cross/plugins) across different branches. But Git does no support this kind of code sharing. Instead, it supports submodules [1] and subtrees [2]. I would suggest to move code that we want to share into separate Git repositories and include them as submodules. I think submodules are easier to understand (GitHub integrates them nicely in their UI). The only drawback: if someone updates code in a shared repository, one needs to update all references to this repository as well. But I'd say this is also a good thing: if someone changes e.g. a plugin and the change is compatible to Cog, but incompatible to the interpreter vm, then the interpreter branch is not automatically broken as soon as one pushes the plugin change. If the above is unclear, I'm happy to explain submodules in more detail.
- Versioning and new releases
If we migrate to Git, I'd recommend to deprecate the way we do versioning in SVN. Instead, we should use Git commit hashes and Git tags.
But have you modified platforms/Cross/vm/sqSCCSVersion.h to capture this information? If so, can you please send me the code so I can integrate it? If not, why not?
Let's say we want to release a new version, we tag the commit of interest with e.g. v1.0.0. When building the Cog VM on this tag, the version will be v1.0.0. If we use GitHub, we might as well use a CI service such as Travis CI [3] to automate the build process. That means, each time someone pushes changes to GitHub, Travis CI will build a new Cog VM (we can call this "bleeding edge"). Let's say I push changes right after the release of v1.0.0, the version for the next build will be something like v1.0.0-37553a9 with "37553a9" being the short SHA1 identifying my latest commit. If we want to release e.g. v1.1.0, we just tag a newer commit and GitHub/Travis CI does the rest for us. I already have this working, you can find a Travis build at [4] and the result at [5]. Obviously, we can push the binaries to a different server.
- Keeping a copy of the code
We of course want to keep a copy of our code at all times in case something happens with GitHub. There are already tools that we can use to automate this. However, I wouldn't try to keep the old SVN repository in sync. I believe this might be quite difficult and I don't see a reason to maintain something we want to deprecate in the first place. Anyway, it should be fairly easy to set up a tool that creates a backup on one of our servers whenever we change code on GitHub.
Doing a migration from SVN to Git(Hub) takes a few hours and I'd recommend we stop pushing code to the SVN as soon as we start to migrate. This obviously requires everyone working with the code base to switch to Git. So please let me know if everyone is comfortable with the migration. If we want to do this next week, I'd recommend to do it on a Thursday or a Friday, because I would be able to do it with Bert sitting two rooms next to me :)
I'm not happy to migrate until there's a functional subversion bridge that works and doesn't break my builds. Cadence pays for my time (and hence pays for a lot of the VM development we enjoy) and its builds use Jenkins and subversion and I will not cooperate with any effort that sabotages this. "Next Thursday" doesn't appear to appreciate the constraints. This has to be done carefully or I will not cooperate.
I hope I have thought about the important things and I'm happy to answer any questions you might have.
Best, Fabio
[1] https://git-scm.com/book/en/v2/Git-Tools-Submodules https://git-scm.com/book/en/v2/Git-Tools-Submodules [2] http://blogs.atlassian.com/2013/05/alternatives-to-git-submodule-git-subtree... http://blogs.atlassian.com/2013/05/alternatives-to-git-submodule-git-subtree/ [3] http://travis-ci.org http://travis-ci.org/ [4] https://travis-ci.org/fniephaus/squeak/builds/119507180 https://travis-ci.org/fniephaus/squeak/builds/119507180 [5] https://www.hpi.uni-potsdam.de/hirschfeld/artefacts/cog/v0.1.0/ https://www.hpi.uni-potsdam.de/hirschfeld/artefacts/cog/v0.1.0/
--
On Sat, Apr 23, 2016 at 5:10 PM David T. Lewis <lewis@mail.msen.com mailto:lewis@mail.msen.com> wrote:
On Sat, Apr 23, 2016 at 02:22:29PM +0200, Nicolas Cellier wrote:
2016-04-23 13:56 GMT+02:00 Cl??ment Bera <bera.clement@gmail.com mailto:bera.clement@gmail.com>:
On Sat, Apr 23, 2016 at 12:54 PM, Bert Freudenberg <bert@freudenbergs.de mailto:bert@freudenbergs.de> wrote:
Actually, Fabio did a complete migration while squeakvm.org http://squeakvm.org/ was out. This had a full history of all SVN commits.
???Unfortunately??? Ian fixed the server too soon so development continued on SVN, so now the git repo is again out-of-date.
We would need to freeze the SVN, do the migration again, and use git from that point on. It would involve a day of downtime, but doing this sooner than later would be a good thing.
doesn't gitsvn help?
I have to admit that I did not even know that an active git svn bridge was possible. It sounds like this it might be very helpful.
It would be great to have the advantages of git for development, and it could also be helpful to be able to have the squeakvm.org http://squeakvm.org/ repo updated periodically from git. There are portions of the platforms tree that Eliot has been able to make identical for oscog and trunk, and this seems like a worthwhile effort to continue.
Another possible advantage is that Ian's cmake build process takes advantage of the SVN revision numbering, and it would be good to make sure this stays healthy as development proceeds (it's a lot nicer than autotools).
Eliot, do you have a view on this?
Dave
_,,,^..^,,,_ (phone)
Hi Esteban, Hi Fabio,
On Apr 23, 2016, at 10:11 AM, Esteban Lorenzano estebanlm@gmail.com wrote:
Hi,
I would like to have a list of constraints so we can sort it (otherwise this will never happen… :S) So far I have:
- sqSCCSVersion.h adapt to git. In Pharo we already have something but I do not think is enough… I will take a look to this.
- do not break Cadence builds. AFAIK, nothing forbids jenkins to stop using SVN and start using GIT (we also use Jenkins for our builds and we didn’t found any problem)… someone has to do the change, but it should be fairly straightforward. Who is the person who can take this task? (I’d do it, but I suppose Cadence has access policy to that)
My colleague Bob Westergaard and I will have to do this. There is no way Cadence will allow people from outside to do so ;-)
So I like Fabio's suggestion of deprecating subversion. We can keep the subversion bridge for some time (6 months, 1 year?), announce when it is going away (if ever?) and give people time to transition.
what more?
(please, take into account that this is very important for us, and that I personally will be in a better position to go back to the trunk, and then contribute back my changes, that’s why I’m pushing it)
And having you, and others, contribute is really important to me too. That's why I'm supporting this.
So another thing to discuss and then define is what's the process for updating the master repository? I've not used github to do this so I need educating. I presume:
- there is a set of trusted developers who have permission to integrate - there is a smaller set of administrators who can redefine the set of trusted developer - there is a commonly used pattern for differentiating between a version of the repository that exists to be built by and tested by slaves, and a version that has built and passed the tests satisfactorily
Esteban
ps: As far as I understood, Fabio didn’t said “next thursday”, but “one thursday” :)
Oops. I should read these messages wearing sunglasses... Sorry
On 23 Apr 2016, at 18:54, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Fabio,
On Apr 23, 2016, at 9:40 AM, Fabio Niephaus lists@fniephaus.com wrote:
Hi all,
Bert already mentioned that I've been working on migrating the repository from SVN to Git. I believe there are three problems that need to be solved here:
- Migrating SVN externals for sharing code between branches
This is currently used to share a few directories (e.g. platforms/Cross/plugins) across different branches. But Git does no support this kind of code sharing. Instead, it supports submodules [1] and subtrees [2]. I would suggest to move code that we want to share into separate Git repositories and include them as submodules. I think submodules are easier to understand (GitHub integrates them nicely in their UI). The only drawback: if someone updates code in a shared repository, one needs to update all references to this repository as well. But I'd say this is also a good thing: if someone changes e.g. a plugin and the change is compatible to Cog, but incompatible to the interpreter vm, then the interpreter branch is not automatically broken as soon as one pushes the plugin change. If the above is unclear, I'm happy to explain submodules in more detail.
- Versioning and new releases
If we migrate to Git, I'd recommend to deprecate the way we do versioning in SVN. Instead, we should use Git commit hashes and Git tags.
But have you modified platforms/Cross/vm/sqSCCSVersion.h to capture this information? If so, can you please send me the code so I can integrate it? If not, why not?
Let's say we want to release a new version, we tag the commit of interest with e.g. v1.0.0. When building the Cog VM on this tag, the version will be v1.0.0. If we use GitHub, we might as well use a CI service such as Travis CI [3] to automate the build process. That means, each time someone pushes changes to GitHub, Travis CI will build a new Cog VM (we can call this "bleeding edge"). Let's say I push changes right after the release of v1.0.0, the version for the next build will be something like v1.0.0-37553a9 with "37553a9" being the short SHA1 identifying my latest commit. If we want to release e.g. v1.1.0, we just tag a newer commit and GitHub/Travis CI does the rest for us. I already have this working, you can find a Travis build at [4] and the result at [5]. Obviously, we can push the binaries to a different server.
- Keeping a copy of the code
We of course want to keep a copy of our code at all times in case something happens with GitHub. There are already tools that we can use to automate this. However, I wouldn't try to keep the old SVN repository in sync. I believe this might be quite difficult and I don't see a reason to maintain something we want to deprecate in the first place. Anyway, it should be fairly easy to set up a tool that creates a backup on one of our servers whenever we change code on GitHub.
Doing a migration from SVN to Git(Hub) takes a few hours and I'd recommend we stop pushing code to the SVN as soon as we start to migrate. This obviously requires everyone working with the code base to switch to Git. So please let me know if everyone is comfortable with the migration. If we want to do this next week, I'd recommend to do it on a Thursday or a Friday, because I would be able to do it with Bert sitting two rooms next to me :)
I'm not happy to migrate until there's a functional subversion bridge that works and doesn't break my builds. Cadence pays for my time (and hence pays for a lot of the VM development we enjoy) and its builds use Jenkins and subversion and I will not cooperate with any effort that sabotages this. "Next Thursday" doesn't appear to appreciate the constraints. This has to be done carefully or I will not cooperate.
I hope I have thought about the important things and I'm happy to answer any questions you might have.
Best, Fabio
[1] https://git-scm.com/book/en/v2/Git-Tools-Submodules [2] http://blogs.atlassian.com/2013/05/alternatives-to-git-submodule-git-subtree... [3] http://travis-ci.org [4] https://travis-ci.org/fniephaus/squeak/builds/119507180 [5] https://www.hpi.uni-potsdam.de/hirschfeld/artefacts/cog/v0.1.0/
--
On Sat, Apr 23, 2016 at 5:10 PM David T. Lewis lewis@mail.msen.com wrote:
On Sat, Apr 23, 2016 at 02:22:29PM +0200, Nicolas Cellier wrote:
2016-04-23 13:56 GMT+02:00 Cl??ment Bera bera.clement@gmail.com:
On Sat, Apr 23, 2016 at 12:54 PM, Bert Freudenberg bert@freudenbergs.de wrote:
> > Actually, Fabio did a complete migration while squeakvm.org was out. > This had a full history of all SVN commits. > > ???Unfortunately??? Ian fixed the server too soon so development continued on > SVN, so now the git repo is again out-of-date. > > We would need to freeze the SVN, do the migration again, and use git from > that point on. It would involve a day of downtime, but doing this sooner > than later would be a good thing. > >
doesn't gitsvn help?
I have to admit that I did not even know that an active git svn bridge was possible. It sounds like this it might be very helpful.
It would be great to have the advantages of git for development, and it could also be helpful to be able to have the squeakvm.org repo updated periodically from git. There are portions of the platforms tree that Eliot has been able to make identical for oscog and trunk, and this seems like a worthwhile effort to continue.
Another possible advantage is that Ian's cmake build process takes advantage of the SVN revision numbering, and it would be good to make sure this stays healthy as development proceeds (it's a lot nicer than autotools).
Eliot, do you have a view on this?
Dave
_,,,^..^,,,_ (phone)

On 23.04.2016, at 19:35, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Esteban, Hi Fabio,
On Apr 23, 2016, at 10:11 AM, Esteban Lorenzano estebanlm@gmail.com wrote:
Hi,
I would like to have a list of constraints so we can sort it (otherwise this will never happen… :S) So far I have:
- sqSCCSVersion.h adapt to git. In Pharo we already have something but I do not think is enough… I will take a look to this.
- do not break Cadence builds. AFAIK, nothing forbids jenkins to stop using SVN and start using GIT (we also use Jenkins for our builds and we didn’t found any problem)… someone has to do the change, but it should be fairly straightforward. Who is the person who can take this task? (I’d do it, but I suppose Cadence has access policy to that)
My colleague Bob Westergaard and I will have to do this. There is no way Cadence will allow people from outside to do so ;-)
So I like Fabio's suggestion of deprecating subversion. We can keep the subversion bridge for some time (6 months, 1 year?), announce when it is going away (if ever?) and give people time to transition.
Are y'all aware that Github automatically provides an SVN bridge?
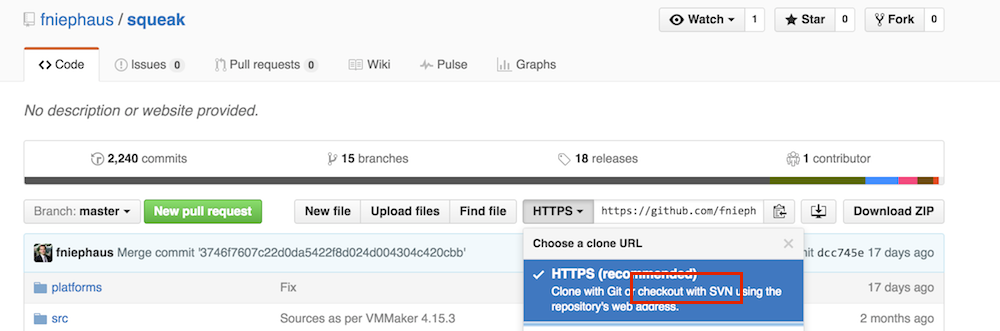{kind=link}
On Apr 23, 2016, at 10:44 AM, Tobias Pape Das.Linux@gmx.de wrote:
On 23.04.2016, at 19:35, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Esteban, Hi Fabio,
On Apr 23, 2016, at 10:11 AM, Esteban Lorenzano estebanlm@gmail.com wrote:
Hi,
I would like to have a list of constraints so we can sort it (otherwise this will never happen… :S) So far I have:
- sqSCCSVersion.h adapt to git. In Pharo we already have something but I do not think is enough… I will take a look to this.
- do not break Cadence builds. AFAIK, nothing forbids jenkins to stop using SVN and start using GIT (we also use Jenkins for our builds and we didn’t found any problem)… someone has to do the change, but it should be fairly straightforward. Who is the person who can take this task? (I’d do it, but I suppose Cadence has access policy to that)
My colleague Bob Westergaard and I will have to do this. There is no way Cadence will allow people from outside to do so ;-)
So I like Fabio's suggestion of deprecating subversion. We can keep the subversion bridge for some time (6 months, 1 year?), announce when it is going away (if ever?) and give people time to transition.
Are y'all aware that Github automatically provides an SVN bridge? <svnongithub.PNG>
Yes :-). That's the key reason we're able to move forward in this. Anyone tested what happens to subversion tags? Are they supported? Do they continue to work? If so, can we provoke the save tag editing that subversion does from git? (The next version number is a server side property).
Hi Fabio,
and the "if not, why not?" question is a request for information, not an expression of annoyance. Subversion tags update the source in checkin. I remember Igor saying that he couldn't find out how to make gig do the same with version numbers (forgive me if my recollection is incorrect). But if git doesn't support this then we need to invent some scheme that does work, for example doing two commits, one to generate a hash and another to commit a tag. But we need sensible increment isn't version numbers, not stupid hashes. It has to be a requirement that one can tell from the output of myvm -version yourvm -version whether the VMs are built from the same or different versions of the source and which one is more up-to-date, and that this depends on version number, not irrelevancies such as build date.
_,,,^..^,,,_ (phone)
On Apr 23, 2016, at 9:54 AM, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Fabio,
On Apr 23, 2016, at 9:40 AM, Fabio Niephaus lists@fniephaus.com wrote:
Hi all,
Bert already mentioned that I've been working on migrating the repository from SVN to Git. I believe there are three problems that need to be solved here:
- Migrating SVN externals for sharing code between branches
This is currently used to share a few directories (e.g. platforms/Cross/plugins) across different branches. But Git does no support this kind of code sharing. Instead, it supports submodules [1] and subtrees [2]. I would suggest to move code that we want to share into separate Git repositories and include them as submodules. I think submodules are easier to understand (GitHub integrates them nicely in their UI). The only drawback: if someone updates code in a shared repository, one needs to update all references to this repository as well. But I'd say this is also a good thing: if someone changes e.g. a plugin and the change is compatible to Cog, but incompatible to the interpreter vm, then the interpreter branch is not automatically broken as soon as one pushes the plugin change. If the above is unclear, I'm happy to explain submodules in more detail.
- Versioning and new releases
If we migrate to Git, I'd recommend to deprecate the way we do versioning in SVN. Instead, we should use Git commit hashes and Git tags.
But have you modified platforms/Cross/vm/sqSCCSVersion.h to capture this information? If so, can you please send me the code so I can integrate it? If not, why not?
Let's say we want to release a new version, we tag the commit of interest with e.g. v1.0.0. When building the Cog VM on this tag, the version will be v1.0.0. If we use GitHub, we might as well use a CI service such as Travis CI [3] to automate the build process. That means, each time someone pushes changes to GitHub, Travis CI will build a new Cog VM (we can call this "bleeding edge"). Let's say I push changes right after the release of v1.0.0, the version for the next build will be something like v1.0.0-37553a9 with "37553a9" being the short SHA1 identifying my latest commit. If we want to release e.g. v1.1.0, we just tag a newer commit and GitHub/Travis CI does the rest for us. I already have this working, you can find a Travis build at [4] and the result at [5]. Obviously, we can push the binaries to a different server.
- Keeping a copy of the code
We of course want to keep a copy of our code at all times in case something happens with GitHub. There are already tools that we can use to automate this. However, I wouldn't try to keep the old SVN repository in sync. I believe this might be quite difficult and I don't see a reason to maintain something we want to deprecate in the first place. Anyway, it should be fairly easy to set up a tool that creates a backup on one of our servers whenever we change code on GitHub.
Doing a migration from SVN to Git(Hub) takes a few hours and I'd recommend we stop pushing code to the SVN as soon as we start to migrate. This obviously requires everyone working with the code base to switch to Git. So please let me know if everyone is comfortable with the migration. If we want to do this next week, I'd recommend to do it on a Thursday or a Friday, because I would be able to do it with Bert sitting two rooms next to me :)
I'm not happy to migrate until there's a functional subversion bridge that works and doesn't break my builds. Cadence pays for my time (and hence pays for a lot of the VM development we enjoy) and its builds use Jenkins and subversion and I will not cooperate with any effort that sabotages this. "Next Thursday" doesn't appear to appreciate the constraints. This has to be done carefully or I will not cooperate.
I hope I have thought about the important things and I'm happy to answer any questions you might have.
Best, Fabio
[1] https://git-scm.com/book/en/v2/Git-Tools-Submodules [2] http://blogs.atlassian.com/2013/05/alternatives-to-git-submodule-git-subtree... [3] http://travis-ci.org [4] https://travis-ci.org/fniephaus/squeak/builds/119507180 [5] https://www.hpi.uni-potsdam.de/hirschfeld/artefacts/cog/v0.1.0/
--
On Sat, Apr 23, 2016 at 5:10 PM David T. Lewis lewis@mail.msen.com wrote:
On Sat, Apr 23, 2016 at 02:22:29PM +0200, Nicolas Cellier wrote:
2016-04-23 13:56 GMT+02:00 Cl??ment Bera bera.clement@gmail.com:
On Sat, Apr 23, 2016 at 12:54 PM, Bert Freudenberg bert@freudenbergs.de wrote:
Actually, Fabio did a complete migration while squeakvm.org was out. This had a full history of all SVN commits.
???Unfortunately??? Ian fixed the server too soon so development continued on SVN, so now the git repo is again out-of-date.
We would need to freeze the SVN, do the migration again, and use git from that point on. It would involve a day of downtime, but doing this sooner than later would be a good thing.
doesn't gitsvn help?
I have to admit that I did not even know that an active git svn bridge was possible. It sounds like this it might be very helpful.
It would be great to have the advantages of git for development, and it could also be helpful to be able to have the squeakvm.org repo updated periodically from git. There are portions of the platforms tree that Eliot has been able to make identical for oscog and trunk, and this seems like a worthwhile effort to continue.
Another possible advantage is that Ian's cmake build process takes advantage of the SVN revision numbering, and it would be good to make sure this stays healthy as development proceeds (it's a lot nicer than autotools).
Eliot, do you have a view on this?
Dave
_,,,^..^,,,_ (phone)
On 23.04.2016, at 19:21, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Fabio,
and the "if not, why not?" question is a request for information, not an expression of annoyance. Subversion tags update the source in checkin. I remember Igor saying that he couldn't find out how to make gig do the same with version numbers (forgive me if my recollection is incorrect). But if git doesn't support this then we need to invent some scheme that does work, for example doing two commits, one to generate a hash and another to commit a tag. But we need sensible increment isn't version numbers, not stupid hashes. It has to be a requirement that one can tell from the output of myvm -version yourvm -version whether the VMs are built from the same or different versions of the source and which one is more up-to-date, and that this depends on version number, not irrelevancies such as build date.
I did such stuff like 4 years ago for self (don't ask why) I changed their whole VM build process to CMake.
Here's some parts that vaguely do what you want want:
This uses "date" to generate a vm build date (lines 12 and following) and "git" to extract VCS infos (lines 39 and following) https://github.com/russellallen/self/blob/master/vm/cmake/configureVmDate.cm... (it is namend .in because it gets configured itself from elsewhere)
It is clearly possible to switch all the stuff to git and cmake and I'd like to see that happen. I would love to have time for that (although it regularly makes me angry :D).
Best regards -Tobias
PS: Personally (i.e. IMHO), I think that IF we go with cmake, we should follo Ians way with probably some mix of the self vm stuff. It can really work. And it can also help us getting things compiled on MS compilers, btw.
_,,,^..^,,,_ (phone)
On Apr 23, 2016, at 9:54 AM, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Fabio,
On Apr 23, 2016, at 9:40 AM, Fabio Niephaus lists@fniephaus.com wrote:
Hi all,
Bert already mentioned that I've been working on migrating the repository from SVN to Git. I believe there are three problems that need to be solved here:
- Migrating SVN externals for sharing code between branches
This is currently used to share a few directories (e.g. platforms/Cross/plugins) across different branches. But Git does no support this kind of code sharing. Instead, it supports submodules [1] and subtrees [2]. I would suggest to move code that we want to share into separate Git repositories and include them as submodules. I think submodules are easier to understand (GitHub integrates them nicely in their UI). The only drawback: if someone updates code in a shared repository, one needs to update all references to this repository as well. But I'd say this is also a good thing: if someone changes e.g. a plugin and the change is compatible to Cog, but incompatible to the interpreter vm, then the interpreter branch is not automatically broken as soon as one pushes the plugin change. If the above is unclear, I'm happy to explain submodules in more detail.
- Versioning and new releases
If we migrate to Git, I'd recommend to deprecate the way we do versioning in SVN. Instead, we should use Git commit hashes and Git tags.
But have you modified platforms/Cross/vm/sqSCCSVersion.h to capture this information? If so, can you please send me the code so I can integrate it? If not, why not?
Let's say we want to release a new version, we tag the commit of interest with e.g. v1.0.0. When building the Cog VM on this tag, the version will be v1.0.0. If we use GitHub, we might as well use a CI service such as Travis CI [3] to automate the build process. That means, each time someone pushes changes to GitHub, Travis CI will build a new Cog VM (we can call this "bleeding edge"). Let's say I push changes right after the release of v1.0.0, the version for the next build will be something like v1.0.0-37553a9 with "37553a9" being the short SHA1 identifying my latest commit. If we want to release e.g. v1.1.0, we just tag a newer commit and GitHub/Travis CI does the rest for us. I already have this working, you can find a Travis build at [4] and the result at [5]. Obviously, we can push the binaries to a different server.
- Keeping a copy of the code
We of course want to keep a copy of our code at all times in case something happens with GitHub. There are already tools that we can use to automate this. However, I wouldn't try to keep the old SVN repository in sync. I believe this might be quite difficult and I don't see a reason to maintain something we want to deprecate in the first place. Anyway, it should be fairly easy to set up a tool that creates a backup on one of our servers whenever we change code on GitHub.
Doing a migration from SVN to Git(Hub) takes a few hours and I'd recommend we stop pushing code to the SVN as soon as we start to migrate. This obviously requires everyone working with the code base to switch to Git. So please let me know if everyone is comfortable with the migration. If we want to do this next week, I'd recommend to do it on a Thursday or a Friday, because I would be able to do it with Bert sitting two rooms next to me :)
I'm not happy to migrate until there's a functional subversion bridge that works and doesn't break my builds. Cadence pays for my time (and hence pays for a lot of the VM development we enjoy) and its builds use Jenkins and subversion and I will not cooperate with any effort that sabotages this. "Next Thursday" doesn't appear to appreciate the constraints. This has to be done carefully or I will not cooperate.
I hope I have thought about the important things and I'm happy to answer any questions you might have.
Best, Fabio
[1] https://git-scm.com/book/en/v2/Git-Tools-Submodules [2] http://blogs.atlassian.com/2013/05/alternatives-to-git-submodule-git-subtree... [3] http://travis-ci.org [4] https://travis-ci.org/fniephaus/squeak/builds/119507180 [5] https://www.hpi.uni-potsdam.de/hirschfeld/artefacts/cog/v0.1.0/
--
On Sat, Apr 23, 2016 at 5:10 PM David T. Lewis lewis@mail.msen.com wrote:
On Sat, Apr 23, 2016 at 02:22:29PM +0200, Nicolas Cellier wrote:
2016-04-23 13:56 GMT+02:00 Cl??ment Bera bera.clement@gmail.com:
On Sat, Apr 23, 2016 at 12:54 PM, Bert Freudenberg bert@freudenbergs.de wrote:
Actually, Fabio did a complete migration while squeakvm.org was out. This had a full history of all SVN commits.
???Unfortunately??? Ian fixed the server too soon so development continued on SVN, so now the git repo is again out-of-date.
We would need to freeze the SVN, do the migration again, and use git from that point on. It would involve a day of downtime, but doing this sooner than later would be a good thing.
doesn't gitsvn help?
I have to admit that I did not even know that an active git svn bridge was possible. It sounds like this it might be very helpful.
It would be great to have the advantages of git for development, and it could also be helpful to be able to have the squeakvm.org repo updated periodically from git. There are portions of the platforms tree that Eliot has been able to make identical for oscog and trunk, and this seems like a worthwhile effort to continue.
Another possible advantage is that Ian's cmake build process takes advantage of the SVN revision numbering, and it would be good to make sure this stays healthy as development proceeds (it's a lot nicer than autotools).
Eliot, do you have a view on this?
Dave
_,,,^..^,,,_ (phone)
Hi Tobias,
On Apr 23, 2016, at 10:30 AM, Tobias Pape Das.Linux@gmx.de wrote:
On 23.04.2016, at 19:21, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Fabio,
and the "if not, why not?" question is a request for information, not an expression of annoyance. Subversion tags update the source in checkin. I remember Igor saying that he couldn't find out how to make gig do the same with version numbers (forgive me if my recollection is incorrect). But if git doesn't support this then we need to invent some scheme that does work, for example doing two commits, one to generate a hash and another to commit a tag. But we need sensible increment isn't version numbers, not stupid hashes. It has to be a requirement that one can tell from the output of myvm -version yourvm -version whether the VMs are built from the same or different versions of the source and which one is more up-to-date, and that this depends on version number, not irrelevancies such as build date.
I did such stuff like 4 years ago for self (don't ask why) I changed their whole VM build process to CMake.
Here's some parts that vaguely do what you want want:
This uses "date" to generate a vm build date (lines 12 and following) and "git" to extract VCS infos (lines 39 and following) https://github.com/russellallen/self/blob/master/vm/cmake/configureVmDate.cm... (it is namend .in because it gets configured itself from elsewhere)
It is clearly possible to switch all the stuff to git and cmake and I'd like to see that happen. I would love to have time for that (although it regularly makes me angry :D).
Best regards -Tobias
PS: Personally (i.e. IMHO), I think that IF we go with cmake, we should follo Ians way with probably some mix of the self vm stuff. It can really work. And it can also help us getting things compiled on MS compilers, btw.
What do you mean by "Ian's way" exactly? Please describe it.
Things I know: - Ian's autoconf code (platforms/unix/conf, the various additional snippets that get included when one builds the autoconf support, rather than things that get computed at build time) is extremely difficult to work with - gmake files work with MS compilers too
I am strongly in favor of gmake files. It's /much/ easier to work with. Please, please, please let's limit the use of cmake to generating a config file as I've already discussed.
_,,,^..^,,,_ (phone)
On Apr 23, 2016, at 9:54 AM, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Fabio,
On Apr 23, 2016, at 9:40 AM, Fabio Niephaus lists@fniephaus.com wrote:
Hi all,
Bert already mentioned that I've been working on migrating the repository from SVN to Git. I believe there are three problems that need to be solved here:
- Migrating SVN externals for sharing code between branches
This is currently used to share a few directories (e.g. platforms/Cross/plugins) across different branches. But Git does no support this kind of code sharing. Instead, it supports submodules [1] and subtrees [2]. I would suggest to move code that we want to share into separate Git repositories and include them as submodules. I think submodules are easier to understand (GitHub integrates them nicely in their UI). The only drawback: if someone updates code in a shared repository, one needs to update all references to this repository as well. But I'd say this is also a good thing: if someone changes e.g. a plugin and the change is compatible to Cog, but incompatible to the interpreter vm, then the interpreter branch is not automatically broken as soon as one pushes the plugin change. If the above is unclear, I'm happy to explain submodules in more detail.
- Versioning and new releases
If we migrate to Git, I'd recommend to deprecate the way we do versioning in SVN. Instead, we should use Git commit hashes and Git tags.
But have you modified platforms/Cross/vm/sqSCCSVersion.h to capture this information? If so, can you please send me the code so I can integrate it? If not, why not?
Let's say we want to release a new version, we tag the commit of interest with e.g. v1.0.0. When building the Cog VM on this tag, the version will be v1.0.0. If we use GitHub, we might as well use a CI service such as Travis CI [3] to automate the build process. That means, each time someone pushes changes to GitHub, Travis CI will build a new Cog VM (we can call this "bleeding edge"). Let's say I push changes right after the release of v1.0.0, the version for the next build will be something like v1.0.0-37553a9 with "37553a9" being the short SHA1 identifying my latest commit. If we want to release e.g. v1.1.0, we just tag a newer commit and GitHub/Travis CI does the rest for us. I already have this working, you can find a Travis build at [4] and the result at [5]. Obviously, we can push the binaries to a different server.
- Keeping a copy of the code
We of course want to keep a copy of our code at all times in case something happens with GitHub. There are already tools that we can use to automate this. However, I wouldn't try to keep the old SVN repository in sync. I believe this might be quite difficult and I don't see a reason to maintain something we want to deprecate in the first place. Anyway, it should be fairly easy to set up a tool that creates a backup on one of our servers whenever we change code on GitHub.
Doing a migration from SVN to Git(Hub) takes a few hours and I'd recommend we stop pushing code to the SVN as soon as we start to migrate. This obviously requires everyone working with the code base to switch to Git. So please let me know if everyone is comfortable with the migration. If we want to do this next week, I'd recommend to do it on a Thursday or a Friday, because I would be able to do it with Bert sitting two rooms next to me :)
I'm not happy to migrate until there's a functional subversion bridge that works and doesn't break my builds. Cadence pays for my time (and hence pays for a lot of the VM development we enjoy) and its builds use Jenkins and subversion and I will not cooperate with any effort that sabotages this. "Next Thursday" doesn't appear to appreciate the constraints. This has to be done carefully or I will not cooperate.
I hope I have thought about the important things and I'm happy to answer any questions you might have.
Best, Fabio
[1] https://git-scm.com/book/en/v2/Git-Tools-Submodules [2] http://blogs.atlassian.com/2013/05/alternatives-to-git-submodule-git-subtree... [3] http://travis-ci.org [4] https://travis-ci.org/fniephaus/squeak/builds/119507180 [5] https://www.hpi.uni-potsdam.de/hirschfeld/artefacts/cog/v0.1.0/
--
On Sat, Apr 23, 2016 at 5:10 PM David T. Lewis lewis@mail.msen.com wrote:
On Sat, Apr 23, 2016 at 02:22:29PM +0200, Nicolas Cellier wrote:
2016-04-23 13:56 GMT+02:00 Cl??ment Bera bera.clement@gmail.com:
On Sat, Apr 23, 2016 at 12:54 PM, Bert Freudenberg bert@freudenbergs.de wrote:
> > Actually, Fabio did a complete migration while squeakvm.org was out. > This had a full history of all SVN commits. > > ???Unfortunately??? Ian fixed the server too soon so development continued on > SVN, so now the git repo is again out-of-date. > > We would need to freeze the SVN, do the migration again, and use git from > that point on. It would involve a day of downtime, but doing this sooner > than later would be a good thing.
doesn't gitsvn help?
I have to admit that I did not even know that an active git svn bridge was possible. It sounds like this it might be very helpful.
It would be great to have the advantages of git for development, and it could also be helpful to be able to have the squeakvm.org repo updated periodically from git. There are portions of the platforms tree that Eliot has been able to make identical for oscog and trunk, and this seems like a worthwhile effort to continue.
Another possible advantage is that Ian's cmake build process takes advantage of the SVN revision numbering, and it would be good to make sure this stays healthy as development proceeds (it's a lot nicer than autotools).
Eliot, do you have a view on this?
Dave
_,,,^..^,,,_ (phone)
On 23.04.2016, at 19:44, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Tobias,
On Apr 23, 2016, at 10:30 AM, Tobias Pape Das.Linux@gmx.de wrote:
On 23.04.2016, at 19:21, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Fabio,
and the "if not, why not?" question is a request for information, not an expression of annoyance. Subversion tags update the source in checkin. I remember Igor saying that he couldn't find out how to make gig do the same with version numbers (forgive me if my recollection is incorrect). But if git doesn't support this then we need to invent some scheme that does work, for example doing two commits, one to generate a hash and another to commit a tag. But we need sensible increment isn't version numbers, not stupid hashes. It has to be a requirement that one can tell from the output of myvm -version yourvm -version whether the VMs are built from the same or different versions of the source and which one is more up-to-date, and that this depends on version number, not irrelevancies such as build date.
I did such stuff like 4 years ago for self (don't ask why) I changed their whole VM build process to CMake.
Here's some parts that vaguely do what you want want:
This uses "date" to generate a vm build date (lines 12 and following) and "git" to extract VCS infos (lines 39 and following) https://github.com/russellallen/self/blob/master/vm/cmake/configureVmDate.cm... (it is namend .in because it gets configured itself from elsewhere)
It is clearly possible to switch all the stuff to git and cmake and I'd like to see that happen. I would love to have time for that (although it regularly makes me angry :D).
Best regards -Tobias
PS: Personally (i.e. IMHO), I think that IF we go with cmake, we should follo Ians way with probably some mix of the self vm stuff. It can really work. And it can also help us getting things compiled on MS compilers, btw.
What do you mean by "Ian's way" exactly? Please describe it.
Things I know:
- Ian's autoconf code (platforms/unix/conf, the various additional snippets that get included when one builds the autoconf support, rather than things that get computed at build time) is extremely difficult to work with
Ian's unix conf uses CMake for a while now. There's no autoconf. Thers no platforms/unix/conf, neither in http://www.squeakvm.org/svn/squeak/trunk/platforms/unix/ nor in https://github.com/fniephaus/squeak/tree/master/platforms/unix
So I'm a bit confused about what you refer to.
- gmake files work with MS compilers too
I am strongly in favor of gmake files. It's /much/ easier to work with.
Sorry, i beg to differ.
Please, please, please let's limit the use of cmake to generating a config file as I've already discussed.
you mean gnu make?
:/
However, its saturday evening, I don't like to argue at that time. Maybe I'll find some time next week to make a write up :)
Best -Tobias
_,,,^..^,,,_ (phone)
On Apr 23, 2016, at 9:54 AM, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Fabio,
On Apr 23, 2016, at 9:40 AM, Fabio Niephaus lists@fniephaus.com wrote:
Hi all,
Bert already mentioned that I've been working on migrating the repository from SVN to Git. I believe there are three problems that need to be solved here:
- Migrating SVN externals for sharing code between branches
This is currently used to share a few directories (e.g. platforms/Cross/plugins) across different branches. But Git does no support this kind of code sharing. Instead, it supports submodules [1] and subtrees [2]. I would suggest to move code that we want to share into separate Git repositories and include them as submodules. I think submodules are easier to understand (GitHub integrates them nicely in their UI). The only drawback: if someone updates code in a shared repository, one needs to update all references to this repository as well. But I'd say this is also a good thing: if someone changes e.g. a plugin and the change is compatible to Cog, but incompatible to the interpreter vm, then the interpreter branch is not automatically broken as soon as one pushes the plugin change. If the above is unclear, I'm happy to explain submodules in more detail.
- Versioning and new releases
If we migrate to Git, I'd recommend to deprecate the way we do versioning in SVN. Instead, we should use Git commit hashes and Git tags.
But have you modified platforms/Cross/vm/sqSCCSVersion.h to capture this information? If so, can you please send me the code so I can integrate it? If not, why not?
Let's say we want to release a new version, we tag the commit of interest with e.g. v1.0.0. When building the Cog VM on this tag, the version will be v1.0.0. If we use GitHub, we might as well use a CI service such as Travis CI [3] to automate the build process. That means, each time someone pushes changes to GitHub, Travis CI will build a new Cog VM (we can call this "bleeding edge"). Let's say I push changes right after the release of v1.0.0, the version for the next build will be something like v1.0.0-37553a9 with "37553a9" being the short SHA1 identifying my latest commit. If we want to release e.g. v1.1.0, we just tag a newer commit and GitHub/Travis CI does the rest for us. I already have this working, you can find a Travis build at [4] and the result at [5]. Obviously, we can push the binaries to a different server.
- Keeping a copy of the code
We of course want to keep a copy of our code at all times in case something happens with GitHub. There are already tools that we can use to automate this. However, I wouldn't try to keep the old SVN repository in sync. I believe this might be quite difficult and I don't see a reason to maintain something we want to deprecate in the first place. Anyway, it should be fairly easy to set up a tool that creates a backup on one of our servers whenever we change code on GitHub.
Doing a migration from SVN to Git(Hub) takes a few hours and I'd recommend we stop pushing code to the SVN as soon as we start to migrate. This obviously requires everyone working with the code base to switch to Git. So please let me know if everyone is comfortable with the migration. If we want to do this next week, I'd recommend to do it on a Thursday or a Friday, because I would be able to do it with Bert sitting two rooms next to me :)
I'm not happy to migrate until there's a functional subversion bridge that works and doesn't break my builds. Cadence pays for my time (and hence pays for a lot of the VM development we enjoy) and its builds use Jenkins and subversion and I will not cooperate with any effort that sabotages this. "Next Thursday" doesn't appear to appreciate the constraints. This has to be done carefully or I will not cooperate.
I hope I have thought about the important things and I'm happy to answer any questions you might have.
Best, Fabio
[1] https://git-scm.com/book/en/v2/Git-Tools-Submodules [2] http://blogs.atlassian.com/2013/05/alternatives-to-git-submodule-git-subtree... [3] http://travis-ci.org [4] https://travis-ci.org/fniephaus/squeak/builds/119507180 [5] https://www.hpi.uni-potsdam.de/hirschfeld/artefacts/cog/v0.1.0/
--
On Sat, Apr 23, 2016 at 5:10 PM David T. Lewis lewis@mail.msen.com wrote:
On Sat, Apr 23, 2016 at 02:22:29PM +0200, Nicolas Cellier wrote:
I have to admit that I did not even know that an active git svn bridge was possible. It sounds like this it might be very helpful.
It would be great to have the advantages of git for development, and it could also be helpful to be able to have the squeakvm.org repo updated periodically from git. There are portions of the platforms tree that Eliot has been able to make identical for oscog and trunk, and this seems like a worthwhile effort to continue.
Another possible advantage is that Ian's cmake build process takes advantage of the SVN revision numbering, and it would be good to make sure this stays healthy as development proceeds (it's a lot nicer than autotools).
Eliot, do you have a view on this?
Dave
_,,,^..^,,,_ (phone)
Hi Eliot,
RE sqSCCSVersion.h: I'm not sure if you like this approach, but I decided to just use macros for version, date and url [1]. I then defined those macros in a global build file [2] and added what I called $COGVOPTS to CFLAGS [3]. It looks like pharo-vm is doing something similar [4], but their approach doesn't require as much code to change. It's probably good if Esteban explains why "he thinks it is not enough".
Best, Fabio
[1] https://github.com/fniephaus/squeak/blob/Cog/platforms/Cross/vm/sqSCCSVersio... [2] https://github.com/fniephaus/squeak/blob/Cog/.travis_build.sh#L8-L11 [3] https://github.com/fniephaus/squeak/blob/ae1a8fd6f99d0e03c37d4037c1586870ca6... [4] https://github.com/pharo-project/pharo-vm/blob/09a717119732559b43a13e8c6f5c4...
Hi Tobias,
On Sat, Apr 23, 2016 at 10:55 AM, Tobias Pape Das.Linux@gmx.de wrote:
On 23.04.2016, at 19:44, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Tobias,
On Apr 23, 2016, at 10:30 AM, Tobias Pape Das.Linux@gmx.de wrote:
On 23.04.2016, at 19:21, Eliot Miranda eliot.miranda@gmail.com
wrote:
Hi Fabio,
and the "if not, why not?" question is a request for information, not
an expression of annoyance. Subversion tags update the source in checkin. I remember Igor saying that he couldn't find out how to make gig do the same with version numbers (forgive me if my recollection is incorrect). But if git doesn't support this then we need to invent some scheme that does work, for example doing two commits, one to generate a hash and another to commit a tag. But we need sensible increment isn't version numbers, not stupid hashes. It has to be a requirement that one can tell from the output of
myvm -version yourvm -version whether the VMs are built from the same or different versions of the
source and which one is more up-to-date, and that this depends on version number, not irrelevancies such as build date.
I did such stuff like 4 years ago for self (don't ask why) I changed their whole VM build process to CMake.
Here's some parts that vaguely do what you want want:
This uses "date" to generate a vm build date (lines 12 and following) and "git" to extract VCS infos (lines 39 and following)
https://github.com/russellallen/self/blob/master/vm/cmake/configureVmDate.cm...
(it is namend .in because it gets configured itself from elsewhere)
It is clearly possible to switch all the stuff to git and cmake and I'd
like to see that happen.
I would love to have time for that (although it regularly makes me
angry :D).
Best regards -Tobias
PS: Personally (i.e. IMHO), I think that IF we go with cmake, we should
follo Ians way with
probably some mix of the self vm stuff. It can really work. And it
can also help us
getting things compiled on MS compilers, btw.
What do you mean by "Ian's way" exactly? Please describe it.
Things I know:
- Ian's autoconf code (platforms/unix/conf, the various additional
snippets that get included when one builds the autoconf support, rather than things that get computed at build time) is extremely difficult to work with
Ian's unix conf uses CMake for a while now. There's no autoconf. Thers no platforms/unix/conf, neither in http://www.squeakvm.org/svn/squeak/trunk/platforms/unix/ nor in https://github.com/fniephaus/squeak/tree/master/platforms/unix
Yes, I know. I also know that, for example, http://www.squeakvm.org/svn/squeak/trunk/platforms/unix/cmake/Plugins.cmake is /not/ easy to work with. It is essentially impenetrable without significant thought. I will critique fully below.
So I'm a bit confused about what you refer to.
- gmake files work with MS compilers too
I am strongly in favor of gmake files. It's /much/ easier to work with.
Sorry, i beg to differ.
Please, please, please let's limit the use of cmake to generating a
config file as I've already discussed.
you mean gnu make?
Yes. And as examples I invite you to read, for example,
http://www.squeakvm.org/svn/squeak/branches/Cog/ build.macos64x64/common/Makefile.app build.macos64x64/common/Makefile.app.newspeak build.macos64x64/common/Makefile.app.squeak.cog build.macos64x64/common/Makefile.flags build.macos64x64/common/Makefile.plugin build.macos64x64/common/Makefile.rules build.macos64x64/common/Makefile.vm
build.macos64x64/pharo.cog.spur/Makefile build.macos64x64/squeak.cog.spur/Makefile build.macos64x64/squeak.stack.spur/Makefile
build.win32x86/common/Makefile build.win32x86/common/Makefile.plugin build.win32x86/common/Makefile.rules
So what are the trade offs? I'll mark cmake plusses with '+', gmake advantages over cmake '-'.
+ cmake and autoconf include systems for computing a platform-specific config.h file from aplatform-independent template that identifies a platform's basic facilities, word size, available APIs, etc. This is of value. I've described earlier in this thread how I want to use this, by generating a single copy of the platform-speciifc file per platform-specific build directory, where each build directory includes several distinct VMs (squeak vs pharo vs newspeak * context vs stack vs cog vs sista * v3 vs spur) and a single copy of support libraries such as Bochs, Cairo et al.
- cmake is second-order. Editing the code does /not/ produce the end product. One must run the build system, inspect the reduced makefiles and map back to the cmake input to correct errors. This is hard. cmake is not significantly better than autoconf in this regard. It took me longer to modify the autoconf system to optionally compile the cogit.c file (now cogitIA32.c, cogitARM32.c et al) when adding Cog to the StackInterpreter build than it did to write the entire set of Mac OS X gnu make makefiles.
- cmake requires that for complex plains one both edit the cmake config files /and/ cmake Makefile includes (e.g. there are
http://www.squeakvm.org/svn/squeak/trunk/platforms/unix/plugins/XDisplayCont... {build.cmake,config.cmake} but in the Gnu makefiles there is only ever a single Makefile that includes a more generic one.
- cmake duplicates effort for every build. The Cog sources build VMs for two versions (v3 & Spur) of two Smalltalk dialects (each with their own icon sets), and for Newspeak. To be able to debug the VM effectively each VM is bolt in three forms, production, assert (asserts at -O1) and debug (asserts at -O0). That's a /lot/ of builds, and waiting for cmake (or autoconf) to configure, and redoing it for each separate build is a waste. The gnu makefiles are first order; they are simply used directly; no slow configure step is required
- AFAICT, there is no support for /any/ build dependency information in the cmake sources (this is information on which C files include which headers, or other C files, which is essential in enabling fast builds when developing the VM). The Gnu Makefiles I've written, following well-documented established patterns, maintains dependency information and shares it between production,assert and debug builds.
- cmake offers no solution to the problem of building support libraries; neither does gnu make. But in my build layout there is a simple convention for multi-platform builds, and for sharing a single copy of each support library between all builds for that platform, i.e. http://www.squeakvm.org/svn/squeak/branches/Cog/ build.linux32ARM build.linux64x64 build.macos64x64 build.linux32x86 build.macos32x86 build.win32x86 and e.g. bochsx64 and bochsx86 within those directories.
:/
However, its saturday evening, I don't like to argue at that time. Maybe I'll find some time next week to make a write up :)
OK, but please address my points above, and please realise that my preferred approach is based on hard experience; I'm not choosing gnu makefiles because of nostalgia or familiarity. I chose them because they're much more productive, apart from cake and autoconf's one advantage, generating a platform-specific config.h. And that I'd like to steal.
Best -Tobias
_,,,^..^,,,_ (phone)
On Apr 23, 2016, at 9:54 AM, Eliot Miranda eliot.miranda@gmail.com
wrote:
Hi Fabio,
On Apr 23, 2016, at 9:40 AM, Fabio Niephaus lists@fniephaus.com
wrote:
Hi all,
Bert already mentioned that I've been working on migrating the
repository from SVN to Git.
I believe there are three problems that need to be solved here:
- Migrating SVN externals for sharing code between branches
This is currently used to share a few directories (e.g.
platforms/Cross/plugins) across different
branches. But Git does no support this kind of code sharing.
Instead, it supports submodules [1]
and subtrees [2]. I would suggest to move code that we want to share
into separate Git
repositories and include them as submodules. I think submodules are
easier to understand
(GitHub integrates them nicely in their UI). The only drawback: if
someone updates code in a
shared repository, one needs to update all references to this
repository as well. But I'd say this
is also a good thing: if someone changes e.g. a plugin and the
change is compatible to Cog,
but incompatible to the interpreter vm, then the interpreter branch
is not automatically broken
as soon as one pushes the plugin change. If the above is unclear,
I'm happy to explain
submodules in more detail.
- Versioning and new releases
If we migrate to Git, I'd recommend to deprecate the way we do
versioning in SVN. Instead, we
should use Git commit hashes and Git tags.
But have you modified platforms/Cross/vm/sqSCCSVersion.h to capture
this information? If so, can you please send me the code so I can integrate it? If not, why not?
Let's say we want to release a new version, we tag the commit of interest with e.g. v1.0.0. When building the Cog VM on
this tag, the version will be
v1.0.0. If we use GitHub, we might as well use a CI service such as
Travis CI [3] to automate the
build process. That means, each time someone pushes changes to
GitHub, Travis CI will build a
new Cog VM (we can call this "bleeding edge"). Let's say I push
changes right after the release
of v1.0.0, the version for the next build will be something like
v1.0.0-37553a9 with "37553a9"
being the short SHA1 identifying my latest commit. If we want to
release e.g. v1.1.0, we just tag
a newer commit and GitHub/Travis CI does the rest for us. I already
have this working, you can
find a Travis build at [4] and the result at [5]. Obviously, we can
push the binaries to a different
server.
- Keeping a copy of the code
We of course want to keep a copy of our code at all times in case
something happens with
GitHub. There are already tools that we can use to automate this.
However, I wouldn't try to keep
the old SVN repository in sync. I believe this might be quite
difficult and I don't see a reason to
maintain something we want to deprecate in the first place. Anyway,
it should be fairly easy to
set up a tool that creates a backup on one of our servers whenever
we change code on GitHub.
Doing a migration from SVN to Git(Hub) takes a few hours and I'd
recommend we stop pushing
code to the SVN as soon as we start to migrate. This obviously
requires everyone working with
the code base to switch to Git. So please let me know if everyone is
comfortable with the
migration. If we want to do this next week, I'd recommend to do it
on a Thursday or a Friday,
because I would be able to do it with Bert sitting two rooms next to
me :)
I'm not happy to migrate until there's a functional subversion bridge
that works and doesn't break my builds. Cadence pays for my time (and hence pays for a lot of the VM development we enjoy) and its builds use Jenkins and subversion and I will not cooperate with any effort that sabotages this. "Next Thursday" doesn't appear to appreciate the constraints. This has to be done carefully or I will not cooperate.
I hope I have thought about the important things and I'm happy to
answer any questions you
might have.
Best, Fabio
http://blogs.atlassian.com/2013/05/alternatives-to-git-submodule-git-subtree...
[3] http://travis-ci.org [4] https://travis-ci.org/fniephaus/squeak/builds/119507180 [5] https://www.hpi.uni-potsdam.de/hirschfeld/artefacts/cog/v0.1.0/
--
On Sat, Apr 23, 2016 at 5:10 PM David T. Lewis lewis@mail.msen.com
wrote:
On Sat, Apr 23, 2016 at 02:22:29PM +0200, Nicolas Cellier wrote:
I have to admit that I did not even know that an active git svn
bridge
was possible. It sounds like this it might be very helpful.
It would be great to have the advantages of git for development, and it could also be helpful to be able to have the squeakvm.org repo
updated
periodically from git. There are portions of the platforms tree that
Eliot
has been able to make identical for oscog and trunk, and this seems
like
a worthwhile effort to continue.
Another possible advantage is that Ian's cmake build process takes
advantage
of the SVN revision numbering, and it would be good to make sure
this stays
healthy as development proceeds (it's a lot nicer than autotools).
Eliot, do you have a view on this?
Dave
_,,,^..^,,,_ (phone)

On Sun, Apr 24, 2016 at 3:33 AM, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Tobias,
On Sat, Apr 23, 2016 at 10:55 AM, Tobias Pape Das.Linux@gmx.de wrote:
On 23.04.2016, at 19:44, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Tobias,
On Apr 23, 2016, at 10:30 AM, Tobias Pape Das.Linux@gmx.de wrote:
On 23.04.2016, at 19:21, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Fabio,
and the "if not, why not?" question is a request for information, not an expression of annoyance. Subversion tags update the source in checkin. I remember Igor saying that he couldn't find out how to make gig do the same with version numbers (forgive me if my recollection is incorrect). But if git doesn't support this then we need to invent some scheme that does work, for example doing two commits, one to generate a hash and another to commit a tag. But we need sensible increment isn't version numbers, not stupid hashes. It has to be a requirement that one can tell from the output of myvm -version yourvm -version whether the VMs are built from the same or different versions of the source and which one is more up-to-date, and that this depends on version number, not irrelevancies such as build date.
I did such stuff like 4 years ago for self (don't ask why) I changed their whole VM build process to CMake.
Here's some parts that vaguely do what you want want:
This uses "date" to generate a vm build date (lines 12 and following) and "git" to extract VCS infos (lines 39 and following) https://github.com/russellallen/self/blob/master/vm/cmake/configureVmDate.cm... (it is namend .in because it gets configured itself from elsewhere)
It is clearly possible to switch all the stuff to git and cmake and I'd like to see that happen. I would love to have time for that (although it regularly makes me angry :D).
Best regards -Tobias
PS: Personally (i.e. IMHO), I think that IF we go with cmake, we should follo Ians way with probably some mix of the self vm stuff. It can really work. And it can also help us getting things compiled on MS compilers, btw.
What do you mean by "Ian's way" exactly? Please describe it.
Things I know:
- Ian's autoconf code (platforms/unix/conf, the various additional snippets that get included when one builds the autoconf support, rather than things that get computed at build time) is extremely difficult to work with
Ian's unix conf uses CMake for a while now. There's no autoconf. Thers no platforms/unix/conf, neither in http://www.squeakvm.org/svn/squeak/trunk/platforms/unix/ nor in https://github.com/fniephaus/squeak/tree/master/platforms/unix
Yes, I know. I also know that, for example, http://www.squeakvm.org/svn/squeak/trunk/platforms/unix/cmake/Plugins.cmake is /not/ easy to work with. It is essentially impenetrable without significant thought. I will critique fully below.
So I'm a bit confused about what you refer to.
- gmake files work with MS compilers too
I am strongly in favor of gmake files. It's /much/ easier to work with.
Sorry, i beg to differ.
Please, please, please let's limit the use of cmake to generating a config file as I've already discussed.
you mean gnu make?
Yes. And as examples I invite you to read, for example,
http://www.squeakvm.org/svn/squeak/branches/Cog/ build.macos64x64/common/Makefile.app build.macos64x64/common/Makefile.app.newspeak build.macos64x64/common/Makefile.app.squeak.cog build.macos64x64/common/Makefile.flags build.macos64x64/common/Makefile.plugin build.macos64x64/common/Makefile.rules build.macos64x64/common/Makefile.vm
build.macos64x64/pharo.cog.spur/Makefile build.macos64x64/squeak.cog.spur/Makefile build.macos64x64/squeak.stack.spur/Makefile build.win32x86/common/Makefile build.win32x86/common/Makefile.plugin build.win32x86/common/Makefile.rulesSo what are the trade offs? I'll mark cmake plusses with '+', gmake advantages over cmake '-'.
- cmake and autoconf include systems for computing a platform-specific config.h file from aplatform-independent template that identifies a platform's basic facilities, word size, available APIs, etc. This is of value. I've described earlier in this thread how I want to use this, by generating a single copy of the platform-speciifc file per platform-specific build directory, where each build directory includes several distinct VMs (squeak vs pharo vs newspeak * context vs stack vs cog vs sista * v3 vs spur) and a single copy of support libraries such as Bochs, Cairo et al.
Naive questions about using a one-time generated config.h... Is this enough to support cross-compilation with cmake itself? Where in the priorities is cross-compilation?
Of minor concern (because I've no clue of the impact)... "Rumprun unikernels are always cross-compiled. In practical terms, that statement means that the compiler will never run on a Rumprun unikernel. Instead, the compiler always runs on a build host (e.g. a regular Linux/BSD system)."
cheers -ben
On Sun, Apr 24, 2016 at 8:00 AM, Ben Coman btc@openinworld.com wrote:
On Sun, Apr 24, 2016 at 3:33 AM, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Tobias,
On Sat, Apr 23, 2016 at 10:55 AM, Tobias Pape Das.Linux@gmx.de wrote:
On 23.04.2016, at 19:44, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Tobias,
On Apr 23, 2016, at 10:30 AM, Tobias Pape Das.Linux@gmx.de wrote:
On 23.04.2016, at 19:21, Eliot Miranda eliot.miranda@gmail.com
wrote:
Hi Fabio,
and the "if not, why not?" question is a request for information,
not an expression of annoyance. Subversion tags update the source in checkin. I remember Igor saying that he couldn't find out how to make gig do the same with version numbers (forgive me if my recollection is incorrect). But if git doesn't support this then we need to invent some scheme that does work, for example doing two commits, one to generate a hash and another to commit a tag. But we need sensible increment isn't version numbers, not stupid hashes. It has to be a requirement that one can tell from the output of
myvm -version yourvm -version whether the VMs are built from the same or different versions of
the source and which one is more up-to-date, and that this depends on version number, not irrelevancies such as build date.
I did such stuff like 4 years ago for self (don't ask why) I changed their whole VM build process to CMake.
Here's some parts that vaguely do what you want want:
This uses "date" to generate a vm build date (lines 12 and following) and "git" to extract VCS infos (lines 39 and following)
https://github.com/russellallen/self/blob/master/vm/cmake/configureVmDate.cm...
(it is namend .in because it gets configured itself from elsewhere)
It is clearly possible to switch all the stuff to git and cmake and
I'd like to see that happen.
I would love to have time for that (although it regularly makes me
angry :D).
Best regards -Tobias
PS: Personally (i.e. IMHO), I think that IF we go with cmake, we
should follo Ians way with
probably some mix of the self vm stuff. It can really work. And it
can also help us
getting things compiled on MS compilers, btw.
What do you mean by "Ian's way" exactly? Please describe it.
Things I know:
- Ian's autoconf code (platforms/unix/conf, the various additional
snippets that get included when one builds the autoconf support, rather than things that get computed at build time) is extremely difficult to work with
Ian's unix conf uses CMake for a while now. There's no autoconf. Thers no platforms/unix/conf, neither in http://www.squeakvm.org/svn/squeak/trunk/platforms/unix/ nor in https://github.com/fniephaus/squeak/tree/master/platforms/unix
Yes, I know. I also know that, for example,
http://www.squeakvm.org/svn/squeak/trunk/platforms/unix/cmake/Plugins.cmake is /not/ easy to work with. It is essentially impenetrable without significant thought. I will critique fully below.
So I'm a bit confused about what you refer to.
- gmake files work with MS compilers too
I am strongly in favor of gmake files. It's /much/ easier to work
with.
Sorry, i beg to differ.
Please, please, please let's limit the use of cmake to generating a
config file as I've already discussed.
you mean gnu make?
Yes. And as examples I invite you to read, for example,
http://www.squeakvm.org/svn/squeak/branches/Cog/ build.macos64x64/common/Makefile.app build.macos64x64/common/Makefile.app.newspeak build.macos64x64/common/Makefile.app.squeak.cog build.macos64x64/common/Makefile.flags build.macos64x64/common/Makefile.plugin build.macos64x64/common/Makefile.rules build.macos64x64/common/Makefile.vm
build.macos64x64/pharo.cog.spur/Makefile build.macos64x64/squeak.cog.spur/Makefile build.macos64x64/squeak.stack.spur/Makefile build.win32x86/common/Makefile build.win32x86/common/Makefile.plugin build.win32x86/common/Makefile.rulesSo what are the trade offs? I'll mark cmake plusses with '+', gmake
advantages over cmake '-'.
- cmake and autoconf include systems for computing a platform-specific
config.h file from aplatform-independent template that identifies a platform's basic facilities, word size, available APIs, etc. This is of value. I've described earlier in this thread how I want to use this, by generating a single copy of the platform-speciifc file per platform-specific build directory, where each build directory includes several distinct VMs (squeak vs pharo vs newspeak * context vs stack vs cog vs sista * v3 vs spur) and a single copy of support libraries such as Bochs, Cairo et al.
Naive questions about using a one-time generated config.h... Is this enough to support cross-compilation with cmake itself?
I don't know but I would have thought that's orthogonal to the issue/ Whatever cross compilation scheme is used one has to use the includes for the platform. So the config.h would be generated w.r.t. the target platform not the host. That's no different.
Where in the priorities is cross-compilation?
Well, I'd love to use more cross compilation; things would be much faster. But again it's additional work to get going. Anyone who gets cross compilation to any target running on Mac OS X please let me know; I'm interested.
Of minor concern (because I've no clue of the impact)... "Rumprun
unikernels are always cross-compiled. In practical terms, that statement means that the compiler will never run on a Rumprun unikernel. Instead, the compiler always runs on a build host (e.g. a regular Linux/BSD system)."
cheers -ben
_,,,^..^,,,_ best, Eliot
On Sat, Apr 23, 2016 at 10:44:02AM -0700, Eliot Miranda wrote:
On Apr 23, 2016, at 10:30 AM, Tobias Pape Das.Linux@gmx.de wrote:
PS: Personally (i.e. IMHO), I think that IF we go with cmake, we should follo Ians way with probably some mix of the self vm stuff. It can really work. And it can also help us getting things compiled on MS compilers, btw.
What do you mean by "Ian's way" exactly? Please describe it.
Things I know:
- Ian's autoconf code (platforms/unix/conf, the various additional snippets that get included when one builds the autoconf support, rather than things that get computed at build time) is extremely difficult to work with
- gmake files work with MS compilers too
My experience is different. I find it a bit obscure in the sense that it would benefit from some better documentation and comments in the cmake files.
Aside from that, Ian got the design dead right. Cmake handles the overall build. The VM build procedures are in a small number of files. Configurations that are specific to some part of the build tree are located with the source, and versioned with the source files to which they apply.
Looking back at the last seven years or so, I would say:
- The number of changes to the cmake procedures has been minimal. - Building a VM with Ian's procedure is still remarkably easy. - The total amount of code (cmake files) required to make this work is small. - In the few cases where I needed to change something, I have been able to figure out what to do. - Despite years of upgrades (sic) to my operating systems and compilers, it still works.
I have very little patience for fiddling around with build systems, and no patience whatsoever for autotools. But I have had no trouble using and occasionally modifying Ian's cmake build procedures.
Dave
David,
On Apr 23, 2016, at 3:13 PM, David T. Lewis lewis@mail.msen.com wrote:
On Sat, Apr 23, 2016 at 10:44:02AM -0700, Eliot Miranda wrote:
On Apr 23, 2016, at 10:30 AM, Tobias Pape Das.Linux@gmx.de wrote:
PS: Personally (i.e. IMHO), I think that IF we go with cmake, we should follo Ians way with probably some mix of the self vm stuff. It can really work. And it can also help us getting things compiled on MS compilers, btw.
What do you mean by "Ian's way" exactly? Please describe it.
Things I know:
- Ian's autoconf code (platforms/unix/conf, the various additional snippets that get included when one builds the autoconf support, rather than things that get computed at build time) is extremely difficult to work with
- gmake files work with MS compilers too
My experience is different. I find it a bit obscure in the sense that it would benefit from some better documentation and comments in the cmake files.
Aside from that, Ian got the design dead right. Cmake handles the overall build. The VM build procedures are in a small number of files. Configurations that are specific to some part of the build tree are located with the source, and versioned with the source files to which they apply.
And how is that significantly different from the gmake files? Gnu make ha goes the overall build, the VM build procedures are in a small number of files. Configurations that are specific to some part of the build tree are located with the source, and versioned with the source files to which they apply. None of this is specific to cmake.
What is specific to both cmake and autoconf is their being Makefile compilers, with all the difficulties that implies (learning a specialized language, waiting for compiles, interpreting compile-time and run-time errors and mapping them back to the source.
Looking back at the last seven years or so, I would say:
- The number of changes to the cmake procedures has been minimal.
- Building a VM with Ian's procedure is still remarkably easy.
- The total amount of code (cmake files) required to make this work is small.
- In the few cases where I needed to change something, I have been able to
figure out what to do.
- Despite years of upgrades (sic) to my operating systems and compilers,
it still works.
Looking back at the past 9 years I would say that Andreas' gnu makefiles for Windows never stopped working, were much easier to extend to Cog and Newspeak and the building of platform-specific Newspeak installers was straight-forward.
I have very little patience for fiddling around with build systems, and no patience whatsoever for autotools. But I have had no trouble using and occasionally modifying Ian's cmake build procedures.
Have you used the gnu makefiles? Have you extended them?
Dave
On Sat, Apr 23, 2016 at 05:10:37PM -0700, Eliot Miranda wrote:
David,
On Apr 23, 2016, at 3:13 PM, David T. Lewis lewis@mail.msen.com wrote:
On Sat, Apr 23, 2016 at 10:44:02AM -0700, Eliot Miranda wrote:
On Apr 23, 2016, at 10:30 AM, Tobias Pape Das.Linux@gmx.de wrote:
PS: Personally (i.e. IMHO), I think that IF we go with cmake, we should follo Ians way with probably some mix of the self vm stuff. It can really work. And it can also help us getting things compiled on MS compilers, btw.
What do you mean by "Ian's way" exactly? Please describe it.
Things I know:
- Ian's autoconf code (platforms/unix/conf, the various additional snippets that get included when one builds the autoconf support, rather than things that get computed at build time) is extremely difficult to work with
- gmake files work with MS compilers too
My experience is different. I find it a bit obscure in the sense that it would benefit from some better documentation and comments in the cmake files.
Aside from that, Ian got the design dead right. Cmake handles the overall build. The VM build procedures are in a small number of files. Configurations that are specific to some part of the build tree are located with the source, and versioned with the source files to which they apply.
And how is that significantly different from the gmake files? Gnu make ha goes the overall build, the VM build procedures are in a small number of files. Configurations that are specific to some part of the build tree are located with the source, and versioned with the source files to which they apply. None of this is specific to cmake.
What is specific to both cmake and autoconf is their being Makefile compilers, with all the difficulties that implies (learning a specialized language, waiting for compiles, interpreting compile-time and run-time errors and mapping them back to the source.
I don't know.
My point is that Ian's design is well considered, and works very well in my experience.
Looking back at the last seven years or so, I would say:
- The number of changes to the cmake procedures has been minimal.
- Building a VM with Ian's procedure is still remarkably easy.
- The total amount of code (cmake files) required to make this work is small.
- In the few cases where I needed to change something, I have been able to
figure out what to do.
- Despite years of upgrades (sic) to my operating systems and compilers,
it still works.
Looking back at the past 9 years I would say that Andreas' gnu makefiles for Windows never stopped working, were much easier to extend to Cog and Newspeak and the building of platform-specific Newspeak installers was straight-forward.
I have no problem believing that :-)
I have very little patience for fiddling around with build systems, and no patience whatsoever for autotools. But I have had no trouble using and occasionally modifying Ian's cmake build procedures.
Have you used the gnu makefiles? Have you extended them?
If you are referring to e.g. the acinclude.m4 and Makefile.inc files, then yes I have used and extended them.
Dave
Dave,
On Apr 23, 2016, at 7:56 PM, David T. Lewis lewis@mail.msen.com wrote:
On Sat, Apr 23, 2016 at 05:10:37PM -0700, Eliot Miranda wrote:
David,
On Apr 23, 2016, at 3:13 PM, David T. Lewis lewis@mail.msen.com wrote:
On Sat, Apr 23, 2016 at 10:44:02AM -0700, Eliot Miranda wrote:
On Apr 23, 2016, at 10:30 AM, Tobias Pape Das.Linux@gmx.de wrote:
PS: Personally (i.e. IMHO), I think that IF we go with cmake, we should follo Ians way with probably some mix of the self vm stuff. It can really work. And it can also help us getting things compiled on MS compilers, btw.
What do you mean by "Ian's way" exactly? Please describe it.
Things I know:
- Ian's autoconf code (platforms/unix/conf, the various additional snippets that get included when one builds the autoconf support, rather than things that get computed at build time) is extremely difficult to work with
- gmake files work with MS compilers too
My experience is different. I find it a bit obscure in the sense that it would benefit from some better documentation and comments in the cmake files.
Aside from that, Ian got the design dead right. Cmake handles the overall build. The VM build procedures are in a small number of files. Configurations that are specific to some part of the build tree are located with the source, and versioned with the source files to which they apply.
And how is that significantly different from the gmake files? Gnu make ha goes the overall build, the VM build procedures are in a small number of files. Configurations that are specific to some part of the build tree are located with the source, and versioned with the source files to which they apply. None of this is specific to cmake.
What is specific to both cmake and autoconf is their being Makefile compilers, with all the difficulties that implies (learning a specialized language, waiting for compiles, interpreting compile-time and run-time errors and mapping them back to the source.
I don't know.
My point is that Ian's design is well considered, and works very well in my experience.
Looking back at the last seven years or so, I would say:
- The number of changes to the cmake procedures has been minimal.
- Building a VM with Ian's procedure is still remarkably easy.
- The total amount of code (cmake files) required to make this work is small.
- In the few cases where I needed to change something, I have been able to
figure out what to do.
- Despite years of upgrades (sic) to my operating systems and compilers,
it still works.
Looking back at the past 9 years I would say that Andreas' gnu makefiles for Windows never stopped working, were much easier to extend to Cog and Newspeak and the building of platform-specific Newspeak installers was straight-forward.
I have no problem believing that :-)
I have very little patience for fiddling around with build systems, and no patience whatsoever for autotools. But I have had no trouble using and occasionally modifying Ian's cmake build procedures.
Have you used the gnu makefiles? Have you extended them?
If you are referring to e.g. the acinclude.m4 and Makefile.inc files, then yes I have used and extended them.
No, I'm referring to the gnu makefiles used to build win32 and Mac OS X cog. I posted their svn urls in my point by point comparison of them with cmake.
Dave
On Sat, Apr 23, 2016 at 08:08:04PM -0700, Eliot Miranda wrote:
Dave,
On Apr 23, 2016, at 7:56 PM, David T. Lewis lewis@mail.msen.com wrote:
On Sat, Apr 23, 2016 at 05:10:37PM -0700, Eliot Miranda wrote:
David,
On Apr 23, 2016, at 3:13 PM, David T. Lewis lewis@mail.msen.com wrote:
On Sat, Apr 23, 2016 at 10:44:02AM -0700, Eliot Miranda wrote:
On Apr 23, 2016, at 10:30 AM, Tobias Pape Das.Linux@gmx.de wrote:
PS: Personally (i.e. IMHO), I think that IF we go with cmake, we should follo Ians way with probably some mix of the self vm stuff. It can really work. And it can also help us getting things compiled on MS compilers, btw.
What do you mean by "Ian's way" exactly? Please describe it.
Things I know:
- Ian's autoconf code (platforms/unix/conf, the various additional snippets that get included when one builds the autoconf support, rather than things that get computed at build time) is extremely difficult to work with
- gmake files work with MS compilers too
My experience is different. I find it a bit obscure in the sense that it would benefit from some better documentation and comments in the cmake files.
Aside from that, Ian got the design dead right. Cmake handles the overall build. The VM build procedures are in a small number of files. Configurations that are specific to some part of the build tree are located with the source, and versioned with the source files to which they apply.
And how is that significantly different from the gmake files? Gnu make ha goes the overall build, the VM build procedures are in a small number of files. Configurations that are specific to some part of the build tree are located with the source, and versioned with the source files to which they apply. None of this is specific to cmake.
What is specific to both cmake and autoconf is their being Makefile compilers, with all the difficulties that implies (learning a specialized language, waiting for compiles, interpreting compile-time and run-time errors and mapping them back to the source.
I don't know.
My point is that Ian's design is well considered, and works very well in my experience.
Looking back at the last seven years or so, I would say:
- The number of changes to the cmake procedures has been minimal.
- Building a VM with Ian's procedure is still remarkably easy.
- The total amount of code (cmake files) required to make this work is small.
- In the few cases where I needed to change something, I have been able to
figure out what to do.
- Despite years of upgrades (sic) to my operating systems and compilers,
it still works.
Looking back at the past 9 years I would say that Andreas' gnu makefiles for Windows never stopped working, were much easier to extend to Cog and Newspeak and the building of platform-specific Newspeak installers was straight-forward.
I have no problem believing that :-)
I have very little patience for fiddling around with build systems, and no patience whatsoever for autotools. But I have had no trouble using and occasionally modifying Ian's cmake build procedures.
Have you used the gnu makefiles? Have you extended them?
If you are referring to e.g. the acinclude.m4 and Makefile.inc files, then yes I have used and extended them.
No, I'm referring to the gnu makefiles used to build win32 and Mac OS X cog. I posted their svn urls in my point by point comparison of them with cmake.
No, I have not used these, and I cannot comment one way or another.
Certainly an approach that works all platforms is a good thing, regardless of the build tools.
Dave

Hi all,
The CMakeVMakerSqueak is getting close enough that it is worth considering for going to Ian's design (its what I have in mind)
My time is very limited so I cannot get this done ASAP.
However, the design seems solid to me and there is no reason why the tool cannot be used to generate what Ian's approach.(Imho, it does this now)
I am currently focusing (at most, one day a week) on writing Help documentation as I create a configuration.
I am very willing to provide feedback via email (every day after my day job) for anybody who wants to get this done.
Steps remaining (excluding refactoring) are:
1. Document workflows. 2. Complete all configurations to generate what Eliot currently supports. 3. Decouple from the pharo CMakeVMMaker 4. Automate the creation of CMake Templates/Components by parsing CMake help output and creating Squeak CMake objects (the idea is similar to Seaside Components for CMake)
I think the design is loosely coupled and makes sense.
I too think Ian's CMake work is awesome. I currently use his approach for generating CMakeLists.txt output for the plugins.
The mantra for the project is "CMAKE drives the development decisions" .
thank you for your time.
tty
---- On Sat, 23 Apr 2016 23:08:04 -0400 Eliot Miranda<eliot.miranda@gmail.com> wrote ----
Dave,
> On Apr 23, 2016, at 7:56 PM, David T. Lewis <lewis@mail.msen.com> wrote: > > >> On Sat, Apr 23, 2016 at 05:10:37PM -0700, Eliot Miranda wrote: >> >> David, >> >>> On Apr 23, 2016, at 3:13 PM, David T. Lewis <lewis@mail.msen.com> wrote: >>> >>> >>>>> On Sat, Apr 23, 2016 at 10:44:02AM -0700, Eliot Miranda wrote: >>>>> >>>>> On Apr 23, 2016, at 10:30 AM, Tobias Pape <Das.Linux@gmx.de> wrote: >>>>> >>>>> PS: Personally (i.e. IMHO), I think that IF we go with cmake, we should follo Ians way with >>>>> probably some mix of the self vm stuff. It can really work. And it can also help us >>>>> getting things compiled on MS compilers, btw. >>>> >>>> What do you mean by "Ian's way" exactly? Please describe it. >>>> >>>> Things I know: >>>> - Ian's autoconf code (platforms/unix/conf, the various additional snippets that get included when one builds the autoconf support, rather than things that get computed at build time) is extremely difficult to work with >>>> - gmake files work with MS compilers too >>> >>> My experience is different. I find it a bit obscure in the sense that it >>> would benefit from some better documentation and comments in the cmake files. >>> >>> Aside from that, Ian got the design dead right. Cmake handles the overall >>> build. The VM build procedures are in a small number of files. Configurations >>> that are specific to some part of the build tree are located with the source, >>> and versioned with the source files to which they apply. >> >> And how is that significantly different from the gmake files? Gnu make ha goes the overall build, the VM build procedures are in a small number of files. Configurations that are specific to some part of the build tree are located with the source, and versioned with the source files to which they apply. None of this is specific to cmake. >> >> What is specific to both cmake and autoconf is their being Makefile compilers, with all the difficulties that implies (learning a specialized language, waiting for compiles, interpreting compile-time and run-time errors and mapping them back to the source. > > I don't know. > > My point is that Ian's design is well considered, and works very well in my experience. > > >>> Looking back at the last seven years or so, I would say: >>> >>> - The number of changes to the cmake procedures has been minimal. >>> - Building a VM with Ian's procedure is still remarkably easy. >>> - The total amount of code (cmake files) required to make this work is small. >>> - In the few cases where I needed to change something, I have been able to >>> figure out what to do. >>> - Despite years of upgrades (sic) to my operating systems and compilers, >>> it still works. >> >> Looking back at the past 9 years I would say that Andreas' gnu makefiles for Windows never stopped working, were much easier to extend to Cog and Newspeak and the building of platform-specific Newspeak installers was straight-forward. > > I have no problem believing that :-) > >>> >>> I have very little patience for fiddling around with build systems, and >>> no patience whatsoever for autotools. But I have had no trouble using >>> and occasionally modifying Ian's cmake build procedures. >> >> Have you used the gnu makefiles? Have you extended them? > > If you are referring to e.g. the acinclude.m4 and Makefile.inc files, then > yes I have used and extended them.
No, I'm referring to the gnu makefiles used to build win32 and Mac OS X cog. I posted their svn urls in my point by point comparison of them with cmake.
> Dave
H Tobias,
On Apr 23, 2016, at 10:30 AM, Tobias Pape Das.Linux@gmx.de wrote:
On 23.04.2016, at 19:21, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Fabio,
and the "if not, why not?" question is a request for information, not an expression of annoyance. Subversion tags update the source in checkin. I remember Igor saying that he couldn't find out how to make gig do the same with version numbers (forgive me if my recollection is incorrect). But if git doesn't support this then we need to invent some scheme that does work, for example doing two commits, one to generate a hash and another to commit a tag. But we need sensible increment isn't version numbers, not stupid hashes. It has to be a requirement that one can tell from the output of myvm -version yourvm -version whether the VMs are built from the same or different versions of the source and which one is more up-to-date, and that this depends on version number, not irrelevancies such as build date.
I did such stuff like 4 years ago for self (don't ask why) I changed their whole VM build process to CMake.
Here's some parts that vaguely do what you want want:
This uses "date" to generate a vm build date (lines 12 and following) and "git" to extract VCS infos (lines 39 and following) https://github.com/russellallen/self/blob/master/vm/cmake/configureVmDate.cm... (it is namend .in because it gets configured itself from elsewhere)
Do you have energy to write a prototype that works with a modified platforms/Cross/vm/sqSCCSVersion.h?
Pointing me at code I have to go read, install cmake on Mac OS X etc, is asking me to spend time I don't have doing stuff I don't see much benefit in. Subversion already "does the right thing". If it were my decision I'd use subversion to checkin versioned builds via the subversion to git bridge. IIABDFI
It is clearly possible to switch all the stuff to git and cmake and I'd like to see that happen. I would love to have time for that (although it regularly makes me angry :D).
Best regards -Tobias
PS: Personally (i.e. IMHO), I think that IF we go with cmake, we should follo Ians way with probably some mix of the self vm stuff. It can really work. And it can also help us getting things compiled on MS compilers, btw.
_,,,^..^,,,_ (phone)
On Apr 23, 2016, at 9:54 AM, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Fabio,
On Apr 23, 2016, at 9:40 AM, Fabio Niephaus lists@fniephaus.com wrote:
Hi all,
Bert already mentioned that I've been working on migrating the repository from SVN to Git. I believe there are three problems that need to be solved here:
- Migrating SVN externals for sharing code between branches
This is currently used to share a few directories (e.g. platforms/Cross/plugins) across different branches. But Git does no support this kind of code sharing. Instead, it supports submodules [1] and subtrees [2]. I would suggest to move code that we want to share into separate Git repositories and include them as submodules. I think submodules are easier to understand (GitHub integrates them nicely in their UI). The only drawback: if someone updates code in a shared repository, one needs to update all references to this repository as well. But I'd say this is also a good thing: if someone changes e.g. a plugin and the change is compatible to Cog, but incompatible to the interpreter vm, then the interpreter branch is not automatically broken as soon as one pushes the plugin change. If the above is unclear, I'm happy to explain submodules in more detail.
- Versioning and new releases
If we migrate to Git, I'd recommend to deprecate the way we do versioning in SVN. Instead, we should use Git commit hashes and Git tags.
But have you modified platforms/Cross/vm/sqSCCSVersion.h to capture this information? If so, can you please send me the code so I can integrate it? If not, why not?
Let's say we want to release a new version, we tag the commit of interest with e.g. v1.0.0. When building the Cog VM on this tag, the version will be v1.0.0. If we use GitHub, we might as well use a CI service such as Travis CI [3] to automate the build process. That means, each time someone pushes changes to GitHub, Travis CI will build a new Cog VM (we can call this "bleeding edge"). Let's say I push changes right after the release of v1.0.0, the version for the next build will be something like v1.0.0-37553a9 with "37553a9" being the short SHA1 identifying my latest commit. If we want to release e.g. v1.1.0, we just tag a newer commit and GitHub/Travis CI does the rest for us. I already have this working, you can find a Travis build at [4] and the result at [5]. Obviously, we can push the binaries to a different server.
- Keeping a copy of the code
We of course want to keep a copy of our code at all times in case something happens with GitHub. There are already tools that we can use to automate this. However, I wouldn't try to keep the old SVN repository in sync. I believe this might be quite difficult and I don't see a reason to maintain something we want to deprecate in the first place. Anyway, it should be fairly easy to set up a tool that creates a backup on one of our servers whenever we change code on GitHub.
Doing a migration from SVN to Git(Hub) takes a few hours and I'd recommend we stop pushing code to the SVN as soon as we start to migrate. This obviously requires everyone working with the code base to switch to Git. So please let me know if everyone is comfortable with the migration. If we want to do this next week, I'd recommend to do it on a Thursday or a Friday, because I would be able to do it with Bert sitting two rooms next to me :)
I'm not happy to migrate until there's a functional subversion bridge that works and doesn't break my builds. Cadence pays for my time (and hence pays for a lot of the VM development we enjoy) and its builds use Jenkins and subversion and I will not cooperate with any effort that sabotages this. "Next Thursday" doesn't appear to appreciate the constraints. This has to be done carefully or I will not cooperate.
I hope I have thought about the important things and I'm happy to answer any questions you might have.
Best, Fabio
[1] https://git-scm.com/book/en/v2/Git-Tools-Submodules [2] http://blogs.atlassian.com/2013/05/alternatives-to-git-submodule-git-subtree... [3] http://travis-ci.org [4] https://travis-ci.org/fniephaus/squeak/builds/119507180 [5] https://www.hpi.uni-potsdam.de/hirschfeld/artefacts/cog/v0.1.0/
--
On Sat, Apr 23, 2016 at 5:10 PM David T. Lewis lewis@mail.msen.com wrote:
On Sat, Apr 23, 2016 at 02:22:29PM +0200, Nicolas Cellier wrote:
2016-04-23 13:56 GMT+02:00 Cl??ment Bera bera.clement@gmail.com:
On Sat, Apr 23, 2016 at 12:54 PM, Bert Freudenberg bert@freudenbergs.de wrote:
> > Actually, Fabio did a complete migration while squeakvm.org was out. > This had a full history of all SVN commits. > > ???Unfortunately??? Ian fixed the server too soon so development continued on > SVN, so now the git repo is again out-of-date. > > We would need to freeze the SVN, do the migration again, and use git from > that point on. It would involve a day of downtime, but doing this sooner > than later would be a good thing.
doesn't gitsvn help?
I have to admit that I did not even know that an active git svn bridge was possible. It sounds like this it might be very helpful.
It would be great to have the advantages of git for development, and it could also be helpful to be able to have the squeakvm.org repo updated periodically from git. There are portions of the platforms tree that Eliot has been able to make identical for oscog and trunk, and this seems like a worthwhile effort to continue.
Another possible advantage is that Ian's cmake build process takes advantage of the SVN revision numbering, and it would be good to make sure this stays healthy as development proceeds (it's a lot nicer than autotools).
Eliot, do you have a view on this?
Dave
_,,,^..^,,,_ (phone)
On 23.04.2016, at 19:49, Eliot Miranda eliot.miranda@gmail.com wrote:
H Tobias,
On Apr 23, 2016, at 10:30 AM, Tobias Pape Das.Linux@gmx.de wrote:
On 23.04.2016, at 19:21, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Fabio,
and the "if not, why not?" question is a request for information, not an expression of annoyance. Subversion tags update the source in checkin. I remember Igor saying that he couldn't find out how to make gig do the same with version numbers (forgive me if my recollection is incorrect). But if git doesn't support this then we need to invent some scheme that does work, for example doing two commits, one to generate a hash and another to commit a tag. But we need sensible increment isn't version numbers, not stupid hashes. It has to be a requirement that one can tell from the output of myvm -version yourvm -version whether the VMs are built from the same or different versions of the source and which one is more up-to-date, and that this depends on version number, not irrelevancies such as build date.
I did such stuff like 4 years ago for self (don't ask why) I changed their whole VM build process to CMake.
Here's some parts that vaguely do what you want want:
This uses "date" to generate a vm build date (lines 12 and following) and "git" to extract VCS infos (lines 39 and following) https://github.com/russellallen/self/blob/master/vm/cmake/configureVmDate.cm... (it is namend .in because it gets configured itself from elsewhere)
Do you have energy to write a prototype that works with a modified platforms/Cross/vm/sqSCCSVersion.h?
Pointing me at code I have to go read, install cmake on Mac OS X etc, is asking me to spend time I don't have doing stuff I don't see much benefit in. Subversion already "does the right thing". If it were my decision I'd use subversion to checkin versioned builds via the subversion to git bridge.
Ah now i get it. Also, my comment was more comment-y for the whole audience than an call for action to you, sorry I didn't make that clear. And to be clear, If the version string is the only thing cmake would be used for, well, then there are a lot of different opinions, too.
What I _wanted_ to say is: In case we switched to cmake, I already have seen a way to do that.
Best -Tobias
IIABDFI
?
It is clearly possible to switch all the stuff to git and cmake and I'd like to see that happen. I would love to have time for that (although it regularly makes me angry :D).
Best regards -Tobias
PS: Personally (i.e. IMHO), I think that IF we go with cmake, we should follo Ians way with probably some mix of the self vm stuff. It can really work. And it can also help us getting things compiled on MS compilers, btw.
_,,,^..^,,,_ (phone)
On Apr 23, 2016, at 9:54 AM, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Fabio,
On Apr 23, 2016, at 9:40 AM, Fabio Niephaus lists@fniephaus.com wrote:
Hi all,
Bert already mentioned that I've been working on migrating the repository from SVN to Git. I believe there are three problems that need to be solved here:
- Migrating SVN externals for sharing code between branches
This is currently used to share a few directories (e.g. platforms/Cross/plugins) across different branches. But Git does no support this kind of code sharing. Instead, it supports submodules [1] and subtrees [2]. I would suggest to move code that we want to share into separate Git repositories and include them as submodules. I think submodules are easier to understand (GitHub integrates them nicely in their UI). The only drawback: if someone updates code in a shared repository, one needs to update all references to this repository as well. But I'd say this is also a good thing: if someone changes e.g. a plugin and the change is compatible to Cog, but incompatible to the interpreter vm, then the interpreter branch is not automatically broken as soon as one pushes the plugin change. If the above is unclear, I'm happy to explain submodules in more detail.
- Versioning and new releases
If we migrate to Git, I'd recommend to deprecate the way we do versioning in SVN. Instead, we should use Git commit hashes and Git tags.
But have you modified platforms/Cross/vm/sqSCCSVersion.h to capture this information? If so, can you please send me the code so I can integrate it? If not, why not?
Let's say we want to release a new version, we tag the commit of interest with e.g. v1.0.0. When building the Cog VM on this tag, the version will be v1.0.0. If we use GitHub, we might as well use a CI service such as Travis CI [3] to automate the build process. That means, each time someone pushes changes to GitHub, Travis CI will build a new Cog VM (we can call this "bleeding edge"). Let's say I push changes right after the release of v1.0.0, the version for the next build will be something like v1.0.0-37553a9 with "37553a9" being the short SHA1 identifying my latest commit. If we want to release e.g. v1.1.0, we just tag a newer commit and GitHub/Travis CI does the rest for us. I already have this working, you can find a Travis build at [4] and the result at [5]. Obviously, we can push the binaries to a different server.
- Keeping a copy of the code
We of course want to keep a copy of our code at all times in case something happens with GitHub. There are already tools that we can use to automate this. However, I wouldn't try to keep the old SVN repository in sync. I believe this might be quite difficult and I don't see a reason to maintain something we want to deprecate in the first place. Anyway, it should be fairly easy to set up a tool that creates a backup on one of our servers whenever we change code on GitHub.
Doing a migration from SVN to Git(Hub) takes a few hours and I'd recommend we stop pushing code to the SVN as soon as we start to migrate. This obviously requires everyone working with the code base to switch to Git. So please let me know if everyone is comfortable with the migration. If we want to do this next week, I'd recommend to do it on a Thursday or a Friday, because I would be able to do it with Bert sitting two rooms next to me :)
I'm not happy to migrate until there's a functional subversion bridge that works and doesn't break my builds. Cadence pays for my time (and hence pays for a lot of the VM development we enjoy) and its builds use Jenkins and subversion and I will not cooperate with any effort that sabotages this. "Next Thursday" doesn't appear to appreciate the constraints. This has to be done carefully or I will not cooperate.
I hope I have thought about the important things and I'm happy to answer any questions you might have.
Best, Fabio
[1] https://git-scm.com/book/en/v2/Git-Tools-Submodules [2] http://blogs.atlassian.com/2013/05/alternatives-to-git-submodule-git-subtree... [3] http://travis-ci.org [4] https://travis-ci.org/fniephaus/squeak/builds/119507180 [5] https://www.hpi.uni-potsdam.de/hirschfeld/artefacts/cog/v0.1.0/
--
On Sat, Apr 23, 2016 at 5:10 PM David T. Lewis lewis@mail.msen.com wrote:
On Sat, Apr 23, 2016 at 02:22:29PM +0200, Nicolas Cellier wrote:
I have to admit that I did not even know that an active git svn bridge was possible. It sounds like this it might be very helpful.
It would be great to have the advantages of git for development, and it could also be helpful to be able to have the squeakvm.org repo updated periodically from git. There are portions of the platforms tree that Eliot has been able to make identical for oscog and trunk, and this seems like a worthwhile effort to continue.
Another possible advantage is that Ian's cmake build process takes advantage of the SVN revision numbering, and it would be good to make sure this stays healthy as development proceeds (it's a lot nicer than autotools).
Eliot, do you have a view on this?
Dave
_,,,^..^,,,_ (phone)
On Apr 23, 2016, at 10:58 AM, Tobias Pape Das.Linux@gmx.de wrote:
...
IIABDFI
?
If It Ain't Broke, Don't Fix It.
On 23.04.2016, at 20:01, Eliot Miranda eliot.miranda@gmail.com wrote:
On Apr 23, 2016, at 10:58 AM, Tobias Pape Das.Linux@gmx.de wrote:
...
IIABDFI
?
If It Ain't Broke, Don't Fix It.
Yes, and I for one hold that it is broken[1] ;)
Best regards and happy weekend -Tobias
[1]: Make for squeak-vm, that is.
Hi All,
one very important question is what are the names of the top level git repository and sub modules? Before you suggest something please check that the name isn't already used on github.
Here are some suggestions
http://cogvm.github.io/.com http://backtothefuture.github.io/.com https://opensmalltalkvm.github.io/com
_,,,^..^,,,_ (phone)
On Apr 23, 2016, at 10:01 AM, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi All,
one very important question is what are the names of the top level git repository and sub modules? Before you suggest something please check that the name isn't already used on github.
Here are some suggestions
http://cogvm.github.io/.com http://backtothefuture.github.io/.com https://opensmalltalkvm.github.io/com
Or github.com/ cogvm backtothefuture opensmalltalkvm of course
_,,,^..^,,,_ (phone)
On Sun, Apr 24, 2016 at 1:03 AM, Eliot Miranda eliot.miranda@gmail.com wrote:
On Apr 23, 2016, at 10:01 AM, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi All,
one very important question is what are the names of the top level git repository and sub modules? Before you suggest something please check that the name isn't already used on github.
Here are some suggestions
http://cogvm.github.io/.com http://backtothefuture.github.io/.com https://opensmalltalkvm.github.io/com
Or github.com/ cogvm backtothefuture opensmalltalkvm of course
Technically...
Previous discussion on moving to git raised the concern about being tied too tightly to a particular third party infrastructure. To guard against this, in case moving on from github to another git service is required in the future, consider using a custom second-level domain per [1] rather than the default third-level one under github.io. So...
cog.com|.net|.org|.io and cogvm.com|.net are all taken[2]. cogvm.org|.io are both available. "io" is where all the trendy kids hang out these days" However I believe its better to avoid competing against another holder of the primary .com.
backtothefuture.com|.net|.org are all taken [2] backtothefuture.io is available.
opensmalltalkvm.com|.net|.org|.io are all available. I believe its best to grab the lot, or at least .com redirected to the one you use, to avoid anyone swooping in later to repurpose the primary domain.
Philosphically...
IIUC the repository is more than just cog, containing also the classic interpeter. So cogvm seems a bit narrow in scope.
backtothefuture initially struck me as too loaded with insider meaning, but its since grown on me as a sense of innovation plus history, and an invitation to the broader programming community perhaps dissatisfied with their status quo. However branding wise you it competes against the popular movie with backtothefuture having 541 Mgoogs**. So the project could end hidden in the noise. Maybe consider bttfvm(160 googs), btfvm(2000 googs).
OpenSmalltalkVM reminds me of the tagline 'Eliot Miranda to deliver the keynote presentation "Cog - The Open Source Smalltalk VM" ' that caught my eye recently [3]. This resonated with me as being very inclusive and marketable in broadening Cog's user base to attract outside interest.
Wouldn't it be good to have it under: https://github.com/squeak-smalltalk/ ?
The VM today is used also by Newspeak and Pharo. We all do mostly our own thing at the Image level, but we share the VM. It would be nice to have a more generic project name to encompass this.
Also Eliot and Clement are doing invovative VM design that could appeal to a broader community as mentioned by Chris[4]. A VM less tied to a specific program run on it might facilitate outsider participation (i.e. $$) directly in the VM rather than just taking the new ideas elsewhere.
And completely wild speculation... imagine Dolphin went open source for lack of a 64 bit VM and it was easiest for them to move their Image over to adopt Cog as their VM. Picking up even one more user of the VM could be worth rebranding. Maybe this is not likely, but its less likely with the VM branded for particular Image not their own.
cheers -ben
** goog - measure of world uniqueness per google search results. [1] https://help.github.com/articles/using-a-custom-domain-with-github-pages/ [2] https://www.namecheap.com/domains/whois.aspx [3] http://www.ooplu.com [4] http://forum.world.st/Simulator-tutorial-tp4888841p4888883.html

On 23 April 2016 at 10:01, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi All,
one very important question is what are the names of the top level gitrepository and sub modules? Before you suggest something please check that the name isn't already used on github.
Here are some suggestions
http://cogvm.github.io/.com http://backtothefuture.github.io/.com https://opensmalltalkvm.github.io/com
_,,,^..^,,,_ (phone)
FWIW I'd go with "cogvm". Short, sweet, to the point.
frank
Wouldn't it be good to have it under: https://github.com/squeak-smalltalk/ ?
Why do you want to set up another GitHub organization for one or two repositories?
I'd go with: https://github.com/squeak-smalltalk/cogvm and for the original Squeak VM: https://github.com/squeak-smalltalk/squeakvm
Best, Fabio

There is also already: https://github.com/squeakvm
On 26 Apr 2016, at 00:12, Fabio Niephaus lists@fniephaus.com wrote:
Wouldn't it be good to have it under: https://github.com/squeak-smalltalk/ ?
Why do you want to set up another GitHub organization for one or two repositories?
I'd go with: https://github.com/squeak-smalltalk/cogvm and for the original Squeak VM: https://github.com/squeak-smalltalk/squeakvm
Best, Fabio
--
On Mon, Apr 25, 2016 at 11:57 PM Frank Shearar frank.shearar@gmail.com wrote: On 23 April 2016 at 10:01, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi All,
one very important question is what are the names of the top level git repository and sub modules? Before you suggest something please check that the name isn't already used on github.Here are some suggestions
http://cogvm.github.io/.com http://backtothefuture.github.io/.com https://opensmalltalkvm.github.io/com
_,,,^..^,,,_ (phone)
FWIW I'd go with "cogvm". Short, sweet, to the point.
frank
On 26 Apr 2016, at 00:12, Fabio Niephaus lists@fniephaus.com wrote:
Wouldn't it be good to have it under: https://github.com/squeak-smalltalk/ https://github.com/squeak-smalltalk/ ?
Why do you want to set up another GitHub organization for one or two repositories?
because the VM exceeds squeak? … and because then we can have more than one project, and keep them well organised.
Esteban
I'd go with: https://github.com/squeak-smalltalk/cogvm https://github.com/squeak-smalltalk/cogvm and for the original Squeak VM: https://github.com/squeak-smalltalk/squeakvm https://github.com/squeak-smalltalk/squeakvm
Best, Fabio
--
On Mon, Apr 25, 2016 at 11:57 PM Frank Shearar <frank.shearar@gmail.com mailto:frank.shearar@gmail.com> wrote: On 23 April 2016 at 10:01, Eliot Miranda <eliot.miranda@gmail.com mailto:eliot.miranda@gmail.com> wrote:
Hi All,
one very important question is what are the names of the top level git repository and sub modules? Before you suggest something please check that the name isn't already used on github.Here are some suggestions
http://cogvm.github.io/.com http://cogvm.github.io/.com http://backtothefuture.github.io/.com http://backtothefuture.github.io/.com https://opensmalltalkvm.github.io/com https://opensmalltalkvm.github.io/com
_,,,^..^,,,_ (phone)
FWIW I'd go with "cogvm". Short, sweet, to the point.
frank
On 25 Apr 2016, at 23:57, Frank Shearar frank.shearar@gmail.com wrote:
On 23 April 2016 at 10:01, Eliot Miranda <eliot.miranda@gmail.com mailto:eliot.miranda@gmail.com> wrote:
Hi All,
one very important question is what are the names of the top level git repository and sub modules? Before you suggest something please check that the name isn't already used on github.Here are some suggestions
http://cogvm.github.io/.com http://cogvm.github.io/.com http://backtothefuture.github.io/.com http://backtothefuture.github.io/.com https://opensmalltalkvm.github.io/com https://opensmalltalkvm.github.io/com
_,,,^..^,,,_ (phone)
FWIW I'd go with "cogvm". Short, sweet, to the point.
+1
frank
On 26.04.2016, at 07:52, Esteban Lorenzano estebanlm@gmail.com wrote:
On 25 Apr 2016, at 23:57, Frank Shearar frank.shearar@gmail.com wrote:
On 23 April 2016 at 10:01, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi All,
one very important question is what are the names of the top level git repository and sub modules? Before you suggest something please check that the name isn't already used on github.Here are some suggestions
http://cogvm.github.io/.com http://backtothefuture.github.io/.com https://opensmalltalkvm.github.io/com
_,,,^..^,,,_ (phone)
FWIW I'd go with "cogvm". Short, sweet, to the point.
+1
That would imply to ditch the interpreter vm altogether. so -0 from me…
Best -Tobias
frank
Hi Tobias,
On Mon, May 2, 2016 at 7:10 AM, Tobias Pape Das.Linux@gmx.de wrote:
On 26.04.2016, at 07:52, Esteban Lorenzano estebanlm@gmail.com wrote:
On 25 Apr 2016, at 23:57, Frank Shearar frank.shearar@gmail.com
wrote:
On 23 April 2016 at 10:01, Eliot Miranda eliot.miranda@gmail.com
wrote:
Hi All,
one very important question is what are the names of the top levelgit repository and sub modules? Before you suggest something please check that the name isn't already used on github.
Here are some suggestions
http://cogvm.github.io/.com http://backtothefuture.github.io/.com https://opensmalltalkvm.github.io/com
_,,,^..^,,,_ (phone)
FWIW I'd go with "cogvm". Short, sweet, to the point.
+1
That would imply to ditch the interpreter vm altogether. so -0 from me…
That's not the intention. What we need is some effort to integrate the ContextInterpreter back into VMMaker.oscog. David doesn't have the time. The Interpreter in VMMaker.oscog is both ahead and behind the VMMaker Interpreter. The VMMaker.oscog one has Andreas' profiler improvements, but it hasn't been refactored to not inherit from ObjectMemory and and fixes that have been applied to VMMaker's Interpreter could do with being integrated. But it's not a hinge join, just not one I or David have time for. Is there anyone out there with curiosity for the VM who does have some time?
Tobias, any students you can point at the task? It's a refactoring job and I'll hand hold.
Best -Tobias
frank
Hi Eliot,
On 02.05.2016, at 20:54, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Tobias,
On Mon, May 2, 2016 at 7:10 AM, Tobias Pape Das.Linux@gmx.de wrote:
On 26.04.2016, at 07:52, Esteban Lorenzano estebanlm@gmail.com wrote:
On 25 Apr 2016, at 23:57, Frank Shearar frank.shearar@gmail.com wrote:
On 23 April 2016 at 10:01, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi All,
one very important question is what are the names of the top level git repository and sub modules? Before you suggest something please check that the name isn't already used on github.Here are some suggestions
http://cogvm.github.io/.com http://backtothefuture.github.io/.com https://opensmalltalkvm.github.io/com
_,,,^..^,,,_ (phone)
FWIW I'd go with "cogvm". Short, sweet, to the point.
+1
That would imply to ditch the interpreter vm altogether. so -0 from me…
That's not the intention.
I thought so. My statement might have been a bit succinct. I'd should have written "This name would sound as if it implied that we ditched..."
What we need is some effort to integrate the ContextInterpreter back into VMMaker.oscog. David doesn't have the time. The Interpreter in VMMaker.oscog is both ahead and behind the VMMaker Interpreter.
I thought so.
The VMMaker.oscog one has Andreas' profiler improvements, but it hasn't been refactored to not inherit from ObjectMemory and and fixes that have been applied to VMMaker's Interpreter could do with being integrated. But it's not a hinge join, just not one I or David have time for. Is there anyone out there with curiosity for the VM who does have some time?
Tobias, any students you can point at the task? It's a refactoring job and I'll hand hold.
I understand that this is important yet tedious work. I could ask around, but I won't promise anything.
Yes, I know that the branches should converge again. But how does that solve the naming issue? Would the (Context)Interpreter become another flavor of CogVM?
Best regards -Tobias
Hi Tobias,
On May 2, 2016, at 12:12 PM, Tobias Pape Das.Linux@gmx.de wrote:
Hi Eliot,
On 02.05.2016, at 20:54, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Tobias,
On Mon, May 2, 2016 at 7:10 AM, Tobias Pape Das.Linux@gmx.de wrote:
On 26.04.2016, at 07:52, Esteban Lorenzano estebanlm@gmail.com wrote:
On 25 Apr 2016, at 23:57, Frank Shearar frank.shearar@gmail.com wrote:
On 23 April 2016 at 10:01, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi All,
one very important question is what are the names of the top level git repository and sub modules? Before you suggest something please check that the name isn't already used on github.
Here are some suggestions
http://cogvm.github.io/.com http://backtothefuture.github.io/.com https://opensmalltalkvm.github.io/com
_,,,^..^,,,_ (phone)
FWIW I'd go with "cogvm". Short, sweet, to the point.
+1
That would imply to ditch the interpreter vm altogether. so -0 from me…
That's not the intention.
I thought so. My statement might have been a bit succinct. I'd should have written "This name would sound as if it implied that we ditched..."
What we need is some effort to integrate the ContextInterpreter back into VMMaker.oscog. David doesn't have the time. The Interpreter in VMMaker.oscog is both ahead and behind the VMMaker Interpreter.
I thought so.
The VMMaker.oscog one has Andreas' profiler improvements, but it hasn't been refactored to not inherit from ObjectMemory and and fixes that have been applied to VMMaker's Interpreter could do with being integrated. But it's not a hinge join, just not one I or David have time for. Is there anyone out there with curiosity for the VM who does have some time?
Tobias, any students you can point at the task? It's a refactoring job and I'll hand hold.
I understand that this is important yet tedious work. I could ask around, but I won't promise anything.
Yes, I know that the branches should converge again. But how does that solve the naming issue? Would the (Context)Interpreter become another flavor of CogVM?
Yes. Since it would be able to use Spur that wouldn't be theft, more an exchange :-)
Best regards -Tobias
On Mon, May 02, 2016 at 04:27:11PM -0700, Eliot Miranda wrote:
Hi Tobias,
On May 2, 2016, at 12:12 PM, Tobias Pape Das.Linux@gmx.de wrote:
Hi Eliot,
On 02.05.2016, at 20:54, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Tobias,
On Mon, May 2, 2016 at 7:10 AM, Tobias Pape Das.Linux@gmx.de wrote:
On 26.04.2016, at 07:52, Esteban Lorenzano estebanlm@gmail.com wrote:
On 25 Apr 2016, at 23:57, Frank Shearar frank.shearar@gmail.com wrote:
On 23 April 2016 at 10:01, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi All,
one very important question is what are the names of the top level git repository and sub modules? Before you suggest something please check that the name isn't already used on github.
Here are some suggestions
http://cogvm.github.io/.com http://backtothefuture.github.io/.com https://opensmalltalkvm.github.io/com
_,,,^..^,,,_ (phone)
FWIW I'd go with "cogvm". Short, sweet, to the point.
+1
That would imply to ditch the interpreter vm altogether. so -0 from me???
That's not the intention.
I thought so. My statement might have been a bit succinct. I'd should have written "This name would sound as if it implied that we ditched..."
What we need is some effort to integrate the ContextInterpreter back into VMMaker.oscog. David doesn't have the time. The Interpreter in VMMaker.oscog is both ahead and behind the VMMaker Interpreter.
I thought so.
The VMMaker.oscog one has Andreas' profiler improvements, but it hasn't been refactored to not inherit from ObjectMemory and and fixes that have been applied to VMMaker's Interpreter could do with being integrated. But it's not a hinge join, just not one I or David have time for. Is there anyone out there with curiosity for the VM who does have some time?
Tobias, any students you can point at the task? It's a refactoring job and I'll hand hold.
I understand that this is important yet tedious work. I could ask around, but I won't promise anything.
Yes, I know that the branches should converge again. But how does that solve the naming issue? Would the (Context)Interpreter become another flavor of CogVM?
Yes. Since it would be able to use Spur that wouldn't be theft, more an exchange :-)
Regarding naming, I think that Eliot's distintion between the traditional "context interpreter" and the "stack interpreter" makes perfect sense. Thus the traditional interpreter VM is ContextInterpreter, and the stack interpreter (upon which the Cog and Spur work is based), is StackInterpreter. Both of these subclass from Interpreter.
For the object memory, the corresponding classes are ClassicObjectMemory and NewObjectMemory, both of which inherit from ObjectMemory.
The traditional "interpreter VM" is now built from ContextInterpreter and ClassicObjectMemory from the VMMaker trunk repository. A stack interpreter built from that repository will generate its code from StackInterpreter and NewObjectMemory. This configuration does not yet work in the VMMaker trunk branch. I think that it is close to working, but I have been saying that for several years now, so don't trust me on this.
My hope is to get to the point where a working stack interpreter can be built from StackInterpreter and NewObjectMemory in VMMaker trunk. If and when that works, we would have a known good code base from which the trunk changes could be back-ported to ("exchanged with"?) the oscog repository for Cog and Spur.
Dave
Hi all, On 03.05.2016, at 03:16, David T. Lewis lewis@mail.msen.com wrote:
On Mon, May 02, 2016 at 04:27:11PM -0700, Eliot Miranda wrote:
[…]
Yes, I know that the branches should converge again. But how does that solve the naming issue? Would the (Context)Interpreter become another flavor of CogVM?
Yes. Since it would be able to use Spur that wouldn't be theft, more an exchange :-)
[ Snip things I also agree with ]
My hope is to get to the point where a working stack interpreter can be built from StackInterpreter and NewObjectMemory in VMMaker trunk. If and when that works, we would have a known good code base from which the trunk changes could be back-ported to ("exchanged with"?) the oscog repository for Cog and Spur.
I completely agree with that structure.
So my concerns about naming were about the Github repo, or better, organization.
I thought a bit and, hey, why not call it VMMaker, after all, its the thing that makes VMs and that name already does things.
Here's my idea:
/VMMaker/ -- Organization (still availabe) /VMMaker/platform/ -- What now is http://www.squeakvm.org/svn/squeak/trunk/platform or http://www.squeakvm.org/svn/squeak/branches/Cog/platforms/ /VMMaker/tools/ -- helping things, such as mkNamedPrims.sh /VMMaker/Cog/ -- Well, what's necessary to build a Cog VM
And later maybe
/VMMaker/VMMaker/ -- The Smalltalk source as filetree
And maybe even SqueakJS, but that's up to Bert :D
What do you think?
Best regards -Tobias
Hi David, Hi All,
On Apr 23, 2016, at 8:10 AM, David T. Lewis lewis@mail.msen.com wrote:
On Sat, Apr 23, 2016 at 02:22:29PM +0200, Nicolas Cellier wrote:
2016-04-23 13:56 GMT+02:00 Cl??ment Bera bera.clement@gmail.com:
On Sat, Apr 23, 2016 at 12:54 PM, Bert Freudenberg bert@freudenbergs.de wrote:
Actually, Fabio did a complete migration while squeakvm.org was out. This had a full history of all SVN commits.
???Unfortunately??? Ian fixed the server too soon so development continued on SVN, so now the git repo is again out-of-date.
We would need to freeze the SVN, do the migration again, and use git from that point on. It would involve a day of downtime, but doing this sooner than later would be a good thing.
doesn't gitsvn help?
I have to admit that I did not even know that an active git svn bridge was possible. It sounds like this it might be very helpful.
It would be great to have the advantages of git for development, and it could also be helpful to be able to have the squeakvm.org repo updated periodically from git. There are portions of the platforms tree that Eliot has been able to make identical for oscog and trunk, and this seems like a worthwhile effort to continue.
Another possible advantage is that Ian's cmake build process takes advantage of the SVN revision numbering, and it would be good to make sure this stays healthy as development proceeds (it's a lot nicer than autotools).
Eliot, do you have a view on this?
I use svn revision numbering to version stamp my builds. IMO it's essential that VMs be version stamped with the urls and version numbers of their constituent sources, and that they be built from versioned C that is produced from versioned VMMaker, /not/ that VM source is generated and built without versioning (except for personal use).
If Pharo uses git directly I want platforms/Cross/VM/sqSCCSVersion.h and its dual in (IIRC) platforms/Cross/plugins/sqSCCSPluginVersion.h to be updated so that git version info is included, and /not/ that Pharo takes its own route. All VMs should understand the -version command line option and display the appropriate information. (I wrote sqSCCSVersion.h to work with any source code control system, given a little editing, and it was hugely galling that this effort was ignored).
I also did a migration to github but didn't find time to test the subversion bridge.
I really, really want a build system that makes *very* limited use of either autoconf or cmake. If you look at the Cog build tree I've written gmake makefiles for Windows (adapted from Andreas' originals) and Mac OS X. These are much more malleable and easy to use than Xcode, autoconfig or cmake (IMNERHO (*)). Sooner rather than later the UNIX builds should move to this pattern too. In each build subdirectory is a common directory containing makefiles, eg build.macos32x86/common, and each build directory contains a very simple Makefile that includes the top level Makefile from common, supplying only configuration information.
The only thing missing from this scheme is a cmake or autoconf generated config file, [eg cogConfig.h to avoid conflicting with config.h files generated by cmake or autoconf when building libraries used by plugins, a maddening problem :-) ]. This file should live in the per-platform build directory, eg build.macos32x86/cogConfig.h, and be built once, not on every bloody build, wasting hide amounts of time for people doing VM development (it delays the results from slaves too).
Volunteers welcomed with open arms, and prostrate kissing of feet. *please* help. I'm begging. We need to "be in the same page"; we need to pool our efforts.
For example I would /love/ for someone expert in either autoconf or cmake to write good install instructions for Mac OS X (Xcode includes neither) and code to generate a cogConfig.h that defines things like HAS_POLL HAS_SELECT HAS_OPENGL et al.
I would /love/ for someone to do the same for Windows under Cygwin and/or Windows under mingw.
I would /love/ for someone to work on a 64-bit Spur build for win64.
I would /love/ for someone to organize the build.linux32ARM builds so that the VMs built there run in both Raspberry Pi and Android, and not merely complain to me that they don't and assume I'm an infinitely expandable resource and will get round to it someday even though I have no access to an android device but have three rpis and a b3.
Have I ranted enough now? Can I go back under my stone now and sulk?
:-)
(*) in my not even remotely humble opinion; I built VMs last night; part of my brain is not in a good mood ;-)
Dave
vm-dev@lists.squeakfoundation.org
-
 Ben Coman
Ben Coman -
 Bert Freudenberg
Bert Freudenberg -
 Clément Bera
Clément Bera -
 David T. Lewis
David T. Lewis -
 Eliot Miranda
Eliot Miranda -
 Esteban Lorenzano
Esteban Lorenzano -
 Fabio Niephaus
Fabio Niephaus -
 Frank Shearar
Frank Shearar -
 gettimothy
gettimothy -
 Nicolas Cellier
Nicolas Cellier -
 Stefan Marr
Stefan Marr -
 stephane ducasse
stephane ducasse -
 Tobias Pape
Tobias Pape -
 Tudor Girba
Tudor Girba -
 Yuriy Tymchuk
Yuriy Tymchuk